前言
26年4.17这一天,在上海参加智元合作伙伴大会及与一集团客户沟通项目解决方案时,看到了PI发布了π0.7
各位从新闻稿了解了π0.7大概是个啥后,如果想
- 深入π0.7背后的更多细节
简言之,0.6 最开始只是加入了RL,还没加入记忆,记忆是后来推出的,0.7算是把记忆加上了,不过0.7的核心是提升了泛化能力 - 甚至深挖因篇幅限制 导致论文中没透露的一系列细节
正因为细节满满,使得本文的篇幅 是原π0.7 paper的2-3倍
则欢迎看本解读,想了解的细节和没想到的细节都有
第一部分 π0.7: a Steerable Generalist Robotic FoundationModel with Emergent Capabilities
1.1 引言与相关工作
1.1.1 引言
如原论文所述
-
大型语言模型不仅能够记忆事实和语义知识,还可以以全新的方式组合这些知识,解决需要建立罕见联系的问题,应用用户自定义的格式(例如JSON),并执行链式思维推理
这种组合式泛化可以说是通才能力的基石,但在物理智能领域却一直难以实现
-
尽管机器人基础模型比如VLA在规模和能力上都取得了显著进展,但它们在泛化到新任务或以新的方式重新组合技能方面的能力迄今仍然有限
总之,与语言模型不同,语言模型可以从其训练数据中组合不同能力来解决新问题,而以往的 VLA 不仅缺乏解决新任务的能力,甚至在没有针对具体任务进行微调的情况下,往往难以流畅地执行它们在训练中见过的全部指令
对此,来自知名具身公司PI的研究者提出了一个新模型π0.7
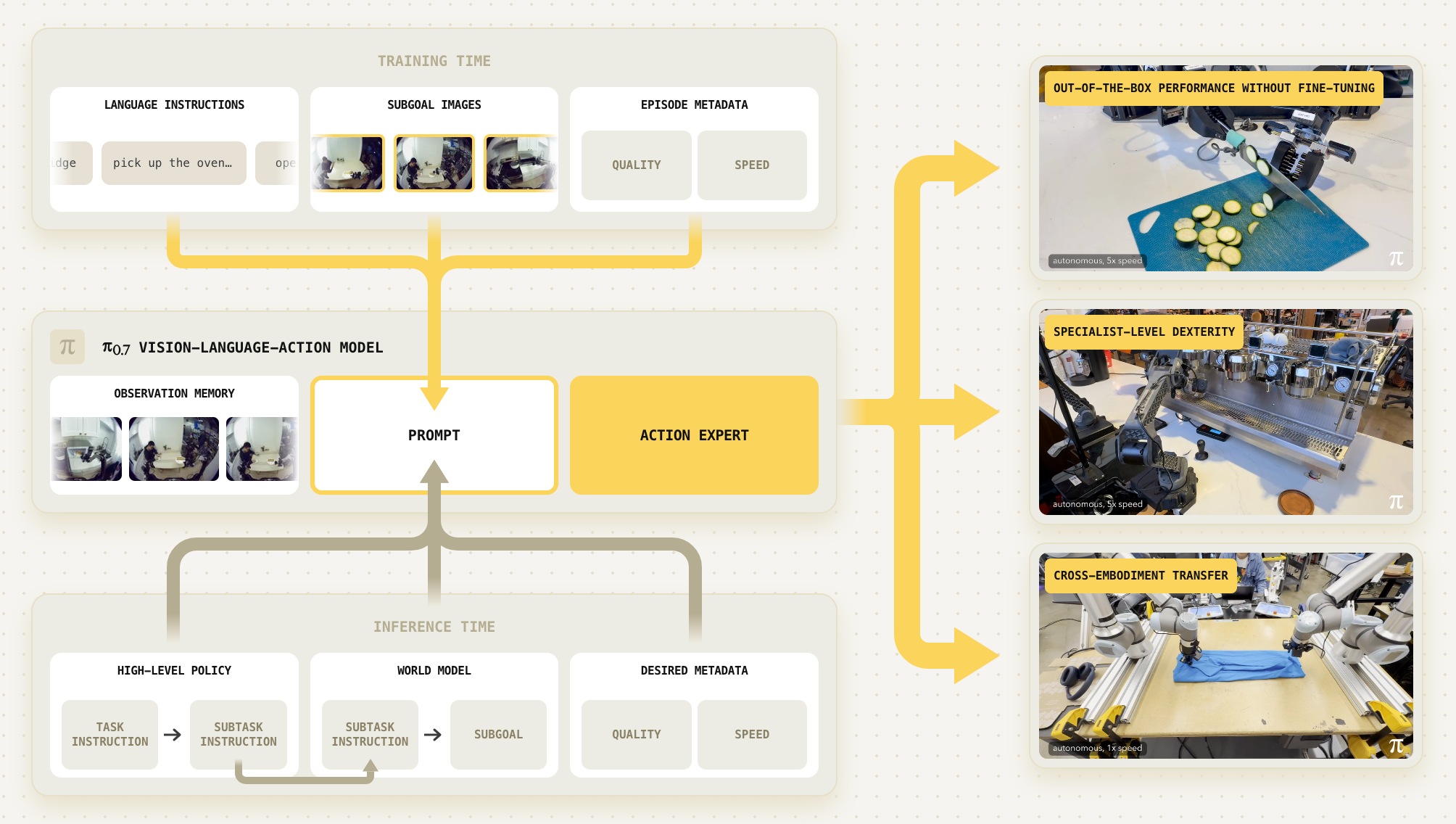
具体而言,它在组合泛化方面表现出强烈迹象------使其能够遵循多样的语言指令,在灵巧操作任务上取得可与更专门的微调模型相媲美的性能,甚至还能以新的方式组合这些行为
-
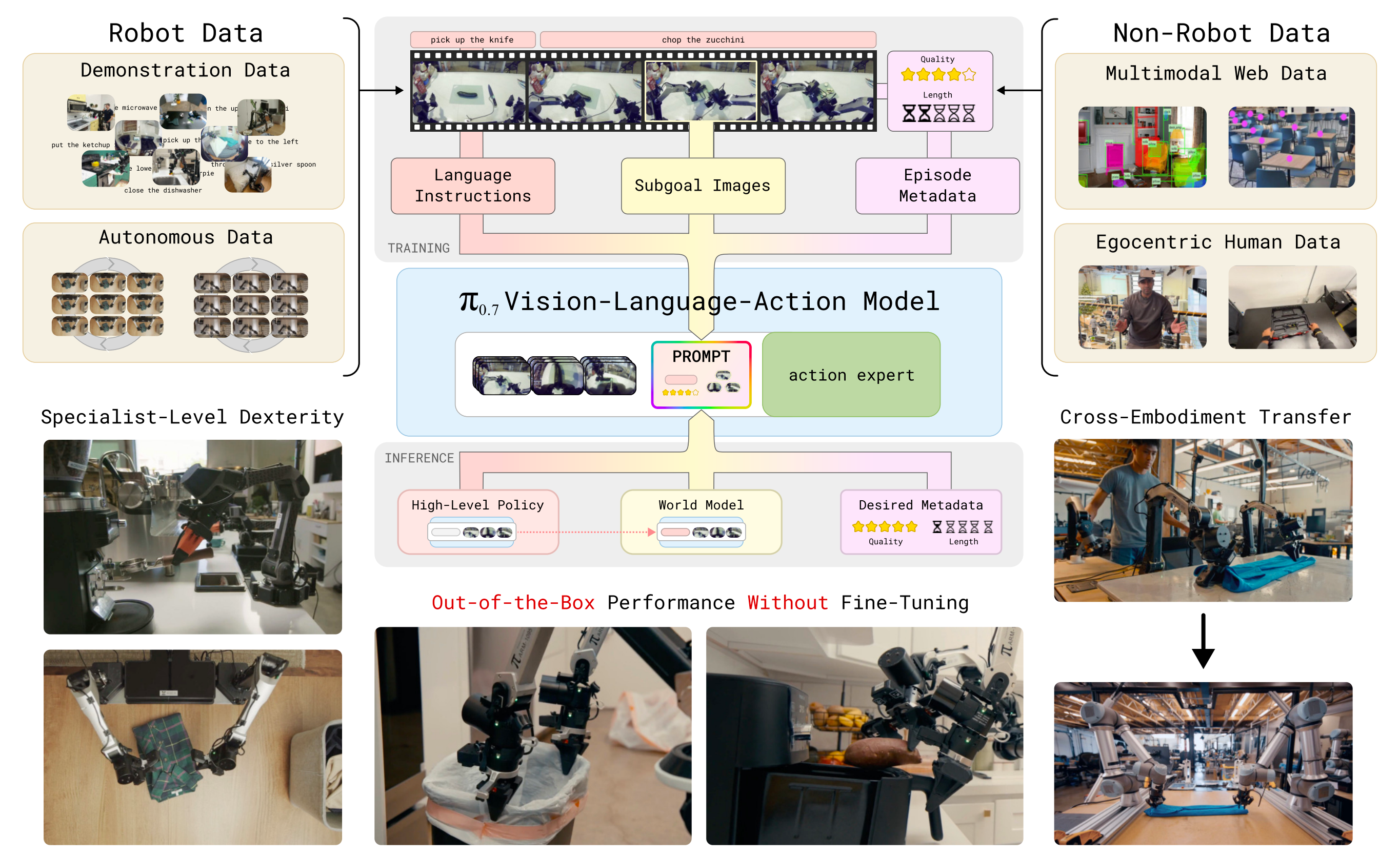
实现这一点依赖于利用大型且多样化的数据集,包括
来自许多使用不同策略的机器人的数据
-
然而,天真地使用这些数据并不会带来成功:在包含策略和任务表现都存在差异的大量多样示例的情况下,简单的训练过程会导致模型将数据集中不同模式平均在一起,从而产生次优结果
在训练π0.7 时,作者通过为数据添加详细的上下文标注来应对这一挑战
这些标注不仅包含关于做什么的信息,还包含关于如何做的信息,并通过多种多模态条件信号将这些知识提供给模型通过这种方式,每个episode 都教会机器人关于细致入微的概念和技能,使其不仅能够有效地执行训练任务,还能以新的方式进行组合来解决新任务
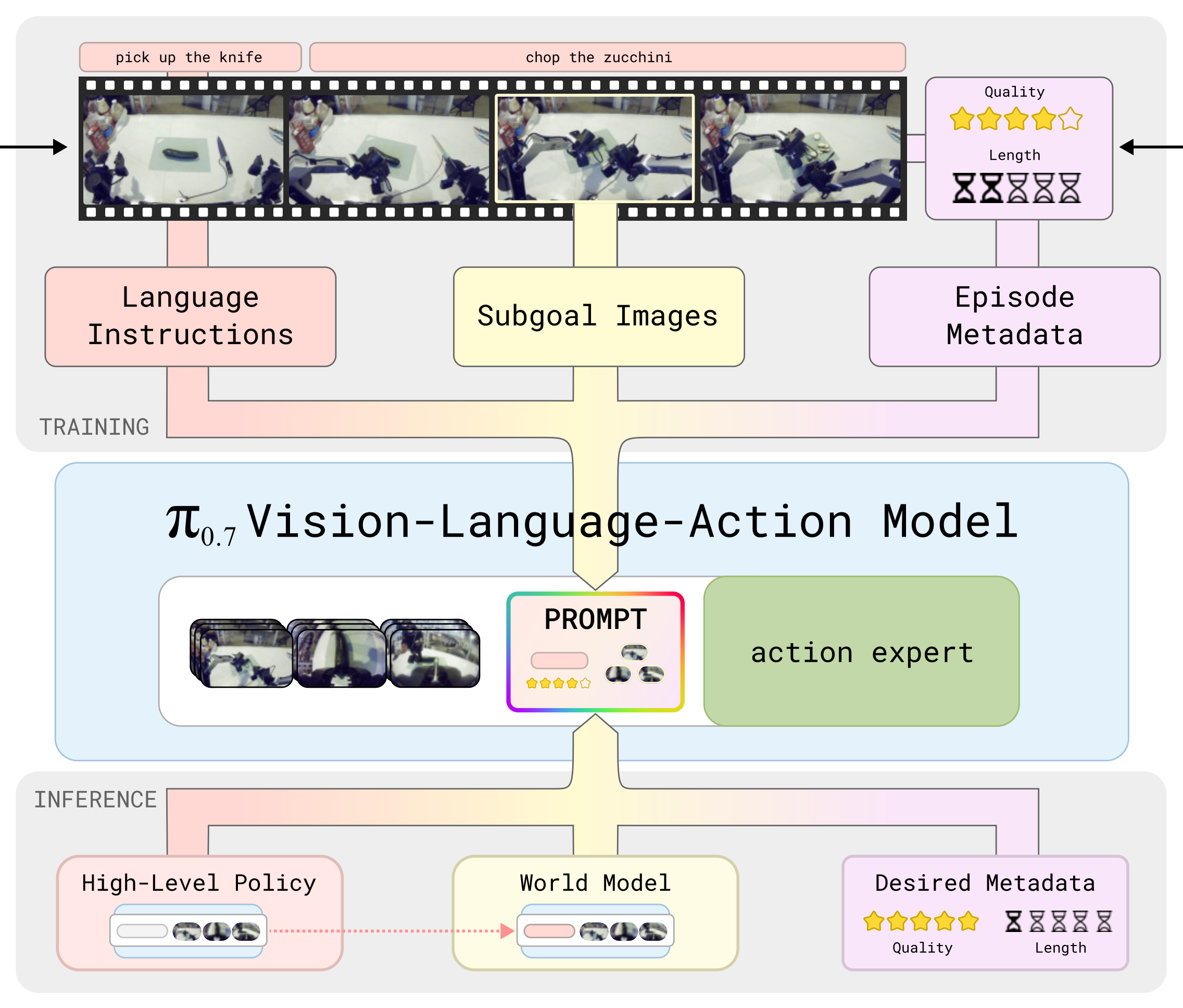
作者提出的prompt 结构包括详细的语言标签、策略元数据以及诸如子目标图像等多模态信息
作者宣称,这使得能够消除大型多样数据集中的歧义,从次优行为中学习而不损害性能,并在指令、形态结构和环境之间实现广泛的泛化
当然了,在其他领域中,已经有工作探索过这样一种思想:通过提供更详细的提示词或上下文,可以提升基础模型的性能。例如,图像与视频生成模型会利用提示扩展(prompt expansion)来生成高质量的内容
作者的方法与这类技术有许多相似之处。然而,在机器人领域,单纯用更详细的文字对数据进行描述并不足够------决定任务成功与熟练程度的细节可能更加微妙(例如关于整个 episode 质量的信息),或者根本难以仅用语言准确表达(例如干净折叠的 T 恤应有的具体外观)
因此,除了使用更详细的文本外,π0.7的模型还在提示中加入了多种额外的元数据,如图 1 所示
包括
关于 episode 质量的信息(策略元数据)
机器人所使用的控制模态
以及子目标图像其中一部分信息在测试时可以选择性提供或省略,但在训练阶段将其纳入模型,有助于模型更有效地组合其训练过的概念,并展现出多种涌现能力
1.1.2 相关工作
首先,对于通用型机器人操作策略
-
已有大量研究致力于开发通用型机器人策略
这些通用策略
有时从零开始训练1--6
1-RT-1
2-A generalist agent
3-Octo
4-Rdt-lb
5-Scaling proprioceptive-visual learning with heterogeneous pre-trained transformers
研究了如何利用异构的预训练 Transformer 来扩展和提升机器人的本体感觉与视觉学习能力
6-A careful examination of large behavior models for multitask dexterous manipulation
详见本博客中解读过的《LBM------大型行为模型助力波士顿人形Atlas完成多任务灵巧操作:CLIP编码图像与语义,之后DiT去噪扩散生成动作》但更常见的是使用预训练的视觉语言模型7--23
7-Rt-2、8-Open X、9-OpenVLA、10-π0、11-Tinyvla、12-3d-vla
13-Gemini robotics: Bringing ai into the physical world
14-π0.5、15-X-vla、16-星海图G0 VLA
17-Vision-language foundation models as effective robot imitators,研究并验证了视觉-语言基础模型可以作为非常高效的机器人模仿学习器
18-Cogact、19-Spatialvla、20-Gr00t n1
21-Robotic control via embodied chain-of-thought reasoning (2024) - 探索具身思维链推理以增强控制
22-Agibot world colosseo (2025) - 智元机器人推出的大规模操作仿真平台
23-Chatvla (2025) - 统一多模态对话与底层动作控制的框架或预训练的视频生成模型24--28进行初始化
24 Cosmos policy (2026) - 微调大规模视频生成模型用于视觉运动控制
25 mimic-video (2025) - 提出视频-动作模型,寻找超越传统 VLA 的泛化表征
26 World action models are zero-shot policies (2026) - 证明世界动作模型可作为零样本控制策略
27 Unleashing large-scale video generative pre-training for visual robot manipulation (2024) - 研究大规模视频预训练在机器人操作上的潜力
28 Gr-2 (2024) - 融合互联网规模知识的生成式视频-语言-动作模型 -
已有大量工作围绕VLA 的体系结构组件展开研究,例如
记忆模块 29--37
29 Tracevla (2024) - 通过视觉轨迹提示增强时空感知
30 Memer (2025) - 通过经验检索扩展机器人的记忆能力
31 Memoryvla (2025) - 为 VLA 模型引入感知-认知记忆模块
32 Onetwovla (2025) - 具备自适应推理能力的统一 VLA 架构
33 Sam2act (2025) - 结合 SAM2 视觉分割大模型与记忆架构
34 Cronusvla (2025) - 在隐空间中跨时间传递运动特征预测动作
35 Ta-vla (2025) - 阐明具备力矩感知能力的 VLA 设计空间
36 Contextvla (2025) - 提出一种高效均摊计算成本的多帧上下文架构
37 Mem: Multi-scale embodied memory (2026) - 提出多尺度具身记忆系统,即本文 π0.7 视觉编码器所套用的架构底座用于长时序规划的层级结构 13-Gemini robotics,14-π0.5,38--40
38 Do as i can, not as i say (SayCan) (2022) - 经典工作,将大语言模型指令与机器人实际物理可行性结合
39 Code as policies (2023) - 让大语言模型直接编写代码程序来执行具身控制
40 Hi robot (2025) - 具备开放式指令遵循能力的层次化 VLA 模型架构以及目标图像条件输入 41
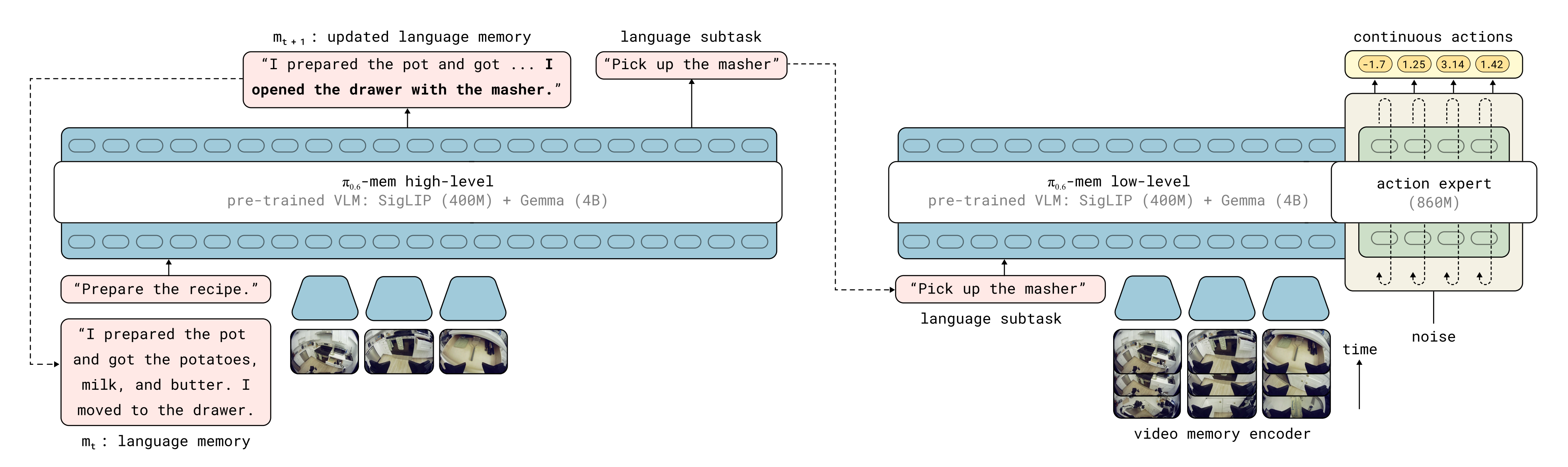
Cot-vla: Visual chain-of-thought reasoning for vision-language-action models,在 VLA 模型中引入视觉维度的思维链(Visual CoT)推理机制作者在π0.6-MEM架构*37-MEM,42-π0.6* 的基础上构建了一种同时融合这三类组件的VLA 模型
尽管通用策略通常是在机器人示范数据上进行训练,先前的研究已经表明,将
网页数据 7-Rt-2人类第一视角视频 25-*mimic-video*,43--49
43. Latent action pretraining from videos,研究了如何直接从互联网视频中进行隐式动作预训练,从而提取有用的运动表征
44. Physbrain: Human egocentric data as a bridge from vision language models to physical intelligence,提出将人类第一人称(Egocentric)视角数据作为连接视觉语言大模型与物理智能的桥梁
45. Emergence of human to robot transfer in vision-language-action models,分析了 VLA 模型中涌现出的将人类动作视频直接迁移到机器人控制上的能力
46. Latbot: Distilling universal latent actions for vision-language-action models,提出了一种为 VLA 模型提取并蒸馏通用隐式动作(Universal Latent Actions)的方法
47. Egovla
48. Being-h0.5: Scaling human-centric robot learning for cross-embodiment generalization,研究了通过扩大以人类为中心的学习数据规模,来实现更好的跨具身泛化
49. Clap: Contrastive latent action pretraining for learning vision-language-action models from human videos,提出了一种对比隐式动作预训练CLAP方法,以更有效地从人类视频中学习 VLA 模型以及
机器人自主采集的经验 50--52
50.
