World Model for Robot Learning: A Comprehensive Survey
- 文章概括
- ABSTRACT
- [1 Introduction](#1 Introduction)
- [2 Background](#2 Background)
-
- [2.1 世界模型与视频生成模型](#2.1 世界模型与视频生成模型)
-
- [2.1.1 世界模型](#2.1.1 世界模型)
- [2.1.2 视频生成模型](#2.1.2 视频生成模型)
- [2.2 机器人策略](#2.2 机器人策略)
-
- [2.2.1 视觉运动策略](#2.2.1 视觉运动策略)
- [2.2.2 视觉-语言-动作策略](#2.2.2 视觉-语言-动作策略)
- [3 用于策略的世界模型](#3 用于策略的世界模型)
-
- [3.1 为什么世界模型有助于机器人策略学习](#3.1 为什么世界模型有助于机器人策略学习)
- [3.2 结合世界模型的逆动力学策略](#3.2 结合世界模型的逆动力学策略)
- [3.3 使用单一世界模型骨干网络的统一策略](#3.3 使用单一世界模型骨干网络的统一策略)
- [3.4 具有专家世界模型骨干网络的 MoE/MoT 风格策略](#3.4 具有专家世界模型骨干网络的 MoE/MoT 风格策略)
- [3.5 统一视觉-语言-动作模型](#3.5 统一视觉-语言-动作模型)
- [3.6 具有潜在空间世界建模的策略](#3.6 具有潜在空间世界建模的策略)
- [4 World Model as Simulator](#4 World Model as Simulator)
-
- [4.1 用于强化学习的世界模型](#4.1 用于强化学习的世界模型)
- [4.2 用于评估的世界模型](#4.2 用于评估的世界模型)
- [5 用于机器人视频生成的世界模型](#5 用于机器人视频生成的世界模型)
-
- [5.1 问题设定与范围](#5.1 问题设定与范围)
- [5.2 作为策略学习想象机制的视频生成](#5.2 作为策略学习想象机制的视频生成)
- [5.3 迈向动作可控的视频世界模型](#5.3 迈向动作可控的视频世界模型)
- [5.4 具有交互和几何先验的结构感知生成](#5.4 具有交互和几何先验的结构感知生成)
- [5.5 从视频骨干网络到基础世界模型](#5.5 从视频骨干网络到基础世界模型)
- [5.6 技术演进与开放挑战](#5.6 技术演进与开放挑战)
- [6 世界模型在其他应用中的使用](#6 世界模型在其他应用中的使用)
-
- [6.1 用于导航的世界模型](#6.1 用于导航的世界模型)
- [6.2 用于自动驾驶的世界模型](#6.2 用于自动驾驶的世界模型)
文章概括
引用:
bash
markup
主页: https://ntumars.github.io/wm-robot-survey/
GitHub: https://github.com/NTUMARS/Awesome-World-Model-for-Robotics-Policy
原文: https://arxiv.org/pdf/2605.00080v1
系列文章:
请在 《 《 《文章 》 》 》 专栏中查找
宇宙声明!
引用解析部分属于自我理解补充,如有错误可以评论讨论然后改正!
ABSTRACT
世界模型是一种预测性表征,用来描述环境在动作作用下如何演化,它们已经成为机器人学习中的核心组成部分。 它们支持策略学习、规划、仿真、评估和数据生成,并且随着基础模型和大规模视频生成技术的兴起而快速发展。 然而,现有文献在模型架构、功能角色以及具身应用领域等方面仍然较为分散。 为了解决这一问题,我们从机器人学习的视角出发,对世界模型进行了全面综述。 我们考察了世界模型如何与机器人策略相结合,如何作为学习得到的模拟器用于强化学习和评估,以及机器人视频世界模型如何从基于想象的生成方法,发展到可控的、结构化的和基础模型规模的形式。 我们进一步将这些思想与导航和自动驾驶联系起来,并总结了具有代表性的数据集、基准测试和评估协议。 总体而言,本文系统性地综述了机器人学习中世界模型相关的快速增长的研究文献,阐明了关键范式和应用,并指出了具身智能体预测建模面临的主要挑战和未来方向。 为了便于持续获取新出现的研究工作、基准测试和相关资源,我们将维护并定期更新与本综述配套的 GitHub 仓库。
1 Introduction
机器人策略学习正在迅速从面向特定任务的控制流程,转向由基础模型驱动的具身智能。 近年来的视觉-语言-动作模型,即 Vision-Language-Action(VLA)策略(Zitkovich et al., 2023; Kim et al., 2025; Black et al., 2024; Intelligence et al., 2025b; Wu et al., 2024),旨在通过将多模态观测直接映射为机器人动作,从而统一感知、语言理解和控制,并有望实现广泛的任务泛化能力和灵活的指令跟随能力。 然而,尽管这些方法呈现出明显的规模化发展趋势(Xiao et al., 2025; Li et al., 2025b; Zhu et al., 2026),纯反应式的 VLA 策略在复杂物理环境中仍然存在局限,因为它们常常难以处理长时程推理、时间维度上的贡献归因,以及在误差不断累积情况下的鲁棒性问题。 越来越多的研究认为,这些局限不仅来自于动作预测能力不足(Ye et al., 2026b; Dang et al., 2026),也来自于缺乏一种明确的预测性结构,来预判世界会如何在智能体行为的作用下发生演化。 这重新激发了人们对世界模型的兴趣(Craik, 1943; Bryson and Ho, 1975; Ha and Schmidhuber, 2018)。世界模型是一种预测性表征,能够捕捉环境动力学,并使智能体在行动之前对未来状态进行推理。
"世界模型"这一术语(Craik, 1943; Bryson and Ho, 1975; Ha and Schmidhuber, 2018)有着悠久的思想渊源。 从核心上看,它描述的是一个系统或环境如何在干预或动作的作用下,从当前状态向后演化;在其最标准的形式中,它可以被看作一个状态转移模型,即根据当前状态和动作来预测下一个状态,或预测一系列未来状态。 早期相关思想出现在 20 世纪 60 年代的认知科学中(Miller et al., 1960),当时研究者提出内部模型可以支持心理模拟、预测和规划。 类似的思想也出现在控制理论和基于模型的决策方法中(Conant and Ashby, 1970; Bryson and Ho, 1975; Richalet et al., 1978),也出现在经典机器人规划中;在经典机器人规划里,几何结构、约束条件和动作后果的内部模型被用来支持机器人在执行动作之前进行决策(Lozano-Perez, 1983)。 在现代机器学习中,世界模型的重新兴起主要由两条发展路径推动(Ha and Schmidhuber, 2018):第一是基于模型的强化学习(Nguyen and Widrow, 1990; Jiang et al., 2026; Zhu et al., 2026),它利用学习到的动力学模型进行规划和策略改进;第二是大规模生成式建模(Ali et al., 2025; Guo et al., 2025; Jiang et al., 2025b; Jang et al., 2025b),尤其是视频生成,它能够从大规模视觉数据或交互数据中学习丰富的时空规律。 这些发展共同使得直接从像素中学习预测性表征,并将其复用于具身决策,变得越来越可行。
在这篇综述中,我们并不强行给世界模型套用一个单一而狭窄的形式化定义,而是从以机器人学习为中心的视角来理解世界模型。 我们的关注重点是:预测未来世界演化的模型如何支持机器人策略学习、规划、仿真、评估和数据生成。 在这一视角下,世界模型可以通过显式展开预测、以未来状态为条件的动作推理,或者预测与控制联合建模,来支持动作选择。 将这些方法统一起来的,并不是某一种单一的分解形式,而是它们都作为预测性结构,使机器人的决策更加有信息依据,并且更加扎根于物理现实。 我们也在广义的预测控制意义上使用"动作"这一概念:低层运动命令规定智能体如何运动,而高层语言指令则规定应当实现怎样的未来状态。 这一视角也将机器人世界模型与一般的感知预测器区分开来:在具身人工智能中,预测质量的重要性取决于它是否对行动有用。 因此,一个可用于行动的世界模型应当具备三种核心能力:第一是前瞻能力 (Mi et al., 2026; Li et al., 2026b; Gu et al., 2026; Bi et al., 2025),也就是在执行之前预判未来状态或动作后果;第二是由想象驱动的规划能力 (Kim et al., 2026),也就是利用想象出来的展开过程来比较并选择候选行为;第三是数据扩增能力(Jang et al., 2025b; Ali et al., 2025),也就是合成额外的示范数据或交互轨迹,以改进学习效果。 这些能力对于操作、导航和驾驶等具身任务尤其重要,因为这些任务的成功依赖于对接触、动力学以及其他物理规律的推理,而这些内容仅靠以语言为中心的预训练是无法充分捕捉的。 从这个意义上说,世界模型并不仅仅是一种生成能力上的增强,而是一座从语义意图通向物理可实现行为的预测性桥梁。
从历史上看,世界模型与机器人策略的结合主要沿着两个方向发展:一是预测建模与动作生成之间更加紧密的耦合(Du et al., 2023; Li et al., 2025c; Zhu et al., 2025a);二是更广泛地将学习得到的世界模型作为模拟器,用于验证、后训练和强化学习(Xiao et al., 2025; Li et al., 2025b; Chandra et al., 2025)。 随着基础模型规模的视频模型兴起(Wan, 2025; Ali et al., 2025),近期方法开始探索将大型视频生成器适配为机器人策略的一部分(Li et al., 2025c; Zhu et al., 2025a),目标是通过未来预测来提高泛化能力和样本效率(Jang et al., 2025b);而后续系统则进一步走向与 VLA 策略进行统一训练和闭环协同优化(Cen et al., 2025)。 与此同时,世界模型也越来越多地被用作可控模拟器,用于后训练和评估(Zhu et al., 2026; Xiao et al., 2025)。这表明,关键目标不仅是生成看起来合理的未来,而是生成与控制相一致、并能够支持决策的未来。 受这些趋势的启发,本文综述与以往综述(Zhang et al., 2025d)相比,主要在三个方面有所不同:它对主要的世界模型范式提供了更细粒度的视角;它更全面地分析了世界模型在策略学习、规划、仿真、评估和视频生成中的作用;并且它围绕 VLA 策略和机器人学习,对世界模型给出了更加清晰的、以机器人为中心的定义。 通过强调动作条件下的一致性、长时程可靠性和实际可部署性,本文综述旨在阐明:世界模型在什么情况下、以及为什么能够转化为真实机器人行为中可测量的性能提升。
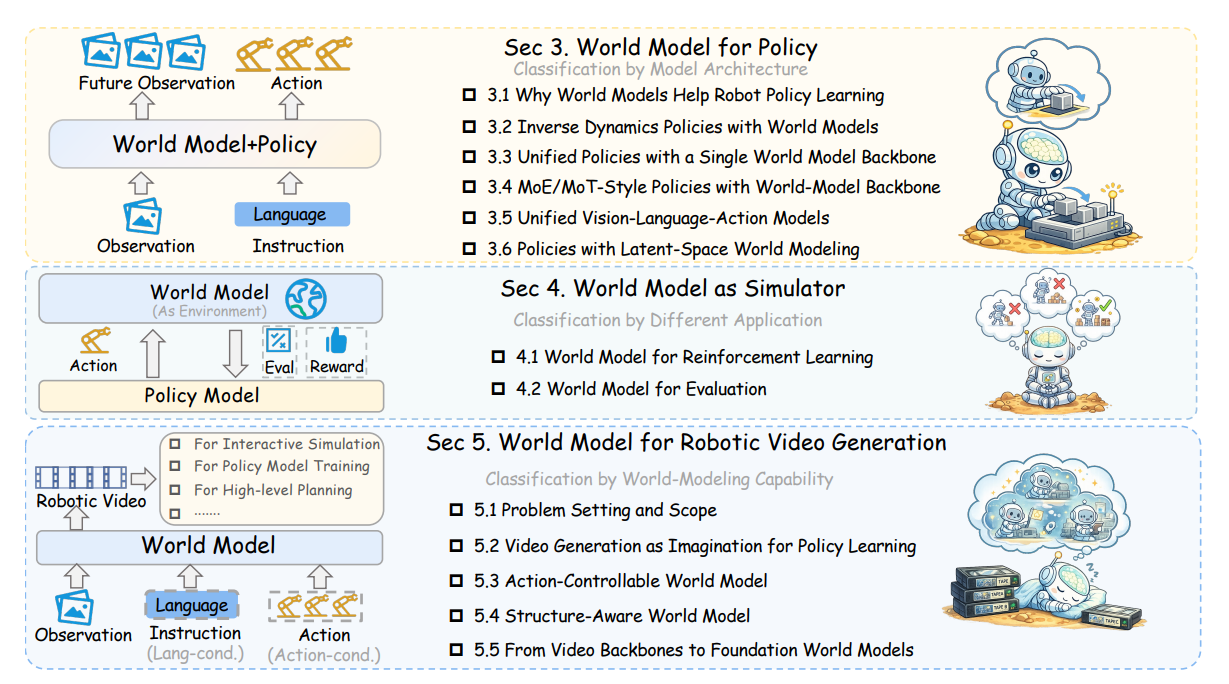 图 1 展示了本文综述的组织结构概览。 第 3 节从架构角度回顾世界模型如何与机器人策略相结合。 第 4 节从应用角度考察作为模拟器的世界模型。 第 5 节聚焦于机器人视频世界模型,并根据世界建模能力对相关文献进行组织梳理。
图 1 展示了本文综述的组织结构概览。 第 3 节从架构角度回顾世界模型如何与机器人策略相结合。 第 4 节从应用角度考察作为模拟器的世界模型。 第 5 节聚焦于机器人视频世界模型,并根据世界建模能力对相关文献进行组织梳理。
我们首先在第 2 节介绍世界模型、视频生成以及 VLA/策略模型的相关背景。 如图 1 所总结的那样,随后我们在第 3 节回顾用于策略的世界模型,在第 4 节回顾作为模拟器的世界模型,并在第 5 节讨论机器人视频世界模型。 我们还会在第 6 节进一步讨论包括导航和自动驾驶在内的更广泛的具身领域,并在第 7 节介绍基准测试、数据集和结果,最后在第 8 节以开放挑战和未来方向作为总结。 尤其是,第 3 节首先引入了一种概率视角,将策略模型、被动世界模型和可控世界模型,以及逆动力学模型,联系为同一个共享预测控制分布下的相关查询形式。
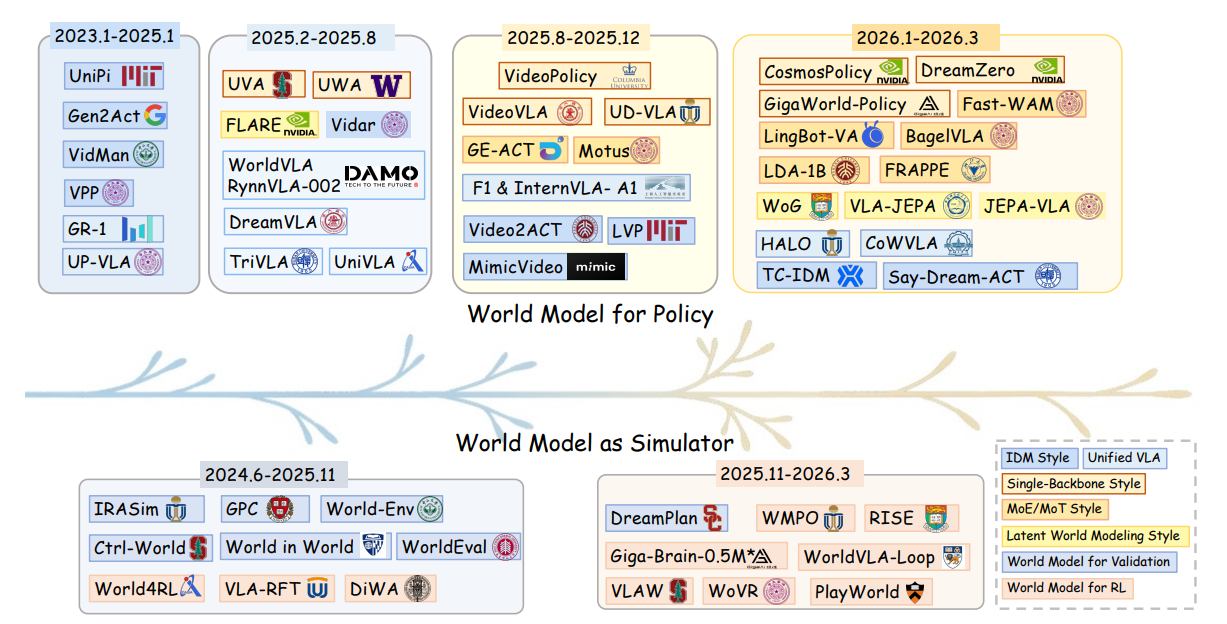 图 2 展示了机器人策略学习中世界模型代表性工作的时间演化过程。 上方分支总结了用于策略的世界模型方法的发展过程,展示出一种趋势:从早期解耦的视频生成加 IDM 流程,逐渐走向通过单一骨干网络、MoE/MoT、统一 VLA 以及潜在世界建模设计实现更紧密的集成。 下方分支总结了作为模拟器的世界模型方法的发展过程,其中世界模型从基于展开预测的验证和候选方案评估,逐渐发展为用于策略强化学习、后训练以及协同演化优化的学习型模拟器。 这些趋势应当被理解为主要的发展方向,而不是严格按照先后顺序发生的替代关系。
