0x1 Langflow 远程代码执行与任意文件写入 CVE-2026-33017/33309
题目描述
Langflow 框架被曝出两个高危安全漏洞:未经身份验证的远程代码执行漏洞(CVE-2026-33017)以及经身份验证的任意文件写入漏洞(CVE-2026-33309)。
搜索
LangFlow 是一个基于 Python 的开源框架,旨在帮助开发者快速构建和部署自然语言处理(NLP)和对话系统。它提供了丰富的工具和组件,使得开发者可以轻松地创建复杂的对话流程和智能助手。LangFlow 专注于简化 NLP 应用的开发过程,通过提供易于理解的 API 和灵活的配置选项,使得对话系统的设计和实现变得更加直观和高效。
思路
题目既然说是远程代码执行和任意文件写入,那就找可能的触发点。
经过随手的点击,我发现了这个。

看看框架的数据包,理解理解。
经过前面的学习,我大概知道json有些是传递前端字段拼接的东西。
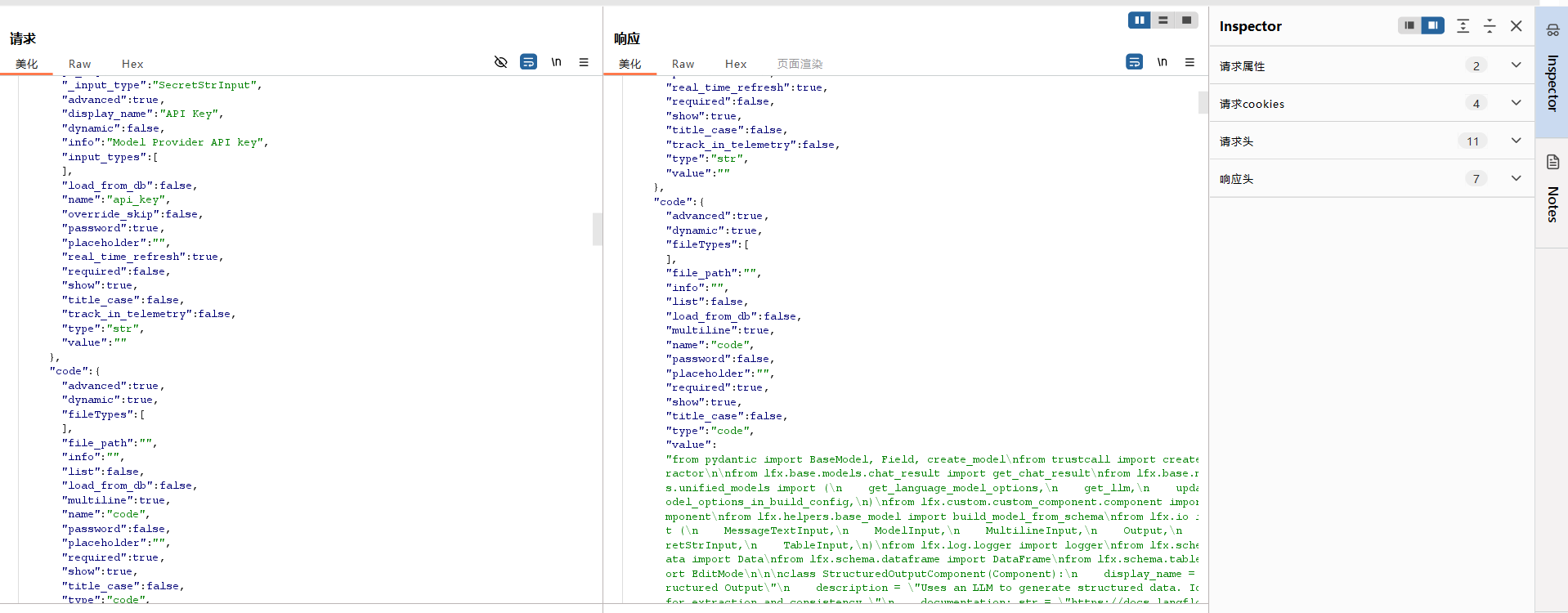
文件上传
POST /api/v2/files HTTP/1.1
Host: ulab.bdziyi.cn:20771
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:149.0) Gecko/20100101 Firefox/149.0
Accept: application/json, text/plain, */*
Accept-Language: zh-CN,zh;q=0.9,zh-TW;q=0.8,zh-HK;q=0.7,en-US;q=0.6,en;q=0.5
Accept-Encoding: gzip, deflate, br
Content-Type: multipart/form-data; boundary=----geckoformboundary2d9d55ff2ec0b46172ad54d7059b1beb
Content-Length: 219
Origin: http://ulab.bdziyi.cn:20771
Connection: keep-alive
Referer: http://ulab.bdziyi.cn:20771/assets/files
Cookie: access_token_lf=eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJzdWIiOiIxNjAyNDU4NS02NGQ3LTRkMGUtYTAzZi0yMjM2MTA2ZWVhOWUiLCJ0eXBlIjoiYWNjZXNzIiwiZXhwIjoxODA2ODM0NDY3fQ._T-1N9BHFujRlJnP4hZgy-Z3Dtmf8gpbWeNP3R1M_Tc; apikey_tkn_lflw=""; auto_login_lf=auto; sidebar:state=true; sidebar:section=components
------geckoformboundary2d9d55ff2ec0b46172ad54d7059b1beb
Content-Disposition: form-data; name="file"; filename="1234.txt"
Content-Type: text/plain
1231111
------geckoformboundary2d9d55ff2ec0b46172ad54d7059b1beb--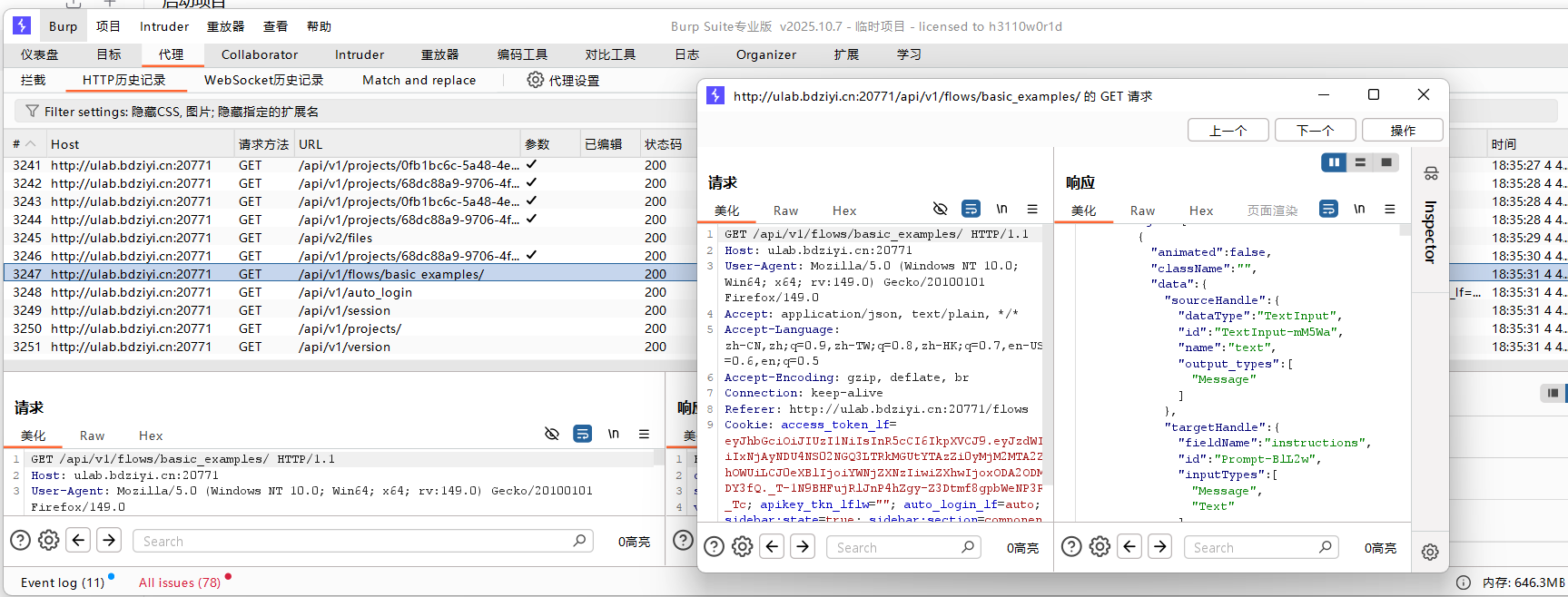
python
POST /api/v1/custom_component/update HTTP/1.1
Host: ulab.bdziyi.cn:20771
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:149.0) Gecko/20100101 Firefox/149.0
Accept: application/json, text/plain, */*
Accept-Language: zh-CN,zh;q=0.9,zh-TW;q=0.8,zh-HK;q=0.7,en-US;q=0.6,en;q=0.5
Accept-Encoding: gzip, deflate, br
Content-Type: application/json
Content-Length: 28591
Origin: http://ulab.bdziyi.cn:20771
Connection: keep-alive
Referer: http://ulab.bdziyi.cn:20771/flow/4c394d5d-31c3-4b8a-bb5b-f19c836324c5/folder/68dc88a9-9706-4f4e-85a3-cb5f234b1973
Cookie: access_token_lf=eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJzdWIiOiIxNjAyNDU4NS02NGQ3LTRkMGUtYTAzZi0yMjM2MTA2ZWVhOWUiLCJ0eXBlIjoiYWNjZXNzIiwiZXhwIjoxODA2ODMxMDMzfQ.MzOXin9LZTTSBxer88c9wMOCAcWDMyu8EP2CjBAOXBU; apikey_tkn_lflw=""; auto_login_lf=auto; sidebar:state=true
{"code":"from pydantic import BaseModel, Field, create_model\nfrom trustcall import create_extractor\n\nfrom lfx.base.models.chat_result import get_chat_result\nfrom lfx.base.models.unified_models import (\n get_language_model_options,\n get_llm,\n update_model_options_in_build_config,\n)\nfrom lfx.custom.custom_component.component import Component\nfrom lfx.helpers.base_model import build_model_from_schema\nfrom lfx.io import (\n MessageTextInput,\n ModelInput,\n MultilineInput,\n Output,\n SecretStrInput,\n TableInput,\n)\nfrom lfx.log.logger import logger\nfrom lfx.schema.data import Data\nfrom lfx.schema.dataframe import DataFrame\nfrom lfx.schema.table import EditMode\n\n\nclass StructuredOutputComponent(Component):\n display_name = \"Structured Output\"\n description = \"Uses an LLM to generate structured data. Ideal for extraction and consistency.\"\n documentation: str = \"https://docs.langflow.org/structured-output\"\n name = \"StructuredOutput\"\n icon = \"braces\"\n\n inputs = [\n ModelInput(\n name=\"model\",\n display_name=\"Language Model\",\n info=\"Select your model provider\",\n real_time_refresh=True,\n required=True,\n ),\n SecretStrInput(\n name=\"api_key\",\n display_name=\"API Key\",\n info=\"Model Provider API key\",\n real_time_refresh=True,\n advanced=True,\n ),\n MultilineInput(\n name=\"input_value\",\n display_name=\"Input Message\",\n info=\"The input message to the language model.\",\n tool_mode=True,\n required=True,\n ),\n MultilineInput(\n name=\"system_prompt\",\n display_name=\"Format Instructions\",\n info=\"The instructions to the language model for formatting the output.