一、什么是 AI
维基百科定义:人工智能(英语:artificial intelligence,缩写为 AI),是指计算机系统执行通常与人类智能相关的任务的能力,例如学习、推理、解决问题、感知和决策。它是计算机科学的一个研究领域,致力于开发和研究使机器能够感知其环境并利用学习和智能采取行动以最大限度地提高其实现既定目标的可能性的方法和软件。
简单来说,artificial,人造的,intelligence 智能。是一种模仿人类和人类思维的机器或计算机。人能做什么,它就能做什么。但它是机器,不是人。人工智能这个概念是 1955 年达特茅斯会议提出的,当时的一些计算机科学家认为"原则上可以制造机器来模拟人类智能"。
但在科幻小说中,更早提出了类似人工智能的概念,甚至一些小说中提出人类本身也是上帝创造的智能体。其实这个说法也挺有意思。人们或许觉得机器是可以预测的,而人具有独特的创造性。但或许人的行为也是可以预测的。有句话说:世界上所有的事情都是必然,没有偶然,如果你觉得有的事情发生是偶然,那只是你对命运这台庞大运转的机器的无知罢了。
缸中大脑理论
美国有位哲学家希拉里·普特南提出过一个缸中大脑的理论,就是说把一个大脑放到营养液里面,给它各种神经电信号,让它体验到真实的世界。它能否意识到自己生活在虚拟现实中?
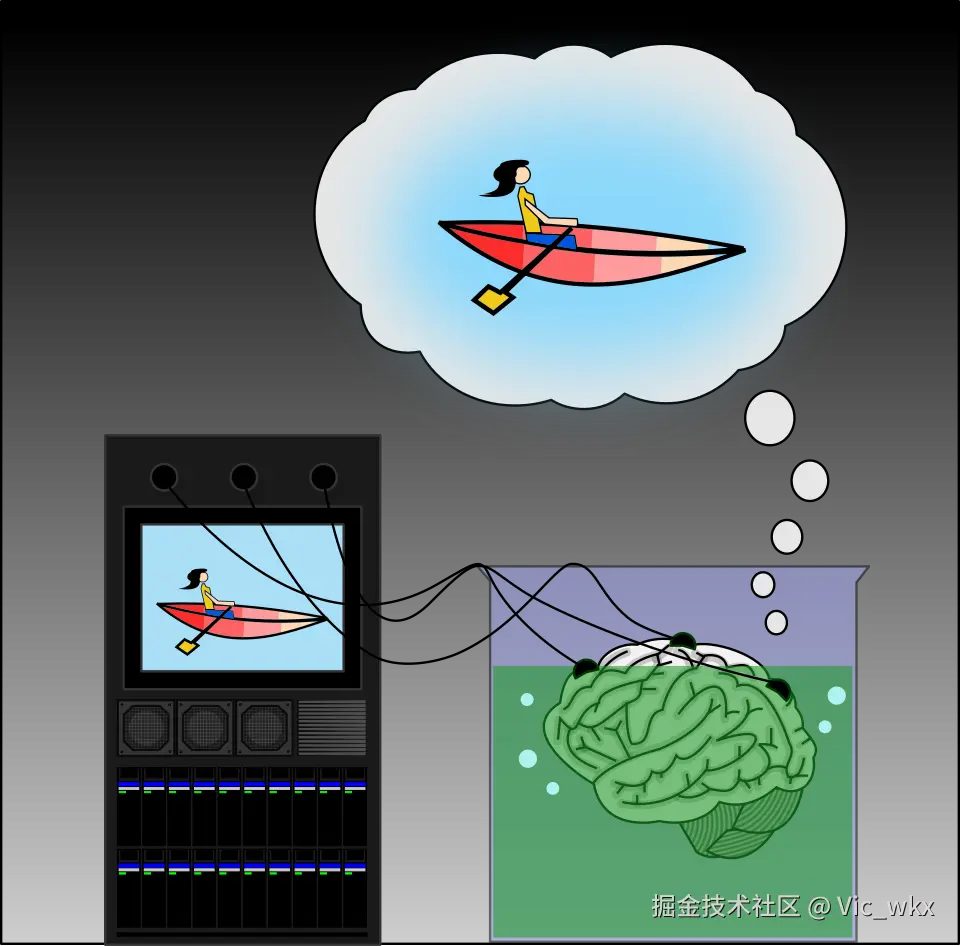
那么再进一步想,我们如何能够确定自己不是生活在缸中的大脑?这是无法确定的。
这个理论也激发了很多电影的诞生,最著名的就是《黑客帝国》,还有《源代码》。也有点像庄周梦蝶的故事。

总之,AI 发展的终极愿景就是让机器像人一样思考,行动,在某些方面超越人类。
标志性的事件有 1996 年,IBM 的超级电脑深蓝挑战国际象棋冠军卡斯帕罗夫,但是以 2-4 落败,第二年,也就是 1997 年,深蓝进化之后再次挑战卡斯帕罗夫,以 3.5:2.5击败卡斯帕罗夫。
2016 年,AlphaGo 击败围棋九段职业选手李世石,2017 年,击败围棋世界冠军柯洁。
2022 年底,OpenAI 发布 ChatGPT,在我认为这是 AI 应用爆发的起点。ChatGPT 让 AI 从计算机科学家的研究进入大众视野,如同旧时王谢堂前燕,飞入了寻常百姓家。变成了人人触手可及的工具。
到现在,AI 已经渗透到各个领域里了。
二、什么是 LLM
LLM (Large Language model),大语言模型,简称大模型,是一种基于人工神经网络的语言模型。
提供输入和输出的数据集,预测其中的规律。
我们项目组的 Damon 之前在我们项目组内分享过一次 AI 的原理,我觉得讲得非常好,所以这里直接用他当时写的例子。
当提供了输入输出之后,我们就能预测输入和输出之间的关系了。
当提供了更多的输入和输出之后,我们就能更准确地预测出输入和输出之间的关系。
输入和输出称为数据集,建立这个预测关系的过程就是训练,训练好的预测函数就是模型。
使用这个模型,就能根据输入预测输出了。
简单来说,大模型就像一个读了大量例子的自动补全引擎。
什么是 GPT
GPT(Generative Pre-trained Transformer),基于 Transformer 的生成式预训练模型。
Generative 生成式的,表示这个模型是用来生成内容的,根据输入预测输出。
Pre-trained 预训练的,表示这个模型是使用了大量的数据集训练好的。
训练好的模型为什么可以联网搜索呢?
有个技术叫做 Retrieval-Augmented Generation,检索增强生成,让模型调用搜索 API 获取结果,模型把搜索结果作为输入,再进行输出。