51. Rldg: Robotic generalist policy distillation via reinforcement learning,详见此文《知识蒸馏RLDG:先基于精密任务训练RL策略(HIL-SERL),得到的RL数据去微调OpenVLA,最终效果超越人类演示数据》
52. Self-improving vision-language-action models with data generation via residual rl,详见此文《PLD------自我改进的VLA:先通过离策略RL学习一个轻量级的残差动作策略,然后让该残差策略收集专家数据,最后蒸馏到VLA中》纳入预训练可以带来收益
故作者整合了以上所有数据源,并发现多样化数据与精细prompt 相结合,可以得到一种在组合式泛化方面表现出强烈迹象、且开箱即用性能优异的模型
其次,对于跨任务与跨形态的泛化
-
先前的大量工作致力于学习不仅能在不同环境、物体和背景间泛化,而且还能泛化到全新任务和全新机器人形态的机器人策略
通常,这类方法会利用人类视频数据
要么用于通用表征学习 53--58
53. R3m: A universal visual representation for robot manipulation,提出了 R3M,这是一种通过人类视频预训练获得的通用机器人操作视觉表征
54. Vip: Towards universal visual reward and representation via value-implicit pre-training,提出了 VIP,一种通过价值隐式预训练来获得通用视觉奖励信号和表征的方法
55. Masked visual pre-training for motor control,经典 MVP 工作,证明了掩码视觉预训练(Masked Visual Pre-training)对底层运动控制的巨大帮助
56. Robotic offline rl from internet videos via value-function pre-training,提出通过对互联网视频进行价值函数预训练,来辅助机器人的离线强化学习
57. Manipulator-independent representations for visual imitation,探索了如何学习一种与具体机械臂硬件无关的视觉模仿表征
58. Visual affordance prediction for guiding robot exploration,提出通过预测视觉环境中的可供性(Affordance)来高效引导机器人的探索过程要么通过人类动作进行直接监督 45,59--65
59. Dexterous manipulation policies from rgb human videos via 3d hand-object trajectory reconstruction,通过 3D 手-物交互轨迹重建技术,直接从人类 RGB 视频中提取灵巧操作策略
60. Videodex: Learning dexterity from internet videos,提出了 VideoDex,展示了如何从大量的互联网视频中直接学习机器人的灵巧操作能力
61. Zero-shot robot manipulation from passive human videos,提出了一种直接从被动(无标注)的人类视频中学习,以实现机器人零样本操作的框架
62. Human-to-robot imitation in the wild,研究了在非结构化的开放环境(in the wild)中,如何让机器人直接模仿人类的动作视频
63. Affordances from human videos as a versatile representation for robotics,从人类视频中提取"可供性(Affordances)"特征,将其作为机器人学习的一种通用表征
64. Egomimic : Scaling imitation learning via egocentric video,提出利用大量第一人称(Egocentric)视频数据来大幅扩展机器人模仿学习的规模
65. Learning adaptive dexterous grasping from single demonstrations,探讨了如何仅仅通过单次人类演示,就能让机器人学会自适应的灵巧抓取策略或者通过提取二维点轨迹 66--69
66. Track2act
67. Robotap: Tracking arbitrary points for few-shot visual imitation
68. Any-point trajectory modeling for policy learning,提出对视觉画面中的任意点轨迹进行建模,以帮助机器人学习控制策略
69. Rt-trajectory其他工作则试图在训练或推理过程中,直接利用互联网上预训练的基础模型来提升泛化能力70--76
70.Dall-e-bot: Introducing web-scale diffusion models to robotics
71. Cacti: A framework for scalable multi-task multi-scene visual imitation learning
72. Genaug: Retargeting behaviors to unseen situations via generative augmentation
73. Scaling robot learning with semantically imagined experience
74. Open-world object manipulation using pre-trained vision-language models
75. Palm-e: An embodied multimodal language model
76. Vima: General robot manipulation with multimodal prompts -
随着大规模跨形态机器人数据集的日益丰富 *77. Open X*
也出现了一系列专门研究显式提升机器人之间跨形态迁移的工作
78. Data analogies enable efficient cross-embodiment transfer
79. Scaling cross-embodied learning: One policy for manipulation, navigation, locomotion and aviation
80. Pushing the limits of cross-embodiment learning for manipulation and navigation
81. Lap: Language-action pre-training enables zero-shot cross-embodiment transfer
82. Enhancing generalization in vision-language-action models by preserving pretrained representations
83. Towards embodiment scaling laws in robot locomotion
84. Scaling cross-embodiment world models for dexterous manipulation与依赖已有数据集不同,一些研究提出了专用的手持设备,用于采集数据,以便之后能泛化到各种不同的机器人形态85,86
85. Universal manipulation interface: Inthe-wild robot teaching without in-the-wild robots,即UMI
86. Visual imitation made easy
在本工作中,作者发现,通过合适的提示设计,他们的模型能够充分利用多样化的机器人数据、人类数据以及互联网数据,从而在跨任务和跨形态方面实现强泛化能力
最后,对于用子目标图像提示机器人
-
相较于π0.6 −MEM
作者模型的一个核心架构组件是允许使用目标图像(包括生成的子目标图像)对模型进行提示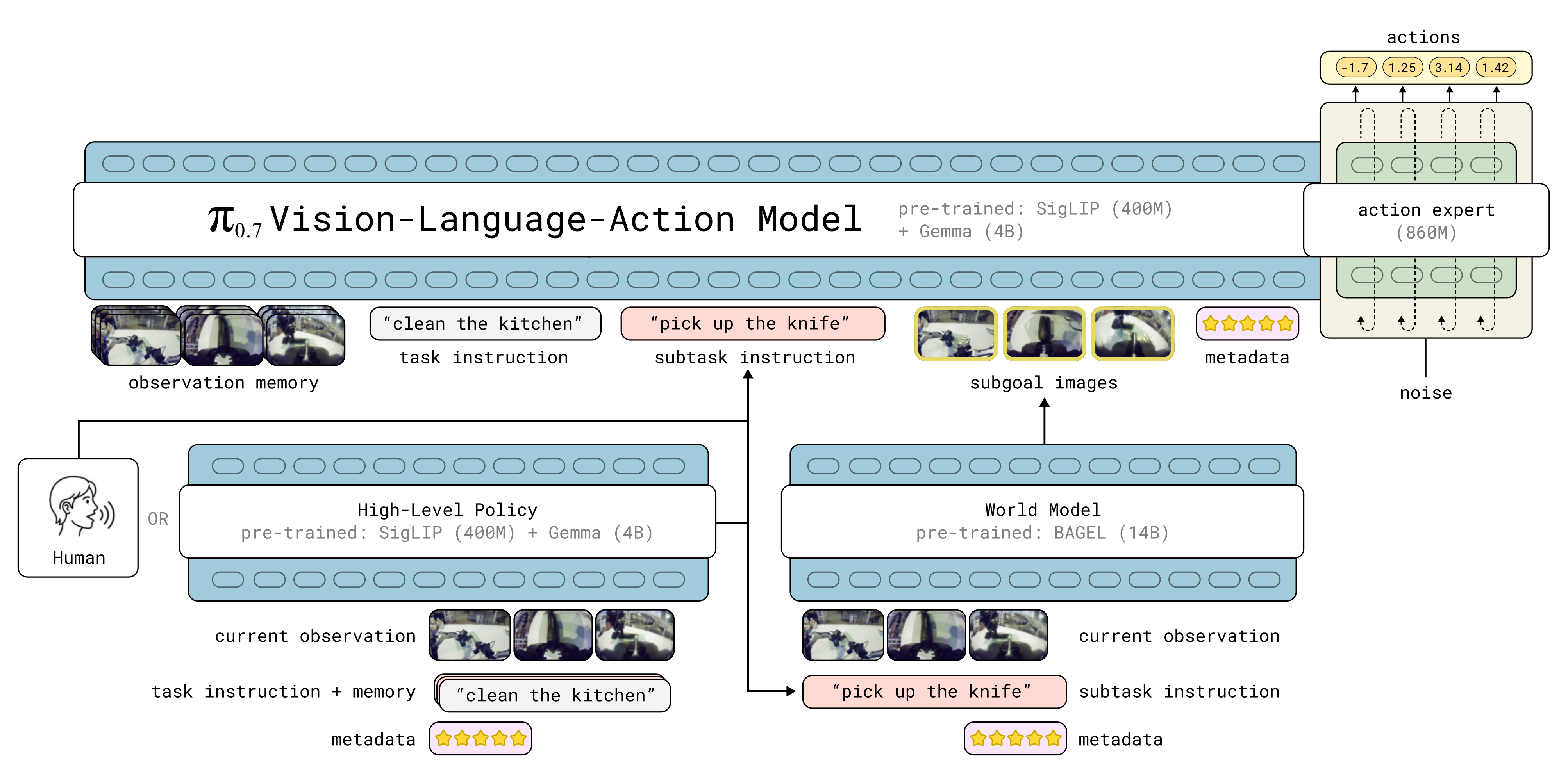
基于目标图像和视频对机器人操作策略进行条件建模已在大量工作中得到探索
这些工作中的一部分利用用户提供的图像87-90
87. Zero-shot visual imitation
88. Actionable models: Unsupervised offline reinforcement learning of robotic skills
89. Robocat: A self-improving foundation agent for robotic manipulation
90. Goal representations for instruction following:A semi-supervised language interface to control而另一些则将策略条件化在由一个独立模型生成的目标图像之上91-98
91. Visual reinforcement learning with imagined goals
92. Hierarchical foresight:Self-supervised learning of long-horizon tasks via visual subgoal generation
93. Zero-shot robotic manipulation with pretrained image-editing diffusion models
94. Learning to act from actionless videos through dense correspondences
95. Uniskill:Imitating human videos via cross-embodiment skill representations
96. Dreamitate: Real-world visuomotor policy learning via video generation
97. Foreact: Steering your vla with efficient visual foresight planning
98. Video language planning或者采用类似chain-of-thought 的方式*41-Cot-vla*
-
另一种做法是将图像和视频生成集成到策略训练目标中
