目录
[Maven 坐标](#Maven 坐标)
[Maven 依赖](#Maven 依赖)
[Maven 仓库](#Maven 仓库)
[Maven 生命周期](#Maven 生命周期)
[Git 与其他版本管理系统的主要区别](#Git 与其他版本管理系统的主要区别)
[Git 三种状态](#Git 三种状态)
[Git 怎么用?](#Git 怎么用?)
[获取 Git 仓库](#获取 Git 仓库)
[容器 VS 虚拟机](#容器 VS 虚拟机)
[🏠 物理机(Physical Machine)](#🏠 物理机(Physical Machine))
[🏢 虚拟机(Virtual Machine)](#🏢 虚拟机(Virtual Machine))
[🛏️ 容器(Container)](#🛏️ 容器(Container))
[Docker 是什么?](#Docker 是什么?)
[Docker 思想](#Docker 思想)
[Docker 特点](#Docker 特点)
[为什么用 Docker](#为什么用 Docker)
[Docker 基本概念](#Docker 基本概念)
[Image、Container 和 Repository 的关系](#Image、Container 和 Repository 的关系)
[Build Ship and Run](#Build Ship and Run)
[Docker 命令](#Docker 命令)
[Docker 数据管理](#Docker 数据管理)
[Docker Compose](#Docker Compose)
[对比 Docker Compose](#对比 Docker Compose)
[Docker 底层原理](#Docker 底层原理)
😺Maven
Apache Maven 的本质是一个软件项目管理和理解工具。基于项目对象模型 (Project Object Model,POM) 的概念,Maven 可以从一条中心信息管理项目的构建、报告和文档。
什么是 POM? 每一个 Maven 工程都有一个 pom.xml 文件,位于根目录中,包含项目构建生命周期的详细信息。通过 pom.xml 文件,我们可以定义项目的坐标、项目依赖、项目信息、插件信息等等配置。
Maven 的主要作用主要有 3 个:
- 项目构建:提供标准的、跨平台的自动化项目构建方式。
- 依赖管理:方便快捷的管理项目依赖的资源(jar 包),避免资源间的版本冲突问题。
- 统一开发结构:提供标准的、统一的项目结构。
Maven 坐标
项目中依赖的第三方库以及插件可统称为构件。每一个构件都可以使用 Maven 坐标唯一标识,坐标元素包括:
- groupId(必须): 定义了当前 Maven 项目隶属的组织或公司。groupId 一般分为多段,通常情况下,第一段为域,第二段为公司名称。域又分为 org、com、cn 等,其中 org 为非营利组织,com 为商业组织,cn 表示中国。以 apache 开源社区的 tomcat 项目为例,这个项目的 groupId 是 org.apache,它的域是 org(因为 tomcat 是非营利项目),公司名称是 apache,artifactId 是 tomcat。
- artifactId(必须):定义了当前 Maven 项目的名称,项目的唯一的标识符,对应项目根目录的名称。
- version(必须):定义了 Maven 项目当前所处版本。
- packaging(可选):定义了 Maven 项目的打包方式(比如 jar,war...),默认使用 jar。
- classifier(可选):常用于区分从同一 POM 构建的具有不同内容的构件,可以是任意的字符串,附加在版本号之后。
举个例子(引入阿里巴巴开源的 EasyExcel):
XML
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>easyexcel</artifactId>
<version>3.1.1</version>
</dependency>Maven 依赖
- dependencies:一个 pom.xml 文件中只能存在一个这样的标签,是用来管理依赖的总标签。
- dependency:包含在 dependencies 标签中,可以有多个,每一个表示项目的一个依赖。
- groupId,artifactId,version(必要):依赖的基本坐标,对于任何一个依赖来说,基本坐标是最重要的,Maven 根据坐标才能找到需要的依赖。我们在上面解释过这些元素的具体意思,这里就不重复提了。
- type(可选):依赖的类型,对应于项目坐标定义的 packaging。大部分情况下,该元素不必声明,其默认值是 jar。
