别再把 RAG 当知识库:用 AutoClaw 搭一套会进化的 Karpathy LLM Wiki
不是让 AI 帮你"记笔记",而是让 AI 开始"维护知识系统"。
很多人做知识库,默认思路还是 RAG:先把资料堆起来,等提问时再检索、再拼答案。这套方式能回答问题,但不太会积累知识。
Karpathy 在 LLM Wiki 里提出的,恰恰是另一条路:不要把知识处理都放在 query-time,而要尽量前移到 ingest-time。换句话说,LLM 不只是"回答问题的聊天机器人",而应该成为"持续维护 wiki 的知识编译器"。
Karpathy 真正改变的,不是写作,而是知识流转方式
一旦接受这个视角,知识库的结构就会完全不同。
- 第一层是
raw/。这里只放尽量不改的原始资料,比如论文、文章、访谈、截图、报告。 - 第二层是
pages/。这里不是原文搬运区,而是提炼、压缩、链接、重写后的知识页。 - 第三层是
SCHEMA.md。它不是说明文,而是 agent 的执行协议,规定ingest、query、lint、QA和writeback到底怎么做。
真正值钱的,从来不是文件夹本身,而是这套"让知识持续被维护"的协议。
为什么很多 AI 知识库最后都烂尾
不是因为模型不够强, 而是因为知识维护太贵。
如果每次都临时检索、临时拼答案,知识就不会复利。聊天记录再长,也不会自动变成结构化资产。
LLM Wiki 要解决的,正是这个问题:
- 把知识编译动作前置到资料进入系统的那一刻。
- 把高价值回答重新写回 wiki。
- 把一次性对话,变成可持续复用的知识积累。
这也是为什么它不是"高级版 RAG",而更像一套知识维护工作流。
为什么 AutoClaw 特别适合干这件事
关键不在于它会写 Markdown, 关键在于,它能把一串动作串成闭环:
- 先审计当前目录。
- 再原地初始化最小骨架。
- 再读取
SCHEMA.md或 default profile。 - 再创建必要模板、
index.md、log.md和_state/id-counter.md。 - 最后自检 Markdown、同步索引、记录审计,并在没有独立审阅时留下
self_check。
所以你得到的,不是一堆文件。而是一套以后还能继续长大的知识维护协议。
这也是 AutoClaw 和普通"帮你写点内容"的 agent 最大的区别:
- 它不是只负责输出。
- 它开始对结构、流程、回写、ID 分配和验证负责。
想让 LLM Wiki 真正"会进化",有 7 条红线必须提前写清楚
**1. 当前工作目录就是 vault 根目录。**不要再额外套一层 llm-wiki/ 或 wiki/,否则后续路径、规则和工具调用会越来越乱。
**2. 模板是可删减的起点,不是必须填满的表单。**新页可以从 _templates/ 出发,但页面写成后要删除不适用的空章节。不要为了"看起来完整"保留空壳标题。
**3. 元数据要少,但要真。**默认只保留 id、title、type、updated_at 这类必要字段。source_ids、related_ids、parent_ids、conflict_ids 按需出现,不要维护一堆空数组,也不要用 confidence=high 伪装理解。
4. 不使用 child_ids。 source_ids 负责来源追溯,parent_ids 只负责真正的上位概念或结构。能通过 backlink、搜索或派生逻辑得到的关系,不必再手工写第二份。
**5. stable 必须有门槛。**当前可用,不等于稳定结论。
可复用但尚未验证的综合,先写成 draft;页面没有特殊状态压力时,可以省略 status,在 index.md 里显示为 usable。
只有来源、结构、边界都较充分,并经过独立复看或明确人类确认后,才写成 stable。
6. ****ID 分配不能长期靠"扫描最大值 + 1" 。默认用 _state/id-counter.md 记录下一枚可用 ID。创建新页面前先占用 next_id,再把计数器推进到下一枚 ID。多 agent 或反复运行时,这个小文件能避免撞号。
7. self_check ** 不能伪装成独立 QA**。没有独立 QA agent,也要留下验证工件,但必须明确写出它只是当前上下文中的自检,不是 independent 审阅。
这几条看起来像细节,实际上决定了你的 wiki 最后是"可进化系统",还是"AI 生成文档堆"。
LLM Wiki 最关键的升级点,到底是什么?