24-Cosmos policy
25-mimic-video
26-World action models are zero-shot policies
99-Video generators are robot policies
100-Fast-wam: Do world action models need test-time future imagination?
101-Learning universal policies via textguided video generation
以改进策略表征并产生更具泛化性的动作作者认为他们的贡献是对这些工作的补充:他们的目标并非提出一种新的架构或模型设计,而是提出一种方法论,使VLA 能够利用更加多样的数据来源,并辅以实证分析来表明这一点会带来强有力的组合泛化迹象
作者宣称,据他们所知,他们的实证结果远远超出了先前工作中所报告的定量改进,展示了诸如叠衣服等灵巧技能在不同机器人上的零样本迁移,以及对新奇物体交互(例如操作空气炸锅)的泛化能力
1.1.3 基于流的VLA模型
VLAs 通过从一个预训练的VLM骨干网络开始,并对其进行适配以用于机器人控制来进行训练。训练数据集 包含机器人轨迹,即观测序列
和动作
- 观测
- 而动作
具体而言
-
VLA 通常被训练为预测一个动作片段,对应于未来动作的一个短轨迹
动作片段可以由一个" 动作专家" 生成,这是一个较小的transformer,它关注VLM 主干,并在运行时实现快速推理,动作专家通常使用flow matching *102-Flow matching for generative modeling*(或扩散)目标来刻画机器人动作的多模态性
-
为了学习有效的表征
π0.7也使用knowledge insulation(KI) 训练策略*103-Knowledge insulating vision-language-action models:Train fast, run fast, generalize better*
VLM 主干由FAST tokens *104-FAST: Efficient action tokenization for vision-language-action models* 进行监督同时虽然动作专家可以关注VLM 主干中的所有激活,但来自动作专家的梯度不会回传到VLM 主干,从而使VLM 通过相对稳定的离散交叉熵损失进行训练
-
除了观察和动作之外,VLA 的每个训练样本还附带一个提示或上下文,作者用
通常这对应于一个语言指令
在设计π0.7 时,作者探究了为每个训练样本的上下文添加附加信息如何能够实现从多样且异质的数据集(包括次优行为和失败)中学习
正如下文将展示的,用这些数据进行训练会得到一个具有更强鲁棒性和灵巧性的模型,并使得模型能够更广泛地泛化。VLA πθ 的训练目标对应于一个近似对数似然,其形式为
- 注意,流匹配(flow matching)动作专家优化的是一个近似的下界,而不是一个具有封闭形式的对数似然10-*π0*
- 数据集
然而,如前所述,作者使用的是一个更广泛的数据集,其中包括失败的回合和次优的自主 rollout ,以及其他数据来源,例如以自我视角采集的人类第一视角视频数据
下文将展示,使用足够细致且信息丰富的上下文 ,可以将这些多样化的数据纳入训练中,而且或许出人意料的是,这甚至会带来更好的策略性能和泛化能力
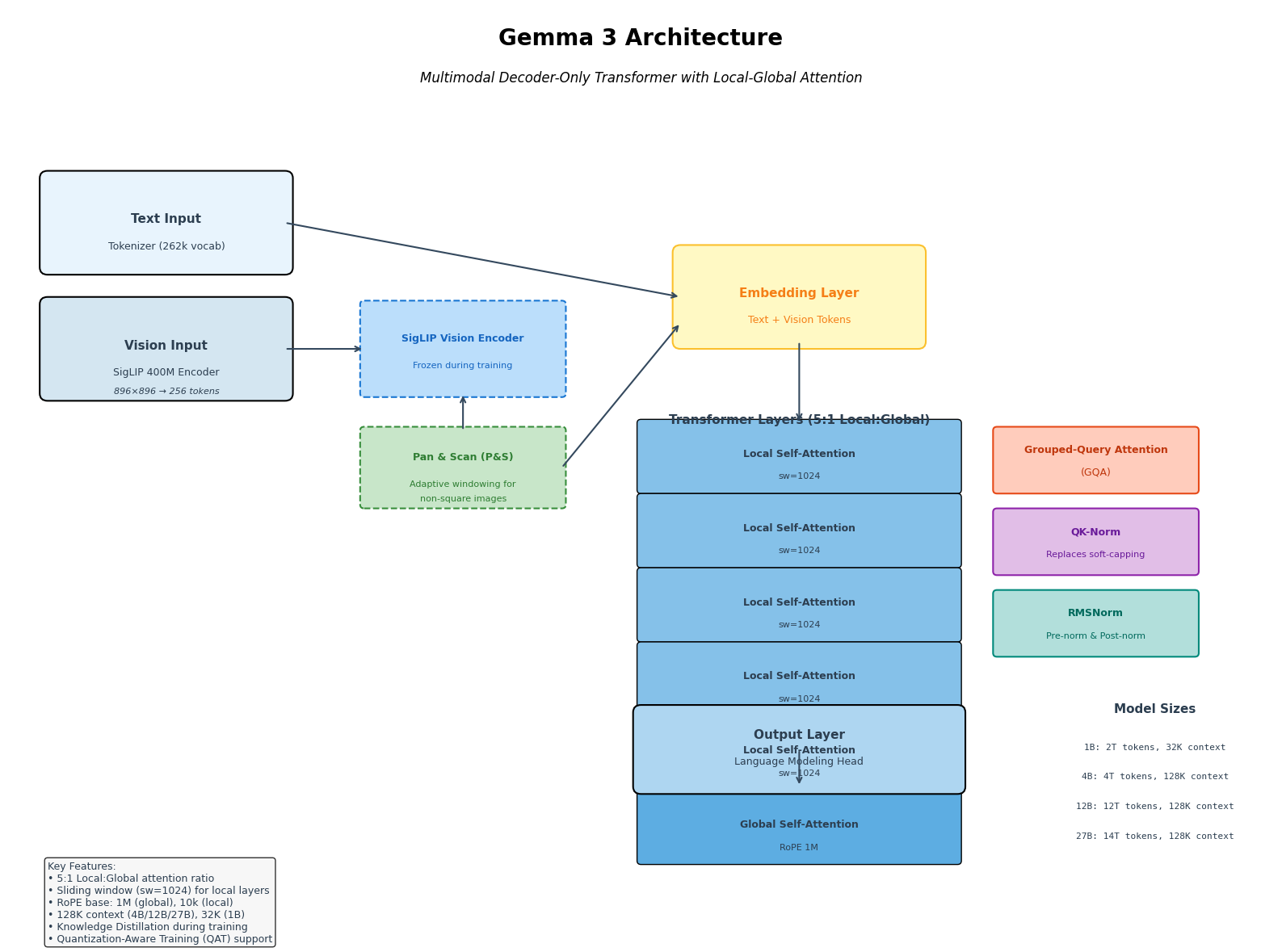
1.2 π0.7的模型架构
1.2.1 π0.7 与 π0.6、π0.5的对比:新增高级策略模块和世界模型模块
π0.7 在现有的 π0.6 VLA架构 *42-π0.6* 和 MEM 记忆系统 *37-MEM* 的基础上构建,并将其扩展为具备多模态上下文条件能力
模型架构的概览如图 2 所示
π0.7 模型是一个拥有 50亿参数的 VLA,由
一个 40 亿参数的 VLM 主干 ++gemma 4B++ 106
Gemma 3 采用Decoder-only Transformer 架构,是gemma系列中首次发布4B的版本
其核心创新是5:1 交错局部-全局注意力层**(局部层滑动窗口1024、RoPE基频10k,全局层RoPE基频1M以支持128K长上下文),++搭配冻结的SigLIP 400M视觉编码器++和Pan & Scan自适应窗口实现多模态理解,并通过GQA、QK-Norm和RMSNorm优化效率与稳定性一个 MEM 风格的视频历史编码器: SigLIP (400M) + MEM
为什么论文的作者在图 2 中非要啰嗦地写成 pre-trained: SigLIP (400M) + Gemma (4B),而不是直接写个 Gemma3 呢?*原因在于他们对这个"全家桶"进行了"魔改":如果只是看静态单张图片,直接用原生的 Gemma3 全家桶就够了
但是,**π0.7 需要看连续的动态视频(多帧历史)。原生 Gemma3 里的 SigLIP 处理不了这么庞大的视频流。所以,PI相当于把 Gemma3 这个全家桶"拆开"**了故虽然视觉编码器还是从gemma3初始化,但作者把里面的 SigLIP 模块单独拎出来,在它外面套上了一层 MEM(时空压缩架构),让它具备了把视频压缩成摘要的能力,即*
压缩完之后,再把这些摘要送进全家桶剩下的那个 Gemma 语言大脑 里去处理以及一个 8.6 亿参数的动作专家++action expert 860M++组成
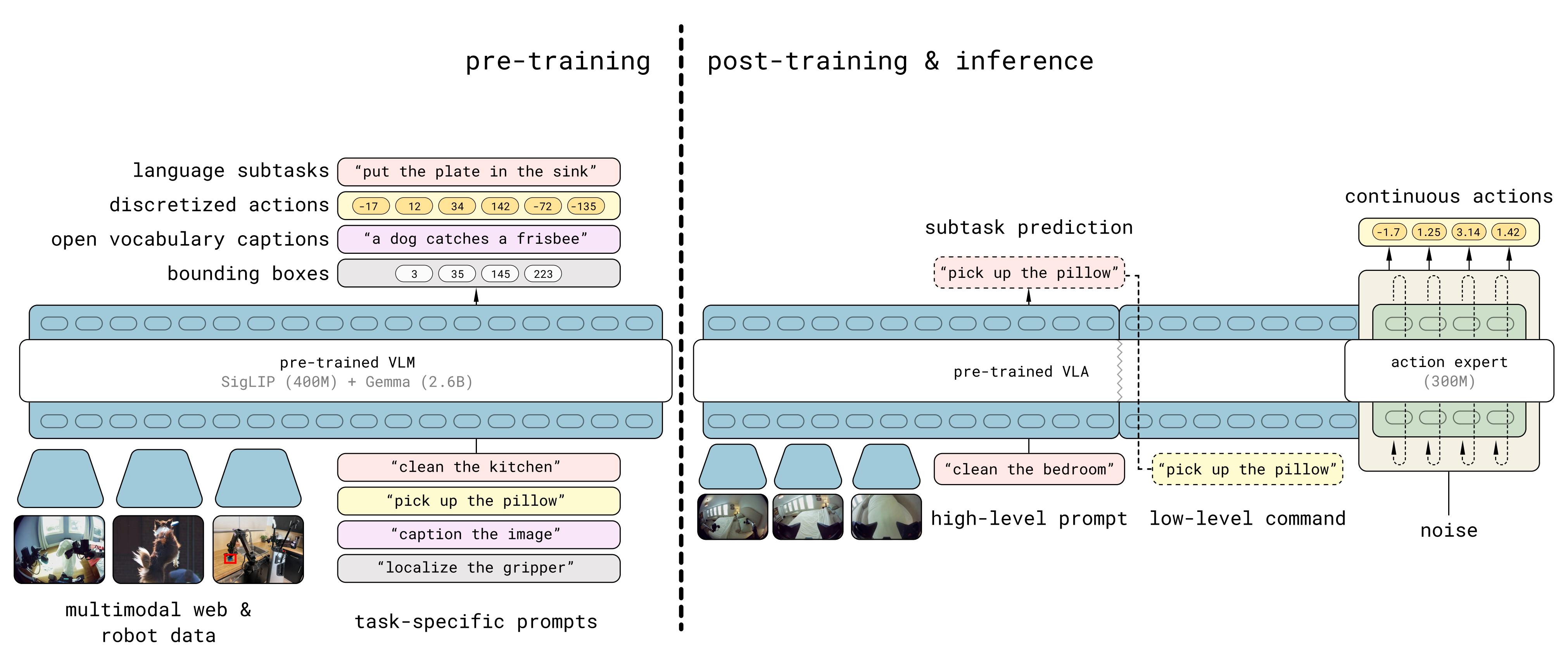
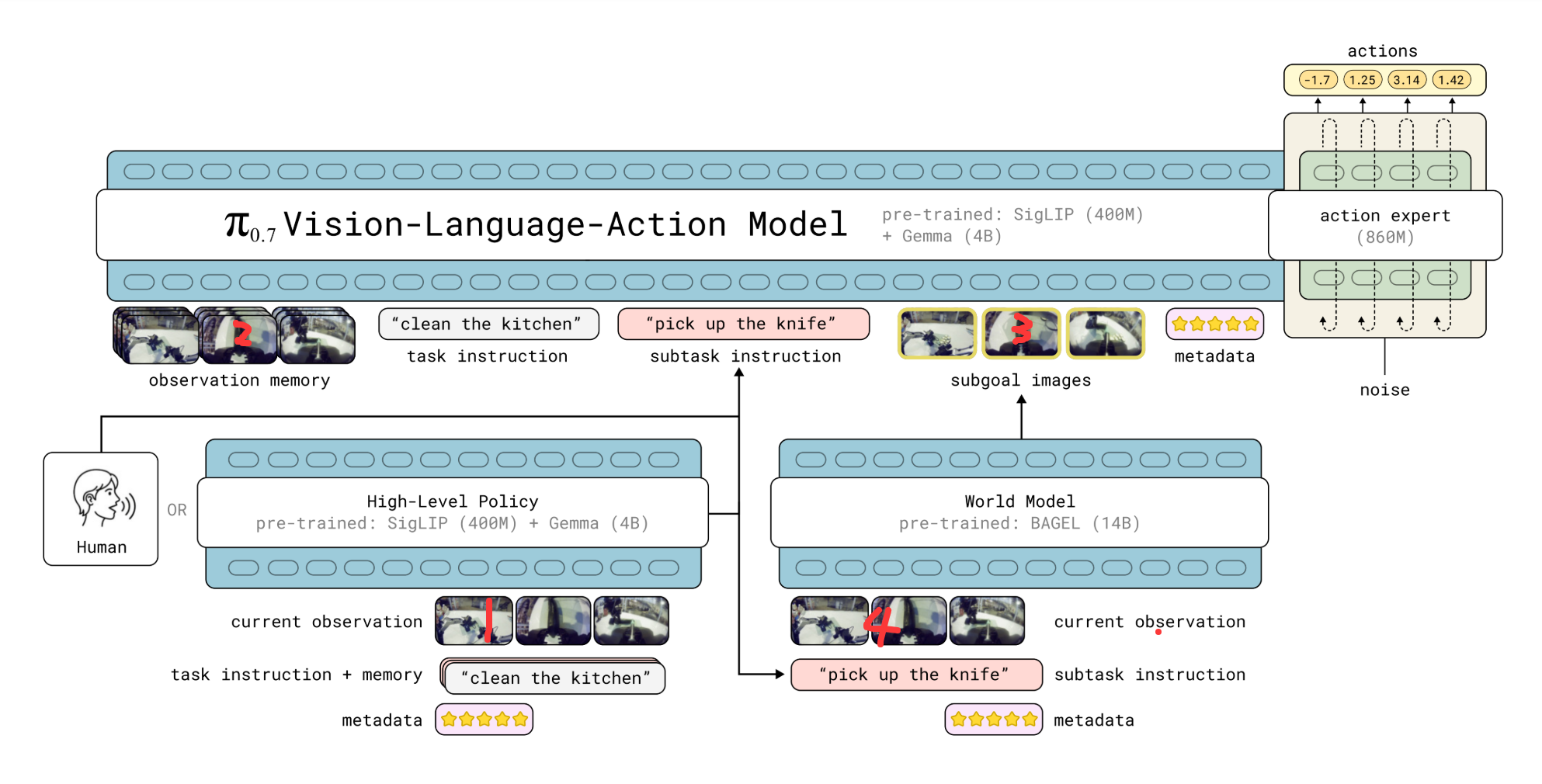
该模型的上下文包含多种不同模态,包括语言指令subtask instruction***、******子目标图像subgoal images、*描述数据质量和策略的任务元数据metadata等多模态输入
在运行时
语言指令**由一个基于相同架构的高层语义策略生成,如下图左侧所示
------------
可能看到上文的视觉编码器,便会有同学疑问:"那π0.7 没有像MEM那样,去弄凭文本记忆系统记进度了么,只弄了视觉编码器 编码短期视觉记忆么 "
相当于流程如下1*) 整合输入:它接收
i )总的目标(task instruction,比如"打扫厨房")
ii )回顾自己之前下发过的指令历史(memory,即进度)
iii)并结合当前的实时画面(current observation)*2*) 生成下一步:经过思考后,它向右侧输出一个全新的当前子任务指令(subtask instruction,图中例子是 "pick up the knife" 拿起刀)*
而子目标图像则由一个基于 BAGEL 图像生成模型 105 的轻量级世界模型生成
再进一步补充说明下,与先前的
-
π0.5------详见此文《π0.5------推理加强的统一模型:先高层预训练离散化token自回归预测子任务、后低层执行子任务(实时去噪生成连续动作)》
-
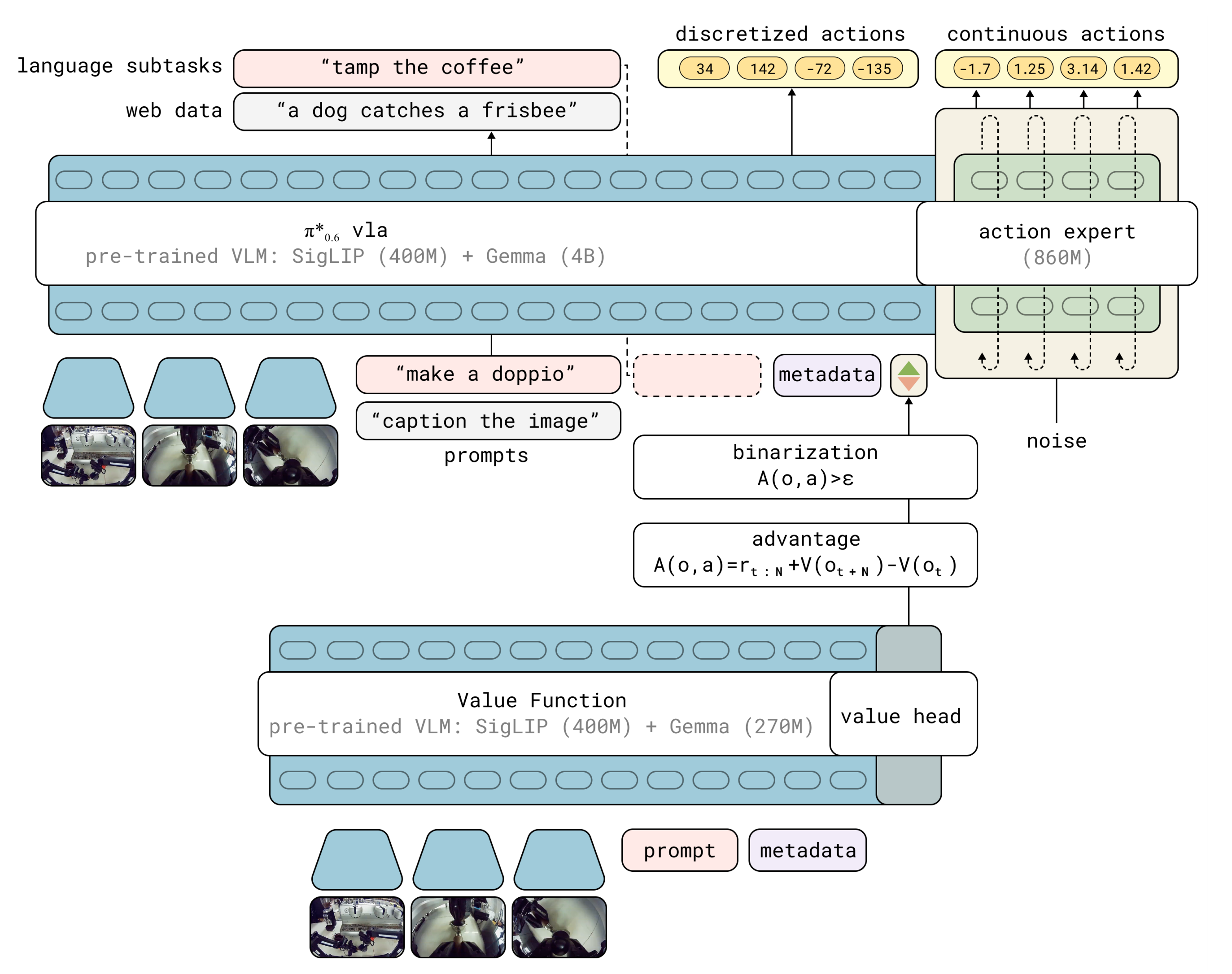
π0.6 模型相比------详见此文《π∗0.6------通过RL框架RECAP微调流式VLA π0.6:先基于示教数据做离线RL预训练,再SFT,最后在线RL后训练(与环境自主交互,从经验数据中学习,且必要时人工干预)》
π0.7 模型的主要结构修改包括
-
采用了 MEM ** *37-详见此文《[MEM------解决VLA长时记忆问题的框架:短时靠高效视频编码抓细节,长线凭文本记忆系统记进度](https://blog.csdn.net/v_JULY_v/article/details/160059758 "MEM——解决VLA长时记忆问题的框架:短时靠高效视频编码抓细节,长线凭文本记忆系统记进度")》* ** 中
的历史视觉编码器( 对应于上图右下角的video memory encoder,以及下图**)**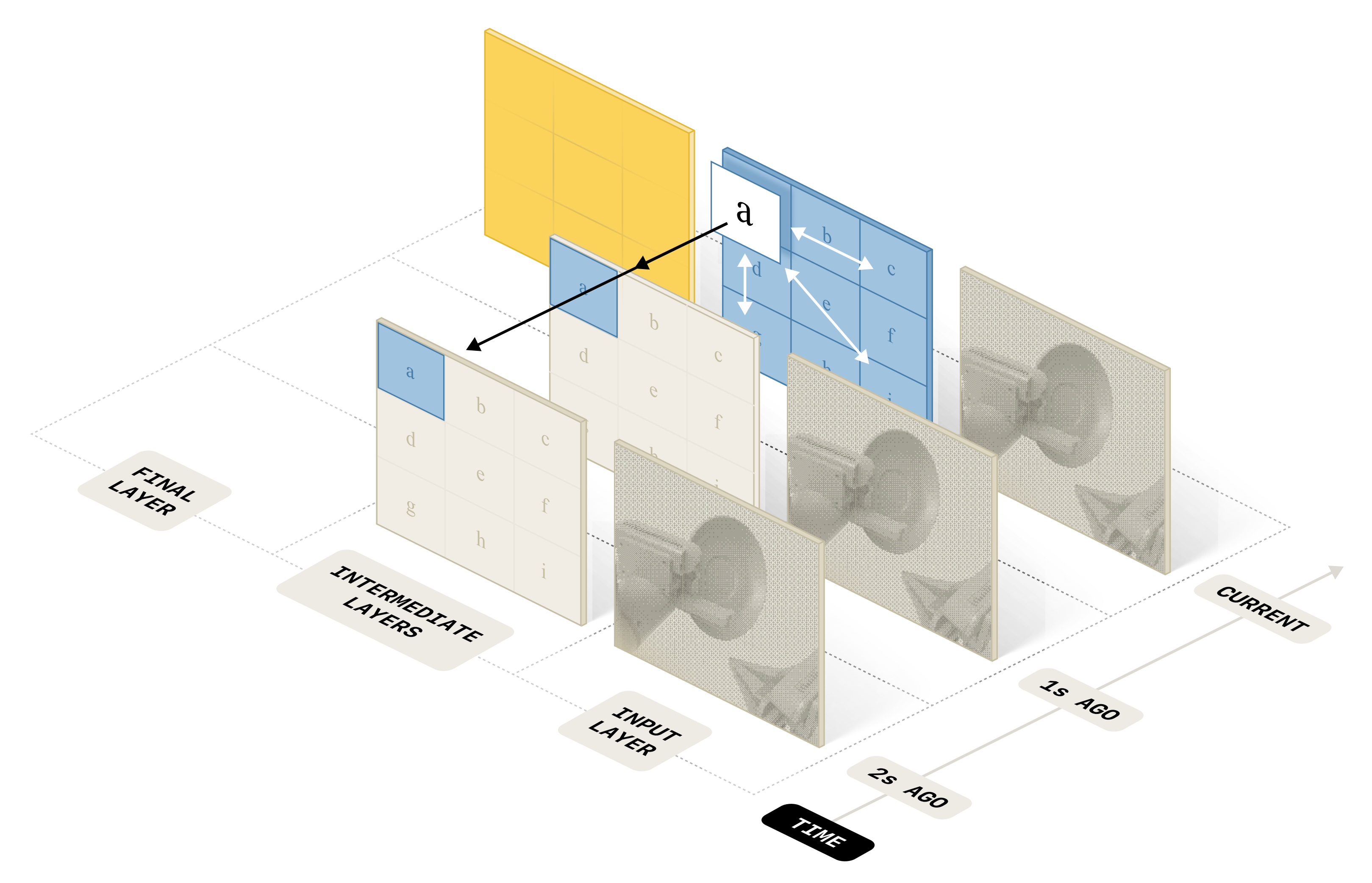
------------
如上文说过的,视觉编码器同样从Gemma3初始化
并遵循 MEM 视频历史编码器 37 的设计
对历史观测同时进行时间和空间压缩,并且无论历史帧的数量多少,都输出固定数量的 token -
以及在上下文中使用视觉子目标图像 ,如下图右下角所示
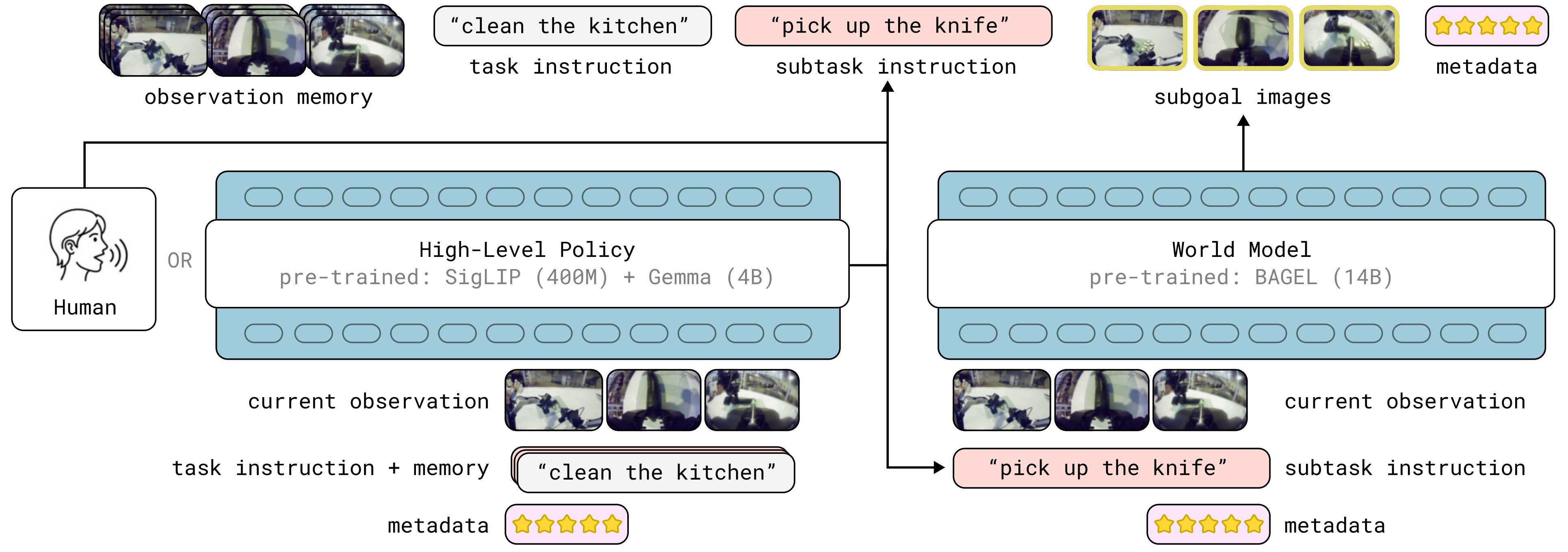
有点值得强调的是
上图π0.7中,用到视觉编码的 总共有三个地方,但每个地方的用途 并不一样
- Observation Memory / 历史记忆
图例:好几层叠在一起
输入:过去 6 秒的视频流
机制:火力全开!同时使用空间提取 + MEM 时间压缩- Current Observation / 高层策略的当前观察
图例:单层不叠加
输入:此时此刻的三张照片
机制:降频工作。只提取空间特征(SigLIP 基础功能),看一眼现状方便下达文字指令- Subgoal Images / 子目标图像
图例:单层不叠加
输入:未来某一刻的三张预测照片
机制:降频工作。只提取空间特征(SigLIP 基础功能),作为动作比对的视觉靶子
1.2.2 π0.7对视觉输入的处理:4路相机(每路相机均包含六帧历史帧)和三张子目标图像
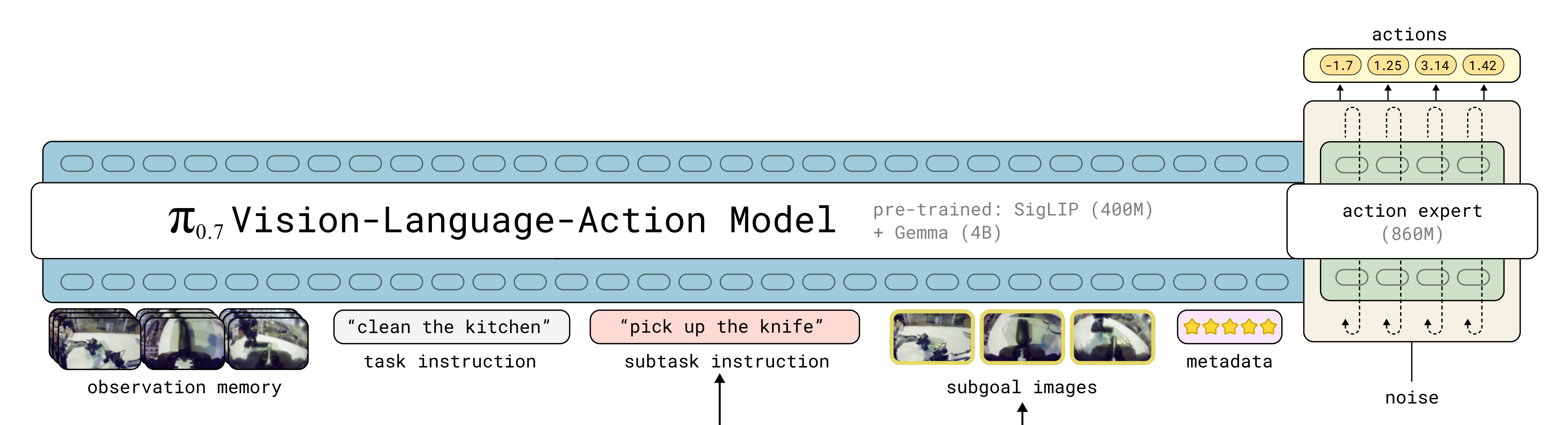
模型的(视觉)输入最多包含四路相机图像(前视图、两个腕部视图,以及可选的后视图)------ 每一路图像最多包含六帧历史帧 相当于observation memory*,以及最多三张子目标图像(不包括后视图) 相当于subgoal images***
-
历史帧通过视觉编码器处理
并被压缩到与单帧相同数量的token
------------
可以观察到输入的多个历史画面最终在左上角的"FINAL LAYER"中,被汇聚成了一个金黄色的单层网格。这完美契合了该编码器最核心的特性:它能够"对历史观察应用时间和空间压缩,并且对于任意数量的历史帧,都能输出固定数量的 token(outputting a fixed number of tokens for any number of history frames)" -
子目标图像也通过同一编码器处理
相机观测与子目标图像都首先被调整为 448x448 像素
- 对于历史帧的采样,使用 1 秒的步长,并以 0.3 的概率将全部历史帧整体丢弃
当存在后视图图像时,该后视图也以 0.3 的概率被丢弃- 且作者采用块因果掩码方案,使得观测tokens 和子目标图像tokens 在各自内部使用双向注意力,而目标图像tokens还可以额外关注观测
- 后续的文本tokens 使用因果注意力(参见附录中的注意力掩码可视化)