\",\n value=(\n \"You are an AI that extracts structured JSON objects from unstructured text. \"\n \"Use a predefined schema with expected types (str, int, float, bool, dict). \"\n \"Extract ALL relevant instances that match the schema - if multiple patterns exist, capture them all. \"\n \"Fill missing or ambiguous values with defaults: null for missing values. \"\n \"Remove exact duplicates but keep variations that have different field values. \"\n \"Always return valid JSON in the expected format, never throw errors. \"\n \"If multiple objects can be extracted, return them all in the structured format.\"\n ),\n required=True,\n advanced=True,\n ),\n MessageTextInput(\n name=\"schema_name\",\n display_name=\"Schema Name\",\n info=\"Provide a name for the output data schema.\",\n advanced=True,\n ),\n TableInput(\n name=\"output_schema\",\n display_name=\"Output Schema\",\n info=\"Define the structure and data types for the model's output.\",\n required=True,\n # TODO: remove deault value\n table_schema=[\n {\n \"name\": \"name\",\n \"display_name\": \"Name\",\n \"type\": \"str\",\n \"description\": \"Specify the name of the output field.\",\n \"default\": \"field\",\n \"edit_mode\": EditMode.INLINE,\n },\n {\n \"name\": \"description\",\n \"display_name\": \"Description\",\n \"type\": \"str\",\n \"description\": \"Describe the purpose of the output field.\",\n \"default\": \"description of field\",\n \"edit_mode\": EditMode.POPOVER,\n },\n {\n \"name\": \"type\",\n \"display_name\": \"Type\",\n \"type\": \"str\",\n \"edit_mode\": EditMode.INLINE,\n \"description\": (\"Indicate the data type of the output field (e.g., str, int, float, bool, dict).\"),\n \"options\": [\"str\", \"int\", \"float\", \"bool\", \"dict\"],\n \"default\": \"str\",\n },\n {\n \"name\": \"multiple\",\n \"display_name\": \"As List\",\n \"type\": \"boolean\",\n \"description\": \"Set to True if this output field should be a list of the specified type.\",\n \"default\": \"False\",\n \"edit_mode\": EditMode.INLINE,\n },\n ],\n value=[\n {\n \"name\": \"field\",\n \"description\": \"description of field\",\n \"type\": \"str\",\n \"multiple\": \"False\",\n }\n ],\n ),\n ]\n\n outputs = [\n Output(\n name=\"structured_output\",\n display_name=\"Structured Output\",\n method=\"build_structured_output\",\n ),\n Output(\n name=\"dataframe_output\",\n display_name=\"Structured Output\",\n method=\"build_structured_dataframe\",\n ),\n ]\n\n def update_build_config(self, build_config: dict, field_value: str, field_name: str | None = None):\n \"\"\"Dynamically update build config with user-filtered model options.\"\"\"\n return update_model_options_in_build_config(\n component=self,\n build_config=build_config,\n cache_key_prefix=\"language_model_options\",\n get_options_func=get_language_model_options,\n field_name=field_name,\n field_value=field_value,\n )\n\n def build_structured_output_base(self):\n schema_name = self.schema_name or \"OutputModel\"\n\n llm = get_llm(model=self.model, user_id=self.user_id, api_key=self.api_key)\n\n if not hasattr(llm, \"with_structured_output\"):\n msg = \"Language model does not support structured output.\"\n raise TypeError(msg)\n if not self.output_schema:\n msg = \"Output schema cannot be empty\"\n raise ValueError(msg)\n\n output_model_ = build_model_from_schema(self.output_schema)\n output_model = create_model(\n schema_name,\n __doc__=f\"A list of {schema_name}.\",\n objects=(\n list[output_model_],\n Field(\n description=f\"A list of {schema_name}.\", # type: ignore[valid-type]\n min_length=1, # help ensure non-empty output\n ),\n ),\n )\n # Tracing config\n config_dict = {\n \"run_name\": self.display_name,\n \"project_name\": self.get_project_name(),\n \"callbacks\": self.get_langchain_callbacks(),\n }\n # Generate structured output using Trustcall first, then fallback to Langchain if it fails\n result = self._extract_output_with_trustcall(llm, output_model, config_dict)\n if result is None:\n result = self._extract_output_with_langchain(llm, output_model, config_dict)\n\n # OPTIMIZATION NOTE: Simplified processing based on trustcall response structure\n # Handle non-dict responses (shouldn't happen with trustcall, but defensive)\n if not isinstance(result, dict):\n return result\n\n # Extract first response and convert BaseModel to dict\n responses = result.get(\"responses\", [])\n if not responses:\n return result\n\n # Convert BaseModel to dict (creates the \"objects\" key)\n first_response = responses[0]\n structured_data = first_response\n if isinstance(first_response, BaseModel):\n