目录
[1.1 系统要求](#1.1 系统要求)
[1.2 系统包安装](#1.2 系统包安装)
[2.1 ONNX 转 HEF 文件](#2.1 ONNX 转 HEF 文件)
[2.1.1 实例化 ClientRunner + 解析ONNX模型](#2.1.1 实例化 ClientRunner + 解析ONNX模型)
[2.2.2 加载/准备量化校准数据集](#2.2.2 加载/准备量化校准数据集)
[2.2.3 参数配置并执行量化操作](#2.2.3 参数配置并执行量化操作)
[2.2.4 保存 HAR 文件并编译生成 HEF 板端文件](#2.2.4 保存 HAR 文件并编译生成 HEF 板端文件)
[2.2 模型可视化](#2.2 模型可视化)
一、环境安装
1.1 系统要求
Hailo Dataflow Compiler 需要以下最低硬件和软件配置:
- Ubuntu 20.04 / 22.04,64 位(在 Windows 上也支持,通过 WSL2 运行)
- 16GB 以上内存(推荐 32GB 以上)
- Python 3.8 / 3.9 / 3.10,包括 pip 和 virtualenv
- python3.X-dev,以及(根据 Python 版本)python3.X-distutils、python3-tk、libfuse2、graphviz、libgraphviz-dev 等软件包可使用如下命令进行安装:sudo apt-get install PACKAGE
以下是基于 GPU 的硬件仿真所需的额外要求:
- Nvidia 的 Pascal / Turing / Ampere 架构 GPU(例如 Titan X Pascal、GTX 1080 Ti、RTX 2080 Ti 或 RTX A4000)
- GPU 驱动版本 525
- CUDA 11.8
- cuDNN 8.9
注意事项 : 如果GPU不符合上述要求,建议就不要仿真了,终端虚拟环境中输入下述命令,关闭GPU,否则会报错
bash
export CUDA_VISIBLE_DEVICES=-11.2 系统包安装
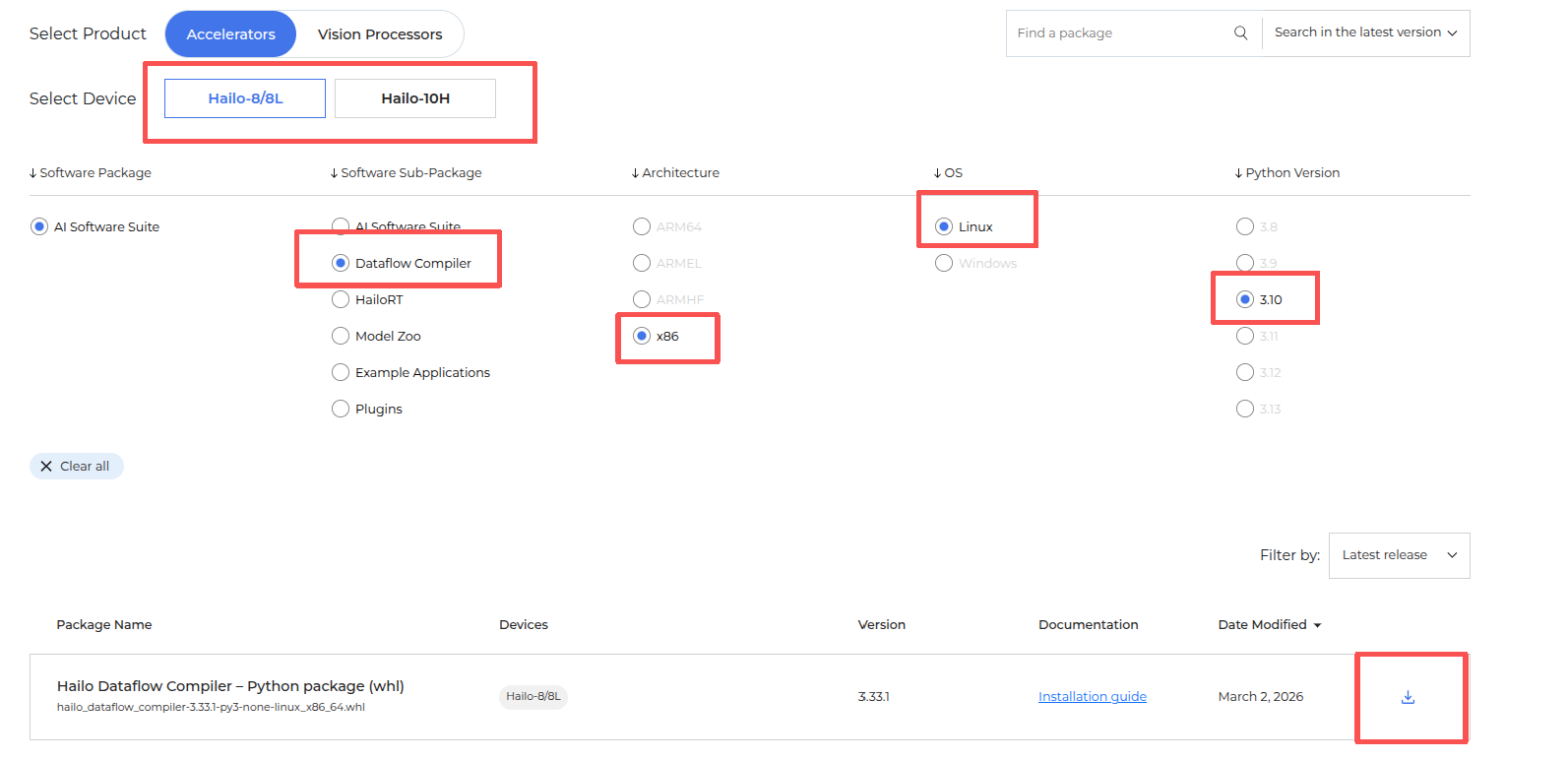
安装包下载路径:
如图,选择好算力卡版本以及操作系统后,就可以下载了
二、模型转换
模型转换分为几个步骤:
-
将 Pytorch 训练模型转换为 ONNX 模型
-
将 ONNX 模型转化为 HAR 文件,HAR 是一种 tar.gz 归档文件,包含部署到 Hailo 运行时的图结构表示和权重数据
-
将 HAR 文件转化为 Hailo 算力卡运行时 HEF 文件
2.1 ONNX 转 HEF 文件
实际转换时,具体流程如下:
-
实例化 ClientRunner + 解析ONNX模型
-
加载/准备量化校准数据集
-
配置预处理参数(均值、方差、缩放等)
-
执行模型量化
-
保存HAR调试文件
-
生成最终HEF部署文件
2.1.1 实例化 ClientRunner + 解析ONNX模型
python
from hailo_sdk_client import ClientRunner, InferenceContext
import cv2
import numpy as np
import os
onnx_model_name = "best_ckpt"
onnx_path = "./models/onnx/best_ckpt.onnx"
hw_arch = "hailo8" # 芯片类型
input_node_name = "image_arrays" # 输出节点,可通过 netron 查看
print("===== Step 1: 解析 ONNX 模型 =====")
runner = ClientRunner(hw_arch=hw_arch)
hn, npz = runner.translate_onnx_model(
onnx_path,
onnx_model_name,
start_node_names=[input_node_name],
)
print("ONNX 解析完成")补充:
- translate_onnx_model 参数说明:
- model_path:模型路径
- model_name:模型名称
- start_node_names(字符串列表,可选):需要解析的第一个 ONNX 节点名称
- end_node_names(字符串列表,可选):解析完成后可停止的 ONNX 节点列表
- net_input_shapes(字典,可选):描述 start_node_names 中每个起始节点的输入形状字典,键为节点名称,值为对应输入形状;仅当原始模型具有动态输入形状时使用(通配符表示动态轴,例如 b, c, h, w)
2.2.2 加载/准备量化校准数据集
量化数据集不支持直接传入图片,先对量化数据集进行处理,处理要求:
- 数据前处理需要严格符合模型实际前处理,如:如果模型前处理是 LetterBox (Yolo系列),则量化数据集处理时也需要使用 LetterBox 进行缩放;
- 如果模型内部已经进行了归一化操作(详见 2.2.3 部分),则量化数据集处理就不需要进行归一化操作了,反之亦然;
- 输入类型需严格匹配模型训练时的类型,如模型训练时采用 RGB 格式进行训练,则量化数据集也需要转换成 RGB 格式;
- 量化数据集数量推荐:官方推荐量化数据集数量应该 >= 1024 张;
python
# txt 中一行存放一张图片的地址
quant_txt_path = "./quant_data/qunat.txt"
# 定义前处理函数,以 LetterBox 为例
def letterbox_image(image_src, dst_size, pad_color=(114, 114, 114)):
src_h, src_w = image_src.shape[:2]
dst_h, dst_w = dst_size
scale = min(dst_h / src_h, dst_w / src_w)
pad_h, pad_w = int(round(src_h * scale)), int(round(src_w * scale))
if image_src.shape[0:2] != (pad_h, pad_w):
image_dst = cv2.resize(image_src, (pad_w, pad_h), interpolation=cv2.INTER_LINEAR)
else:
image_dst = image_src
top = int((dst_h - pad_h) / 2)
down = int((dst_h - pad_h + 1) / 2)
left = int((dst_w - pad_w) / 2)
right = int((dst_w - pad_w + 1) / 2)
image_dst = cv2.copyMakeBorder(image_dst, top, down, left, right, cv2.BORDER_CONSTANT, value=pad_color)
return image_dst
print("===== Step 2: 加载量化数据集 =====")
def load_quantization_images(txt_path, input_size=(640, 640), max_images=1200):
image_paths = []
with open(txt_path, 'r') as f:
image_paths = [line.strip() for line in f.readlines() if line.strip()]
image_paths = image_paths[:max_images]
calib_data = []
h_input, w_input = input_size # (h, w)
for path in image_paths:
img = cv2.imread(path)
if img is None:
continue
