1.默克尔树
1.1默克尔树根哈希
像之前我们对区块头进行了哈希,包括创世区块的哈希值,可见这些数据就是区块的最终哈希,但是好像没看到交易数据?这样得来的哈希值如何能代表区块呢?区块的核心就是交易数据。
问题的关键点在默克尔树,在CBlock类有这个字段:uint256 hashMerkleRoot;
它是默克尔树根哈希,代表了交易数据,是根据一定的规则将交易数据进行多重哈希得来的值。
所以我们哈希值区块头,将这个值也包含进去了,相当于间接的哈希了交易数据。其性质是一样的。不需要哈希原始交易数据。
1.2交易类CTransaction
为了方便理解默克尔树,这里区块里的交易部分用字符串代替,不涉及真实的交易实现,我们先来实现一个简单的交易类,里面保存交易数据,如下:
cpp
//处理和存储交易数据的类
class CTransaction
{
public:
string vin;
string vout;
};在真实的区块里,vin,vout的定义不是字符串 ,而是自定义类对象,并且是vector数组。
这里我就简单的用一个字符串代替了。
比如,A转给B 50个btc。交易数据格式就是这这样:
vin="a:50";
vout="b:50";
表示扣掉a 50个btc,b增加50btc。
这里不采用string data="a to b 50";是为了更接近源码的设计写法,方便以后我们更好的理解交易部分。
1.3交易数据序列化
因为哈希需要字节形式的数据,所以我们需要将CTransaction类对象序列化字节流。
在源码中已经有相关实现,我们直接拿来使用。
cpp
uint256 GetHash() const
{
return SerializeHash(*this);
}SerializeHash这个函数,将对象序化并且进行哈希,然后返回哈希值。
我们来看一下怎么实现的,方便我们来正常的使用它,解决兼容性问题:
这是一个模板函数,定义在util.h头文件里
cpp
template<typename T>
uint256 SerializeHash(const T& obj, int nType=SER_GETHASH, int nVersion=VERSION)
{
// Most of the time is spent allocating and deallocating CDataStream's
// buffer. If this ever needs to be optimized further, make a CStaticStream
// class with its buffer on the stack.
CDataStream ss(nType, nVersion);
ss.reserve(10000);
ss << obj;
return Hash(ss.begin(), ss.end());
}util头文件我们已经有了,但是我们之前只添加了一个hash函数,这里我们不复制util.h头文件,只复制里面的SerializeHash函数代码到我们的util.h中(复制上述代码)。
可以看到,序列化用到了CDataStream类
先创建CDataStream类对象,nType,nVersion为默认值,SER_GETHASH,VERSION在serialize.h有定义。
然后为这个对象预分配10000字节空间,一般序列化对象不会超过这个大小,足够用了。
接着ss<<obj,这是最关键的一句,将obj序列化给ss。
这个<<写法是重载了操作符。
然后ss.begin()是序列化数据起始地址,ss.end是结束地址。
2.CDataStream类
CDataStream类是一个序列化类,用来帮助我们序列化各种类型,如int,string,vector,map等。都可以用CDataStream很方便的实现序列化和反序列化。
这个类存在于serialize.h头文件里,我们需要将源码中的serialize.h拷到我们的项目中。
以下为解决文件报错过程(不需要了解可跳过,后面会给出改好的头文件,直接使用即可)
2.1boost库
复制过来后,发现开头有这一句:
cpp
#include <boost/type_traits/is_fundamental.hpp>这个是boost第三方库相关,说明serialize.h需要使用boost库的某些功能。
经过查找,发现使用的是 boost::is_fundamental<T>这个模板类功能,这个类的作用是能帮我们判断一个类型是否是基本类型,如int,char,double,而不是string,或者用户自定义的类等。
为什么需要这个呢,因为序列化vector类型时,需要判断是vector<int>基本类型,还是vector<string>类型,因为基本和非基本类型内存布局原因,两者需要不同的序列化实现。
由于源码中使用boost库的地方不多,只是序列vector类型需要用到,分别用到了下面三个类:
boost::is_fundamental;
boost::true_type;
boost::false_type;
而安装boost库,可能需要指定的版本。
这里我们优先使用替换方案解决,这个库将留在以后看情况安装,非目前重点。
2.2type_traits代用库
我们可以用自带的C++ 标准库type_traits来代替,需要C++ 11支持。
用里面的std::is_fundamental模板类代替boost::is_fundamental;
std::is_fundamental会根据类型生成对应的类实例:std::is_fundamental<类型>()
基本类型生成: std::true_type 类型对象
非基本类型生成: std::false_type 类型对象。
以下为使用示例:
cpp
// tmp.cpp : 此文件包含 "main" 函数。程序执行将在此处开始并结束。
//
#include <iostream>
#include<string>
#include <type_traits>
#include<vector>
template<typename T>
void Serialize_impl(const std::vector<T>& v,const std::true_type&)
{
std::cout << "调用基本类型序列化" << std::endl;
//处理v对象代码...