structured_data = first_response.model_dump()\n # Extract the objects array (guaranteed to exist due to our Pydantic model structure)\n return structured_data.get(\"objects\", structured_data)\n\n def build_structured_output(self) -> Data:\n output = self.build_structured_output_base()\n if not isinstance(output, list) or not output:\n # handle empty or unexpected type case\n msg = \"No structured output returned\"\n raise ValueError(msg)\n if len(output) == 1:\n return Data(data=output[0])\n if len(output) > 1:\n # Multiple outputs - wrap them in a results container\n return Data(data={\"results\": output})\n return Data()\n\n def build_structured_dataframe(self) -> DataFrame:\n output = self.build_structured_output_base()\n if not isinstance(output, list) or not output:\n # handle empty or unexpected type case\n msg = \"No structured output returned\"\n raise ValueError(msg)\n if len(output) == 1:\n # For single dictionary, wrap in a list to create DataFrame with one row\n return DataFrame([output[0]])\n if len(output) > 1:\n # Multiple outputs - convert to DataFrame directly\n return DataFrame(output)\n return DataFrame()\n\n def _extract_output_with_trustcall(self, llm, schema: BaseModel, config_dict: dict) -> list[BaseModel] | None:\n try:\n llm_with_structured_output = create_extractor(llm, tools=[schema], tool_choice=schema.__name__)\n result = get_chat_result(\n runnable=llm_with_structured_output,\n system_message=self.system_prompt,\n input_value=self.input_value,\n config=config_dict,\n )\n except Exception as e: # noqa: BLE001\n logger.warning(\n f\"Trustcall extraction failed, falling back to Langchain: {e} \"\n \"(Note: This may not be an error---some models or configurations do not support tool calling. \"\n \"Falling back is normal in such cases.)\"\n )\n return None\n return result or None # langchain fallback is used if error occurs or the result is empty\n\n def _extract_output_with_langchain(self, llm, schema: BaseModel, config_dict: dict) -> list[BaseModel] | None:\n try:\n llm_with_structured_output = llm.with_structured_output(schema)\n result = get_chat_result(\n runnable=llm_with_structured_output,\n system_message=self.system_prompt,\n input_value=self.input_value,\n config=config_dict,\n )\n if isinstance(result, BaseModel):\n result = result.model_dump()\n result = result.get(\"objects\", result)\n except Exception as fallback_error:\n msg = (\n f\"Model does not support tool calling (trustcall failed) \"\n f\"and fallback with_structured_output also failed: {fallback_error}\"\n )\n raise ValueError(msg) from fallback_error\n\n return result or None\n","template":{"_type":"Component","api_key":{"_input_type":"SecretStrInput","advanced":true,"display_name":"API Key","dynamic":false,"info":"Model Provider API key","input_types":[],"load_from_db":false,"name":"api_key","override_skip":false,"password":true,"placeholder":"","real_time_refresh":true,"required":false,"show":true,"title_case":false,"track_in_telemetry":false,"type":"str","value":""},"code":{"advanced":true,"dynamic":true,"fileTypes":[],"file_path":"","info":"","list":false,"load_from_db":false,"multiline":true,"name":"code","password":false,"placeholder":"","required":true,"show":true,"title_case":false,"type":"code","value":"from pydantic import BaseModel, Field, create_model\nfrom trustcall import create_extractor\n\nfrom lfx.base.models.chat_result import get_chat_result\nfrom lfx.base.models.unified_models import (\n get_language_model_options,\n get_llm,\n update_model_options_in_build_config,\n)\nfrom lfx.custom.custom_component.component import Component\nfrom lfx.helpers.base_model import build_model_from_schema\nfrom lfx.io import (\n MessageTextInput,\n ModelInput,\n MultilineInput,\n Output,\n SecretStrInput,\n TableInput,\n)\nfrom lfx.log.logger import logger\nfrom lfx.schema.data import Data\nfrom lfx.schema.dataframe import DataFrame\nfrom lfx.schema.table import EditMode\n\n\nclass StructuredOutputComponent(Component):\n display_name = \"Structured Output\"\n description = \"Uses an LLM to generate structured data. Ideal for extraction and consistency.\"\n documentation: str = \"https://docs.langflow.org/structured-output\"\n name = \"StructuredOutput\"\n icon = \"braces\"\n\n inputs = [\n ModelInput(\n name=\"model\",\n display_name=\"Language Model\",\n info=\"Select your model provider\",\n real_time_refresh=True,\n required=True,\n ),\n SecretStrInput(\n name=\"api_key\",\n display_name=\"API Key\",\n info=\"Model Provider API key\",\n real_time_refresh=True,\n advanced=True,\n ),\n MultilineInput(\n name=\"input_value\",\n display_name=\"Input Message\",\n info=\"The input message to the language model.\",\n tool_mode=True,\n required=True,\n ),\n MultilineInput(\n name=\"system_prompt\",\n display_name=\"Format Instructions\",\n info=\"The instructions to the language model for formatting the output.\",\n value=(\n \"You are an AI that extracts structured JSON objects from unstructured text. \"\n \"Use a predefined schema with expected types (str, int, float, bool, dict). \"\n \"Extract ALL relevant instances that match the schema - if multiple patterns exist, capture them all. \"\n \"Fill missing or ambiguous values with defaults: null for missing values. \"\n \"Remove exact duplicates but keep variations that have different field values. \"\n \"Always return valid JSON in the expected format, never throw errors. \"\n \"If multiple objects can be extracted, return them all in the structured format.\"\n ),\n required=True,\n advanced=True,\n ),\n MessageTextInput(\n name=\"schema_name\",\n display_name=\"Schema Name\",\n info=\"Provide a name for the output data schema.\",\n advanced=True,\n ),\n TableInput(\n name=\"output_schema\",\n display_name=\"Output Schema\",\n info=\"Define the structure and data types for the model's output.\",\n required=True,\n # TODO: remove deault value\n table_schema=[\n {\n \"name\": \"name\",\n \"display_name\": \"Name\",\n \"type\": \"str\",\n \"description\": \"Specify the name of the output field.\",\n \"default\": \"field\",\n \"edit_mode\": EditMode.INLINE,\n },\n {\n \"name\": \"description\",\n \"display_name\": \"Description\",\n \"type\": \"str\",\n \"description\": \"Describe the purpose of the output field.\",\n \"default\": \"description of field\",\n \"edit_mode\": EditMode.POPOVER,\n },\n {\n \"name\": \"type\",\n \"display_name\": \"Type\",\n \"type\": \"str\",\n \"edit_mode\": EditMode.INLINE,\n \"description\": (\"Indicate the data type of the output field (e.g., str, int, float, bool, dict).\"),\n \"options\": [\"str\", \"int\", \"float\", \"bool\", \"dict\"],\n \"default\": \"str\",\n },\n {\n \"name\": \"multiple\",\n \"display_name\": \"As List\",\n \"type\": \"boolean\",\n \"description\": \"Set to True if this output field should be a list of the specified type.\",\n \"default\": \"False\",\n \"edit_mode\": EditMode.INLINE,\n },\n ],\n value=[\n {\n \"name\": \"field\",\n \"description\": \"description of field\",\n \"type\": \"str\",\n \"multiple\": \"False\",\n }\n ],\n ),\n ]\n\n outputs = [\n Output(\n name=\"structured_output\",\n display_name=\"Structured Output\",\n method=\"build_structured_output\",\n ),\n Output(\n name=\"dataframe_output\",\n display_name=\"Structured Output\",\n method=\"build_structured_dataframe\",\n ),\n ]\n\n def update_build_config(self, build_config: dict, field_value: str, field_name: str | None = None):\n \"\"\"Dynamically update build config with user-filtered model options.\"\"\"\n return update_model_options_in_build_config(\n component=self,\n build_config=build_config,\n cache_key_prefix=\"language_model_options\",\n get_options_func=get_language_model_options,\n field_name=field_name,\n field_value=field_value,\n )\n\n def build_structured_output_base(self):\n schema_name = self.schema_name or \"OutputModel\"\n\n llm = get_llm(model=self.model, user_id=self.user_id, api_key=self.api_key)\n\n if not hasattr(llm, \"with_structured_output\"):\n msg = \"Language model does not support structured output.\"\n raise TypeError(msg)\n if not self.output_schema:\n msg = \"Output schema cannot be empty\"\n raise ValueError(msg)\n\n output_model_ = build_model_from_schema(self.output_schema)\n output_model = create_model(\n schema_name,\n __doc__=f\"A list of {schema_name}.\",\n objects=(\n list[output_model_],\n Field(\n description=f\"A list of {schema_name}.