图 2 展示了机器人策略学习中世界模型代表性工作的时间演化过程。 上方分支总结了用于策略的世界模型方法的发展过程,展示出一种趋势:从早期解耦的视频生成加 IDM 流程,逐渐走向通过单一骨干网络、MoE/MoT、统一 VLA 以及潜在世界建模设计实现更紧密的集成。 下方分支总结了作为模拟器的世界模型方法的发展过程,其中世界模型从基于展开预测的验证和候选方案评估,逐渐发展为用于策略强化学习、后训练以及协同演化优化的学习型模拟器。 这些趋势应当被理解为主要的发展方向,而不是严格按照先后顺序发生的替代关系。
图 2 突出了近期文献中两个密切相关的发展趋势。 在策略方面,早期的解耦式流程(Hu et al., 2025; Du et al., 2023)仍然是一条重要路线;与此同时,设计空间已经逐步扩展到单一骨干网络方法(Kim et al., 2026)、统一 VLA 方法(Cen et al., 2025)以及潜在世界建模方法(Su et al., 2026),这些方法在预测与动作生成之间实现了更紧密的集成。 在模拟器方面,世界模型的作用已经从基于想象未来来验证或排序候选动作,扩展为作为学习得到的环境,用于强化学习、后训练,甚至与策略共同演化(Li et al., 2025b; Guo et al., 2026a; Liu et al., 2026b)。 综合来看,这两个趋势表明,世界模型不再只是作为辅助预测器来使用,而是越来越多地被整合进机器人系统的核心学习与决策闭环之中。 作为本文综述的补充,我们还将持续维护并更新配套的 GitHub 仓库,使其能够与该领域快速发展的进展保持同步。
总而言之,我们的主要贡献如下:
-
我们提出了一篇以策略为中心的机器人学习世界模型综述,尤其关注预测模型如何与 VLA 策略相结合,以支持动作生成、规划、仿真、评估和数据生成。
-
我们通过区分世界模型的主要架构范式和功能角色,为该领域提供了更加细粒度的分类体系,揭示了在更宽泛讨论中常常被忽视的重要差异。
-
我们通过阐明机器人世界模型与机器人学习、VLA 策略、视频生成以及模拟器式使用方式之间的关系,并总结代表性基准测试、数据集和开放挑战,对机器人世界模型进行了更加全面且定义更加清晰的论述。
2 Background
2.1 世界模型与视频生成模型
为了给本文后续内容建立一套准确的术语体系,我们首先澄清本文中反复使用的两个密切相关的概念。 在近期的具身人工智能文献中,"世界模型"这一术语被使用得相当宽泛,它可以指潜在动力学模型、未来状态预测器、视频预测器,甚至可以指大型策略模型内部隐含的预测性结构。 由于我们的关注重点是以策略为中心,而不是纯粹的生成式建模,因此我们会以一种更加精确且功能性的意义来使用这些术语。
2.1.1 世界模型
在本文综述中,我们是在以机器人和具身智能为中心的意义上使用"世界模型"这一术语,而不是在最宽泛的生成式意义上使用它。 具体来说,世界模型指的是一种关于智能体---环境动力学的预测模型,它捕捉机器人系统或具身系统在动作作用下如何演化。 在其最标准的形式中,世界模型建模的是一个状态转移过程:给定当前状态或观测以及一个动作,它预测下一个状态,或者预测一系列未来状态,如图 1 底部所示。
这里,我们是在一种广义的预测控制意义上使用"动作"这一概念。 也就是说,低层运动命令和高层语言指令都被视为动作:前者是智能体执行的具体物理动作,而后者是高层语义动作,用来规定应当实现怎样的未来状态。 为了与本文其余部分的符号保持一致,我们将这两种形式的动作区分开来,用 a a a 表示低层物理动作,用 l l l 表示高层语言动作或任务动作。 在这一约定下,一个通用形式可以写为:
p ( x t + 1 : t + H ∣ x t , a t : t + H − 1 , l ) ( 1 ) p(x_{t+1:t+H}\mid x_t,a_{t:t+H-1},l) \quad (1) p(xt+1:t+H∣xt,at:t+H−1,l)(1)
其中, x t x_t xt 表示时间 t t t 时被建模的状态, a t : t + H − 1 a_{t:t+H-1} at:t+H−1 表示在时间范围 H H H 内的动作序列, l l l 表示高层动作规定,例如语言指令或目标描述。 这一形式化表达有意不限定具体采用哪一种状态空间。 在本文的设定中,真正重要的是:预测出来的未来是否能够为下游具身决策提供可行动的依据。
在这一形式化表达下,我们是在功能意义上使用"世界模型"这一概念,用它来指那些输出能够支持策略相关计算的预测模型,包括控制、规划、仿真、评估和数据生成。 它的定义性特征并不只是预测一个看起来合理的未来,而是要预测未来会如何在与机器人相关的动作作用下发生变化,并且这种预测要能够支持具身决策。 因此,这一定义比计算机视觉中一般意义上的未来预测更窄:一个模型并不会仅仅因为能够生成看起来合理的未来图像或视频,就符合本文意义上的世界模型定义。 相反,它必须以一种与机器人交互相关、并且对下游策略相关计算有用的形式,捕捉环境的演化过程。 在具身控制中,最重要的子类是动作条件世界模型,因为那些视觉上看似合理、但与动作不一致的未来,对于闭环决策的价值是有限的。 根据具体方法的不同,被建模的变量 x t x_t xt 可以是视觉观测、潜在状态、结构化物理状态,甚至可以是用于规划的抽象符号状态(Liang et al., 2026, 2025c; Athalye et al., 2026; Liang et al., 2026),这既涵盖了经典的潜在动力学模型,也涵盖了较新的用于机器人学习的生成式预测模型。 在符号状态的情况下,世界模型预测的是谓词、物体关系、可供性或因果过程之间的转移,而不是像素层面的变化(Liang et al., 2025c; Athalye et al., 2026; Liang et al., 2026)。
然而,在当前的具身系统中,状态最常见且最具可扩展性的实现形式,恰恰是观测流,尤其是视觉观测序列。 因此,机器人领域中许多实际使用的世界模型,都是直接在视觉观测空间中实现的。 相应地,尽管世界模型是一个更一般的概念,但本文综述主要关注的具体模型主要是视觉世界模型,也就是定义在未来观测之上的视频生成模型。
2.1.2 视频生成模型
视频生成模型直接在图像或视频空间中预测未来。 在具身设定中,它可以写为:
p ( v t + 1 : t + H ∣ o t , a t : t + H − 1 , l ) ( 2 ) p(v_{t+1:t+H}\mid o_t,a_{t:t+H-1},l) \quad (2) p(vt+1:t+H∣ot,at:t+H−1,l)(2)
其中, o t o_t ot 表示当前观测,它可以代表来自多个视角的观测; v t + 1 : t + H v_{t+1:t+H} vt+1:t+H 表示未来帧或未来视频片段。 与潜在状态世界模型相比,这种形式保留了更丰富的空间、时间和交互细节,因为未来是以显式视觉证据的形式表示的,而不是以抽象状态变量的形式表示的。 从前文的视角来看,这样的模型可以被理解为一种在视觉观测空间中实现的世界模型。 由于视觉观测是具身智能体最常获得的状态形式,因此这种视觉形式的实现也是本文综述中主要考虑的形式。 这种关注不应被理解为作者假定像素级预测就是控制任务的最优抽象;相反,它反映的是基于视频的世界模型在近期机器人学习文献中的突出地位。
然而,这种视觉上的显式表达也使建模问题变得更加困难。 除了感知上的真实感之外,具身视频生成模型还必须保持时间连贯性、动作一致性、物理合理性以及长时程稳定性。 近年来,大规模视频生成骨干网络的发展,使得这种建模方式在机器人领域中变得越来越可行(Yang et al., 2024b)。 因此,视频生成模型不再仅仅用于被动的视觉延续。 它们越来越多地被适配为动作条件预测模块,用于支持基于想象的监督、可控展开、模拟器构建,以及面向机器人学习的合成数据生成(Liang et al., 2024; Zhou et al., 2024; Pai et al., 2025; Zhu et al., 2025b; Guo et al., 2026b; Huang et al., 2026; Liao et al., 2026)。
其中,动作条件视频生成模型在具身人工智能中占据着尤为重要的位置。 这里,"动作"这一概念应当被广义地理解:条件信息既可以来自低层连续控制,也可以来自更高层的任务描述或语言描述,这些描述规定了应当实现怎样的未来。 在这两种形式下,这些模型既继承了视频预测的表达能力,又能够建模视觉未来如何随着候选动作的结果而发生变化。 这使它们特别适合本文综述所采用的以策略为中心的设定:它们不仅可以作为合理未来的生成器,还可以作为控制、规划和策略改进的预测性基础。 因此,除非另有说明,本文后续讨论的世界模型主要是基于视频的世界模型,并特别强调动作条件情形。
2.2 机器人策略
当前最先进的机器人控制方法已经从解析式控制器转向端到端学习模型(Ai et al., 2025)。 从形式上看,机器人策略是一种决策模型,它将物理控制表述为一个动作预测任务,即把当前环境观测映射为未来动作轨迹。 在这里,我们特别关注模仿学习范式,在这种范式中,策略通过专家示范进行训练,并直接从专家示范中合成行为。
给定当前观测 o t o_t ot,其中包括视觉状态和本体感知状态,以及一个可选的语言指令 l l l,策略会预测未来动作序列 a t + 1 : t + k a_{t+1:t+k} at+1:t+k。 这一过程通常被建模为如下条件概率分布:
p ( a t + 1 : t + k ∣ o t , l ) ( 3 ) p(a_{t+1:t+k}\mid o_t,l) \quad (3) p(at+1:t+k∣ot,l)(3)
在实践中,将预测动作组织为长度为 k k k 的时间动作块,已经成为一种主流策略,用来保证时间连贯性,并减轻误差累积问题(Chi et al., 2023; Zhao et al., 2023; Wu et al., 2026b)。 从架构角度来看,当代机器人策略主要分化为两种范式:专用视觉运动策略和通用型视觉-语言-动作模型,即 Vision-Language-Action(VLA)模型。 前者以 Diffusion Policy 等框架为代表(Chi et al., 2023, 2025a; Dasari et al., 2025),重点是训练面向特定任务的、通常较轻量的端到端网络,并利用生成式建模以高精度和低延迟捕捉复杂的动作分布。 相反,由 RT-2(Zitkovich et al., 2023)、OpenVLA(Kim et al., 2025)和 π 0 \pi_0 π0(Black et al., 2024)开创的 VLA 模型,是通过在大规模机器人轨迹数据上微调大规模视觉-语言模型,即 Vision-Language Models(VLMs)而发展起来的(Open X-Embodiment Collaboration, 2024)。因此,它们继承了基础模型中丰富的语义知识和开放词汇推理能力,从而实现更强的跨任务泛化能力(Octo Model Team et al., 2024)和跨具身形态泛化能力(Doshi et al., 2024)。
2.2.1 视觉运动策略
视觉运动策略建立了从原始状态到动作空间的直接映射,因此通常形成一种较为轻量、但泛化能力受限的架构。 最直接的方法是将这种映射表述为一个回归任务(Bain and Sammut, 1995; Osa et al., 2018; Zhao et al., 2023)。 在这一范式中,神经网络对当前观测进行编码,并以确定性的方式直接回归连续的物理动作数值。
为了解决人类示范中固有的多模态问题,近期的视觉运动策略越来越多地采用生成模型。 这些方法使用生成式技术来捕捉完整的动作分布,例如基于扩散模型(Ho et al., 2020; Song et al., 2021)的 Diffusion Policy(Chi et al., 2023, 2025a),以及 flow matching 方法(Zhang and Gienger, 2024; Lipman et al., 2023; Liu, 2022)。 通过将动作预测表述为一个条件生成过程,这些模型可以从初始高斯噪声出发,合成高保真、多模态的动作序列。 此外,为了提高采样效率并加速生成过程,近期研究探索了用信息量更丰富的基础分布来替代标准高斯噪声,例如视觉表征(Gao et al., 2025a)和动作历史(Jia et al., 2026b)。 Pan et al.(2026)发现,生成式策略通过注入随机性和监督式迭代计算,提高了对动作流形的贴合程度,因此性能优于回归方法。
2.2.2 视觉-语言-动作策略
