一、主界面
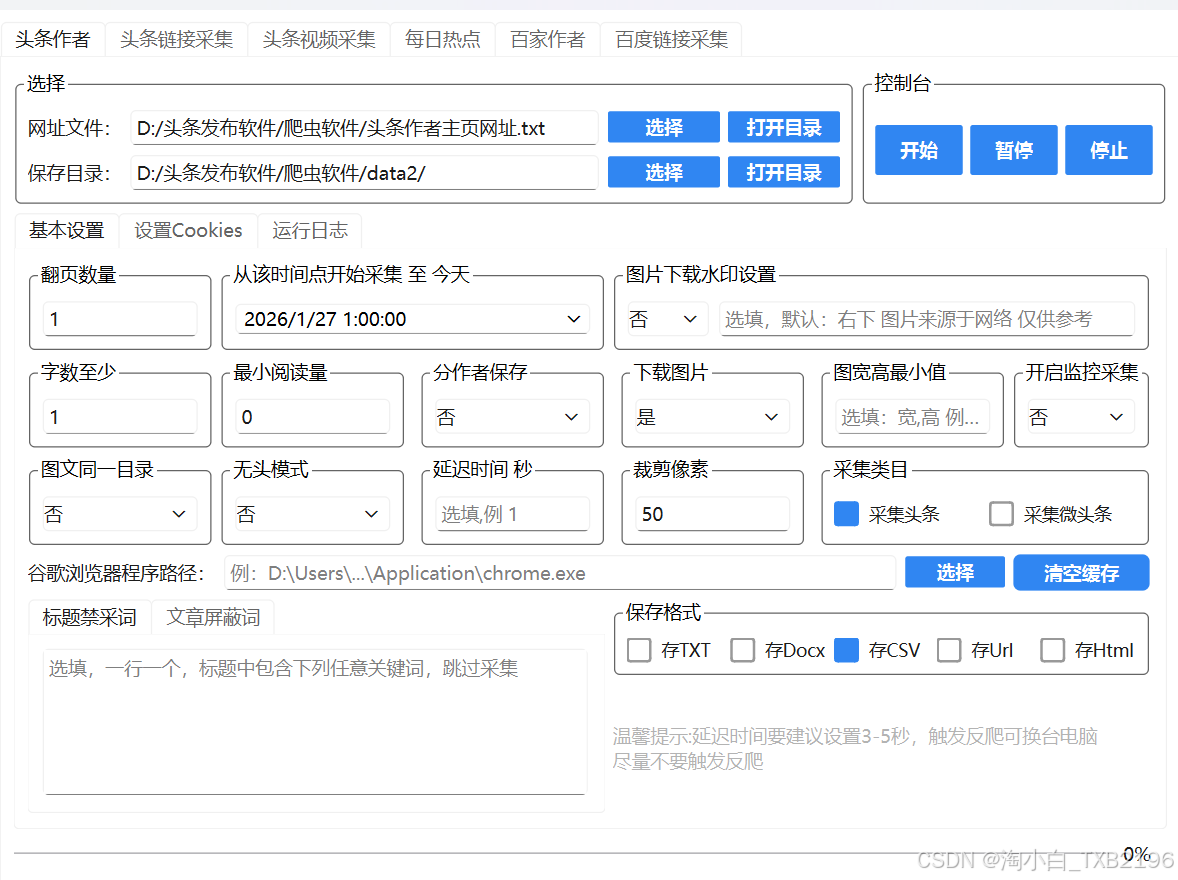
二、头条作者采集
用于批量采集指定头条号作者的所有文章(或微头条),支持按阅读量、字数、发布时间等条件过滤。
2.1 基本设置
-
网址文件:请使用「选择」按钮选取存放作者主页网址的 TXT 文件。
-
保存目录:点击「选择」按钮指定一个文件夹,用于存放采集结果。
2.2 保存格式
支持以下输出格式(可多选或单选,根据实际需求勾选):
-
url:只保存文章网址,生成一个 TXT 文件。 -
txt:每篇文章保存为一个独立 TXT 文件,图片自动下载到同目录下的images文件夹。 -
docx:保存为 Microsoft Word 文档(.docx)。 -
html:保存为网页文件(.html)。 -
csv:仅存储文章网址,生成 CSV 表格文件。
2.3 采集过滤条件
-
最小阅读量:低于此数值的文章将跳过不采集。
-
翻页数量:指在作者文章列表页执行下拉加载的次数(用于触发更多历史文章)。
-
字数限制:文章正文总字数低于此值时不予采集。
-
时间限制:从该时间点开始采集,到当前时间为止,使用选择项选择时间
-
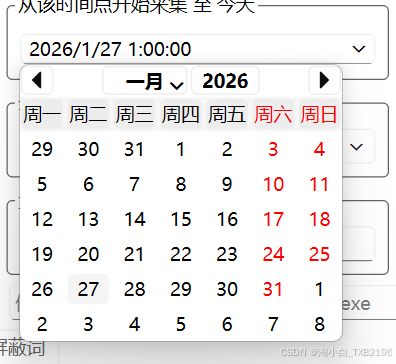
-
文章屏蔽词:每行一个关键词。文章标题或正文包含其中任一关键词,则不采集该文章。注意不要留空行。
-
标题禁采词:标题中包含下面关键词,跳过采集,一行一个
2.4 图片相关设置
-
下载图片的宽高限制:
-
单个数值(如
200):表示图片宽度或高度小于 200 像素则不下载。 -
两个数值(如
200,300):表示宽度小于 200 且高度小于 300 时不下载。
-
-
屏蔽图片 :
0= 正常下载图片;1= 完全不下载图片。 -
裁剪像素:下载图片时从底部向上裁剪指定像素(建议值 30~50),常用于去除水印或无关区域。
-
图文同目录 :仅对 txt 保存模式有效。
-
1:txt 文件与图片共同存放在该文章的专属目录下。 -
0:常规模式,txt 与图片分别存放。
-
2.5 采集行为
-
延迟时间:每采集完一篇文章后暂停的秒数(建议适当设置,避免触发反爬)。
-
头条 Cookie:建议使用软件内置的 Cookie,请勿随意更换;若更换可能导致采集失败。
-
强制监控采集:开启监控采集后,延迟时间要长一些。
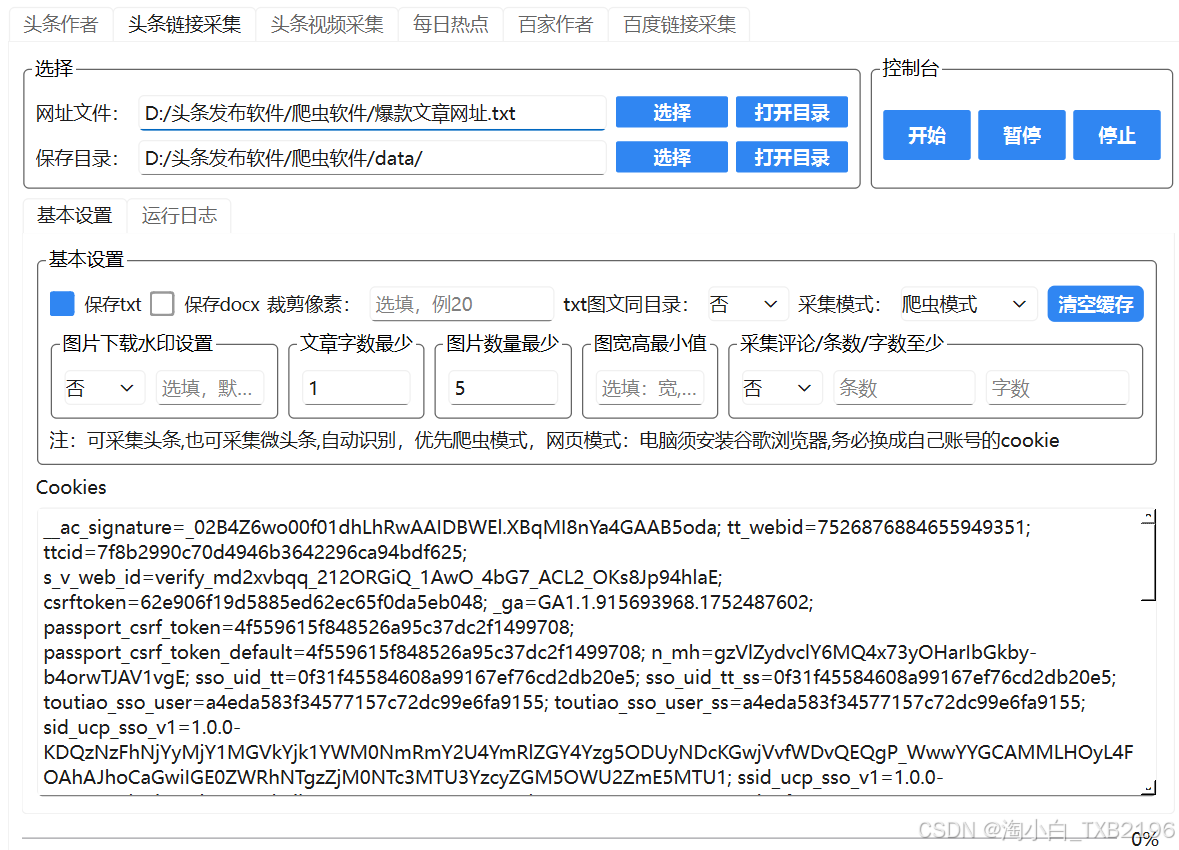
三、头条链接采集
