目录
- 模型开发类
-
- 论文1:提出/验证STILT模型
- [论文2:WRF--STILT 模型引入](#论文2:WRF–STILT 模型引入)
- [论文3:STILT-R v2更新说明](#论文3:STILT-R v2更新说明)
- 论文4:
- 模型应用类
-
- [论文1:WRF--STILT 模型应用(成渝经济圈CCEC)](#论文1:WRF–STILT 模型应用(成渝经济圈CCEC))
- 论文4:
- 参考
-
- [1. 欧拉网格模型概述](#1. 欧拉网格模型概述)
模型开发类
论文1:提出/验证STILT模型
J2003-《A near-field tool for simulating the upstream influence of atmospheric observations: The Stochastic Time-Inverted Lagrangian Transport (STILT) model》-提出/验证STILT模型
(用于模拟大气观测上游影响的近场工具:随机时间反演拉格朗日传输(STILT)模型)
该论文主要介绍了一种名为STILT的新型大气传输模型,旨在通过大气浓度观测数据来反演和诊断地表的温室气体(如CO2)排放通量。以下是该论文核心研究内容的详细介绍:
1. 研究背景与动机
- 近场(Near-field)变异性挑战:行星边界层(PBL)中的痕量气体浓度对地表通量(排放或吸收)极其敏感。然而,地表源和汇分布不均,导致大气浓度在"近场"(即气团到达观测点前刚刚接触过的地表区域)产生巨大的变异性。
- 传统模型的局限性:传统的欧拉(Eulerian)网格模型由于空间分辨率的限制,通常会将这些亚网格尺度(subgrid scale)的近场影响平均化,难以准确捕捉复杂的边界层动力学和高分辨率的浓度变化。
2. STILT模型的核心机制
- 受体导向框架(Receptor-oriented framework):与从排放源出发的正向模拟不同,STILT采用从观测点(即受体,Receptor)出发的**时间反演(向后追踪)**方法。
- 拉格朗日粒子扩散:模型释放大量虚拟粒子代表气团,利用分析的气象风场和马尔可夫链(Markov chain)过程模拟湍流运动,在时间上向后追踪这些粒子的轨迹。
- 计算足迹(Footprint):通过统计粒子在不同时间和空间网格中停留的时间,模型可以计算出"影响函数"或"足迹"(Footprint)。足迹定量地将上游特定区域、特定时间的地表通量与受体处观测到的浓度变化联系起来。这种向后追踪的方法极大地节省了计算资源。
3. 物理与数值要求