不是"能不能自动生成更多页"。而是:
一次 ingest,不只是新增几页,而是把新证据编译进旧结构。一次 query,也不只是吐出答案,而是把值得复用的洞察有门槛地写回 wiki。
知识真正开始复利,就是从这里开始的。
所以一个好的 LLM Wiki,不是每一页都写得花哨。而是同时满足四件事:
- 忠于
raw - 页面之间能导航
- 新资料进来时,旧知识能被重写,而不是继续堆料
- 知道什么只是
usable,什么才配叫stable
只要这几点成立,你得到的就不是一份 AI 笔记,而是一个会进化的第二大脑。
实操:从零开始创建llm-wiki
从零开始,使用AutoClaw创建自己的llm-wiki的最小操作流程如下所示:
第一步:请克隆
llm_wiki_prompt 项目到本地。
git clone github.com/AIwork4me/l...
第二步:新建一个名为llm-wiki的AutoClaw分身。
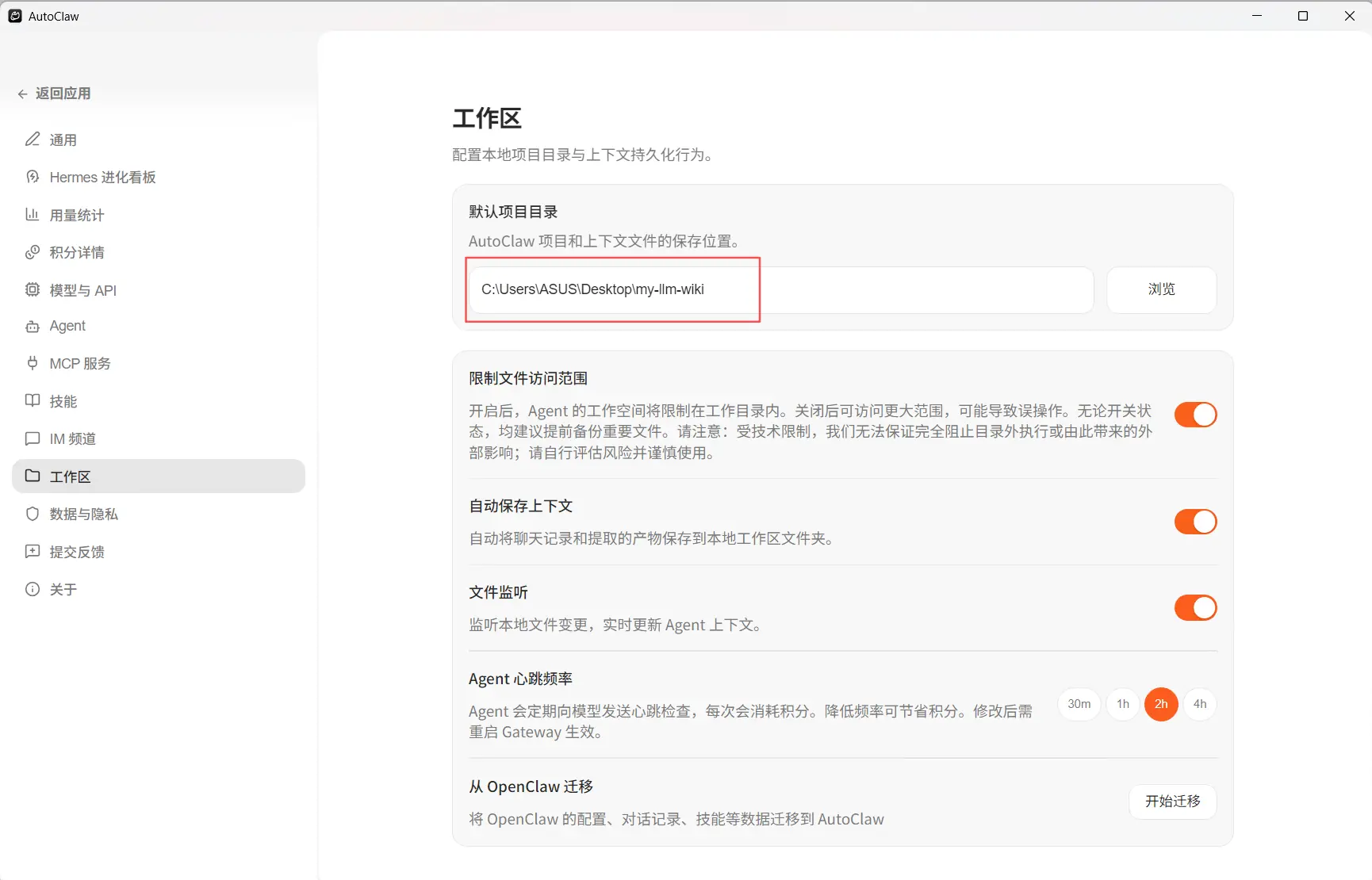
第三步,新建一个空目录, 例如: "my-llm-wiki",作为你的 wiki vault,并将其设置llm-wiki的项目目录。