- scope(可选):依赖的范围,默认值是 compile。
- optional(可选):标记依赖是否可选
- exclusions(可选):用来排除传递性依赖,例如 jar 包冲突
Maven 仓库
在 Maven 世界中,任何一个依赖、插件或者项目构建的输出,都可以称为 构件 。
坐标和依赖是构件在 Maven 世界中的逻辑表示方式,构件的物理表示方式是文件,Maven 通过仓库来统一管理这些文件。 任何一个构件都有一组坐标唯一标识。有了仓库之后,无需手动引入构件,我们直接给定构件的坐标即可在 Maven 仓库中找到该构件。
Maven 仓库分为:
- 本地仓库:运行 Maven 的计算机上的一个目录,它缓存远程下载的构件并包含尚未发布的临时构件。
- 远程仓库:官方或者其他组织维护的 Maven 仓库。
Maven 远程仓库可以分为:
- 中央仓库:这个仓库是由 Maven 社区来维护的,里面存放了绝大多数开源软件的包,并且是作为 Maven 的默认配置,不需要开发者额外配置。
- 私服:私服是一种特殊的远程 Maven 仓库,它是架设在局域网内的仓库服务,私服一般被配置为互联网远程仓库的镜像,供局域网内的 Maven 用户使用。
- 其他的公共仓库:有一些公共仓库是为了加速访问(比如阿里云 Maven 镜像仓库)或者部分构件不存在于中央仓库中。
Maven 依赖包寻找顺序:
- 先去本地仓库找寻,有的话,直接使用。
- 本地仓库没有找到的话,会去远程仓库找寻,下载包到本地仓库。
- 远程仓库没有找到的话,会报错。
Maven 生命周期
Maven 的生命周期就是为了对所有的构建过程进行抽象和统一,包含了项目的清理、初始化、编译、测试、打包、集成测试、验证、部署和站点生成等几乎所有构建步骤。
| 生命周期 | 作用 |
|---|---|
| default | 核心构建流程(最重要) |
| clean | 清理构建产物 |
| site | 生成项目文档站点 |
default 生命周期:
validate 校验项目→ compile 编译源码→ test 执行单元测试→ package 打包(JAR/WAR)→ verify 校验包→ install 安装到本地仓库→ deploy 发布到远程仓库
Maven 生命周期是对项目构建流程的抽象和统一,主要包括 default、clean 和 site 三个生命周期。其中 default 是核心生命周期,包含从编译、测试、打包到部署的完整流程。每个生命周期由多个有序阶段组成,执行某个阶段时会自动执行之前的所有阶段。
😺Git
Git 是一个典型的分布式版本控制系统。
在分布式版本控制系统中,客户端在克隆仓库时不仅获取最新代码,还会获取整个版本历史,因此本地仓库是一个完整副本。这种设计避免了单点故障问题,即使中央服务器宕机,也可以通过任意一个本地仓库恢复整个代码库。同时,这也使得大多数操作可以在本地完成,提高了性能和离线能力。
Q:那 GitHub 是不是中心?
A:Git 是分布式版本控制系统,每个开发者本地都有完整仓库,所以本质上没有中心节点,是去中心化的。GitHub 只是团队协作中常用的远程仓库,只是一个"协作中心",相当于一个大家共享的代码中转站,但不是必须的。
Git 与其他版本管理系统的主要区别
Git 与传统版本控制系统(如 SVN)的主要区别在于数据存储方式。
传统系统采用基于差异(diff)的方式,只记录文件的变化,这样的话,当我们的增量特别特别多的时候,要得到最终的文件会耗费大量时间和性能。
而 Git 采用快照(snapshot)的方式,每次提交都会记录整个项目的状态。不过为了节省空间,对于未修改的文件,Git 会复用之前的版本,而不是重复存储。这种设计使得 Git 在版本恢复、分支操作和性能方面更高效。
Git 三种状态
Git 有三种状态,你的文件可能处于其中之一:
- 已修改(modified):已修改表示修改了文件,但还没保存到数据库中。
- 已暂存(staged):表示对一个已修改文件的当前版本做了标记,使之包含在下次提交的快照中。
- 已提交(committed):数据已经安全的保存在本地数据库中。
由此引入 Git 项目的三个工作区域的概念:工作目录(Working Directory) 、暂存区域(Staging Area) 以及 Git 仓库(.git directory)。
基本的 Git 工作流程如下:
- 在工作目录中修改文件。
- 暂存文件,将文件的快照放入暂存区域。
- 提交更新,找到暂存区域的文件,将快照永久性存储到 Git 仓库目录。
Q:为什么要有"暂存区"?
A:暂存区的存在使得开发者可以精确控制每次提交的内容,是 Git 区别于其他版本控制系统的重要设计。
Git 怎么用?
