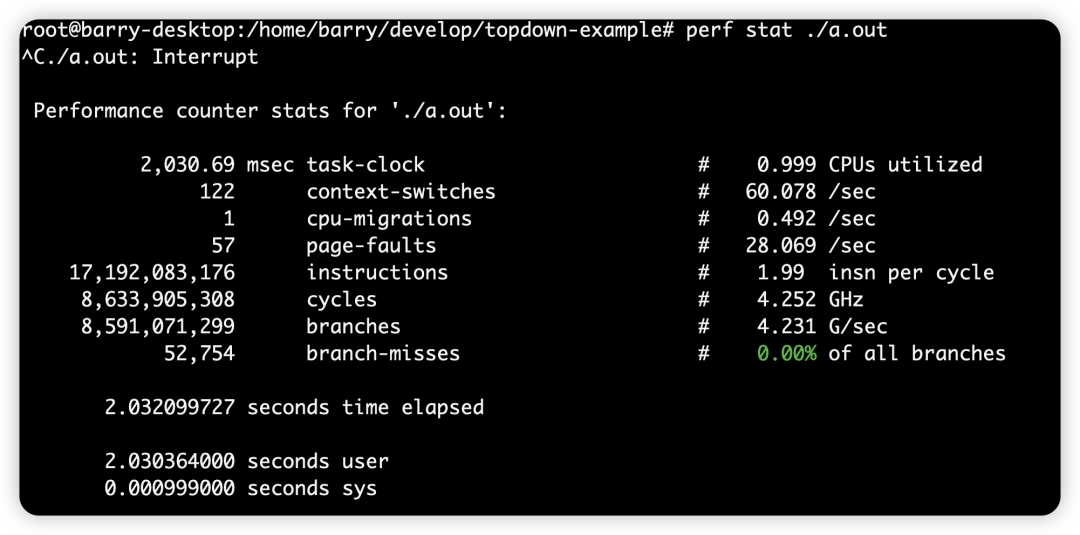
对于简单的while(1)循环:
cs
int main(){ while(1); return 0;}L1:

L2:

L3/L4:
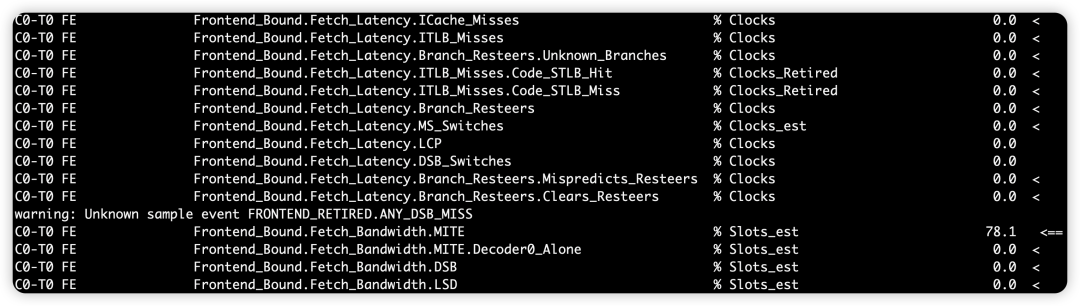
为什么 Core Bound 是 0%?
这是最关键的逻辑:没有"停顿(Stall)",就没有"受限(Bound)"。
-
没有依赖等待:
jmp指令不依赖任何复杂的计算结果,它不需要等待前面的指令算完。 -
没有资源溢出: 只有一个指令在跑,后端的预留站(Reservation Station)和重命名寄存器永远不会被占满。
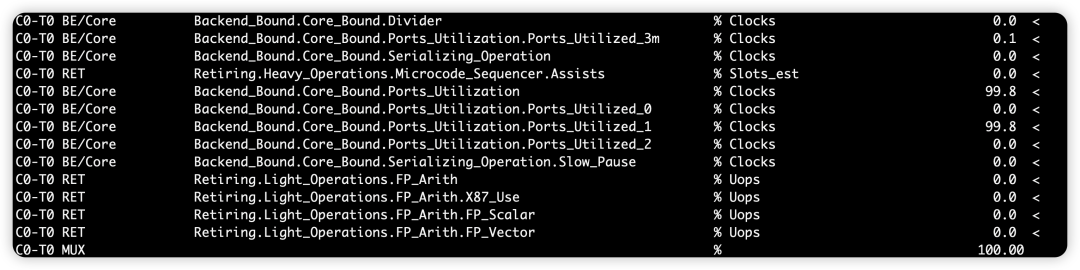
核心解读:Ports_Utilized_1 = 99.8%
-
含义 :在 99.8% 的时钟周期里,后端有且只有一个端口在执行指令。
-
真相 :由于你的代码只有一条
jmp指令,它始终被分配到执行跳转的特定端口。 -
Ports_Utilized_3m(同时使用 3 个以上端口)是0% -
- while(1); 是"绝对串行":每周期只敲一个端口,剩下端口全闲着。
为什么 Ports_Utilization 又是 99.8%?