Transformer 的原理我看了一些,但是还是没有怎么理解。只是听说以前的算法理解东西是线性的,逐字逐句读取。不仅不能并行,而且长上下文中,会遗忘前文。
Transformer 模型通过 Attention 机制,可以并行理解全局内容。理解过程类似于开会。每个人发言,也就是每条数据先列出来,然后每个人决定要和哪些人讨论,也就是根据 Attention 机制确定每条数据之间的关联性,然后多个讨论组分组讨论,这里可以并行,通过提高算力可以调高效率。最后总结会议结果,整理输出。
我对这个算法的理解只到这个程度,所以就不展开讲了。总之,目前主流的大模型都是基于 Transformer 架构。GPT,Claude,Gemini
注意到我们这里把 GPT 和 Claude,Gemini 并列了,前面说到,GPT 的意思是基于 Transformer 的生成式预训练模型。Claude,Gemini 也是基于 Transformer 的,也是预训练的,也是生成式模型,它们应该也叫 GPT 才对。不过 OpenAI 把自己的产品就叫做 GPT,所以后面的大模型都不叫这个名字了,以示区分。
这是一个大模型的结构图:
AI 模型(Artificial Intelligence Models) ├── 语言模型(LLM, Large Language Model) │ ├── GPT(OpenAI) │ ├── Claude(Anthropic) │ └── Gemini(Google) │ ├── 视觉模型(CV, Computer Vision) │ ├── YOLO(目标检测) │ ├── Vision Transformer(图像分类) │ └── Segment Anything(图像分割) │ ├── 语音模型(Speech) │ ├── Whisper(语音识别 ASR) │ ├── Tacotron(语音合成 TTS) │ └── WaveNet(语音生成) │ └── 多模态模型(Multimodal) ├── GPT-4V(OpenAI) ├── Gemini(Google) └── Claude(Anthropic, 部分多模态能力)
除了语言模型,还有视觉模型、语音模型,还有一个叫多模态模型。
模态是什么意思呢,就是输入输出的类型。
| 信息 | 模态 |
|---|---|
| 一段文字 | 文本模态 |
| 一张图片 | 视觉模态 |
| 一段语音 | 语音模态 |
| 一个视频 | 视频模态 |
现在的主流模型都是多模态的,可以支持多种输入输出。
三、AI 中的概念
参数
大模型就像一个读了大量例子的自动补全引擎。又是一个预测函数。作为一个函数,参数越多,能表示的内容就越复杂。
比如 f(x) = x 这样的函数,只有一个参数 1。只能做一件事:输入什么,就输出什么。
f(x) = kx + b 这样的函数,有两个参数 k 和 b,就能表示所有的直线了。
大模型的参数是上亿级的,我们用模型的时候可以看到 7B 的模型,B 代表 billion,十亿,7B 参数就表示 70 亿参数。7B 的模型属于小模型,最新的大模型参数是万亿级的。
算力
还有一个基本概念是算力,算力就是计算机的运算能力。算力越强,模型学得越快、学得越多、效果越好。前面提到过,transformer 算法采用了 attention 机制,可以并行计算,所以才能通过提高算力,提高模型训练速度
token
大模型中的另一个概念是 token,token 可以翻译成词元。通常都直接说 token,token 表示的是大模型输入和输出的基本单位。
我们平时说的话,一个字可以作为一个基本单位。但大模型分析一句话,并不是拆成一个一个的字来分析,而是拆成一个一个的 token。
比如今天天气怎么样?