获取 Git 仓库
- 在现有目录中初始化仓库:进入项目目录运行 git init 命令,该命令将创建一个名为 .git 的子目录。
- 从一个服务器克隆一个现有的 Git 仓库:
git clone url 自定义本地仓库的名字: git clone url directoryname
记录每次更新到仓库
bash
工作区(Working Directory)
↓ add
暂存区(Staging Area)
↓ commit
本地仓库(Repository)- 检测当前文件状态 : git status
- 提出更改(把它们添加到暂存区):git add filename (针对特定文件)、git add *(所有文件)、git add *.txt(支持通配符,所有 .txt 文件)
- 忽略文件:.gitignore 文件
- 提交更新: git commit -m "代码提交信息" (每次准备提交前,先用 git status 看下,是不是都已暂存起来了, 然后再运行提交命令 git commit)
- 跳过使用暂存区域更新的方式 : git commit -a -m "代码提交信息"。 git commit 加上 -a 选项,Git 就会自动把所有已经跟踪过的文件暂存起来一并提交,从而跳过 git add 步骤。
- 移除文件:git rm filename (从暂存区域移除,然后提交。)
- 对文件重命名:git mv README.md README(这个命令相当于mv README.md README、git rm README.md、git add README 这三条命令的集合)
推送改动到远程仓库
如果你还没有克隆现有仓库,并欲将你的仓库连接到某个远程服务器,你可以使用如下命令添加:git remote add origin <server> ,比如我们要让本地的一个仓库和 GitHub 上创建的一个仓库关联可以这样:git remote add origin https://github.com/Snailclimb/test.git
将这些改动提交到远端仓库:git push origin master (可以把 master 换成你想要推送的任何分支)如此你就能够将你的改动推送到所添加的服务器上去了。
查看提交历史
git log 会按提交时间列出所有的更新,最近的更新排在最上面。
只看某个人的提交记录:
bash
git log --author=bob撤销操作
bash
本地仓库(Repository)
↓ git reset (--soft / --mixed / --hard)
暂存区(Staging Area)
↓ git restore --staged / git reset file
工作区(Working Directory)
↓ git restore / git checkout --- 修改最后一次提交(commit)还未 push,漏加文件、改 commit message:
bash
git commit --amend
git add missing_file
git commit --amend❌ 不要对已经 push 的提交使用(会改历史)
- 取消暂存的文件(已 add 未 commit,从暂存区 → 工作区)
bash
git reset filename
新写法:git restore --staged file
git add a.txt
git reset a.txt- 丢弃工作区修改(未 add,恢复到最近一次 commit)
bash
git checkout -- filename
新写法:git restore file
git checkout -- a.txt- 强制回退(已 commit 未 push,危险操作)
假如你想丢弃你在本地的所有改动与提交,可以到服务器上获取最新的版本历史(拉远程),并将你本地主分支指向它(全部回滚):
bash
git fetch origin
git reset --hard origin/master分支
创建分支
bash
git branch test切换分支
bash
git checkout test
git checkout master合并分支
bash
git merge test😺Docker
Docker 是世界领先的软件容器平台。
容器
容器就是将软件打包成标准化单元,以用于开发、交付和部署。
- 容器镜像是轻量的、可执行的独立软件包 ,包含软件运行所需的所有内容:代码、运行时环境、系统工具、系统库和设置。
- 容器化软件适用于基于 Linux 和 Windows 的应用,在任何环境中都能够始终如一地运行。
- 容器赋予了软件独立性,使其免受外在环境差异(例如,开发和预演环境的差异)的影响,从而有助于减少团队间在相同基础设施上运行不同软件时的冲突。
容器 VS 虚拟机
容器和虚拟机都是用于实现资源隔离和应用部署的技术,但它们的实现方式不同。
虚拟机是基于硬件虚拟化技术,在物理机上通过 Hypervisor 虚拟出多台独立的虚拟机,每个虚拟机都有完整的操作系统和内核,因此隔离性强,但资源开销大、启动慢。
容器则是基于操作系统级虚拟化,多个容器共享宿主机内核,只打包应用及其依赖,不包含完整操作系统,因此更加轻量,启动速度快,资源利用率高。
在实际应用中,虚拟机更适合需要强隔离或不同操作系统的场景,而容器更适合微服务和快速部署的场景,两者可以互补共存。
🏠 物理机(Physical Machine)
- 独占硬件资源
- 无虚拟化层
- 性能最好,但资源利用率低,扩容困难
🏢 虚拟机(Virtual Machine)
- ✔ 强隔离(像独立机器)
- ✔ 可运行不同 OS(Linux / Windows)
- ❌ 重(每个 VM 都有 OS)
- ❌ 启动慢(分钟级)
bash
物理机
→ Hypervisor
→ VM1(OS + App)
→ VM2(OS + App)🛏️ 容器(Container)
- ✔ 轻量(无 OS)
- ✔ 秒级启动
- ✔ 高密度部署
- ❌ 隔离弱于 VM
- ❌ 依赖宿主内核(不能跨 OS)
bash
物理机
→ 操作系统(内核)
→ 容器1(App)
→ 容器2(App)Q:那我docker的时候为什么是在linux虚拟机上docker的?
