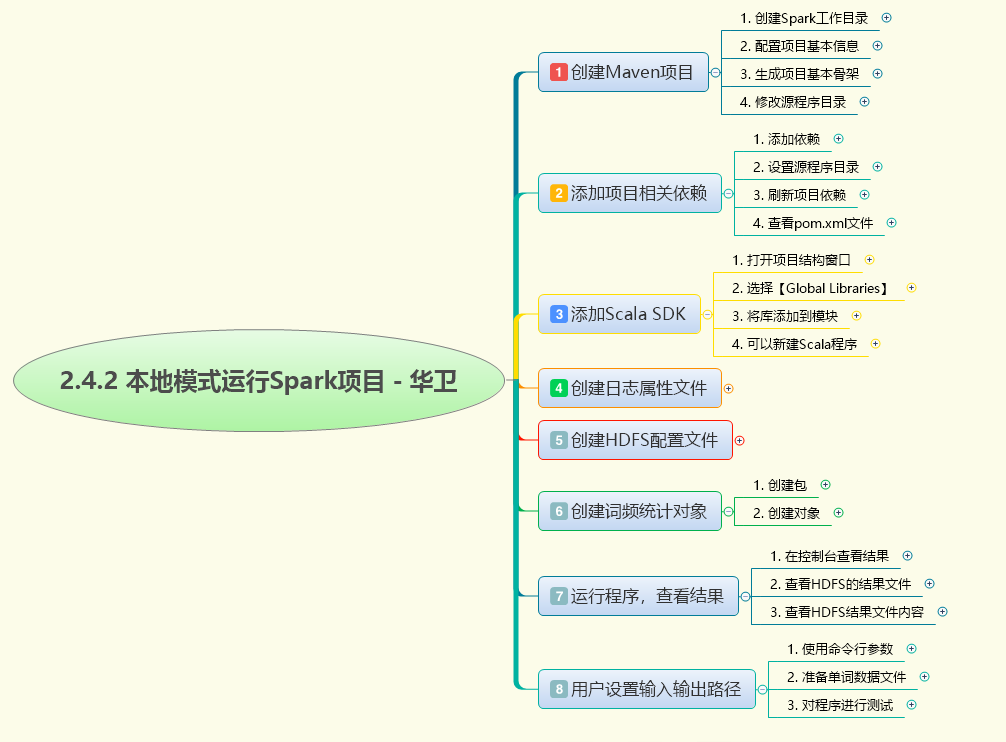
本次实战演示如何在本地模式下运行Spark项目进行词频统计。首先创建Maven项目并配置Spark 3.1.3依赖和Scala SDK,设置JDK 8环境。接着创建必要的配置文件如log4j.properties和hdfs-site.xml。在net.huawei.rdd包下创建WordCount对象,实现Spark RDD词频统计功能:读取HDFS文件,通过flatMap分割单词,map映射为键值对,reduceByKey聚合计数,最后按词频降序排列。程序支持命令行参数自定义输入输出路径,并将结果保存到HDFS。整个过程涵盖了从项目创建、环境配置到代码实现和测试的完整流程。