TorchMetrics是一个包含100多个PyTorch指标实现的集合(如分类、检测、分割、回归等),并提供易于使用的API来创建自定义指标。可以将TorchMetrics与任何PyTorch模型或PyTorch Lightning结合使用。源码地址:https://github.com/Lightning-AI/torchmetrics,最新发布版本为v1.9.0,license为Apache-2.0。
安装完YOLO环境后,执行以下命令:评估指标任务不同,安装命令也不同
bash
pip install torchmetrics
pip install torchmetrics[detection]YOLOv8/YOLO11/YOLO26有自己内置的评估逻辑 ,一般不建议直接在训练循环内部强行替换其指标计算。这里训练完YOLOv8后评估,只是为了演示TorchMetrics的使用。
Classify主要测试代码如下:
python
def _parse_label_file(label_file):
idx_to_class = {}
class_to_idx = {}
with open(label_file, mode="r", encoding="utf-8") as f:
for line in f:
line = line.strip()
if not line:
continue
idx, name = line.split()
idx = int(idx)
idx_to_class[idx] = name
class_to_idx[name] = idx
return idx_to_class, class_to_idx
def _get_images(images_path):
image_files = list(Path(images_path).rglob("*.*"))
image_files = [p for p in image_files if p.suffix.lower() in [".jpg", ".jpeg", ".png", ".bmp", ".webp"]]
if len(image_files) == 0:
raise RuntimeError(colorama.Fore.RED + f"no images found: {images_path}")
return image_files
def test_classify(model_name, images_path, label_file):
if model_name is None or not model_name or not Path(model_name).is_file():
raise FileNotFoundError(colorama.Fore.RED + f"{model_name} is not a file")
if images_path is None or not images_path or not Path(images_path).is_dir():
raise FileNotFoundError(colorama.Fore.RED + f"{images_path} is not a directory")
if label_file is None or not label_file or not Path(label_file).is_file():
raise FileNotFoundError(colorama.Fore.RED + f"{label_file} is not a file")
_, class_to_idx = _parse_label_file(label_file)
print(f"class to idx: {class_to_idx}")
num_classes = len(class_to_idx)
acc_metric = MulticlassAccuracy(num_classes=num_classes)
f1_metric = MulticlassF1Score(num_classes=num_classes)
acc_metric.reset()
f1_metric.reset()
image_files = _get_images(images_path)
model = YOLO(model_name)
model.eval()
with torch.no_grad():
for img_path in image_files:
class_name = img_path.parent.name
if class_name not in class_to_idx:
print(colorama.Fore.YELLOW + f"invalid image file: {img_path}")
continue
gt_label = class_to_idx[class_name]
results = model(str(img_path), verbose=False)
probs = results[0].probs.data
pred_label = int(torch.argmax(probs).item())
pred_tensor = torch.tensor([pred_label])
gt_tensor = torch.tensor([gt_label])
acc_metric.update(pred_tensor, gt_tensor)
f1_metric.update(pred_tensor, gt_tensor)
acc = acc_metric.compute().item()
f1 = f1_metric.compute().item()
print(colorama.Fore.GREEN + f"Accuracy: {acc:.4f}\nF1 Score: {f1:.4f}")执行结果如下图所示:

Detect主要测试代码如下:
python
def test_detect(model_name, images_path, txts_path):
if model_name is None or not model_name or not Path(model_name).is_file():
raise FileNotFoundError(colorama.Fore.RED + f"{model_name} is not a file")
if images_path is None or not images_path or not Path(images_path).is_dir():
raise FileNotFoundError(colorama.Fore.RED + f"{images_path} is not a directory")
if txts_path is None or not txts_path or not Path(txts_path).is_dir():
raise FileNotFoundError(colorama.Fore.RED + f"{txts_path} is not a directory")
image_files = _get_images(images_path)
preds_all = []
targets_all = []
model = YOLO(model_name)
model.eval()
with torch.no_grad():
for img_path in image_files:
txt_path = txts_path + "/" + img_path.stem + ".txt"
if not Path(txt_path).exists():
raise FileNotFoundError(colorama.Fore.RED + f"{txt_path} does not exist")
img = cv2.imread(str(img_path))
if img is None:
raise FileNotFoundError(colorama.Fore.RED + f"unable to load image file: {img_path}")
h, w = img.shape[:2]
gt_boxes = []
gt_labels = []
with open(txt_path, mode="r", encoding="utf-8") as f:
for line in f:
parts = line.strip().split()
if len(parts) != 5:
raise RuntimeError(colorama.Fore.RED + f"{txt_path}: file content is incorrect")
cls = int(parts[0])
cx, cy, bw, bh = map(float, parts[1:])
x1 = (cx - bw / 2) * w