第四步,把初始化llm-wiki的提示词:llm_wiki_from_scratch.md 发给 AutoClaw
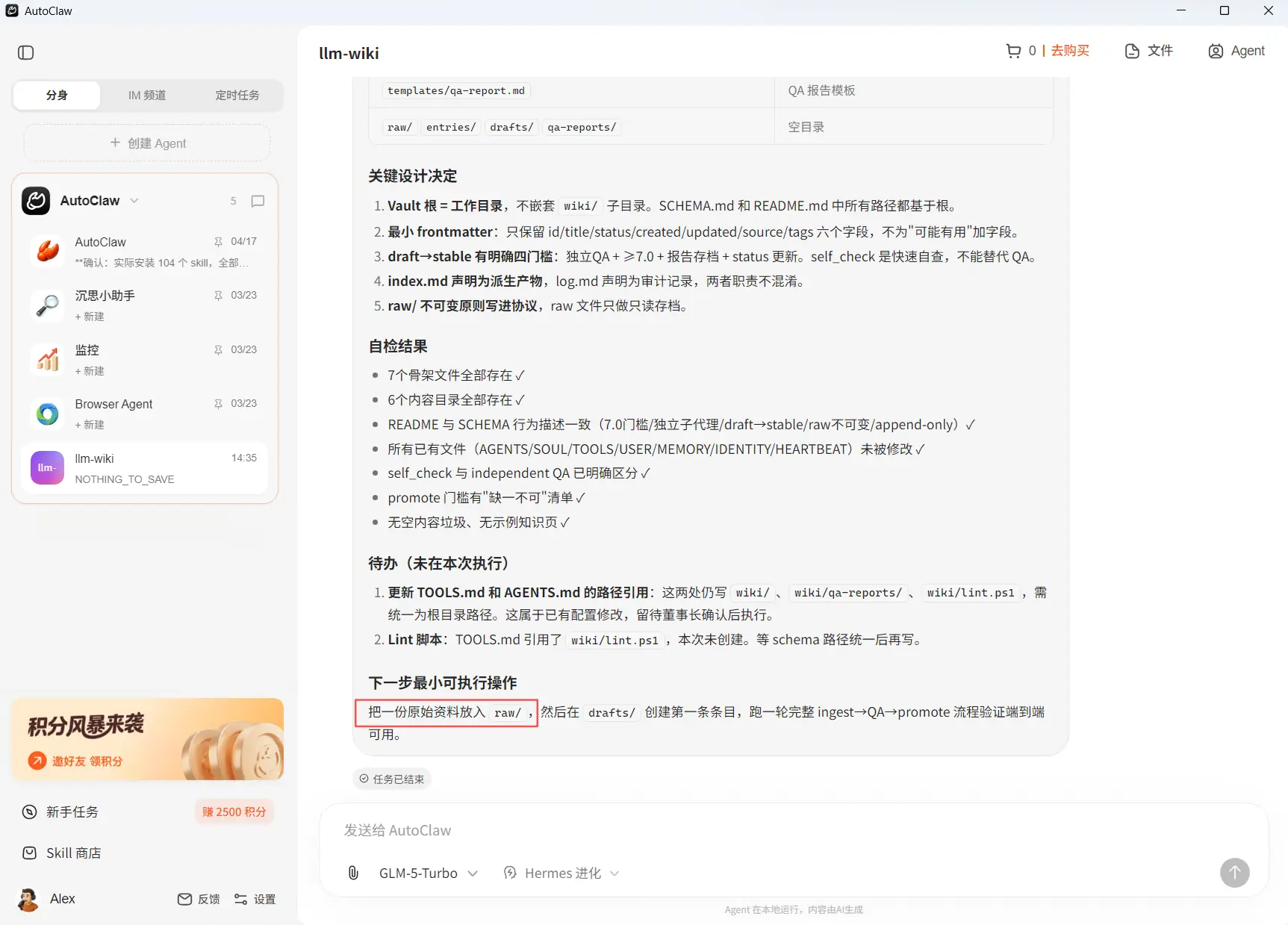
执行完毕后,在llm-wiki 确认生成了 SCHEMA.md、index.md、log.md 和 _state/id-counter.md
第五步 ,把第一份论文、文章或访谈放进文件夹 raw/
告诉它:请 ingest raw/xxx.pdf