为了利用视觉-语言模型,即 VLM,强大的推理能力,VLA 模型通常会在预训练骨干网络上配备一个专门的动作头,并在机器人轨迹数据上对整个框架进行联合微调。 在 VLA 模型中,动作预测主要结合了离散表示和连续表示这两种范式。
一方面,离散动作 token 化会将连续动作量化为 token,这些 token 位于与语言模型相同的词表空间中,从而直接利用 VLM 的下一个 token 预测能力(Liu et al., 2025a)。RT-2(Zitkovich et al., 2023)和 OpenVLA(Kim et al., 2025)就是这一方向的成功代表。 然而,标准的基于分箱的离散化方法在高频控制中可能表现困难。为此,FAST(Pertsch et al., 2025)提出了频率空间动作序列 token 化方法,即 Frequency-space Action Sequence Tokenization(FAST),该方法使用离散余弦变换,即 discrete cosine transform(DCT),将动作块压缩为密集的 token 序列。 这使得自回归 VLA 能够以生成模型级别的精度处理高度灵巧的任务,同时显著减少训练时间。 它的模仿学习目标与标准负对数似然损失相同。
另一方面,为了克服量化误差,并在高频控制中保持精度,连续动作表示已经成为一种有前景的替代方案。 这种方法通常将动作头视为一个条件生成器,用来学习一个概率生成模型,例如扩散模型或 flow matching 方法; π \pi π 系列模型就是这一方向的成功代表(Black et al., 2024; Intelligence et al., 2025a,b)。 这些生成式形式并不是预测确定性的动作值,而是建模人类示范中的完整多模态分布
3 用于策略的世界模型
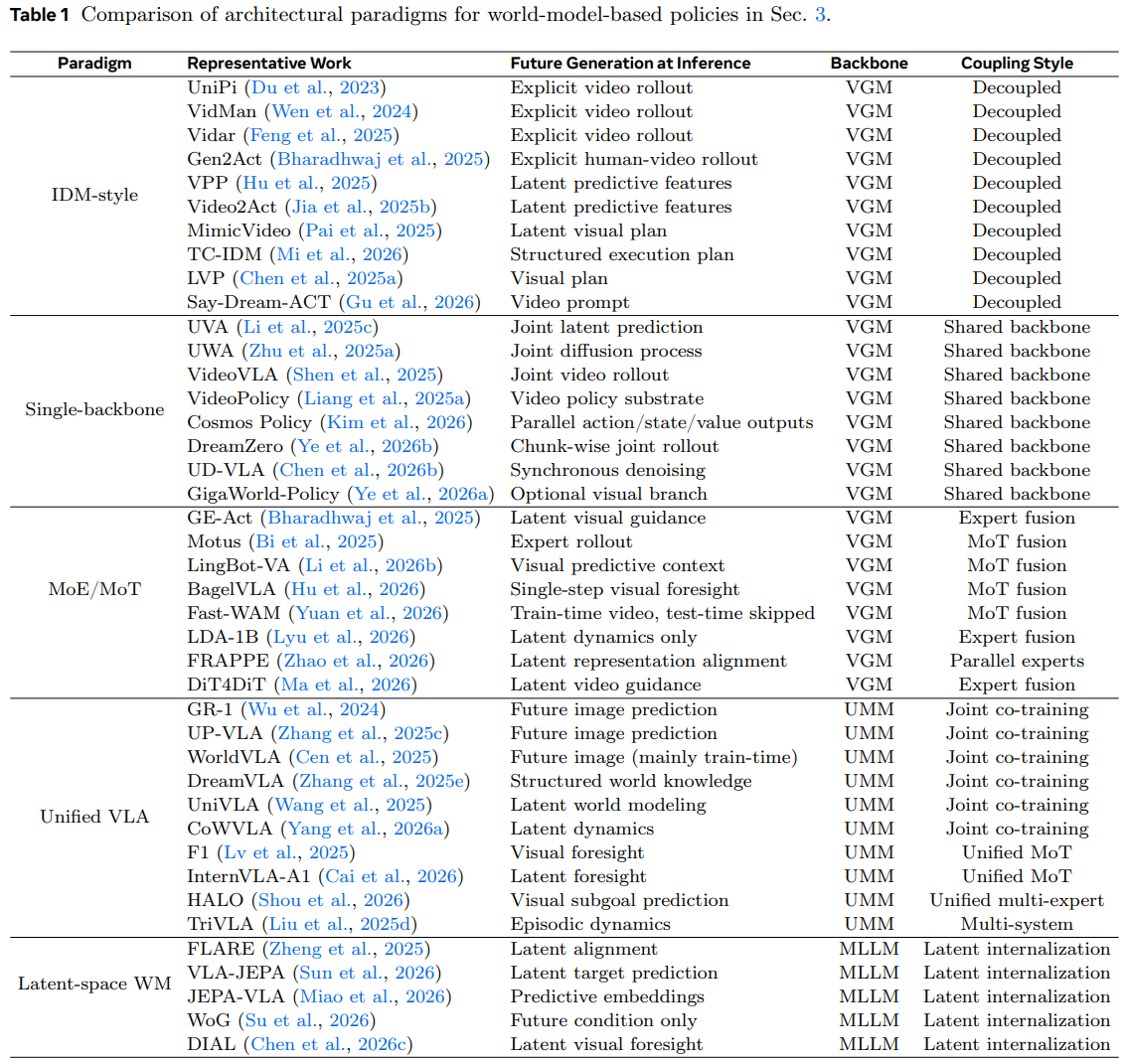
图 2 的上方分支将现有的策略耦合范式放在一个更广阔的时间发展背景中。 该领域已经逐渐从解耦式的"先预测、再行动"流程,发展到更加统一、更加内化的预测控制形式。 重要的是,这一发展过程不应被理解为:经过视频预训练的骨干网络在控制任务中天然优于 VLM、潜在表示、结构化表示或符号化替代方案。 哪一种预测性基础最有效,仍然是一个开放的经验性问题;本文这里的重点,是组织和梳理那些快速增长的方法族,这些方法将视觉或基于视频的世界模型先验与机器人策略相结合,同时也会在相关地方强调潜在表示和结构化表示的变体。
3.1 为什么世界模型有助于机器人策略学习
近年来,机器人策略越来越多地引入世界模型,而这些世界模型通常以视频生成模型的形式实现,因为大规模视频预训练可能为时间动态和物理规律提供有用的先验知识。 它们的好处并不仅限于预测未来,还在于能够提供结构化的预测表征,从而降低动作生成过程中的歧义性。 通过以预期结果为条件,而不是仅仅依赖当前观测,策略能够获得更长时程的前瞻能力,以及更有信息量的控制依据。
这一趋势可以从概率视角来解释。 假设目标是建模未来观测和未来动作的联合条件分布。 令 o t o_t ot 表示当前观测, a t a_t at 表示一个动作, l l l 表示指令,例如语言指令或任务规定。 该分布可以表示为:
p ( o t + 1 : t + k , a t + 1 : t + k ∣ o t , l ) . ( 4 ) p(o_{t+1:t+k},a_{t+1:t+k}\mid o_t,l). \quad (4) p(ot+1:t+k,at+1:t+k∣ot,l).(4)
那么,若干看似不同的范式,都可以被看作同一个底层预测控制模型的不同边缘分布或条件分布:
策略模型:
p ( a t + 1 : t + k ∣ o t , l ) = ∫ p ( o t + 1 : t + k , a t + 1 : t + k ∣ o t , l ) d o . ( 5 ) p(a_{t+1:t+k}\mid o_t,l)=\int p(o_{t+1:t+k},a_{t+1:t+k}\mid o_t,l)d_o. \quad (5) p(at+1:t+k∣ot,l)=∫p(ot+1:t+k,at+1:t+k∣ot,l)do.(5)
被动世界模型:
p ( o t + 1 : t + k ∣ o t , l ) = ∫ p ( o t + 1 : t + k , a t + 1 : t + k ∣ o t , l ) , d a . ( 6 ) p(o_{t+1:t+k}\mid o_t,l)=\int p(o_{t+1:t+k},a_{t+1:t+k}\mid o_t,l),d_a. \quad (6) p(ot+1:t+k∣ot,l)=∫p(ot+1:t+k,at+1:t+k∣ot,l),da.(6)
可控世界模型:
p ( o t + 1 : t + k ∣ o t , a t + 1 : t + k ) . ( 7 ) p(o_{t+1:t+k}\mid o_t,a_{t+1:t+k}). \quad (7) p(ot+1:t+k∣ot,at+1:t+k).(7)
逆动力学模型:
p ( a t + 1 : t + k ∣ o t : t + k ) . ( 8 ) p(a_{t+1:t+k}\mid o_{t:t+k}). \quad (8) p(at+1:t+k∣ot:t+k).(8)
从这个意义上说,策略模型、被动世界模型,也就是视频生成模型、可控世界模型以及逆动力学模型,并不是完全彼此分离的抽象概念;相反,它们对应的是对同一个理想化联合分布进行查询或分解的不同方式。 这也解释了为什么世界模型和策略可以自然地耦合在一起:策略可以将世界模型生成的未来观测作为一种中间潜在变量,而类似逆动力学的解码器则可以从这些预测出的未来中恢复出可执行动作。
因此,将世界模型整合进策略学习中,可以更一般地理解为:在动作生成过程中引入预测性结构。 模型不再学习一个从当前观测到动作的直接、整体式映射,而是将未来观测作为辅助预测变量进行推理,这些变量能够为动作选择提供信息,或对动作选择形成约束。 在一些形式中,模型首先预测一个合理的未来,然后在该未来的条件下解码动作。 在另一些形式中,模型会先生成候选动作,然后通过预测出的未来结果来评估这些动作,或对这些动作进行正则化。 更加统一的方法则会在一个共享的生成过程中联合建模观测和动作。
在实践中,引入这种预测性结构可以为控制提供有用的归纳偏置,尤其是在机器人动作数据有限、但可以利用大规模预测式预训练的情况下(Jang et al., 2025b)。 受这一视角启发,我们从架构角度组织本节内容,根据预测生成如何与动作产生过程交互,对基于世界模型的策略方法进行分类,范围从解耦式流程到紧密集成的端到端形式。 表 1 从比较性的架构视角总结了这些范式,重点展示它们的代表性方法、未来生成是否在推理阶段仍然保持激活、底层骨干网络类型,以及世界建模与动作生成之间的耦合方式。 这种架构上的发展也呼应了基础模型中的更广泛趋势,即设计空间已经从模块化流程扩展到共享骨干网络、专家耦合架构,以及能力内化的潜在形式。
3.2 结合世界模型的逆动力学策略
一类具有代表性的工作通过解耦式设计将世界模型引入机器人控制,其中未来预测和动作生成由两个不同的模块实现。 其核心思想是:首先使用一个世界模型,最常见的是图像或视频生成模型,来预测一个以任务为条件的未来观测序列,或者预测其潜在表示;然后训练一个单独的策略模块,根据当前观测和预测出的未来共同推断可执行动作。 与那些在单一骨干网络中联合建模感知、预测和控制的统一端到端策略不同,这一范式保留了明确的功能划分:世界模型提供关于"接下来应该发生什么"的结构化假设,而策略则将这些预期未来转换为低层动作。 如图 3(a) 所示,这一类方法采用的是一种解耦式的"先预测、再行动"流程:世界模型首先生成未来观测或其预测性表示,然后一个单独的逆动力学式策略将这些预期未来映射为可执行动作。
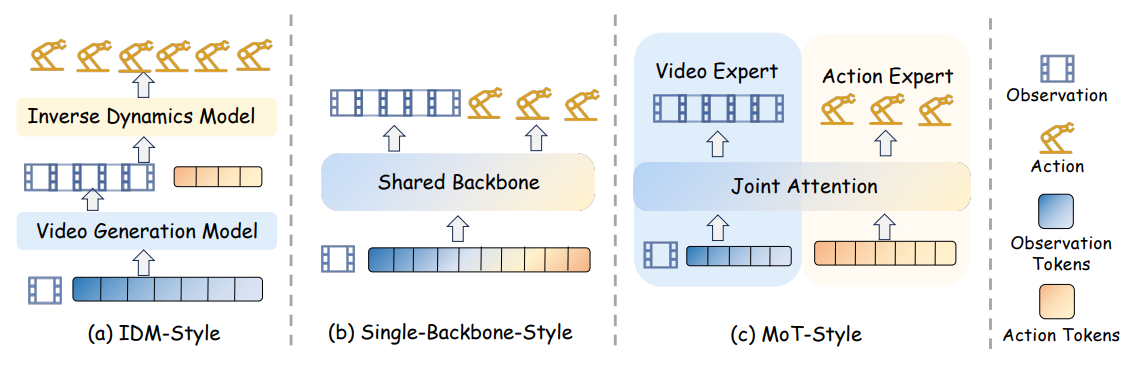 图 3 展示了将世界模型用作策略的代表性架构范式。 (a) IDM 风格 ,即逆动力学模型风格。 视频生成模型首先预测未来观测,然后逆动力学模型从预测出的视觉轨迹中恢复动作,从而形成一种解耦式的"先预测、再行动"流程。 (b) 单一骨干网络风格 。 观测 token 和动作 token 在一个统一的共享骨干网络中被处理,因此未来预测和动作生成会在一个共同的潜在空间中被联合建模。 © MoT 风格。 视频专家和动作专家仍然保持一定程度的专门化,同时通过共享的联合注意力机制实现跨模态交互,从而使世界建模与策略生成之间形成更深层次的耦合。
图 3 展示了将世界模型用作策略的代表性架构范式。 (a) IDM 风格 ,即逆动力学模型风格。 视频生成模型首先预测未来观测,然后逆动力学模型从预测出的视觉轨迹中恢复动作,从而形成一种解耦式的"先预测、再行动"流程。 (b) 单一骨干网络风格 。 观测 token 和动作 token 在一个统一的共享骨干网络中被处理,因此未来预测和动作生成会在一个共同的潜在空间中被联合建模。 © MoT 风格。 视频专家和动作专家仍然保持一定程度的专门化,同时通过共享的联合注意力机制实现跨模态交互,从而使世界建模与策略生成之间形成更深层次的耦合。
这一类方法首先构建一个预测的未来轨迹:
o ^ t + 1 : t + H = W ( o t , l ) , ( 9 ) \hat{o}_{t+1:t+H}=\mathcal{W}(o_t,l), \quad (9) o^t+1:t+H=W(ot,l),(9)
或者,更一般地,构建一个未来潜在表示:
z ^ t + 1 : t + H = W ( E img ( o t ) , E text ( l ) ) , ( 10 ) \hat{z}{t+1:t+H}=\mathcal{W}(E{\text{img}}(o_t),E_{\text{text}}(l)), \quad (10) z^t+1:t+H=W(Eimg(ot),Etext(l)),(10)
其中, W \mathcal{W} W 表示世界模型, H H H 表示预测时域。 随后,策略同时以当前观测和生成的未来作为条件:
π ( a t + 1 : t + H ′ ∣ o t , l ) = P ( a t ∣ E img ( o t ) , E text ( l ) , Φ ( o ^ t + 1 : t + H ) ) , ( 11 ) \pi(a_{t+1:t+H'}\mid o_t,l)=P(a_t\mid E_{\text{img}}(o_t),E_{\text{text}}(l),\Phi(\hat{o}_{t+1:t+H})), \quad (11) π(at+1:t+H′∣ot,l)=P(at∣Eimg(ot),Etext(l),Φ(o^t+1:t+H)),(11)
或者等价地,以潜在形式表示为:
π ( a t + 1 : t + H ′ ∣ o t , l ) = P ( a t ∣ E img ( o t ) , E text ( l ) , z ^ t + 1 : t + H ) , ( 12 ) \pi(a_{t+1:t+H'}\mid o_t,l)=P(a_t\mid E_{\text{img}}(o_t),E_{\text{text}}(l),\hat{z}_{t+1:t+H}), \quad (12) π(at+1:t+H′∣ot,l)=P(at∣Eimg(ot),Etext(l),z^t+1:t+H),(12)
其中, Φ ( ⋅ ) \Phi(\cdot) Φ(⋅) 表示作用于预测未来观测的特征提取器, H ′ H' H′ 表示动作块的大小。从控制角度看,这一形式是逆动力学式的:策略不是仅仅根据当前状态来推断动作,而是利用一个预期的状态转移或未来演化信号,从而降低动作生成中的歧义性。
从历史上看,这一路线中的早期工作建立了"先预测、再行动"的基本解耦范式。UniPi(Du et al., 2023)是一个具有代表性的早期例子:它使用一个任务条件世界模型生成未来视频轨迹,然后训练一个单独的逆动力学模型,通过比较相邻帧来推导动作表示。后续方法主要通过逐步重新设计暴露给策略的未来表示形式,来推进这一范式的发展。 早期的视觉扩展方法,例如 VidMan(Wen et al., 2024)和 Vidar(Feng et al., 2025),保留了经典的两阶段流程,同时引入了掩码逆动力学,以强调与动作相关的区域。 Gen2Act(Bharadhwaj et al., 2025)采用了类似的解耦式设计,但它不是以机器人中心的未来展开作为执行条件,而是以生成的人类视频作为执行条件。 此外,VPP(Hu et al., 2025)和 Video2Act(Jia et al., 2025b)等工作代表了一种密切相关的变体,它们不再依赖显式的像素空间展开,而是将视频世界模型视为紧凑预测表示的来源。 这些方法并不是从完整渲染出的未来帧中解码动作,而是从预训练视频扩散模型的潜在空间中提取与控制相关的特征,并将其注入一个单独的动作头,从而在预测和控制之间形成一个更加紧凑且稳定的接口。 V2A(Luo and Du, 2025)探索了一个相关方向,它通过目标条件探索进一步将生成的视频状态落实到动作上:它并不是从预测未来中学习一个直接的逆动力学解码器,而是将合成的视频状态视为视觉目标,并通过类似 hindsight 的自我探索来学习一个目标条件策略。
