没上 RAG,效果却不输 RAG:这套 Easysearch AI 助手完整复盘
先把结论说透
这套系统的核心不是"检索技术炫技",而是三件事做得特别扎实:
- 知识够准
Skill 文档本地维护,且和 Easysearch 官方文档强绑定。
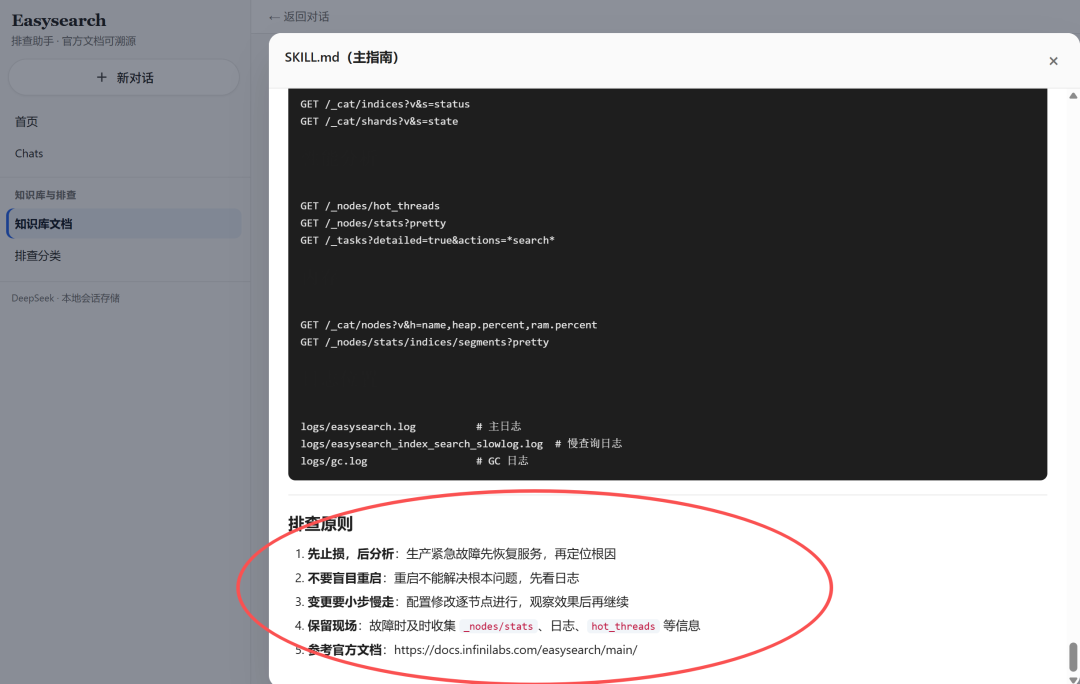
- 规则够硬
系统提示词里把输出格式、溯源要求、ES/Easysearch 差异处理写死。
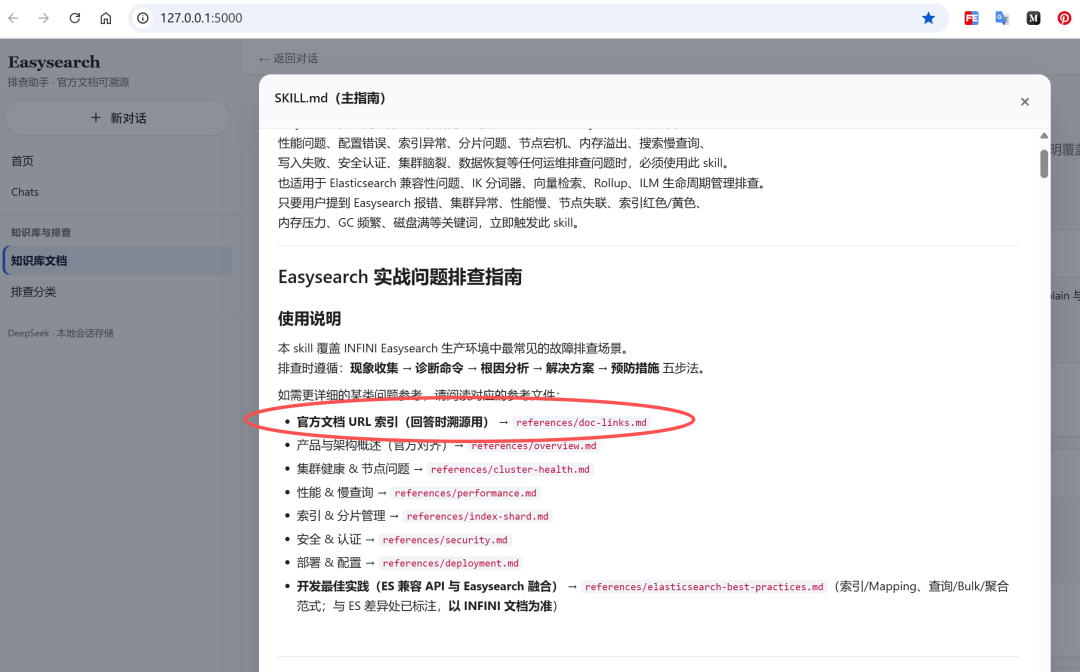
- 体验够顺
前端参考 Claude 风格,SSE 流式输出,用户觉得"它真懂我问题"。
所以你会看到一个有意思的现象:
不用 RAG,也能拿到很高的"可用回答率"。
为什么没上 RAG 也成立?
很多团队默认"做知识问答 = 必上 RAG"。这句话不全错,但也不是绝对。
我们这个场景的特点
- 问题域比较聚焦
就是 Easysearch 运维/排障/开发实践。
- 知识规模可控
几十篇高质量 Markdown 足够覆盖 80% 真实问题。
- 规范要求高
回答必须给官方链接、命令可执行、风险点要提示。