A:Docker 本身不依赖虚拟机,而是依赖 Linux 内核。容器是基于操作系统级虚拟化实现的,需要使用 Linux 的 Namespace 和 Cgroup 等内核特性,因此必须运行在 Linux 环境中。如果是在 Windows 或 macOS 上使用 Docker,通常需要通过虚拟机来提供一个 Linux 环境,在该环境中运行 Docker。
Docker 是什么?
Docker 是一种开源的容器化平台,用于将应用及其依赖打包成一个标准化的镜像,并以容器的形式运行。它基于 Linux 内核的 Namespace 和 Cgroup 技术,实现了进程级的隔离和资源控制,属于操作系统级虚拟化。
Docker 的核心优势是可以保证应用在不同环境中的一致运行,同时具备轻量、启动快、易部署等特点,广泛应用于微服务架构和云原生开发中。
我们总是容易遇到【环境配置复杂 + 环境不一致导致程序跑不起来】这样的问题,它有个名字叫【环境问题 / 环境依赖地狱 Dependency Hell】,Docker 就是用来解决这个问题的,而且这就是 Docker 最核心的价值之一。
- 传统方式:手动安装 Java + MySQL + Redis + 配置环境变量 + 调整版本。人工操作多、容易出错、不可复制。
- Docker 方式:打包成镜像(Image)= 应用 + 依赖 + 环境 + 配置,docker run → 直接运行。 核心思想:把"环境"也一起打包带走。
Docker 思想
- 集装箱:就像海运中的集装箱一样,Docker 容器包含了应用程序及其所有依赖项,确保在任何环境中都能以相同的方式运行。
- 标准化:Docker 提供统一的构建、运行和分发机制,例如 Dockerfile、镜像仓库等,使开发、测试和运维流程统一。
- 隔离:每个 Docker 容器都在自己的隔离环境中运行,与宿主机和其他容器隔离。通过 Linux 的 Namespace 和 Cgroup 技术实现的,使不同容器之间互不影响。
Docker 特点
- 轻量 : 在一台机器上运行的多个 Docker 容器可以共享这台机器的操作系统内核;它们能够迅速启动,只需占用很少的计算和内存资源。镜像是通过文件系统层进行构造的,并共享一些公共文件。这样就能尽量降低磁盘用量,并能更快地下载镜像。
- 标准 : Docker 容器基于开放式标准,能够在所有主流 Linux 版本、Microsoft Windows 以及包括 VM、裸机服务器和云在内的任何基础设施上运行。
- 安全 : Docker 赋予应用的隔离性不仅限于彼此隔离,还独立于底层的基础设施。Docker 默认提供最强的隔离,因此应用出现问题,也只是单个容器的问题,而不会波及到整台机器。
为什么用 Docker
- 一致的运行环境:Docker 的镜像提供了除内核外完整的运行时环境,确保了应用运行环境一致性,从而不会再出现 "这段代码在我机器上没问题啊" 这类问题;
- 更快速的启动时间:可以做到秒级、甚至毫秒级的启动时间。大大的节约了开发、测试、部署的时间。
