一、前言
本文主要记录使用 anomalib中的dinomaly算法做缺陷训练之后的部署,在python端已经能够导出 onnx模型文件。需要将其部署在 VS2022 C++ 端,并能够使用显卡做推理加速。
我的显卡是 3080Ti , 这里需要用到 onnxruntime-gpu库,来加载转换好的onnx 模型文件,onnxruntime-gpu库 下载的地址为:https://github.com/microsoft/onnxruntime/releases ,需要注意下载的版本和自己的 cuda cudnn 相对应, 我的是 cuda12.4+cudnn 9.2+onnxruntime-win-x64-gpu-1.20.1
三、VS2022 配置
VS2022 需要配置好 opencv、cuda12.4、onnxruntime-win-x64-gpu-1.20.1
打开项目-》属性-》VC++目录-》包含目录:
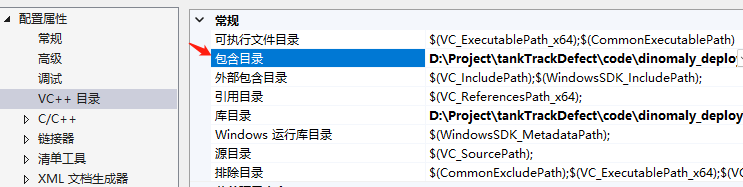
D:\Project\tankTrackDefect\code\dinomaly_deploy\onnxruntime-win-x64-gpu-1.20.1\include
D:\Program Files\opencv4.8.0\build\include
D:\Program Files\opencv4.8.0\build\include\opencv2
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.4\include
打开项目-》属性-》VC++目录-》库目录:
D:\Project\tankTrackDefect\code\dinomaly_deploy\onnxruntime-win-x64-gpu-1.20.1\lib
D:\Program Files\opencv4.8.0\build\x64\vc16\lib
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.4\lib\x64
打开项目-》属性 -》链接器-》输入:
onnxruntime.lib
onnxruntime_providers_cuda.lib
onnxruntime_providers_shared.lib
opencv_world480.lib
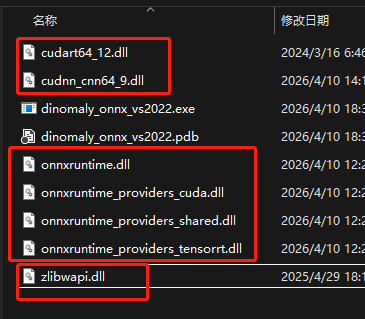
然后还需要到 C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.4\bin 找到
cudart64_12.dll 和 cudnn_cnn64_9.dll 这2个东西
到 C:\Windows\System32 找到 zlibwapi.dll
到 onnxruntime-win-x64-gpu-1.20.1\lib 找到 4个dll , 分别是:
onnxruntime.dll onnxruntime_providers_cuda.dll onnxruntime_providers_shared.dll onnxruntime_providers_tensorrt.dll
一共是 7个dll , 一起复制到 项目 exe 可执行文件所在文件夹下
四、代码
onnx模型文件和demo图片 我放到dinomaly_model 文件夹 和cpp代码文件放一块了
示例代码如下:
cpp
// LayerSegInference.h
#pragma once
#define RET_OK nullptr
#include <string>
#include <vector>
#include <cstdio>
#include <opencv2/opencv.hpp>
#include "onnxruntime_cxx_api.h"
class OrtLayerSeg
{
public:
OrtLayerSeg();
~OrtLayerSeg();
public:
// 供类外部调用的运行函数
char* RunSession(cv::Mat& iImg, std::vector<int>& layerSuface, cv::Mat& outputImg);
private:
// 配置onnx,cuda等
char* CreateSession();
// 数据blob,拉直成一维的
template<typename T>
char* BlobFromImage(cv::Mat& iImg, T& iBlob);
// 做pad填充或者归一化等
char* PreProcess(cv::Mat& iImg, std::vector<int>& ImgSize, cv::Mat& oImg);
// 模型推理,输出数据解析
template<typename N>
char* TensorProcess(cv::Mat& iImg, N& blob, std::vector<int64_t>& inputNodeDims,
std::vector<int>& layerSuface, cv::Mat& outputImg);
private:
Ort::Env env;
Ort::Session* session;
Ort::RunOptions options;
// 输入输出层名已知,直接赋值
std::vector<const char*> inputNodeNames = { "input" };
std::vector<const char*> outputNodeNames = { "pred_score", "pred_label", "anomaly_map", "pred_mask" };
const ORTCHAR_T* modelPath = L"./dinomaly_model/dinomaly_model_3.onnx"; //
std::vector<int> imgSize;
bool cudaEnable = true;
int logSeverityLevel = 3;
int intraOpNumThreads = 1;
};
cpp
// LayerSegInference.cpp
#include "LayerSegInference.h"
std::vector<cv::Vec3b> colors = {
cv::Vec3b(0, 0, 0), // Black
cv::Vec3b(255, 0, 0), // Blue
cv::Vec3b(0, 255, 0), // Green
cv::Vec3b(0, 0, 255), // Red
