
最近,月之暗面(Moonshot AI)正式开源了新一代模型 Kimi K2.6,同时在官网 Kimi.com、Kimi App、Kimi API 以及 Kimi Code 中全面上线。 它不仅是一个大参数 MoE 模型,更是一个从架构设计开始就面向「长程编码 + Agent 编排」的原生多模态 Agentic 模型,在长序列编码、Coding-Driven Design、Agent Swarm 和 Proactive Agents 等方向上都做了非常激进的工程投入。
如果你正在做 RAG 系统、代码智能体、Agent 编排平台,或者是 Cursor / VSCode 这类 IDE 场景里的长程编程助手,K2.6 非常值得单独拿出来研究和实测。
一、模型定位:原生多模态 Agentic 大模型
官方给 Kimi K2.6 的定位是:"open‑source, native multimodal agentic model"。 简单翻译一下,几个关键词就很关键:
-
Open-source:开源权重,方便本地和私有化部署。
-
Native multimodal:不仅支持文本,还支持图片和视频输入,用 MoonViT 视觉编码器做统一表征。
-
Agentic:从一开始就为工具调用、长链路推理、Agent Swarm 以及持续运行的 Proactive Agents 设计,而不是单纯的「聊天/补全模型再外挂一个工具层」。
从产品形态上看,K2.6 目前已经全面接入:
-
Kimi.com / Kimi App(面向终端用户);
-
Kimi API 与 Kimi Code(面向开发者和工程团队)。
二、核心能力:长程编码 + Coding-Driven Design + Agent Swarm
1. 长程编码:从 4k 行代码到 12 小时持续执行
Kimi 官方在 Tech Blog 里给了几个非常硬核的长程编码案例。
-
在 Mac 本地自动下载并部署 Qwen3.5‑0.8B ,用 Zig 语言重写和优化推理逻辑,整个流程涉及 4000+ 次工具调用、超过 12 小时持续执行、14 轮迭代。
-
在此过程中,将推理吞吐从约 15 tokens/s 提升到约 193 tokens/s,最终性能比 LM Studio 还快约 20%。
-
这说明 K2.6 在「跨语言、跨工具链、跨上下文」的长链路工程任务上具有很强的泛化能力,而不仅仅是做几道 LeetCode。
另一个经典案例是对 exchange-core(一个已经高度优化的开源交易撮合引擎)进行系统级性能重构:
-
连续 13 小时 执行,
-
尝试 12 套不同优化策略 ,累计发起上千次工具调用,改动超过 4000 行代码;
-
分析 CPU 和内存分配 flame graph,重新设计内核线程拓扑,从 4ME+2RE 调整为 2ME+1RE;
-
在一个已经接近物理瓶颈的系统上,依然挖出了 185% 中位吞吐提升 (0.43 → 1.24 MT/s)和 133% 性能吞吐提升(1.23 → 2.86 MT/s)。
这些案例非常适合作为「长程编码Agent」的实证 benchmark,比单纯看 SWE‑Bench 之类指标更接近真实工程环境。
2. Coding‑Driven Design:从一句话到可上线页面
在前端与全栈方向,K2.6 提出的一个关键词是 Coding‑Driven Design。
-
通过非常简单的自然语言提示(甚至配合图片/视频输入),就能生成结构清晰、具备美学考量的完整前端界面;
-
自动生成 hero 区块、栅格布局、交互元素、复杂动画(包括滚动触发),并且可以调用图像/视频生成工具产出统一风格的视觉素材;
-
不仅是静态页面,还能一站式补全轻量级全栈流程(认证、用户交互、数据库读写等),适合做内部工具和 MVP Demo。