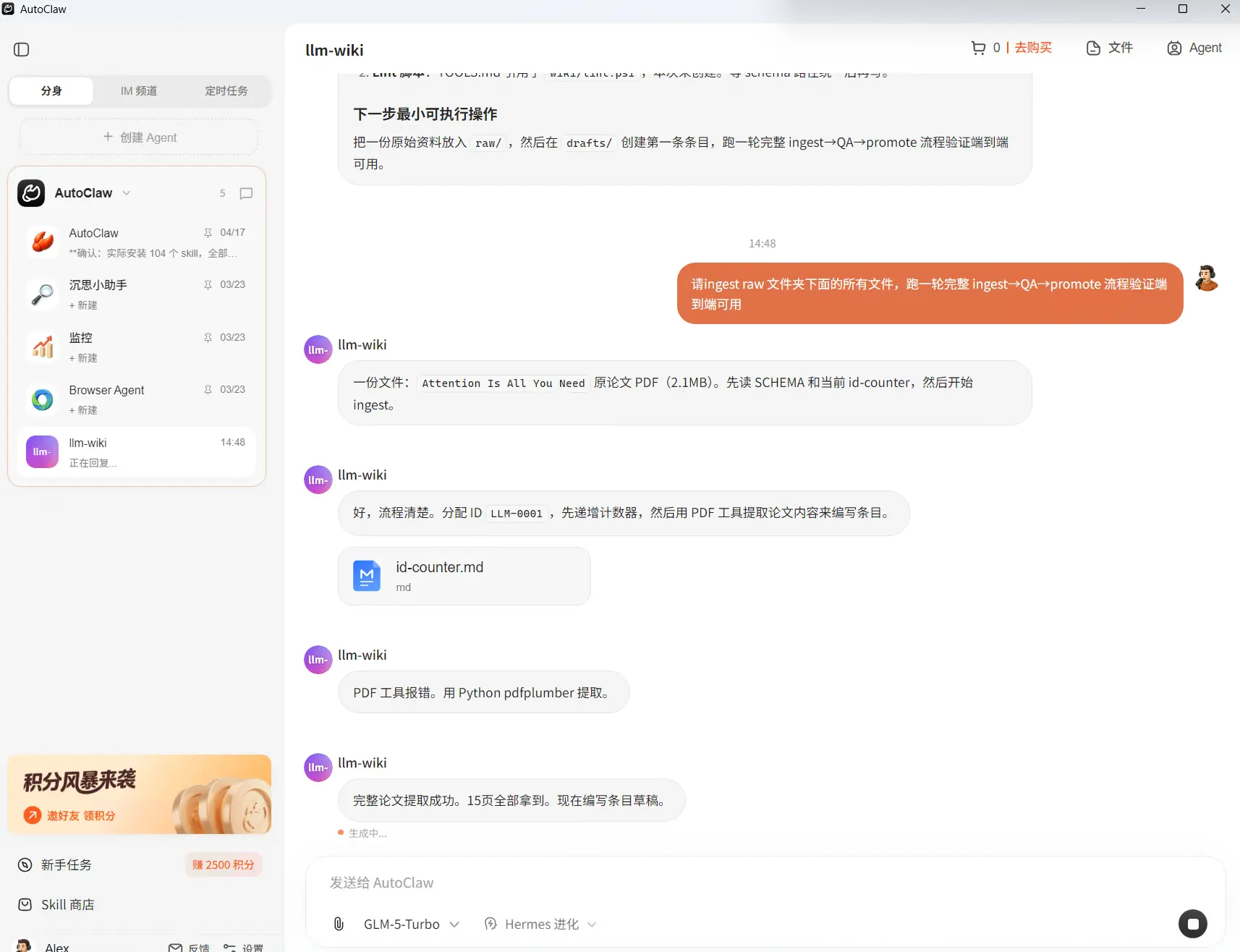
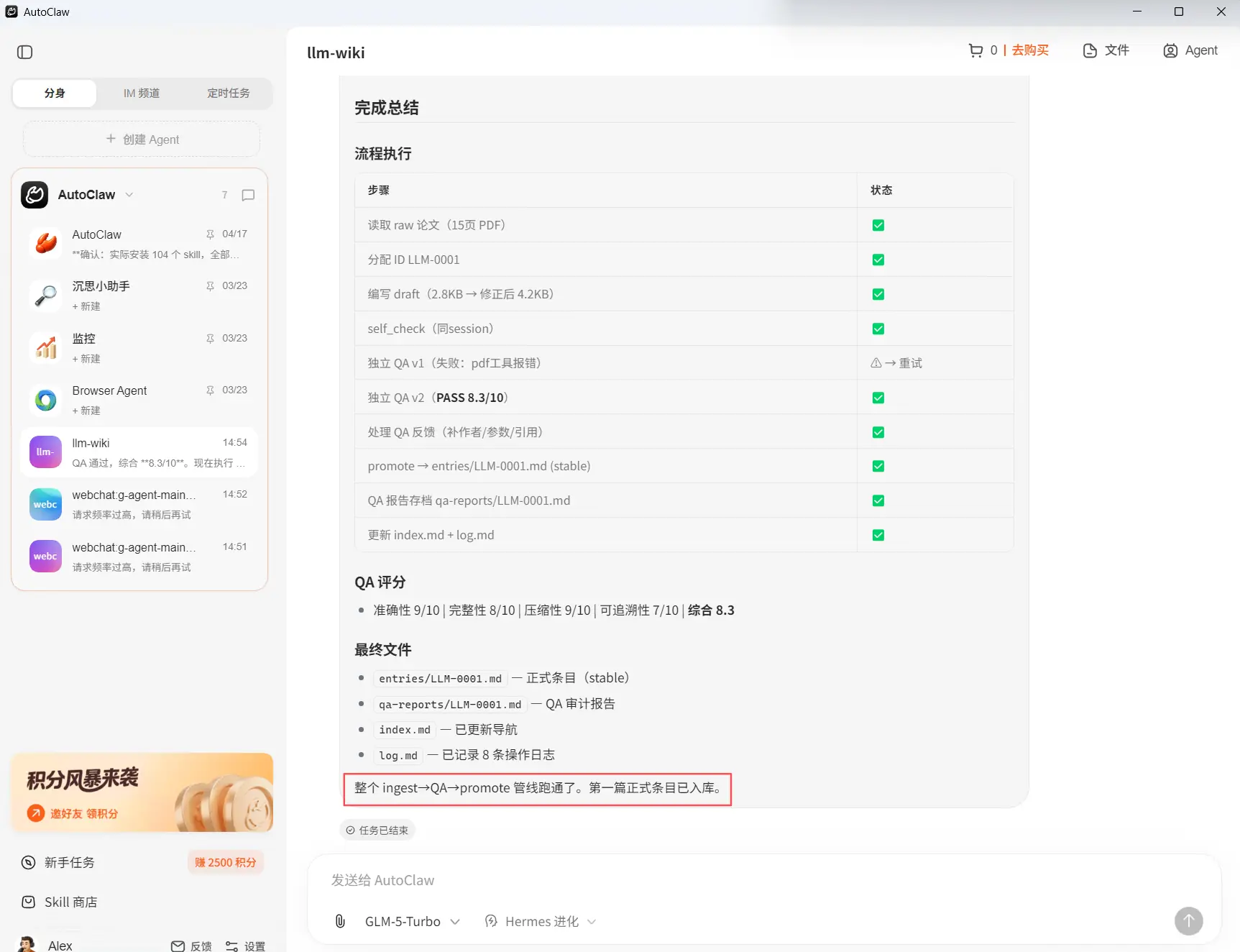
重点检查 index.md、log.md、qa-reports/ 有没有同步更新,stable 有没有被过早使用,并查看AutoClaw的子代理的QA报告,若一切正常,说明:ingest→QA→promote 流程验证端到端可用。
第六步:用obsidian打开my-llm-wiki文件夹,查看创建的wiki。