为了确保模型模拟的真实性和源-受体关系的准确性,论文详细探讨了拉格朗日粒子模型必须满足的物理条件:
- 充分混合标准(Well-mixedness):模型必须保证初始均匀混合的粒子在湍流中不会出现非物理的聚集或稀释。
- 风切变与垂直湍流的耦合:必须准确模拟气团在不同高度间的垂直混合以及随之而来的水平风切变导致的扩散。
- 高时间分辨率:时间步长必须足够小,以解析湍流速度自相关性的衰减。
- 质量一致性:必须将粒子视为具有相等质量的空气块,并考虑大气密度的垂直梯度。
4. 时间可逆性与质量守恒测试
- 研究人员对STILT进行了实证测试,比较了正向(Forward)和反向(Backward)时间模拟的结果。
- 关键发现 :如果驱动模型的气象数据(如数值天气预报模型输出的风场)存在质量不守恒(Mass violation),会导致正向和反向模拟出现不对称和误差。在修正了风场的质量守恒问题后,STILT模型表现出了良好的时间可逆性。
5. 实际应用:COBRA实验案例
- 论文将STILT模型应用于北美COBRA(CO2 Budget and Rectification Airborne)实验的观测数据分析中。
- 以威斯康星州的WLEF高塔观测为例,STILT成功生成了高分辨率的足迹图,揭示了不同时间段内(如早晨与下午),风向变化如何导致不同类型的植被(如农田、混合林)对观测点CO2浓度的影响发生显著改变。这证明了简单的边界层一维收支模型在复杂地形和风场下是不适用的,必须依赖STILT这样的近场工具。
6. 基于信息论的评估(信息增益)
- 论文引入了信息论中的**香农熵(Shannon entropy)**概念,量化了STILT模型相对于传统欧拉网格模型的优势。
- 结果表明,在气团到达观测点前的最初十几个小时内(即近场影响最强烈的时期),拉格朗日粒子方法能够提供显著的信息增益(Information Gain),因为它能以亚网格级别的精度解析上游影响区域,减少了排放源位置的不确定性。
论文2:WRF--STILT 模型引入
J2010-《Coupled weather research and forecasting--stochastic time-inverted lagrangian transport (WRF--STILT) model》
(耦合天气研究与预报-随机时间反演拉格朗日传输(WRF-STILT)模型)
详细介绍了如何将先进的中尺度数值天气预报模型(WRF)与STILT模型进行在线/离线耦合