这种场景下,先把知识做成结构化 Prompt 手册 ,比"上来先建向量库"更快出效果。
没上 RAG 的代价和收益
代价:
-
每轮请求 token 变大(因为系统提示词长)。
-
知识继续膨胀时,上下文窗口会成为瓶颈。
收益:
-
不存在"检索漏召回"导致答偏。
-
输出风格和约束稳定(尤其是"官方文档溯源")。
-
工程复杂度低,0 到 1 速度极快。
一句话:我们不是反对 RAG,而是先用更短路径把业务价值打出来。
从 0 到 1 的技术路线(按实际落地顺序)
1)先把"能聊起来"打通:Flask + DeepSeek
后端就一个 app.py,核心目标是"先跑通,再可控":
-
Flask 提供页面与 API。
-
openaiPython SDK 直连 DeepSeek 兼容端点。 -
.env管理DEEPSEEK_API_KEY、模型名、Base URL。
这一步没啥花活,但很关键:
先验证模型接口稳定可用,再谈知识增强。
2)把"知识"做成系统内核:Skill 全量注入
系统启动时会加载:
-
skill/SKILL.md(主指南) -
skill/references/*.md(专题文档)
然后拼成系统提示词,放在每次请求的 system 消息里。
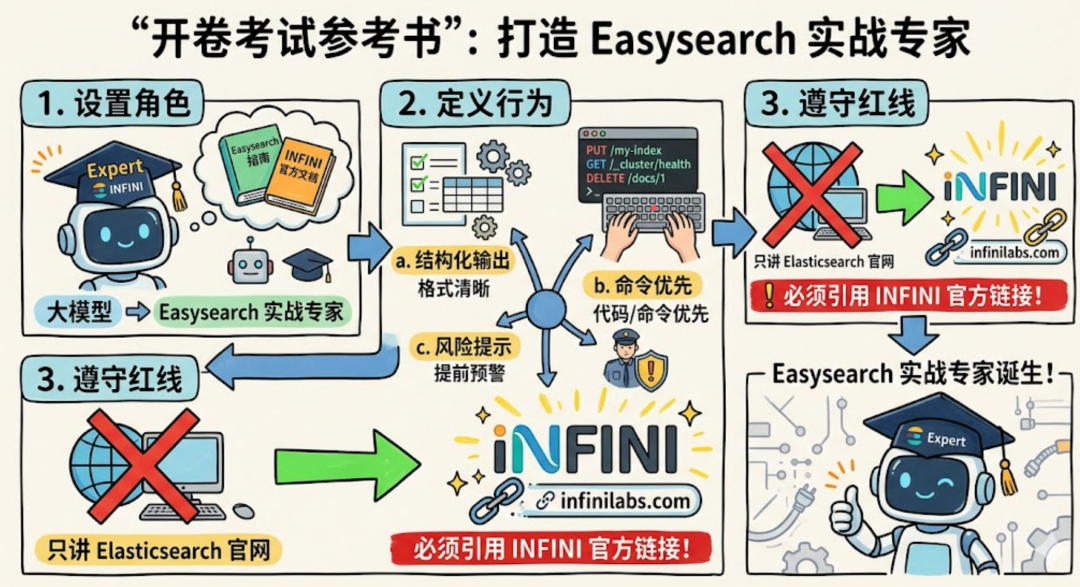
这相当于给模型发一本"开卷考试参考书":
-
先定角色:你是 Easysearch 实战专家。
-
再定行为:结构化输出、命令优先、风险提示。
-
最后定红线:必须引用 INFINI 官方链接,不可只讲 Elasticsearch 官网。
这就是"没 RAG 也能准"的第一性原理:先把知识和规矩塞对地方。
3)让回答"能落地":强制官方溯源
我们不是让模型"尽量引用",而是直接在系统提示词写了硬要求:
-
每轮回答都要有"官方文档溯源"小节。
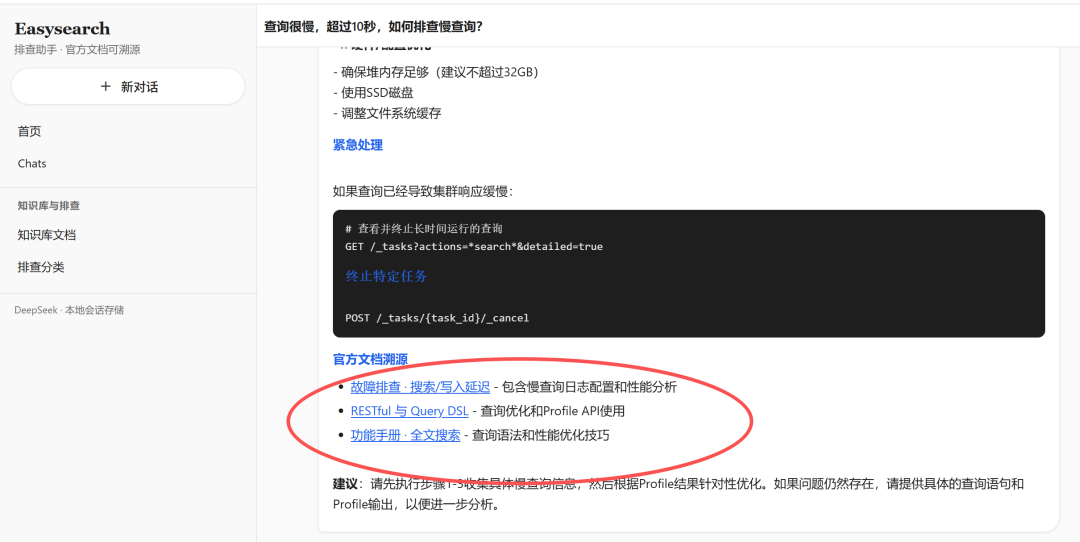
-
链接必须落在
docs.infinilabs.com/easysearch。 -
场景和链接要对应(排障、Cat API、REST、集群管理等)。
这个设计的价值很大:
用户不只看到建议,还能一键跳到官方页二次确认,信任感会明显上升。
4)把 ES 经验做"融合翻译",而不是照搬