在 TMAM 模型中,Core_Bound.Ports_Utilization 的父级指标衡量的是:"执行压力是否集中"。
-
因为你的
Ports_Utilized_1达到了近乎 100%,CPU 认为后端正面临极度的单一端口压力。 -
尽管只有 1 个端口在忙,但它"忙得很有规律"。由于这个端口始终处于被占用状态,在
while(1);这种极简循环里,它被定义为 Core Bound 的子项,表示"虽然我没卡住(0% Backend Bound),但我已经被这条单指令压榨到了单端口执行的极限"。
如何理解 Frontend Bound 50% 和 Retiring 50%?
你可能会奇怪,既然是 while(1);,为什么 Retiring 不是 100%?
-
机器宽度 vs 指令密度: 现代 CPU 每个时钟周期可以处理 4 到 8 条指令(Slots)。但你的
while(1);循环体太小了,可能每一组时钟周期只能提供 1 或 2 条指令。 -
空置的槽位: 剩下的槽位因为没有指令可填,被标记为 Frontend Bound(前端没能填满所有槽位)。
-
结果: 这一半的 Slot 退休了(50% Retiring),另一半空着(50% Frontend Bound)。
总结
对于 while(1); 来说:
- Backend Bound = 0%:是因为后端处理得太快、太顺畅了,完全没排队。
IPC是1.99。while(1);对应汇编是2条指令 nop + jmp:
apache
0000000000001129 <main>: 1129: f3 0f 1e fa endbr64 112d: 55 push %rbp 112e: 48 89 e5 mov %rsp,%rbp 1131: 90 nop 1132: eb fd jmp 1131 <main+0x8>为什么 IPC 是1.99( 2)?
虽然汇编是 nop 和 jmp,但在 Retiring 阶段,它们是两条独立的指令。
-
物理执行 :
nop指令在现代 CPU 中通常在前端就被处理掉(Nop-elimination),或者被分配到一个极其简单的微操作。jmp也是一个微操作。 -
统计结果 :在一个时钟周期内,CPU 退休(Retire)了一个
nop和一个jmp。因此:
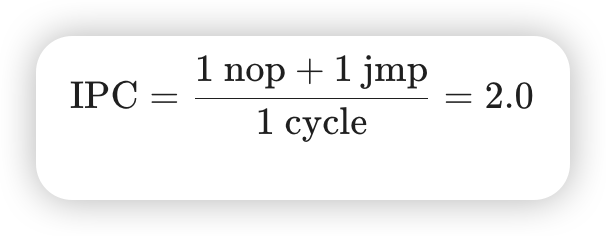
2. 为什么只有一个 Port 在执行?
这是最关键的一点。在 Skylake 微架构中:
-
nop不占用执行端口 :现代 CPU 拥有"消除 NOP"的能力。当nop到达重命名(Rename)或分配(Allocate)阶段时,CPU 直接标记它已完成,而不需要把它发往任何执行端口。 -
jmp占用1个port :只有jmp真正需要进入执行后端并敲击端口。 -
结论 :在 99.8% 的时钟周期里,只有一个物理微操作(
jmp)需要执行,所以Ports_Utilized_1是 100%。
如果现在代码做4 个独立的加法操作,完全发挥后端多个ALU 端口的实力,并尽可能消除了内存访问和分支干扰:
php
int main() { // 使用寄存器变量,建议编译器不要写回内存 register long a = 0, b = 0, c = 0, d = 0;