这篇论文确立了WRF-STILT作为一个强大的社区耦合模型。通过引入时间平均的质量耦合风场和先进的对流处理机制,该模型成功解决了拉格朗日粒子模型长期面临的质量不守恒难题。它为温室气体通量反演(自上而下的碳收支研究)、空气质量模拟、飞行计划制定以及卫星数据验证提供了一个高精度、高气象真实性的核心工具。
1. 研究背景与动机
- 降低传输误差:在利用大气浓度观测数据反演大陆尺度的温室气体(如CO2)地表通量时,气象传输模型的误差是最大的不确定性来源之一。
- 高分辨率气象场的需求:早期的STILT模型通常依赖于较粗分辨率的全球或区域分析风场(如NCEP或EDAS)。为了更真实地模拟区域尺度、复杂地形下的边界层动力学和传输过程,研究人员决定将STILT与高分辨率、物理过程先进的WRF模型耦合。
2. WRF-STILT 耦合的核心技术与创新
论文详细描述了连接欧拉网格模型(WRF)和拉格朗日粒子模型(STILT)的数值和物理处理方法:
1、质量耦合风场(Mass-coupled wind variables):这是该研最重要的突破之一。前一篇论文提到,气象场插值会导致"质量不守恒",从而引起正反向轨迹不对称。为了解决这个问题,WRF-STILT接口提取了WRF模型内部用于平流计算的时间平均的、与质量耦合的风速(U,V,Ω),而不是传统的瞬时风速。这极大地改善了插值到粒子位置时的质量守恒特性。
2、对流过程的显式处理(Treatment of Convection) :传统的拉格朗日模型往往忽略或简单处理次网格尺度的湿对流。该耦合模型直接提取了WRF中积云对流参数化方案(如Grell-Devenyi方案)计算出的上升气流、下沉气流的质量通量以及卷入/卷出率。
STILT利用这些数据,以随机概率的方式模拟粒子在对流云中的垂直快速传输,同时严格遵守热力学第二定律的"充分混合标准"。
3、网格与坐标系转换:详细处理了WRF的交错网格(Arakawa C-grid)和地形跟随气压坐标到STILT所需的无交错网格和高度坐标的转换。
3. 实验设置与气象验证
- 研究人员在美国东北部(特别是针对缅因州的Argyle高塔和威斯康星州的WLEF高塔观测站)设置了WRF的粗网格(40km)和嵌套高分辨率网格(8km)。
- 通过与探空探空气球(Radiosonde)和NARR再分析数据进行对比,验证了WRF模拟风场和边界层高度的准确性及误差随预报时间的增长规律。
4. 轨迹模拟结果与敏感性分析
论文展示了使用耦合模型计算出的向后轨迹(Back trajectories)和足迹(Footprints),并进行了对比分析:
- 空间分辨率的影响:对比粗网格(40km)和嵌套细网格(8km)发现,高分辨率网格能更好地解析局地地形和弱天气系统(如海岸线附近的海陆风或低压槽),导致计算出的气团来源路径发生巨大改变。