朝着更紧凑表示的方向发展,MimicVideo(Pai et al., 2025)用部分去噪的潜在视觉计划替代显式视频预测,从而得到一个更加紧凑且与控制更对齐的接口。 TC-IDM(Mi et al., 2026)和 LVP(Chen et al., 2025a)进一步推进了这种抽象,它们将生成的未来转换为面向执行的中间表示,例如以工具为中心的几何轨迹,或可重定向的视觉计划。 从提示方式的角度看,Say-Dream-ACT(Gu et al., 2026)并不是将生成的视频计划作为显式的逆动力学目标,而是将其作为单独动作策略的上下文视觉引导。 综合来看,这些方法揭示了这一类方法中的一个共同趋势:预测未来逐渐从原始像素空间展开,转向越来越结构化、紧凑且便于执行的表示形式,同时世界模型和策略在架构上仍然保持解耦。
一个相关且互补的方向,是在这种解耦式流程中引入更加结构化的几何中间表示。这些方法并不是仅仅将生成视频或示范视频作为原始视觉未来来使用,而是进一步从视频中提取具有 3D 感知能力的运动结构,并将其作为一种与动作更加相关的预测先验。 从这个意义上说,其关键接口仍然是以视觉为基础的,但未来被表示为一种更加结构化的形式,例如稠密对应关系、3D 轨迹、运动场,或者可执行的 3D 流。 代表性例子包括 AVDC(Ko et al., 2024),它通过稠密对应关系从合成视频中恢复动作;VidBot(Chen et al., 2025b),它从人类视频中提取 3D 手部轨迹和交互线索;Object-centric 3D Motion Field(Yin et al., 2025),它通过以物体为中心的 3D 运动结构来表示动作,这一点类似于 Hind4sight-Net(Nematollahi et al., 2020);以及 NovaFlow(Li et al., 2026a),它将生成视频蒸馏为可执行的 3D 物体流,用于下游执行。 这些工作可以被看作解耦范式的一种结构化扩展:世界模型仍然以视觉为基础,但 3D 表示作为一种中间结构化先验,使下游动作恢复更加直接且鲁棒。
这一类方法的一个定义性特征是其架构解耦:预测模型通常先经过预训练,然后被冻结、轻量适配,或者连接到一个单独的策略头,而不是与动作生成进行联合优化。 这种分离带来了模块化、可复用的视频先验以及可解释的未来预测,但它也会使性能受到生成未来的保真度和可控性的限制;当视觉上看似合理的预测与动作不一致时,还可能导致误差累积。 即便如此,这一范式仍然是世界模型直接服务于机器人策略学习的最早且最具影响力的路径之一,并且它自然地推动了后续视频---动作架构中更加紧密耦合方式的出现。
3.3 使用单一世界模型骨干网络的统一策略
图 3 展示了将世界模型用作策略的代表性架构范式。 (a) IDM 风格 ,即逆动力学模型风格。 视频生成模型首先预测未来观测,然后逆动力学模型从预测出的视觉轨迹中恢复动作,从而形成一种解耦式的"先预测、再行动"流程。 (b) 单一骨干网络风格 。 观测 token 和动作 token 在一个统一的共享骨干网络中被处理,因此未来预测和动作生成会在一个共同的潜在空间中被联合建模。 (c) MoT 风格。 视频专家和动作专家仍然保持一定程度的专门化,同时通过共享的联合注意力机制实现跨模态交互,从而使世界建模与策略生成之间形成更深层次的耦合。
不同于前文所述的解耦式逆动力学流程,另一条耦合更紧密的研究路线使用单一生成式骨干网络来联合建模未来视觉演化和未来动作。 图 3(b) 直观地总结了这一转变:它不再是将世界模型的预测结果传递给下游策略模块,而是将观测 token 和动作 token 放在同一个共享骨干网络中处理,因此未来建模和动作生成被耦合在同一个生成过程中。 这一设计背后更根本的动机,并不仅仅是视频模型能够"想象"未来观测,而是预训练的视频生成骨干网络本身就是针对时间预测建模进行优化的。与许多 VLM 骨干网络不同(Kim et al., 2025; Black et al., 2024),这些 VLM 主要通过图像---文本或视觉---语言对齐目标进行预训练,因此更强调语义对应关系;而视频生成模型则被训练来建模按时间顺序排列的观测,因此可能编码关于运动连续性、时间因果性以及近似物理动力学的有用先验。因此,当动作生成被嵌入到同一个用于建模未来世界演化的去噪过程或生成过程中时,策略可能会受益于这样一个骨干网络:它本身已经带有一种倾向,即能够跨时间传播约束。然而,经过视频预训练的骨干网络是否在机器人控制中始终优于相同规模的 VLM 骨干网络,仍然是一个开放的经验性问题;当前结果应被看作是支持一种有前景归纳偏置的提示性证据,而不是一个确定性的架构结论。
从高层次来看,这一类方法用一个统一的多模态生成目标,取代了"先预测、再行动"的两阶段分解方式。令 x = z v ; z a \mathrm{x}=z\^v;z\^a x=zv;za 表示未来视觉表示和动作表示的拼接。 一个共享骨干网络 f θ f_\theta fθ 在条件 ( o t , l ) (o_t,l) (ot,l) 下,基于被扰动的输入 x ~ τ \tilde{\mathrm{x}}_\tau x~τ 进行训练:
y ^ = f θ ( x ~ τ , o t , l , τ ) , x = z v ; z a , ( 13 ) \hat{y}=f_\theta(\tilde{\mathrm{x}}_\tau,o_t,l,\tau),\quad \mathrm{x}=z\^v;z\^a, \quad (13) y^=fθ(x~τ,ot,l,τ),x=zv;za,(13)
其中, τ \tau τ 表示去噪步数,并采用一个通用的统一目标:
L unified = E ℓ ( y \^ , y ) , ( 14 ) \mathcal{L}_{\text{unified}}=\mathbb{E}\\ell(\\hat{y},y), \quad (14) Lunified=Eℓ(y\^,y),(14)
其中,具体目标取决于特定实现形式: y y y 可以对应连续去噪模型中的扩散噪声,也可以对应 flow-matching 变体中的速度场,或者对应离散去噪形式中的被掩码 token。
一些具有代表性的早期统一设计,例如 UVA(Li et al., 2025c)、UWA(Zhu et al., 2025a)以及后来的 VideoVLA(Shen et al., 2025),已经明确体现了这一视角。 它们并没有保留模块化的"世界模型 + 策略头"分解方式,而是将控制看作通向统一预测生成器的直接接口。 UVA 学习一个联合的视频---动作潜在空间,并对这两种模态进行联合监督;与此同时,它通过轻量级的模态专用解码头保持高效部署,使策略推理能够绕过显式视频生成。 UWA 则将这种耦合进一步推进到扩散过程本身:它在单一 transformer 中,在模态专用时间步的条件下整合视频扩散和动作扩散,并且可以通过时间步控制将视觉未来边缘化,从而作为策略进行查询。 在这一统一视角的基础上,VideoVLA 将重点转向直接把预训练视频生成器转换为机器人控制模型:它将 Video Diffusion Transformer 扩展为 Video-Action Diffusion Transformer,使其能够联合预测未来视觉结果和动作序列,从而让预训练视频模型本身成为策略的骨干网络。 VideoPolicy(Liang et al., 2025a)采用了一个密切相关的视角,它将视频生成视为主要的策略基础,并将动作预测简化为叠加在生成行为之上的轻量级接口。
后续方法通过最小化视觉预测与控制之间的表示差距,进一步加强了这种耦合。 Cosmos Policy(Kim et al., 2026)是这一思想的一种特别直接的实现:它基本保持预训练视频扩散架构不变,并将机器人动作、未来状态和值函数编码为原始扩散序列中的额外潜在"帧"。 在推理阶段,这些输出并不需要被对称地全部使用:在直接策略模式下,执行只需要动作输出;而在规划模式下,未来状态和值预测可以用于对候选轨迹进行排序。 DreamZero(Ye et al., 2026b)遵循相同的端到端思想,采用一种自回归 flow-matching 视频---动作 DiT,但它执行的是闭环的分块联合去噪,而不是自由运行式的长时程展开,因此在保持视频---动作紧密对齐的同时,限制了误差累积。 UD-VLA(Chen et al., 2026b)将同一原则扩展到离散多模态设定中,它在单一同步去噪轨迹中耦合未来图像 token 和动作 token,同时引入专门的测试时效率提升技术。 GigaWorld-Policy(Ye et al., 2026a)提供了一种更加明确以动作为中心的变体:它在单一共享 transformer 堆栈中联合优化未来动作预测和动作条件未来视频生成,同时采用一种因果设计,使视觉分支在推理阶段成为可选部分。
归根结底,这些统一方法之间的关键差异,并不在于它们是否都会在线渲染完整的未来视频,而在于控制过程中视觉分支有多少仍然保持激活。 有些方法会保留显式的未来预测,以保证一致性或用于规划;而另一些方法则在保留联合训练收益的同时,为了提高效率,对视觉分支进行边缘化、截断或部分舍弃。 在所有这些情况下,与前文的解耦方法不同,世界模型不再被视为一个独立的上游模块,供下游策略使用。 相反,世界建模和策略学习被压缩进同一个生成过程中,这为将大规模视频预训练中的时空先验注入控制提供了一条可能路径。
3.4 具有专家世界模型骨干网络的 MoE/MoT 风格策略
图 3 展示了将世界模型用作策略的代表性架构范式。 (a) IDM 风格 ,即逆动力学模型风格。 视频生成模型首先预测未来观测,然后逆动力学模型从预测出的视觉轨迹中恢复动作,从而形成一种解耦式的"先预测、再行动"流程。 (b) 单一骨干网络风格 。 观测 token 和动作 token 在一个统一的共享骨干网络中被处理,因此未来预测和动作生成会在一个共同的潜在空间中被联合建模。 (c) MoT 风格。 视频专家和动作专家仍然保持一定程度的专门化,同时通过共享的联合注意力机制实现跨模态交互,从而使世界建模与策略生成之间形成更深层次的耦合。
与前文所述的单一骨干网络生成器相比,另一条相关但在架构上不同的研究路线,通过为视频预测、动作生成,有时也为语言或场景理解保留独立的专家流,从而保留了明确的专门化分工。 这些方法并不是将所有模态都压缩进一个共享的扩散骨干网络中,而是采用 MoE/MoT 风格(Liang et al., 2025b)或多分支设计,其中不同模态的专家通过共享注意力、交叉注意力或交错的自回归序列进行交互。 如图 3(c) 所示,与单一骨干网络模型不同,这些方法保留了独立的视频专家和动作专家,同时通过重复交互将二者耦合起来。其动机仍然是将预训练视频扩散模型中的时空先验和物理先验(Wan, 2025; Ali et al., 2025)迁移到控制中,但它基于一种不同的架构假设:完全参数共享并不总是最优的,因为视频预测和动作生成具有不同的时间频率、表示尺度和优化需求。从这个意义上说,这些模型类似于 π 0 \pi_0 π0(Black et al., 2024)和 π 0.5 \pi_{0.5} π0.5(Intelligence et al., 2025b)等专家化 VLA 设计;不同之处在于,它们的骨干网络主要不是静态语义编码器,而是具有时间预测能力的视频生成器,其表示中可能包含关于运动连续性、时间因果性和近似物理动力学的有用线索。
从高层次来看,这些方法可以被看作是在使用专门化专家学习一种耦合的预测---控制映射:
( h ℓ + 1 v , h ℓ + 1 a ) = F ℓ m i x ( h ℓ v , h ℓ a ; o t , l ) , ( 15 ) (\mathrm{h}^v_{\ell+1},\mathrm{h}^a_{\ell+1})=\mathcal{F}^{\mathrm{mix}}{\ell}(\mathrm{h}^v{\ell},\mathrm{h}^a_{\ell};o_t,l), \quad (15) (hℓ+1v,hℓ+1a)=Fℓmix(hℓv,hℓa;ot,l),(15)
其中, ℓ \ell ℓ 表示层索引, F ℓ m i x \mathcal{F}^{\mathrm{mix}}_{\ell} Fℓmix 表示逐层交互算子,例如联合注意力、交叉注意力或共享注意力融合(Bao et al., 2023)。该算子在保留视频专家和动作专家各自不同参数化方式的同时,将二者耦合起来。 在这一视角下,视频分支充当一个具有时间预测能力的潜在流;策略则是通过不断将这种前瞻信息注入动作分支而得到的,而不是从一个完全独立的下游头部中解码动作。