cv::Vec3b(255, 255, 0), // Cyan
cv::Vec3b(255, 0, 255), // Magenta
};
OrtLayerSeg::OrtLayerSeg() {
CreateSession();
}
OrtLayerSeg::~OrtLayerSeg() {
delete session;
}
template<typename T>
char* OrtLayerSeg::BlobFromImage(cv::Mat& iImg, T& iBlob) {
return RET_OK;
}
char* OrtLayerSeg::CreateSession()
{
char* Ret = RET_OK;
try
{
env = Ort::Env(ORT_LOGGING_LEVEL_WARNING, "LayerSeg");
Ort::SessionOptions sessionOption;
// 因为用CUDA,所以要配置GPU
if (cudaEnable)
{
OrtCUDAProviderOptions cudaOption;
cudaOption.device_id = 0;
sessionOption.AppendExecutionProvider_CUDA(cudaOption);
}
sessionOption.SetGraphOptimizationLevel(GraphOptimizationLevel::ORT_ENABLE_ALL);
sessionOption.SetIntraOpNumThreads(intraOpNumThreads);
sessionOption.SetLogSeverityLevel(logSeverityLevel);
session = new Ort::Session(env, modelPath, sessionOption);
options = Ort::RunOptions{ nullptr };
return RET_OK;
}
catch (const std::exception& e)
{
const char* str1 = "[ONNX LayerSeg]:";
const char* str2 = e.what();
std::string result = std::string(str1) + std::string(str2);
std::cout << result << std::endl;
char output[] = "[ONNX LayerSeg]: Create session failed.";
Ret = output;
return Ret;
}
}
char* OrtLayerSeg::RunSession(cv::Mat& iImg, std::vector<int>& layerSuface, cv::Mat& outputImg)
{
char* Ret = RET_OK;
cv::Mat processedImg;
PreProcess(iImg, imgSize, processedImg);
float* processedImgData = processedImg.ptr<float>();
int height = imgSize[1];
int width = imgSize[0];
int channels = 3;
// 创建 blob 并填充
float* blob = new float[height * width * channels];
// 分离通道(OpenCV 的 split 已经高度优化)
std::vector<cv::Mat> channel_mats(3);
cv::split(processedImg, channel_mats);
// 将每个通道的数据复制到 blob 的对应位置
for (int c = 0; c < channels; ++c) {
memcpy(blob + c * height * width,
channel_mats[c].ptr<float>(),
height * width * sizeof(float));
}
//BlobFromImage(processedImg, blob);
std::vector<int64_t> inputNodeDims = { 1, 3 , imgSize.at(1) , imgSize.at(0) }; // n c h w
TensorProcess(iImg, blob, inputNodeDims, layerSuface, outputImg);
return Ret;
}
char* OrtLayerSeg::PreProcess(cv::Mat& iImg, std::vector<int>& ImgSize, cv::Mat& oImg)
{
char* Ret = RET_OK;
ImgSize = { 308 , 630 }; // w , h
cv::Mat input;
cv::resize(iImg , input , cv::Size(ImgSize[0], ImgSize[1]));
//数据处理 标准化
std::vector<cv::Mat> channels, channel_p;
split(input, channels);
cv::Mat R, G, B;
B = channels.at(0);
G = channels.at(1);
R = channels.at(2);
// 先转换为 float 类型(范围 0-255 的 float)
R.convertTo(R, CV_32F);
G.convertTo(G, CV_32F);
B.convertTo(B, CV_32F);
//按照ImageNet的均值和方差进行标准化预处理
//B = (B / 255. - 0.406) / 0.225;
//G = (G / 255. - 0.456) / 0.224;
//R = (R / 255. - 0.485) / 0.229;
B = B / 255.;
G = G / 255.;
R = R / 255.;
channel_p.push_back(R);
channel_p.push_back(G);
channel_p.push_back(B);
cv::Mat outt;
merge(channel_p, outt);
outt.copyTo(oImg );
return Ret;
}
template<typename N>
char* OrtLayerSeg::TensorProcess(cv::Mat& iImg, N& blob, std::vector<int64_t>& inputNodeDims,