- 对流的影响:开启对流质量通量后,部分粒子会被快速抬升到自由对流层,这改变了粒子在低层的分布,从而对最终计算出的"地表足迹"(即观测点对上游地表排放的敏感度)产生不可忽视的影响。
5. 质量守恒的严格测试
- dmass诊断:论文统计了粒子在传输过程中经历的质量违背累积量。结果证明,使用WRF的时间平均质量耦合风场,其质量守恒表现远远优于使用瞬时风场或全球分析场。
- 正反向轨迹对比:研究人员重复了前一篇论文中的时间可逆性测试(释放向后轨迹寻找源区,再从源区释放向前轨迹看是否回到受体)。测试结果显示,使用时间平均风场时,正反向粒子数高度一致,完美契合了"充分混合标准"。
论文3:STILT-R v2更新说明
J2018《Simulating atmospheric tracer concentrations for spatially distributed receptors: updates to the Stochastic Time-Inverted Lagrangian Transport model's R interface (STILT-R version 2)》
(模拟空间分布受体的大气示踪物浓度:随机时间反演拉格朗日传输模型R接口的更新(STILT-R 第2版))
这是对STILT模型在软件架构和物理算法上的一次重大现代化升级,专门针对高分辨率、城市尺度和移动观测的需求进行了优化。
GitHub-Stochastic Time-Inverted Lagrangian Transport model
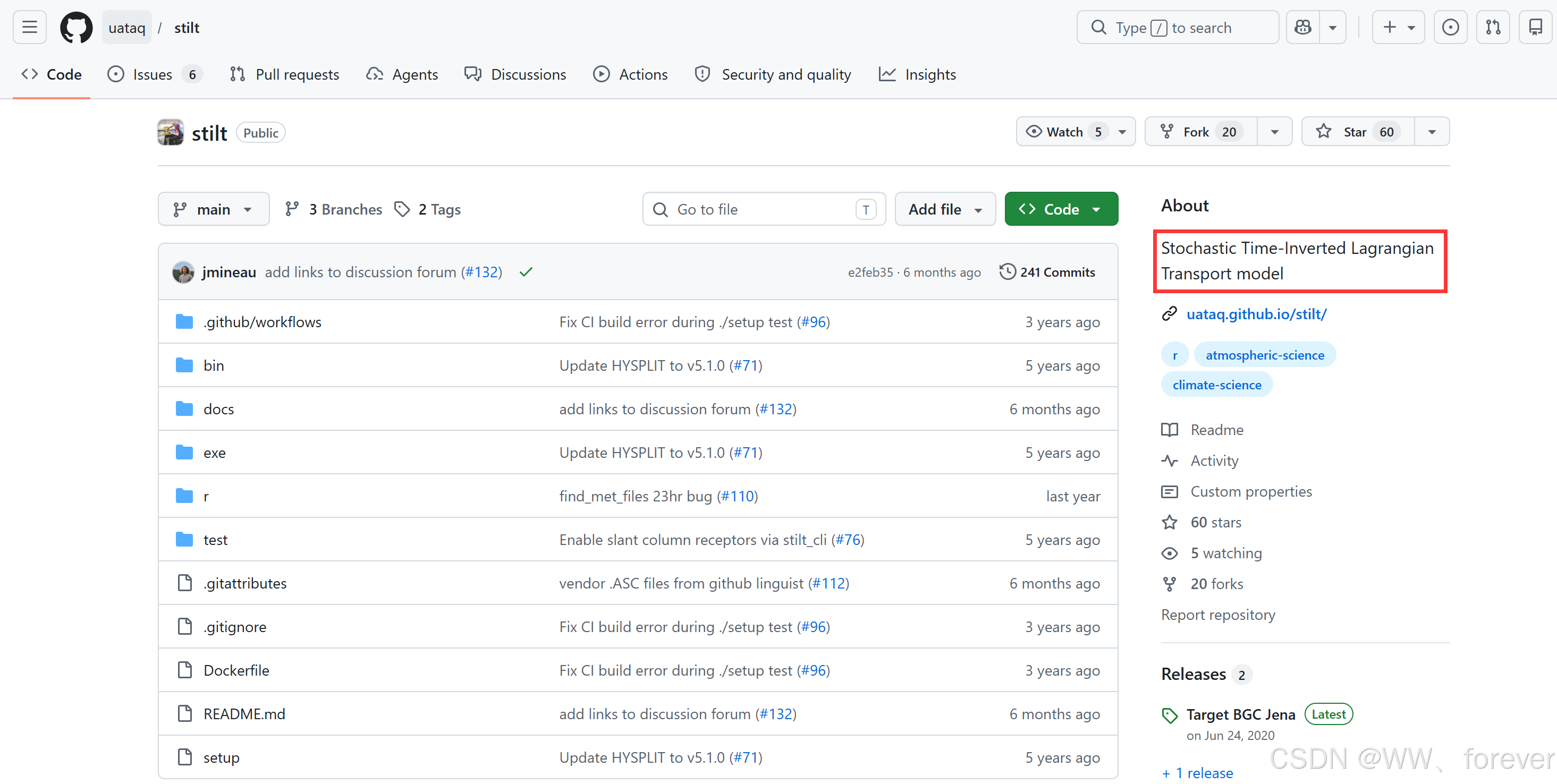
1. 研究背景与动机
- 城市高分辨率观测的兴起:城市是全球温室气体的主要排放源。近年来,利用火车、公交车或密集廉价传感器网络进行"空间分布"和"高频移动"观测成为趋势。
- 传统模型的局限性:传统的STILT模型最初为区域尺度(100-1000公里)设计。面对成千上万个密集的移动观测点(受体),传统模型面临巨大的计算瓶颈。此外,传统模型在处理极近距离(1-10公里内)的排放源时,其物理假设和网格分配方法会导致较大的误差。
2. STILT-R v2 的核心技术更新
为了适应城市微尺度(< 1 km)的模拟,研究团队对STILT的R语言接口和底层算法进行了三项关键升级:
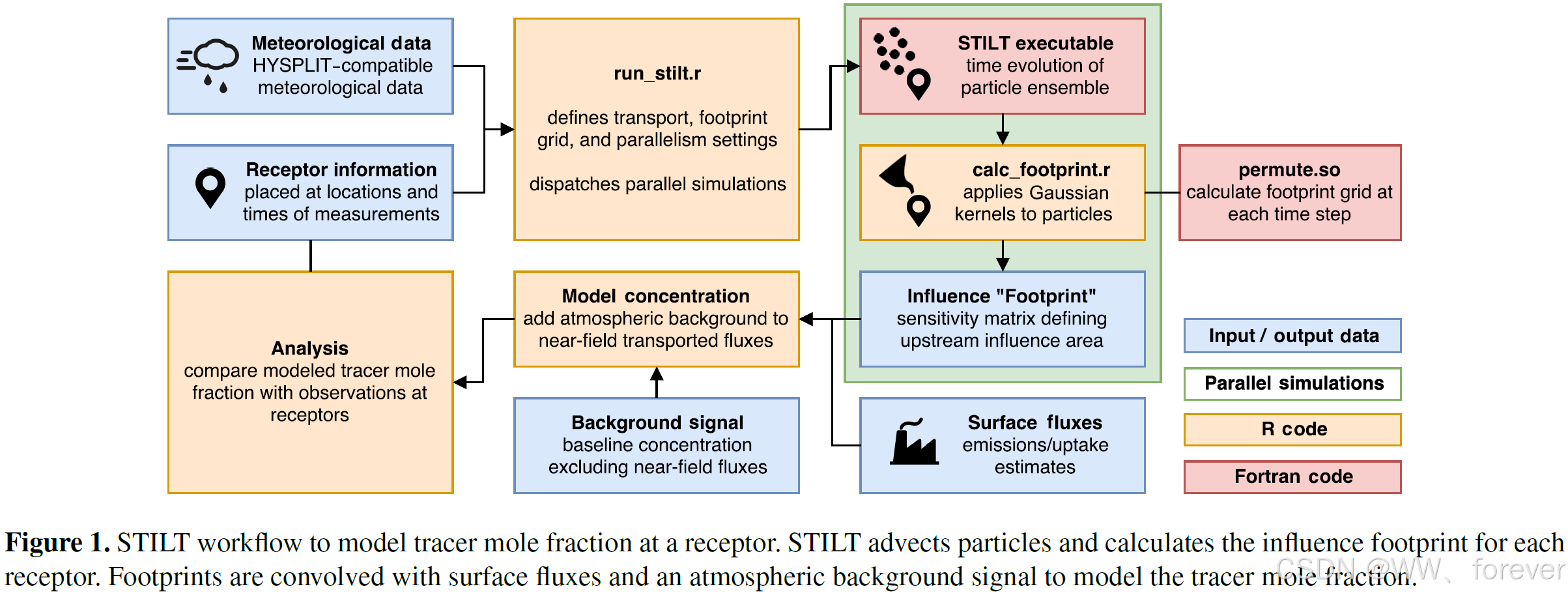
A、自动化并行计算(Model Parallelization):
