YOLOv3的提升效果
YOLOv3未变的
从YOLOv1开始,yolo算法就是通过划分单元格grid cell来做检测,只是划分的数量不一样。
采用"leaky ReLU"作为激活函数。
端到端进行训练,统一为回归问题。一个loss function搞定训练,只需关注输入端和输出端。
从yolo_v2开始,yolo就用batch normalization作为正则化、加速收敛和避免过拟合的方法,把BN层和leaky relu层接到每一层卷积层之后。
多尺度训练。想速度快点,可以牺牲准确率;想准确率高点,可以牺牲一点速度。
沿用了v2中边框预测的方法。
YOLOv3改进的
简要介绍
YOLOv3是目标检测领域的一个重要进步,它在YOLOv2的基础上引入了多项关键技术和模块,显著提升了检测性能。以下是YOLOv3的一些核心改进点:
1、多尺度特征融合: YOLOv3通过特征金字塔网络(FPN)结构,利用不同尺度的特征图进行检测,这使得它能够更好地识别不同大小的目标 。
2、Darknet-53主干网络: YOLOv3采用了更深的Darknet-53网络作为其主干网络,这有助于提取更丰富的特征信息 。
3、残差连接: 借鉴了ResNet的设计,YOLOv3在网络中引入了残差连接,这有助于缓解深层网络训练中的梯度消失问题,并提高网络性能 。
4、改进的损失函数: YOLOv3将损失函数从softmax的交叉熵损失切换为二分类交叉熵损失,这有助于解决类别不平衡问题,提高小目标的检测准确率 。
5、类别预测的改进: YOLOv3使用独立的Logistic回归分类器代替了softmax来预测类别,这使得模型能够更好地处理多标签分类问题 。
6、多尺度训练: YOLOv3采用不同分辨率的图像进行训练,提高了模型对不同尺寸目标的泛化能力 。
7、数据增强: YOLOv3在训练过程中应用了大量的数据增强技术,如随机缩放、裁剪和颜色扭曲,这有助于提高模型的鲁棒性 。
**8、锚框尺寸的优化:**YOLOv3根据数据集的特点动态调整锚框的大小和比例,以提高检测精度 。
1、 Bounding Box Prediction 边界框预测
YOLO3延续了K-means聚类得到先验框的尺寸方法,为每种下采样尺度设定3种先验框,总共聚类出9种尺寸的先验框 。在COCO数据集这9个先验框是:(10x13),(16x30),(33x23),(30x61),(62x45),(59x119),(116x90),(156x198),(373x326)。 