- 隔离性:避免公用的服务器,资源会容易受到其他用户的影响。
- 弹性伸缩,快速扩展:善于处理集中爆发的服务器使用压力;
- 迁移方便:可以很轻易的将在一个平台上运行的应用,迁移到另一个平台上,而不用担心运行环境的变化导致应用无法正常运行的情况。
- 持续交付和部署:使用 Docker 可以通过定制应用镜像来实现持续集成、持续交付、部署。
Docker 基本概念
Docker 中有非常重要的三个基本概念:
镜像(Image)、容器(Container)和仓库(Repository)。
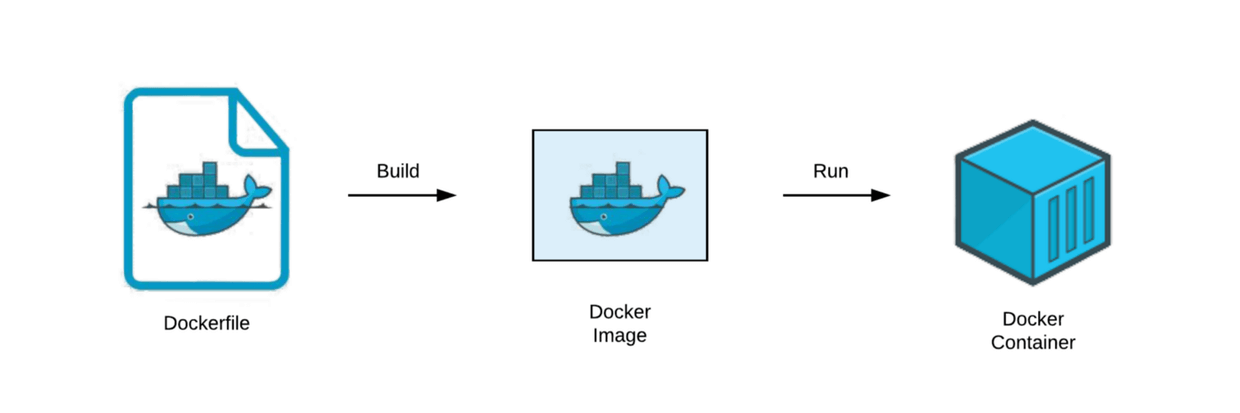
镜像(Image)
Docker 镜像是一个只读的文件系统,可以理解为一个 root 文件系统,包含应用运行所需的程序、依赖、配置和环境等内容。
镜像采用分层存储结构,每一层都是只读的,构建完成后不会再发生改变。新的镜像是在已有镜像基础上叠加新的层。
这种分层结构提高了镜像的复用性和构建效率,同时支持缓存机制。但需要注意的是,删除操作只是标记删除,并不会真正移除底层文件。
镜像本身是静态的,不能直接运行,必须通过 docker run 启动为容器,容器才是真正运行的实例。镜像是容器的模板,容器是镜像的运行实例。
镜像的核心价值在于实现"环境一致性"和"可复制部署",即一次构建,到处运行。
容器(Container):镜像运行时的实体
镜像(Image)和容器(Container)的关系,就像是面向对象程序设计中的 类 和 实例 一样,镜像是静态的定义,容器是镜像运行时的实体。容器可以被创建、启动、停止、删除、暂停等 。
容器基于镜像创建,镜像是只读的,而容器在其上增加了一层可写层,用于运行时数据存储。但该可写层的生命周期与容器一致,容器删除时数据也会丢失。
按照 Docker 最佳实践的要求,容器不应该向其存储层内写入任何数据 ,容器存储层要保持无状态化。所有的文件写入操作,都应该使用数据卷(Volume) ,它的读写会跳过容器存储层,直接对宿主发生读写,其性能和稳定性更高。数据卷的生存周期独立于容器,容器消亡,数据卷不会消亡。因此, 使用数据卷后,容器可以随意删除、重新 run ,数据却不会丢失。
仓库(Repository):集中存放镜像文件的地方
Docker 仓库是用于集中存储和分发镜像的服务,通常由 Registry、Repository 和 Tag 组成。
Registry 是镜像仓库服务,例如 Docker Hub;Repository 表示一个具体的软件仓库,通常包含该软件的多个版本镜像;Tag 用于标识镜像的具体版本。
一个 Docker Registry 中可以包含多个仓库(Repository);每个仓库可以包含多个标签(Tag);每个标签对应一个镜像。用户可以通过"仓库名:标签"的方式指定镜像版本,例如 mysql:8.0。如果不指定标签,默认使用 latest。
仓库可以分为公有仓库和私有仓库,公有仓库用于共享镜像,私有仓库用于企业内部管理镜像。
Q:Docker Hub 是什么?
A:Docker 官方提供的公共镜像仓库服务。
Image、Container 和 Repository 的关系
|------------|---------------|
| Dockerfile | 源代码 |
| Image | 已编译的程序 + 运行环境 |
| Container | 正在运行的进程 |
一句话总结:写 Dockerfile → build 镜像 → push 到仓库 → pull 到服务器 → run 成容器
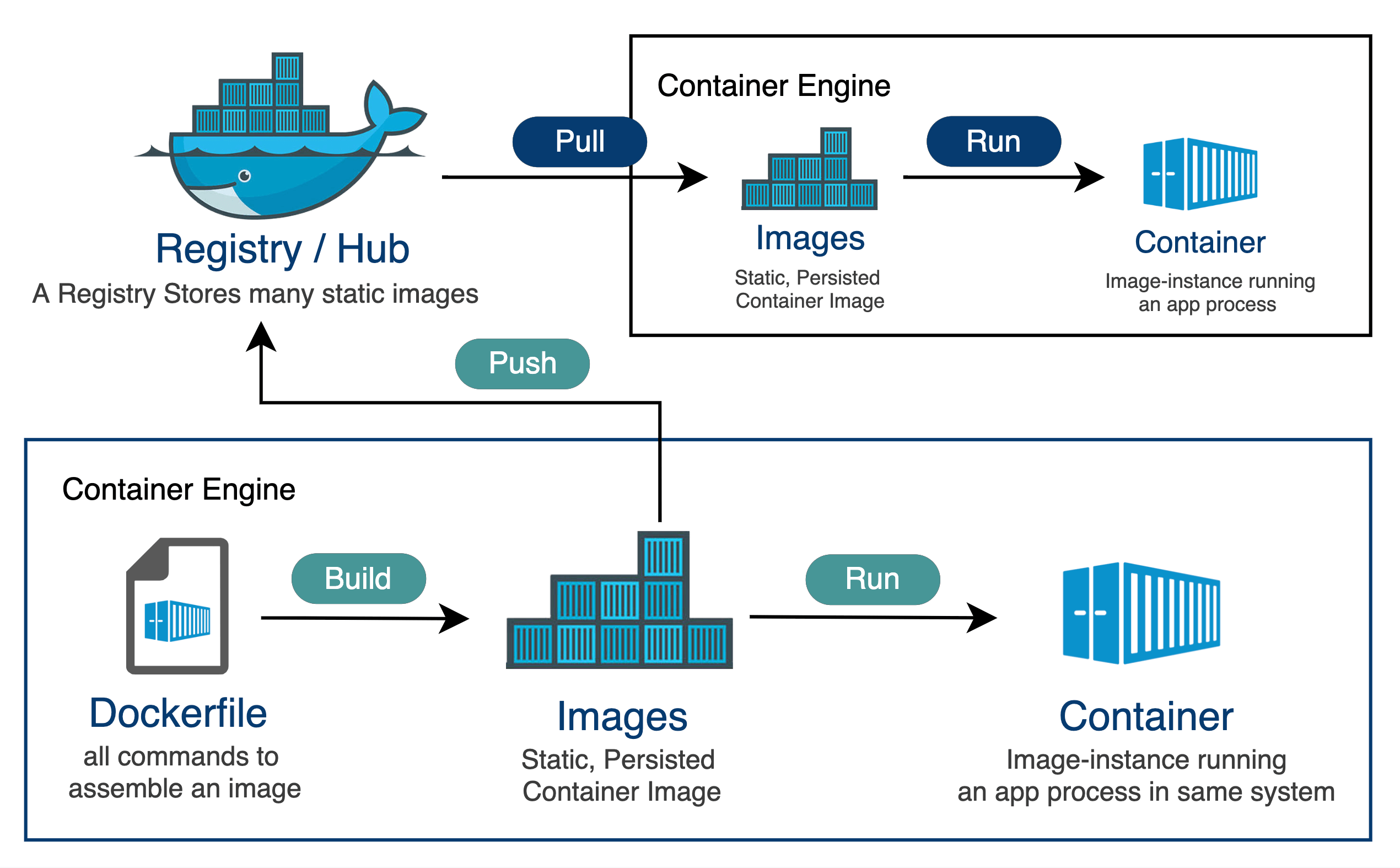
- Dockerfile:定义镜像怎么来,构建镜像的"脚本",定义环境、安装依赖、拷贝代码、设置启动命令。
- Image:应用运行模板(只读),docker build 来的。
- Container:运行中的进程(镜像实例),docker run 来的。
- Repository:镜像集合(带版本),docker push 来的。
- Registry:存储仓库的服务器 + 分发中心,docker pull 来的。
Docker 的核心对象包括 Dockerfile、Image、Container、Repository 和 Registry。
Dockerfile 是一个文本文件,用于定义镜像的构建过程,通过 docker build 命令可以根据 Dockerfile 构建镜像(Image)。
Image 是只读模板,Container 是镜像的运行实例,通过 docker run 命令可以创建并启动容器。
Repository 是镜像的集合,通常用于存储同一个软件的不同版本镜像;Registry 是镜像仓库服务,例如 Docker Hub。
镜像可以通过 docker push 上传到 Registry,也可以通过 docker pull 从 Registry 下载到本地。
🔴 从开发到部署全过程:
第一步:写 Dockerfile
java
FROM openjdk:8 //基础镜像用官方的 OpenJDK 8
COPY app.jar /app.jar //把你本机的 app.jar 文件复制到容器根目录下
CMD ["java","-jar","/app.jar"] //容器启动时执行命令:java -jar /app.jar第二步:构建镜像,本地生成 Image
bash
docker build -t myapp:v1 .第三步:上传镜像,上传到 Docker Hub / 私有仓库
bash
docker push myapp:v1第四步:服务器拉取镜像
bash
docker pull myapp:v1第五步:运行容器
bash
docker run -d myapp:v1Q:docker run 做了哪些事情?