重构了代码库(开源于GitHub),引入了高级的并行计算方法。支持单节点多核并行(Process forking)以及基于SLURM调度器的多节点集群并行。这使得模型能够将海量的受体(如移动列车轨迹上的每一个点)自动分配到不同的计算线程中,使总模拟时间随CPU核心数线性减少。
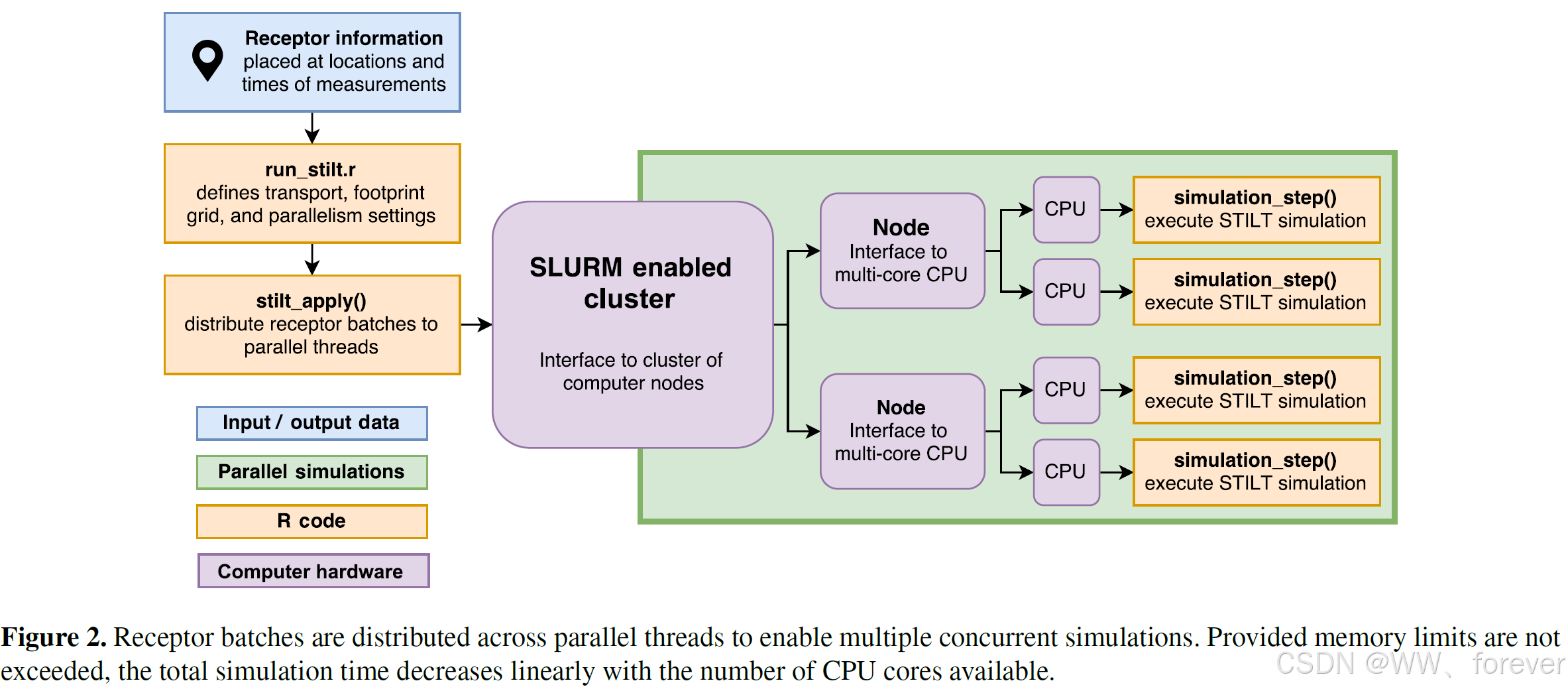
B、超近场(Hyper Near-Field, HNF)垂直混合深度的修正:
这是物理机制上的重要改进。
原版STILT假设地表排放会瞬间混合到一个有效深度(通常是边界层高度的一半)。但在"超近场"(距离受体1-10公里,传输时间0.1-1小时内),空气块还来不及充分混合。
新版本基于泰勒均匀湍流理论,引入了一个随时间动态增长的有效混合深度( h ′ h' h′)。这极大地增强了模型对紧邻受体的地表排放源的敏感度再现。
C、基于核密度估计(KDE)的足迹计算:
为了节省计算资源,拉格朗日模型通常使用较少的粒子(如200个)来代表气团。
原版STILT使用"动态网格粗化"方法来计算足迹(Footprint,即源区敏感度),这在高分辨率下会导致严重的网格噪音和过度平滑。
新版引入了高斯核密度估计器,其平滑核的带宽会根据粒子群的扩散程度和运行时间动态调整。测试表明,该方法用极少的粒子就能完美逼近"暴力计算(10万粒子)"的平滑足迹形态。
3. 实际应用与模型评估
研究团队将升级后的STILT-R v2应用于美国盐湖城(SLC)轻轨列车在2015年7月收集的高频CO2观测数据中:
极高分辨率清单:结合了分辨率高达0.002度(约200米,相当于一个城市街区大小)的Hestia人为碳排放清单和高分辨率生物通量清单。
结果对比:将新算法(带有HNF修正的KDE,即GWD方法)与旧算法进行对比。结果表明,GWD方法在空间和时间上与轻轨观测到的CO2浓度吻合度最高。
捕捉微尺度特征:模型成功模拟出了盐湖城"城市中心-郊区-乡村"的CO2浓度梯度,甚至能反映出列车经过繁忙十字路口或主干道时的局部浓度峰值。
4. 关键发现与对未来的启示
网格分辨率的重要性:论文证明,将排放清单和足迹网格粗化到0.01度或0.1度,会完全抹杀掉移动观测捕捉到的微尺度空间变异。进行城市级模拟必须使用极高分辨率(如0.002度)。
"超近场"主导效应的警告:研究发现,像轻轨或汽车这样的地面移动平台,其测量信号极易被紧邻的"超近场"排放(如与轻轨并行的公路上的汽车尾气)所主导。这会导致模型难以完美匹配观测绝对值(因为存在亚网格尺度的未混合现象)。
