在追求语音合成自然度和情感表现力的道路上,一个长期存在的技术挑战在于:如何让机器生成的语音,像真人一样自然地发出笑声、哭声或咳嗽等非言语声音(Non-Verbal Sounds,NVs)。这些声音是传递情感、丰富交流的重要载体。然而,当前大多数高质量语音合成数据集都缺乏对这些非言语声音的精确标注,这直接导致了能够自然生成此类声音的语音合成系统寥寥无几。
为了填补这一关键数据空白,希尔贝壳联合昆山杜克大学正式开源"SMIIP-NV 数据集"。这是目前已知规模最大的、开源的、包含非言语声音标注的情感语音合成数据集。它的发布旨在为攻克"带有情感的、可发声的"语音合成这一难题提供坚实的数据基础。
"SMIIP-NV: A Multi-Annotation Non-Verbal Expressive Speech Corpus in Mandarin for LLM-Based Speech Synthesis" 被多媒体顶级会议ACM MM 2025录用。

-
Huggingface****:********https://huggingface.co/xunyi/SMIIP-NV_finetune_CosyVoice2****
数据说明
SMIIP-NV 语料库是一个同时标注了情感与非言语声音的语音合成语料库,非言语声音涵盖了笑声、哭声以及咳嗽声。该语料库包含 33 小时语音数据,覆盖 5 种不同情感及 3 类非言语发声,针对非言语部分标注了文本以及精确的时间戳信息。此外,语料库还针对包含笑声或哭声的语音片段进行了专项标注。为验证本数据集的实用价值,我们采用轻量级大语言模型(LLM),搭建了非言语语音合成任务的基准模型。
试验说明
基于该数据集,我们在一种轻量级LLM的非自回归语音合成框架上构建了非言语语音合成基线系统,并进一步在主流开源语音合成系统 CosyVoice2 上进行了微调实验验证。
在基线系统中,我们采用基于 Transformer 的轻量级非自回归语音合成模型作为基础架构,并将笑声、哭声和咳嗽等非言语发声形式和情感标签显式引入为特殊控制标记。模型首先在 WenetSpeech4TTS(约 10,000 小时)上进行大规模预训练,随后使用 SMIIP-NV 数据集进行微调,从而学习在语音合成过程中生成自然、可控的非言语表达。此外,为验证数据集的通用性与迁移能力,我们基于开源系统 CosyVoice2-0.5B 官方模型进行微调,仅新增非言语特殊标记而不改变其原有结构,并在分布式多卡环境下完成训练。
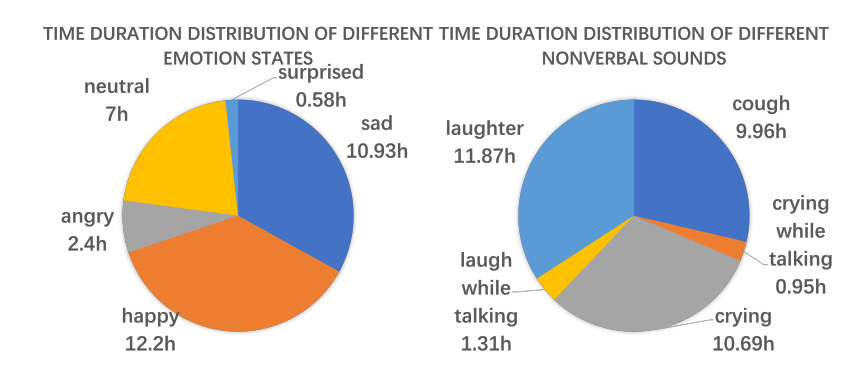
图1非言语及情感数据时长分布
实验结果表明,微调后的基线模型在测试集上的主观评测结果显示,合成的笑声、哭声和咳嗽在自然度上的 MOS 分别达到 4.18、4.18 和 3.99 ,与真实语音高度接近;在 CosyVoice2 上的微调实验中,非语言语音的 MOS 均超过 4.0,验证了 SMIIP-NV 数据集良好的有效性与泛化能力。
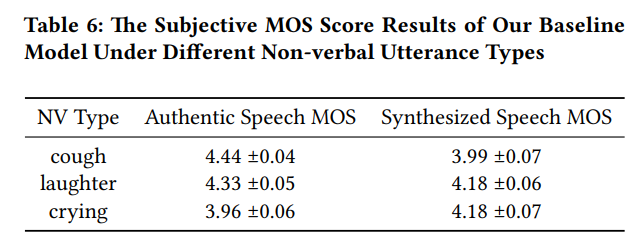
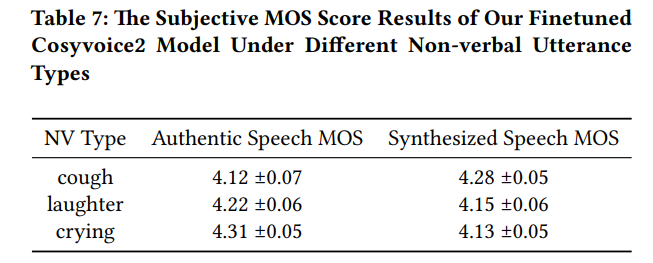
图2SMIIP-NV微调基线模型主观MOS**评估结果