适用于已有具体文章链接(头条或微头条)的场景,例如从易撰等平台导出的爆文网址列表。软件会自动下载文章和图片到本地。
3.1 链接格式注意事项
- 微头条链接转换 :若从易撰等获取的微头条链接格式为
https://www.toutiao.com/item/123/,需手动将item改为w,即https://www.toutiao.com/w/123/,否则软件无法识别。
3.2 基本设置
-
网址文件:点击「选择」按钮选取存放链接的 TXT 文件(每行一个链接)。
-
保存目录:点击「选择」按钮指定存放结果的文件夹。
-
保存 txt:将每篇文章保存为 TXT 文件。
-
保存 docx:将每篇文章保存为 Word 文档。
3.3 图片与采集模式
-
裁剪像素:同头条作者采集中的说明(从底部裁剪图片)。
-
txt 图文同目录 :仅对 TXT 格式有效,设为
1时 TXT 与图片存放在同一文章目录下。 -
采集模式:
-
爬虫模式(推荐):直接请求网页源码(速度快,但可能被反爬)。
-
网页模式 :驱动谷歌浏览器进行渲染采集。使用网页模式时必须填入自己的头条账号 Cookie,因为许多链接需要登录后才能访问,否则会跳转到登录页面。
-
四、每日热点
获取各个平台实时热门话题,实时关注热门词条!