官方内部建立了 Kimi Design Bench,从「视觉输入任务」「落地页构造」「全栈应用开发」「通用创意编程」四个方向评估模型表现,相比 Google AI Studio 等方案,K2.6 在多个子项上表现非常亮眼。
3. Agent Swarm 2.0:300 个子 Agent,4000 步并行编排
在 K2.5 时代,Kimi 首次公开了 Agent Swarm 预研版本;到 K2.6,这套系统直接升级为高并发、大规模的 Agent Swarm 2.0。
-
支持 最多 300 个子 Agent 并行运行 ,总共最高 4000 个协作步骤;
-
可以动态拆分任务到不同领域的专门 Agent(检索、长文档分析、代码修改、报告撰写等),并行执行后再统一汇总;
-
一个完整的 Agent Swarm Run 可以在一次执行中直接产出「长文档 + 网站 + PPT + 表格」等多种形态结果。
更有意思的是,K2.6 支持把高质量的 PDF、PPT、Excel、Word 等文件「技能化」,转成可复用的 Skills:模型不仅记住其中的结构和风格,还能在后续任务中复刻同档次的排版和表达风格。
4. Proactive Agents:真正 24/7 挂机工作的 AI
K2.6 还专门强调了「主动型 Agent」(Proactive Agents)的能力,典型代表是 OpenClaw 和 Hermes 这类跨应用的持续运行智能体。
-
官方 RL 基建团队搭建了一个基于 K2.6 的运维 Agent,让它 连续自主运行 5 天,负责监控、告警处理和系统运维;
-
这个 Agent 需要长期维护上下文,处理多线程任务,从「接收告警 → 分析原因 → 调用脚本 → 验证恢复」闭环执行;
-
在内部 Claw Bench 评测体系上,K2.6 在任务完成率和工具调用准确率上,相比 K2.5 有大幅度提升,尤其是在需要长期无人值守的工作流上。
三、模型架构与规格:为工具调用和长上下文而生
模型结构信息主要集中在官方 Hugging Face 模型卡和技术说明里,这里做一个面向开发者的简要总结。
-
架构:Mixture‑of‑Experts(MoE)结构;
-
总参数规模 :约 1T,激活参数约 32B,在保证效果的同时兼顾推理成本;
-
层数:61 层,其中包含 1 层 Dense;
-
专家数与路由:384 个专家,每个 token 选择 8 个专家,还有 1 个 shared expert;
-
注意力机制:使用 MLA(类似高效注意力变体),hidden dim 为 7168,64 个 attention heads;
-
上下文长度 :官方支持 256K tokens,在长文档分析、长程代码库修改场景非常实用;
-
激活函数:SwiGLU;
-
视觉编码器:MoonViT,参数量约 400M,用来处理图像和视频输入。
总体来说,这是一套典型的「大规模 MoE + 超长上下文 + 原生多模态」设计,并且在 Agent/工具调用场景做了大量微调和工程优化。
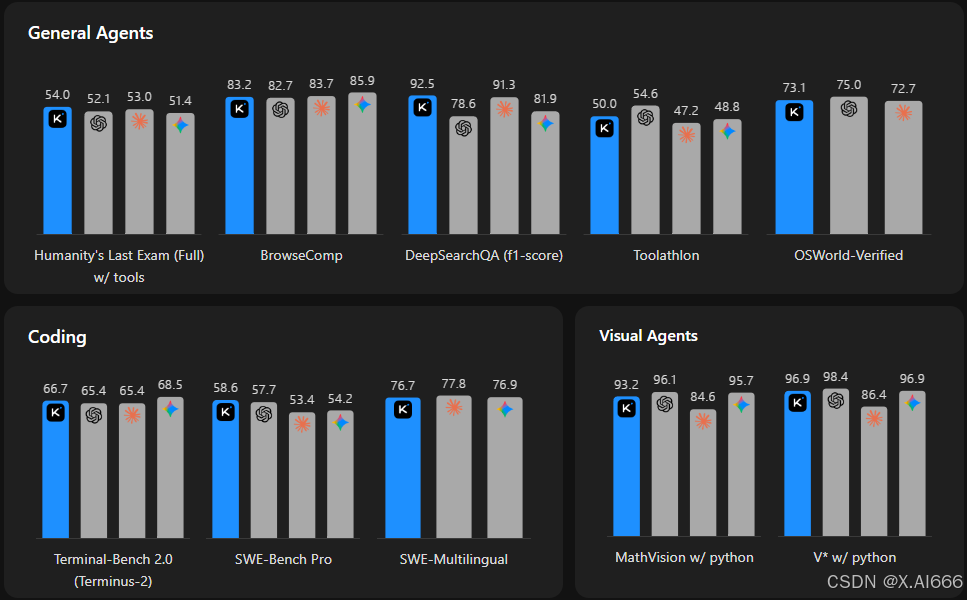
四、基准测试表现:对标 GPT‑5.4、Claude Opus 4.6、Gemini 3.1 Pro
在官方 Tech Blog 中,Kimi 给出了非常详细的对比表,覆盖 Agentic、Coding、Reasoning & Knowledge、Vision 等多个方向。
几个比较关键的点摘出来:
-
Agentic 任务
-
Humanity's Last Exam Full(w/ tools):K2.6 得分 54.0,高于 GPT‑5.4 的 52.1 和 Gemini 3.1 Pro 的 51.4,相比 K2.5 的 50.2 提升明显。
-