Elasticsearch 和 Easysearch 有差异。
我们做法不是删 ES 经验,而是做了融合版文档:
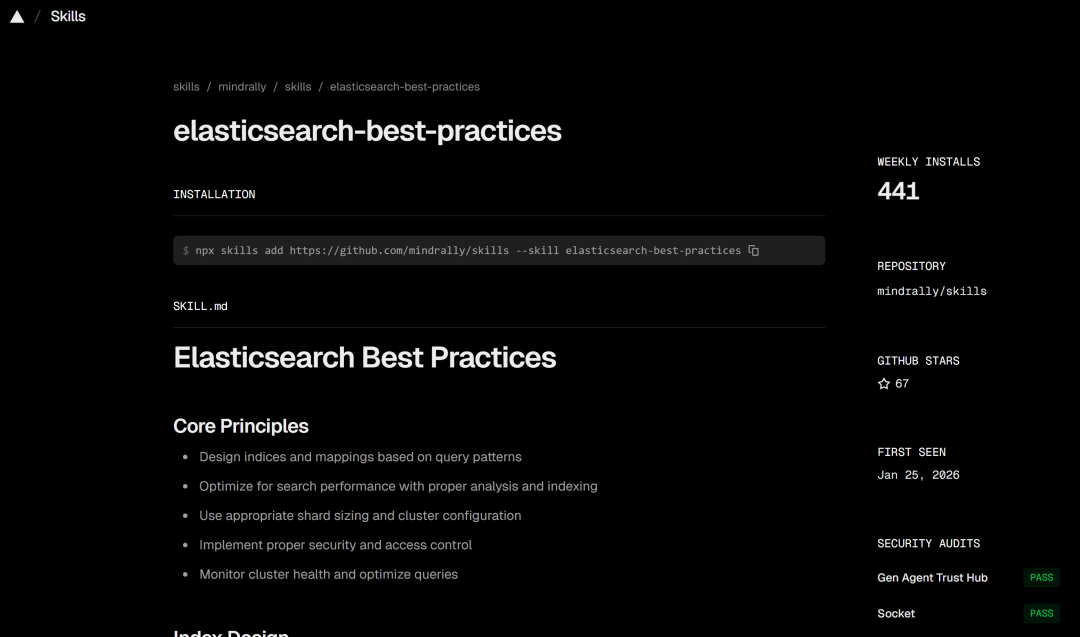
-
新增
elasticsearch-best-practices.md(Easysearch 适配版)。 -
专门写了"差异表":配置、安全模型、ILM、插件、兼容边界。
-
明确规则:可借鉴 ES 范式,但最终以 Easysearch 官方行为为准。
这一步是第二个关键:
把"通用最佳实践"翻译成"你这套系统能直接执行的实践"。
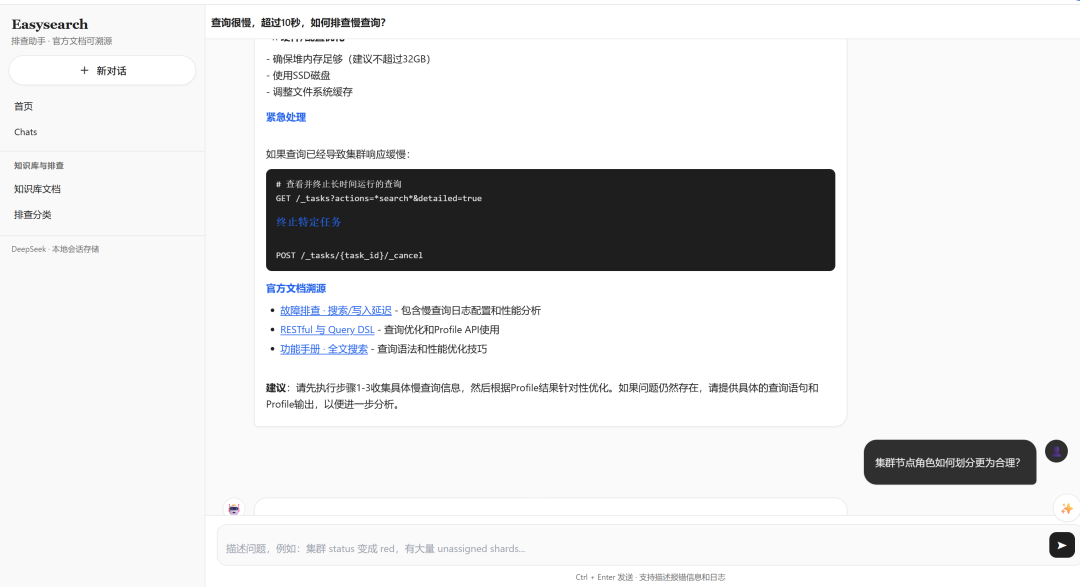
5)把前端做成"愿意用"的样子(Claude 风格参考)
我们前端参考 Claude 的核心不是"像",而是"顺手":
-
左侧稳定导航,主区专注内容。
-
浅灰+白卡,阅读压迫感低。
-
激活态、hover、分组层级清晰。
-
移动端可折叠侧栏,路径一致。
再配合 SSE 流式输出,用户体感就是:
它在认真思考,并且每秒都在给你进展。
这点看似 UI,实际直接影响"你愿不愿意连续追问三轮"。
