文章目录
(一)仓库地址
一个无离散音频分词器的语音合成系统。
因为本身就有中文说明,所以废话暂时略过,请看源仓库。
🔗 VoxCPM仓库地址
(1.1)版本2.0
前不久才更新到2.0,对比1.5版本增加了几十种语言/方言的支持。
在应用上也更加灵活,可以精细的克隆源音频,也可以通过控制语句来描述音色。
💡 PS:想到1.0时期,稍微一长就嘶嘶叫,简直进步太大了。
(二)安装
(2.1)克隆仓库
还请先注意项目的要求和你本地环境情况。
- Python ≥ 3.10 (< 3.13), PyTorch ≥ 2.5.0, CUDA ≥ 12.0
没问题的话。
C:\> git clone https://github.com/OpenBMB/VoxCPM.git
(2.2)设置环境
我不想用conda所以最近都是venv,进入你克隆的仓库目录后:
C:\VoxCPM> python -m venv venv
然后激活环境:
C:\VoxCPM> .\venv\scripts\activate
(2.3)安装依赖
留意下是否进入了虚拟环境:
(venv) C:\VoxCPM> pip install voxcpm
(2.4)切换到用N卡
反正我一直用Nvidia的卡。
先卸载CPU的Torch(先看眼确认了再折腾哦):
(venv) C:\VoxCPM> pip uninstall torch torchaudio
然后安装CUDA版本的(我的卡是4060Ti16GB,请注意对应版本):
(venv) C:\VoxCPM> pip install torch>=2.11.0 torchaudio --index-url https://download.pytorch.org/whl/cu126
我自己这还差个东西:
(venv) C:\VoxCPM> pip install torchcodec
(三)运行
如果只是想用它,而不是进一步的开发,就直接运行官方的界面。