A:如果本地没有镜像,会先 pull,然后 create 容器,最后 start 启动。
Q:Dockerfile 的作用是什么?
A:用于定义镜像构建过程,通过 docker build 生成镜像。
Build Ship and Run
Docker - Build, Ship, and Run Any App, Anywhere
那么 Build, Ship, and Run 到底是在干什么呢?
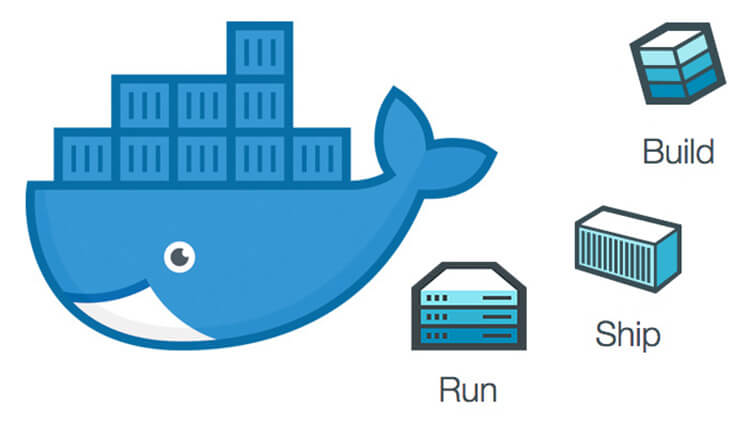
- Build(构建镜像):镜像就像是集装箱包括文件以及运行环境等等资源。
- Ship(运输镜像):主机和仓库间运输,这里的仓库就像是超级码头一样。
- Run (运行镜像):运行的镜像就是一个容器,容器就是运行程序的地方。
Docker 运行过程也就是去仓库把镜像拉到本地,然后用一条命令把镜像运行起来变成容器。所以,我们也常常将 Docker 称为码头工人或码头装卸工,这和 Docker 的中文翻译搬运工人如出一辙。
Docker 命令
基本命令
bash
docker version # 查看docker版本
docker images # 查看所有已下载镜像,等价于:docker image ls 命令
docker container ls # 查看所有容器
docker ps #查看正在运行的容器
docker image prune # 清理临时的、没有被使用的镜像文件。-a, --all: 删除所有没有用的镜像,而不仅仅是临时文件;拉取镜像
bash
docker search mysql # 查看mysql相关镜像
docker pull mysql:5.7 # 拉取mysql镜像
docker image ls # 查看所有已下载镜像构建镜像
运行 docker build命令并指定一个 Dockerfile 时,Docker 会读取 Dockerfile 中的指令,逐步构建一个新的镜像,并将其保存在本地。
bash
# imageName 是镜像名称,1.0.0 是镜像的版本号或标签
docker build -t imageName:1.0.0 .删除镜像
删除镜像之前首先要确保这个镜像没有被容器引用,通过我们前面讲的命令 docker ps 即可查看。
bash
➜ ~ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
c4cd691d9f80 mysql:5.7 "docker-entrypoint.s..." 7 weeks ago Up 12 days 0.0.0.0:3306->3306/tcp, 33060/tcp mysql可以看到 mysql 正在被 id 为 c4cd691d9f80 的容器引用,我们需要首先通过 docker stop c4cd691d9f80 或者 docker stop mysql 暂停这个容器。
然后查看 mysql 镜像的 id:
bash
➜ ~ docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
mysql 5.7 f6509bac4980 3 months ago 373MB通过 IMAGE ID 或者 REPOSITORY 名字即可删除
bash
docker rmi f6509bac4980 # 或者 docker rmi mysql镜像推送
bash
# 将镜像推送到私有镜像仓库 Harbor
# harbor.example.com是私有镜像仓库的地址,ubuntu是镜像的名称,18.04是镜像的版本标签
docker push harbor.example.com/ubuntu:18.04Docker 数据管理
数据卷是由 Docker 管理的数据存储区域,有如下这些特点:
- 可以在容器之间共享和重用。
- 即使容器被删除,数据卷中的数据也不会被自动删除,从而确保数据的持久性。
- 对数据卷的修改会立马生效。
- 对数据卷的更新,不会影响镜像。
bash
# 创建一个数据卷
docker volume create my-vol