作者在图 19 中描述了用于训练 π0.7 和轻量级世界模型(用于子目标图像生成)的注意力模式,以及使用它们进行推理时的注意力模式
π0.7 模型及其世界模型(用于生成子目标图像)在训练和推理过程中使用了多种不同且非平凡的注意力模式
++在没有图像目标的情况下++,作者使用与 π0.5 相同的注意力模式,即对所有具备记忆感知的图像视图的嵌入之间施加全局双向注意力*
注意,FAST token(只在训练时可用)与 flow 动作彼此之间没有注意连接*
++当存在图像目标时++**,作者在文本提示之后,将它们作为一个额外的块因果、块内双向的注意力块加入序列中
++当进行无分类器引导++**(classifier-free guidance,发生在推理阶段)时,作者将正例和负例打包到同一序列中,以构造一个带有两个分支(正分支与负分支)的"注意力树",从而实现高效推理,这两个分支彼此之间互不关注遵循 BAGEL 的设计
++在训练阶段++世界模型会接收图像的三个拷贝(相当于如果有三个视角,则三个视角的三张图片,每张图片都有三种表示),每个拷贝在多视角组内是块内双向注意:
该图片的当前观测,用 ViT编码;
该图片的当前观测,用 VAE 编码;
该图片带噪声的图像目标,用 VAE 编码
++世界模型在推理时++也使用类似的 CFG 技巧,但其掩码更为复杂,因为它具有三个 CFG 组而不是两个顺带补充说明下
*ViT :负责进行语义理解(看懂画面里是桌子、刀还是机械臂)
VAE:负责提取细粒度的图像特征(因为世界模型的最终任务是"画"出未来的图像,所以它必须极其精准地捕捉像素级的细节)
VAE 的最终训练目标是学会"画"出机器人执行动作后的未来画面。它使用的是标准流匹配(Flow Matching)损失来预测目标图像 。*它的"标准答案(Ground Truth)"是提取自训练数据中,某个动作语义片段结束那一刻的真实视频帧(即
本点,在下文的《1.3.2 子目标图像》中还会进一步阐述
------------
进一步而言,对于世界模型的三个相机输入
每个相机下 拍摄到的当前观测,复制三份,一份vit编码、一份vae编码,一份是**带噪声的目标图片反正带噪声的目标图片是Ground Truth 得由世界模型输出,所以带噪声的目标图片,在时空上 也只是一帧而已
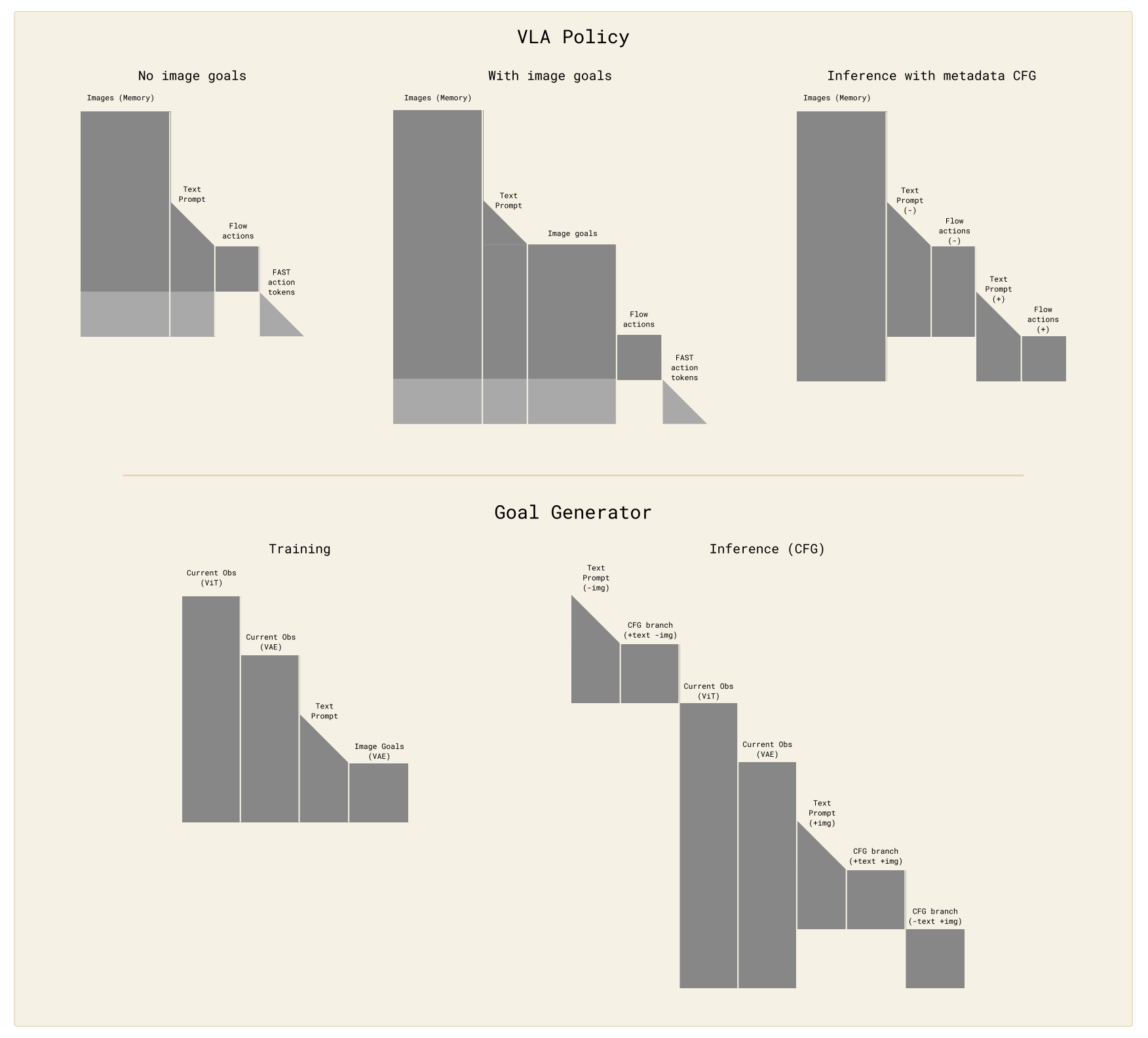
- 作者还将机器人的本体状态
不同于使用离散化文本tokens 来表示
更轻量级的"动作专家"是一个拥有 860M 参数的变压器,它经过训练能够使用流匹配目标来预测连续动作
- 作者使用自适应 RMSNorm 来注入用于流匹配的时间步信息。动作专家(action expert)所处理的动作 token 数目固定为 50,对应一个包含 50 个步骤的动作块(action chunk)。这 50 个 token 彼此之间采用双向注意(bidirectional attention),并且还可以注意到VLM 主干网络(backbone)的激活
- π0.7 还在训练阶段采用了实时动作分块(real-time actionchunking, RTC)107,108 的训练时版本,以在存在推理延迟的情况下生成平滑的动作轨迹
训练过程中,作者模拟0 到 12 个时间步的延迟,这对应于在 50Hz 机器人上最多240ms 的推理时延
总之
- 之前的模型 π0、π0.5 和 π0.6 将任务的简短文本描述作为上下文
在训练 π0.7 时,作者扩展了上下文,以包含更多信息和模态:更具表达力的语言指令、episode 元数据以及子目标图像,从而能够在多样化且可能次优的数据上进行训练接下来,将描述由π0.7 使用的上下文
1.3 π0.7的4层prompt:子任务指令、子任务图像、Episode Metadata、控制模式
1.3.1 子任务说明
参考π0.514,除了包含整体文本任务描述 (例如,"清理厨房")之外,作者在提示中还加入了能够刻画下一个语义子任务的中间、高层文本------作者用
表示这段中间文本(例如,"打开冰箱门")
-
在推理阶段,*
在语义子任务上对模型进行条件化也使得能够一步步地以口头方式指导模型
由于模型被训练为遵循多样的语言指令,它可以在一个新任务中遵循人类的实时指令,例如,将一个红薯放入空气炸锅中(图14) -
在指导完成后,可以将这些口头指导数据用于微调π0.7,使其成为一个高层策略,将机器人观测 current observation、任务描述 ask instruction、过去子任务指令的历史 memory映射到新的子任务指令上subtask instruction(图2 左下)
即如上文1.2.1节开头所述的流程
1*) 整合输入:它接收总的目标(task instruction,比如"打扫厨房"),回顾自己之前下发过的指令历史(memory,即进度),并结合当前的实时画面(current observation)*
2*) 生成下一步:经过思考后,它向右侧输出一个全新的当前子任务指令(subtask instruction,图中例子是 "pick up the knife" 拿起刀)*
这个高层策略随后引导机器人完全自主地执行该任务
1.3.2 子目标图像
尽管子任务指令在传达任务的高层意图方面是有效的,但它们可能缺乏对实际执行至关重要的细节------例如,"打开冰箱门"并未具体说明机械臂应如何抓住把手
-
子目标图像通过描绘场景在不久的将来期望达到的状态来解决这一问题,以图像的形式提供更丰富的说明,展示任务成功推进后世界应有的样子
故作者考虑多视角子目标
-
在运行时,子目标图像由一个轻量级的世界模型生成 ,该模型接收与主模型相同的子任务指令
相对于语言指令,基于机器人当前观测生成的、扎根于当前观测的子目标图像往往可以更清晰地消除策略目标的歧义,从而在语言遵循和泛化上取得改进作者将该世界模型记作
其中
片段末尾的图像帧作为真实的子目标,即
遵循SuSIE 93,作者的世界模型使用具有web 规模预训练的现成图像生成与编辑模型进行初始化。且从BAGEL105 进行初始化,这是一个14B 混合Transformer 模型,能够进行图像理解、编辑和生成
通过在该的世界模型训练中加入web 数据、如第一人称人类视频等非机器人数据源以及其他视频数据,可以从这些其他数据源中获取语义和物理概念,然后通过子目标图像将它们迁移到π0.7 中。实现细节见附录C
世界模型以 BAGEL 105 为初始化基础,并在很大程度上沿用了相同的训练方案
作者使用了机器人数据和第一人称人类视频数据中的一个子集
这些数据都配有高质量的分段语言标注,因为作者发现标注质量(尤其是时间分段质量)对子目标质量有很大影响
且作者还额外混入了若干开源图像编辑数据集和开源视频数据集,以更好地保留模型的语义知识每个训练样本都由一个子任务指令
其中遵循BAGEL
相机输入 同时使用ViT(用于语义理解)和VAE(用于细粒度图像细节)进行处理
ViT token进一步由一个7B LLM 骨干网络处理
VAE token则由一个7B 生成骨干网络处理ViT 输入被调整为分辨率448 × 336
而VAE 输入(包括目标图像 )被调整为分辨率512 × 384
这种差异是由于ViT 和VAE 不同的patch 大小(分别为14 和16)导致的。在测试时,作者设置∆= 4 秒作为重新生成子目标的时间间隔,以与SuSIE 93 保持一致
------------------------
此外*,总结一下关于世界模型输入输出的分辨率*
图像类别 使用的编码器 / 模块 分辨率 (宽 × 高) 物理意义与核心作用 1. 当前观测 ViT 448 × 336 抓语义:帮助模型看懂画面里"有什么"(如:这是桌子、刀、机械臂) 2. 当前观测 VAE 512 × 384 抓细节:提取当前画面极高精度的底层像素特征(如:刀刃的精确朝向) 3. 带噪声的目标图像 VAE 512 × 384 定目标:作为生成过程的"带噪底板",模型需通过它还原出未来的细节 4. 输出的子目标图像 世界模型 (原生解码) 512 × 384 出结果:世界模型最终"画"出的、干净清晰的未来单帧快照预测 注意,最后一行中,虽然世界模型原生输出的第4类图像是 512 × 384,但当这张图要被送去给 π0.7 主模型看的时候,如上文《1.2.2 π0.7对视觉输入的处理:4路相机(每路相机均包含六帧历史帧)和三张子目标图像》所述,系统会用代码强制把它 Resize(缩放)为**
最后*,再总结一下,如下图4个地方的图片*
标记 1、2、3:
标记 4:同时包含448 × 336(ViT) 和 512 × 384 (VAE) 两种分辨率
1.3.3 Episode metadata:速度、质量、是否犯错
在扩大提供给模型的上下文时,一个关键目标是能够在更广泛且更加多样化的轨迹数据集上进行训练
- 而与只使用高质量示范数据不同,π0.7 利用了较低质量的示范数据(包括失败案例),甚至还利用了来自以往模型的自主收集数据
- 由于作者仍然希望 π0.7 在测试时尽可能好地完成任务,因此需要为这些多样化的轨迹适当地标注有关任务是如何执行的信息,以便模型能够正确地对其进行情境化
为此,作者还在上下文中加入多种"回合元数据"信息,用于描述给定训练回合的一些属性。用 m 表示元数据的集合,它可以包含多种标签,包括
- 整体速度:以时间步(timesteps)衡量的整个 episode 的长度
作者以 500 步为区间对取值进行离散化,例如,1750 到 2250 之间的数值被归入"2000 步"这一档。通常,更快的速度也对应更高的质量,例如,该 episode 中出现的错误更少 - 整体质量:任务执行质量,以 1 到 5 之间的分数表示,5 表示最高质量
- 错误:用于指示机器人在给定的动作片段中是否犯错的标签(例如,未能抓取物体或执行了错误的子任务)。这些标签由人工对数据进行粗粒度标注而得
因此,π0.7 模型使用真实的片段速度(ground-truth episode speed),以及关于片段质量和错误区段的人工标注,在一个多样化的数据混合上进行训练
这种数据多样性(例如,不同速度的片段)为模型提供了必要的信号,使其能够学习将这些元数据与目标动作相关联。在运行时,可以通过元数据提示来指示模型以高速、高质量且无错误地执行任务
1.3.4 控制模式:指定使用关节级控制还是末端执行器控制
作者还考虑在低层动作执行中使用不同的控制模式
- 具体来说,作者在训练过程中同时包含关节级和末端执行器动作,并使用文本标识符
- 然后在运行时,可以根据任务选择控制模式
将所有上下文信息综合在一起,下述示例展示了一个可能提供给模型的提示词
<Multi-view observation>
<Multi-view subgoals>
Task: peel vegetables.
Subtask: pick up thepeeler.
