Playwright 的脚本录制功能 (codegen)------ 一个能让你 "点点鼠标就生成代码" 的神器,它能帮你快速构建自动化测试脚本,大幅提升工作效率。
1. Playwright codegen特点
Playwright 的 codegen 并非传统意义上的 "录制回放" 工具,它有几个核心优势:
- 智能定位技术 :优先使用role/name/text/test-id等语义化属性生成选择器,而非脆弱的 CSS 选择器或 XPath,脚本更稳定
- 多语言支持:可生成 Python、JavaScript/TypeScript、C# 等多种语言代码
- 自动等待 :内置智能等待机制,无需手动添加
time.sleep() - 设备模拟:支持模拟手机、平板等不同设备环境
- 网络控制:可录制网络请求,支持 HAR 文件导出
2. 启动录制工具
最基础的录制命令:
playwright codegen https://www.baidu.comTarget这里可以选择生成不同语言的录制脚本
这里我们选择生成pytest样式的脚本
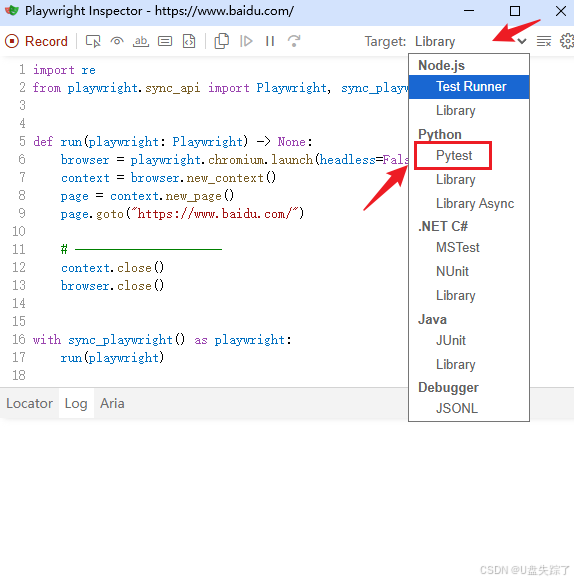
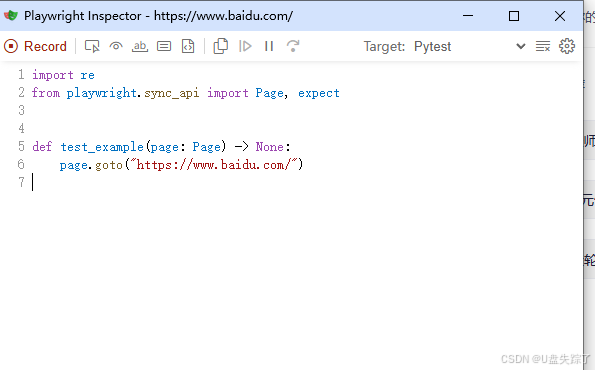
会自动转换为pytest样式的脚本
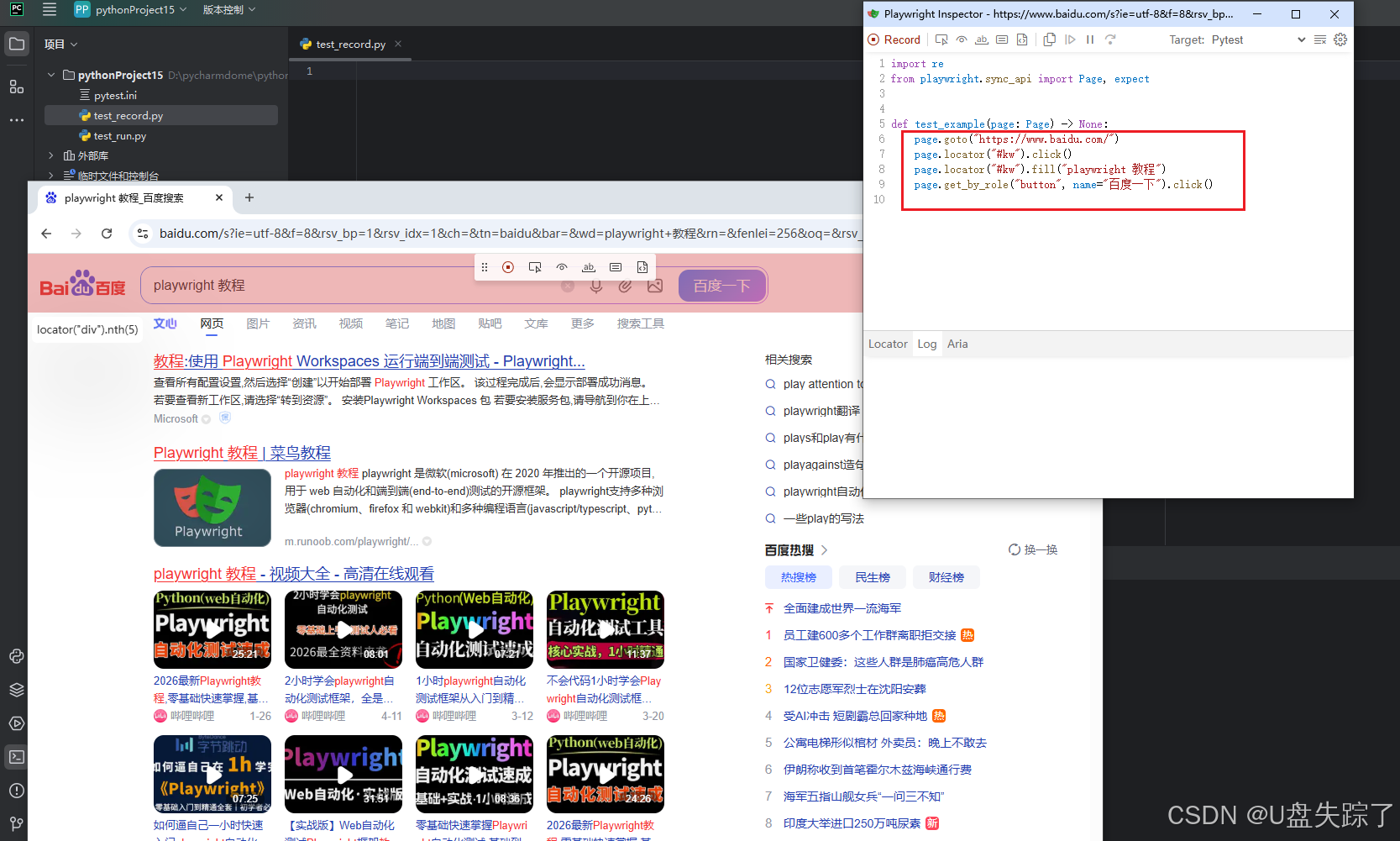
可以看到我们操作的每一步都会自动生成对应的脚本
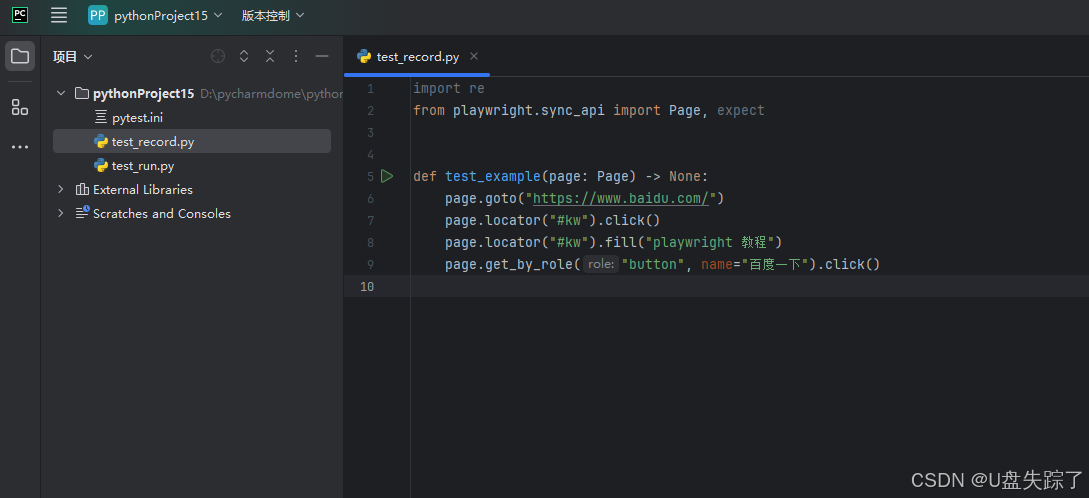
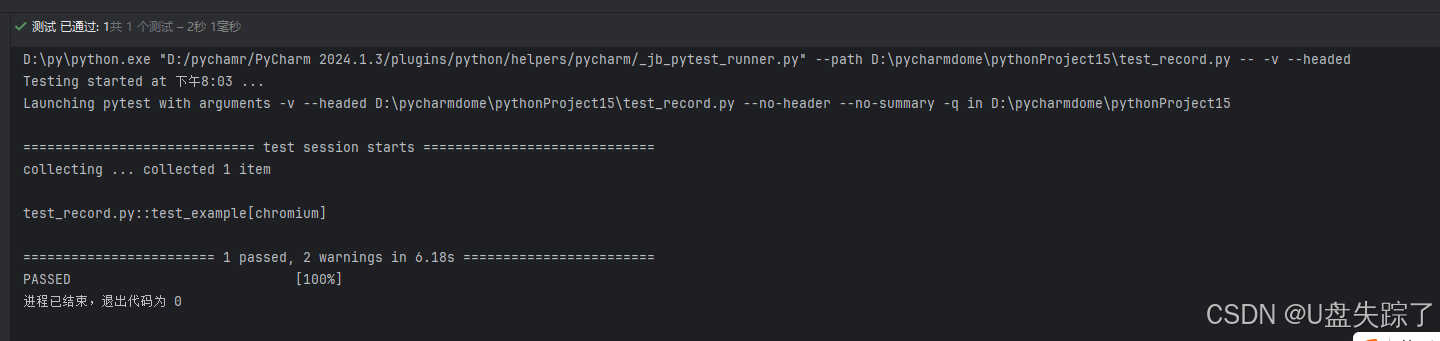
执行脚本,和录制时操作的效果是一致的;
3. 录制功能参数
1. 常用命令行参数
表格
| 参数 | 说明 | 示例 |
|---|---|---|
--browser |
指定浏览器类型 | --browser=firefox |
--headed |
以有头模式运行 | --headed |
--device |
模拟移动设备 | --device="iPhone 13" |
--output |
保存代码到文件 | --output=test.py |
--target |
指定生成语言 | --target=python |
--color-scheme |
模拟配色方案 | --color-scheme=dark |
--save-storage |
保存上下文状态 | --save-storage=state.json |
2. 示例:
playwright codegen --device="iPhone 13" --output=test_record.py https://www.baidu.com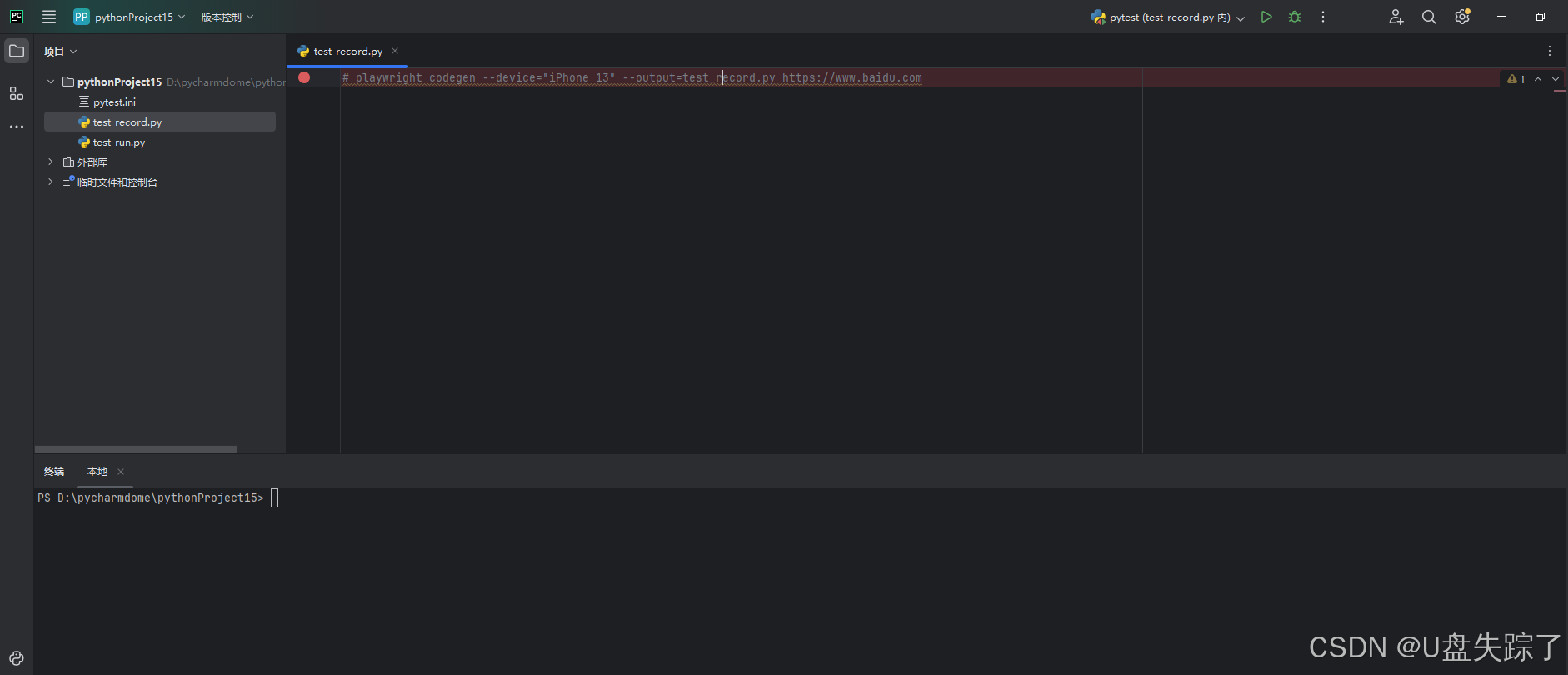
可以看到浏览器对应以参数形式,打开浏览器并且对py文件写入代码,十分的方便,这里就不一一举例了,感兴趣的可以自己尝试;
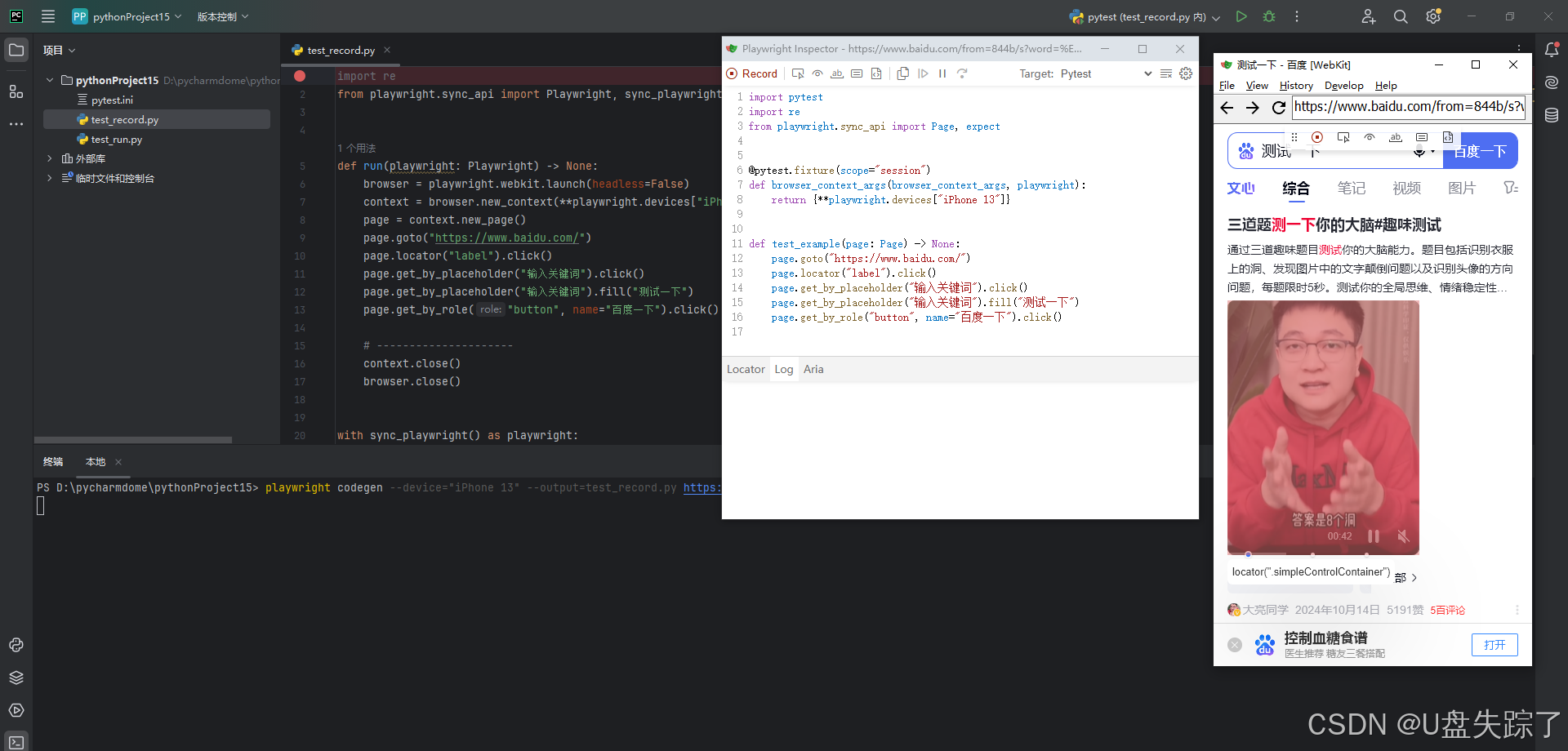
4,Playwright Inspector