# 查看所有的数据卷
docker volume ls
# 查看数据卷的具体信息
docker inspect web
# 删除指定的数据卷
docker volume rm my-vol在用 docker run 命令的时候,使用 --mount 标记来将一个或多个数据卷挂载到容器里。
Docker Compose
Docker Compose 是 Docker 官方提供的容器编排工具,用于定义和管理多个容器。
它通过一个 YAML 配置文件(docker-compose.yml)描述应用中的所有服务,包括镜像、端口、网络和依赖关系等。开发者可以通过 docker-compose up 和 docker-compose down 等命令,一键启动或停止整个应用。
Docker Compose 简化了多容器应用的部署和管理过程,适用于开发、测试以及中小规模的应用场景。
对比 Docker Compose
不用 Docker Compose 需要:
bash
docker run mysql
docker run redis
docker run backend
docker run frontend启动顺序混乱 ❌ 网络配置复杂 ❌ 参数一大堆 ❌ 容易出错 ❌
使用 Docker Compose,只需要一个文件 docker-compose.yml:
XML
services:
mysql:
redis:
backend:
frontend:然后:
bash
docker-compose up即 Docker Compose 把"多个 docker run"变成"一个配置 + 一个命令"。
Q:docker-compose 和 docker run 区别?
A:docker run 用于单个容器,docker-compose 用于管理多个容器。
Q:docker-compose.yml 里主要写什么?
A:服务(services)、镜像、端口、依赖关系、网络等。
Q:docker-compose 适合生产环境吗?
A:一般用于开发和测试,小规模生产可以,大规模推荐 Kubernetes。
常见命令
- 启动
bash
# 在当前目录下寻找 docker-compose.yml 文件,并根据其中定义的服务启动应用程序
docker-compose up
# 后台启动
docker-compose up -d
# 强制重新创建所有容器,即使它们已经存在
docker-compose up --force-recreate
# 重新构建镜像
docker-compose up --build
# 指定要启动的服务名称,而不是启动所有服务
# 可以同时指定多个服务,用空格分隔。
docker-compose up service_name- 暂停
bash
# 在当前目录下寻找 docker-compose.yml 文件
# 根据其中定义移除启动的所有容器,网络和卷。
docker-compose down
# 停止容器但不移除
docker-compose down --stop
# 指定要停止和移除的特定服务,而不是停止和移除所有服务
# 可以同时指定多个服务,用空格分隔。
docker-compose down service_name- 查看
bash
# 查看所有容器的状态信息
docker-compose ps
# 只显示服务名称
docker-compose ps --services
# 查看指定服务的容器
docker-compose ps service_nameDocker 底层原理
硬件虚拟化(虚拟机),虚拟出"完整电脑",每个 VM 有自己的 OS,问题是重、慢、吃资源。
操作系统级虚拟化(Docker),不虚拟硬件,直接用宿主机内核。
namespace 用于实现容器之间的资源隔离,使每个容器拥有独立的进程空间、网络空间和文件系统;cgroup 用于对容器的 CPU、内存等资源进行限制和管理。
Docker 本质就是带隔离和限制的进程。
Docker 本质上是运行在宿主机上的隔离进程,与虚拟机相比,不需要额外的操作系统,因此启动更快、资源占用更少。