分配上,在最小的13*13特征图上(有最大的感受野)应用较大的先验框(116x90),(156x198),(373x326),适合检测较大的对象。中等的26*26特征图上(中等感受野)应用中等的先验框(30x61),(62x45),(59x119),适合检测中等大小的对象。较大的52*52特征图上(较小的感受野)应用较小的先验框(10x13),(16x30),(33x23),适合检测较小的对象。

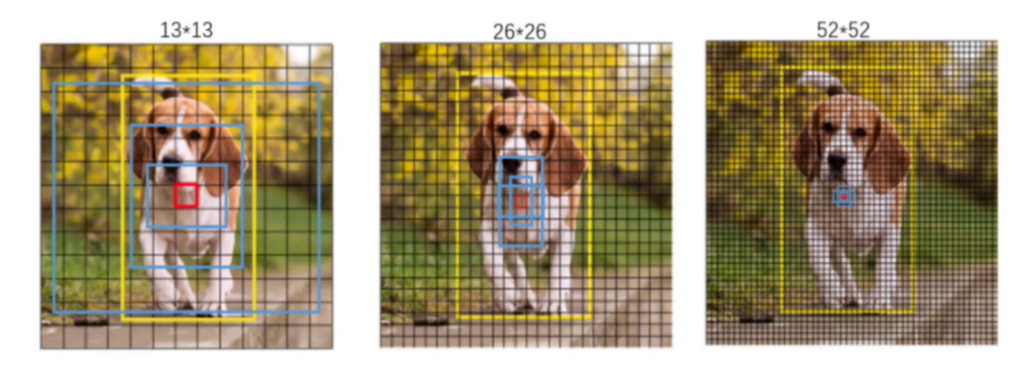
2、分类器的改变
YOLOv3用多个独立的Logistic分类器替代了传统目标检测模型中常用的Softmax分类器
Softmax函数将神经网络的输出转换为概率分布,所有类别的概率之和为1。然而,Softmax函数的是每个样本只属于一个类别。但在更复杂的目标检测场景中,一个物体可能同时属于多个类别,例如一个人可能同时被标记为"人"和"行人"。这种情况下,Softmax函数就不再适用,因为它会强制每个样本只属于一个类别。
在Logistic分类器(逻辑回归)中,每个类别的预测是独立进行的。对于输入样本,分类器会为每个类别计算一个概率值,表示该样本属于该类别的可能性。
Logistic分类器通常使用Sigmoid函数(也称为Logistic函数)作为激活函数。Sigmoid函数将神经网络的输出映射到(0, 1)区间,表示样本属于某个类别的概率。Sigmoid函数的数学表达式为如下图,其中,z是神经网络的原始输出。
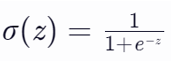
示例:
假设有一个图像分类任务,需要识别图像中是否包含"猫"、"狗"和"动物"三种动物。使用Logistic分类器时,模型会为每个类别(猫、狗、动物)分别计算一个概率值。例如:
图像A:猫的概率=0.8,狗的概率=0.3,动物的概率=0.7
图像B:猫的概率=0.2,狗的概率=0.7,动物的概率=0.6
设定阈值为0.5,则:
图像A会被标记为"猫"(因为猫的概率>0.5)也会标记为动物,而不会被标记为"狗" (因为它们的概率<0.5)。
图像B会被标记为"狗"和"动物"(因为它们的概率都>0.5),而不会被标记为"猫"(因为猫的概率<0.5)。
3、网络的改进
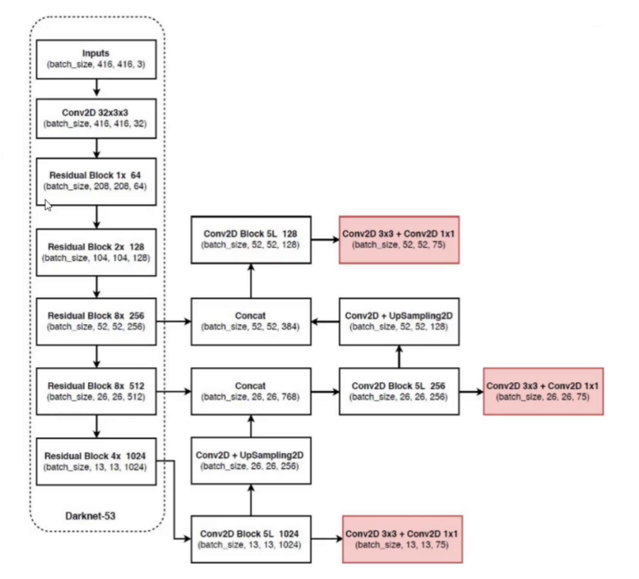
YOLOv3的第一处改进便是换上了更好的backbone网络:DarkNet53 。相较于YOLOv2中所使用的DarkNet19,新的网络使用了更多的卷积------53层卷积,同时,添加了残差网络中的残差连结结构,以提升网络的性能。