观测网络设计建议:如果目标是反演评估整个城市的宏观排放清单,建议将观测仪器放置在较高建筑物顶部,或距离主干道至少0.5公里处,以减少超近场局部源的过度干扰,让排放物有时间进行自然稀释。
论文4:
模型应用类
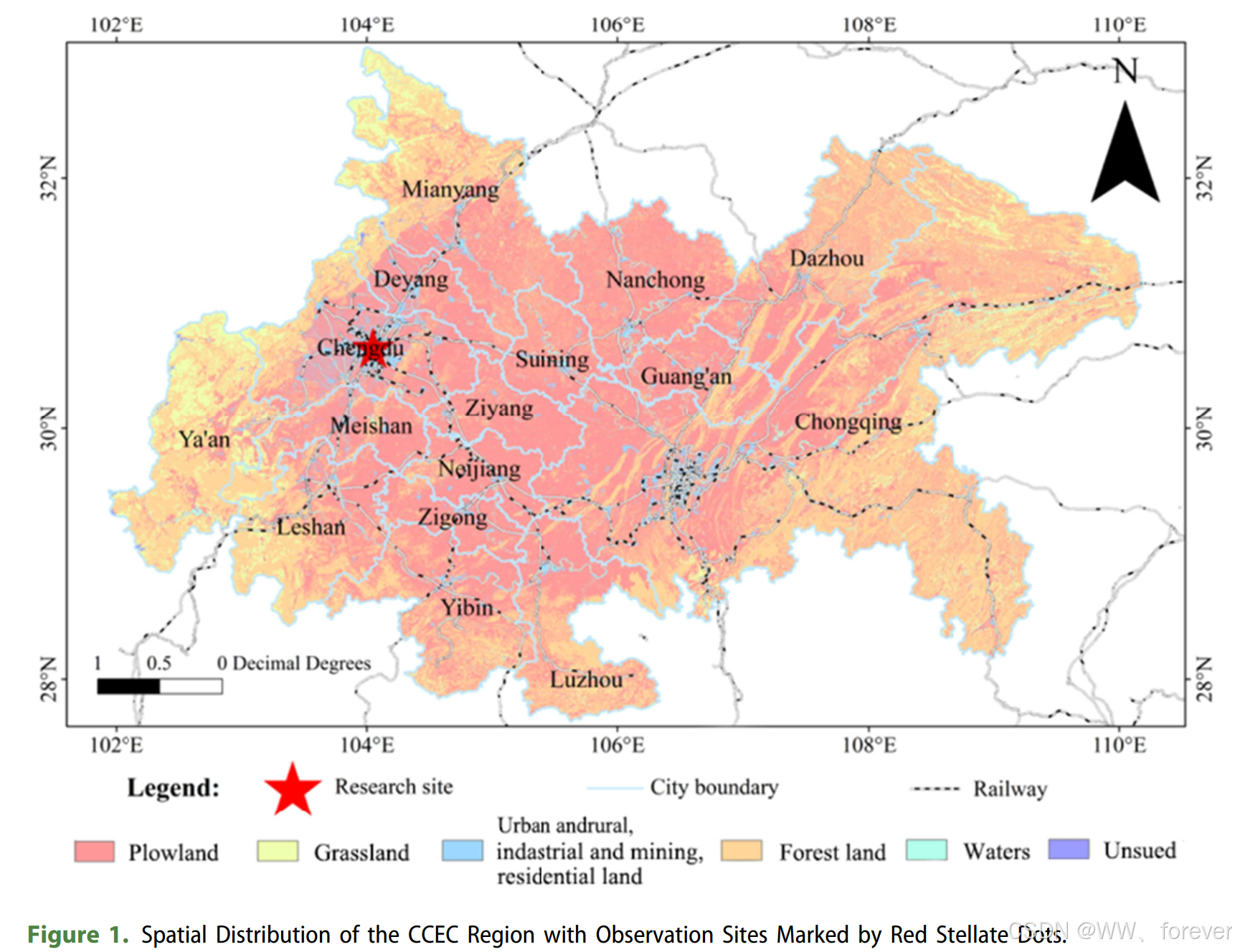
论文1:WRF--STILT 模型应用(成渝经济圈CCEC)
J2026-《Bayesian inversion of urban sectoral scale anthropogenic CO2 emissions coupled with weather research and forecasting (WRF) and stochastic time-inverted lagrangian transport (STILT) models in Chengdu-Chongqing economic circle》-Carbon management(三区)
(基于WRF-STILT模型耦合的成渝经济圈城市部门尺度人为CO2排放贝叶斯反演)
该研究聚焦于中国西部重要发展区域------成渝经济圈(CCEC),利用"自上而下"(Top-down)的大气反演方法,结合地面高频观测数据和大气传输模型,对该区域的城市部门尺度人为二氧化碳(CO2)排放进行了高时空分辨率的估算和优化。
1. 研究背景与动机
碳中和目标与城市排放 :城市是全球温室气体排放的主力军。为了实现中国的"双碳"目标(2030年碳达峰,2060年碳中和),需要对工业、能源、交通等关键部门的碳排放进行精准核算。
传统排放清单的局限性 :目前主要依赖"自下而上"(Bottom-up)的方法(即活动数据乘以排放因子)来编制碳排放清单。然而,这种方法在城市尺度上存在极大的不确定性(可高达150%),且数据发布存在严重滞后,无法满足高精度、近实时减排评估的需求。
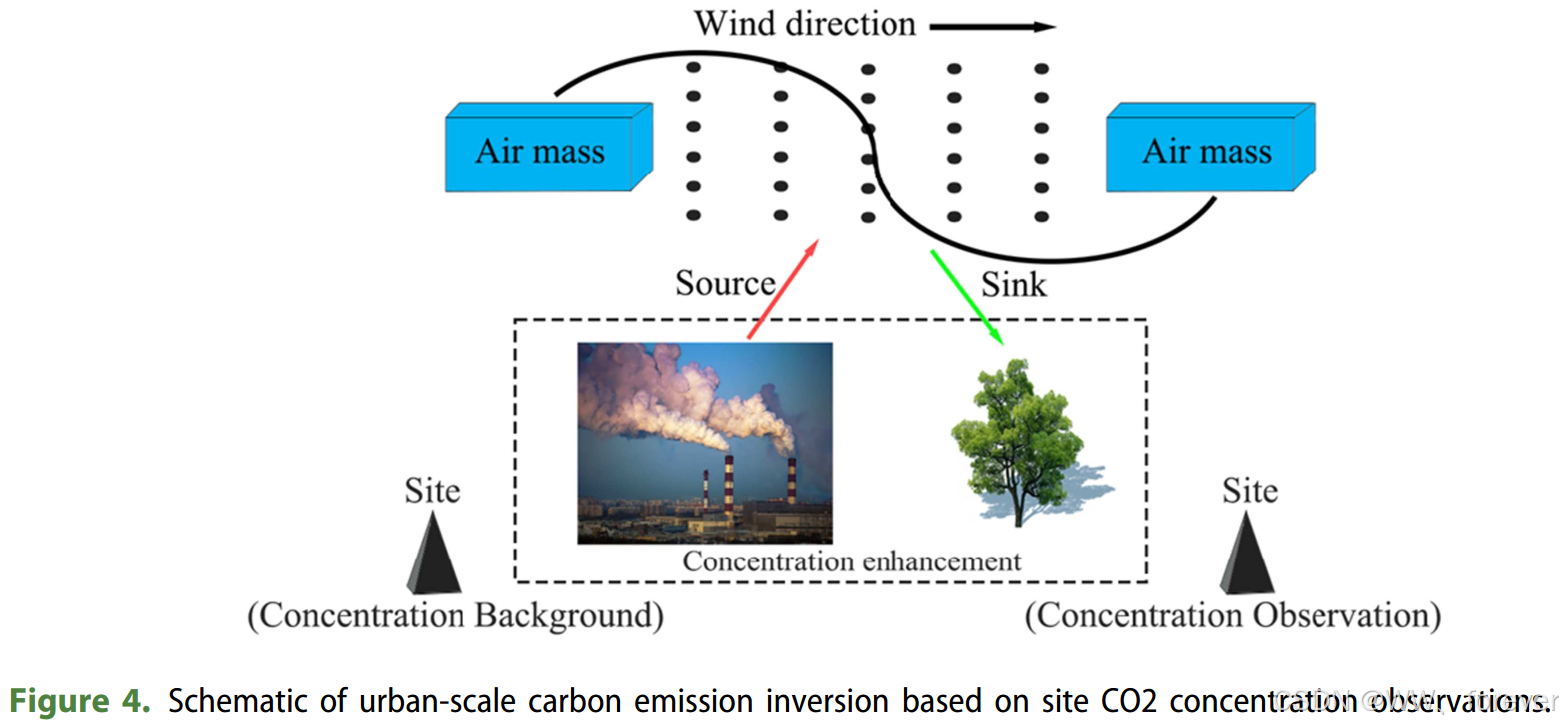
自上而下反演的优势:利用地面观测的大气CO2浓度,结合大气传输模型(如WRF-STILT)和反演算法,可以独立验证和修正先验排放清单(Priori inventories),这被称为"自上而下"的方法。
2. 研究方法与模型构建
研究团队构建了一个耦合的WRF-STILT模型框架,并结合多比率因子贝叶斯优化算法进行碳排放反演。
观测数据:使用了位于四川成都的一个高精度地面观测站(Picarro G1101-I)在2019年12月至2020年5月期间连续测量的CO2浓度数据。
先验排放清单(Priori Inventories):引入了两种全球/国家级网格化排放清单作为初始基准:
-
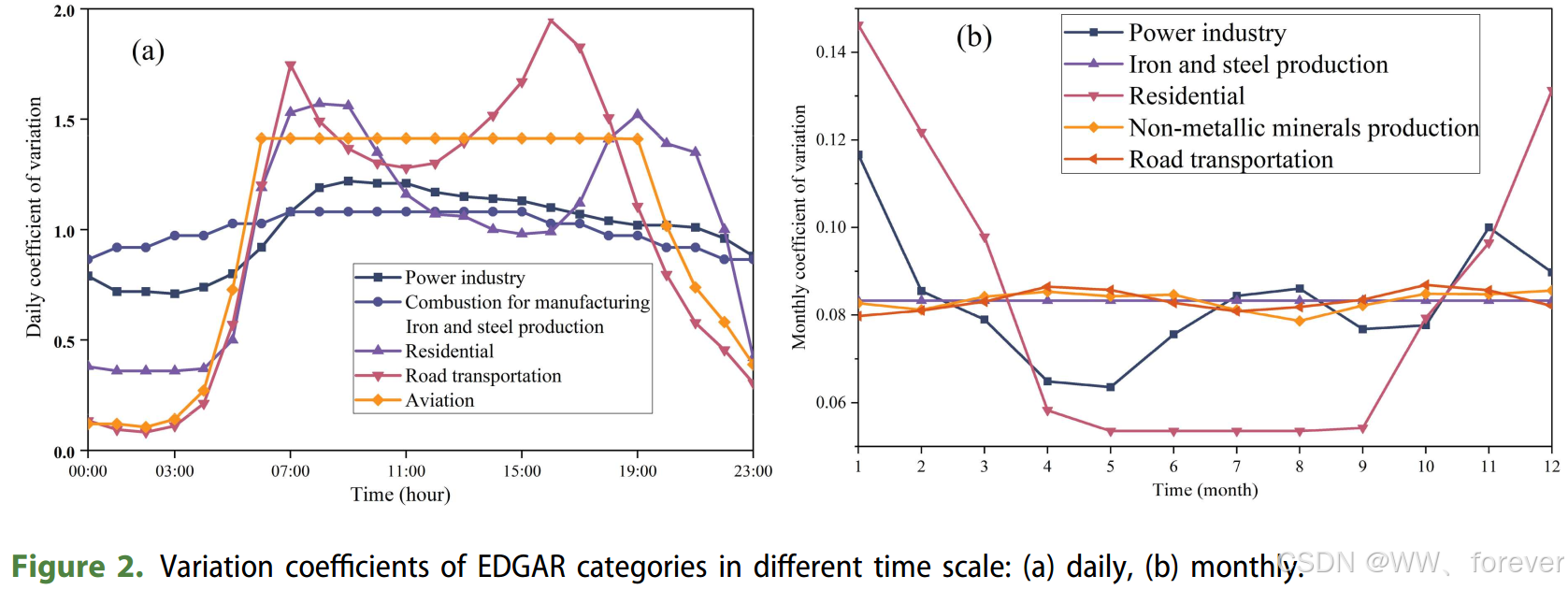