Speed: 8000.
Quality: 5.
Mistake:false.
Control Mode: joint.<Proprioception>
在训练过程中,作者随机丢弃提示的每个部分,这为π0.7在测试时使用提示组件的任意子集提供了灵活性(例如,带有或不带子目标图像地运行)
-
首先,作者发现当给定子目标图像时,模型训练速度显著更快**------动作预测任务本质上变成了在当前帧和未来帧之间推断机器人动作的"逆动力学" 问题
因此,作者只在训练中将视觉子目标图像添加到每个批次中25 % 的样本中
-
在带有子目标图像的样本中,作者还以
-
对于episode 元数据 ,作者则在15 % 的情况下完全丢弃它,另外,每个组件(整体速度、整体质量和错误标签)各自以5 % 的概率被单独丢弃
另,不对上文所述的"1.2.4 控制模式"使用dropout
1.4 π0.7 模型与训练配方
下面将讨论如何通过在多样化数据上训练,将不同的上下文融入 π0.7 模型中,并介绍模型架构、训练以及推理的具体细节
1.4.1 训练数据集
π0.7 的训练数据集由
- 涵盖广泛任务的大量示范数据构成
这些任务包含许多不同的机器人平台 (包括静态和移动式、单臂或双臂),以及多样化的环境(内部实验室式和家庭式环境,以及真实家庭环境) - 还包括来自
- 以及来自网络的辅助非机器人数据源,包括物体定位与属性预测、视觉问答和纯文本预测
- 此外,作者还包含视频-语言任务,包括对内部机器人数据和来自网络的视频进行描述
此外,与经典的VLA 训练流程有显著不同,作者在训练中大量使用次优的机器人数据。这包括
-
质量较低的演示(失败的轨迹或包含大量错误的成功轨迹)
将轨迹的元数据纳入上下文,使得模型可以有效利用所有这些评估数据,并且正如将在下文Sec. IX-A------A. 在具有挑战性的任务上的开箱即用性能 中看到的那样,使其能够达到与那些通过RL 在单个任务上专门优化以获得高性能的模型相近的表现
这对应于一种" 蒸馏" 过程,其中通用的π0.7 模型可以继承通过RL 训练得到的专家模型的能力 -
以及在模型评估实验中由先前版本的模型收集的数据
对于后者,次优数据还扩展了给定任务中可能出现的状态和场景的多样性,从而带来更强的鲁棒性,使得模型在高度灵巧的任务中,甚至有时可以超过经过RL 训练的,或更普遍地说,经过单任务后训练的策略
例如,我们使用π∗0.6模型在RL 训练过程中收集的数据作为额外示例,从而有效地使π0.7 能够蒸馏其行为
1.4.2 使用子目标图像进行训练
在训练π0.7 以处理子目标图像时,作者需要模型能够适应具有不同延迟和不同图像质量水平的目标,包括由世界模型生成的图像,这需要在训练时仔细选择哪些子目标作为上下文提供给模型
作者在真实图像和生成图像的组合上进行训练,其中
- 真实图像来自训练轨迹中未来时间步的图像,且发现以下采样方案在选择真实图像的时间步时是有效的:
- 除了这些真实图像之外,作者还通过从世界模型中采样大量子目标图像,并使用这些生成图像替代真实的未来图像,将其加入到π0.7 的上下文中来构造额外的训练样本,从而缓解真实图像和生成图像之间的训练-测试不匹配问题
1.5 在运行时对 π0.7 进行提示及机器人系统细节
1.5.1 在运行时对 π0.7 进行提示:含对"算法1"的逐行解释说明
在运行时,作者将π0.7 配置为在不进行任何特定任务后训练的情况下,根据期望的行为以不同形式的上下文运行
如下图所示『π0.7 在提示中使用多种模态的上下文,包括:子任务指令、子目标图像以及回合元数据。作者在训练模型时对每个组件使用dropout,然后在推理时灵活组合不同模态进行提示。例如,当使用 UR5e 双臂机械臂折叠衬衫时,作者采用子目标图像与元数据进行提示』

-
对于任何任务,作者始终使用控制模式
和episode 元数据来提示模型 -
对于episode 元数据的选择,作者遵循
总体速度:针对每个任务设置为该任务中情节长度的第15th 百分位
总体质量:始终设置为5,即最高分
错误:始终设置为false,表示没有错误 -
子任务指令
当使用子目标图像时
作者在语义意图发生变化时(即出现新的
或自上次生成子目标图像后经过∆= 4 秒时
二者先到者触发,更新子目标图像
完整流程见Algorithm 1

别忘了上面定义过的:
除了观察和动作之外,VLA 的每个训练样本还附带一个提示或上下文,作者用
作者将该世界模型记作
考虑再三,为方便大家更好的理解,我还是再把上述15行伪代码 逐行解释说明下
一、 初始化阶段(Lines 1 - 5)
机器人在启动执行任务前,需要把所有的"上下文线索"准备好,并做出第一次动作预测
Line 1: Input: ... 准备基础输入
获取系统当前的初始观察画面Line 2: Initialize subtask
确定第一步小目标。 调用高层策略(High-level policy)或者接收人类实时的语音指导,将大任务拆解,生成当前的子任务指令Line 3:
世界模型"想象"画面。 将当前画面、子任务和元数据喂给世界模型Line 4:
组装多模态提示词(Prompt)。 把前面所有的信息(总指令、子指令、目标图、元数据、控制模式)打包,组合成一个完整的上下文大礼包Line 5:
首次动作推理。 主 VLA 模型
右侧备注可选 CFG(无分类器引导),用于强化模型对元数据(如高质量操作)的服从度二、 实时控制主循环(Lines 6 - 15)
这是机器人高频运行的控制环。由于大模型的推理非常耗时(动辄上百毫秒),这里巧妙地使用了异步(Async)机制,保证机器人动作不卡顿
Line 6: for t = 0, 1, 2, ... do
系统时间戳开始高频推进
Lines 7-10: 异步刷新"目标画面"(低频更新)
if
触发条件有两个:
如果条件满足,就去请求世界模型生成新图像
关键点在于右侧的标注:这是一个非阻塞的异步操作,意味着请求发出去后,主循环继续跑,不会等图像生成好才动,避免机器人定住不动获取新图像后,更新上下文集合
Lines 11-13: 异步预测"动作块"(中频更新)
if
右侧标注了 RTC(Real-Time Action Chunking),这是一种专门处理推理延迟的技术,能确保在上一个动作块还没执行完时,下一个动作块已经平滑地接上了Line 14: Execute a_t
底层高频执行。 在每个极短的时间步对于研发具身智能落地来说,这个算法展示了一个非常成熟的三层运行架构:
- 最高频:Execute
- 中频:VLA 预测动作块(Action Chunking),几百毫秒刷新一次,且采用异步 RTC 隐藏推理延迟
- 低频:生成子任务

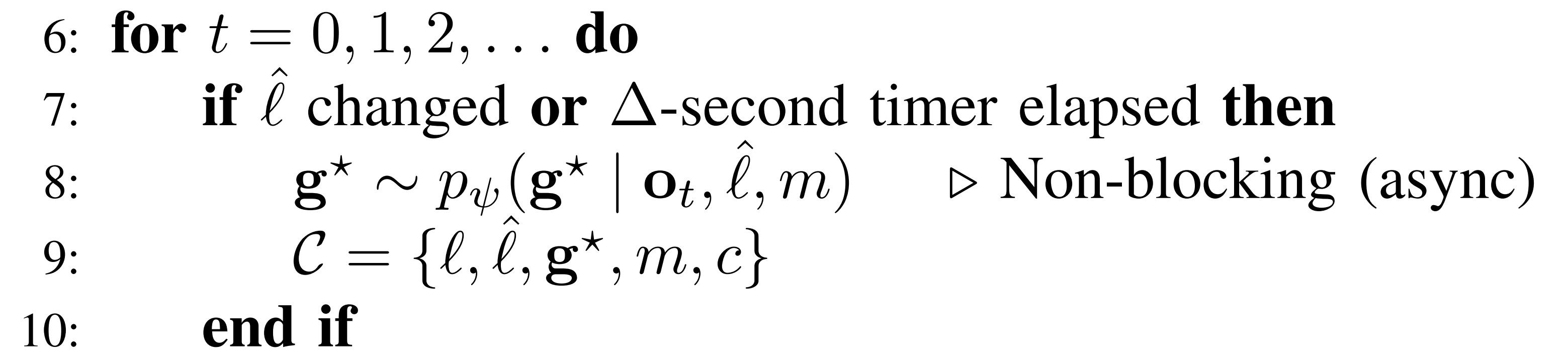
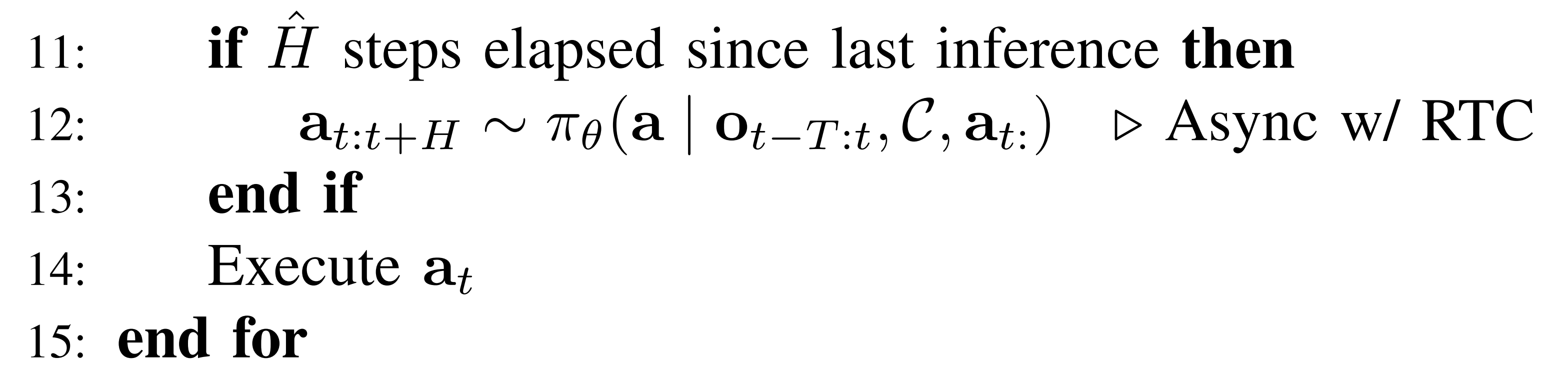
总之,作者采用异步推理:视觉子目标和子任务指令的生成在单独的线程中进行,而VLA 推理始终使用最新可用的结果
- 对于所有实验,作者使用5 个去噪步骤来生成50 步的动作块,并从该动作块中执行
- 由于每个提示组件都是通过dropout 进行训练的,因此 π0.7 也可以与无分类器引导(CFG)109 结合使用,用于提示的任何部分,例如引导生成的动作朝向更高的速度
具体来说,每一步动作去噪过程如下
其中表示在" 无条件" 模式中使用的上下文集合,
是CFG 权重。虽然上下文的任意部分都可以被丢弃,但作者将CFG 应用于情节元数据,以在灵巧任务中激发出强大的性能
且使用适中的取值
1.5.2 机器人系统细节
作者将π0.7 部署在多种机器人平台上(图4)
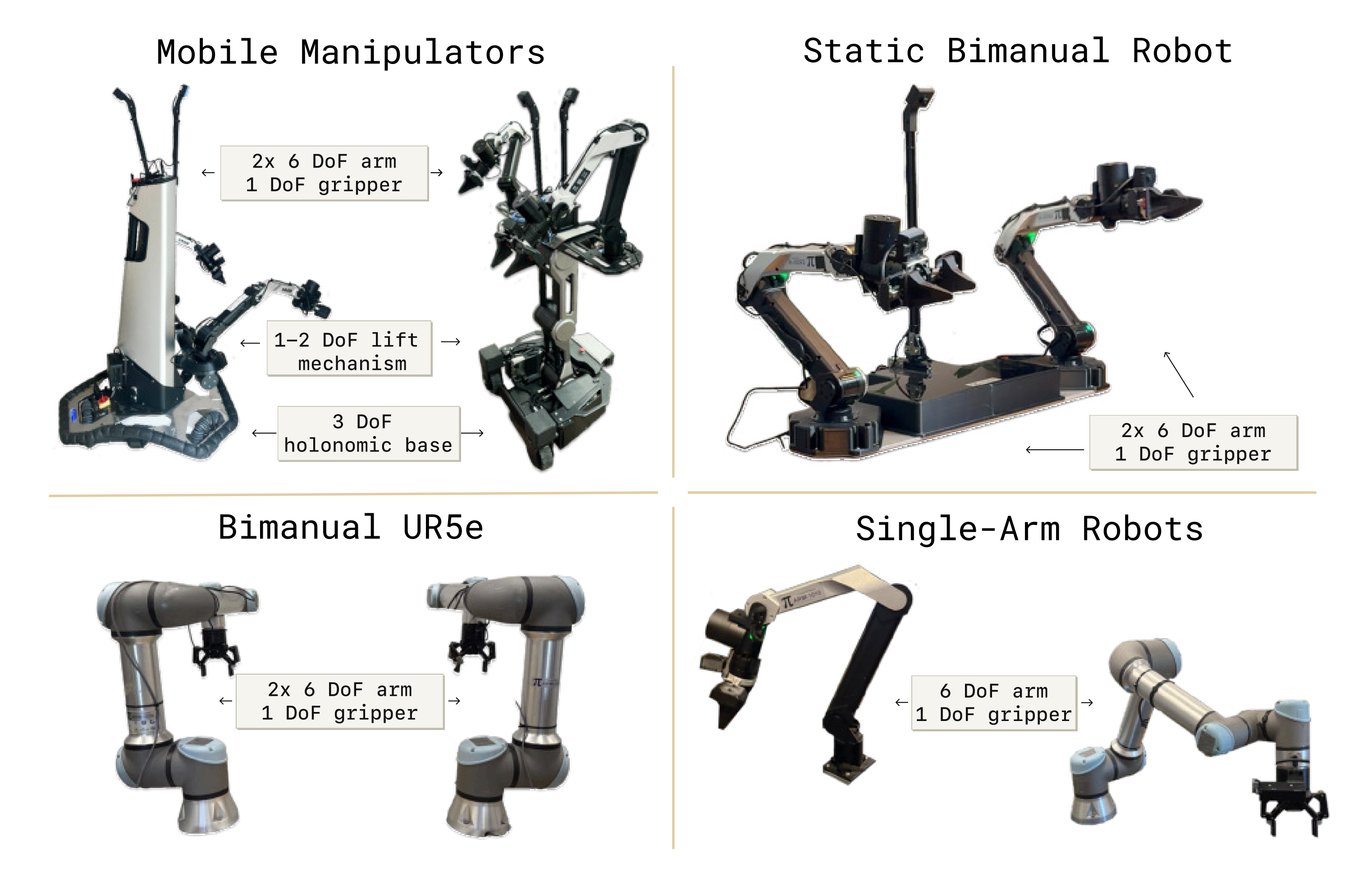
如上图所示,从左到右、从上到下,逐一包括
- 配备两条6DoF机械臂的双臂移动操作机器人
- 配备轻量级6 DoF 机械臂的静态双臂操作(static bimanual manipulators)系统("BiPi")
- 以及配备Robotiq 夹爪的双臂UR5e 系统
-
额外的泛化和语言跟随实验使用单臂6 自由度系统------即使用与BiPi 平台相同的机械臂
且在实践中,由于机械臂的形状、其在桌面上的位置(在两侧而不是在一侧边缘),以及夹爪和手指的形状,UR5e 机械臂需要采用不同的操作策略,这使得向该平台进行跨形体迁移成为一个巨大的挑战
注意,虽然大部分数据是使用与BiPi 平台相似的机械臂收集的,但作者用于跨形体测试的UR5e 机械臂要长得多,具有不同的形态结构,并且重得多
此外
- 所有操作器都使用平行夹爪
UR5e 机器人以20 Hz 运行,而所有其他机器人以50 Hz 运行 - 每个机器人都有一个前向摄像头以及安装在每个机械臂上的腕部摄像头,移动机器人还配有一个后向摄像头
π0.7 模型的动作输出通过一个简单的PD 控制器施加到每个机器人上。为了控制末端执行器的运动,作者应用数值逆运动学将目标末端执行器位姿转换为目标关节位置
第二部分 实验评估
在作者的实验中,他们评估π0.7 在多大程度上可以利用多样的数据来源,以在开箱即用性能、广泛泛化能力以及更有效迁移方面表现出色,并利用多种上下文模态
具体而言,作者研究π0.7 在多大程度上能够开箱即用地执行复杂且灵巧的任务,特别是
- 与更加专业的、经过RL 微调的模型进行比较(Sec. IX-A)
- 评估其灵活遵循指令来执行多种不同任务的能力(Sec. IX-B)
- 研究其在不同实体间的迁移能力(Sec, IX-C)
- 并测试其将技能以先前未见的方式组合以完成新任务的能力(Sec. IX-D)
- 最后,进行受控实验,以研究在他们的机器人数据集中任务和上下文多样性增加时,π0.7 的性能如何变化(Sec. IX-E)
2.1 在具有挑战性的任务上的开箱即用性能
作者宣称,π0.7 在无需任务特定后训练的情况下在灵巧任务上取得了高性能
- 在作者的第一组实验中,他们研究π0.7 在训练数据中已经出现过的灵巧任务上能够掌握到何种程度,但此时的目标是尽可能稳健且高效地完成这些任务
- 对于以往的机器人基础模型来说,这出乎意料地困难:通常表现最好的策略是针对特定下游任务进行微调的,即使它们使用的是通用型的预训练42, 50
作者希望回答的问题是:通用的π0.7 模型能否在各种灵巧操作任务上匹配任务特定微调模型的性能?