Playwright Inspector 是 Playwright 提供的一个图形用户界面(GUI)调试工具,它可以帮助开发者调试 Playwright 脚本。这个工具允许开发者逐步执行脚本,实时编辑定位器,选择定位器,并查看操作日志。
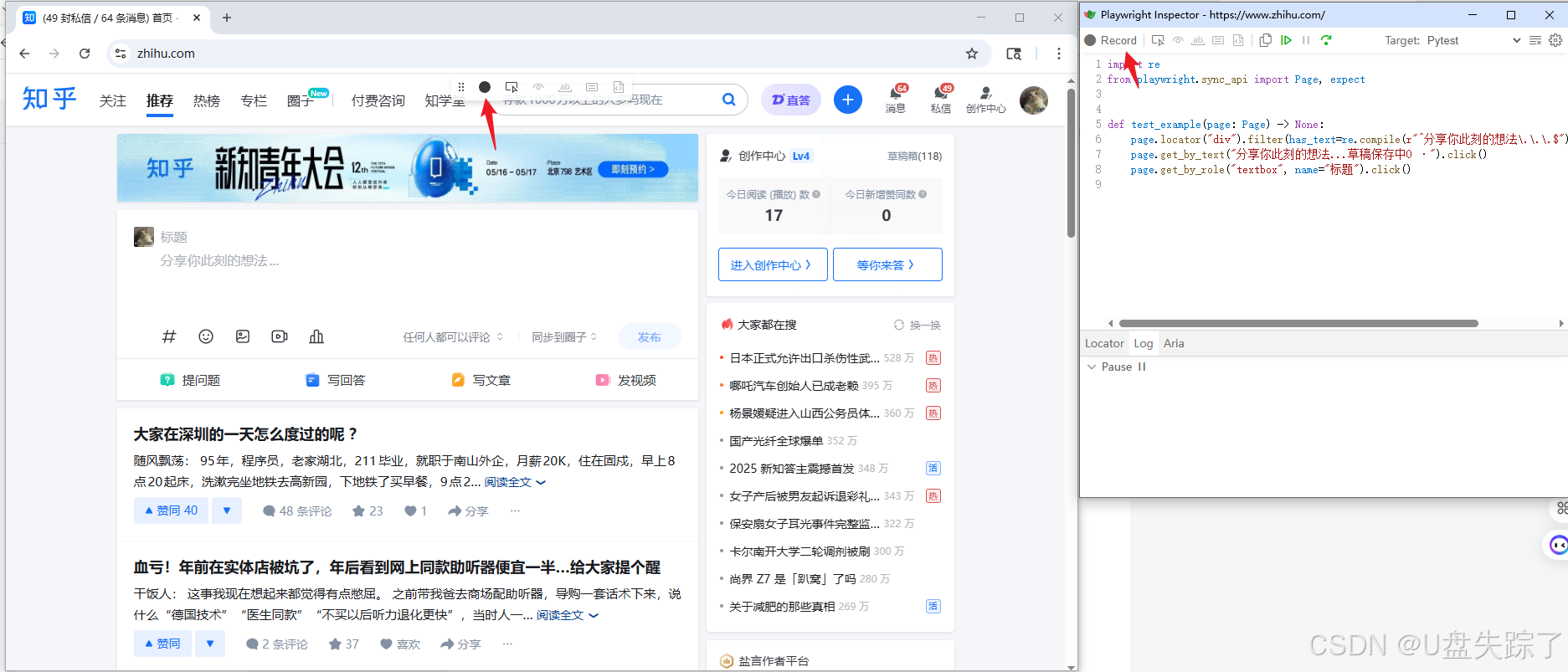
4.1 Record
点击Record 记录,即录制脚本的意思
4.2 Pick locator
Pick locator 是「单独抓取页面元素的定位代码」,只拿定位器、不录操作
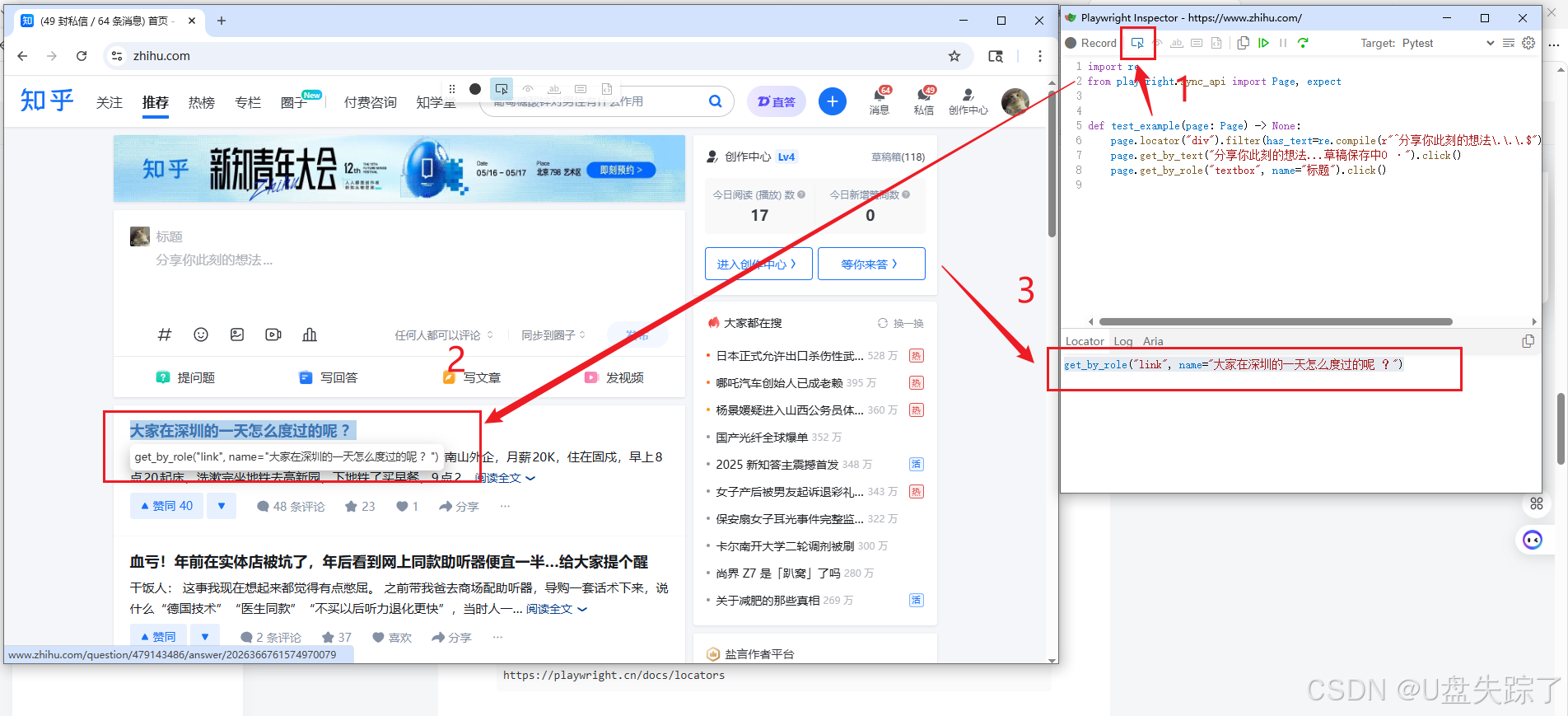
1)定位器语法
定位器可以参考官方文档写的巨详细
https://playwright.cn/docs/locators4.3 Assert visibility
检查元素在不在
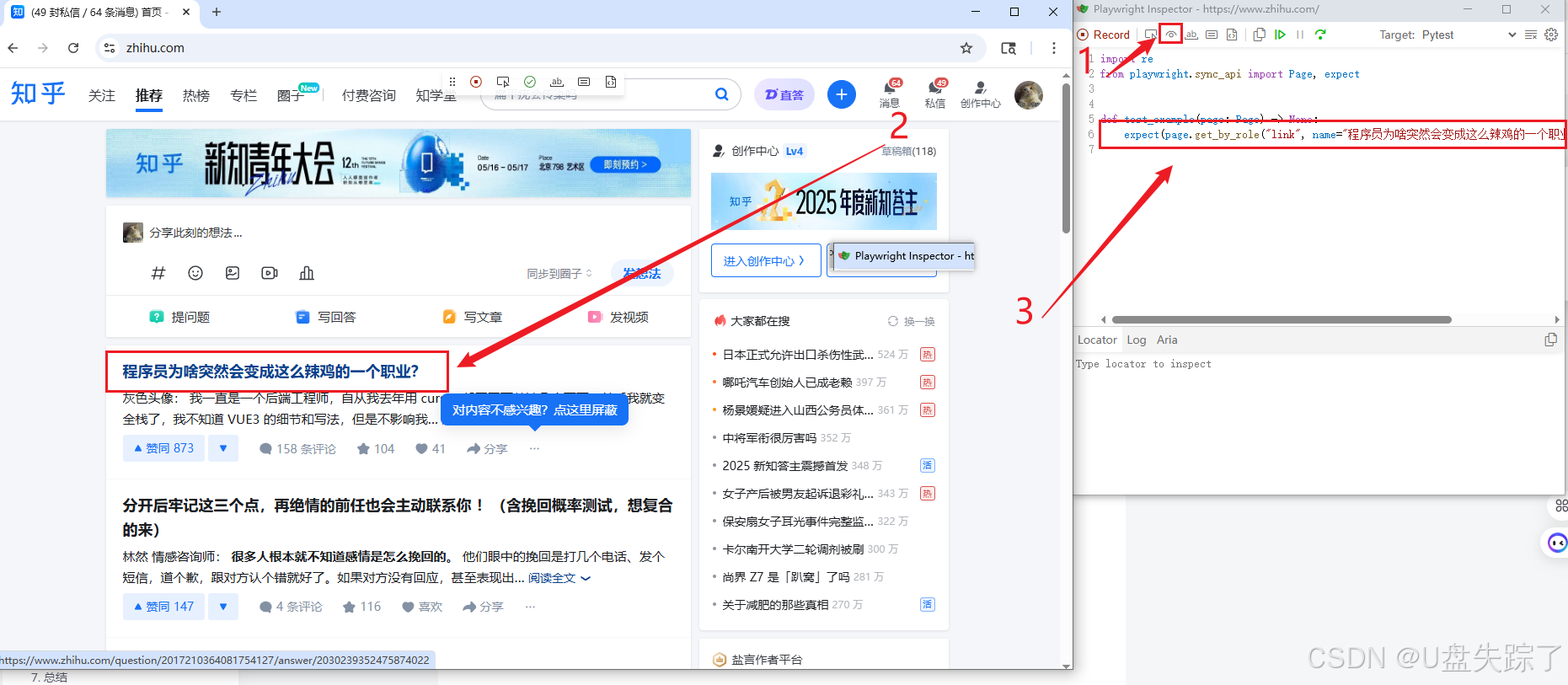
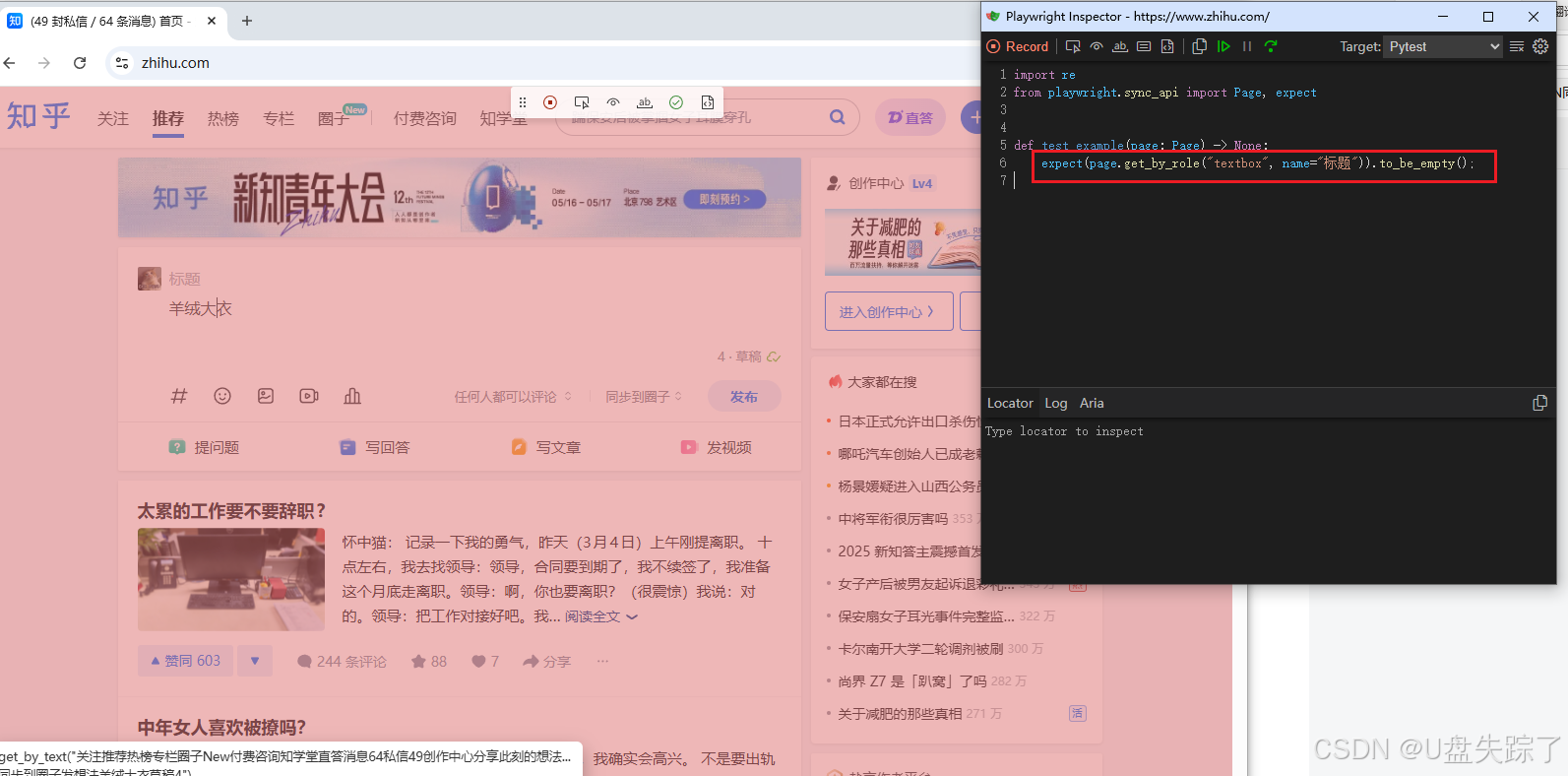
4.4 Assert text
检查元素在不在 + 字对不对
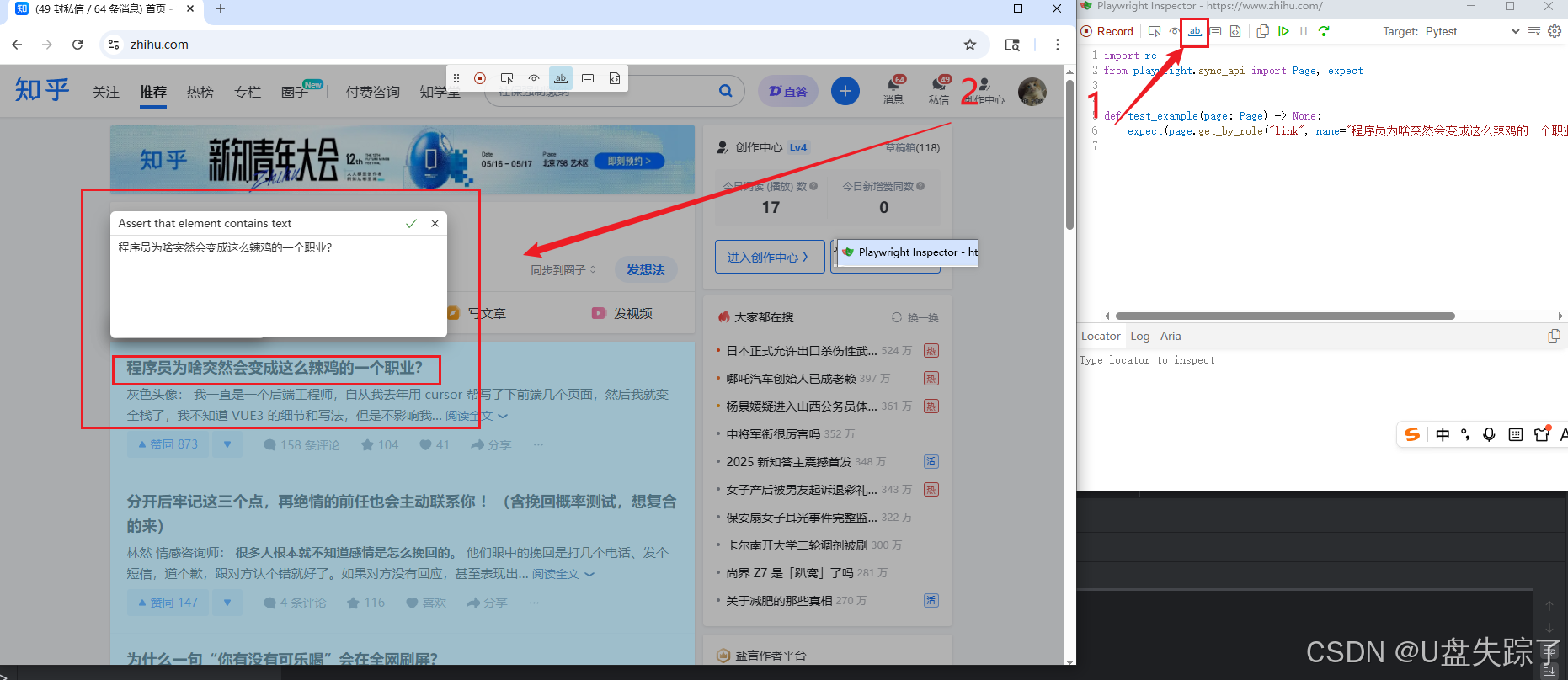
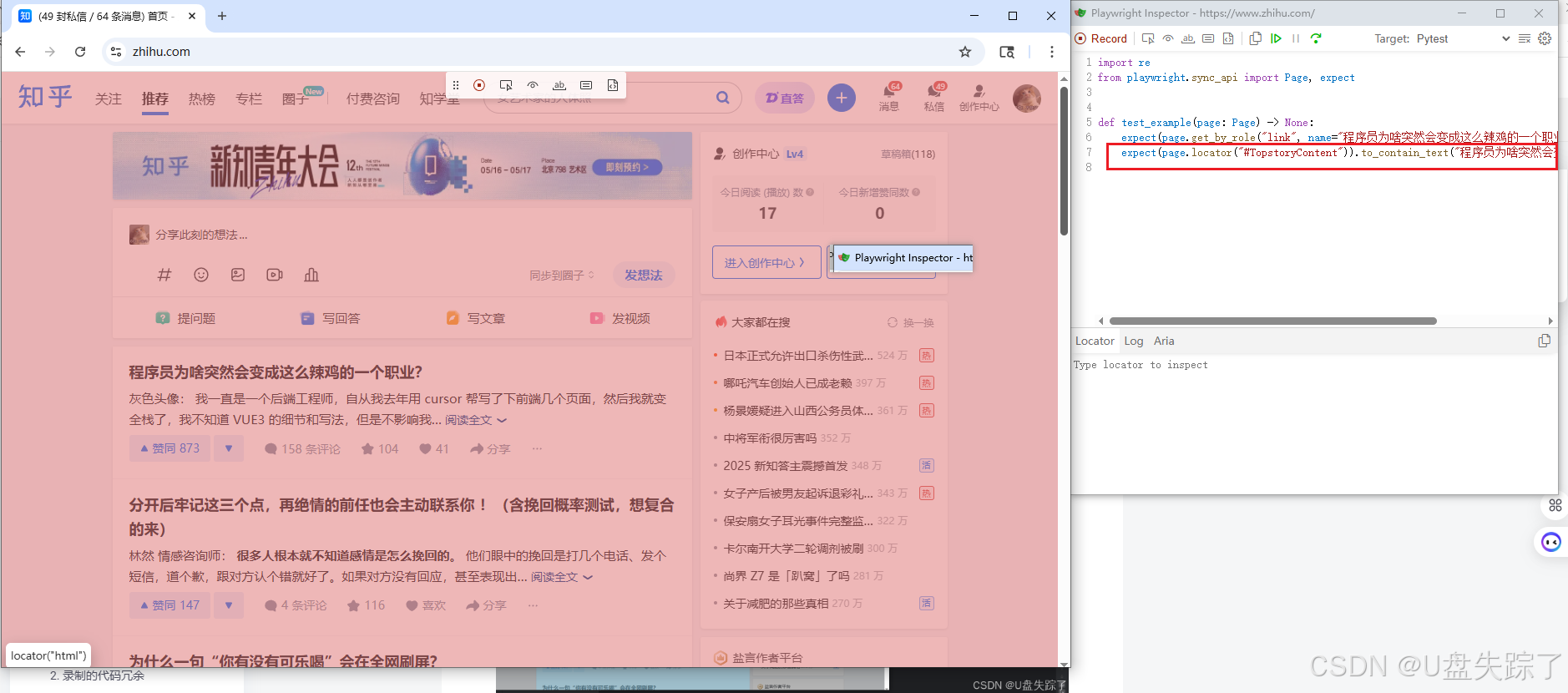
点击√会生成断言脚本
4.5 Assert value
断言输入框当前是否有值
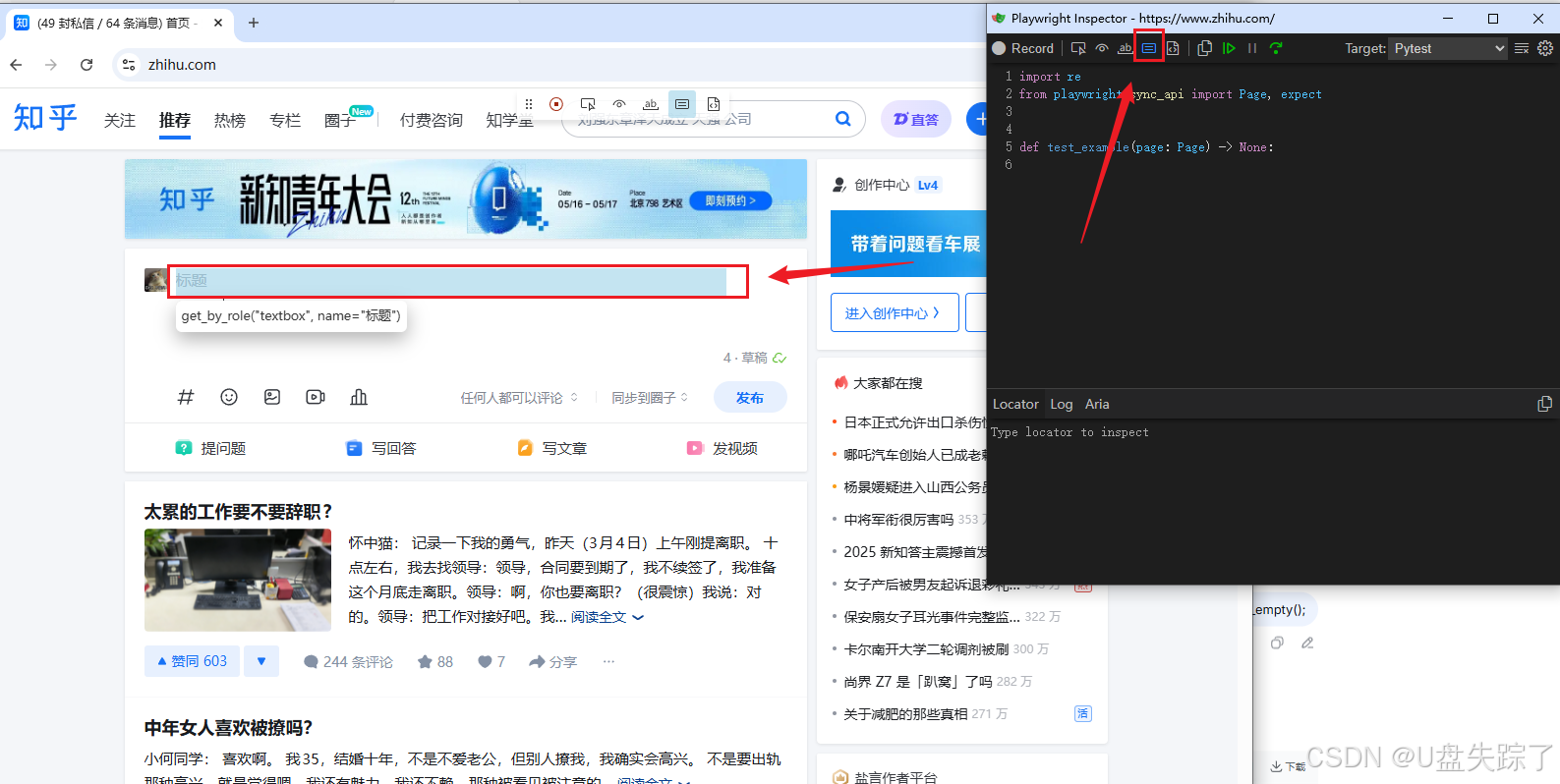
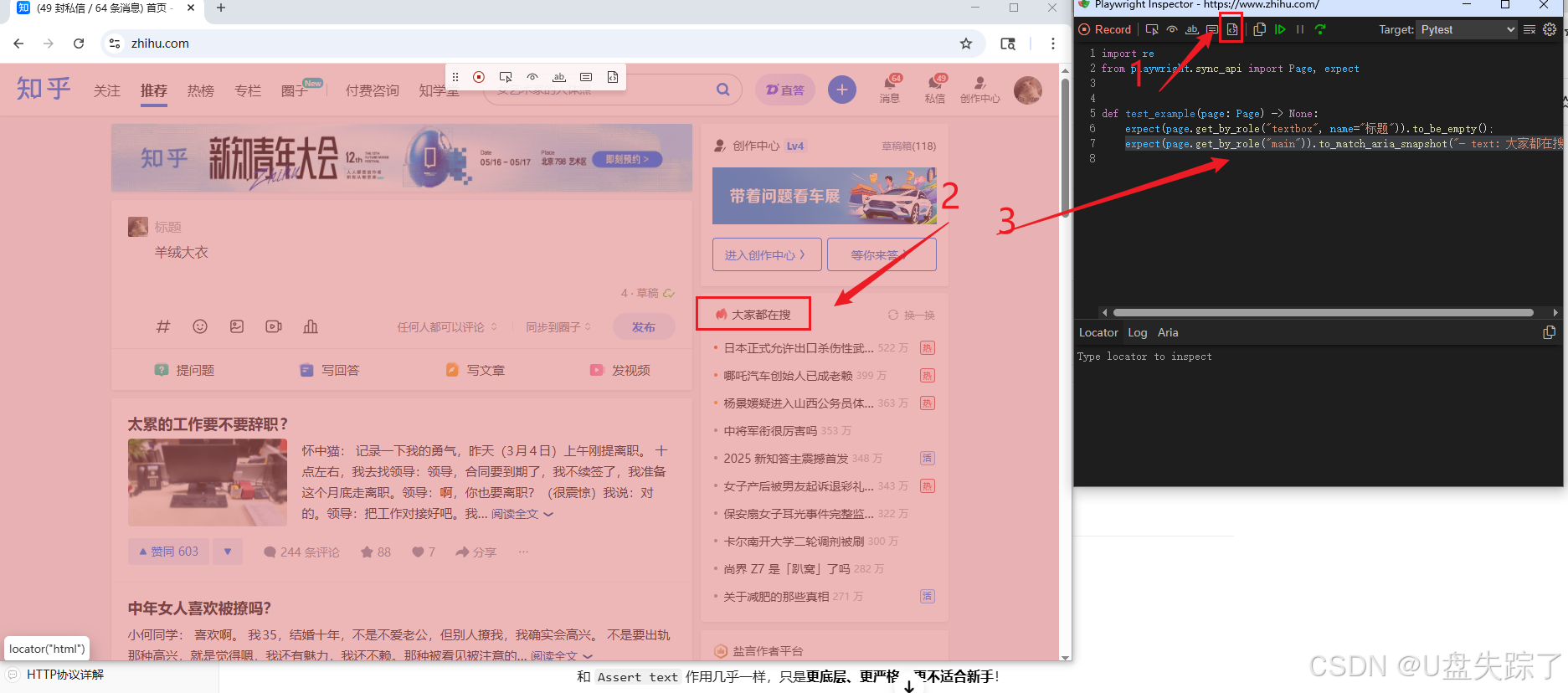
4.6 Assert snapshot
断言页面结构
1)断言区别
| 断言选项 | 作用 | 校验目标 | 严格度 | 新手推荐 |
|---|---|---|---|---|
| ✅ Assert visibility | 断言可见 | 元素是否显示在页面 | 低 | ✅ 必用 |
| ✅ Assert text | 断言文本 | 元素显示的文字是否正确 | 中 | ✅ 必用 |
| ✅ Assert value | 断言输入值 | 输入框里填写的内容 | 中 | ✅ 必用 |
| 🚫 Assert snapshot | 断言视觉快照 | 校验结构 + 文字 + 链接 + 属性全部一致 | 极高 | ❌ 不推荐 |
注意点: expect 是 Playwright 专用的断言函数,不是 Python 自带的,必须手动导入才能用。
# 必加:导入 sync_playwright + expect
from playwright.sync_api import sync_playwright, expect
def test_case():
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
# 加载登录状态
context = browser.new_context(storage_state="login_state.json")
page = context.new_page()
# 打开知乎
page.goto("https://www.zhihu.com/", wait_until="networkidle")
page.wait_for_timeout(3000)