在这一类方法中,一个常见模式是并行专家耦合,即将一个预训练视频扩散骨干网络与一个较轻量的动作分支配对。 GE-Act(Liao et al., 2026)遵循这一模式:它在一个预训练视频扩散世界模型旁边引入一条并行的 flow-matching 动作路径,并使用深层交叉注意力将视觉潜在特征注入动作生成过程。 在这里,视频分支提供预测性的世界状态结构,而动作分支则将其转换为可执行控制,并且不需要在线完整渲染视频。 这一范式的早期实现利用图像编辑扩散模型来预测子目标,然后由目标条件策略去跟随这些子目标(Black et al., 2023; Hatch et al., 2025)。
第二种更明确的模式是基于 Mixture-of-Transformers 的深层交互,在这种模式中,多个专家在整个网络中都被保留下来,并通过共享注意力反复融合。 Motus(Bi et al., 2025)、LingBot-VA(Li et al., 2026b)、BagelVLA(Hu et al., 2026)以及更近期的 DiT4DiT(Ma et al., 2026)是这一方向的代表性例子。 Motus 最直接地将这一设计表述为一种 Mixture-of-Transformers,其中为理解、视频生成和动作分别设置专门的专家。 LingBot-VA 通过将视频 token 和动作 token 交错放入一个共享的自回归序列中,并使用带有共享注意力的双流 MoT,将这一思想推进到因果世界建模方向,从而把想象出来的未来状态转化为动作优化的上下文。 BagelVLA 将相同直觉扩展到更长时程的操作任务中,在一个执行循环内交错进行语言规划、视觉预测和动作生成;它的 Residual Flow Guidance 进一步通过单步去噪(Liu et al., 2023b)而不是完整视频展开,使视觉前瞻变得更加实用。 DiT4DiT(Ma et al., 2026)通过耦合架构遵循相同直觉,使用视频分支中的中间去噪特征来指导动作预测。 Fast-WAM(Yuan et al., 2026)可以被看作这一类方法中的一个混合点:它采用了一个共享注意力的 Mixture-of-Transformers 骨干网络,并具有耦合的视频分支和动作分支;但它得出的结论是,主要收益可能更多来自训练阶段的视频协同训练,而不是推理阶段显式的未来想象。 在这些变体中,视频分支越来越不被视为一个需要忠实渲染出来的输出,而是被视为一个预测性的潜在过程,其隐藏状态用于指导动作生成。
第三种模式是潜在空间专家化,它在保留专门化多模态分支的同时,将世界建模从像素空间转移到结构化潜在动力学空间。 LDA-1B(Lyu et al., 2026)代表了这一方向:它将视觉预测转移到 DINO(Caron et al., 2021)潜在空间中,并在一个多模态扩散 transformer 内部,通过共享自注意力耦合视觉专家和动作专家。 FRAPPE(Zhao et al., 2026)从未来表示对齐的角度遵循了相关思想:它并不重建未来观测,而是训练多个带有独立适配器的并行专家流,并在潜在空间中将它们与视觉基础模型对齐。 尽管它相比前文那些明确架构化的 MoT 模型更加偏向训练方法,但它反映了同一个底层思想:深度耦合的专门化预测流能够改善具有世界感知能力的动作生成。
综合来看,这些方法弥合了分离式模块化流程与完全统一的单一骨干网络生成器之间的差距。 它们在保留架构专门化的同时,将世界建模直接嵌入到策略之中。 具体而言,视频扩散模型提供预测性的前瞻能力,而 MoE/MoT 机制则在不丢失模态专门结构的情况下,将这种前瞻能力转化为动作。 与单一骨干网络方法相比,关键区别在于架构:二者都旨在将未来预测与动作生成耦合起来,但这些方法是通过深度交互的专门化专家来实现这一点,而不是通过完全参数共享来实现。
3.5 统一视觉-语言-动作模型
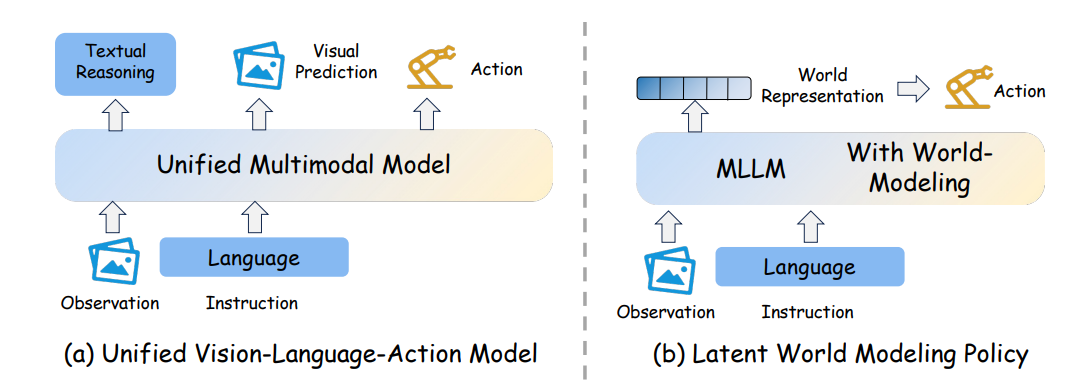 图 4 展示了两种基于 MLLM 的路径,用于将世界建模内化到策略学习中。 (a) 统一视觉-语言-动作模型 。 一个统一的多模态模型联合处理观测和语言,并被训练为在产生动作的同时,生成面向未来的辅助输出,例如文本推理或视觉预测。 (b) 面向 VLA 的潜在空间世界建模。 该模型并不显式预测未来图像,而是在同一个 MLLM 骨干网络内部,将未来动力学内化为一种紧凑的世界表示或世界建模能力,然后再将这种潜在预测知识映射为动作。
图 4 展示了两种基于 MLLM 的路径,用于将世界建模内化到策略学习中。 (a) 统一视觉-语言-动作模型 。 一个统一的多模态模型联合处理观测和语言,并被训练为在产生动作的同时,生成面向未来的辅助输出,例如文本推理或视觉预测。 (b) 面向 VLA 的潜在空间世界建模。 该模型并不显式预测未来图像,而是在同一个 MLLM 骨干网络内部,将未来动力学内化为一种紧凑的世界表示或世界建模能力,然后再将这种潜在预测知识映射为动作。
统一 VLA 模型为"将世界模型作为策略"提供了另一条路径。 尽管它们并不总是使用显式的视频世界模型,但它们仍然会在同一个多模态策略骨干网络内部学习面向未来的预测结构,例如通过未来图像预测、视觉前瞻,或者结构化世界知识来实现。 如图 4(a) 所示,这一类方法不同于前文那些基于视频骨干网络的范式,其区别在于:未来建模被内化到统一 VLA 架构内部,而不是通过一个单独的预测模块引入。
其中一个重要子类会执行显式的未来状态预测。 这些方法会直接预测未来图像,可能是一帧图像,也可能是一小段图像序列,并将其作为统一训练目标的一部分。 GR-1(Wu et al., 2024)是这一方向的早期代表,它在单一 GPT 风格的 transformer 中联合预测动作和未来图像。 UP-VLA(Zhang et al., 2025c)采用了类似策略,通过未来图像预测来同时提升动作生成能力和视觉泛化能力。 WorldVLA(Cen et al., 2025)进一步在一个自回归框架中统一了动作和图像的理解与生成,同时主要将未来图像预测作为一种联合训练信号,而不是作为推理阶段必须输出的结果。
第二个子类用隐式或潜在的未来建模来替代像素级预测。 这些方法并不直接预测未来帧,而是预测一种更加紧凑、具有未来感知能力,并且与动作更加紧密对齐的表示。 DreamVLA(Zhang et al., 2025e)预测结构化世界知识,包括动态线索、空间线索和语义线索,用以支持逆动力学建模。 UniVLA(Wang et al., 2025)在一个原生多模态 token 化框架上,于后训练阶段引入世界建模,使模型能够从大规模视频数据中吸收因果动力学信息,而不需要引入一个单独的外部世界模型。 CoWVLA(Yang et al., 2026a)进一步推进了这一方向,它建模潜在运动和紧凑的未来视觉目标,而不是重建冗余的未来帧。
第三个子类由多专家或多系统统一模型构成,这些模型在训练层面和任务层面仍然是统一的,但在架构内部保留了明确的功能专门化。 这一类别包括 F1(Lv et al., 2025)、InternVLA-A1(Cai et al., 2026)、HALO(Shou et al., 2026)和 TriVLA(Liu et al., 2025d)。 尽管这些方法也采用了专家化或 MoT 风格的设计,但它们的预测分支更适合被理解为统一 VLA 框架中的视觉前瞻或子目标生成,而不是原生视频骨干网络世界模型。 F1 在 Mixture-of-Transformers 架构中预测未来视觉状态,并将其作为规划目标。 InternVLA-A1 通过轻量级潜在视觉前瞻,以及对前瞻预测和动作生成的联合优化,扩展了这一设计。 HALO 将预测分支推进到视觉子目标预测和具身推理方向,而 TriVLA 则将定位、情节式动态感知和控制组织为相互协调的子系统。
综合来看,统一 VLA 模型将"世界模型作为策略"的概念扩展到了显式视频生成之外。 其中一些方法通过直接预测未来图像来实现这一点,另一些方法通过紧凑的潜在世界知识或语义世界知识来实现,还有一些方法则通过带有显式前瞻模块的统一多专家系统来实现。 在这些不同变体中,共同原则是:动作生成不再被视为一种从当前观测出发的纯反应式映射,而是与一个内部预测目标联合训练;这个内部预测目标捕捉未来状态演化,或者捕捉其紧凑替代表示。 因此,相对于前面几个小节而言,这里的关键区别并不在于模型是否包含一个显式的独立世界模型,而在于面向未来的预测建模是否被内化在同一个多模态策略骨干网络之中。
3.6 具有潜在空间世界建模的策略
图 4 展示了两种基于 MLLM 的路径,用于将世界建模内化到策略学习中。 (a) 统一视觉-语言-动作模型 。 一个统一的多模态模型联合处理观测和语言,并被训练为在产生动作的同时,生成面向未来的辅助输出,例如文本推理或视觉预测。 (b) 面向 VLA 的潜在空间世界建模。 该模型并不显式预测未来图像,而是在同一个 MLLM 骨干网络内部,将未来动力学内化为一种紧凑的世界表示或世界建模能力,然后再将这种潜在预测知识映射为动作。
"将世界模型作为策略"的另一条路径,是由这样一类方法定义的:它们完全在表示空间中内化未来预测,而不依赖显式的图像或视频生成。 这些方法并不是合成未来观测,而是构建预测性潜在目标、具有未来感知能力的嵌入表示,或者紧凑的控制条件,并在同一个策略框架中将它们与动作生成耦合起来。 在这一语境下,世界建模并不是通过视觉重建来实现的,而是通过学习一种具有未来感知能力的表示来实现;这种表示以一种对控制直接有用的形式,捕捉环境可能如何演化。 因此,这类方法通过将预测性结构注入动作生成,保留了世界建模的核心优势,同时避免了显式生成式解码带来的计算开销和冗余。 从概念上看,这一方向与 JEPA 系列方法有关(Assran et al., 2023, 2025)。JEPA 在嵌入空间而不是像素空间中建模预测,但这里的重点并不是 JEPA 本身;相反,本文关注的是一些 VLA 方法的出现,这些方法将这种表示空间中的预测原则转化为策略学习中的实用机制。 图 4(b) 展示了这种更加内化的变体。 在这里,骨干网络通常同样是基于 MLLM 的,而不是基于 video-DiT 的;但未来建模被更深地吸收到潜在世界表示或参数化世界知识之中,因此动作生成可以由内部预测结构来引导,而不需要显式解码未来图像。
从时间顺序上看,FLARE(Zheng et al., 2025)是这一方向的早期代表。 它提出了"未来潜在表示对齐",即 Future Latent Representation Alignment,将动作去噪网络的隐藏特征与未来观测的潜在嵌入进行对齐,从而使策略能够在不显式生成未来状态的情况下,隐式地预判未来状态。 VLA-JEPA(Sun et al., 2026)通过为 VLA 采用 JEPA 风格的预训练目标,使这一思想更加明确:它的关键设计是无泄漏状态预测,其中未来帧只被用来产生用于监督的潜在目标,从而鼓励模型在潜在空间中学习与动作相关的状态转移,而不是通过像素变化走捷径。 JEPA-VLA(Miao et al., 2026)采取了一条互补路线:它并不是添加一个显式的潜在预测头,而是认为视频 JEPA 模型学习到的预测性嵌入,尤其是 V-JEPA 2(Assran et al., 2025)中的预测性嵌入,已经比静态视觉表示提供了更强的策略先验,因此它将这些预测性嵌入适配为现有 VLA 模型的更优骨干网络。 最近,WoG(Su et al., 2026)将世界建模转移到动作生成的条件空间中:它并不是预测未来图像或通用的未来潜在表示,而是学习与动作一起预测紧凑的面向未来的条件,使模型能够直接预测对精确控制最有用的那部分未来信息。 DIAL(Chen et al., 2026c)提供了一个密切相关的近期例子:它通过潜在世界建模将高层意图与低层动作解耦,并使用 VLM 特征空间中的潜在视觉前瞻作为下游动作生成的结构化瓶颈。
除了神经网络潜在表示之外,在符号式或面向规划器的世界模型中,还存在一种相关但更加经典的非像素抽象形式。 与前文回顾的神经网络策略骨干不同,这些方法通常将世界建模外化为一种抽象转移模型,该模型定义在谓词、物体关系、可供性、操作符或因果过程之上;随后,符号规划器或任务与运动规划器会查询这个模型,以生成高层技能序列(Silver et al., 2021; Shah et al., 2025; Liang et al., 2025c; Athalye et al., 2026; Liang et al., 2026)。 我们将这一方向作为一种互补视角纳入讨论,是为了强调:有用的世界模型并不一定依赖于预测像素;它们也可以捕捉抽象逻辑、物体关系、因果规律和符号动力学,用于规划与控制。
综合来看,本小节强调了一条基于世界模型的策略学习的非像素路径。 其中的主线是潜在空间世界建模,在这种方式中,策略避免了显式的未来图像或视频解码,同时仍然将未来动力学内化进动作生成过程中。 前文提到的符号规划器例子进一步强化了同一个更广泛的观点:当紧凑的潜在变量或抽象变量能够为动作提供更直接的接口时,与控制相关的预测就可以通过这些变量来表达。
4 World Model as Simulator
除了作为用于条件生成、规划或内部监督的预测模块之外,世界模型还可以更直接地作为交互式模拟器使用。 在这一范式中,世界模型的价值不仅在于它能够建模未来演化,还在于它能够替代环境本身发挥作用(Xiao et al., 2025; Li et al., 2025b; Zhu et al., 2026; Gemini Robotics Team et al., 2025):给定当前观测、任务指令和候选动作,模型可以展开未来状态,提供反馈信号,并通过想象中的交互来支持下游决策。 这使得"作为模拟器的世界模型"成为面向具身智能的世界建模中一种特别直接且实用的扩展形式。
这一方向对于视觉运动策略尤其具有吸引力,因为在真实物理机器人上进行传统强化学习通常速度慢、成本高、难以重置,而且可能存在安全风险;与此同时,纯模仿学习仍然受限于示范数据质量,并且难以轻易从失败中学习。 因此,近期工作使用由世界模型构建的学习型模拟器来替代代价高昂的真实世界交互,使策略能够通过想象中的展开来改进,而不是依赖反复的物理试错(Wu et al., 2023)。 在 World-Env(Xiao et al., 2025)、VLA-RFT(Li et al., 2025b)和 WMPO(Zhu et al., 2026)等框架中,世界模型被明确用作一种低成本、可控的虚拟环境,用于后训练,从而在提高数据效率和鲁棒性的同时,显著降低对真实交互的依赖。
与此同时,将世界模型视为模拟器的观点所带来的收益并不局限于强化训练。 由于世界模型能够展开以动作为条件的未来状态,它也可以从预测轨迹中暴露出可验证的信号,例如类似奖励的反馈(Xiao et al., 2025; Li et al., 2025b)、任务完成线索,或者展开一致性;这些信号不仅对策略优化有用,也对评估、排序和测试时决策有用。 这一点已经体现在一些系统中,这些系统会为学习得到的模拟器增加奖励反馈或终止反馈;同时,这一思想也自然扩展到基于展开的候选行为评估中。 在这里,支持想象式训练的同一种预测能力,也成为一种机制,用于在候选动作序列真正执行之前判断它是否可能成功。
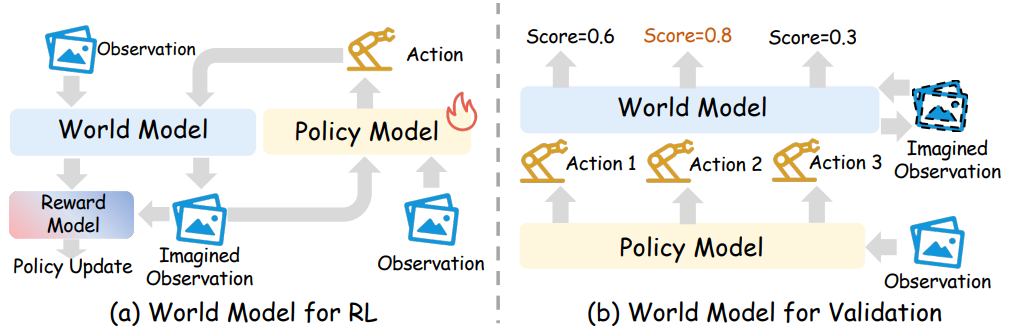 图 5 展示了世界模型在策略学习中的两种用途。 (a) 在强化学习设定中,世界模型作为学习型模拟器,产生想象中的状态转移,用于策略改进。 (b) 在验证设定中,世界模型对候选动作的想象后果进行评分,以支持决策时的动作选择。
图 5 展示了世界模型在策略学习中的两种用途。 (a) 在强化学习设定中,世界模型作为学习型模拟器,产生想象中的状态转移,用于策略改进。 (b) 在验证设定中,世界模型对候选动作的想象后果进行评分,以支持决策时的动作选择。
基于这一原因,我们围绕模拟器范式的两种互补用途来组织本节内容。 如图 5 所总结的那样,世界模型至少可以通过两种不同的功能角色来支持策略学习:一是作为用于强化学习的学习型模拟器,二是作为用于决策时验证的评估器。 我们首先讨论用于强化训练的世界模型 ,在这种情况下,学习型模拟器被用来替代物理交互,并通过想象展开来支持策略改进。 随后,我们讨论用于评估的世界模型,在这种情况下,同样的模拟器能力被用于通过预测展开和未来状态反馈来验证、排序或评估候选行为。
4.1 用于强化学习的世界模型
世界模型在具身学习中的另一个作用,是作为交互式模拟器,用于强化学习式的后训练。 不同于前面那些范式,在那些范式中,世界模型主要提供预测性条件、规划线索或内部监督;而本小节中的方法则直接将世界模型用作一个学习得到的环境,使视觉-语言-动作模型,即 Vision-Language-Action(VLA)策略,可以在其中展开轨迹、接收奖励,并通过想象中的交互来改进自身。 在这一设定中,世界模型不再仅仅是一个合理未来的预测器;它变成了承载强化学习过程的媒介。 从高层次来看,这些方法是在一个学习得到的模拟器内部优化策略:
( o ^ t + 1 , r ^ t , d ^ t ) ∼ p ϕ ( ⋅ ∣ o ≤ t , a ≤ t , l ) , ( 16 ) (\hat{o}{t+1},\hat{r}t,\hat{d}t)\sim p\phi(\cdot\mid o{\leq t},a{\leq t},l), \quad (16) (o^t+1,r^t,d^t)∼pϕ(⋅∣o≤t,a≤t,l),(16)
其中,世界模型 p ϕ p_\phi pϕ 提供想象出来的状态转移,并且可以选择性地提供奖励信号和终止信号。 随后,策略通过最大化期望回报,从想象展开中得到改进:
J ( θ ) = E τ ^ ∼ ( π θ , p ϕ ) ∑ t γ t r \^ t , ( 17 ) J(\theta)=\mathbb{E}{\hat{\tau}\sim(\pi\theta,p_\phi)}\left\\sum_t\\gamma\^t\\hat{r}_t\\right, \quad (17) J(θ)=Eτ^∼(πθ,pϕ)t∑γtr\^t,(17)
或者,在实践中,通过一种 GRPO 风格的策略优化目标来实现:
L R L ( θ ) = − E t min ( r t ( θ ) A \^ t , clip ( r t ( θ ) , 1 − ϵ , 1 + ϵ ) A \^ t ) , r t ( θ ) = π θ ( a t ∣ s t ) π θ old ( a t ∣ s t ) , ( 18 ) \mathcal{L}{RL}(\theta)=-\mathbb{E}t\left\\min\\left(r_t(\\theta)\\hat{A}_t,\\operatorname{clip}(r_t(\\theta),1-\\epsilon,1+\\epsilon)\\hat{A}_t\\right)\\right,\quad r_t(\theta)=\frac{\pi\theta(a_t\mid s_t)}{\pi{\theta_{\text{old}}}(a_t\mid s_t)}, \quad (18) LRL(θ)=−Etmin(rt(θ)A\^t,clip(rt(θ),1−ϵ,1+ϵ)A\^t),rt(θ)=πθold(at∣st)πθ(at∣st),(18)
同时,还会结合一些针对具体任务的变体,以适配分块动作头或基于 flow 的动作头。 在这一共同视角下,这些方法的共同目标是:用学习得到的世界模拟器内部的强化学习,来替代代价昂贵的真实物理交互。
在这一第一层级范式中,UniSim(Yang et al., 2024a)、World-Env(Xiao et al., 2025)和 VLA-RFT(Li et al., 2025b)等早期工作,通过将动作条件世界模拟与奖励生成相结合,建立了在学习型模拟器中进行强化学习的基本流程。 DiWA(Chandra et al., 2025)表明,从大规模 play data 中学习得到的冻结世界模型,已经能够支持扩散策略的完全离线适配;而 World4RL(Jiang et al., 2025d)则将这一思想扩展到更高保真度的操作精修中,通过扩散世界模型实现端到端的想象式策略优化。
后续工作使这一范式越来越能够兼容现代 VLA 架构和更大规模的具身数据集。 World-Gymnast(Quevedo et al., 2025)表明,在视频世界模型内部进行强化学习,能够优于监督微调和软件模拟器。 PlayWorld(Yin et al., 2026)从自主 play 中学习机器人世界模型,并表明在学习得到的模拟器中进行强化学习,可以提升下游真实世界表现。 RehearseVLA(Xiao et al., 2026)将同样的原则适配到 VLA 后训练中,使用一个物理一致的世界模拟器,以及一个用于奖励和终止反馈的即时反思器。 与此同时,WMPO(Zhu et al., 2026)强调像素空间想象和 on-policy GRPO;ProphRL(Zhang et al., 2025b)通过 FA-GRPO 和 FlowScale 将强化学习更新适配到基于 flow 的动作头;RISE(Yang et al., 2026b)为模拟器加入组合式动力学和进度价值估计;而 GigaBrain-0.5M ∗ ^* ∗(Team et al., 2026)则将基于世界模型的强化学习扩展到预训练 VLA 的适配中。 尽管这些方法之间存在差异,但它们都主要将世界模型视为策略优化发生的环境。
第二层级的发展则明确认识到:学习得到的模拟器本身并不完美,必须与策略一起改进。 World-VLA-Loop(Liu et al., 2026b)、VLAW(Guo et al., 2026a)和 WoVR(Jiang et al., 2026)从不同方式体现了这一转变。 World-VLA-Loop(Liu et al., 2026b)联合预测未来观测和奖励,并通过使用策略失败展开来精修模拟器,从而闭合这一循环。 VLAW(Guo et al., 2026a)采用一种迭代式的修复与改进策略,在用于模拟器精修的真实世界数据和用于 VLA 改进的合成数据之间交替进行。 WoVR(Jiang et al., 2026)进一步推进了这一方向,它将模拟器可靠性视为核心瓶颈,并引入可控的动作条件视频建模、关键帧初始化展开,以及显式的世界模型---策略协同演化:
ϕ k + 1 ← UpdateWM ( ϕ k , D real ∪ D policy ( π θ k ) ) , θ k + 1 ← UpdatePolicy ( θ k , D ^ ( ϕ k + 1 ) ) , ( 19 ) \phi^{k+1}\leftarrow \operatorname{UpdateWM}\left(\phi^k,D_{\text{real}}\cup D_{\text{policy}}(\pi_{\theta^k})\right),\quad \theta^{k+1}\leftarrow \operatorname{UpdatePolicy}\left(\theta^k,\hat{D}(\phi^{k+1})\right), \quad (19) ϕk+1←UpdateWM(ϕk,Dreal∪Dpolicy(πθk)),θk+1←UpdatePolicy(θk,D^(ϕk+1)),(19)
其中,策略展开用于精修世界模型,而改进后的世界模型又反过来为后续策略更新产生更好的想象数据。 从这个意义上说,研究重点已经从"在世界模型中进行强化学习",进一步转向"与世界模型一起进行强化学习";在后一种情况下,世界模型自身的保真度、动作跟随精度和展开可靠性也必须被持续改进。
综合来看,本小节揭示了世界模型在策略改进中所扮演角色的清晰演进。 第一层级范式将世界模型视为用于强化训练的学习型模拟器,各方法之间主要在奖励设计、展开表示和优化兼容性方面存在差异。 第二层级范式进一步认识到,想象式强化学习的有效性取决于模拟器本身的可靠性,因此将模拟器精修、展开调控以及策略---世界模型协同演化作为整个循环中的组成部分。
4.2 用于评估的世界模型
除了作为用于强化学习后训练的学习型模拟器之外,世界模型还可以在执行之前评估候选行为。 在这里,目标不是通过反复的想象式交互来改进策略,而是估计哪一个候选动作序列、策略或检查点最有可能在真实世界中成功。 如图 5(b) 所示,世界模型通过对候选动作的想象后果进行评分或验证,从而支持决策时的选择。 给定当前观测、任务指令以及一个或多个候选动作,世界模型会展开预测的未来,并将这些未来用于排序、拒绝不合适动作,或进行安全过滤。 从这个意义上说,评估器角色是模拟器视角的自然延伸:一旦世界模型能够替代环境本身,它就不仅可以用于想象中的训练,也可以用于判断策略下一步应该做什么。
图 5 展示了世界模型在策略学习中的两种用途。 (a) 在强化学习设定中,世界模型作为学习型模拟器,产生想象中的状态转移,用于策略改进。 (b) 在验证设定中,世界模型对候选动作的想象后果进行评分,以支持决策时的动作选择。
一种直接的评估形式是基于展开的候选行为评估。 在这种形式中,策略提出多个动作序列,世界模型预测它们的未来结果,然后系统选择想象后果最有利的候选动作。 GPC(Qi et al., 2026)是一个特别清晰的例子:它并不重新训练策略,而是在部署阶段为一个冻结的生成式机器人策略增加一个动作条件世界模型,并利用预测性前瞻在线排序和优化候选动作。 IRASim(Zhu et al., 2025b)同样通过模拟多个候选轨迹,并选择预测价值最高的轨迹,展示了基于模型的规划。 World-in-World(Zhang et al., 2025a)将这一思想扩展到闭环规划中,在该方法中,候选计划会在想象中展开,由一个修正策略进行评估,并在执行前被修正。 DreamPlan(Jia et al., 2026a)则将同样的评估器逻辑转化为训练信号:它基于世界模型展开,为候选动作构造偏好对。 在这些方法中,世界模型充当一种决策时或接近决策时的选择器,将想象中的未来转化为动作选择。