- 作者使用如图6 所示的任务。这些包括他们此前用于评估RL 训练的π∗0.6 模型50 的制作浓缩咖啡、搭建盒子和折叠衣物任务,在这些任务中,作者可以直接比较单一通用的π0.7 模型与各个RL 微调专家π∗0.6 模型在速度和鲁棒性方面的差异
- 且作者还研究了许多其他灵巧操作任务,包括作者先前" 机器人奥运会" 实验中的一些任务(制作花生酱三明治、将衬衫翻到里面朝外以及驾驶通过一扇门)
以及一些额外的灵巧任务,例如将一根西葫芦完全切片、去皮几种水果和蔬菜(西葫芦、黄瓜和胡萝卜),以及一个涉及更换垃圾桶中垃圾袋的长时程任务
2.1.1 "开箱即用"上的性能对比:π0.7 PK π0.6 RL Specialist、π0.6 SFT Specialist
作者发现
- π0.7在本论文所考虑的所有任务上,开箱即用地就能取得与π∗0.6 版本50 中使用的RL 专家相当的性能(图6,第一行)
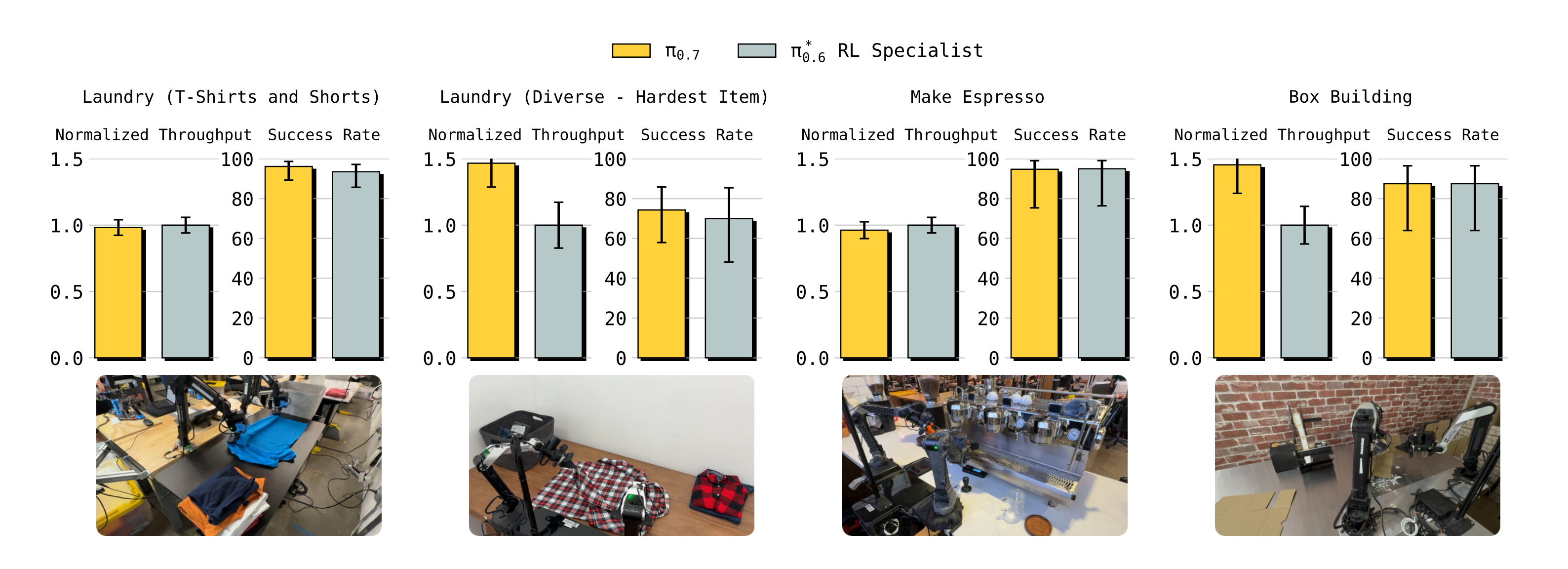
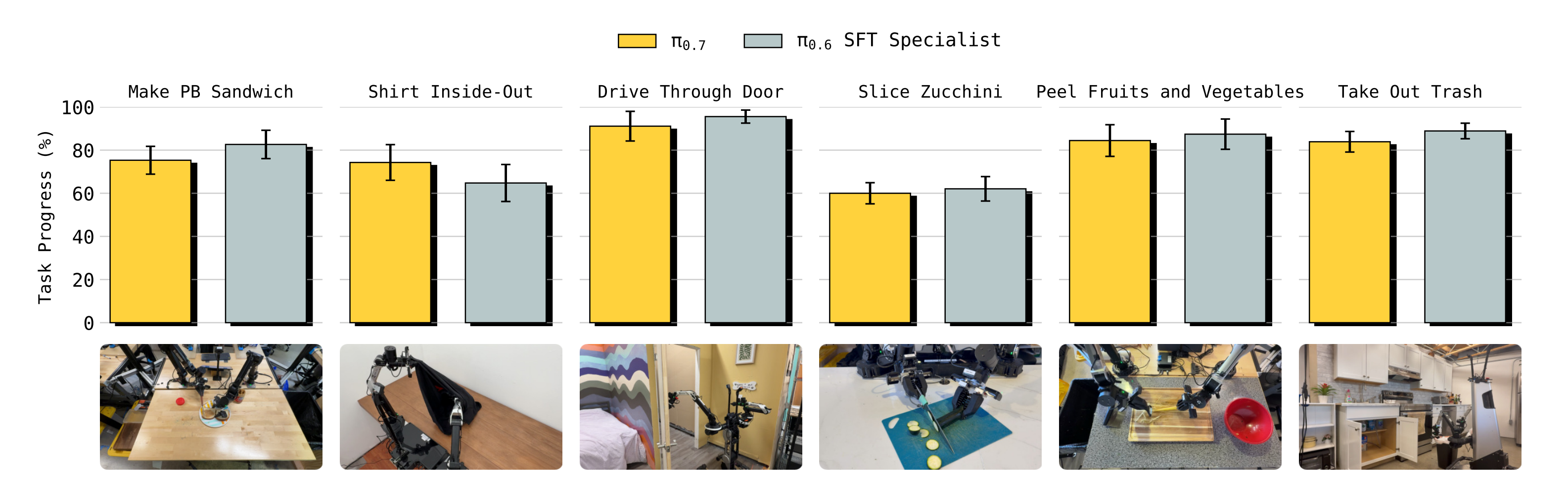
并且在困难的洗衣和搭建盒子任务中,甚至在吞吐量上超过了这些专家 - 此外,作者将π0.7 与在π0.6 基础上训练的SFT 专家在若干其他灵巧任务上进行了比较,发现π0.7 同样能够非常接近所有专家策略的性能(图6,第二行)
2.1.2 训练配方(数据与提示)上的消融实验:如果no eval data、no metadata会怎样
为了理解π0.7的训练方法是如何影响性能的,作者在 π0.6 发布的任务上,额外将 π0.7 与两个消融(ablation)版本进行了比较 :
- 一个是 π0.7(无评估数据版,no eval data),它在训练中排除了*++所有的自主评估片段++*(因此无法通过提炼强大的策略------如强化学习(RL)训练出的策略------的执行轨迹来获益);
- 另一个是π0.7(无元数据版,no metadata),它从上下文中省略了片段metadata
最终,在 π0.6 发布任务上的对比结果如图 7 所示
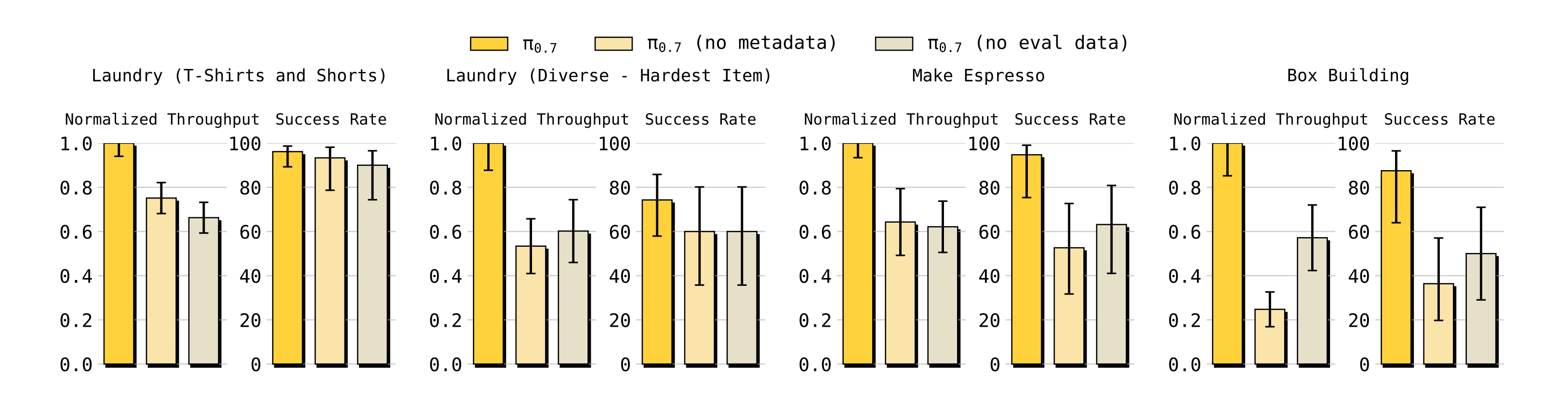
作者发现,π0.7 在各项指标上都优于 π0.7(no metadata)和 π0.7(no eval data),其中在吞吐量上的差距最为显著。这里的吞吐量(成功次数/小时)是相对于 π0.7 归一化后的结果
证明了在训练中结合多样化、质量参差不齐的评估数据,与丰富的"元数据"提示,对于模型掌握这些挑战性任务至关重要
2.1.3 无需微调的记忆任务表现:π0.7 > π0.6-MEM SFT Specialist
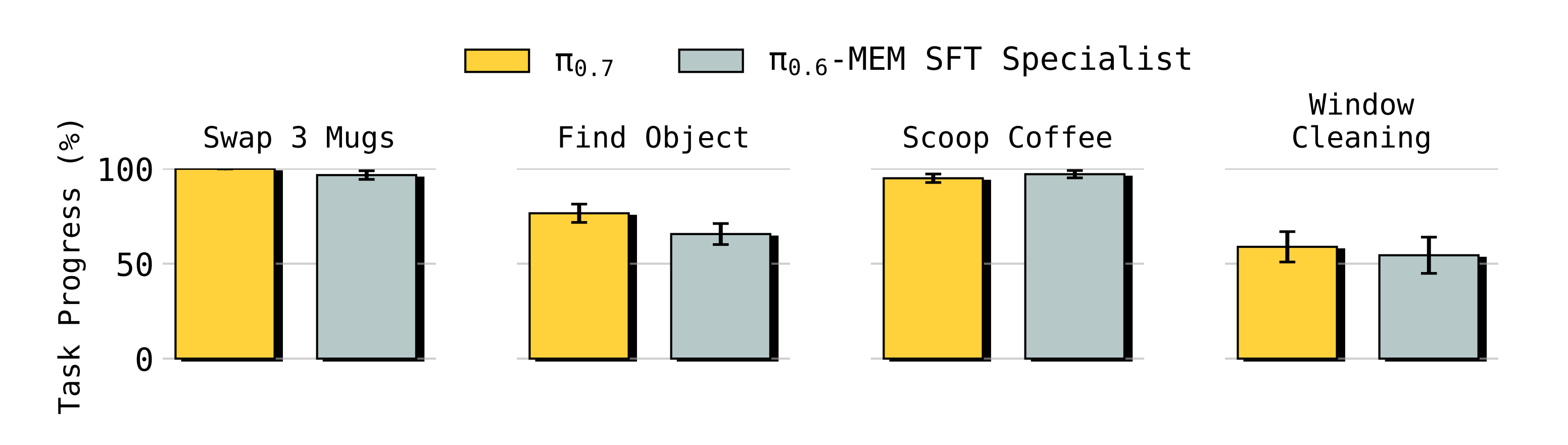
此外,结果表明,π0.7 显著优于没有评估数据的 π0.7,并且在无需微调的情况下,π0.7 在需要记忆的任务中也取得了很高的性能
在这些实验中,作者研究π0.7 在需要明确跟踪先前观测的任务上表现得有多好37
作者还将同一个开箱即用的π0.7 模型与Torne 等人37 中使用记忆机制、为特定任务微调的π0.6 版本进行比较,发现π0.7 在所有这些任务上都能达到与这些微调专家相当或更好的性能(图8)
2.2 遵循指令
作者在接下来的实验中,研究π0.7 在多大程度上能够遵循语言指令,包括其在多种不同情境下执行任务以及遵循与训练数据系统性不同的指称性指令的能力
实验特别关注在杂乱环境中执行任务,此时机器人可能执行的任务很多,这就要求π0.7 必须高度关注给定的指令才能成功
作者宣称,他们的结果发现,π0.7 在指令遵循能力方面相比我们之前的模型π0.5 14 和π0.6 42 有显著提升
2.2.1 π0.7 可以通过灵活的提示来执行各种不同的任务
-
语言跟随一直是机器人基础模型面临的一个众所周知的挑战,特别是在处理那些与训练中所见指令不直接对应的开放词汇指令时
在这些实验中,作者旨在研究π0.7 能力的广度,以回答:π0.7 是否能够比以往的模型更好地处理更广泛的语言指令?
-
作者在4 个未见过的厨房和2 个未见过的卧室中的多样化指令集上评估π0.7(图9)
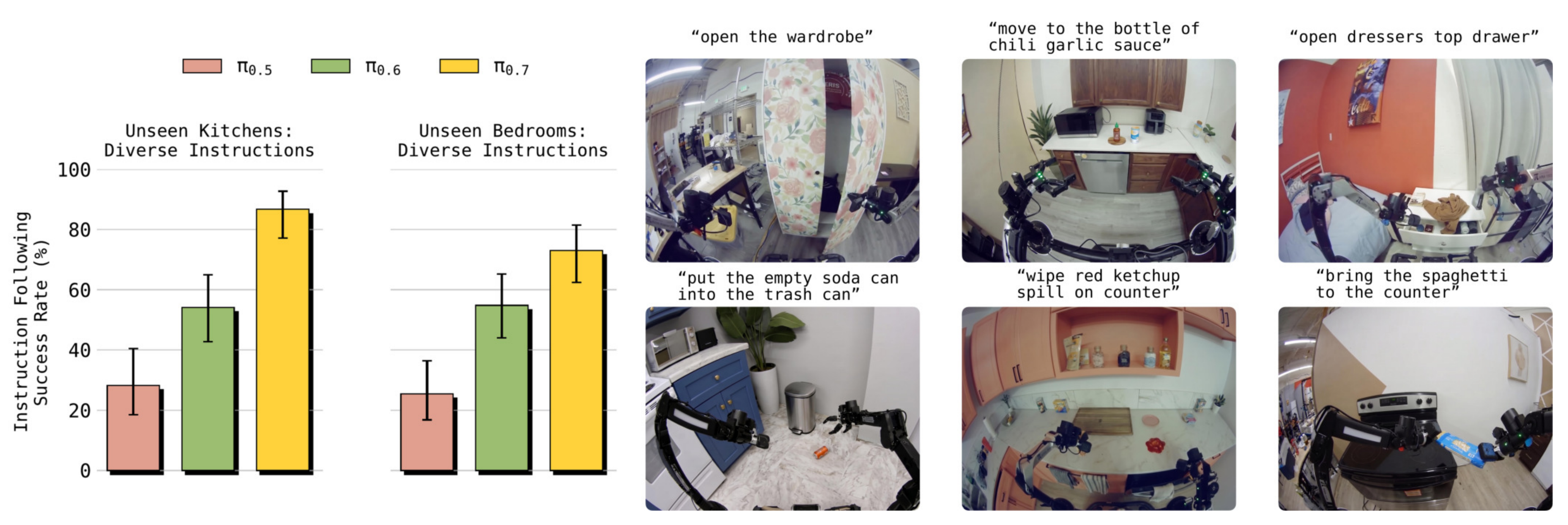
每个实验测试机器人是否能够按照由3 到6 个步骤组成的指令序列来实现特定目标。这些任务在厨房和卧室环境中要求完成多种不同的真实任务,包括重新摆放和整理物品、与家具交互以及清理溢出的液体这种新的测试环境与多样化指令的组合对机器人基础模型提出了巨大挑战,它们即使在已见环境中也很难遵循简单指令
结果发现π0.7 能够显著优于π0.5 和π0.6,并具有较高的整体指令遵循成功率
2.2.2 π0.7 能够处理分布外的指代类指令
由于作者的训练数据在广度和多样性上的特点,通常难以量化测试指令究竟有多新颖
在接下来的实验中,作者有意设计了一组不同寻常的指令,这些指令以非传统方式指代物体,或需要对其空间关系进行理解
- 在图 10 中,作者将 π0.7 与以往模型在一组物体重新摆放(object re-arrangement)指令上的表现进行了比较,并将这些指令划分为标准指令和复杂指令
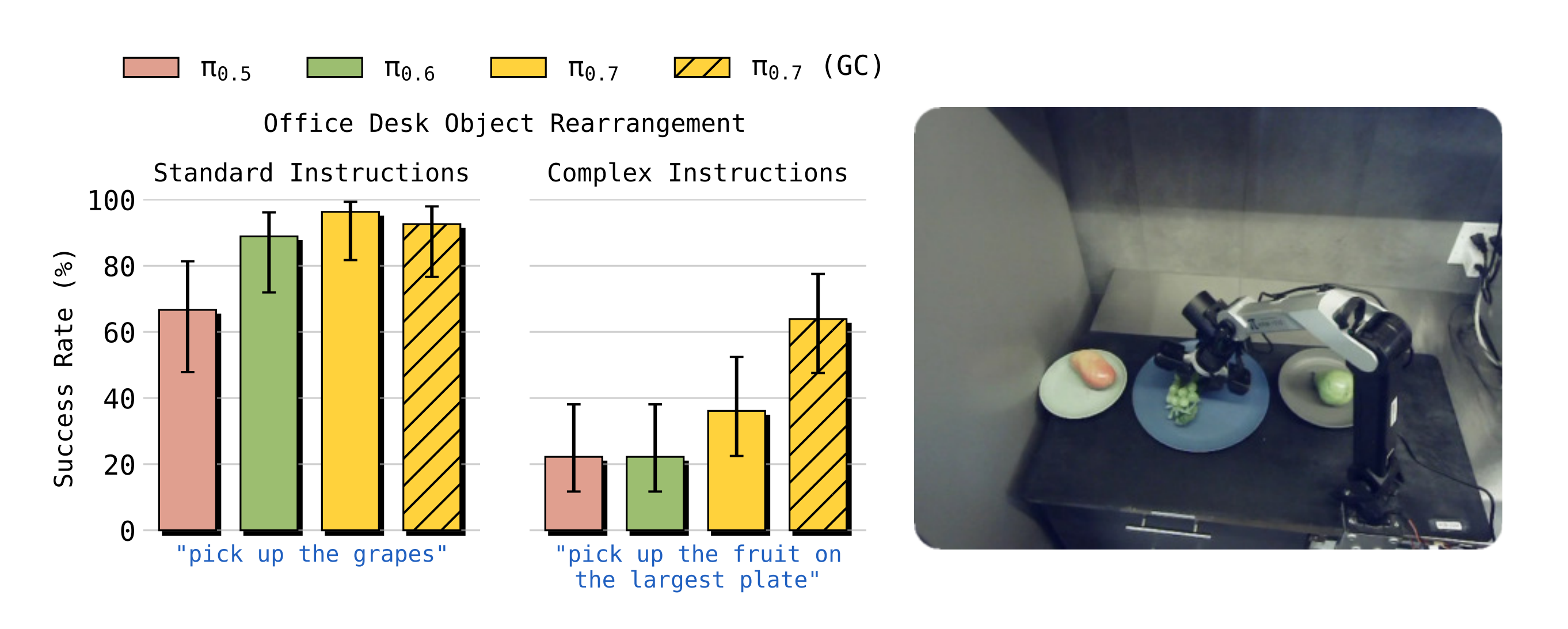
"pick upan object I would use to eat soup"(捡起一个我会用来喝汤的物体)
或
"pick up the fruit on the largest plate"(捡起最大盘子上的水果) -
在这些实验中,作者还评估了带有和不带有子目标图像的 π0.7 ,这些子目标图像由一个轻量级世界模型生成,如前文所述
π0.7 和之前的模型在较为简单的重排类指令上都能成功(指令包括"捡起勺子"、"把勺子放在叉子的左边"和"把勺子放在叉子的右边"),但在复杂且不常见的指令上(指令包括"捡起桌子上最大的碗"、"捡起我会用来喝汤的物体"和"捡起放在最大盘子上的水果")
可以看到,π0.7 在复杂指令上的表现优于以往模型,而子目标图像的使用进一步提升了其性能,将来自世界模型的语义理解引入到策略中
π0.7的表现显著更好
引入由轻量级世界模型生成的子目标图像(π0.7(GC)) 可进一步提升对指令的执行效果,使得 π0.7 在遵循复杂指令方面的能力显著增强
2.2.3 π0.7 可以遵循与数据集偏差相违背的指令
数据集偏差给指令跟随带来了重大挑战:如果机器人在某个场景中总是执行相同的操作,那么在此类数据上训练出的模型,往往会在这些场景中忽视语言指令,而是盲目地复制数据中出现过的行为
在下一个实验中,作者构造了一些存在这一问题的情境,并测试是否可以通过提示让π0.7 违背数据集中的自然偏差
且设计了两个任务:
- "反向收拾餐具(Reverse Bussing)"
在作者的数据集中,"bussing" 任务是指将垃圾放入垃圾桶,将餐具放入收拾餐具的桶中
而在"反向收拾餐具"任务中,要求机器人执行相反的操作:把垃圾放入收拾餐具的桶里,把餐具扔进垃圾桶 - "反向冰箱到微波炉(Reverse Fridge to Microwave)"
"Fridge to Microwave"任务要求将食物从冰箱取出并放入微波炉中,作者++没有采集反向操作的数据
在测试时,在该任务的"反向"版本("Reverse Fridge to Microwave")中,作者通过提示让机器人将食物从微波炉拿回冰箱++,从而打破数据集中的偏差
图11中的结果表明,π0.7在这些任务上的表现相较于以往模型有显著提升
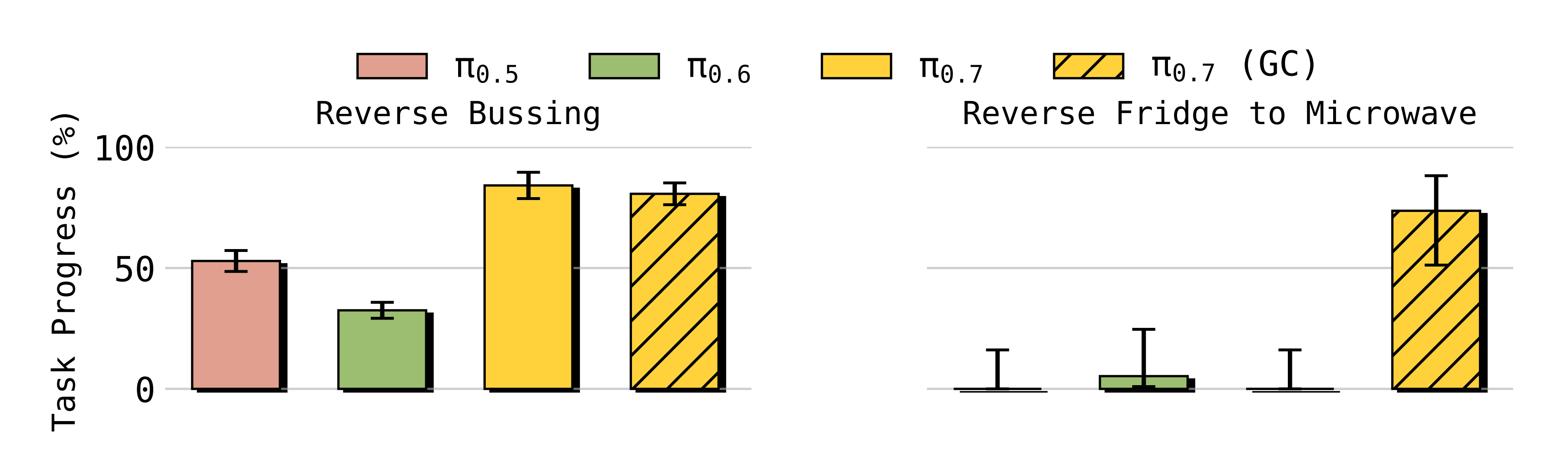
- 这表明π0.7具有显著更强的语言跟随能力,并且对指令给予了足够的重视,从而能够在这些任务中克服数据中存在的偏置
- 在"Reverse Fridgeto Microwave"(反向从冰箱到微波炉)这一任务上
*基于生成的子目标图像进行条件建模(π0.7(GC))*对成功至关重要,因为世界模型可以有效地利用网页规模的图像生成预训练,根据文本指令生成相应的子目标
2.3 跨机体迁移
尽管已有许多模型使用了来自多种不同机器人形态的数据 3,5,8,80,但要在零样本设置下,将复杂任务从一个源机器人形态迁移到一个从未见过该任务的目标机器人,仍然是一个重大挑战
-
在这些实验中,作者旨在研究跨机体迁移是否是 π0.7 的一种涌现属性。具体来说,π0.7 能否直接将能力迁移到那些从未收集过该任务特定数据的机器人形态上?