y1 = (cy - bh / 2) * h
x2 = (cx + bw / 2) * w
y2 = (cy + bh / 2) * h
gt_boxes.append([x1, y1, x2, y2])
gt_labels.append(cls)
if len(gt_boxes) == 0:
gt_boxes = torch.zeros((0, 4))
gt_labels = torch.zeros((0,), dtype=torch.int64)
else:
gt_boxes = torch.tensor(gt_boxes, dtype=torch.float32)
gt_labels = torch.tensor(gt_labels, dtype=torch.int64)
results = model(str(img_path), verbose=False)[0]
if results.boxes is None or len(results.boxes) == 0:
pred_boxes = torch.zeros((0, 4))
pred_scores = torch.zeros((0,))
pred_labels = torch.zeros((0,), dtype=torch.int64)
else:
pred_boxes = results.boxes.xyxy.cpu()
pred_scores = results.boxes.conf.cpu()
pred_labels = results.boxes.cls.cpu().to(torch.int64)
preds_all.append({"boxes": pred_boxes, "scores": pred_scores, "labels": pred_labels})
targets_all.append({"boxes": gt_boxes, "labels": gt_labels})
print(f"total samples: {len(preds_all)}")
metric = MeanAveragePrecision(iou_type="bbox", class_metrics=True)
metric.update(preds_all, targets_all)
result = metric.compute()
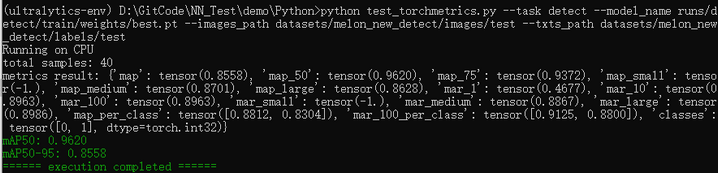
print(f"metrics result: {result}")
map50 = result["map_50"].item()
map5095 = result["map"].item()
print(colorama.Fore.GREEN + f"mAP50: {map50:.4f}\nmAP50-95: {map5095:.4f}")执行结果如下图所示:
Segment主要测试代码如下:
python
def _polygon_to_mask(polygons, h, w):
mask = np.zeros((h, w), dtype=np.uint8)
for poly in polygons:
pts = np.array(poly, dtype=np.int32).reshape(-1, 2)
cv2.fillPoly(mask, [pts], 1)
return mask
def test_segment(model_name, images_path, txts_path):
if model_name is None or not model_name or not Path(model_name).is_file():
raise FileNotFoundError(colorama.Fore.RED + f"{model_name} is not a file")
if images_path is None or not images_path or not Path(images_path).is_dir():
raise FileNotFoundError(colorama.Fore.RED + f"{images_path} is not a directory")
if txts_path is None or not txts_path or not Path(txts_path).is_dir():
raise FileNotFoundError(colorama.Fore.RED + f"{txts_path} is not a directory")
image_files = _get_images(images_path)
model = YOLO(model_name)
num_classes = len(model.names) + 1 # 0:background
metric = MeanIoU(num_classes=num_classes, per_class=True, input_format="index")
metric.reset()
total = 0
target_size = (480, 480)
model.eval()
with torch.no_grad():
for img_path in image_files:
txt_path = txts_path + "/" + img_path.stem + ".txt"
if not Path(txt_path).exists():
raise FileNotFoundError(colorama.Fore.RED + f"{txt_path} does not exist")
img = cv2.imread(str(img_path))
if img is None:
raise FileNotFoundError(colorama.Fore.RED + f"unable to load image file: {img_path}")
h, w = img.shape[:2]
gt_mask = np.zeros((h, w), dtype=np.uint8)
pred_mask = np.zeros((h, w), dtype=np.uint8)
with open(txt_path, mode="r", encoding="utf-8") as f:
for line in f:
parts = list(map(float, line.strip().split()))
cls = int(parts[0])
coords = parts[1:]
pts = []
for i in range(0, len(coords), 2):
x = coords[i] * w
y = coords[i + 1] * h
pts.append([x, y])
mask = _polygon_to_mask([pts], h, w)
gt_mask[mask == 1] = cls + 1
results = model(str(img_path), verbose=False)[0]
if results.masks is not None:
masks = results.masks.data.cpu().numpy()
classes = results.boxes.cls.cpu().numpy().astype(int)
for i in range(len(masks)):
m = masks[i]
cls = classes[i]
m = (m > 0.5).astype(np.uint8)
m = cv2.resize(m, (w, h), interpolation=cv2.INTER_NEAREST)
pred_mask[m == 1] = cls + 1
pred_tensor = torch.tensor(cv2.resize(pred_mask, target_size, interpolation=cv2.INTER_NEAREST)).long()
gt_tensor = torch.tensor(cv2.resize(gt_mask, target_size, interpolation=cv2.INTER_NEAREST)).long()
metric.update(pred_tensor.unsqueeze(0), gt_tensor.unsqueeze(0))
total += 1
miou_per_class = metric.compute()
print(f"metrics result(per class): {miou_per_class}")
miou = miou_per_class[1:].mean().item() # remove backgroud
print(colorama.Fore.GREEN + f"total samples: {total}\nmIoU: {miou:.4f}")执行结果如下图所示:
