前言
近期(26年4月中旬)出差长三角地区,两天四城
- 昨天衢州(轮式代工厂)、杭州(场景训练中心)
- 今天南通(变压器工厂)、上海(人形本体厂商)
高铁上还完成了对一篇paper的解读。其实,博客中的很多paper,我们都会搞下,把机器人和最前沿具身技术落地到各个工厂中,对我们而言,最感兴奋
毕竟我们属于:具身垂直场景的训练及落地交付,而本体厂商侧重硬件制造、高校侧重理论创新、我司七月则侧重落地交付,各自其职 缺一不可
额外说下
- 目前平均每月去5个工厂,近两年每年基本50个工厂,两年100个工厂
可以让我们对工厂典型场景的理解能力最深,从而提前沉淀在工业场景的技术积累- 而之所以有机会能跑这么多工厂,原因在于
1 我们是++20余家头部本体厂商的场景交付伙伴++ ,他们会给我司源源不断介绍工厂客户(委托七月帮他们的工厂客户去做落地交付)
2 我2500万 PV的具身博客和200多万播放量的具身视频号,在中国发挥着越来越大的影响力和知名度
3 一帮朋友的高密度给我们推荐客户,而我们给出去的方案,终端客户无一例外全部高度认可
第一部分
1.1 引言与相关工作
1.1.1 引言
如原论文所说,觉-语言-动作(Vision-Language-Action, VLA)模型(Intelligence 等,2025;Kim 等,2024;Li 等,2025;Team 等,2026;Zitkovich 等,2023)通过利用大规模预训练,在实现跨多种任务的通用操作方面取得了重大进展
然而,要在真实世界环境中取得成功,远不止需要静态场景理解:机器人交互在部分可观测性和延迟反馈的条件下展开,其中决策的后果仅在较长的时间跨度后才会显现(Huang 等人,2022 年;Zitkovich 等人,2023 年)
因此,学习如何将当前行为与未来结果关联起来,仍然是真实世界机器人领域的一项根本性挑战
这一挑战要求具备一种能力,能够评估正在进行的交互是否正朝着成功完成任务的方向发展。这样的进展感知使机器人能够区分有益行为和不良行为,并通过经验不断改进
-
在强化学习(RL)(Sutton et al., 1998)中,这一能力由价值函数形式化表示,它估计预期的未来结果,并为策略改进提供学习信号。近期的VLA框架如π∗0,6(Intelligence et al.,2025)凸显了这一重要性:其"通过优势条件策略进行经验与纠正的强化学习------RECAP "流程依赖于用于优势估计和策略优化的多任务价值函数,表明学习性能在很大程度上依赖于价值模型的质量
详见此文《π∗0.6------通过RL框架RECAP微调流式VLA π0.6:先基于示教数据做离线RL预训练,再SFT,最后在线RL后训练(与环境自主交互,从经验数据中学习,且必要时人工干预)》
-
基于这一重要性,近期工作开始探索利用视觉--语言模型(VLMs
Bai et al., 2025
Chenet al., 2024
Comanici et al., 2025
Li et al., 2024
Marafioti et al., 2025
Zhu et al., 2025
进行价值估计,将价值预测表述为分类问题
Intelligence et al., 2025或
时间顺序排序问题
Ma et al., 2024尽管这些方法展现出良好前景,但它们也继承了一个关键局限:VLM 主要在静态图像--文本数据上进行训练,侧重语义理解,而并非显式建模场景如何随时间演化
因此,它们能够捕捉场景中"当前有什么",却难以表征交互是如何动态地改变环境的
这种不匹配限制了其在具有时间延展性的机器人任务中,支持可靠价值估计的能力
上述局限性揭示了一个关键洞见:价值估计本质上是一个预判未来如何演化的问题。与在静态数据上训练的判别式模型不同,视频生成模型被显式优化用于捕捉时间演化过程,学习场景在交互展开时如何变化。这使得视频生成模型自然而然成为价值估计的基础,因为想象未来结果的能力可以直接用于评估当前行为是否在朝着任务完成的方向推进
在这一观察的指导下,来自GigaAI、四川大学和清华大学的研究者将价值学习重新表述为未来预测,并提出了一种视频生成式价值模型(Video-generative Value model,ViVa)
- 其paper地址为
- 其项目地址为
简言之,给定当前的多视角观测以及机器人本体感知,ViVa 共同预测未来的本体感知状态,并输出一个标量值来表示任务向成功完成推进的进度 。通过将价值估计建立在对未来具身动力学的预期之上,ViVa 利用预训练视频生成模型的时空先验,将预测性的结构融入到超越静态快照的表示中
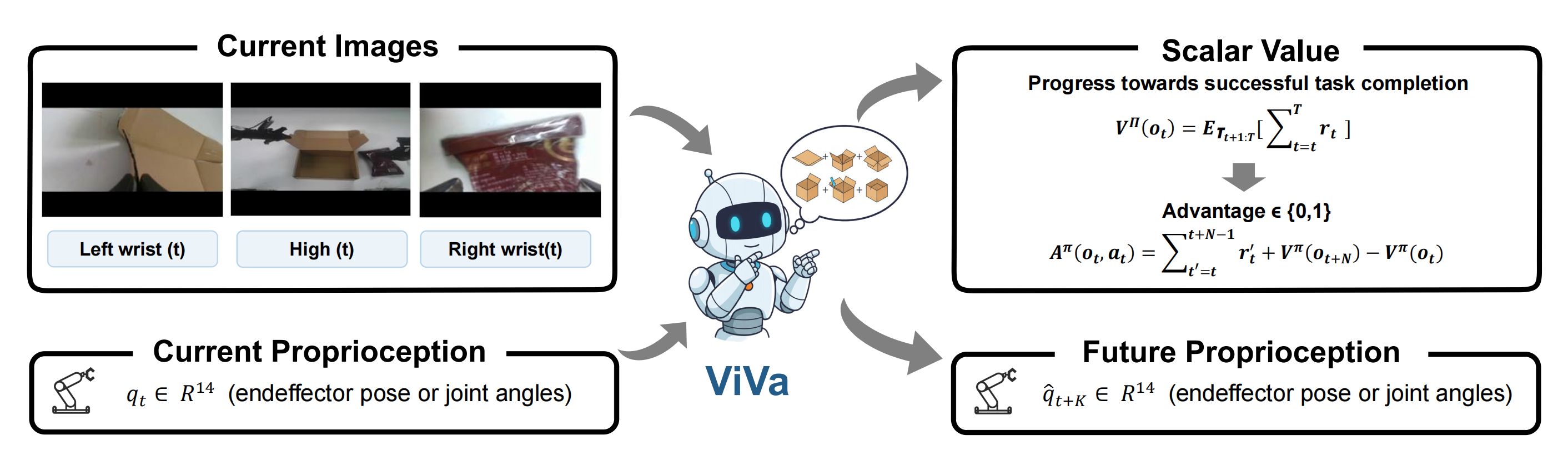
具体而言
-
这是一种++将预训练视频生成器重新用作机器人强化学习中价值函数的新方法++
通过利用从大规模视频语料库中学习到的时空先验,该模型能够捕捉关于场景随时间演化的丰富动力学特征
以当前观测和机器人本体感觉(proprioception)作为输入,ViVa 联合预测未来的本体感觉以及当前状态的标量价值将价值估计建立在对未来具身动力学的预期之上,使ViVa 能够融入超越静态快照的预测结构,从而在内在上将价值与前瞻性紧密耦合。这样的设计为优势函数计算提供了更可靠的价值信号,进而提升了机器人操作任务中的策略优化效果
-
作者将基于视频的价值模型 集成到 RECAP 流水线中,用其替换原先基于 VLM 的价值函数
作者宣称,在具有挑战性的真实世界任务------装箱任务中,该方法相比以往方法展现出明显优势
作者宣称,他们对全部三个任务的定性分析进一步表明,ViVa 能够产生更加可靠的价值信号,准确跟踪任务进度并检测执行错误
且通过利用从视频语料中学习到的时空先验,ViVa 还可以推广到以往方法难以处理的新颖物体上,这表明基于视频生成的价值模型为实现可扩展的真实世界机器人学习提供了一条可行路径
1.1.2 相关工作
首先,对于机器人学习中的价值函数,侧重对当前任务完成进度的评估
价值函数在机器人操作的强化学习中发挥着基础性作用,它通过提供学习信号,在反馈延迟且稀疏的情形下引导策略改进(Ross et al., 2011; Sutton et al., 1998)
- 早期工作探索了从演示与离线数据集中学习价值函数或Q函数的方法,包括用于操作任务的校准Q-learning和离线强化学习方法(Huang et al., 2025; Kalashnikov et al., 2018; Lampe et al., 2024; Levineet al., 2020; Luo et al., 2024; Mandlekar et al., 2020; Mendonca et al., 2023; Sharma et al.,2023)
- 后续研究将价值估计纳入端到端的机器人学习流程中,采用如PPO和REINFORCE等策略梯度方法,以及诸如任务完成时间预测等任务特定建模形式,表明精确的价值建模对于实现长时程的机器人行为至关重要(Ghasemipour et al., 2025; Zhai et al., 2025)
VLA 模型的成功(Cheang et al., 2024; Kim et al., 2024; Li et al., 2024; Liu et al., 2024; O�Neill et al.,2024; Team et al., 2024)激发了人们将VLM 从策略学习扩展到价值估计的兴趣(Frans et al., 2025; Ma etal., 2023, 2024)
- GVL(Ma et al., 2024)展示了VLM 可以通过将价值预测表述为对打乱顺序的视频帧进行时间排序的问题,从视觉轨迹中提供可迁移的逐帧价值估计,从而在多样的操作任务中实现对进度敏感的学习
- 基于这一方向,最新的框架π∗0.6(Intelligence et al., 2025) 将基于VLM 的价值函数引入强化学习流水线,利用它们来估计状态-动作优势,用于基于优势的策略细化
这样的整合在诸如叠衣服和制作浓缩咖啡等具有挑战性的长时间任务中带来了显著收益,表明价值模型的质量在真实世界环境中可以直接转化为策略性能的提升
总之,如原论文所述,这些工作展示了基于VLM 的价值估计在机器人强化学习中的可行性
但问题是,现有方法依赖于在静态图文数据上训练的判别式 VLM(视觉语言模型),仅以隐式方式捕获时间动态。这使得价值估计局限于单个帧,而无法显式建模物理交互随时间演变的过程
正是因为这种局限性促使作者利用视频生成模型:这类模型直接从大规模视频数据中学习时空动态,为长时间跨度任务中的价值估计提供了一个天然的基础
其次,面向机器人操作的视频生成模型,侧重对未来走势的判断
-