除了对离散候选动作进行简单排序之外,一种更主动的范式会将世界模型视为模型预测控制,即 Model Predictive Control(MPC)中的转移动力学。 在这一设定中,系统并不是仅仅从少数预定义动作中进行选择,而是在世界模型想象出的轨迹中主动优化一个动作序列,以最小化代价函数。 TD-MPC2(Hansen et al., 2024)和 LeWorldModel(Maes et al., 2026)等工作表明,潜在空间中的 MPC 可以显著增强具身智能体的长时程推理能力。 通过在世界模型中进行基于梯度的规划,智能体能够发现训练示范中并未显式出现的复杂策略。 这种协同作用实际上将世界模型从一个被动的动作评判者,转变为用于连续控制优化的主动导航地图。
第二种更加明确的形式,是直接将世界模型本身用作策略评估器。 一个近期的大规模例子是 Evaluating Gemini Robotics Policies in a Veo World Simulator(Team et al., 2025a),该工作使用视频世界模拟器进行离线策略评估、分布外测试,即 OOD testing,以及安全性探测。 WorldEval(Li et al., 2025e)是最清晰的例子:它研究世界模型是否能够作为真实世界策略评估的可扩展代理,在完全想象的环境中对不同机器人策略,甚至同一策略的不同检查点进行排序,同时还充当安全检测器。 同样的角色也体现在 WorldArena(Shang et al., 2026)这一基准层面上,该工作明确将策略评估识别为具身世界模型的核心下游用途之一。
第三种形式出现在模拟器配备显式反馈头的情况下,这些反馈头会将想象展开转化为评估信号。 World-Env(Xiao et al., 2025)为模拟器增加了连续奖励预测和动作终止预测。 VLA-RFT(Li et al., 2025b)使用在可控世界模拟器内部的想象轨迹上计算得到的已验证奖励。 World-VLA-Loop(Liu et al., 2026b)在一个状态感知视频世界模型中联合预测未来观测和奖励信号。 RISE(Yang et al., 2026b)通过引入一个进度价值模型,使这种评估器角色更加明确;该模型会根据任务进展程度对想象结果进行评分。 在这些系统中,想象展开不仅是合成训练数据的来源,也是判断某个行为是否有希望、是否完成任务,或者是否值得执行的依据。
一个相关但更轻量的视角出现在潜在空间预测世界模型中,尤其是 JEPA 这一方向。 这些方法并不生成显式的像素空间未来来对候选动作进行排序,而是在嵌入空间中进行预测和规划。 V-JEPA 2(Assran et al., 2025)和 V-JEPA 2.1(Mur-Labadia et al., 2026)是代表性例子,其中后者进一步表明,潜在动作条件世界模型可以支持以图像目标为条件的零样本机器人规划。 更近期的 LeWorldModel(Maes et al., 2026)将这一方向推进到一种更简单、更快速的端到端 JEPA 形式,同时也表明潜在预测模型能够检测物理上不合理的事件。 然而,目前这些方法更适合被看作预测性规划和合理性检查的相邻方向,而不是本文所考虑的更广泛具身控制意义上已经充分发展的策略评估器。
这种评估器视角也说明了为什么动作忠实性和展开可靠性如此重要。 只有当评估器想象出的未来能够保留候选动作的因果后果时,它才是有用的。 CtrlWorld(Guo et al., 2026b)明确展示了这种联系,即动作忠实的展开可以支持想象中的策略评估。 与此同时,WoVR(Jiang et al., 2026)强调了一个重要警示:幻觉和长时程误差不仅会降低视觉质量,还可能直接破坏评估信号本身。 因此,对于评估而言,仅有真实感是不够的;真正重要的是,展开是否足够可靠,能否以贴近真实世界执行结果的方式支持排序、选择和拒绝。
综合来看,这些工作揭示了模拟器范式的明显扩展。 在具身机器人学习中,世界模型不再只是用于强化训练的低成本环境;它也越来越多地被用作评估器,能够比较策略、为候选行为评分、检测可能的失败,并同时支持决策时动作选择和离线策略评估(Li et al., 2025e; Team et al., 2025a)。 这一转变对本文后续内容具有重要概念意义,因为它表明,世界模型的价值不仅在于生成未来轨迹,还在于生成足够可信的轨迹,以支持策略评估和动作选择。
5 用于机器人视频生成的世界模型
5.1 问题设定与范围
具身世界建模的一条重要路径,是直接在图像或视频空间中表示未来。 在这一设定中,模型根据当前观测、任务规定,以及通常还包括的一系列候选动作,来预测机器人---环境交互的视觉演化过程。 与通用视频合成不同,机器人视频生成受到更严格的要求:预测出的未来不仅应当在视觉上合理,还应当具有时间连贯性、动作一致性、物理可信性,并且对下游决策有用。 因此,机器人视频生成不应仅仅被理解为一个感知生成问题,而应被理解为一种具体机制,用于构建视觉上显式的世界模型,从而支持机器人策略学习、规划、评估、仿真和数据生成。 近年来,大规模视频生成骨干网络的发展,例如 CogVideoX,发挥了重要的推动作用;它们表明,长时程、高保真的时空生成能力可以在大规模数据上被学习,并随后适配到具身场景中(Yang et al., 2024b)。 本节之所以关注基于视频的世界模型,是因为它们构成了近期研究中一个快速增长且具有实际影响力的分支,而不是因为我们假定像素级预测是具身控制中最紧凑或普遍最优的表示方式。
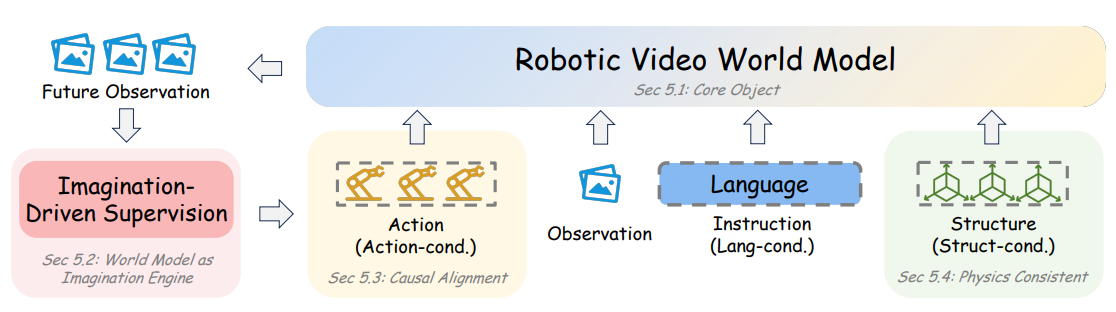 图 6 展示了机器人视频世界模型的统一视角。 第 5.1 节将核心对象定义为机器人视频世界模型,即一种在视觉空间中预测未来观测的模型。 在这一核心基础上,第 5.2 节将预测未来用作监督的想象引擎,第 5.3 节引入动作条件以提高因果对齐和可控性,第 5.4 节进一步加入结构先验,以增强物理一致性和交互一致性。 因此,最终得到的未来观测不仅在视觉上是合理的,而且越来越能够用于下游机器人学习和决策。 最后,第 5.5 节强调了一个更广泛的转变:从面向特定任务的视频预测,转向一种建立在强视频先验之上的、可扩展且可复用的世界模型接口。
图 6 展示了机器人视频世界模型的统一视角。 第 5.1 节将核心对象定义为机器人视频世界模型,即一种在视觉空间中预测未来观测的模型。 在这一核心基础上,第 5.2 节将预测未来用作监督的想象引擎,第 5.3 节引入动作条件以提高因果对齐和可控性,第 5.4 节进一步加入结构先验,以增强物理一致性和交互一致性。 因此,最终得到的未来观测不仅在视觉上是合理的,而且越来越能够用于下游机器人学习和决策。 最后,第 5.5 节强调了一个更广泛的转变:从面向特定任务的视频预测,转向一种建立在强视频先验之上的、可扩展且可复用的世界模型接口。
在本文综述中,我们也将任务条件或语言条件视为一种高层动作形式。 在这一视角下,机器人视频生成不仅包括以低层动作为条件的展开,也包括由文本或任务引导的视觉预测;后者会在低层控制被落实之前,规定应当实现怎样的未来。 因此,关键问题并不只是模型能否生成视觉上令人信服的未来视频,而是这些未来是否具有可行动性:它们是否忠实于条件动作,是否保持物理上合理的交互动力学,并且是否能够被转换为可执行的机器人行为。 在机器人领域中,视频世界模型的价值取决于它是否能够保留动作后果、交互结构和物理规律,并以此改善策略行为。 按照这一观点,如图 6 所示,我们将相关文献组织为四个发展阶段:作为策略学习想象机制的视频生成、动作可控的展开模型、具有更丰富交互先验的结构感知生成,以及被适配为可复用世界模型的基础规模视频骨干网络。 表 2 在这一以能力为导向的分类体系下,总结了代表性方法。
5.2 作为策略学习想象机制的视频生成
第一类方法主要将视频生成用作策略学习中的想象引擎。 其核心思想是利用强大的生成先验来合成未来任务执行过程,然后将这些想象出来的未来转化为机器人控制的监督信号。 在这一方向中,视频模型的价值并不在于它能够生成视觉上令人印象深刻的视频片段,而在于它能够将监督信号扩展到已采集机器人轨迹的狭窄支持范围之外。
一个密切相关的分支是由文本或任务引导的机器人视频生成。 在我们的定义中,语言可以被视为一种高层动作,用来规定应当实现怎样的未来。 从这一视角来看,UniPi(Du et al., 2023)和 Video Language Planning(Du et al., 2024)等方法并不仅仅是在进行感知合成,而是在进行机器人世界建模;在这种建模中,语义动作被转换为预测性的视觉轨迹。 这一分支主要用于数据扩增和视觉规划,因为它能够在低层动作落实之前,提供与任务相关的示范和面向未来的监督信号。
Dreamitate(Liang et al., 2024)是一个早期且具有代表性的例子。 它在特定任务的人类示范数据上微调一个视频扩散模型,并在测试阶段,将新场景中合成出来的执行过程直接用作指导动作的视觉计划,以实现真实世界机器人控制。 RoboDreamer(Zhou et al., 2024)通过组合式世界建模扩展了这一方向。在该方法中,指令被分解为可复用的基本单元,生成过程则以这些结构化组件为条件,从而提升模型对未见过的物体和动作组合的泛化能力。 ManipDreamer(Li et al., 2025f)通过引入动作树表示,并结合深度信息和语义视觉引导,进一步强化了这一方向,从而提升了指令跟随能力,以及时间一致性和物理一致性。
一个相关但更加明确的视角,是将想象重新解释为一种可学习的数字孪生体。 DreMa(Barcellona et al., 2025)将 Gaussian Splatting 与物理模拟器结合起来,重建一种显式且可操作的场景表示,从而使模型能够为模仿学习生成额外示范。 PhysWorld(Mao et al., 2025)通过从生成视频中重建物理世界模型,并借助以物体为中心的残差强化学习,将预测运动落实到机器人动作中,从而解决照片级真实运动与物理可执行行为之间的差距。 这些方法超越了纯粹的视觉想象,开始将生成的未来与具有物理意义的执行过程联系起来。
这种想象范式也自然地扩展到合成数据生成和高层规划中。 当未来生成以任务描述或语言描述为条件时,生成的视频可以作为高层示范替代物,或者作为与任务相关的合成监督信号。 它们还可以作为长时程决策中的视觉计划发挥作用(Du et al., 2024; Chen et al., 2025a)。 DreamGen(Jang et al., 2025a)将强大的视频生成器适配到目标具身形态上,合成神经轨迹,并通过潜在动作建模或逆动力学恢复可执行动作。 它的核心观点是,更强的视频世界模型不仅可以用于正则化策略,还可以生成合成经验,从而提升下游泛化能力。 综合来看,这些工作确立了机器人视频生成的第一个主要作用,即作为一种想象引擎,拓宽可用于策略学习的监督信号和规划信号。
5.3 迈向动作可控的视频世界模型
第二类方法将重点从想象式监督转向显式可控性。 在这里,核心问题不再是模型能否生成看起来合理的未来视频,而是生成的未来是否能够以足够高的精度跟随给定的动作序列,从而支持操作推理和下游控制。 这一转变非常重要,因为在具身设定中,如果一个视觉上令人信服的展开不能忠实地响应动作干预,那么它的价值是有限的。
IRASim(Zhu et al., 2025b)是这一转变的代表性方法。 它将机器人操作表述为一个从轨迹到视频的问题,并在每个 transformer 块中引入帧级动作条件,以加强单个动作与对应未来帧之间的对齐。 RoboEnvision(Yang et al., 2025)关注长时程多任务操作,并强调在较长任务演化过程中保持语义一致性和时间一致性的困难。 RoboMaster(Fu et al., 2026)通过协同轨迹控制来处理更加复杂的机器人---物体交互。 它通过将操作过程分解为多个阶段,并建模机械臂与被操作物体之间的耦合运动,提高了模型在丰富接触动力学下的忠实性。 Ctrl-World(Guo et al., 2026b)进一步将可控性推进到策略在环展开的方向。 它结合了联合多视角预测、帧级动作控制以及基于记忆的长时程生成,使预测出的未来能够同时支持策略评估和有针对性的策略改进。 EnerVerse-AC(Jiang et al., 2025c)遵循了一个相关方向,并将世界模型表述为一个动作条件多视角生成器,使其既可以作为数据引擎,也可以作为机器人推理中的评估器。 Interactive World Simulator(Wang et al., 2026c)将这一方向从可控生成进一步推进到真正的交互式仿真,强调面向闭环展开、示范采集和策略评估的高频、长时程且稳定的策略条件交互。 EVA(Wang et al., 2026b)则从后训练对齐的角度补充了这一方向,它针对视觉上合理的展开与物理上可执行的机器人行为之间的可执行性差距,使用逆动力学奖励将视频世界模型与平滑且符合具身形态的动作序列对齐。