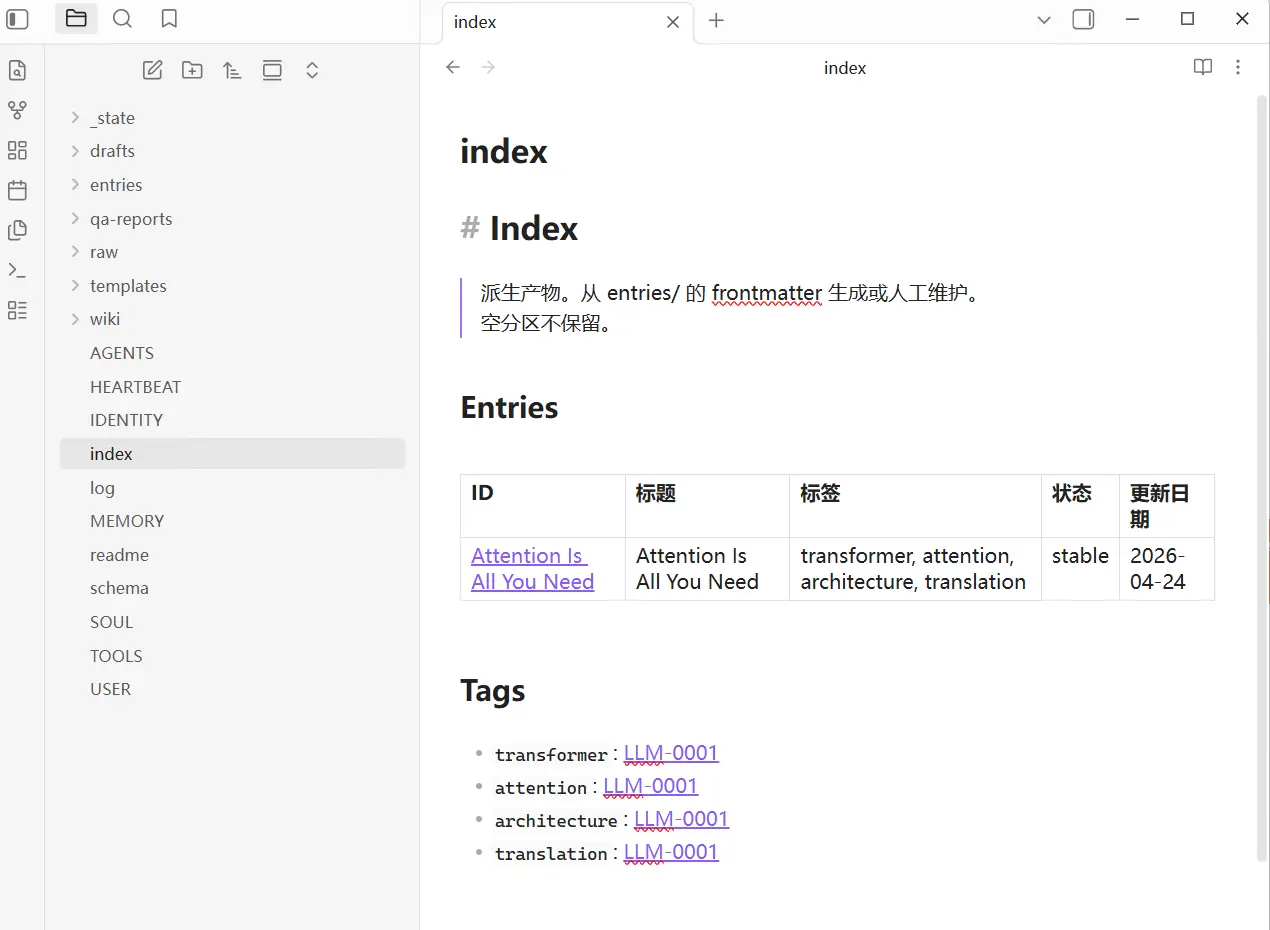
到此,成功创建基于AutoClaw + Obsidian 创建Karpathy 风格的LLM-wiki。接下来只需把的文件放入raw文件夹,请AutoClaw继续处理即可。
结尾
Karpathy 这套思路最厉害的地方,不是让 LLM 更会回答。而是让 LLM 第一次真正变成了知识维护者。
对个人和团队来说,这比一次漂亮答案重要得多。
因为真正稀缺的,从来不是单次输出,
而是一套会越长越好的知识系统。