# 你的断言代码(现在可以正常运行了)
expect(page.get_by_label("创作中心卡片")).to_match_aria_snapshot(
"- text: 创作中心\n- link \"Lv4\":\n - /url: /creator/account/growth-level")
# 关闭资源
context.close()
browser.close()2)断言语法
断言可以参考官方文档写的巨详细
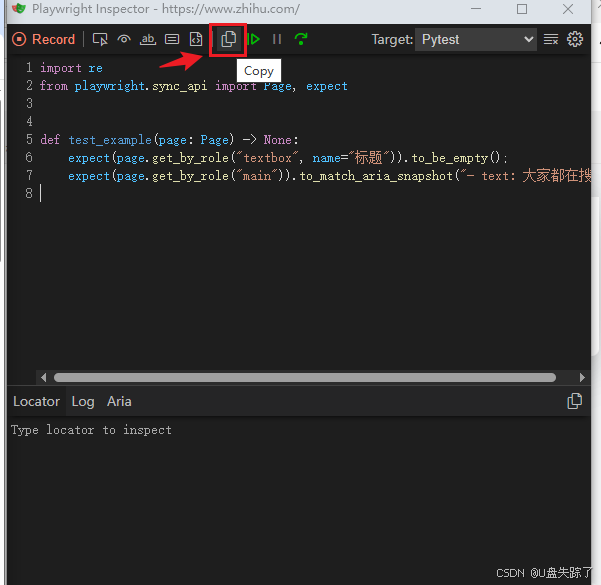
https://playwright.net.cn/docs/test-assertions#:~:text=Playwright%20%E5%8C%85%E5%90%AB%E4%BB%A5%20expect%20%E5%87%BD%E6%95%B0%E5%BD%A2%E5%BC%8F%E5%91%88%E7%8E%B0%E7%9A%84%E6%B5%8B%E8%AF%95%E6%96%AD%E8%A8%80%E3%80%82%20%E8%A6%81%E8%BF%9B%E8%A1%8C%E6%96%AD%E8%A8%80%EF%BC%8C%E8%AF%B7%E8%B0%83%E7%94%A8%20expect%28value%29%20%E5%B9%B6%E9%80%89%E6%8B%A9%E4%B8%80%E4%B8%AA%E5%8F%8D%E6%98%A0%E9%A2%84%E6%9C%9F%E7%9A%84%E5%8C%B9%E9%85%8D%E5%99%A8%E3%80%82%20%E6%9C%89%E8%AE%B8%E5%A4%9A,%E3%80%81%20toBeTruthy%EF%BC%8C%E5%8F%AF%E7%94%A8%E4%BA%8E%E6%96%AD%E8%A8%80%E4%BB%BB%E4%BD%95%E6%9D%A1%E4%BB%B6%E3%80%82%20Playwright%20%E8%BF%98%E5%8C%85%E5%90%AB%20Web%20%E4%B8%93%E7%94%A8%E7%9A%84%20%E5%BC%82%E6%AD%A5%E5%8C%B9%E9%85%8D%E5%99%A8%EF%BC%8C%E5%AE%83%E4%BB%AC%E4%BC%9A%E4%B8%80%E7%9B%B4%E7%AD%89%E5%BE%85%E7%9B%B4%E5%88%B0%E6%BB%A1%E8%B6%B3%E9%A2%84%E6%9C%9F%E6%9D%A1%E4%BB%B6%E3%80%82%20%E8%AF%B7%E8%80%83%E8%99%91%E4%BB%A5%E4%B8%8B%E7%A4%BA%E4%BE%8B4.7 copy
复制当前生成的脚本
4.8 Resume
最常见的含义是 "恢复" 或 "继续执行"
可以理解为继续执行page.pause()这个语句后面的脚本;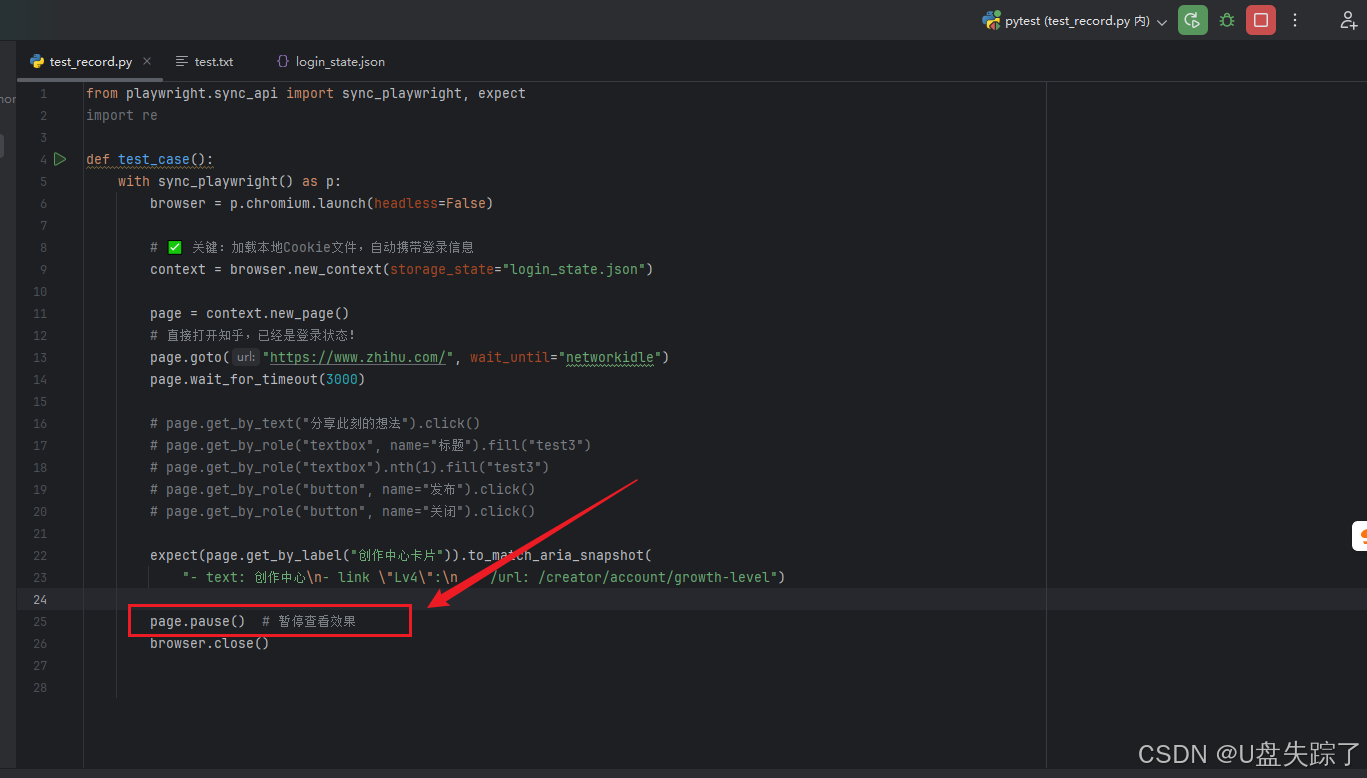
4.9 Step Over
在 Playwright Inspector(以及几乎所有代码调试器)中,Step Over 的意思是:单步跳过。
