如果你在 Mac 上通过 oMLX 使用 Jackrong/MLX-Qwopus3.5-9B-v3-4bit,发现在自带 Chat 界面无法上传图片,即使手动设置为VLM,能上传图片了,但实际回答时像"没看到图",那大概率和我遇到的是同一个问题。
这个问题不是单点故障,而是两层原因叠加导致的:一层是模型配置里缺少 vision_config,另一层是聊天模板没有正确处理图像输入。
我的最终处理方式是:改用 mlx-community/Qwopus3.5-9B-v3-4bit 版本,再把其中的 chat_template.jinja 替换为 mlx-community/Qwen3.5-9B-4bit 的 chat_template.jinja。
问题背景
最近我在 Mac 上通过 oMLX 跑 Jackrong/MLX-Qwopus3.5-9B-v3-4bit 时,发现自带 Chat 界面中无法上传图片,这个显然不正常,因为Qwen3.5是支持多模态的。

即使在模型设置中手动设置为VLM类型,能上传图片了,但回答内容明显不像真正读取到了图像信息。
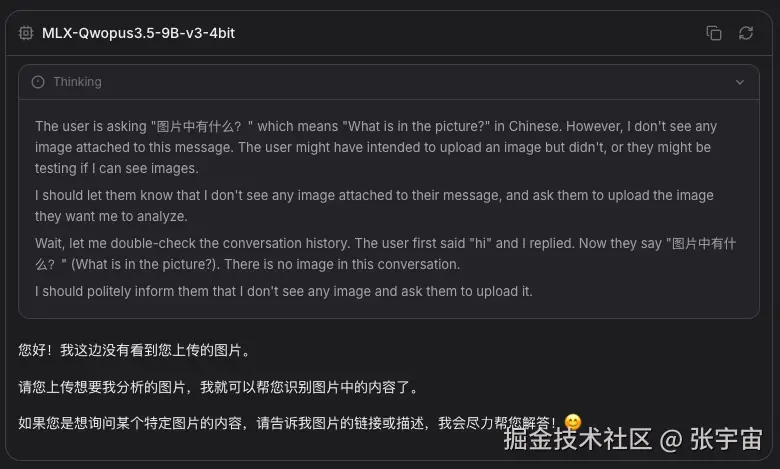 一开始我以为只是某个参数没配对,后来顺着模型文件一路排查,才发现问题其实出在两个不同层面。
一开始我以为只是某个参数没配对,后来顺着模型文件一路排查,才发现问题其实出在两个不同层面。
排查过程
第一层问题:模型没有被正确识别为多模态
先看模型配置文件后发现,config.jinja 里缺少了 vision_config 这一段。对 oMLX 来说,这意味着它无法把这个模型识别为多模态模型,后面的图像处理流程自然也就接不上。
也就是说,这时候问题还不是"模型看图效果不好",而是它在框架这一层就没有被当成一个完整的视觉语言模型来处理。
基于这一点,我后续改用了 mlx-community 转换的 MLX 版本 mlx-community/Qwopus3.5-9B-v3-4bit。
第二层问题:聊天模板没有正确渲染图像输入
换成 mlx-community 版本之后,多模态相关配置已经补齐了,但问题依然没有完全解决。
继续往下看后发现,原先沿用的聊天模板本身也有问题。更准确地说,Jackrong/MLX-Qwopus3.5-9B-v3-4bit 里的模板并没有正确处理图像输入,因此即便模型配置层面已经具备了多模态能力,真正送进模型的消息格式依然不对。
这也是为什么只修掉第一层问题还不够。模型"被识别为多模态"和"图像输入被正确拼进 prompt"是两件事,前者解决的是身份识别,后者解决的是实际喂给模型的数据格式。
解决办法
我的最终做法有两步:
- 将模型改为
mlx-community/Qwopus3.5-9B-v3-4bit。 - 将该模型目录中的
chat_template.jinja,替换为mlx-community/Qwen3.5-9B-4bit提供的原版chat_template.jinja。
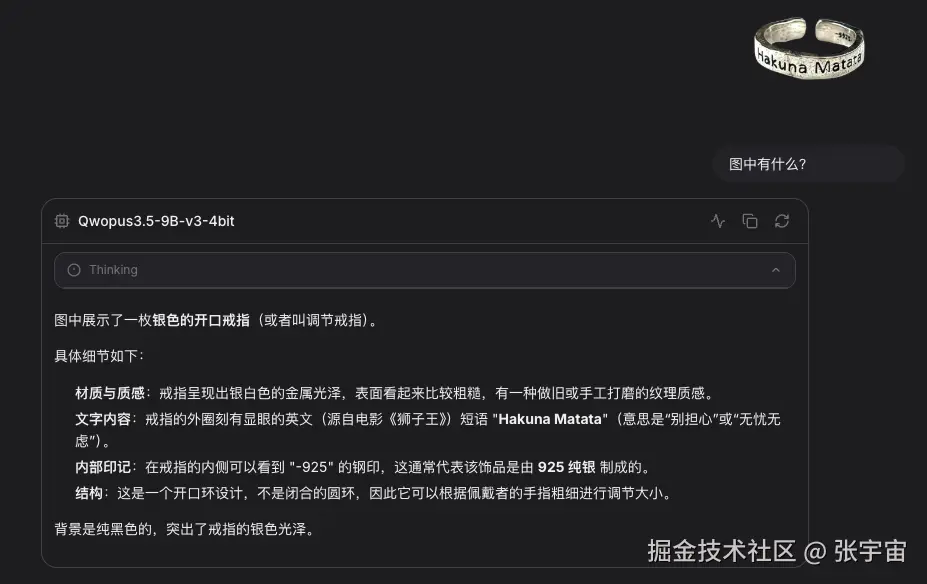
替换完成后,模型终于可以正确识别图片内容,图像输入也能正常参与推理。
补充说明
这次修改的核心:一是多模态配置,二是图像输入对应的模板逻辑。
另外,我目前只验证了这样修改后图像能力能够恢复,但不确定替换 chat_template 对模型整体表现的影响,大家自己注意。