总体来看,这些工作标志着一个决定性的概念转变。 对于机器人视频世界模型而言,保真度越来越不仅仅由真实感来衡量,也由动作忠实性、可控交互能力,以及对闭环决策的有用性来衡量。
5.4 具有交互和几何先验的结构感知生成
一个密切相关的研究方向,是通过为交互引入更加丰富的中间结构来提升可控性。 这些方法并不是仅仅以低维动作序列作为条件,而是编码掩码、几何信息、视角信息或身份线索,从而更好地保留接触关系和场景结构。 其背后的基本直觉是:当模型被要求保留显式的交互结构,而不仅仅是合成视觉上令人信服的运动时,机器人视频生成会变得更加有用。
Mask2IV(Li et al., 2025a)很好地体现了这一思想。 它采用了一种两阶段设计:首先预测行为主体和物体的交互轨迹,然后以这些轨迹为条件生成视频。 这消除了对用户提供的密集掩码的需求,同时仍然保留了对交互结果的灵活控制能力。
TesserAct(Zhen et al., 2025)进一步推进了结构化建模,它将表示空间从 2D 视频扩展到一种覆盖 RGB、深度和法线信号的 4D 具身世界模型,从而提升空间一致性,并支持更强的逆动力学建模和策略学习。 RoboVIP(Wang et al., 2026a)关注现代策略学习器的一个实际需求,即时间上连贯的多视角观测。 它引入视觉身份提示来引导多视角视频扩散,并将生成的视频作为操作数据的可扩展增强。
这种结构感知视角也将机器人视频世界模型与更广泛的结构化和符号化世界建模路线联系起来。 上述方法是在生成的视觉未来中保留结构,而另一类方法则将世界抽象为谓词、物体关系、可供性或因果过程,并预测它们的转移,以用于规划(Liang et al., 2025c; Athalye et al., 2026; Liang et al., 2026)。 这些方法的目标并不是提升视觉保真度;相反,它们关注的是更加紧凑且可组合的预测变量,而这些变量可能与长时程推理和可执行控制更加对齐。 尽管这些方法在表示方式和目标上有所不同,但它们共享一个共同原则:更丰富的结构先验可以使生成的未来更加可控,在不同视角和接触关系中更加一致,并最终对下游具身学习更加有用。
5.5 从视频骨干网络到基础世界模型
最新的一些工作将机器人视频世界模型重新理解为通用交互式预测器,而这些预测器是通过适配大规模视频骨干网络构建出来的。 在这一范式中,视频生成不再仅仅是一个下游增强工具。 它变成了一种可复用的基础载体,用于仿真、规划、评估以及大规模机器人数据生产。
Vid2World(Huang et al., 2026)是这一转变的典型例子。 它并不是从零开始训练一个机器人世界模型,而是系统性地将一个预训练视频扩散模型转换为适合动作条件展开的交互式世界模型。 Genie Envisioner(Liao et al., 2026)将这一思想扩展为一个统一的世界基础平台,该平台将视频世界建模与动作解码结合起来,用于机器人操作。 DreamDojo(Gao et al., 2026a)通过在大规模人类第一视角视频上进行预训练,进一步推动了基础模型范式;它引入连续潜在动作,以连接无标注的人类交互和机器人控制,并随后针对目标具身形态对模型进行后训练。 它表明,这样的模型可以支持长时程实时展开、策略评估以及基于模型的规划。
WoW(Chi et al., 2025c)提出了一个互补性的观点。 它强调,物理直觉无法仅仅通过被动的视频观察获得,因此它转而在大量机器人交互轨迹上训练一个大型生成式世界模型。 通过将生成式展开与逆动力学和评价机制相结合,它显式地闭合了从想象到行动的循环。 在平台层面,UnifoLM-WMA-0(Unitree, 2025)和 Cosmos Predict 2.5(Ali et al., 2025)进一步体现了走向可复用世界骨干网络的趋势;而 GigaWorld-0(Team et al., 2025b)则通过将一个可控视频分支与一个具有物理基础的 3D 分支相结合,用于大规模具身数据合成,从而将数据引擎这一视角完全明确化。 ABot-PhysWorld(Chen et al., 2026d)将这一趋势进一步扩展到物理对齐的世界基础模型方向。 它明确面向物理上合理且动作可控的操作视频生成。
综合来看,这些工作表明该领域正在发生一个更广泛的转变。 机器人视频生成越来越不再被视为一个孤立的生成任务,而是被视为交互式世界建模的基础层
5.6 技术演进与开放挑战
综合来看,相关文献呈现出一条清晰的技术演进路线。 早期方法,例如 Dreamitate、RoboDreamer、DreMa、ManipDreamer、DreamGen 和 PhysWorld,主要将视频生成视为一种想象机制,用来为策略学习提供额外监督信号(Liang et al., 2024; Zhou et al., 2024; Barcellona et al., 2025; Li et al., 2025f; Jang et al., 2025a; Mao et al., 2025)。 下一波方法,包括 IRASim、RoboEnvision、RoboMaster、Ctrl-World、EnerVerse-AC、Interactive World Simulator 和 EVA,则将动作对齐、可控展开、交互可用性、可执行性以及评估用途作为核心目标(Zhu et al., 2025b; Yang et al., 2025; Fu et al., 2026; Guo et al., 2026b; Jiang et al., 2025c; Wang et al., 2026c,b)。 一条并行路线则通过掩码、几何信息和多视角身份线索引入更加丰富的交互结构,例如 Mask2IV、TesserAct 和 RoboVIP(Li et al., 2025a; Zhen et al., 2025; Wang et al., 2026a)。 最新系统,包括 Vid2World、Genie Envisioner、DreamDojo、WoW、ABot-PhysWorld、UnifoLM-WMA-0、Cosmos Predict 2.5 和 GigaWorld-0,则越来越多地将机器人视频生成提升为具身世界建模中的可复用基础层(Huang et al., 2026; Liao et al., 2026; Gao et al., 2026a; Chi et al., 2025c; Chen et al., 2026d; Unitree, 2025; Ali et al., 2025; Team et al., 2025b)。
这一演进过程也揭示了该领域的核心瓶颈。 关键挑战已经不再只是生成真实感强的未来。 真正的挑战在于生成这样的未来:它们能够与机器人动作保持因果对齐,在长时程内保持物理和运动学上的自洽,在不同视角和不同具身形态之间保持一致,在交互过程中保持稳定,并且具有足够的可执行性,能够支持真实的策略改进。 因此,对于机器人而言,视频生成的真正价值在于:将未来预测转化为感知与决策之间一个可控的、交互式的、可行动的接口。
6 世界模型在其他应用中的使用
6.1 用于导航的世界模型
世界模型已经成为具身导航中的一种有用抽象,因为在具身导航中,智能体必须在严重部分可观测的条件下行动,并且需要对尚未可见的空间、物体或路径进行推理。 这一研究路线并不是将导航视为一个纯反应式的下一步决策问题,而是在智能体实际移动之前,使用世界模型来想象以动作为条件的未来观测,构建具有未来感知能力的规划状态,或者从想象轨迹中推导出类似价值函数的信号(Koh et al., 2021; Bar et al., 2025; Huang et al., 2025b; Nie et al., 2025; Sharma et al.)。 从这个意义上说,世界模型将尚未看见的空间转化为一种预测性规划基础,用于推理未来可见性、可通行性以及目标推进程度(Koh et al., 2021; Bar et al., 2025)。
早期工作强调对未见观测进行前瞻式预测。 Pathdreamer 会为尚未访问过的室内视角生成合理的未来 360 ∘ 360^\circ 360∘ RGB、深度和语义观测,并表明使用想象观测进行规划,可以显著缩小与使用真实未来观测进行规划之间的差距(Koh et al., 2021)。 VISTA 提出了一种用于指令条件视觉想象的"想象并对齐"策略(Huang et al., 2025c),而 VISTAv2 则将其扩展为一种导航世界模型,该模型会在候选动作条件下展开第一视角未来,并将其投射到一个在线价值地图中用于规划(Huang et al., 2025b)。 一条并行趋势则将这一思想扩展为可控视频预测器:NWM 明确将可控视频生成表述为一种导航世界模型(Bar et al., 2025);SparseVideoNav 用稀疏未来生成来替代密集的长时程展开,以实现更快部署(Zhang et al., 2026);EgoWM 则通过轻量级条件化,将预训练的互联网规模视频扩散模型适配为动作条件的第一视角世界模型(Bagchi et al., 2026)。 综合来看,这些方法表明,世界模型在导航中的价值,与其说在于视觉真实感本身,不如说在于它能够以一种可用于规划、轨迹排序和价值估计的形式,揭示隐藏的未来结构。
6.2 用于自动驾驶的世界模型
同样,世界模型也已经成为自动驾驶中的一种重要范式,并且它们正在越来越多地统一感知、预测、规划和仿真。 与机器人操作相比,自动驾驶对长时程预测、多智能体交互、结构化几何以及安全关键型规划提出了更高要求。 因此,自动驾驶世界模型通常会学习随未来演化的场景表示,这些表示可以位于图像空间、多视角空间、占据空间或紧凑潜在空间中,并将其用于支持下游规划或端到端驾驶决策(Hu et al., 2022, 2023; Zheng et al., 2024; Wang et al., 2024b)。 早期且具有代表性的工作已经揭示了两条互补路线。 其中一条路线强调紧凑或结构化的预测状态:MILE 为城市驾驶学习一种带有几何归纳偏置的潜在动力学模型(Hu et al., 2022);而 OccWorld 则在 3D 占据空间中表述世界建模,使自车运动和场景演化能够以一种与规划兼容的形式表示出来(Zheng et al., 2024)。 另一条路线则更加明确地体现了生成式世界模型视角:GAIA-1 将驾驶世界建模表述为对视频、文本和动作 token 的多模态序列建模(Hu et al., 2023);而 DriveDreamer 则使用带有结构约束的扩散式建模,从真实驾驶数据中捕捉复杂交通演化过程(Wang et al., 2024a)。
近期工作进一步将这些方向推进到面向规划和统一驾驶智能的方向。 DriveWM 生成可控的多视角未来视频,并结合想象出来的多未来展开和基于图像的奖励,来选择更安全的轨迹(Wang et al., 2024b)。 UniDWM 进一步主张使用一种具有结构感知和动力学感知能力的潜在世界表示,作为感知、预测和规划的统一基础(Xiong et al., 2026)。 DriveWorld-VLA 通过将潜在世界状态作为规划器的决策状态,加强了世界建模与动作生成之间的联系,使动作条件想象能够在不进行昂贵像素级展开的情况下指导控制(Liu et al., 2026a)。 从规模化的角度来看,DriveVLA-W0 表明,通过世界建模进行未来图像预测可以提供密集的自监督信号,从而使端到端驾驶 VLA 的性能超越仅依赖低维动作监督的情况(Li et al., 2026c)。 进一步推进这种层级协同关系的是 SteerVLA(Gao et al., 2026b),它在概念上将高层 VLM 表述为一种语义世界模型,用来生成细粒度的常识推理,从而引导低层 VLA 策略完成复杂的长尾驾驶动作。 总体来看,自动驾驶中的世界模型最好被理解为一座从被动场景理解通向预测性驾驶智能的桥梁(Hu et al., 2023; Wang et al., 2024b; Xiong et al., 2026):有些方法将其用作未来场景的可控模拟器,有些方法将其用作规划所需的结构化状态空间,还有一些方法将其用作密集预测监督,以扩展端到端驾驶策略(Zheng et al., 2024; Li et al., 2026c)。 在这些不同变体中,共同直觉是相同的:安全驾驶不仅需要识别当前场景,还需要推理该场景会如何在自车行为和周围交通动态的共同作用下发生演化(Hu et al., 2022; Wang et al., 2024a; Xiong et al., 2026)。