可以理解为,如脚本中有两条page.pause()语句,点击Step Over即跳过25行的调试进入到27行的调试;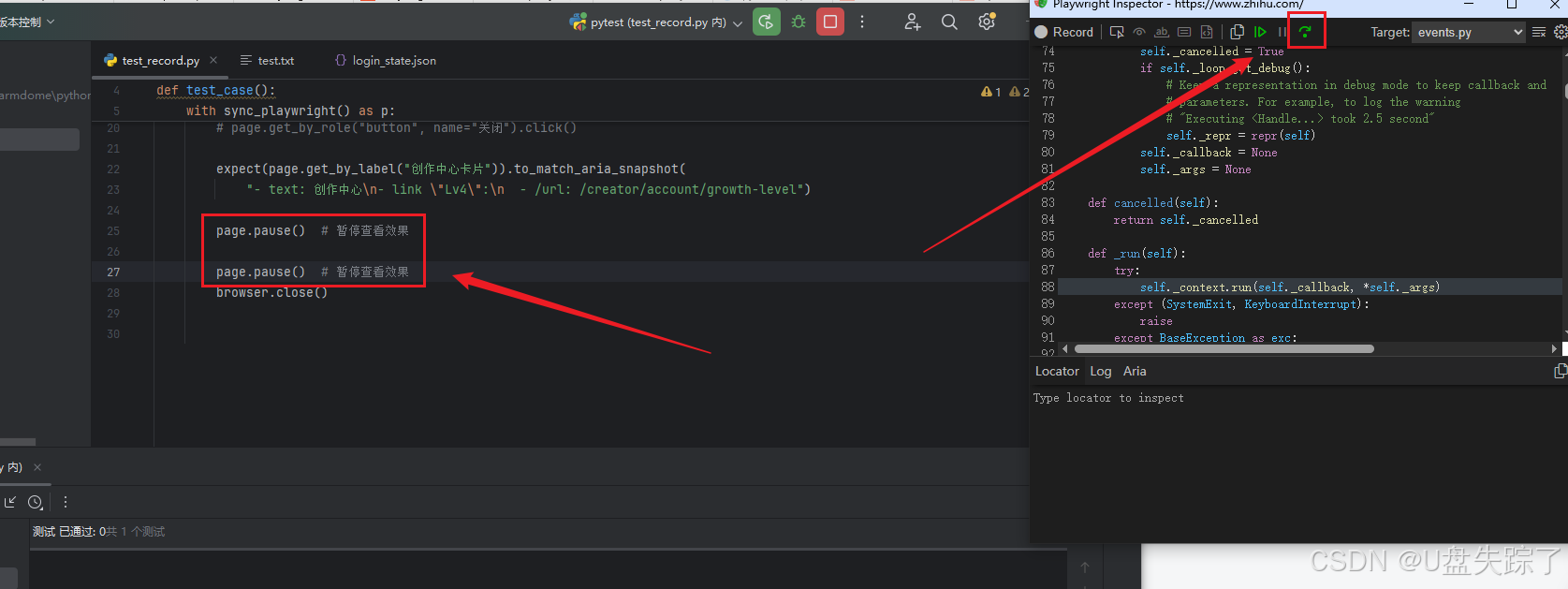
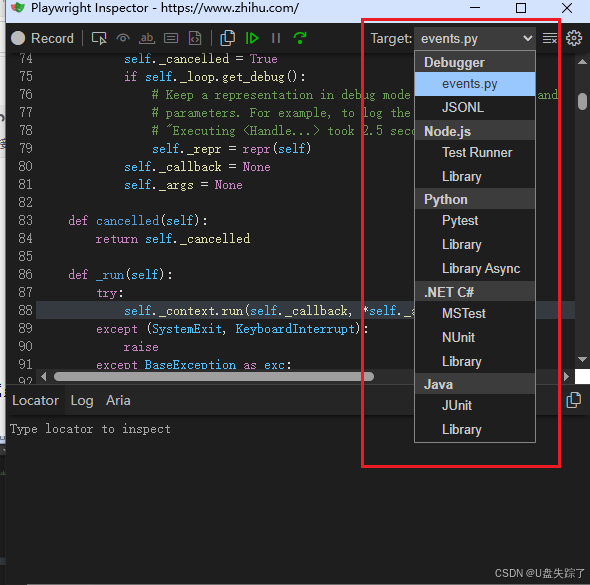
4.10 Target
获取不同语言的脚本
4.11 Clear
顾名思义是清除已生成的脚本,初始化
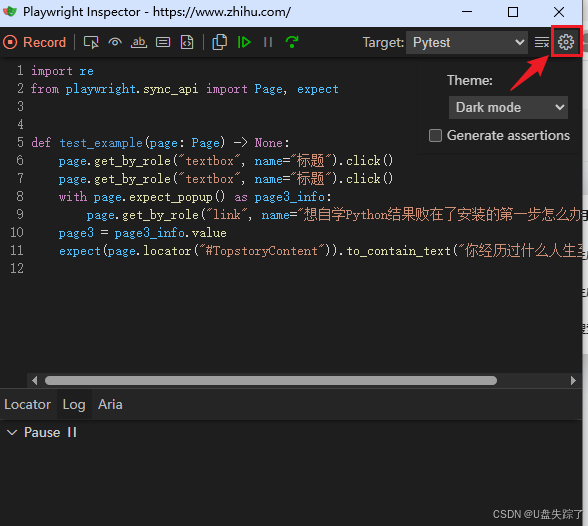
4.12 Settings
设置这里可以选择主题,建议选择黑色主题,因为前面的按钮点击后不明显;
Generate assertions的意思是自动生成断言代码,默认不勾选
5. 存储状态复用
--save-storage=state.json
# 录制登录并保存状态
playwright codegen --save-storage=login_state.json https://www.zhihu.com
# 后续测试加载状态
playwright codegen --load-storage=login_state.json https://www.zhihu.com
这里直接手机扫码,登录成功后,直接结束录制,可以发现登录态已经保存下来了;
通过加载本地保存登录的json,browser.new_context(storage_state="login_state.json")
from playwright.sync_api import sync_playwright
def test_case():
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
# ✅ 关键:加载本地Cookie文件,自动携带登录信息
context = browser.new_context(storage_state="login_state.json")
page = context.new_page()
# 直接打开知h,已经是登录状态!
page.goto("https://www.zhihu.com/")
page.pause() # 暂停查看效果
browser.close()可以看到能够直接携带登录态去访问页面了
from playwright.sync_api import sync_playwright
import re
def test_case():
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
# ✅ 关键:加载本地Cookie文件,自动携带登录信息
context = browser.new_context(storage_state="login_state.json")
page = context.new_page()
# 直接打开知乎,已经是登录状态!
page.goto("https://www.zhihu.com/", wait_until="networkidle")
page.wait_for_timeout(3000)
page.get_by_text("分享此刻的想法").click()