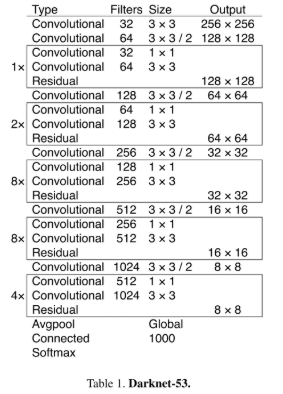
如上图, 这个网络主要是由一系列的1x1和3x3的卷积层组成,没有池化层和全连接层,全部卷积,卷积层仍旧是线性卷积、BN层以及LeakyReLU激活函数的串联组合。下采样通过stride为2来实现。
4、Feature Extractor 特征提取
使用了新的网络,新网络是YOLOv2中使用的网络、Darknet-19和新式的Darknet网络之间的一种混合方法。我们的网络使用连续的3 × 3 3×33×3和1 × 1 1×11×1卷积层,但现在也有一些快捷连接,而且明显更大。它有53个卷积层,所以我们把它叫做Darknet-53
将darknet-19里加入了ResNet残差连接,改进之后的模型叫Darknet-53 Darknet-53主要做了如下改进:
(1)没有采用最大池化层,转而采用步长为2的卷积层进行下采样。
(2)为了防止过拟合,在每个卷积层之后加入了一个BN层和一个LeakyReLU。
(3)引入了残差网络的思想,目的是为了让网络可以提取到更深层的特征,同时避免出现梯度消失或爆炸。
(4)将网络的中间层和后面某一层的上采样进行张量拼接,达到多尺度特征融合的目的。
YOLOv3的网络架构
总结
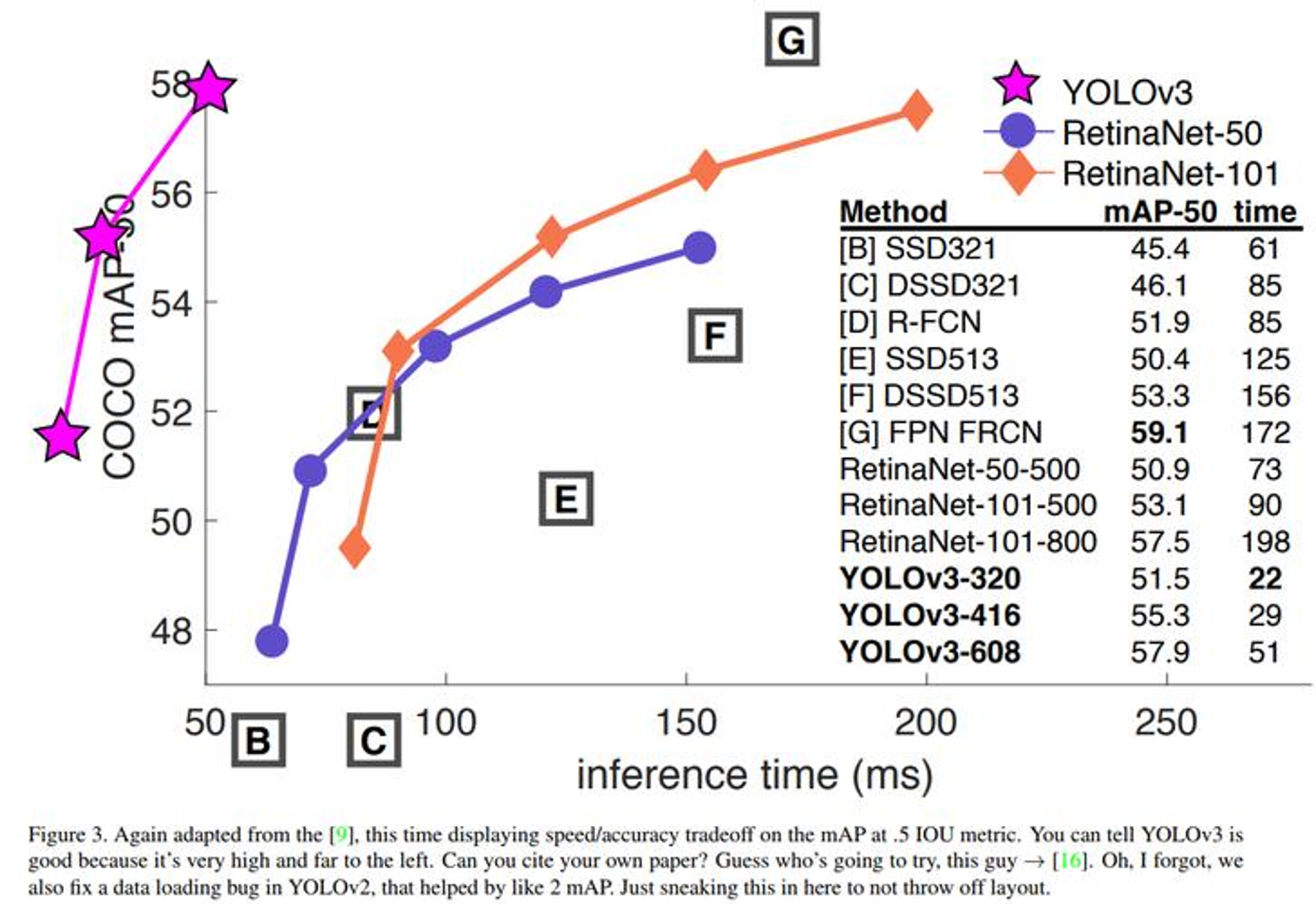
YOLOv3 擅于预测出合适的目标,但无法预测出非常精准的边界框。YOLOv3 小目标预测能力提升,但中大目标的预测反而相对较差。若将速度考量进来,YOLOv3 整体来说表现非常出色。
YOLOv3在小目标\密集目标的改进:
1、 grid cell个数增加,YOLOv1(7×7),YOLOv2(13×13),YOLOv3(13×13+26×26+52×52)
2、 YOLOv2和YOLOv3可以输入任意大小的图片,输入图片越大,产生的grid cell越多,产生的预测框也就越多
3、 专门小目标预先设置了一些固定长宽比的anchor,直接生成小目标的预测框是比较难的,但是在小预测框基础上再生成小目标的预测框是比较容易的
4、 多尺度预测(借鉴了FPN),既发挥了深层网络的特化语义特征,又整合了浅层网络的细腻度的像素结构信息
5、 对于小目标而言,边缘轮廓是非常重要的,即浅层网络的边缘信息。在损失函数中有着惩罚小框项
**6、**网络结构:网络加了跨层连接和残差连接(shortcut connection),这样可以整合各个层的特征,这样使得网络本身的特征提取能力提升了。