6)会话本地化:SQLite 把工程复杂度压住
storage.py 用 SQLite 存 chat 和 message:
-
无需额外数据库服务。
-
CRUD 简单,索引够用。
-
单机工具场景下非常稳。
这对 0 到 1 很重要:
你不会把时间浪费在"先搭一套云数据库和鉴权体系"上。
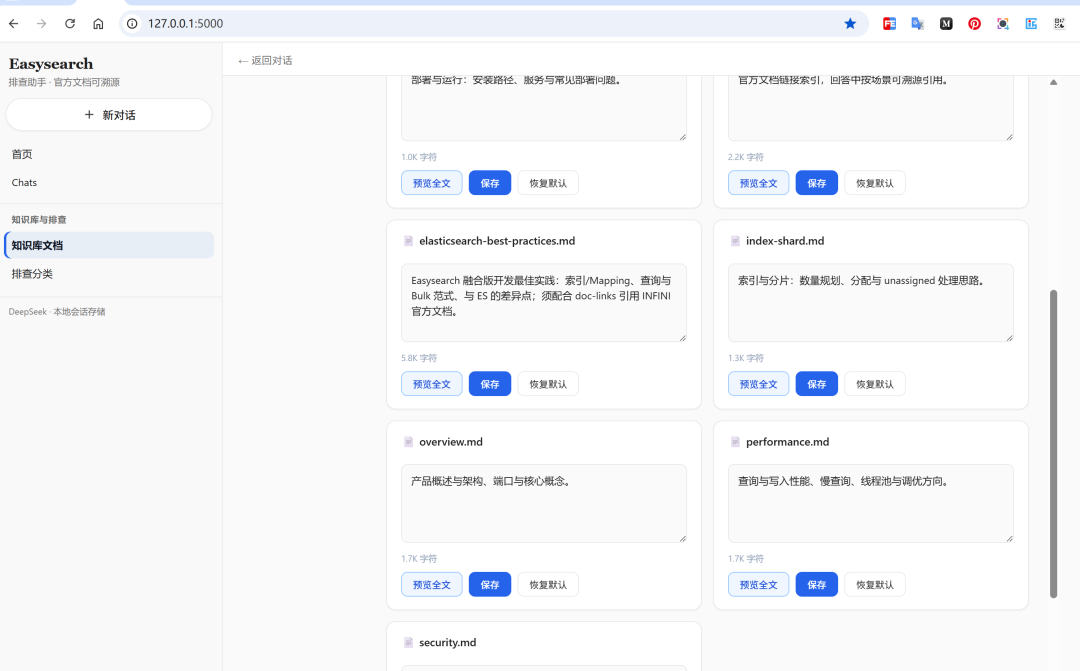
7)知识库可运营:不仅能看,还能改
系统提供知识库页面:
-
看每个 Skill 文件做什么。
-
预览 Markdown 全文。
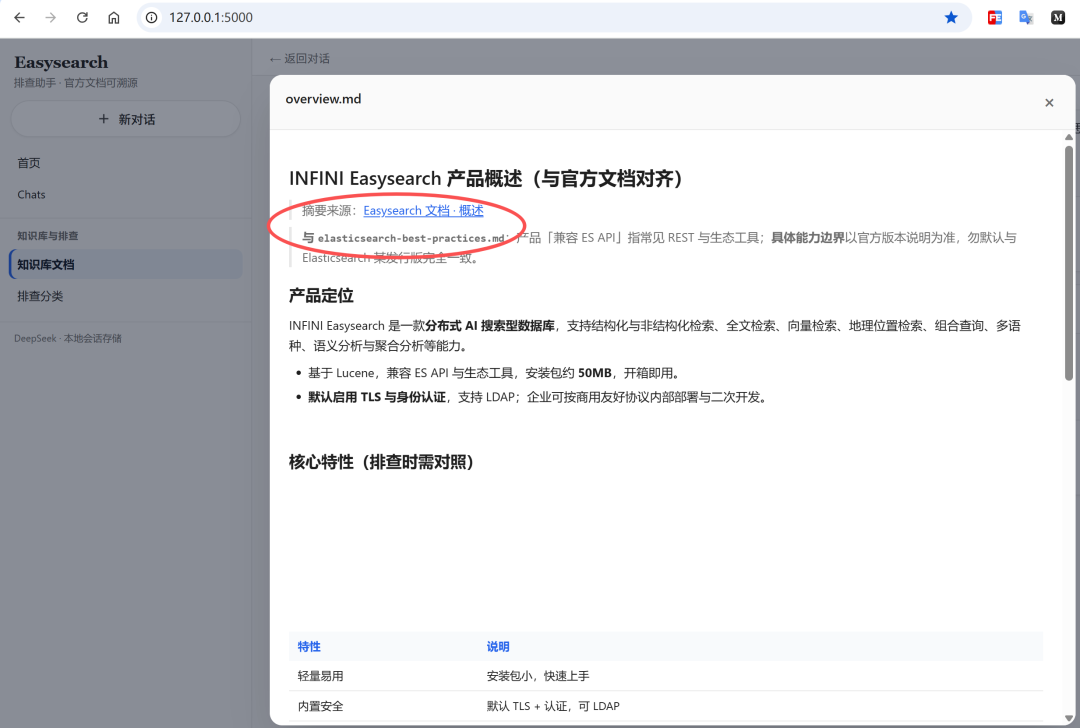
-
可编辑卡片描述并落盘到
data/kb_docs_overrides.json。
这意味着产品不是"写死 Prompt 的 Demo",而是一个能持续迭代的知识运营面板。
真实效果为什么"不输 RAG"?
你可以把答案质量拆成 4 个维度:
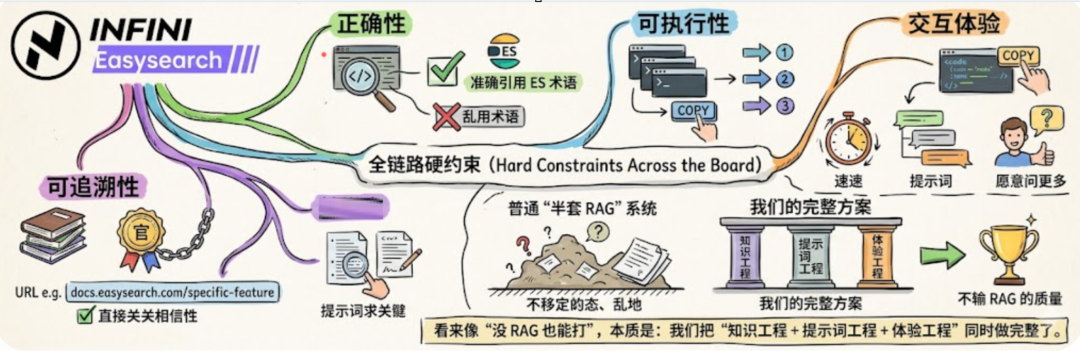
- 正确性:
是否贴合 Easysearch,不乱用 ES 术语。