}
template<typename T>
void Serialize_impl(const std::vector<T>& v,const std::false_type&)
{
std::cout << "调用非基本类型序列化" << std::endl;
//处理v对象代码...
}
template<typename T>
void Serialize(const std::vector<T>& v)
{
Serialize_impl(v,std::is_fundamental<T>()); //通过is_fundamental选择生成 true_type还是false_type
}
int main()
{
std::cout << "注意:以下为1是基本类型,0是非基本类型" << std::endl;
std::cout << std::is_fundamental<int>::value << std::endl;
std::cout << std::is_fundamental<std::string>::value << std::endl;
//以下为应用示例,可以根据类型调用不同的函数
//创建不同类型的vector 对象;
std::vector<int> i;
std::vector<std::string> s;
//调用Serialize函数序列化,观察会执行什么函数
Serialize(i);
Serialize(s);
}结果:
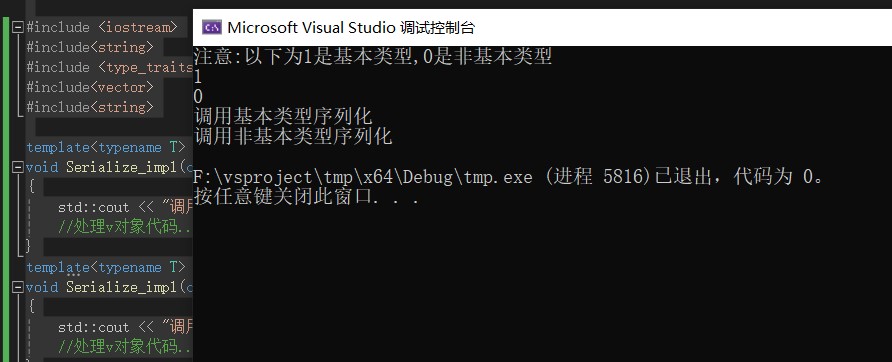
可以看到,程序会通过不同的类型选择执行不同的序列化,这个库实现的是这样的一个功能。
那么,我们用type_traits替换boost库需要的操作是。
注释掉头boost头文件,然后加入我们的替用库头文件,接着将boost改成std就行,它们的类命名,只是命名空间不一样,其它不用改。这里为了省事,我直接用宏定义替换:
cpp
//#include <boost/type_traits/is_fundamental.hpp>
#include <type_traits>
#define boost std2.3basic_string类型
在这个文件中,有basic_string这个类,这是一个模板类,可以根据类型生成ascii字符串,还是宽字符串,比如:
std::basic_string<char> str = "Hello, World!";它生成的就是string类型。等同于 string str;(宽字符就不介绍了)
而basic_string所在头文件 就是string,在这里如果不包含会识别不到basic_string。
所以我们还得包含一下:
cpp
#include<string>
using namespace std;2.4set类型
这也是一个容器,性质类似于map vector,CDataStream也支持序列化这种类型。
我们需要包含头文件,解决std::set报错:
cpp
#include <set>2.5 ios::badbit
这个就是一个值,相当于读取文件报错之类返回的值。
比如if res==ios::badbit cout<<"文件损坏""<<endl;
它的作用就是这个,这个存在于头文件ios中,我们需要包含这个头文件,解决
exceptmask = ios::badbit | ios::failbit; 这句代码报错。
这里的是用法是设置捕获哪些报错,我们现在不需要太过关注,大概了解即可。
解决ios报错:
cpp
#include <ios>2.6 vector insert
vector中的insert函数可以在容器指定位置插入一个元素,此方法有多个重载。
我们主要需要了解这个重载:
iterator insert(iterator position, InputIterator first, InputIterator last);它表示,将迭代器first到last这段范围的数据插入到position之前。
如下示例:
cpp
#include <iostream>
#include <vector>
int main() {
std::vector<char> vec = { 'A', 'B', 'C' };
char arr[] = { 'X', 'Y','Z'};
char* first = arr; // 指针指向首元素
char* last = arr + 3; // 范围不包含arr+3 指到arr+3。即arr+3之前的数据
// 使用指针作为迭代器
auto it = vec.insert(vec.begin() + 1, first, last);//vec.begin()+1 迭代器指向'B'
//输出查看效果
for (char c : vec) {
std::cout << c << " ";
}
return 0;
}结果:X,Y,Z这一段插入到指定字符B之前:
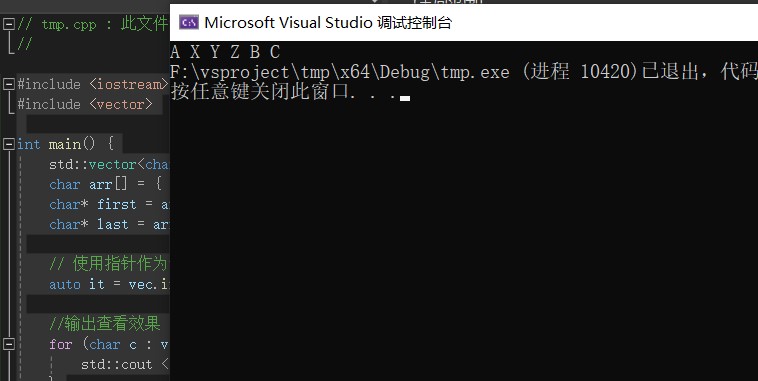
明白了上面,我们再来看这个报错:
cpp
#if !defined(_MSC_VER) || _MSC_VER >= 1300
void insert(iterator it, const char* first, const char* last)
{
insert(it, (const_iterator)first, (const_iterator)last);