\", # type: ignore[valid-type]\n min_length=1, # help ensure non-empty output\n ),\n ),\n )\n # Tracing config\n config_dict = {\n \"run_name\": self.display_name,\n \"project_name\": self.get_project_name(),\n \"callbacks\": self.get_langchain_callbacks(),\n }\n # Generate structured output using Trustcall first, then fallback to Langchain if it fails\n result = self._extract_output_with_trustcall(llm, output_model, config_dict)\n if result is None:\n result = self._extract_output_with_langchain(llm, output_model, config_dict)\n\n # OPTIMIZATION NOTE: Simplified processing based on trustcall response structure\n # Handle non-dict responses (shouldn't happen with trustcall, but defensive)\n if not isinstance(result, dict):\n return result\n\n # Extract first response and convert BaseModel to dict\n responses = result.get(\"responses\", [])\n if not responses:\n return result\n\n # Convert BaseModel to dict (creates the \"objects\" key)\n first_response = responses[0]\n structured_data = first_response\n if isinstance(first_response, BaseModel):\n structured_data = first_response.model_dump()\n # Extract the objects array (guaranteed to exist due to our Pydantic model structure)\n return structured_data.get(\"objects\", structured_data)\n\n def build_structured_output(self) -> Data:\n output = self.build_structured_output_base()\n if not isinstance(output, list) or not output:\n # handle empty or unexpected type case\n msg = \"No structured output returned\"\n raise ValueError(msg)\n if len(output) == 1:\n return Data(data=output[0])\n if len(output) > 1:\n # Multiple outputs - wrap them in a results container\n return Data(data={\"results\": output})\n return Data()\n\n def build_structured_dataframe(self) -> DataFrame:\n output = self.build_structured_output_base()\n if not isinstance(output, list) or not output:\n # handle empty or unexpected type case\n msg = \"No structured output returned\"\n raise ValueError(msg)\n if len(output) == 1:\n # For single dictionary, wrap in a list to create DataFrame with one row\n return DataFrame([output[0]])\n if len(output) > 1:\n # Multiple outputs - convert to DataFrame directly\n return DataFrame(output)\n return DataFrame()\n\n def _extract_output_with_trustcall(self, llm, schema: BaseModel, config_dict: dict) -> list[BaseModel] | None:\n try:\n llm_with_structured_output = create_extractor(llm, tools=[schema], tool_choice=schema.__name__)\n result = get_chat_result(\n runnable=llm_with_structured_output,\n system_message=self.system_prompt,\n input_value=self.input_value,\n config=config_dict,\n )\n except Exception as e: # noqa: BLE001\n logger.warning(\n f\"Trustcall extraction failed, falling back to Langchain: {e} \"\n \"(Note: This may not be an error---some models or configurations do not support tool calling. \"\n \"Falling back is normal in such cases.)\"\n )\n return None\n return result or None # langchain fallback is used if error occurs or the result is empty\n\n def _extract_output_with_langchain(self, llm, schema: BaseModel, config_dict: dict) -> list[BaseModel] | None:\n try:\n llm_with_structured_output = llm.with_structured_output(schema)\n result = get_chat_result(\n runnable=llm_with_structured_output,\n system_message=self.system_prompt,\n input_value=self.input_value,\n config=config_dict,\n )\n if isinstance(result, BaseModel):\n result = result.model_dump()\n result = result.get(\"objects\", result)\n except Exception as fallback_error:\n msg = (\n f\"Model does not support tool calling (trustcall failed) \"\n f\"and fallback with_structured_output also failed: {fallback_error}\"\n )\n raise ValueError(msg) from fallback_error\n\n return result or None\n"},"input_value":{"_input_type":"MultilineInput","advanced":false,"copy_field":false,"display_name":"Input Message","dynamic":false,"info":"The input message to the language model.","input_types":["Message"],"list":false,"list_add_label":"Add More","load_from_db":false,"multiline":true,"name":"input_value","placeholder":"","required":true,"show":true,"title_case":false,"tool_mode":true,"trace_as_input":true,"trace_as_metadata":true,"type":"str","value":""},"model":{"_input_type":"ModelInput","advanced":false,"display_name":"Language Model","dynamic":false,"external_options":{"fields":{"data":{"node":{"display_name":"Connect other models","icon":"CornerDownLeft","name":"connect_other_models"}}}},"info":"Select your model provider","input_types":["LanguageModel"],"list":false,"list_add_label":"Add