# BGR -> RGB,具体取决于模型要求的输入类型
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img_processed = letterbox_image(img, (h_input, w_input))
calib_data.append(img_processed.astype(np.float32))
return np.array(calib_data, dtype=np.float32)
calib_dataset = load_quantization_images(quant_txt_path, input_size)
print(f"加载 {len(calib_dataset)} 张量化图片")2.2.3 参数配置并执行量化操作
Hailo 模型的参数配置是通过一个脚本实现的,具体如下:
python
alls_lines = [
"normalization = normalization([0.0, 0.0, 0.0], [255.0, 255.0, 255.0])\n",
]
runner.load_model_script("".join(alls_lines))
print("===== Step 4: 模型量化中... =====")
runner.optimize(calib_dataset)
print("模型量化完成")补充:主要脚本配置参数说明:
- normalization : 归一化参数,均值设置为 0 ,方差设置为 1, 则代表归一化操作需由用户在模型外手动完成(同时需注意量化参数数据集配置也需要手动归一化);
- model_optimization_flavor:
设置 optimization_level 参数,取值范围 0, 4, 其中 level 4 精度损失最低,但模型转化时间最长;
设置 compression_level参数,取值范围 0, 5,默认使用 8-bit 权重,提高 compression_level → 更多权重使用 4-bit → 压缩更强,但可能降低精度;
- change_output_activation:对指定输出层(仅限 Conv 层)进行 Sigmoid 操作,将输出结果的 Sigmoid 操作放在模型内部进行,可以一定程度上增加模型准确率;
- quantization_param: 设置模型量化参数,如可以通过下述方法配置 16 位输出:
python
quantization_param(output_layer1, precision_mode=a16_w16)其余配置参数(不常用,不做详细解释):
- pre_quantization_optimization(量化前优化)
- post_quantization_optimization (量化后优化)
- input_conversion(输入格式转换)
- transpose(张量转置)
- normalization(归一化)
- nms_postprocess(非极大值抑制后处理)
- change_output_activation(修改输出激活函数)
- logits_layer(逻辑层 / 原始输出层)
- set_seed(设置随机种子)
- resize(尺寸调整)
2.2.4 保存 HAR 文件并编译生成 HEF 板端文件
python
print("===== Step 5: 编译生成 HEF =====")
hef_data = runner.compile()
hef_path = f"{onnx_model_name}.hef"
with open(hef_path, 'wb') as f:
f.write(hef_data)
runner.save_har(f"{onnx_model_name}_compiled.har")
print(f"\n成功生成 HEF:{hef_path}")2.2 模型可视化
如果保存了 HAR 文件,可以使用相关工具查看计算图(模型结构)用以调试,查看命令如下:
bash
hailo visualizer {hailo_model_har_name} --no-browser