EDGAR(全球大气研究排放数据库):提供年度尺度的部门排放,研究中使用了月度和小时时间分配因子对其进行时间降尺度。
-
GRACED(近实时全球网格化日CO2排放数据集):结合了夜间灯光、交通流量等近实时活动代理数据,具有更高的时空动态性。

WRF-STILT 传输模型:
- WRF:用于模拟高分辨率(最内层3km×3km)的气象场(风向、风速、边界层高度等)。
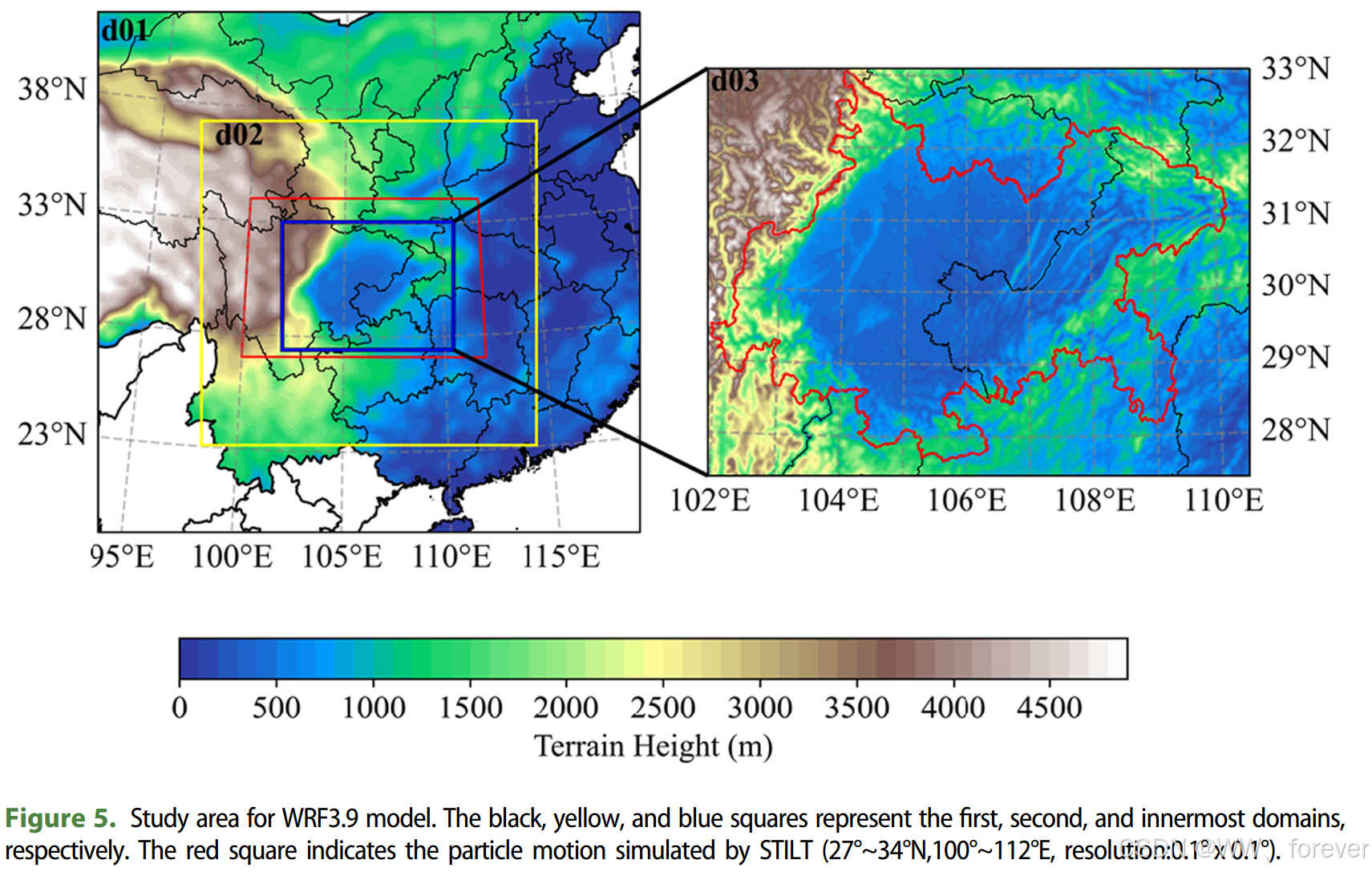

- STILT:拉格朗日随机粒子扩散模型。从观测站点(受体)向后追踪气团轨迹,计算上风向区域地表排放对观测站点CO2浓度的"足迹权重"(Footprint weight,即敏感度)。
多比率因子贝叶斯反演算法:根据观测浓度与模型模拟浓度的差异,通过最小化成本函数,为不同的排放部门(如电力、工业、交通、住宅等)计算出最优的"缩放因子"(Scaling factors),从而修正先验清单,得到后验(Posterior)排放量。
3. 核心研究结果
足迹权重与源区贡献:
STILT模型揭示了成渝地区的足迹权重存在显著的时空差异。冬季(12月至2月)的足迹分布更集中。
受盛行风(偏北风和东北风)影响,对成都观测站CO2浓度贡献最大的强影响区主要位于站点的东北方向(包括成都周边、眉山、德阳等地)。
CO2浓度增强模拟对比:
工业部门对CO2浓度升高的贡献最大,其次是电力部门。
GRACED vs. EDGAR:基于GRACED清单模拟的CO2浓度(日均值和小时均值)整体低于EDGAR,且GRACED的模拟结果更接近实际观测值。这是因为EDGAR倾向于将排放集中在少数大型点源上,导致局部浓度被高估;而GRACED利用代理数据将排放更平滑地分配到空间中,且能更好地反映疫情(COVID-19)初期的排放下降。
误差敏感性分析:
研究测试了不同浓度误差约束条件(如±0.25 ppm至±7 ppm)对反演结果的影响。结果表明,当误差范围在±5 ppm以内时,GRACED模拟值与观测值的相关性高达0.94以上,表现出极强的鲁棒性。
部门尺度的排放优化(缩放因子):
反演结果显示,EDGAR清单在成渝地区显著高估了炼油(REF)和非金属矿物(NMN)部门的排放,而低估了住宅煤炭燃烧(RCO)和钢铁生产(IRO)的排放。
相比之下,GRACED清单的部门偏差较小(除了严重低估了航空运输部门)。
4. 交叉验证与结论
与MEIC清单的交叉验证:研究将反演得到的后验碳排放通量与中国高分辨率多尺度排放清单(MEIC,被认为更符合中国本土实际)进行了对比。