- 可执行性:
命令能复制,步骤有先后。
- 可追溯性:
给了官方链接,且链接对题。
- 交互体验:
响应快、结构清晰、愿意继续问。
我们这套方案在这 4 维都做了硬约束。
而很多"半套 RAG"系统,反而死在检索质量不稳定和 Prompt 约束不够硬。
所以看起来像"没 RAG 也能打",本质是:
我们把"知识工程 + 提示词工程 + 体验工程"同时做完整了。
什么时候该上 RAG?别神化,也别排斥
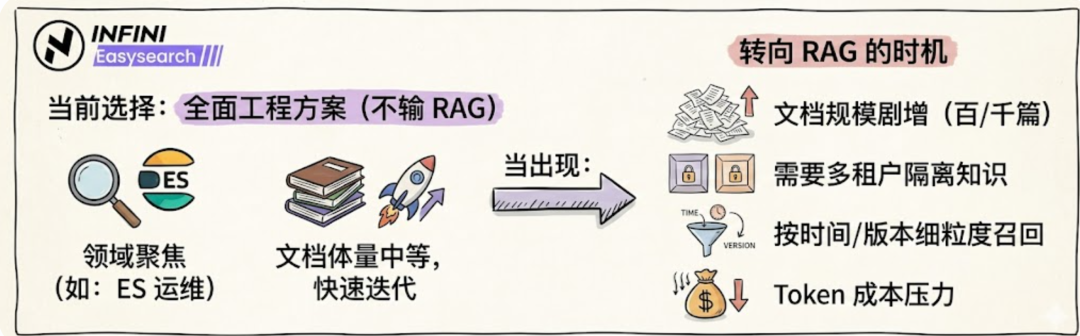
现在这套适合:
-
领域聚焦(如 Easysearch 运维)。
-
文档体量中等。
-
追求快速交付、快速迭代。
当你出现下面情况,就该把 RAG 提上日程:
-
文档规模显著增长(上百上千篇)。
-
需要多租户隔离知识。
-
需要按时间/版本做细粒度召回。
-
Token 成本开始成为压力点。
最稳的路线是:
先把当前这套跑到高可用,再引入"可观测的 RAG",而不是推倒重来。
如果要从 1 到 10,可以怎么升级?
务实路线图:
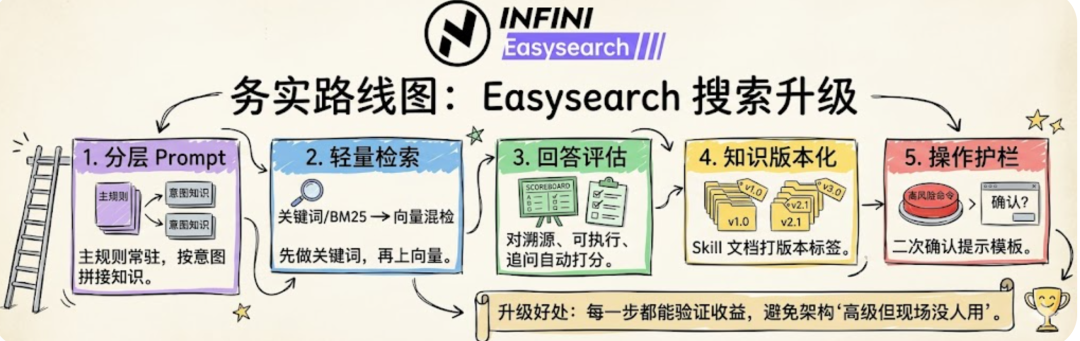
- 分层 Prompt:
主规则常驻,专题知识按意图拼接。
- 轻量检索:
先做关键词/BM25,再上向量混检。
- 回答评估:
对"溯源率、命令可执行率、追问命中率"做自动打分。
- 知识版本化:
Skill 文档按版本标签,回答注明依据版本。
- 操作护栏:
高风险命令加二次确认提示模板。
这样升级的好处是:
每一步都能验证收益,不会陷入"架构很高级,但现场没人用"。
最后一句
这套系统证明了一件很实在的事:
在垂直场景里,先把知识组织和规则约束做好,即使不上 RAG,也能交付接近甚至不输很多 RAG 系统的实际体验。
前端参考 Claude,让人愿意打开;
后端坚持 Easysearch 官方溯源,让人敢在生产照做。
这就是它真正有吸引力的地方:
不是"技术名词多",而是"拿来就能解决问题"。
告别全网瞎搜!Claude 风格的 Easysearch 企业级实战助手从 0 到 1 实现
Elasticsearch vs Easysearch 选型避坑指南
Easysearch 向量搜索 vs Elasticsearch:别再问"兼容不兼容"了,先看这篇