More","model_type":"language","name":"model","override_skip":false,"placeholder":"Setup Provider","real_time_refresh":true,"refresh_button":true,"required":true,"show":true,"title_case":false,"tool_mode":false,"trace_as_input":true,"track_in_telemetry":false,"type":"model","value":""},"output_schema":{"_input_type":"TableInput","advanced":false,"display_name":"Output Schema","dynamic":false,"info":"Define the structure and data types for the model's output.","is_list":true,"list_add_label":"Add More","name":"output_schema","placeholder":"","required":true,"show":true,"table_icon":"Table","table_schema":[{"default":"field","description":"Specify the name of the output field.","display_name":"Name","edit_mode":"inline","formatter":"text","name":"name","type":"str"},{"default":"description of field","description":"Describe the purpose of the output field.","display_name":"Description","edit_mode":"popover","formatter":"text","name":"description","type":"str"},{"default":"str","description":"Indicate the data type of the output field (e.g., str, int, float, bool, dict).","display_name":"Type","edit_mode":"inline","formatter":"text","name":"type","options":["str","int","float","bool","dict"],"type":"str"},{"default":"False","description":"Set to True if this output field should be a list of the specified type.","display_name":"As List","edit_mode":"inline","formatter":"text","name":"multiple","type":"boolean"}],"title_case":false,"tool_mode":false,"trace_as_metadata":true,"trigger_icon":"Table","trigger_text":"Open table","type":"table","value":[{"description":"Primary company domain name","multiple":"False","name":"domain","type":"str"},{"description":"Company's LinkedIn URL","multiple":"False","name":"linkedinUrl","type":"str"},{"description":"Lowest priced plan in USD (number only)","multiple":"False","name":"cheapestPlan","type":"str"},{"description":"Boolean indicating if they offer a free trial","multiple":"False","name":"hasFreeTrial","type":"bool"},{"description":"Boolean indicating if they have enterprise options","multiple":"False","name":"hasEnterprisePlan","type":"bool"},{"description":"Boolean indicating if they offer API access","multiple":"False","name":"hasAPI","type":"bool"},{"description":"Either 'B2B' or 'B2C' or 'Both","multiple":"False","name":"market","type":"str"},{"description":"List of available pricing tiers","multiple":"True","name":"pricingTiers","type":"str"},{"description":"List of main features","multiple":"True","name":"KeyFeatures","type":"str"},{"description":"List of target industries","multiple":"True","name":"targetIndustries","type":"str"}]},"schema_name":{"_input_type":"MessageTextInput","advanced":true,"display_name":"Schema Name","dynamic":false,"info":"Provide a name for the output data schema.","input_types":["Message"],"list":false,"list_add_label":"Add More","load_from_db":false,"name":"schema_name","placeholder":"","required":false,"show":true,"title_case":false,"tool_mode":false,"trace_as_input":true,"trace_as_metadata":true,"type":"str","value":""},"system_prompt":{"_input_type":"MultilineInput","advanced":true,"copy_field":false,"display_name":"Format Instructions","dynamic":false,"info":"The instructions to the language model for formatting the output.","input_types":["Message"],"list":false,"list_add_label":"Add More","load_from_db":false,"multiline":true,"name":"system_prompt","placeholder":"","required":true,"show":true,"title_case":false,"tool_mode":false,"trace_as_input":true,"trace_as_metadata":true,"type":"str","value":"You are an AI that extracts structured JSON objects from unstructured text. Use a predefined schema with expected types (str, int, float, bool, dict). Extract ALL relevant instances that match the schema - if multiple patterns exist, capture them all. Fill missing or ambiguous values with defaults: null for missing values. Remove exact duplicates but keep variations that have different field values. Always return valid JSON in the expected format, never throw errors. If multiple objects can be extracted, return them all in the structured format."},"_frontend_node_flow_id":{"value":"4c394d5d-31c3-4b8a-bb5b-f19c836324c5"},"_frontend_node_folder_id":{"value":"68dc88a9-9706-4f4e-85a3-cb5f234b1973"},"is_refresh":false},"field":"model","field_value":"","tool_mode":false}学习