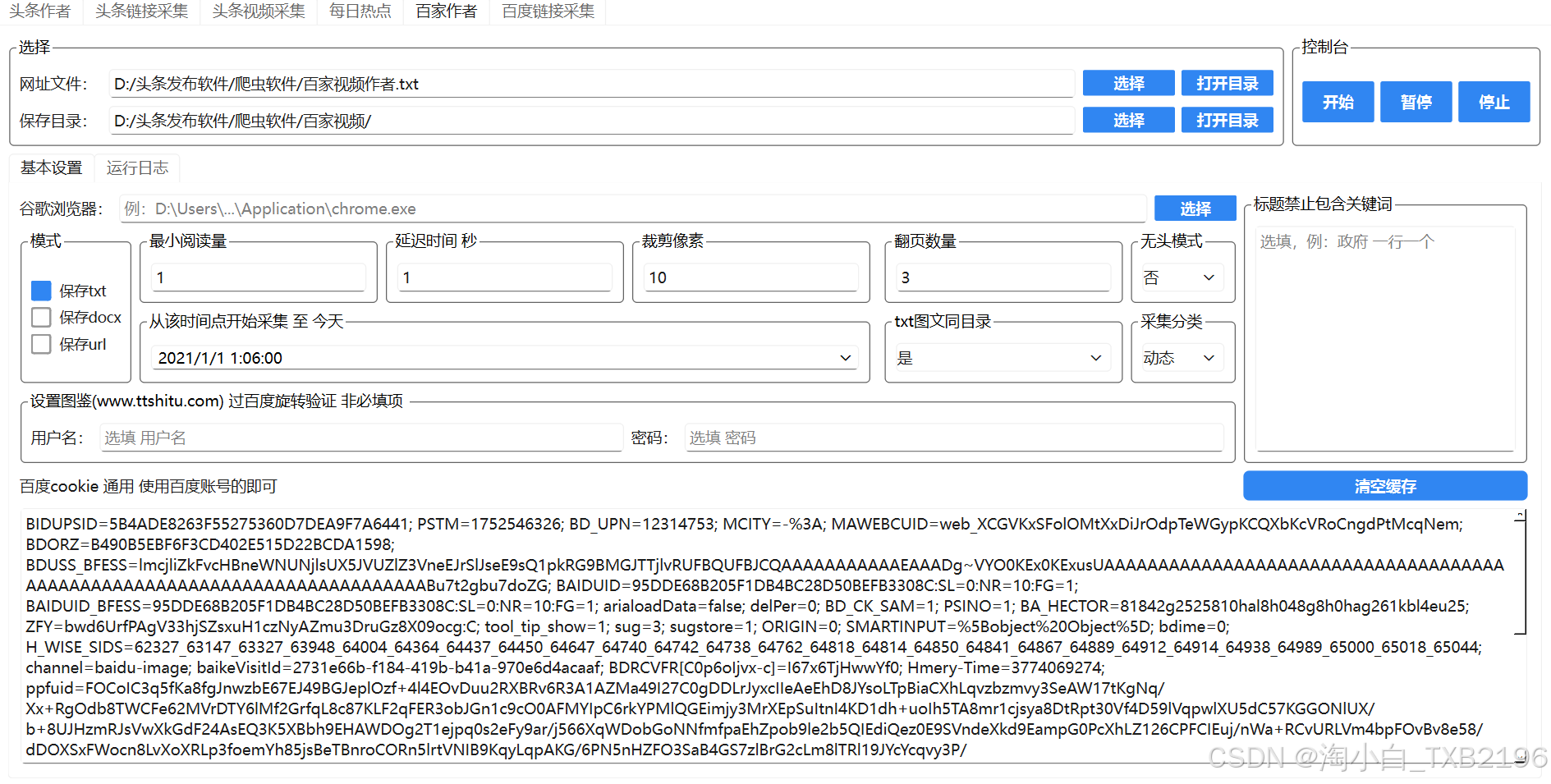
五、百家号作者采集
本模块用于批量采集指定百家号作者发布的文章。
5.1 获取百家号作者网址
打开目标百家号作者的主页网址按行存入 TXT 文件,然后通过「选择」按钮加载该文件。
5.2 特有功能(与头条作者采集不同之处)
-
生成竖图:为方便文章发布至百家号时调用竖图缩略图而设计。可根据需要选择开启(生成)或不生成。
-
标题禁止包含关键词:每行一个关键词。若文章标题包含其中任一词语,则不采集该文章。
-
百度 Cookie:请使用您自己的百度账号 Cookie 进行采集。
其余设置(保存格式、过滤条件、图片处理、延迟时间等)与头条作者采集基本一致,请参考第二节。
六、百家号链接采集
适用于已有具体百家号文章链接或百度动态文章链接的场景。将链接整理到 TXT 文件中,软件即可自动采集。
6.1 设置说明
-
基本选项(保存目录、保存格式、图片裁剪、图文同目录等)与头条链接采集相同。
-
采集模式同样提供:
-
网页模式 (推荐)(驱动浏览器,需使用自己的百度账号 Cookie)
-
爬虫模式(直接抓取源码)
-