在集星獭编排对接过程中,客户项目团队及交付团队常面临各类高频问题,此类问题的反复上报不仅耗费大量沟通成本,还会影响项目整体推进效率。
为有效解决上述痛点,提升编排对接效率,集星獭团队梳理了对接过程中的核心问题,整理形成常见问题清单,目前已发布至汉得开放平台。
重点覆盖以下高频问题,精准解决编排对接过程中的各类障碍:
- 编排不执行问题(包括同步、异步执行)
- 日志记录问题
- 任务节点取值问题
- 各类消息队列问题
同步执行问题
一、执行响应耗时很长甚至超时
问题描述
通过postman或者其他调用工具同步调用编排接口(编排对应的透传接口)时,接口调用耗时很长甚至报调用超时的错误,但是编排实例的耗时和每个任务实例的耗时又比较短。
接口返回的错误消息或者后台服务日志中通常会包含 error.horc.wait_response_timeout,默认是5分钟没有返回响应就会报超时错误。
问题原因
编排同步执行的效率受影响于jipaas-orchestration-workloader服务的cpu核心数,最大并发数默认为cpu核心数,例如cpu核心数为1,那么最大并发只有1;
另外对于k8s部署的,若没有手动设置workloader服务的cpu(resources.limits.cpu),cpu核心数只有1,最大并发也只有1
解决方案
-
针对k8s部署的需要手动设置workloader服务pod的cpu配置,尽可能调大为8核心以上,争对物理机部署的同样也需尽量保证workloader服务所属机器cpu为8核以上
-
不要部署jipaas-orchestration-all服务模式,建议部署jipaas-orchestration、jipaas-orchestration-workloader服务,因为部署all模式会间接增大workloader服务的cpu使用
-
同步执行的最大并发数默认为cpu核心数,也可以手动设置workloader服务的配置项 hzero.orchestration.worker.sync-execute-thread-nums(同步执行最大并发),可以调整为cpu核心数x2;hzero.orchestration.netty.server.worker-thread(netty客户端的并发),可以调整为cpu核心数x2
-
针对1.8之前的版本,horc_orch_task_instance表数据量巨大也会增加耗时,可以删除历史数据。
二、执行报错:no_suitable_workloader
问题描述
编排同步执行报错,接口返回的错误消息包含:error.horc.no_suitable_workloader,无法执行编排任务。
问题原因
这种错误首先只有当编排部署为集群模式(zk/etcd)时才会出现,原因是manager服务没有找到合适的workloader服务执行任务,实际可能原因如下:
- 集群内没有存活的workloader服务
- 编排执行时传递了工作组(workerGroup),但是没有该工作组对应的workloader服务存活;配置项: hzero.orchestration.worker.worker-group
- workloader服务虽然存活,但是该服务的cpu或者内存资源不足,也会被认为当前服务不可用,无法执行编排任务。
解决方案
-