实在不懂他们是怎么找到的,看一下poc。
https://wittpeng.blog.csdn.net/article/details/159549218
什么是Langflow
Langflow是一个强大的低代码AI工作流构建平台,用于构建和部署AI代理和工作流应用。
特点
低代码
拖拽式可视化界面
多模型支持
OpenAI、Anthropic、Azure、HuggingFace等
向量数据库
Pinecone、Milvus、Weaviate、Qdrant等
数据源集成
GitHub、Gmail、Notion、Confluence等
MCP服务器
可将工作流部署为MCP服务器
Python定制
可用Python自定义任何组件
主要应用场景
- RAG应用:搭建知识库问答
- Agent工作流:多步骤自动化
- API部署:将工作流发布为API
- MCP工具:作为MCP客户端的工具
< 1.8.0
1.81这里date被删除了,但是仍然可以利用。
"""Build a public flow without requiring authentication.
This endpoint is specifically for public flows that don't require authentication.
It uses a client_id cookie to create a deterministic flow ID for tracking purposes.
Security Note:
- The 'data' parameter is NOT accepted to prevent flow definition tampering
- Public flows must execute the stored flow definition only
- The flow definition is always loaded from the database
The endpoint:
1. Verifies the requested flow is marked as public in the database
2. Creates a deterministic UUID based on client_id and flow_id
3. Uses the flow owner's permissions to build the flow
4. Always loads the flow definition from the database
Requirements:
- The flow must be marked as PUBLIC in the database
- The request must include a client_id cookie
Args:
flow_id: UUID of the public flow to build
background_tasks: Background tasks manager
inputs: Optional input values for the flow
files: Optional files to include
stop_component_id: Optional ID of component to stop at
start_component_id: Optional ID of component to start from
log_builds: Whether to log the build process
flow_name: Optional name for the flow
request: FastAPI request object (needed for cookie access)
queue_service: Queue service for job management
event_delivery: Optional event delivery type - default is streaming
Returns:
Dict with job_id that can be used to poll for build status
""""""构建一个无需身份验证的公共流程。
此端点专用于不需要身份验证的公共流程。
它使用 client_id cookie 创建一个确定性的流程 ID 用于跟踪目的。
安全提示:
-
不接受 'data' 参数,以防止流程定义被篡改
-
公共流程只能执行存储的流程定义
-
流程定义始终从数据库加载
此端点执行以下操作:
-
验证请求的流程在数据库中标记为公开
-
基于 client_id 和 flow_id 创建一个确定性的 UUID
-
使用流程所有者的权限来构建流程
-
始终从数据库加载流程定义
要求:
-
流程必须在数据库中标记为 PUBLIC
-
请求必须包含 client_id cookie
参数:
flow_id: 要构建的公共流程的 UUID
background_tasks: 后台任务管理器
inputs: 流程的可选输入值
files: 可选包含的文件
stop_component_id: 可选,要停止的组件 ID
start_component_id: 可选,要开始的组件 ID
log_builds: 是否记录构建过程
flow_name: 流程的可选名称
request: FastAPI 请求对象(需要访问 cookie)
queue_service: 用于作业管理的队列服务
event_delivery: 可选的事件传递类型,默认为流式
返回:
包含 job_id 的字典,可用于轮询构建状态
"""
问题路由
https://github.com/langflow-ai/langflow/security/advisories/GHSA-vwmf-pq79-vjvx
当攻击者提供data数据时,数据会依次经过以下流程:
start_flow_build(data=attacker_data)→generate_flow_events()--build.py:81create_graph()→build_graph_from_data(payload=data.model_dump())--build.py:298Graph.from_payload(payload)解析攻击者节点 --base.py:1168add_nodes_and_edges()→initialize()→_build_graph()--base.py:270,527_instantiate_components_in_vertices()迭代节点 --base.py:1323vertex.instantiate_component()→instantiate_class(vertex)--loading.py:28code = custom_params.pop("code")提取攻击者代码loading.py:43eval_custom_component_code(code)→create_class(code, class_name)--eval.py:9prepare_global_scope(module)--validate.py:323exec(compiled_code, exec_globals)--任意代码执行 --validate.py:397
python
@router.post("/build_public_tmp/{flow_id}/flow")
async def build_public_tmp(
#强调格式v=k
*,
#后台管理器
background_tasks: LimitVertexBuildBackgroundTasks,
#解析对象
flow_id: uuid.UUID,
#提取输入值,inputs{{}}提取,可选数据流
inputs: Annotated[InputValueRequest | None, Body(embed=True)] = None,
#文件id
files: list[str] | None = None,
#范围限定,
stop_component_id: str | None = None,
start_component_id: str | None = None,
#是否记录日志
log_builds: bool | None = True,
#实例名称
flow_name: str | None = None,
#重点
request: Request,
#
queue_service: Annotated[JobQueueService, Depends(get_queue_service)],
event_delivery: EventDeliveryType = EventDeliveryType.POLLING,
):
java
async def start_flow_build(
*,
flow_id: uuid.UUID,
background_tasks: BackgroundTasks,
inputs: InputValueRequest | None,
data: FlowDataRequest | None,
files: list[str] | None,
stop_component_id: str | None,
start_component_id: str | None,
log_builds: bool,
current_user: CurrentActiveUser,
queue_service: JobQueueService,
flow_name: str | None = None,
) -> str:
"""Start the flow build process by setting up the queue and starting the build task.