结果显示,在较小的误差约束(±2 ppm)下,基于GRACED清单反演的CO2排放通量(0.0498 mg/m²/s)与MEIC清单(0.0506 mg/m²/s)最为接近。
核心结论:
- WRF-STILT耦合模型结合贝叶斯优化算法,能够有效实现城市尺度(10km分辨率、日尺度)的部门级碳排放高精度反演。
- 使用包含近实时动态信息的先验清单(如GRACED),结合严格的浓度观测误差约束,可以显著降低城市碳排放估算的不确定性。
论文4:
参考
1. 欧拉网格模型概述
欧拉法(Eulerian Approach)并不追踪每一个单独的流体微团(比如一个小水滴),而是关注空间中固定的点。
观察视角 : 你站在河岸上的桥上,看着下方的水流经过。关心的是桥下某一个特定位置的速度、压力和密度如何随时间变化,而不是那滴水最后流向了哪里。
数学表达 : 在欧拉网格中,物理量(如速度 u u u)是空间位置 x \mathbf{x} x 和时间 t t t 的函数,即 u = f ( x , t ) u = f(\mathbf{x}, t) u=f(x,t)。
网格形式: 计算域被划分为一个个固定的网格单元(Cell)。流体像"幽灵"一样穿过这些格子,而网格本身的形状和位置保持不变。
对比小贴士: 与之相对的是拉格朗日法(Lagrangian),它像是在水滴上装了GPS,跟着水滴一起跑。
欧拉网格模型空间分辨率是否存在限制?
是的,欧拉网格模型在空间分辨率上存在显著的物理和算力限制。 这种限制通常被称为"尺度问题"。
A. 最小物理尺度的限制(耗散尺度)
在湍流模拟中,能量会从大涡流传递到极小的涡流,最终转化为热能。这个最小的尺度被称为柯尔莫哥洛夫尺度 (Kolmogorov Scale)。如果你的网格比这个尺度大,你就无法捕捉到流体真实的能量耗散,模拟结果就会失真。
限制: 为了完全模拟(DNS),网格数量必须达到 R e 9 / 4 Re^{9/4} Re9/4( R e Re Re 为雷诺数)。对于高雷诺数流体,这需要的计算量是天文数字。
B. 数值扩散(Numerical Diffusion)
由于欧拉网格是离散的,当流体穿过网格边缘时,计算会产生人为的"抹平"效应。如果网格太粗,原本锐利的界面(如油水交界面或激波)会变得模糊不清。这种限制要求在物理量变化剧烈的区域(如边界层)必须大幅增加网格密度。
C. 内存与算力的硬性瓶颈维度灾难:
空间分辨率每提升一倍,在三维模拟中,网格数量就会增加 8 倍( 2 3 2^3 23),同时为了满足稳定性(CFL条件),时间步长通常也得缩短。这导致高精度模拟对硬件(GPU/超算中心)的要求极高。