视频生成模型通过从大规模视频数据中学习来预测未来的视觉序列,从而捕获关于物体运动、物理交互以及场景演化的时空先验(Blattmann et al., 2023; Kong et al., 2024; Yang et al.,2024; Zheng et al., 2024)
与在静态图文对上训练的视觉-语言模型不同,视频生成模型被显式地优化,用于刻画场景如何随时间演变
近期的最先进方法通常采用扩散 Transformer(Baoet al., 2023; Peebles and Xie, 2023)来建模潜在视频分布,从而支持在语言指令(Blattmannet al., 2023; Singer et al., 2022; Villegas et al., 2022),或部分观测(Ceylan et al., 2023; Qi etal., 2023)条件下进行未来预测
这些特性使得视频生成模型非常适合用于预判视觉动态 -
总之,预见未来视觉结果的能力在机器人领域引起了越来越多的关注
已有工作将视频预测作为世界模型用于规划,通过生成的未来画面来模拟动作结果或指导决策
Du 等2023
Zhou 等2024其他方法则将视频生成集成到策略学习流程中,例如通过逆动力学提取动作
Yang 等,2023在生成的目标帧上对策略进行条件建模
Du 等2023
Zhang 等2025或在生成动作的同时联合生成视频帧
Cheang 等,2024
Wu 等,2023
Ye 等,2026最新研究还通过合成人与物体交互的视频来探索从人到机器人的迁移(Bharadhwaj 等,2024;Kareer 等,2025;Zhao 等,2025)
尽管已有这些进展,现有方法主要利用视频生成来产生或引导动作
与之相反,作者研究视频生成的一种互补角色:价值估计
对未来动力学的预测会隐式编码任务进展的信号,这表明视频模型可以评估交互是否朝着成功完成的方向发展。基于这一洞见,作者提出 ViVa,这是一种视频生成式价值模型,它将一个预训练的视频生成器重新用作标量价值预测器,从而将价值估计建立在对未来具身动力学的预期之上
1.2 完整方法论
1.2.0 问题表述
作者将机器人操作形式化为由元组定义的马尔可夫决策过程(MDP),其中
- S 是状态空间
- A 是动作空间
- T : S × A →S 是状态转移动力学
- R : S × A →R 是奖励函数
- γ ∈0, 1 是折扣因子
实际上,完整状态并不能被直接观测到;取而代之的是,在每个时间步 ,智能体接收
-
一个观测
(例如,多视角RGB 图像)
以及其本体感受状态然后将联合观测记为
-
智能体根据策略
长度为在策略π 下,一条轨迹的概率为
-
奖励函数表示为
回报是累积奖励
强化学习RL的目标是最大化期望回报
在这项工作中,作者专注于学习价值函数,它用于++估计给定观测下的期望未来回报++
对于一个策略π,价值函数被定义为