这句话可以拆成:今天、天气、怎么样、?,这样四个 token
谢谢你。
这句话可以作为一个 token。
为什么要这样做呢,主要是为了提高效率。因为很多常用的词语和短句可以合并在一起理解。
token 的消耗和模型的价格挂钩,简单的类比可以理解成汉字字数、英语的词数约等于 token 的消耗量,但通常会低一些。
上下文
上下文是指模型的理解范围。模型能记住的之前的内容,就叫上下文。
举个简单的例子,我们问大模型,1+1 等于几,模型回答 2
我们又问:再加上 3 呢?模型回答等于 5,这就是因为模型记住了上文中的内容。
GLM 最新发布的模型 GLM 5.1 参数是 754B,上下文是 1M token,部分推理支持 2M token。
四、使用 AI 的概念
Agent:智能体,从被动执行的工具,进化为能主动规划任务的智能助手。
工具调用:赋予AI调用外部API的能力,构建连接虚拟模型与现实世界的桥梁。
部署方式:本地部署或者云端 API 服务
模型选择:不同模型决定能力大小。
体验 OpenClaw
一行命令就完成安装了,但是为了保证安全,我把我一台不用的 Macbook 先格式化了,建了个新的账号才安装的 OpenClaw。
arduino
curl -fsSL https://openclaw.ai/install.sh | bash安装完成后,会自动进入设置页面。首先就有一个 Security 条款。这里写的什么内容呢?我看到这种内容就会想起之前在电视剧里看到的一个情节。讲了一群盗墓贼进到一个墓里,墓穴周围写了很多不认识的文字。有一个盗墓贼就问:这里写的啥? 主角就站出来说:我知道。 那个盗墓贼就问:你还认识这种古文字? 主角说:我不用认识古文字就知道,这里写的是:盗墓者死。
这里的条款也是一样,不用读就知道,是个免责声明,出了问题我不负责。
同意就行了。
最后安装模型,就是给电脑安装一个大脑。
配置 skill,给它一些能力。让它可以调用。
最后生成了一张艺术成分很高的照片。
但是 AI 有点像个渣男,吹得头头是道,实际上也就那样。
OpenClaw 就是一个助手。我们平时有什么事情需要请一个助手吗?开公司的人可能需要,本身就要招人,可以招一个 AI 干活儿。
但是我想了想,我自己其实不需要助手。
我媳妇给我的微信备注是小助理,她把我当成助手。有时候帮她做图片,剪视频,做 PPT 等等,我就是一个 Claw。
而有时候剪的视频有几个 G,我不确定现在的 AI 能否处理这种大小的视频,所以我都还是自己手动剪辑。
五、AI 发展曲线
2020 GPT-3 发布,是个里程碑时间,但是就我个人而言,没有明显感知。
2022 年 ChatGPT 发布,引爆全球 AI 热潮。到如今是全球访问量排名第五的网站,绝对是现象级产品了。
主流模型,御三家。
AI 应用。ChatGPT,豆包这些。
即梦 AI,生成图片的
老罗的细红线科技出的且听,把一本书提炼出 AI 讲解。现在改名一卒听库了。
Agent 应用,比如 OpenClaw。
各家都退出自己的 Claw,阿里,腾讯,飞书都推出了一键部署的 claw。就是为了绑定自家大模型,卖自家的算力和云服务器。锁定用户,有了数据,才能更好的进化。
六、如何评价 AI 模型
可以看到排名
还可以看到性价比排名。
huggingFace 网站是 AI 界的 github。开源的 AI 模型都在上面,它出了一个开源模型排行榜。
图灵测试。
七、AI 的应用
问答、检索,生成
代码生成,逻辑解释
文生图。
视频、音乐生成。