Returns:
the job_id.
"""
job_id = str(uuid.uuid4())
try:
_, event_manager = queue_service.create_queue(job_id)
task_coro = generate_flow_events(
flow_id=flow_id,
background_tasks=background_tasks,
event_manager=event_manager,
inputs=inputs,
data=data,
files=files,
stop_component_id=stop_component_id,
start_component_id=start_component_id,
log_builds=log_builds,
current_user=current_user,
flow_name=flow_name,
)
queue_service.start_job(job_id, task_coro)
except Exception as e:
await logger.aexception("Failed to create queue and start task")
raise HTTPException(status_code=500, detail=str(e)) from e
return job_id格式
java
"/api/v1/build_public_tmp/{flow_id}/flow": {
"post": {
"tags": [
"Chat"
],
"summary": "Build Public Tmp",
"description": "Build a public flow without requiring authentication.<br><br>This endpoint is specifically for public flows that don't require authentication.<br>It uses a client_id cookie to create a deterministic flow ID for tracking purposes.<br><br>The endpoint:<br>1. Verifies the requested flow is marked as public in the database<br>2. Creates a deterministic UUID based on client_id and flow_id<br>3. Uses the flow owner's permissions to build the flow<br><br>Requirements:<br>- The flow must be marked as PUBLIC in the database<br>- The request must include a client_id cookie<br><br>Args:<br> flow_id: UUID of the public flow to build<br> background_tasks: Background tasks manager<br> inputs: Optional input values for the flow<br> data: Optional flow data<br> files: Optional files to include<br> stop_component_id: Optional ID of component to stop at<br> start_component_id: Optional ID of component to start from<br> log_builds: Whether to log the build process<br> flow_name: Optional name for the flow<br> request: FastAPI request object (needed for cookie access)<br> queue_service: Queue service for job management<br> event_delivery: Optional event delivery type - default is streaming<br><br>Returns:<br> Dict with job_id that can be used to poll for build status",
"operationId": "build_public_tmp_api_v1_build_public_tmp__flow_id__flow_post",
"parameters": [
{
"name": "flow_id",
"in": "path",
"required": true,
"schema": {
"type": "string",
"format": "uuid",
"title": "Flow Id"
}
},
java
def prepare_global_scope(module):
"""Prepares the global scope with necessary imports from the provided code module.
Args:
module: AST parsed module
Returns:
Dictionary representing the global scope with imported modules
Raises:
ModuleNotFoundError: If a module is not found in the code
"""
exec_globals = globals().copy()
imports = []
import_froms = []
definitions = []
for node in module.body:
if isinstance(node, ast.Import):
imports.append(node)
elif isinstance(node, ast.ImportFrom) and node.module is not None:
import_froms.append(node)
elif isinstance(node, ast.ClassDef | ast.FunctionDef | ast.Assign | ast.AnnAssign):
definitions.append(node)
for node in imports:
for alias in node.names:
module_name = alias.name
# Import the full module path to ensure submodules are loaded
module_obj = importlib.import_module(module_name)
# Determine the variable name
if alias.asname:
# For aliased imports like "import yfinance as yf", use the imported module directly
variable_name = alias.asname
exec_globals[variable_name] = module_obj
else:
# For dotted imports like "urllib.request", set the variable to the top-level package
variable_name = module_name.split(".")[0]
exec_globals[variable_name] = importlib.import_module(variable_name)
for node in import_froms:
module_names_to_try = [node.module]
# If original module starts with langflow, also try lfx equivalent
if node.module and node.module.startswith("langflow."):
lfx_module_name = node.module.replace("langflow.", "lfx.", 1)
module_names_to_try.append(lfx_module_name)
success = False
last_error = None
for module_name in module_names_to_try:
try:
imported_module = _import_module_with_warnings(module_name)
_handle_module_attributes(imported_module, node, module_name, exec_globals)
success = True
break
except ModuleNotFoundError as e:
last_error = e
continue
if not success:
# Re-raise the last error to preserve the actual missing module information
if last_error:
raise last_error
msg = f"Module {node.module} not found. Please install it and try again"
raise ModuleNotFoundError(msg)
if definitions:
combined_module = ast.Module(body=definitions, type_ignores=[])
compiled_code = compile(combined_module, "<string>", "exec")
exec(compiled_code, exec_globals)
return exec_globals