若是workloader服务宕机了,可以重启该服务
-
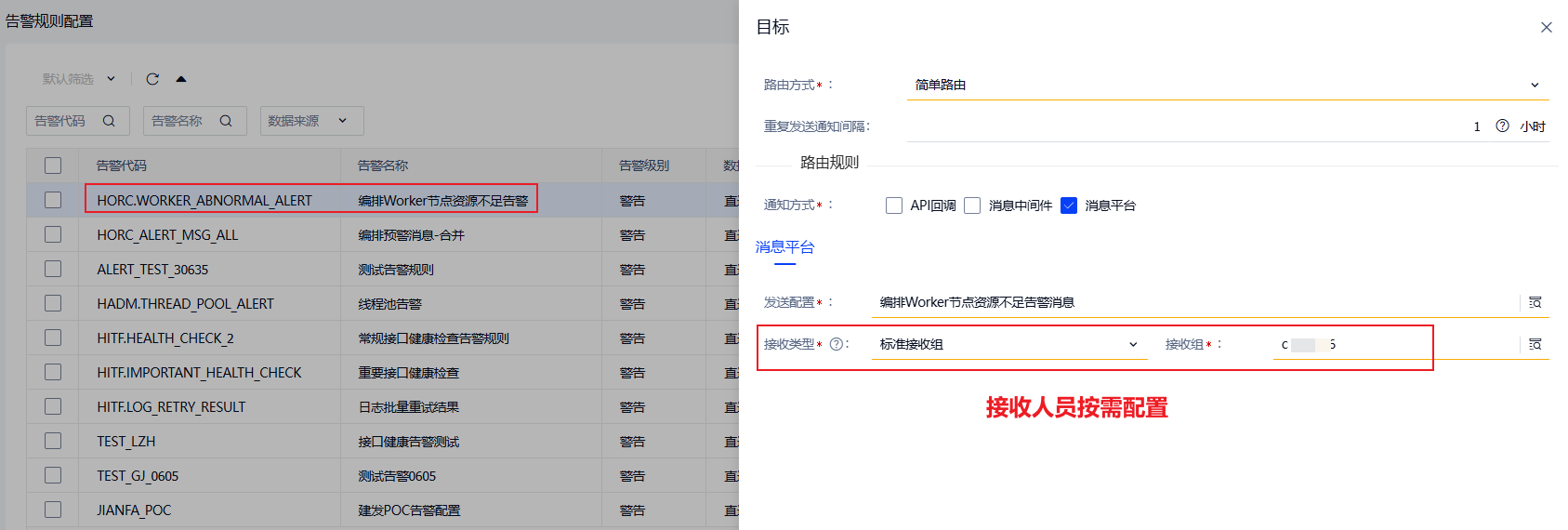
若是资源不足导致的:在1.8.2以上及1.9.1以上版本,当出现workloader资源不足时,可以通过配置告警代码第一时间发送告警消息给相关人员,workloader服务配置项:
hzero.orchestration.worker.abnormal-alert-code,默认告警代码为HORC.WORKER_ABNORMAL_ALERT,只需按需配置接收人员即可。
成功配置后会收到如下的告警消息:
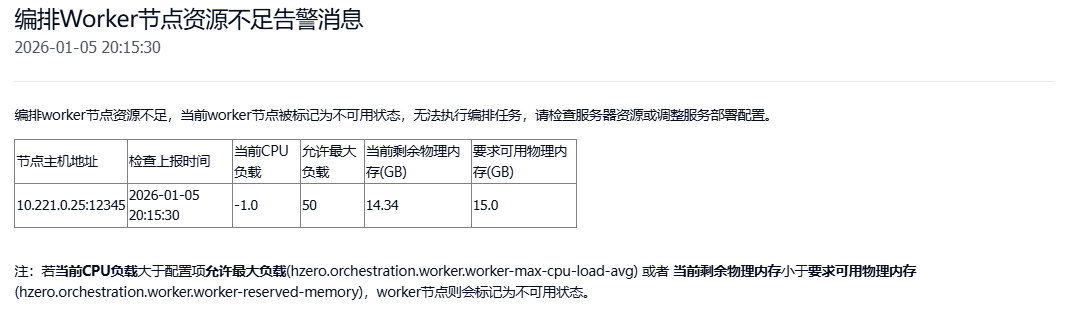
3、若是资源不足导致的:可以扩容该workloader服务的cpu和物理内存,也可以修改workloader服务的配置项允许最大负载 (hzero.orchestration.worker.worker-max-cpu-load-avg)、要求可用物理内存 (hzero.orchestration.worker.worker-reserved-memory)
异步执行问题
一、编排未执行、未生成编排实例
问题描述
从编排界面点击运行、调试按钮或定时任务运行的编排没有被执行,待运行的数据全部积压在 未处理编排实例 界面
问题原因
上述情况执行编排的简易原理:执行时会往未处理编排实例界面(可以理解为中间表)插入一条数据,若被成功执行,则会删除该中间表数据;若由于某些原因没有被执行,则中间表的数据会一直存在,相当于保留了待执行记录。
解决方案
从1.8.2.RELEASE及1.9.1.RELEASE版本开始,未处理编排实例 界面会把编排未执行的原因展示到界面上,以便快速定位排查问题。
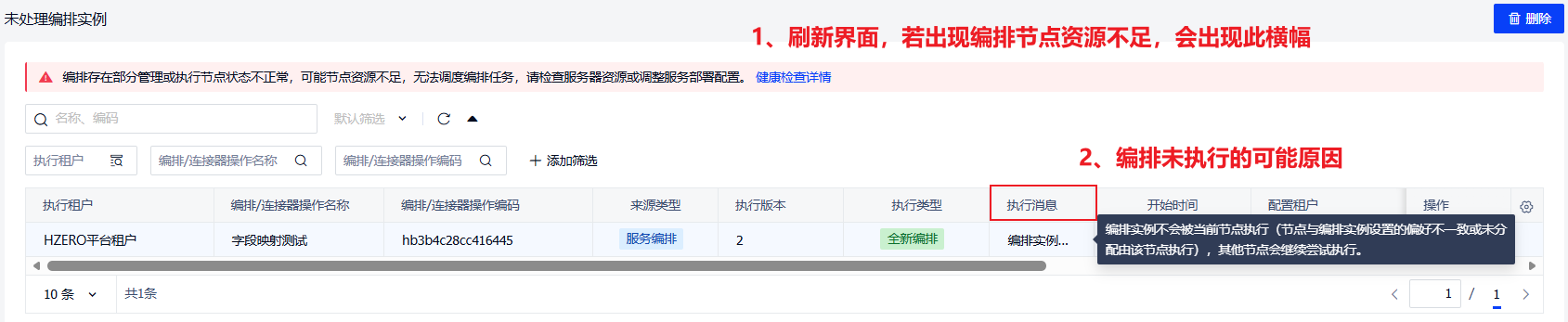
常见问题包括manager资源不足、执行所填偏好不对、编排未启用未发布等,更详细解释参考🔗编排常见问题清单
二、生成编排实例,但未执行任务节点
问题描述
编排被执行生成了编排实例,但是编排定义中的任务节点没有被执行,没有生成相应的任务实例,从jipaas-orchestration服务后台查询日志可能会出现如下类似的错误:
-
send command : Command [type=TASK_EXECUTE_REQUEST, opaque=90, bodyLen=17897] to Host{address='xxxx:12345'} error -
error.horc.no_suitable_workloader
问题原因
-
没有存活的workloader服务(若部署的是jipaas-orchestration-all,则自带workloader服务,可忽略该原因)
-
若没有使用zookeeper/etcd集群模式:
-
需确保jipaas-orchestration服务的配置项
hzero.orchestration.distributed.manager.worker-listen-port与workloader服务的配置项hzero.orchestration.worker.listen-port配置的端口一致 -
若是主机部署,需确保jipaas-orchestration服务的配置项