page.get_by_role("textbox", name="标题").fill("test3")
page.get_by_role("textbox").nth(1).fill("test3")
page.get_by_role("button", name="发布").click()
page.get_by_role("button", name="关闭").click()
page.pause() # 暂停查看效果
browser.close()6. 录制网络请求
6.1 录制HAR的意义
6.1.1 HAR 文件的三大核心意义
1)核心意义一:锁定环境,让测试不再"飘忽不定" (最最重要!)
这是 HAR 最大的用处。在没有 HAR 的情况下,你的自动化测试会依赖一个随时可能变化的后端。
-
没有 HAR:今天后端接口返回"哪吒汽车创始人已成老赖",明天可能改成"哪吒汽车创始人已和解"。你的测试今天能过,明天就挂了。你不得不花时间去排查是代码问题还是后端数据变了。
-
有了 HAR :你录下了今天这个返回"已成老赖"的响应。以后每次跑测试,Playwright 都会把这段录好的"已成老赖" 返回给页面。你的测试从此与后端解耦,永远稳定,不会再因为后端数据变化而出现莫名其妙的失败。
简单说:HAR 给你的测试加了一把"时间锁",锁住了那一刻的后端数据。
2)核心意义二:离线运行,让测试"快如闪电"
-
没 HAR:每次测试都要真实地去请求网络,等待图片、CSS、JS、API 一个个加载完,速度受网速、服务器响应时间影响。
-
有 HAR :所有数据都从你电脑硬盘上的 HAR 文件读取,速度比真实网络快几倍甚至几十倍。而且你可以彻底断开网线,测试依然能跑得飞快。
简单说:HAR 把你的测试从"在线视频"变成了"本地缓存",随看随有,从不卡顿。
3)核心意义三:协作与复现,让 Bug "无处遁形"
-
复现线上Bug:线上出了个 Bug,你可以在本地录制一个包含 Bug 的 HAR,然后把 HAR 文件发给同事。同事不需要配置任何后端环境,直接重放,就能在你电脑上看到一模一样的 Bug 现场,极大方便了调试。
-
前后端分离开发 :前端开发时,后端接口还没写好。前端可以先用 Mock 工具录一份假数据生成 HAR,然后基于这个 HAR 写自己的 UI 测试。等后端接口好了,再把
update=False改成update=True跑一次,就能轻松切换到真实数据。
简单说:HAR 是一个可以随身携带、随时重放、永不消失的"现场快照"。
6.2 录制HAR参数作用
6.2.1 --save-har
--save-har 是 Playwright 命令行中指定 HAR 文件保存路径和名称的参数。
它的作用告诉 Playwright 把录制的网络请求保存到哪个文件中。
基本用法
# 保存到当前目录下的 example.har
playwright open --save-har=example.har https://example.com
# 保存到指定文件夹
playwright open --save-har=./recordings/my-test.har https://example.com