std::vector<int>& layerSuface, cv::Mat& outputImg)
{
Ort::Value inputTensor = Ort::Value::CreateTensor<typename std::remove_pointer<N>::type>(
Ort::MemoryInfo::CreateCpu(OrtDeviceAllocator, OrtMemTypeCPU), blob, imgSize.at(0) * imgSize.at(1) * 3,
inputNodeDims.data(), inputNodeDims.size());
auto output_tensors = session->Run(options, inputNodeNames.data(), &inputTensor, 1, outputNodeNames.data(),
outputNodeNames.size());
for (int i = 0; i < outputNodeNames.size(); ++i) {
auto output_info = output_tensors[ i ].GetTensorTypeAndShapeInfo();
auto output_shape = output_info.GetShape();
size_t output_elements = output_info.GetElementCount();
std::cout << "Output shape: ";
for (auto dim : output_shape) { // 输出的 shape 在这里
size_t k = dim;
std::cout << k << " ";
}
std::cout << std::endl;
std::cout << "Output elements: " << output_elements << std::endl;
}
// 分别处理每个输出
auto& pred_score_tensor = output_tensors[0]; // pred_score
auto& anomaly_map_tensor = output_tensors[2]; // anomaly_map
auto& pred_mask_tensor = output_tensors[3]; // pred_mask
float* pred_score = pred_score_tensor.GetTensorMutableData<float>();
float* anomaly_map = anomaly_map_tensor.GetTensorMutableData<float>();
bool* pred_mask = pred_mask_tensor.GetTensorMutableData<bool>();
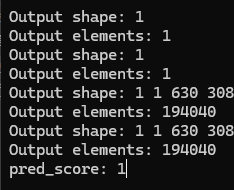
std::cout << "pred_score: " << pred_score[0];
auto type_info = pred_mask_tensor.GetTensorTypeAndShapeInfo();
auto element_type = type_info.GetElementType();
// 显示出 热力图
int amap_height = imgSize[1];
int amap_width = imgSize[0];
cv::Mat heatmap(amap_height, amap_width, CV_32FC1);
for (int i = 0; i < amap_height * amap_width; ++i) {
heatmap.at<float>(i) = anomaly_map[i];
}
cv::Mat heatmap_8u;
heatmap.convertTo(heatmap_8u, CV_8UC1, 255.0 );
cv::Mat heatmap_color;
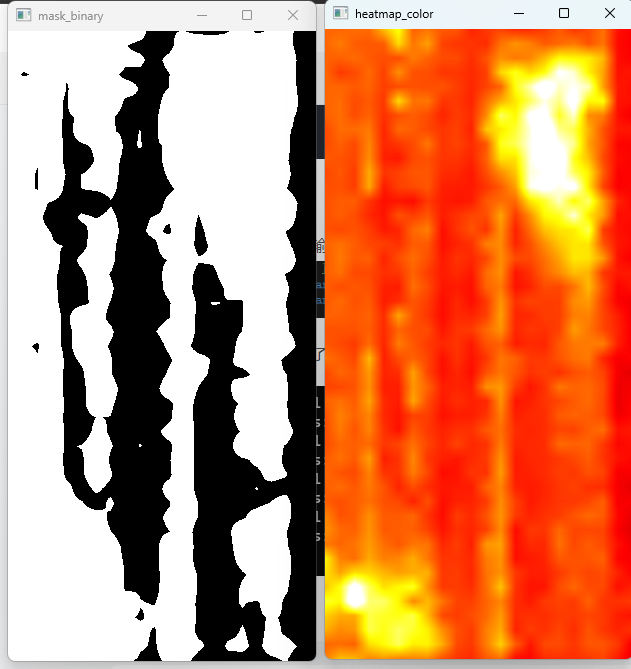
cv::applyColorMap(heatmap_8u, heatmap_color, cv::COLORMAP_HOT);
cv::imshow("heatmap_color", heatmap_color);
// 显示自定义预测二值图
// 二值化 (阈值 0.5,可以根据需要调整)
float pred_thr = 0.5;
cv::Mat mask_binary;
cv::threshold(heatmap, mask_binary, pred_thr, 1.0, cv::THRESH_BINARY);
// 转换为 0-255 范围用于显示
cv::Mat mask_8u;
mask_binary.convertTo(mask_8u, CV_8UC1, 255.0);
cv::imshow("mask_binary", mask_binary);
// 显示系统的预测二值图
/*
cv::Mat mask(amap_height, amap_width, CV_32FC1);
for (int i = 0; i < amap_height * amap_width; ++i) {
mask.at<float>(i) = pred_mask[i] ? 255 : 0;
}
cv::imshow("mask", mask); */
cv::waitKey(0);
cv::destroyAllWindows();
delete blob;
return RET_OK;
}
cpp
// main.cpp
#pragma once
#include "LayerSegInference.h"
int main()
{
std::string image_path = "./dinomaly_model/demo.jpg";
cv::Mat image = cv::imread(image_path );
cv::Mat outputImg;
OrtLayerSeg* LayerSeg = new OrtLayerSeg;
std::vector<int> layerSuface;
char* ret = LayerSeg->RunSession(image, layerSuface, outputImg);
return 0;
}五、运行效果
dinomaly 输入输出名

运行代码 输出了 整体异常分数值、热力图、预测的二值掩码图