hzero.orchestration.distributed.manager.worker-address填写的是workloader服务所在的主机IP,且能够网络连通该主机IP -
若是k8s部署,首先需要对workloader服务建k8s service(暴漏端口需包括
hzero.orchestration.worker.listen-port配置对应的端口),然后jipaas-orchestration服务的配置项hzero.orchestration.distributed.manager.worker-address填写该workloader服务创建的k8s service 名称
-
-
若使用zookeeper/etcd集群模式:
- workloader服务虽然存活,但是该服务的cpu或者内存资源不足,也会被认为当前服务不可用,无法执行编排任务
- 编排执行时传递了工作组(workerGroup)或者任务节点中配置了工作组,但是没有该工作组对应的workloader服务存活;配置项: hzero.orchestration.worker.worker-group
解决方案
- 若是没有存活的workloader服务,可以启动该服务
- 按照上面的问题原因第2点检查配置是否正确
- 若是资源不足导致的:可以扩容该workloader服务的cpu和物理内存,也可以修改workloader服务的配置项允许最大负载 (hzero.orchestration.worker.worker-max-cpu-load-avg)、要求可用物理内存 (hzero.orchestration.worker.worker-reserved-memory)
日志记录问题
未记录编排、任务执行日志
问题描述
编排执行完成后,编排实例、任务实例界面点击日志按钮,没有记录执行日志
解决方案
-
编排定义基础配置界面配置 日志策略为记录全部日志;任务节点日志策略优先级:若任务节点没有配置日志策略,任务节点的日志策略使用编排定义的,若配置了则使用节点配置的;
-
检查jipaas-orchestration、jipaas-orchestration-workloader服务根目录
src/main/resources下的logback-spring.xml文件,确保文件包含如下内容:可以自定义修改文件内容,例如配置日志回滚策略;但是需注意 INSTANCE_LOG、INSTANCE_LOG_FILE、TASK_LOG、TASK_LOG_FILE这4个appender必须存在且不能修改完整配置文件见汉得开放平台🔗编排常见问题清单
其他已知问题
一、节点结果取值问题
- Spel表达式取值报错:无法将map类型转为string类型
- 编排节点结果取值报错:StreamConstraintsException: String length (20054016) exceeds the maximum length (20000000)
*解决方案见汉得开放平台🔗编排常见问题清单
二、消息队列问题
包括RabbitMQ、Kafka、RocketMQ、ActiveMQ等常用消息队列问题,例如:
-
RabbitMQ找不到vhost
-
Kafka在发送或消费消息时,报消息序列化或解序列化错误
-
Kafka消息被重复消费
-
依赖组件版本不一致
*解决方案见汉得开放平台🔗编排常见问题清单