-
作者发现,对于若干任务,π0.7 在目标载体上能够完全开箱即用地取得成功,即使在这些任务上目标机器人没有任何训练数据。对于更为温和的载体差异,π0.5 和π0.6 模型也表现出一定程度的跨载体迁移涌现
然而,随着机器人形态差异的加大,有效地转移复杂技能需要在策略上做出更重大的改变
在这些情形下,π0.7的表现显著优于先前的模型,甚至在衬衫折叠任务上达到了与人类远程操作者"零样本"表现相当的水平,此点将在下文中进行讨论
下面的实验结果采用关节空间控制,因为作者发现对于他们先前的模型而言,末端执行器控制并不会带来显著的性能提升(附录 E)
2.3.1 零样本跨形体迁移用于物体重排任务
首先研究一组更简单的物体重排任务,在这些任务中,作者在与收集该任务数据时所使用的机器人不同的机器人上测试π0.7
结果如图12 所示
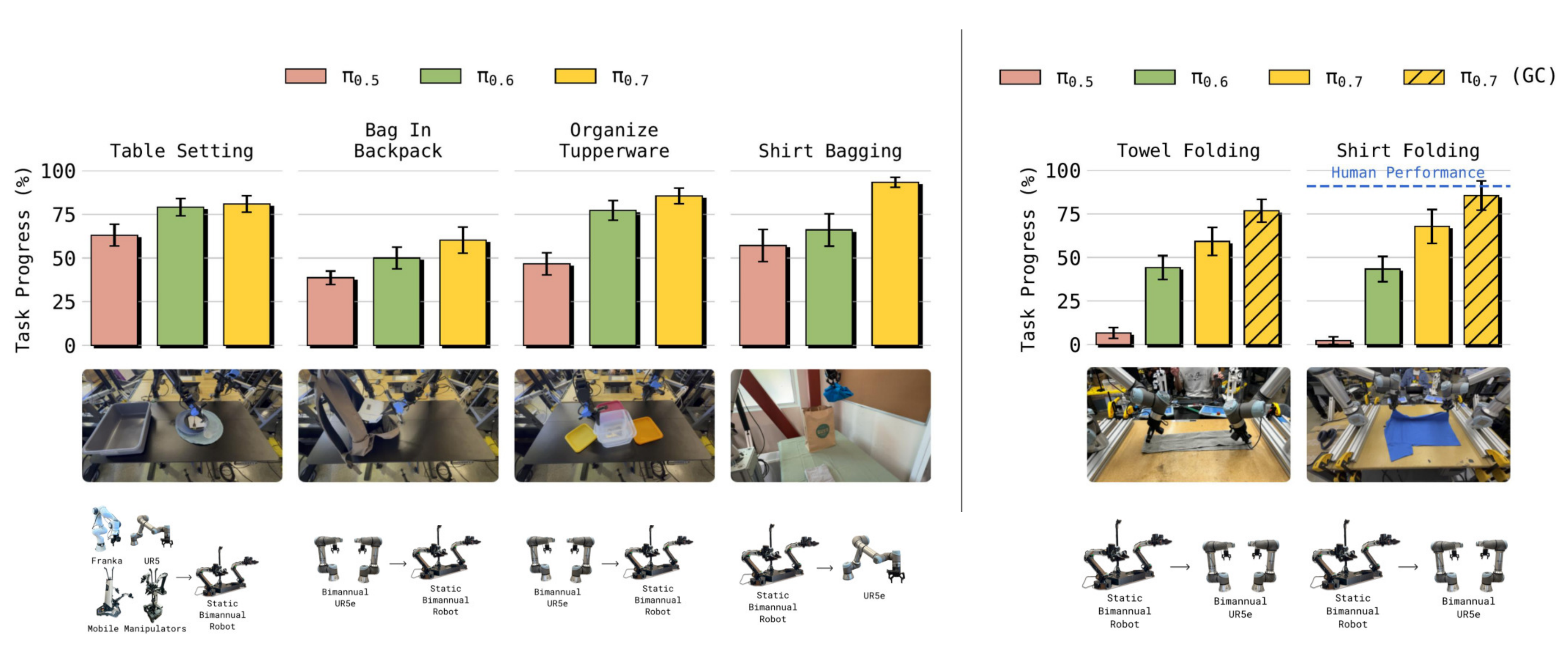
- 对于第一个任务"Table Setting ",数据是使用多种不同类型的机器人收集的,包括移动式、静态式和单臂系统
这是最有利于跨形体迁移的设置,因为模型可以从多种不同机器人中推断出任务的共同结构
当在一个静态双臂机器人系统上进行评估时,作者发现所有方法都表现出明显的跨形体迁移迹象 - 然而,当显著加大形体差异,并在所有数据均在较大的UR5e 双臂平台上收集的情况下,将策略在较小的静态双臂平台上进行测试("Bag In Backpack" 和"Organize Tupperware" 任务)时,作者发现π0.5 的性能显著下降,而π0.6 和π0.7 仍然能够取得较强的性能
- 随后,作者进一步加大形体差异,研究这样一个任务的迁移:数据是在较小的静态双臂平台上收集,而评估则在单臂UR5e 平台上进行("Shirt Bagging "任务)
这需要显著不同的策略,因为目标机器人只有一只手臂,体型更大,也更重
在这里,π0.7 的表现明显优于之前的模型
值得注意的是,成功的迁移往往要求策略去发现适应目标形态的新操纵方式,而不是简单地复制源机器人的行为。例如,较矮且关节固定的双臂机器人必须用一只手臂撑开袋口,另一只手臂完成插入操作;而更高的 UR5e 机械臂则可以通过单臂抓取-放置就完成同样的任务(图 13(a))

- (a) 在源机器人上,人类遥操作员使用一只机械臂将袋口撑开,另一只机械臂执行插入操作。而在 UR5e 目标机器人上,π0.7 却发现了一种单臂抓取-放置策略,更适合该机器人更长的工作空间
- (b) 在源机器人上,人类遥操作员以倾斜的末端执行器接近衬衫,而在UR5e 上,π0.7 则采用垂直抓取,这更适合该大型机器人手臂的姿态与位置控制
在这两种情况下,++该策略不仅仅是复制源端行为,而是为当前任务在目标形体上发现了更为合适的操作策略++
说白了,相当于机器人在自主执行任务过程中,有了一定的自主变通能力,而非纯机械模仿人类示教的流程
尽管存在显著的形态差异,模型仍能为每种机体选择合适的策略,展现出超越简单模仿原始机器人运动的跨机体迁移能力
2.3.2 用于灵巧任务的零样本跨机体迁移
诸如叠衣服之类的灵巧任务对于跨具身性迁移来说更具挑战性
这类任务比仅仅抓取和重新放置物体需要更精细的操作技能。要成功折叠一件 T 恤,需要一系列精确的抓取和放置动作,而且正确的抓取角度可能会随着机器人的可达工作空间和夹爪朝向而变化。而作者的大部分折叠数据是使用轻量级的***静态双臂机器人(static bimanual robot)***采集的(见图 4)
没有使用双臂 UR5e 系统采集任何叠衣数据------该系统的形态结构、可达工作空间以及动力学特性(例如更高的内部惯量)与作者用于采集叠衣数据的机器人有显著差异
作者发现 UR5e 在遥操作上整体更为困难,也不太适合进行非常精细的抓取,这表明要用这台机器人叠衣物,需要改变原有的操作策略
π0.7 在双臂 UR5e 系统上成功完成了毛巾和衬衫的折叠任务(图 12,右)
-
在源机器人(图 4 中的静态双臂机器人)上,人类操作员通常会让末端执行器带有一定倾角接近布料,以便在抬起之前先将织物压在桌面上
-
在 UR5e 上,π0.7 则采用了垂直抓取方式,这种方式更适应机械臂的运动学特性------这一策略不同于源机器人训练数据中的方式,但更适合目标形体(图 13(b))
作者还发现,结合世界模型进行子目标图像生成可以显著提升性能(在图中标记为 π0.7(GC) ),因为世界模型可以更有效地在源机器人和目标机器人之间构建视觉类比
生成的子目标会预测对目标机器人来说合理的抓取方式以及衣物构型,模型则将这一额外上下文作为提示,用于选择更优的动作
作者对 10 名有经验的远程操作员进行了用户研究(他们在所有机器人上的远程操作总经验平均为 375 小时,经验水平位列前 2%)
与策略类似,这些操作员在源机器人形态上具有丰富经验,但从未在 UR5e 双臂系统上尝试进行衬衫折叠,这对人类和策略来说都构成了一个零样本跨机体迁移设定
最终
- 人类操作员达成了 90.9% 的任务进度和 80.6% 的成功率
- 而 π0.7 达成了 85.6% 的任务进度和 80% 的成功率,表现出与这些专家操作员相当的性能
这种对比所凸显的强大的跨实体迁移性能在科学上令人兴奋,而且具有实际意义:灵巧技能可以从易于远程操作的轻型低成本平台上转移到负载量大的工业机械臂上,毕竟在工业机械臂上收集人类演示数据的成本要高得多,难度也大得多
2.4 组合式任务泛化
在下一组实验中,作者研究 π0.7 通过对训练中见过的技能进行组合式泛化,在执行新任务方面的能力表现如何
这一直被视为机器人基础模型的一类"宏大挑战":尽管以往的模型已经在语义概念层面展示了泛化能力(例如:根据一个从未见过的文本标签去触及对应物体),但要让其执行全新的任务仍然被证明是非常困难的
作者发现
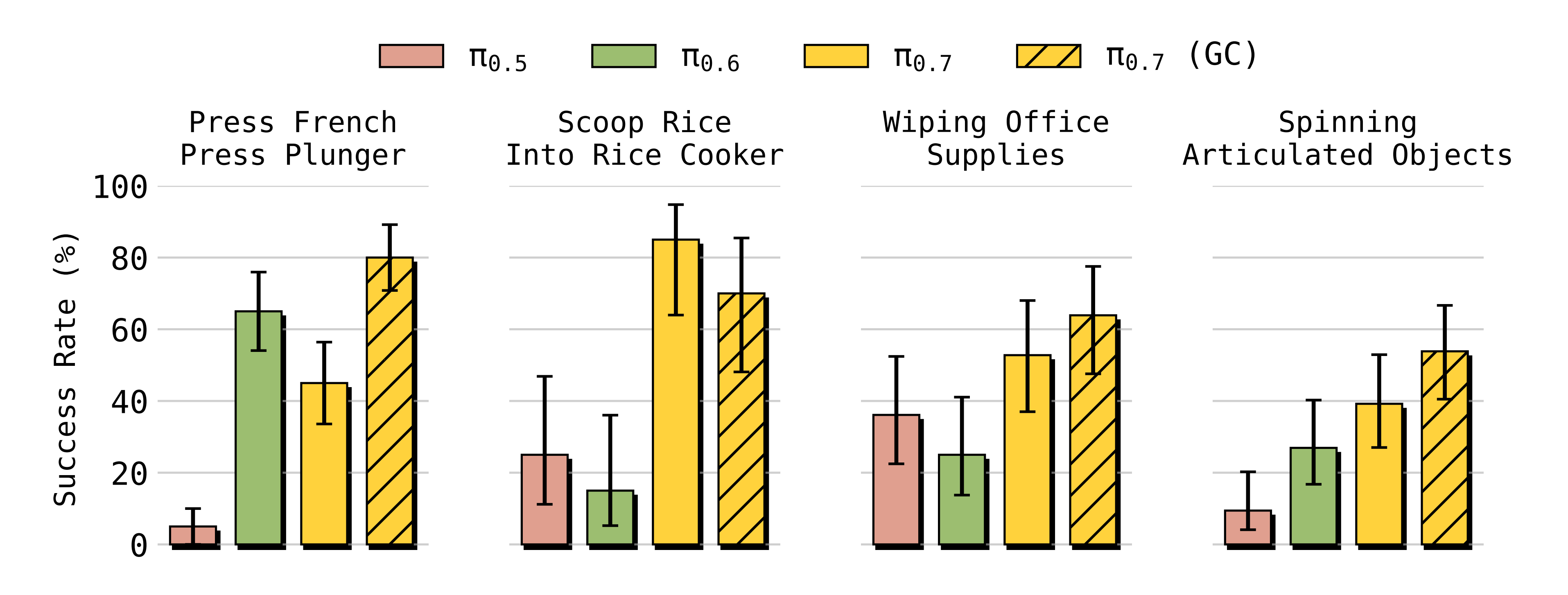
- 对于一些短视野任务,π0.7 即使在没有为这些任务专门收集数据的情况下,也可以完全开箱即用地很好地工作。这些任务涉及以新的方式操作不熟悉的物体,例如用布擦拭一副耳机,或转动台式风扇(图17)
- 对于更长视野、更复杂的任务,我们发现实际上可以利用π0.7 的指令跟随能力,通过语言对其进行" 指导" 来完成任务
这为在不收集任何额外训练数据的情况下教会π0.7 新任务提供了一种令人兴奋的新方法
2.4.1 π0.7能够即开即用地执行新的短时任务
作者发现,π0.7可以直接在零样本的情况下完成诸如
- 按压法压壶的活塞pressing the plunger on a french press
- 将米饭舀入电饭煲scooping rice into arice cooker
- 擦拭常见办公物品wiping down common office objects
- 以及旋转各种可动结构物体(spinningvarious articulated items directly out of the box)
等短时任务(见图17)
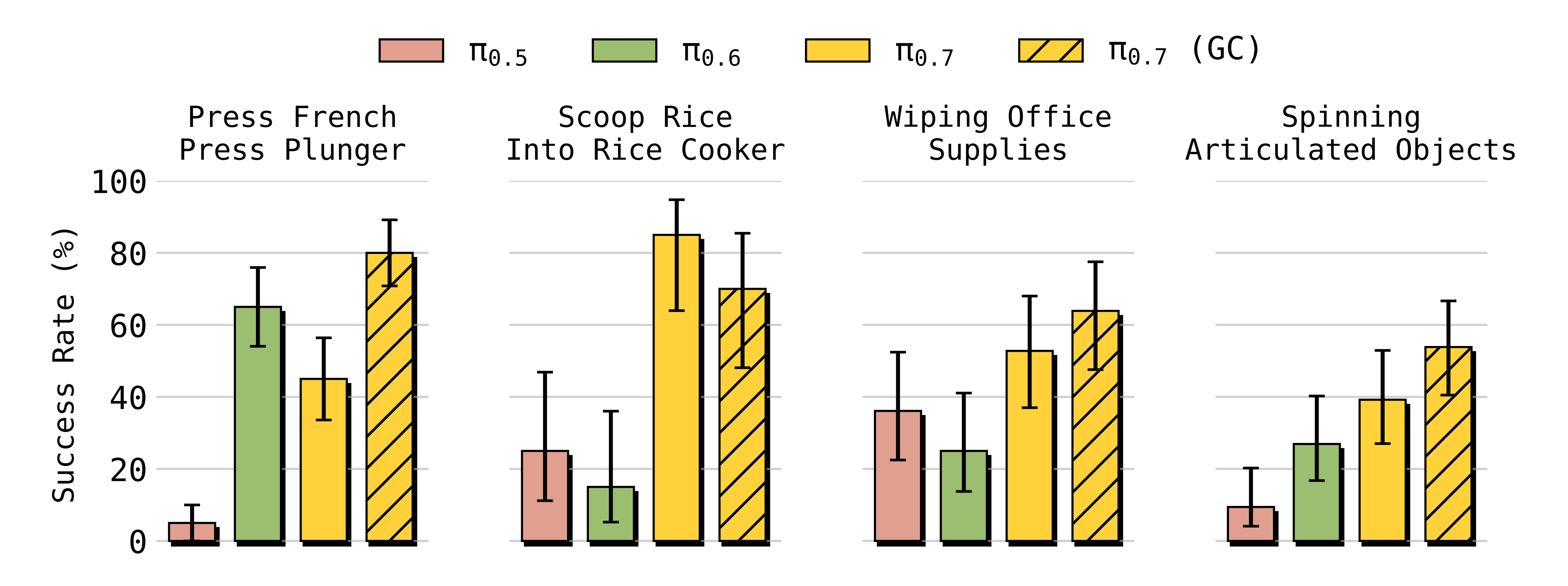