作者的目标不是学习一个策略,而是学习一个能够从当前观测准确预测的模型。然而,由于部分可观测性以及需要对未来动态进行推理,直接从单张图像估计长时域回报是具有挑战性的
为了解决这一问题,作者才提出的视频生成式价值模型,通过想象未来状态,将价值预测建立在预期具身动态之上
1.2.1 整体架构
作者在 Wan2.2(Wan 等人,2025)之上构建他们的视频生成式价值模型
Wan2.2 是一个预训练的视频扩散 Transformer,最初用于在给定初始图像和文本条件的情况下生成未来帧。为了将其适配为价值估计模型,作者通过 latent injection(Agarwal 等人,2025;Liang 等人,2025)扩展其输入与输出模态,而无需修改其核心架构
ViVa 的整体架构如图 2 所示『左:当前机器人的本体感知信息和标量价值通过重复填充与广播操作被映射到潜在帧。右:注入的潜变量组成一个统一的序列,其中,当前观测(空白 token、本体感知信息以及多视角图像)作为干净的条件帧,而未来的本体感知信息和价值则作为带噪声的目标帧。扩散 Transformer 在这些干净前缀的条件下对目标进行去噪,联合预测未来的具身状态以及一个标量价值,该价值被定义为归一化回报』
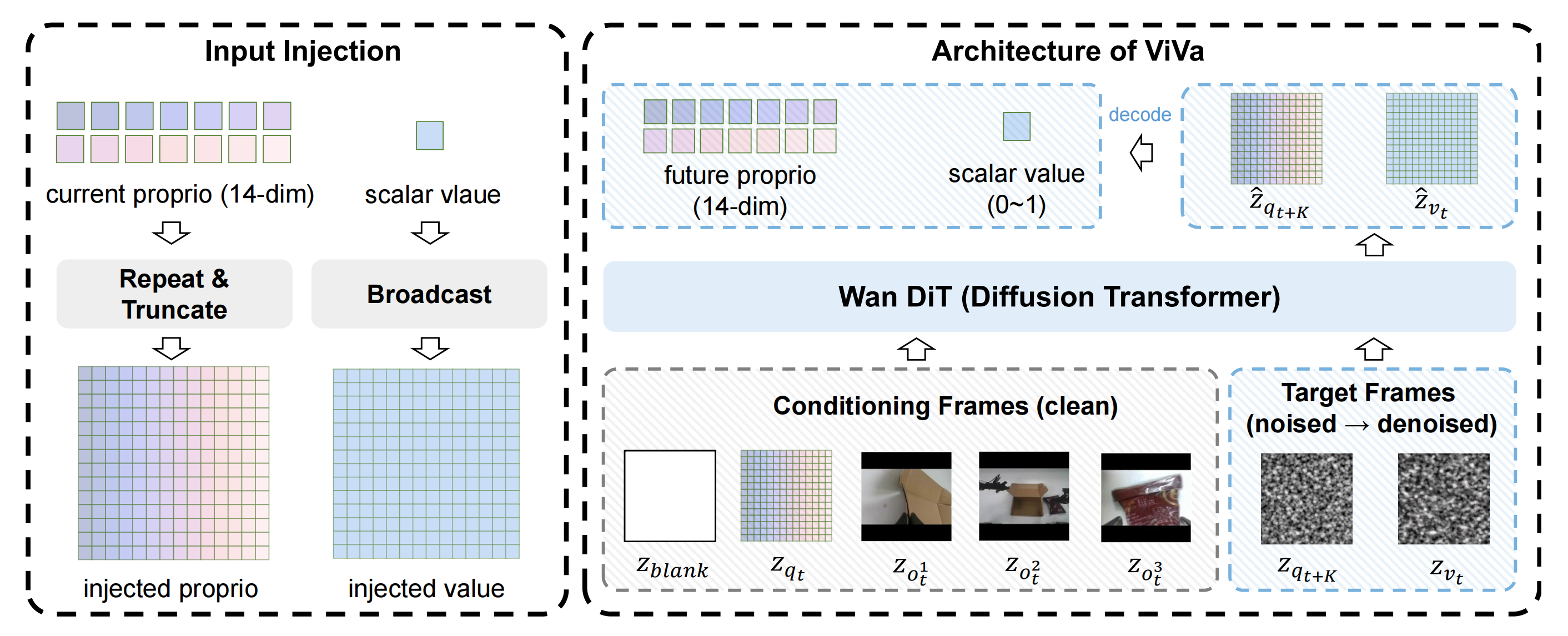
-
模态的潜在编码
所有输入和输出模态都被映射到形状为作者使用预训练的时空VAE 对图像进行编码:
每个相机视角
对于如本体感受状态*这二者首先被归一化到−1, 1 以匹配潜在空间的统计分布
-
训练期间的潜在序列
训练期间,作者组装一个固定长度的潜在帧序列,其中包含条件帧和目标帧。令K 表示一个固定的预测范围。该序列为:
其中
去噪器
-
推理过程中的潜在序列
在推理时,仅有条件帧可用。作者将当前观测(图像和本体感受)编码到各自的潜在帧中,构成相同的前缀
-
训练目标
作者采用与 Wan2.2(Wan 等,2025)中相同的 flow matching 形式化方法。令作者构建一条线性插值路径
模型
总体目标是一个加权组合
其中
作者也尝试过联合预测未来的视觉潜变量,但观察到价值估计精度有所下降
作者推测这是由于两个任务之间固有的难度不匹配所致:视觉生成需要捕获高维空间结构,而价值潜变量具有更简单的结构,在联合优化过程中更容易受到视觉重建目标的干扰
通过将所有模态都视为潜在帧,作者的架构在保留其时空先验的同时,将一个强大的视频生成器重新用于价值估计
而引入对未来本体感受(proprioceptive)的预测有两个目的:
- 一是迫使模型内化机器人的自身动力学,这对于需要精确肢体协同的任务至关重要
- 二是为价值估计提供一种补充视觉线索的隐式运动度量
总之,通过在视觉观测的基础上联合推理并预测具身动力学,作者宣称,他们的模型捕捉到任务状态如何演化的更丰富概念,从而在长时间跨度的操作任务中实现更准确的回报归因
// 待更