# 保存为 zip 压缩格式(体积更小)
playwright open --save-har=example.har.zip https://example.com6.2.2 --save-har-glob
--save-har-glob 是 Playwright 命令行工具的一个参数,用来过滤哪些网络请求应该被保存到 HAR 文件中。
作用只保存匹配规则的请求,其他请求不保存。
这样可以:
-
减少 HAR 文件大小
-
只关注你关心的 API 请求
-
避免保存图片、CSS、JS 等静态资源
只保存包含 /api/ 的请求
playwright open --save-har=example.har --save-har-glob="/api/" https://example.com
只保存特定域名的请求
playwright open --save-har=example.har --save-har-glob="/zhihu.com/" https://www.zhihu.com
只保存 JSON 请求(常见写法)
playwright open --save-har=example.har --save-har-glob="**/*.json" https://example.com
通配符规则
| 模式 | 匹配什么 |
|---|---|
**/api/** |
URL 中任意位置包含 /api/ 的请求 |
**/*.json |
以 .json 结尾的请求 |
https://api.example.com/** |
特定域名下的所有请求 |
**/user/** |
包含 /user/ 的请求 |
** |
匹配所有请求(默认行为) |
6.2.2.1 实际例子
1)例子1:只保存知乎的 API 请求
playwright open --save-har=zhihu.har --save-har-glob="**/api/**" https://www.zhihu.com这样只会保存类似这些请求:
-
✅
https://www.zhihu.com/api/v3/feed -
✅
https://www.zhihu.com/api/v4/questions -
❌
https://static.zhihu.com/css/main.css(不保存) -
❌
https://picx.zhimg.com/image.jpg(不保存)
2)例子2:保存多个模式(使用多次参数)
playwright open --save-har=example.har \
--save-har-glob="**/api/**" \
--save-har-glob="**/graphql" \
https://example.com3)例子3:排除某些请求(用感叹号)
# 保存所有请求,但不保存图片
playwright open --save-har=example.har \
--save-har-glob="**" \
--save-har-glob="!**/*.jpg" \
--save-har-glob="!**/*.png" \
https://example.com4)在 Python 代码中的对应方式
命令行参数对应 Python 中的 record_har_url_filter:
# 等价于 --save-har-glob="**/api/**"
context = browser.new_context(
record_har_path="example.har",
record_har_url_filter="**/api/**" # 只保存 API 请求
)5)常见使用场景
| 场景 | 推荐配置 |
|---|---|
| 测试后端 API | --save-har-glob="**/api/**" |
| 测试页面加载性能 | 不设置(保存所有) |
| 减少 HAR 文件大小 | 排除图片、CSS、JS |
6)验证是否生效
录制完成后,用文本编辑器打开 HAR 文件,搜索 "entries" 数组,里面应该只包含你指定模式的请求。
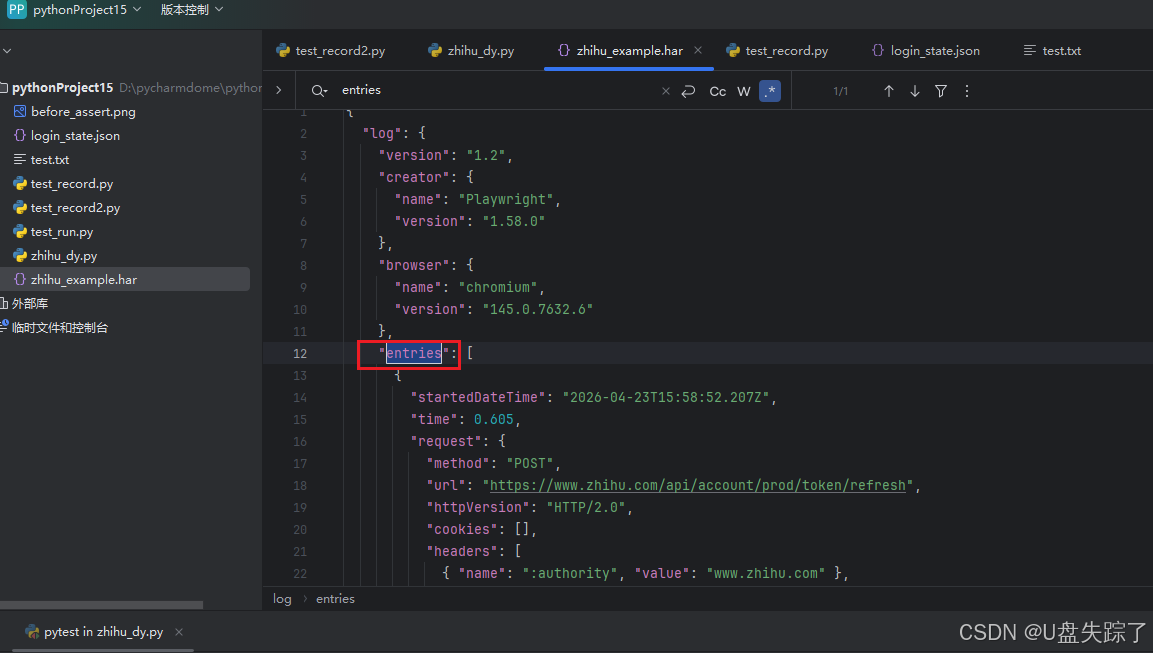
生成的HAR (HTTP Archive) 是一个 JSON 格式的文件,记录了:
-
所有网络请求的 URL、方法、请求头
-
所有网络响应的状态码、响应头、响应体
-
请求和响应的时序信息
6.3 录制HAR示例
# 打开浏览器并开始录制,将匹配 **/api/** 的请求保存到 example.har
# --save-har 参数即保存har文件
playwright open --load-storage=login_state.json --save-har=zhihu_example.har --save-har-glob="**/api/**" https://www.zhihu.com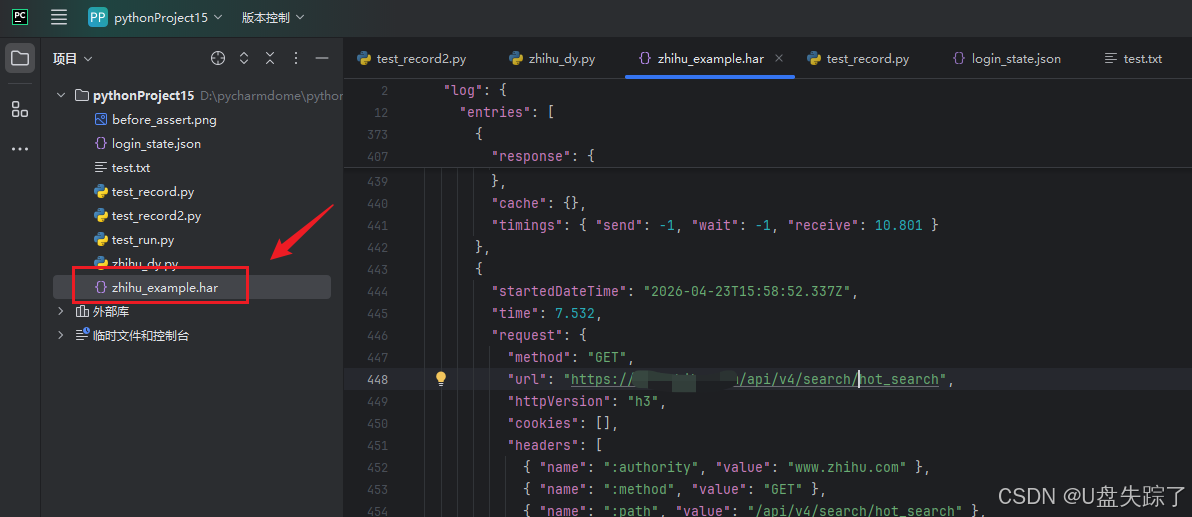
当前录制har文件的数据内容展示
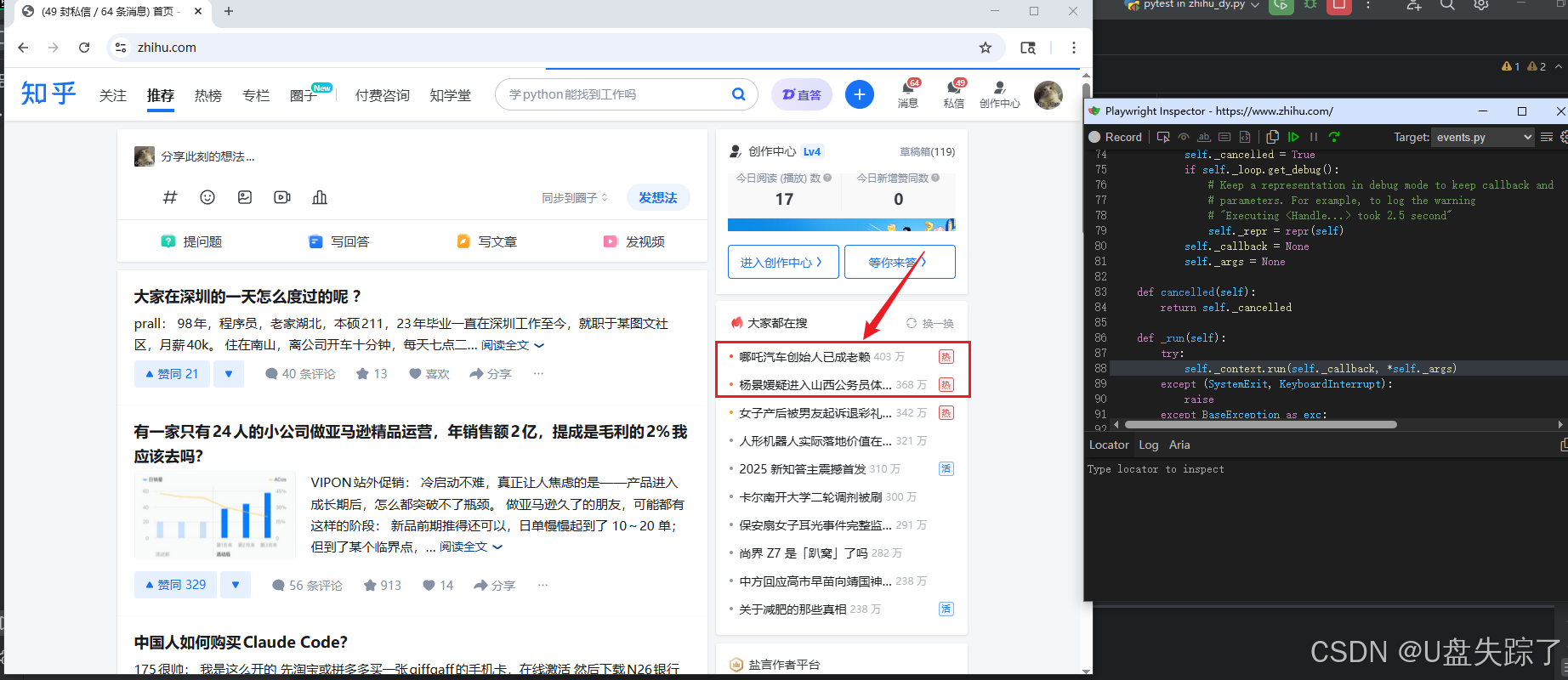
修改har文件数据验证下断言
#!/usr/bin/env python
# -*- coding: utf-8 -*-
#
# 文件名:zhihu_dy.py
# 作者:Administrator
# 日期:2026/4/23
# 描述:
from playwright.sync_api import sync_playwright, expect
def test_case1():
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
# ✅ 关键:加载本地Cookie文件,自动携带登录信息
context = browser.new_context(storage_state="login_state.json")
page = context.new_page()
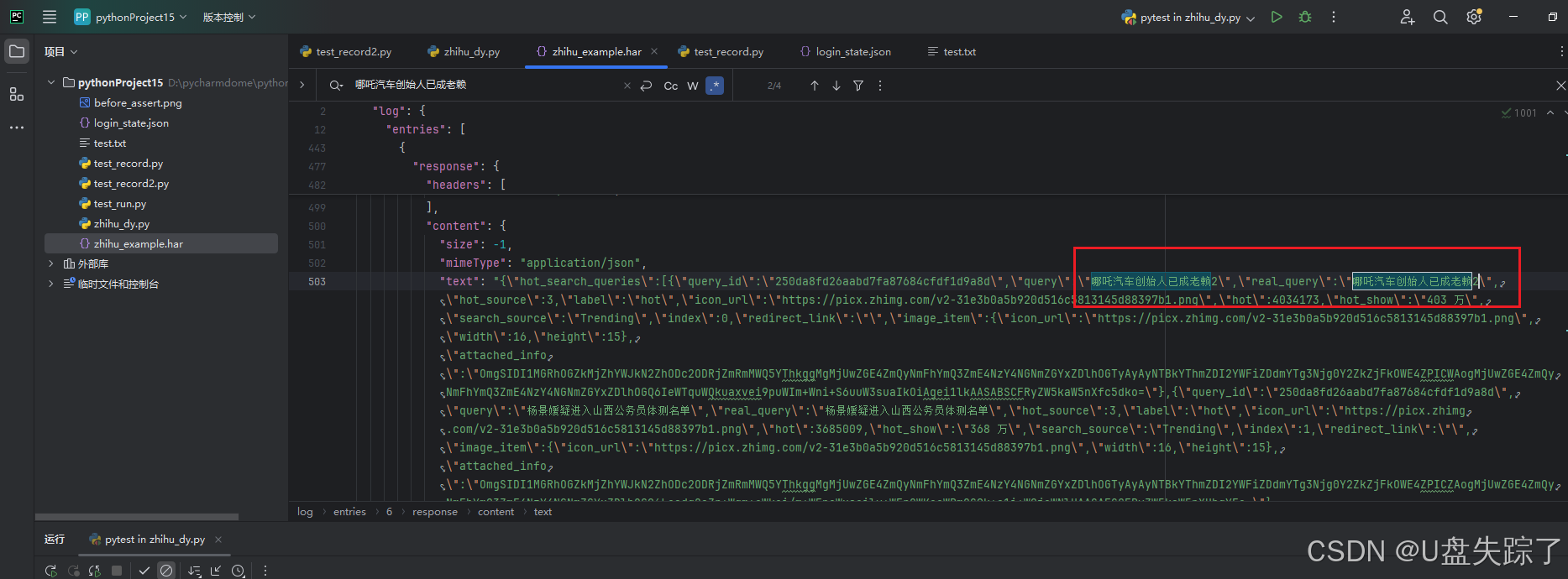
# 关键点:告诉 Playwright 用 example.har 文件里的数据来响应匹配的请求
# update=False 表示直接使用已存好的 HAR 数据,不再发真实网络请求
page.route_from_har("zhihu_example.har", url="*/**/api/**", update=False)
page.goto("https://www.zhihu.com")
# 后续页面上触发的符合条件的请求,都会用 HAR 文件里的数据返回
# 因此你可以正常做 UI 断言,比如:
# page.screenshot(path="before_assert.png")
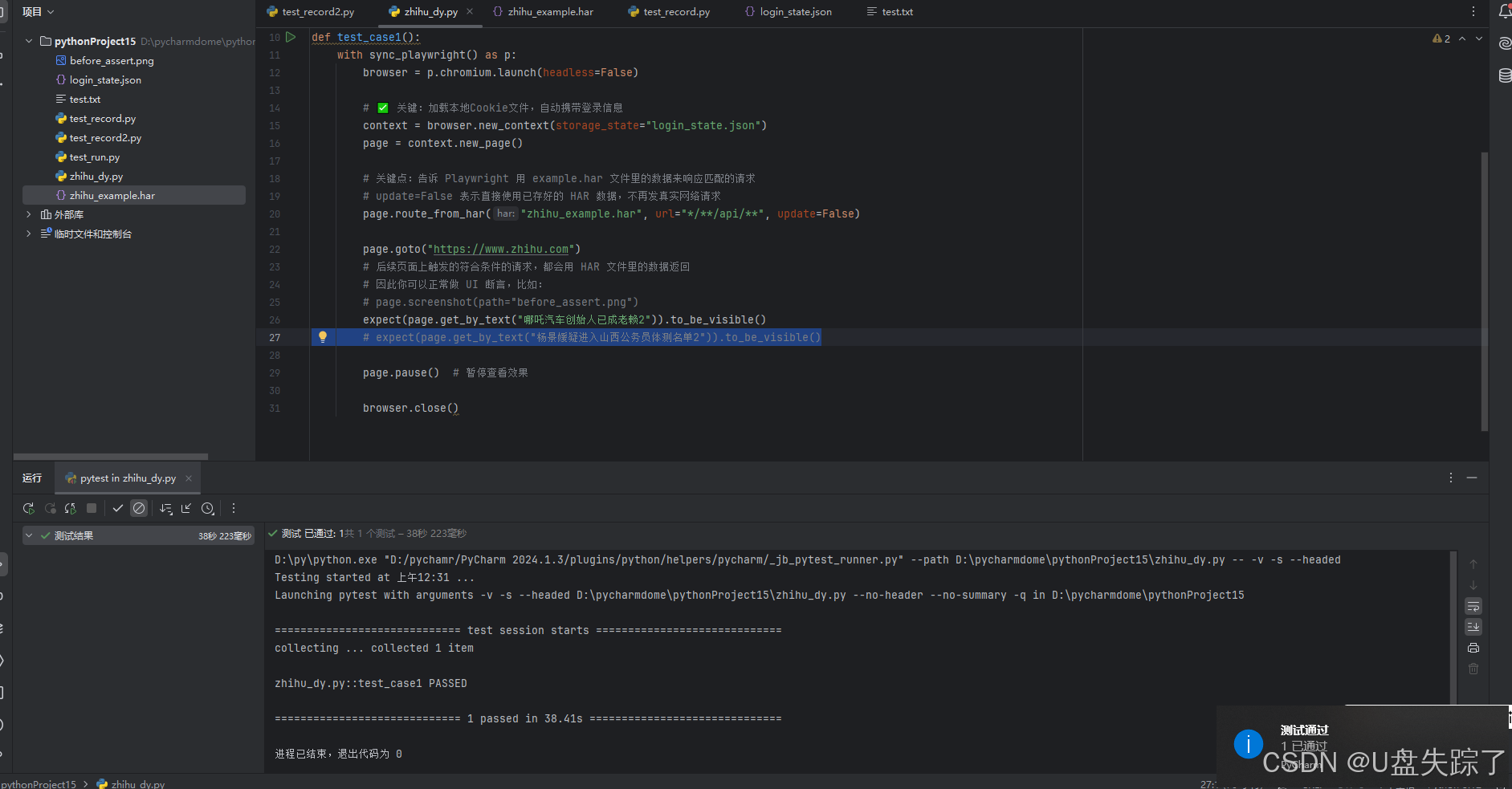
expect(page.get_by_text("哪吒汽车创始人已成老赖2")).to_be_visible()
page.pause() # 暂停查看效果
browser.close()可以看到修改的响应内容,在页面上展示出来了
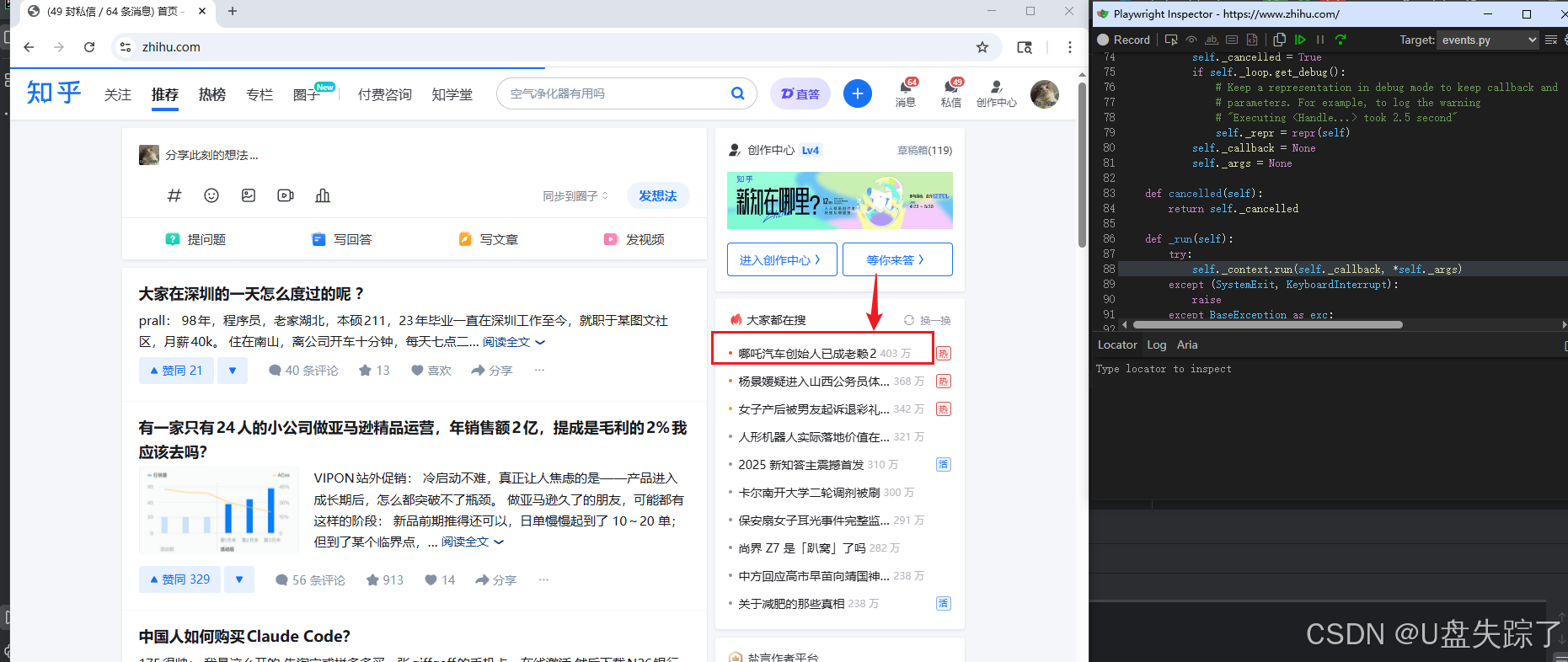
断言也是成功的
# update=False 表示直接使用已存好的 HAR 数据,不再发真实网络请求
page.route_from_har("zhihu_example.har", url="*/**/api/**", update=False)
| 步骤 | 作用 | 操作 | 代码设置 |
|---|---|---|---|
| 1️⃣ 录制 | 录制模式 :发真实网络请求,并把请求/响应写入 HAR 文件 | 跑一次 update=True,生成/更新 HAR 文件 |
route_from_har(..., update=True) |
| 2️⃣ 重放 | 重放模式 :不从真实网络请求,直接从 HAR 文件读取响应 | 改 update=False,跑测试 |
route_from_har(..., update=False) |
7. 录制功能好处
7.1 快速生成登录脚本
登录是大多数系统的基础流程,录制功能可以帮你快速生成包含验证码处理、Cookie 管理的完整登录脚本。
7.2 复杂表单提交
对于包含多级表单、动态字段、文件上传的复杂页面,录制功能可以准确记录每一步操作,避免手动编写时遗漏步骤。
7.3 页面交互调试
当你不确定某个元素的定位方式或操作方法时,录制功能可以帮你快速获取正确的代码片段。
7.4 跨浏览器兼容性测试
通过--browser参数,分别录制不同浏览器的操作,快速生成跨浏览器测试用例。
8. 常见问题与解决方案
8.1 录制的脚本运行失败
原因:页面元素动态变化、选择器不稳定、网络延迟
解决方案:
- 优化选择器,使用更稳定的定位方式
- 添加显式等待,确保元素加载完成
- 启用
--slowmo=1000参数,慢动作录制,便于观察执行过程
8.2 录制的代码冗余
解决方案:
- 删除不必要的操作步骤
- 合并重复的元素定位
- 提取公共方法,提高代码复用性
8.3 无法录制某些操作
原因:部分浏览器原生对话框、文件选择框等无法通过常规方式录制
解决方案:
- 使用 Playwright 的 API 手动处理:
page.on("dialog", lambda dialog: dialog.accept()) - 对于文件上传,使用
page.set_input_files("input[type=file]", "path/to/file")
9. 总结
录制功能是辅助工具 而非替代方案。最佳实践是:录制生成原型 → 手动优化 → 封装复用,让自动化测试既高效又可靠。