尽管在训练过程中并未针对这些具体任务采集任何机器人数据。这相当令人兴奋------由于π0.7 能够灵活组合各种技能,常常只需提示它获取期望的行为,就能让它执行新的简单任务
2.4.2 π0.7 可以仅通过语言被指导来执行新的长时任务
虽然π0.7 可以通过直接提示来执行新的短时任务,但简单地让机器人执行一个未见过的长时任务(比如烤红薯)是行不通的:尽管π0.7 展现出很高的开箱即用泛化能力,这些任务仍然过于复杂,需要长达5 分钟、包含多个阶段的交互
然而,π0.7 的语言跟随能力为我们提供了一条教会模型此类任务的令人兴奋的新路径:作者不再为每个希望机器人学会的复杂技能提供示范数据,而是可以用语言来" 指导"机器人完成新任务,有点类似于人类会如何教另一个人完成任务(图14)

作者设置了几个真实的多阶段厨房任务:
- "Loading an Air Fryer":使用空气炸锅来烹饪红薯
- "Unloading an Air Fryer":将物品从空气炸锅中倒出
- "Toasting a Bagel":使用烤面包机烤贝果
在每种情况下,作者的机器人数据中都不包含该任务的任何训练片段,尽管在人类数据和外部数据集中,在不同的上下文中出现过类似的电器
然而,人可以通过逐步指令来引导机器人完成任务,例如"pick up the sweet potato"和"open the air fryer"
- 作者在图15 中给出了对π0.7 进行指导以及相关对比的结果
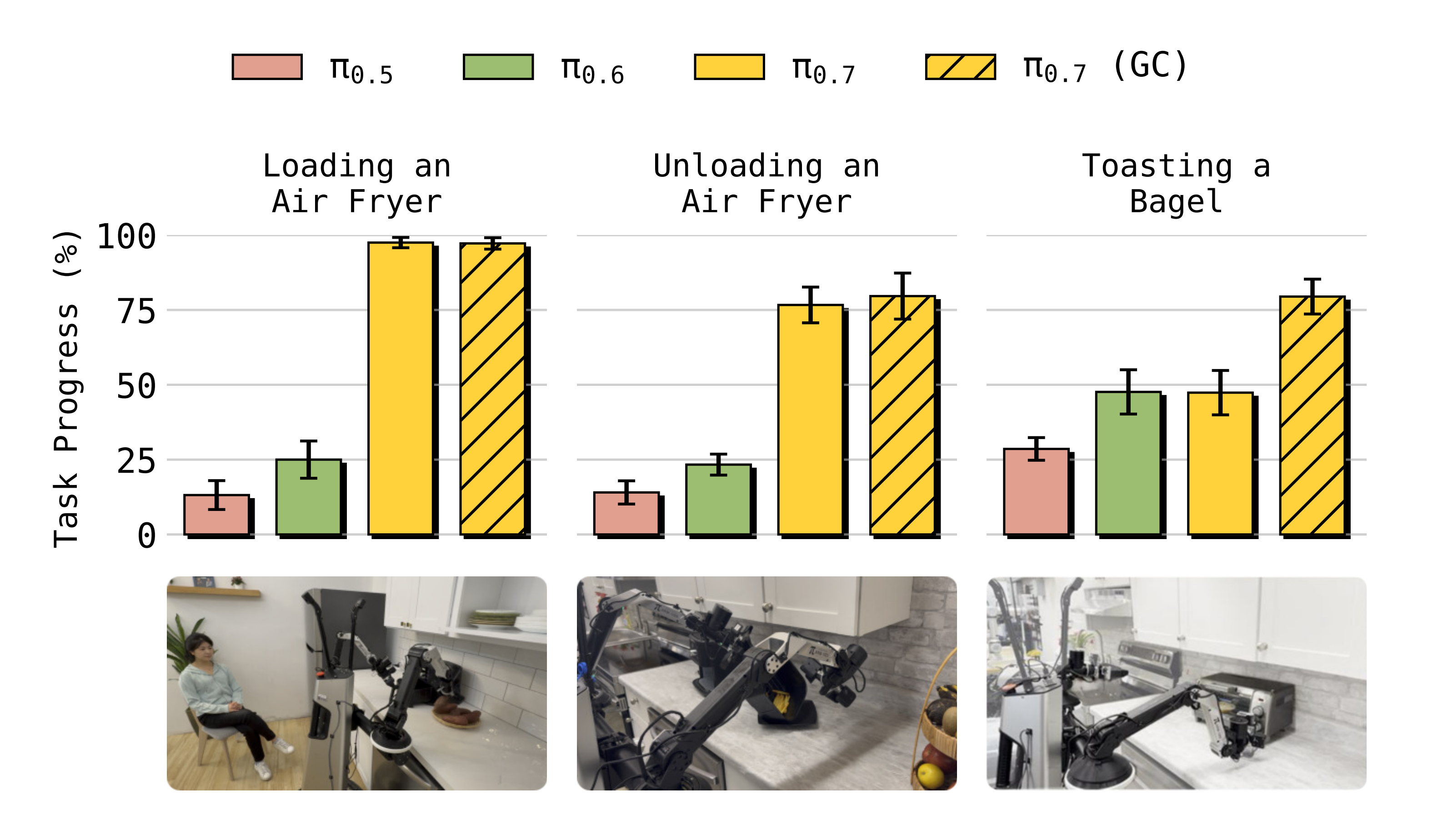
关键在于,这些模型都没有关于这些特定任务的任何动作级数据,并且在"coaching" 片段中,环境和任务是完全未见过的 - 作者发现,与先前方法相比,π0.7 在所有这些任务上都能被更有效地指导,并且在以生成的子目标图像作为条件时,性能还能进一步提升
2.4.3 指导数据可以赋予 π0.7 新的能力
由于可以通过指导让 π0.7 执行新的任务,作者实际上可以利用指导数据中的逐步说明来训练一个高层次的语言策略,使其在任务执行过程中用合适的语言指令来提示 π0.7
- 这样就使得 π0.7 能够在无需收集任何额外遥操作数据的情况下,执行完全未见过的、长时程任务
作者在图 16中展示了这一实验在五种不同情形下的结果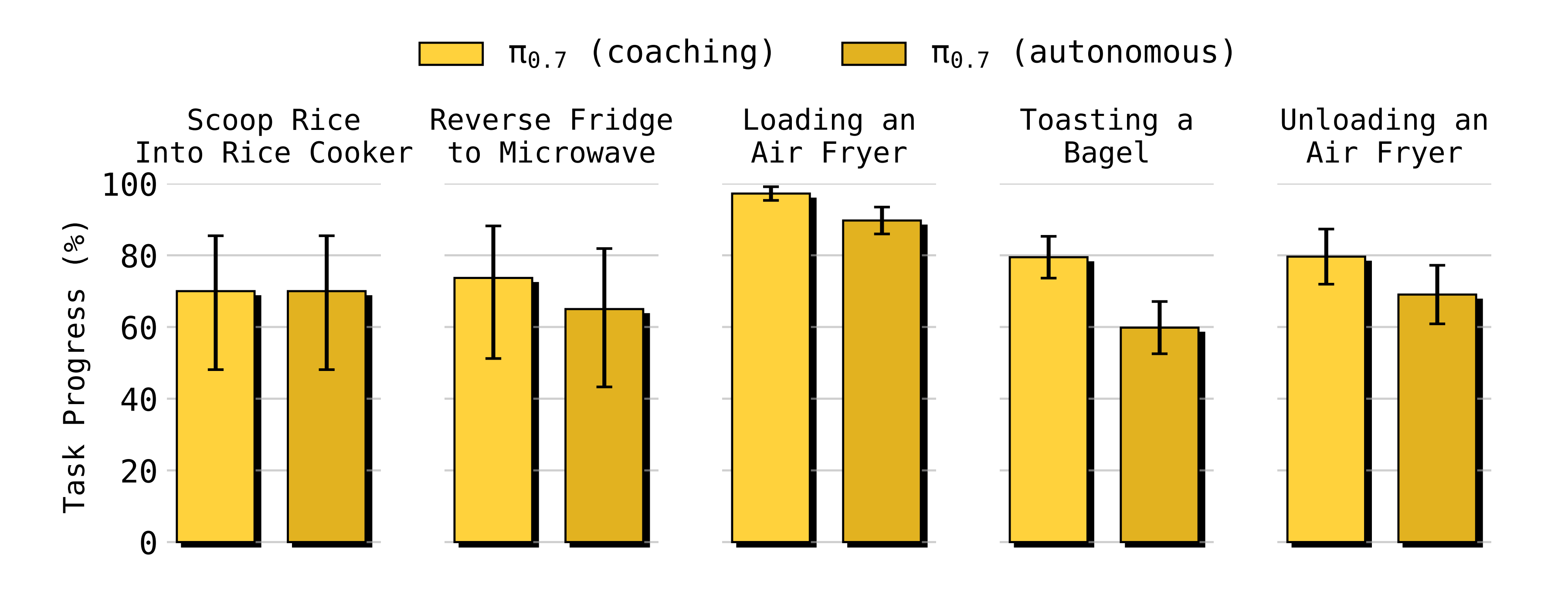
- 对于所有这些任务,作者宣称,他们发现可以成功训练一个自主策略(π0.7 (autonomous)),其性能大致能够匹配通过提示模型执行任务而收集到的辅导轨迹(π0.7(coaching)) 的表现
2.5 π0.7 能够从多样且质量参差不齐的数据中进行有效学习吗?
在作者最后一组实验中,作者进行了一组受控消融研究,以理解π0.7 是否能够有效利用大型且多样化的数据集,以及其性能是否会随着数据集多样性的提升而提升。这些问题很难被明确回答,因为此类模型的性能取决于大量因素,而非常大的数据集也很难被干净地划分,以便消融"多样性"
为对这些问题提供一定的理解
- 作者首先研究当在越来越大但质量更加混合的数据集上训练时,π0.7 在已见任务上的表现是否会持续提升
- 接着,研究π0.7 是否能够利用具有高任务多样性的数据集来推动泛化能力的提升
2.5.1 π0.7 可以从混合质量的数据中有效学习
从多样化的机器人数据中有效学习在目前训练机器人策略时一直是一个重大挑战。设计者通常会仔细过滤或整理数据,以获得具有一致策略的高质量数据集110, 111
然而,数据过滤既费力、又与任务强相关,并且最终会丢弃大量有价值的信息
在这些实验中,作者旨在回答:π0.7 能否从具有多样操作策略的数据中学到更多?
为了研究这个问题,作者考虑在图6 中研究过的"Laundry(T-Shirts and Shorts)" 任务
且根据折叠质量和速度对人工操作员收集的数据进行了标注,并将数据集划分为4 个桶,分别包含:
- 质量和速度排名前30 % 的数据
- 排名前50 %
- 排名前80 %
- 所有数据
然后针对每个桶中的数据,从头开始训练新的π0.7 模型,分别使用或不使用episode 元数据(共8 个模型)
作者发现,虽然在规模更大、质量参差不齐的数据集上训练时,π0.7(不含元数据)的表现实际上会变差,但π0.7(含元数据)却能够在训练数据量不断增加的情况下持续提升,即便数据集规模的扩大意味着平均数据质量的下降(图 18 左),模型仍然能够持续改进
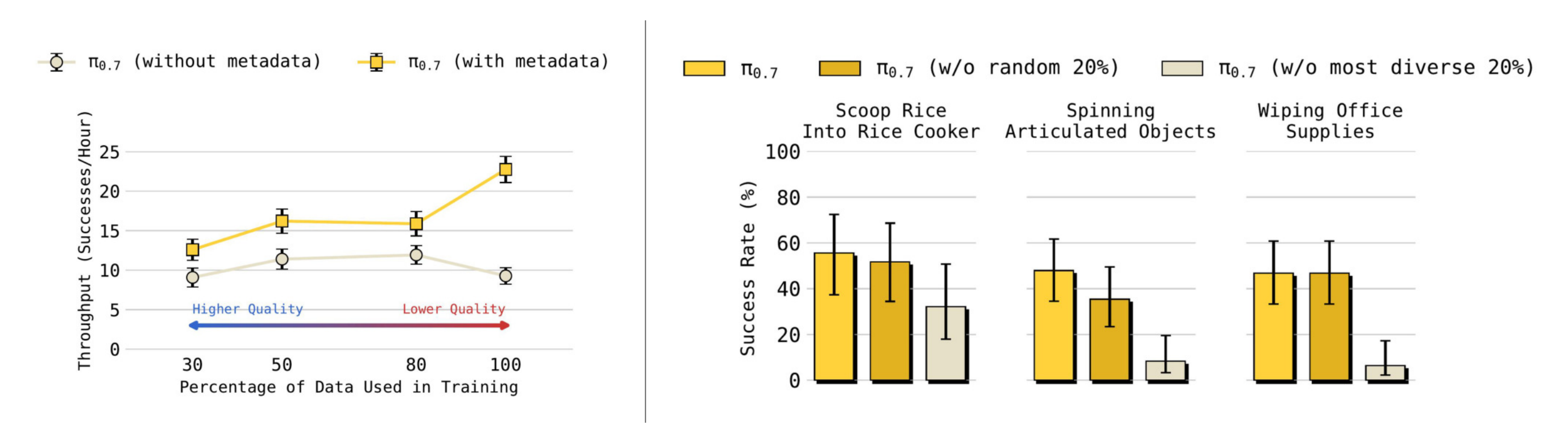
- 左图:作者发现,当在更大规模的数据集上进行训练时,即使数据的平均质量实际上在下降,++π0.7(带元数据)仍然可以持续提升其性能++
相比之下,如果不在丰富的条件信息上进行训练,作者发现π0.7(无元数据)在引入更多低质量数据时,其性能实际上会下降
总之,以上结果表明,多样化提示的方法在某种意义上有效地提高了模型设计的可扩展性,即它能从更大的数据集中获得更多益处,即使这些更大的数据集实际上由质量更低的数据构成,而这些数据会损害以常规方式训练的模型
Episode 元数据在π0.7 训练过程中有效地区分了大规模数据集中不同的数据质量和策略,并在测试时支持对期望行为模式的提示
2.5.2 π0.7能否将数据集多样性的提升转化为更好的泛化性能?
为研究这个问题,作者在图17 中的部分短时间跨度未见任务上,可以看到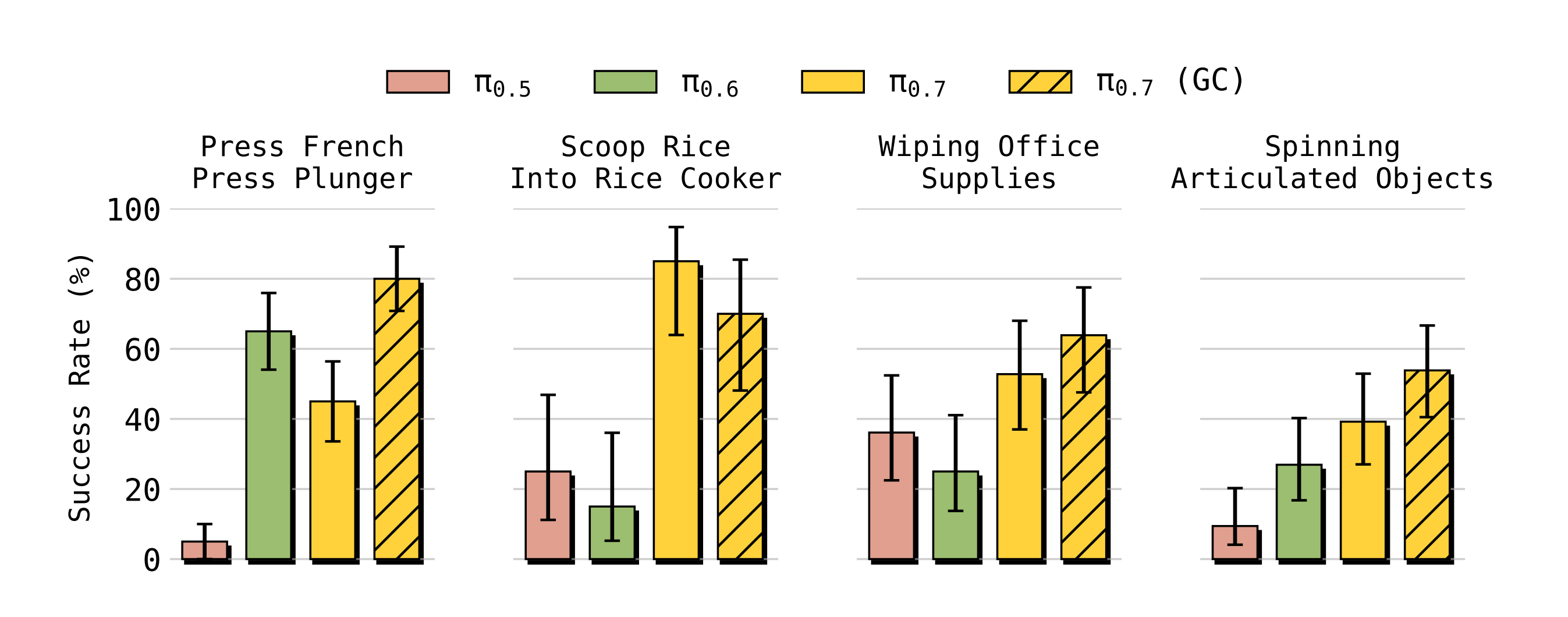
- π0.7可以"开箱即用"地执行多种新的短时任务,包括将米饭舀入电饭煲、旋转齿轮组和台式风扇等各类物体,以及用抹布擦拭物体(如尺子和耳机),即便这些任务都未采集过任何训练数据
- π0.7在直接条件化于语言指令(π0.7)或生成的图像目标(π0.7(GC))时,表现大致同样出色
接下来,将π0.7 与以下消融版本进行比较
- π0.7(去除最多样化的20 %):π0.7,但去除了我们数据中任务多样性最高的20 %
- π0.7(去除随机20 %):π0.7,随机抽取20 % 的数据并去除,用作与π0.7(去除最多样化的20 %)进行数据控制的对比
最终结果如图18所示
即在所有任务上,π0.7和 π0.7(随机去除 20%)都显著优于 π0.7(去除多样性最高的 20%),这表明 π0.7 能够有效吸收高任务多样性的数据,并将这些数据转化为在短时域、未见任务上的性能提升(见图 18,右)
- 右图:当π0.7在训练时不使用具有最高任务多样性的机器人数据,其性能会大幅退化
这表明,π0.7能够利用机器人数据中的任务多样性,从而在组合式任务泛化方面取得显著提升
论文最后,作者强调
- 与其为了让机器人解决每一个新任务都要有意识地收集有针对性的数据,不如利用一个具备组合式泛化能力的模型,让用户只需通过提示的方式,指示它执行所需任务
- 能够在大规模上实现这种组合式泛化的模型,将会彻底改变对机器人学习的研究范式,使得可以通过"提示""指导"和"解释"来教会机器人,而不再必须为其收集额外的动作数据
说白了,这就是具身通用模型的价值和意义,不用再专门针对一项项任务针对性的收集数据进行额外的微调