while (1) { // 使用内联汇编确保生成最纯粹的指令流 // 1. 展开循环:减少 jmp 指令占用的槽位比例 // 2. 独立寄存器:确保 4 条指令可以同时分配给 4 个不同的执行端口 __asm__ __volatile__ ( "add $1, %[a]; add $1, %[b]; add $1, %[c]; add $1, %[d];" "add $1, %[a]; add $1, %[b]; add $1, %[c]; add $1, %[d];" "add $1, %[a]; add $1, %[b]; add $1, %[c]; add $1, %[d];" "add $1, %[a]; add $1, %[b]; add $1, %[c]; add $1, %[d];" "add $1, %[a]; add $1, %[b]; add $1, %[c]; add $1, %[d];" "add $1, %[a]; add $1, %[b]; add $1, %[c]; add $1, %[d];" "add $1, %[a]; add $1, %[b]; add $1, %[c]; add $1, %[d];" "add $1, %[a]; add $1, %[b]; add $1, %[c]; add $1, %[d];" : [a] "+r" (a), [b] "+r" (b), [c] "+r" (c), [d] "+r" (d) : : "cc" ); } return 0;}结果变成:
L1:

frontend bound消除,backend bound到15.7%,84.2%的时间在retiring指令。
L2:

backend bound主要是core bound不是memory bound,因为我们用的register变量。
L3/L4:
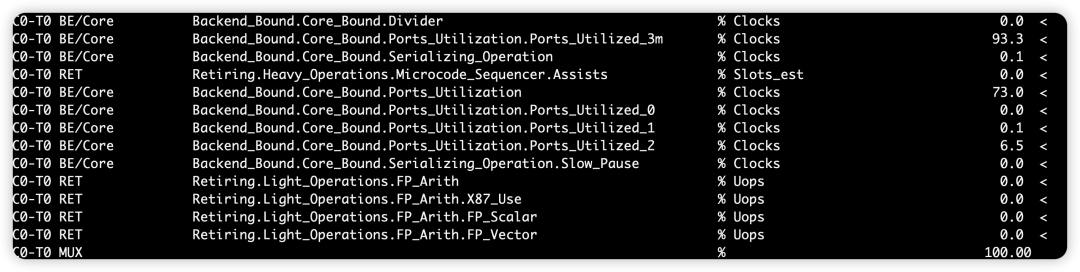
核心指标:Ports_Utilized_3m (93.3%)
这表示在 93.3% 的时钟周期里,后端执行单元(Execution Units)正同时有 3 个或更多的端口 在发射(Dispatch)uOps。
-
你的代码:
add a; add b; add c; add d; jmp; -
硬件行为: Skylake 有 4 个 ALU 端口(0, 1, 5, 6)。因为你的加法在不同寄存器上,没有数据依赖 ,所以 CPU 可以真正地在同一个周期把这 4 个
add发射到这 4 个不同的端口去。 -
结论: 这个 93.3% 证明了你极大地利用了指令级并行(ILP)。你的后端基本没有闲着的时候。
对比 : Ports_Utilized_3m(同时使用 3 个以上端口)是 93.3%,之前while(1);则是0%。
-
while(1); 是"绝对串行":每周期只敲一个端口,剩下端口全闲着。
-
展开后的代码:是"高度并行":每周期大家一起干活。
IPC:
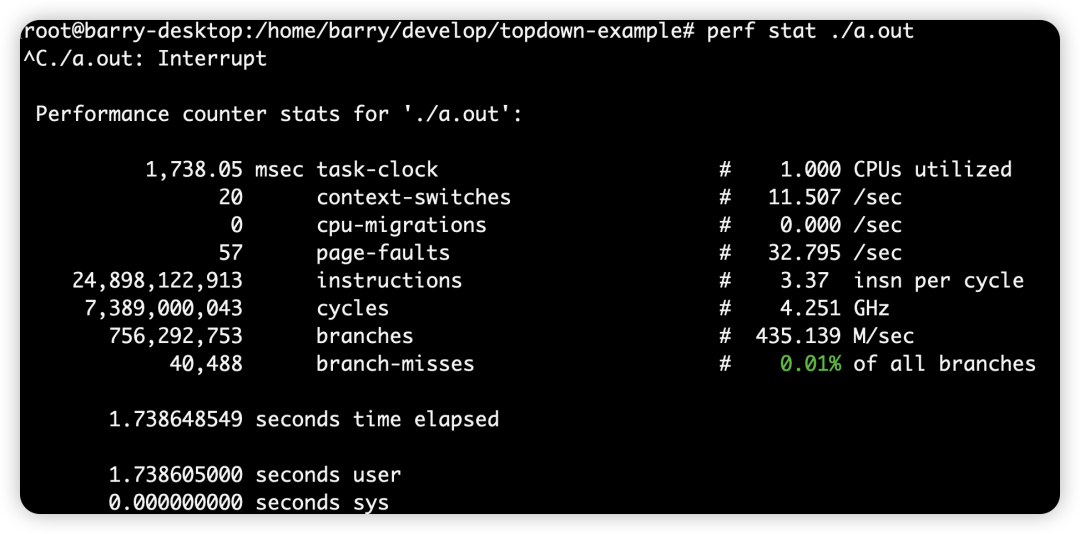
insn per cycle是3.37。