DeepSearchQA(f1-score):K2.6 为 92.5,高于 GPT‑5.4 的 78.6 与 Gemini 3.1 Pro 的 81.9,同时也超过 K2.5 的 89.0。
-
-
编码相关
-
Terminal‑Bench 2.0(Terminus‑2 框架):K2.6 = 66.7,优于 K2.5 的 50.8,也略高于 GPT‑5.4 的 65.4。**
-
SWE‑Bench Pro:K2.6 = 58.6,对比 GPT‑5.4 的 57.7、Claude Opus 4.6 的 53.4、Gemini 3.1 Pro 的 54.2,都有优势。
-
SWE‑Bench Multilingual / Verified 等指标上,K2.6 相比 K2.5 也有明显提升,在多语言和严格验证场景中更加稳定。
-
-
推理与知识
-
AIME 2026:K2.6 取得 96.4 的成绩,虽然略低于 GPT‑5.4 的 99.2,但在开源模型中非常靠前。
-
GPQA‑Diamond、HMMT 等基准上,K2.6 相比 K2.5 全面提升。
-
-
视觉多模态
-
MathVision(w/ python):K2.6 达到 93.2,在需要视觉+数学推理的任务上接近顶级闭源模型表现。
-
MMMU‑Pro、CharXiv、V* 等一系列视觉推理基准上,K2.6 在开源阵营中属于第一梯队。
-
官方也说明:K2.6 与 K2.5 均使用 Thinking 模式,Claude Opus、GPT‑5.4、Gemini 3.1 Pro 分别使用各自的高推理/高努力配置,并统一了 temperature、top‑p 和上下文等测试参数,尽量保证对比公平性。
五、部署与使用:API、推理引擎与 Vendor Verifier
1. 官方 API 与推理推荐
Kimi 官方建议,如果你希望复现论文/官网公布的基准成绩 ,应该优先使用 官方 API(platform.moonshot.ai),因为内部做了完整的 Serving、量化、缓存与工具链优化。
对于第三方推理服务,官方提供了 Kimi Vendor Verifier(KVV),用来评估不同服务商在真实任务上的表现,从而筛选出「性能不掉线」的供应商。
在本地或自建集群部署方面:
-
K2.6 与 K2.5 采用相同架构和权重格式,部署方式可以复用;
-
官方推荐的推理引擎包括 vLLM、SGLang、KTransformers 等;
-
Transformers 版本要求
>= 4.57.1, < 5.0.0,模型卡中给出了示例配置与部署指引文档。
2. 推理精度 vs 性能:原生 INT4 量化
K2.6 延续了 Kimi‑K2‑Thinking 中的 Native INT4 量化方案:在保证绝大部分任务精度基本不损失的前提下,显著降低显存占用和推理成本,更适合在单机或者轻量 GPU 集群上落地。
六、调用示例:Thinking 模式、Instant 模式与多模态
官方推荐使用 OpenAI/Anthropic 兼容的 Chat Completions 接口来调用 K2.6。
一个典型的调用思路大概是这样(伪代码):
python
from openai import OpenAI
client = OpenAI(base_url="https://api.moonshot.ai/v1", api_key="YOUR_API_KEY")
def chat_with_kimi(model_name: str):
messages = [
{"role": "system", "content": "You are Kimi, an AI assistant created by Moonshot AI."},
{"role": "user", "content": "帮我分析一下这个仓库的性能瓶颈,并给出优化建议。"},
