目录
[4.安装 CUDA Toolkit](#4.安装 CUDA Toolkit)
[5.在容器中测试NVIDIA Container Toolkit](#5.在容器中测试NVIDIA Container Toolkit)
[6.安装 NVIDIA Container Toolkit](#6.安装 NVIDIA Container Toolkit)
[7.配置 Docker 运行](#7.配置 Docker 运行)
[8.测试基础 GPU 访问](#8.测试基础 GPU 访问)
[10.启动 Ollama 容器](#10.启动 Ollama 容器)
1.安装wsl下的ubuntu
以管理员身份打开 PowerShell 或 Windows 命令提示符=
powershell,安装指定版本,指令:
wsl --install -d Ubuntu-24.04安装完成会提示输入用户名、密码以及确认密码;

输完之后直接进入ubuntu
查看当前版本:

开始菜单中多了一项
检查网络配置
先更新下载
sudo apt-get update;
sudo apt-get install net-tools;
2.安装docker
安装步骤见:
安装验证

3.验证GPU驱动
输入:nvidia-smi
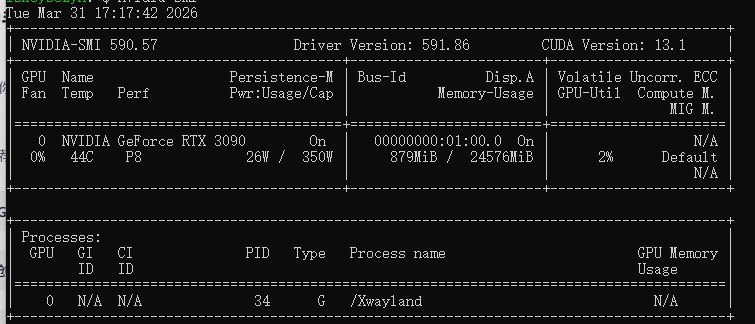
验证**nvcc --version**
提示未找到,则安装
4.安装 CUDA Toolkit
你的系统是 Ubuntu 24.04,请执行以下命令:
# 1. 下载并安装 NVIDIA 官方软件源配置包
wget https://developer.download.nvidia.com/compute/cuda/repos/wsl-ubuntu/x86_64/cuda-keyring_1.1-1_all.deb
sudo dpkg -i cuda-keyring_1.1-1_all.deb
# 2. 更新软件包列表
sudo apt-get update
# 3. 安装 CUDA Toolkit(安装后自动配置环境变量)
sudo apt-get -y install cuda-toolkit-12-6设置环境变量
ls /usr/local/ | grep cuda

find /usr -name nvcc 2>/dev/null

设置环境变量
echo 'export PATH=/usr/local/cuda/bin:$PATH' >> ~/.bashrc
echo 'export LD_LIBRARY_PATH=/usr/local/cuda/lib64:$LD_LIBRARY_PATH' >> ~/.bashrc
更新环境变量source ~/.bashrc
验证 nvcc --version

5.在容器中测试NVIDIA Container Toolkit
# 1. 停止并删除失败的容器
sudo docker stop ollama 2>/dev/null
sudo docker rm ollama 2>/dev/null
# 2. 卸载现有的 nvidia-container-toolkit(如果已安装)
sudo apt-get remove -y nvidia-container-toolkit nvidia-container-runtime
sudo rm -f /etc/apt/sources.list.d/nvidia-container-toolkit.list
sudo apt-get update6.安装 NVIDIA Container Toolkit
# 1. 安装依赖
sudo apt-get install -y curl gnupg
# 2. 添加 NVIDIA 官方 GPG 密钥
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg
# 3. 添加软件源
echo "deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://nvidia.github.io/libnvidia-container/stable/deb/$(ARCH) /" | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
# 4. 更新并安装
sudo apt-get update
sudo apt-get install -y nvidia-container-toolkit7.配置 Docker 运行
bash
# 1. 配置 Docker 使用 NVIDIA 运行时
sudo nvidia-ctk runtime configure --runtime=docker
# 2. 重启 Docker 服务
sudo systemctl restart docker
# 3. 验证配置是否成功
cat /etc/docker/daemon.json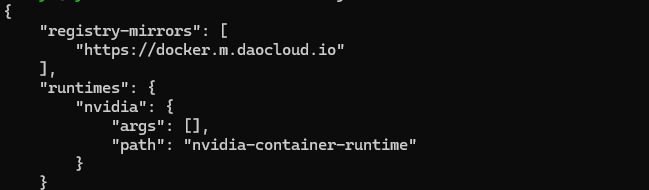
8.测试基础 GPU 访问
sudo docker run --rm --gpus all nvidia/cuda:12.2.0-base-ubuntu22.04 nvidia-smi
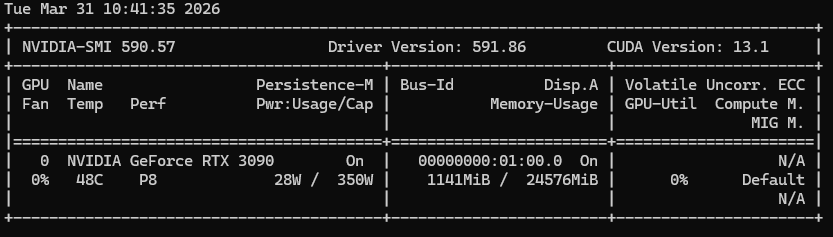
9.测试安装完成
运行docker,安装ollama
打开终端,拉取最新的 Ollama Docker 镜像。
sudo docker pull ollama/ollama:latest
等待下载完成
10.启动 Ollama 容器
sudo docker run -d --gpus all --name ollama -p 11434:11434 -v ollama_data:/root/.ollama ollama/ollama
参数:--gpus all,在显卡中启动ollama,不加该参数默认在内存中运行
sudo docker run -d --gpus all --name ollama -p 11434:11434 ollama/ollama
加载模型,可以进入docker中下载也可以在本地命令行操作,
docker exec -it ollama ollama run qwen2.5-coder:32b
或则进入容器的命令行:
sudo docker exec -it ollama /bin/bash
ollama run qwen2.5-coder:32b
此处32b需要更具自己的现显存确定,大概计算方式为32/2*1.5=24G(需要运行的显存大小)
第一次执行是要下载大模型的需要等一会
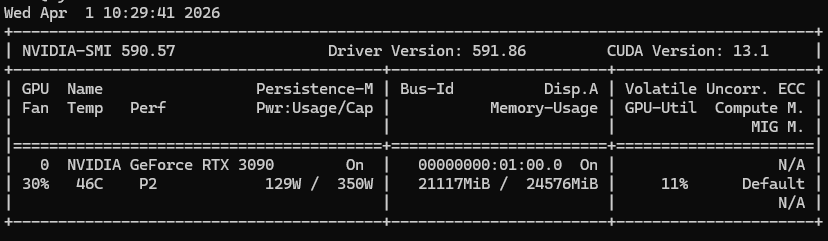
说明有一部分加载到内存里面去了,看看
指令:docker exec -it ollama ollama ps

可以看出确实有一部分加载到内存里面去了,可以删除模型下载一个14b的,此处不在演示;