}
#endif将指针类型强制转换成const_iterator不合法了,这是由于以前的编译不严格,可以这样转换。
现在已经不允许了。
这里是自己写的insert函数,有好几个重载,而这里的调用是三个迭代器参数类型,对应着下面这个函数:
cpp
void insert(iterator it, const_iterator first, const_iterator last)
{
if (it == vch.begin() + nReadPos && last - first <= nReadPos)
{
// special case for inserting at the front when there's room
nReadPos -= (last - first);
memcpy(&vch[nReadPos], &first[0], last - first);
}
else
vch.insert(it, first, last);
}最终还是调用vch的insert函数(上面的memcpy也可以用insert替换,只是效率问题)
所以我们解决这个报错,直接调用vch.insert(it,first,last)其实就可以了,不需要强制转换。
本身可以直接使用指针,如下:
cpp
#if !defined(_MSC_VER) || _MSC_VER >= 1300
void insert(iterator it, const char* first, const char* last)
{
//insert(it, (const_iterator)first, (const_iterator)last);
vch.insert(it, first, last);
}
#endif2.7 assert
这个assert是用于调试的,如果条件为假,则终止程序运行,并输出一些报错信息。
这个assert在<cassert>头文件中定义,所以我们需要包含一下解决assert未定义标识符报错:
cpp
#include<cassert>ok,现在没有报错了,此文件已经可以正常编译了。
CDataStream示例
我们现在来测试一下CDataStream的使用,先测试string类型。
cpp
#include <iostream>
#include "serialize.h"
#include<string.h>
using namespace std;
int main() {
CDataStream ss(SER_DISK,101);
string str = "hello";
ss << str;
auto p = ss.begin();
}2.8allocator内存分配
测试直接报错,主要是跟rebind相关。
因为vector之类的容器,内部肯定要分配内存,而这些容器使用的是alloactor类来分配管理内存,这样就不必每一个容器单独写一份代码。 它们是这样设计的。
通过模板来指定:
cpp
template<typename T, typename Allocator = std::allocator<T>>
class vector;这样,当你不显式指定模板的第二个参数
比如vector<int> a; 那么使用的就是allocator默认分配器。
而在CDataStream的vector中,使用了自定义分配内存器,为什么要这样呢,是为了安全性。
因为在释放内存空间后,可能会有残留的数据,所以需要手动擦除掉,而不是仅简单的标注这块内存不使用了。
所以我们需要参与内存分配这个过程,就必须自定义分配器。
相关源码如下:
cpp
template<typename T>
struct secure_allocator : public std::allocator<T>
{
// MSVC8 default copy constructor is broken
typedef std::allocator<T> base;
typedef typename base::size_type size_type;
typedef typename base::difference_type difference_type;
typedef typename base::pointer pointer;
typedef typename base::const_pointer const_pointer;
typedef typename base::reference reference;
typedef typename base::const_reference const_reference;
typedef typename base::value_type value_type;
secure_allocator() throw() {}
secure_allocator(const secure_allocator& a) throw() : base(a) {}
~secure_allocator() throw() {}
template<typename _Other> struct rebind
{ typedef secure_allocator<_Other> other; };
void deallocate(T* p, std::size_t n)
{
if (p != NULL)