]
# Thinking 模式:带可观测推理过程
resp_thinking = client.chat.completions.create(
model=model_name,
messages=messages,
max_tokens=4096,
)
print(resp_thinking.choices[0].message.reasoning)
print(resp_thinking.choices[0].message.content)
# Instant 模式:关闭思维链,追求极致延迟
resp_instant = client.chat.completions.create(
model=model_name,
messages=messages,
max_tokens=4096,
extra_body={"thinking": {"type": "disabled"}},
)
print(resp_instant.choices[0].message.content)-
Thinking 模式 :会在
message.reasoning中返回完整推理过程,适合调试 Agent 和编码任务; -
Instant 模式 :通过
extra_body关闭 thinking,用于对延迟敏感的在线服务,代价是少了可观测的思维链。
在视觉与视频方面,K2.6 支持直接传入 base64 编码的图片/视频数据,消息体使用 image_url / video_url 类型即可,这在官网示例和 Hugging Face 模型卡中都有详细演示。
此外,K2.6 还支持 preserve_thinking 模式,在多轮对话中保留完整思维链,让 Agent 在长任务中记得「自己刚才是怎么推理的」,特别适合作为 Coding Agent 的核心大脑。
七、对开发者意味着什么?
从 Coder/Agent 平台开发者的视角,Kimi K2.6 带来的价值可以简单概括为三点:
-
用得起的高阶 Agent 能力
在很多 Agent 基准(DeepSearchQA、HLE w/ tools、Claw Eval 等)上接近甚至赶上闭源 SOTA,同时开源权重+支持自建推理,整体 TCO 会比直接用顶级闭源模型低一个量级。
-
真正可用的长程编码和多模态场景
从 Qwen3.5 本地部署到 exchange-core 性能重构,再到全栈 Web 界面一键生成,官方给了足够多的真实项目案例,证明 K2.6 不只是「跑基准测试好看」。
-
Agent Swarm + Proactive Agents 的工程落地样板
无论你是做 RAG 中心的系统,还是做 Workflow Orchestrator,K2.6 的 Agent Swarm 和 Claw Groups 设计都很值得借鉴:300 子 Agent、4000 步并行、多端多模型混合、支持人机协作,基本把「下一代 AI 团队协作形态」提前展示了一遍。
八、总结
如果说 K2.5 还是在「证明国产开源模型可以和顶级闭源对线」,那么 K2.6 已经明确把重心放在 "把 Agent 这件事做到极致" 上了。
-
它用真实的工程案例说明:长程编码和性能优化不是 PPT,而是可以让模型连续跑十几个小时、改上千行代码并显著提升吞吐的东西。
-
它用 Agent Swarm、Proactive Agents、Claw Groups 等实践展示了未来「一个人 + 一群 Agent + 一堆工具」的协作范式。
-
它用开源权重 + 官方 API + Vendor Verifier 打通了从研究到生产部署的完整链路。
对于正在做 AI 代码助手、RAG Agent 平台、自动化运维/交易/风控系统的开发者来说,Kimi K2.6 绝对值得在你的模型候选列表里排到前列,并且亲手跑一遍长程任务 Benchmark。