PS: 可以指定端口,比如 --port 8808。
bash
call venv\Scripts\activate.bat
python app.py
pause然后看日志:
bash
funasr version: 1.3.1.
Downloading Model from https://www.modelscope.cn to directory: C:\Users\Shion\.cache\modelscope\hub\models\iic\SenseVoiceSmall
WARNING:root:trust_remote_code: False
* Running on local URL: http://0.0.0.0:8808
* To create a public link, set `share=True` in `launch()`.没出错就打开浏览器:
官方说明都中文的,所以这里就省略介绍了,放上源音频,设置下模式,生成。
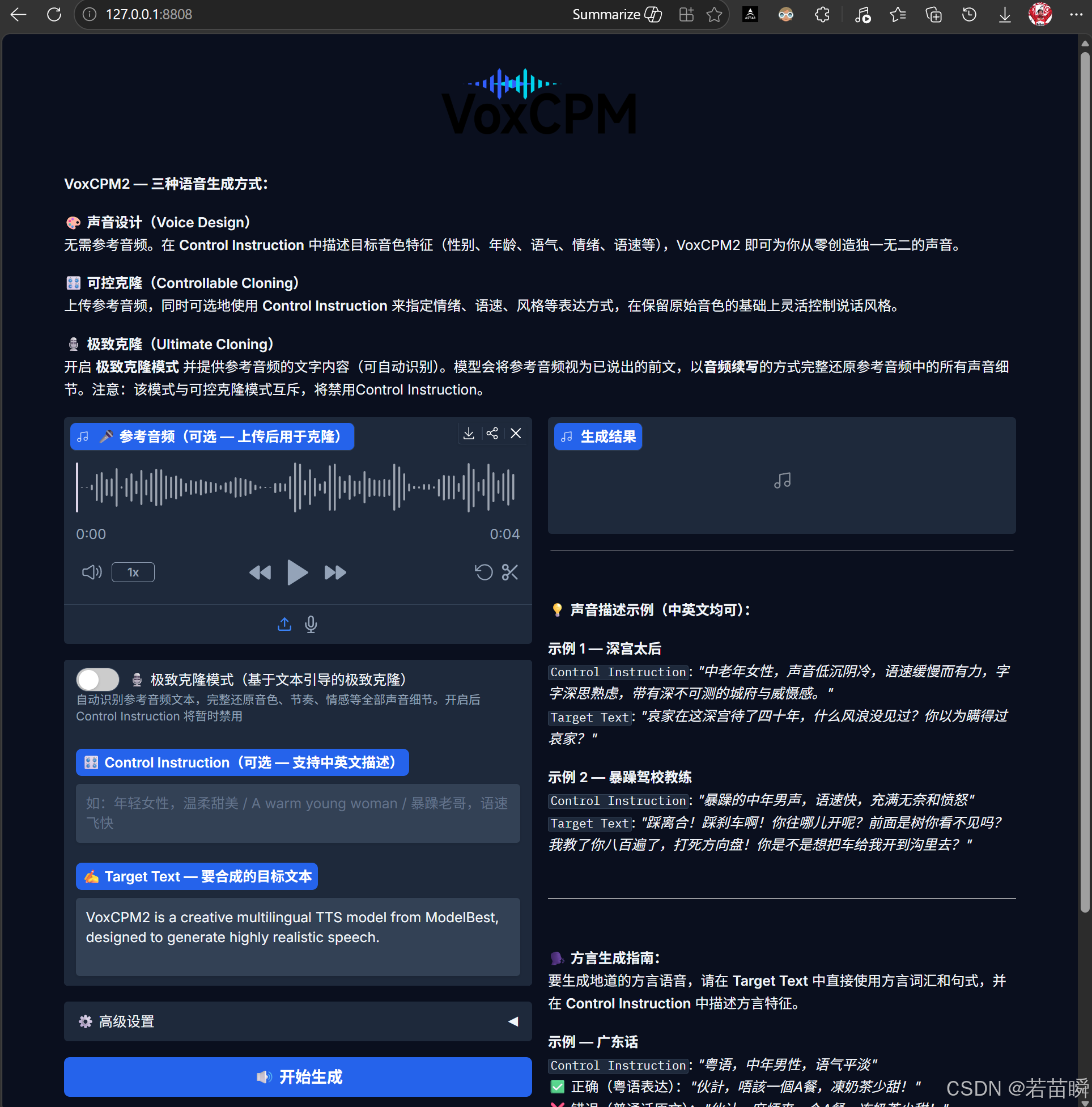
(3.1)下载模型
首次运行会自动下载2.0的模型(第二次就不会等那么久了),
不像1.x时代把模型放在项目目录,2.0的模型好像放在了用户目录中。
类型 C:\Users\用户名\.cache\huggingface\hub\models--openbmb--VoxCPM2\里面(这里系统是Win11)。
💡提示:如果你的网络下载不了模型,可能需要设置huggingface的访问:
set HF_ENDPOINT=https://hf-mirror.com
(3.2)生成结果
没出错的话,结果就出来了,可以试听,下载。
如果不满意就再次生成,毕竟还是有开盲盒成分的。
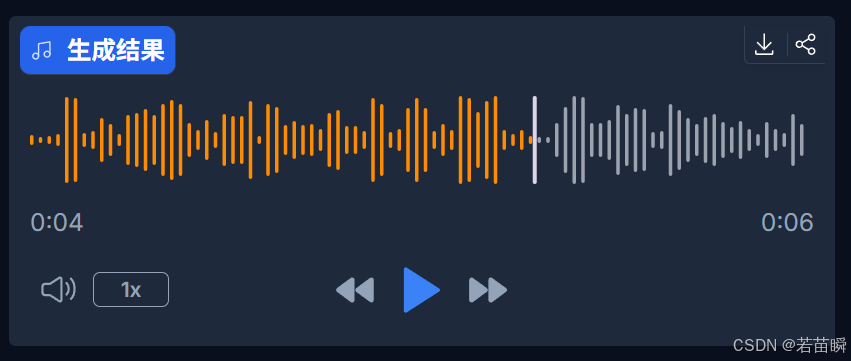
(3.3)例子
可以听听我做的这个:🔗 B站视频。
方言语速快见谅......