memset(p, 0, sizeof(T) * n);
allocator<T>::deallocate(p, n);
}
};重写了父类allocator的deallocate方法,这个方法是在内存释放时被调用。
在里面我们调用memset擦除了内存。
因为容器内部有多种类型,所以这里需要rebind机制,这里就不详细介绍rebind相关了。
你只需要知道,之前rebind写法已经不兼容现在的编译器了。所以这里会报错。
那么这里我们为了省事,安全性现在我们不需要考虑,直接不使用自定义分配器,而是使用默认的分配器,即:
将
cpp
typedef vector<char, secure_allocator<char> > vector_type;
vector_type vch;改为:
cpp
typedef vector<char, std::allocator<char> > vector_type;
vector_type vch;即可。
2.9构造函数
改完之后,出现 "CDataStream::CDataStream": 重定义默认参数 : 参数 1
这是因为这两个构造函数
cpp
CDataStream(const vector_type& vchIn, int nTypeIn=0, int nVersionIn=VERSION) : vch(vchIn.begin(), vchIn.end())
{
Init(nTypeIn, nVersionIn);
}
CDataStream(const vector<char>& vchIn, int nTypeIn=0, int nVersionIn=VERSION) : vch(vchIn.begin(), vchIn.end())
{
Init(nTypeIn, nVersionIn);
}有冲突了,为什么呢,本来vector_type用的是自定义分配器,跟vector<char> 类型参数无冲突。
现在改成了默认的,它就等同于vector<char>这个类型了,所以相当于定义了两个相同参数的构造函数,我们注释掉其中一个即可。
ok,改完后运行不报错了(注意只是粗略的改一下,可能会有其它bug相关,这个目前不是重点。
我们需要项目先跑起来,了解默克尔树相关,其它问题将留待以后详细测试研究解决)
2.91复制构造函数
ps:这之前还有一个报错:
cpp
friend CDataStream operator+(const CDataStream& a, const CDataStream& b)
{
CDataStream ret = a; // 调用复制构造函数
ret += b;
return ret;
}类对象在进行这种赋值时 ret=a,拷贝副本,如果你没有显式定义复制构造函数,编译器会自动生成一个,会对所有的成员进行复制。
但在这里,没有正常生成报错,可能是编译版本,或更改了allocator导致vch不能正常复制有关。
具体原因不研究,我们直接显式定义拷贝,CDataStream增加如下构造函数:
cpp
//解决没有相关复制构造函数问题
CDataStream(const CDataStream& other)
: vch(other.vch),
nReadPos(other.nReadPos),
state(other.state),
exceptmask(other.exceptmask),
nType(other.nType),
nVersion(other.nVersion)
{
}复制相关成员。
3.测试使用
现在我们用如下代码测试:
cpp
#include <iostream>
#include "serialize.h"
#include<string.h>
using namespace std;
int main() {
CDataStream ss(SER_DISK, 101);
string str = "hello";
ss << str; //序列化
//输出字符串
for (auto it = ss.begin(); it != ss.end(); ++it)
{
cout << *it << " ";
}
} cout << endl;
//输出ascii码
for (auto it = ss.begin(); it != ss.end(); ++it)
{
cout << (unsigned int)(*it) << " ";
}
}运行结果:
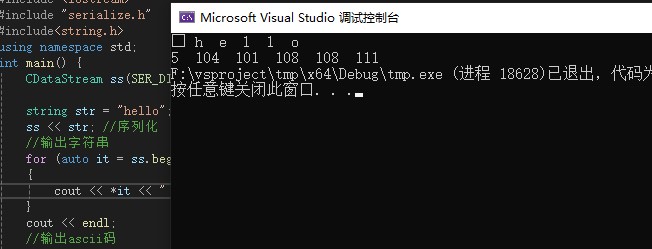
正常输出hello字符串和ascii码,说明ss序列化正常,里面的数据没问题。
但是这里前面多了一个5的这个数字,前面5这个数字,用来表示数据长度,表示有5个字符数据。
这是CDataStrem自定义添加的说明,相关函数为WriteCompactSize用来写入数据大小到vch里。
注意:这些数据都存在 vector_type vch; vch这个vector类型的变量里。 即CDataStrem类成员vch里。
看定义:
typedef vector<char, std::allocator<char> > vector_type;
vector_type vch;
这其实就是一个vector的char数组,简单来看: vector<char> vch;
改好的serialize.h下载地址:
务必使用vs2022 Community新版本之类的编译器,否则不保证兼容性。