前言
随着 harness 的完善,Agent 的启动过程正在从"输入任务后直接执行",逐渐变成"先完成一组初始化动作,再进入任务"。
常见初始化内容包括:
- 个人记忆、协作偏好、输出风格
- 项目背景、目录结构、技术栈、历史约定
- 团队规范、工作流、提交和评审规则
- 工具说明、MCP 配置、常用命令
- 特定任务类型依赖的 skills / agents
这些内容大多不是一次性信息。它们变化不频繁,却会在每个新会话里反复出现。
问题也就集中在这里:
- 重复:相同初始化内容在多个会话中反复执行。
- 耗时:每次启动都要等待加载和确认。
- 不稳定:步骤越多,越容易漏读、乱序或加载不完整。
当 Agent 使用越来越依赖记忆、项目上下文和工具体系后,初始化本身就变成了一个需要工程化处理的问题。
解决思路:复用稳定初始化
一次 Agent 任务可以拆成两部分:
- 稳定初始化:记忆、规则、项目背景、工具、skills。
- 具体任务:本次真正要做的分析、开发、写作或排查。
基座工程关注的是第一部分。
如果某些内容满足下面三个条件,就不应该每次都重新初始化:
- 相对稳定
- 高频使用
- 启动时必需
更合理的方式是:先让 Agent 完成一次稳定初始化,把这个状态保存成基座;之后每个新任务都从这个基座派生。
可以把它理解成下面这条链路:
markdown
记忆 / 规则 / 项目上下文 / skills
│
▼
生成基座会话
│
▼
每次新对话,都 fork 基座会话
│
▼
执行具体任务需要注意:基座复用优化的是初始化过程,不是让上下文内容本身消失。初始化内容仍然会成为会话状态的一部分。
实现方式:给 Codex 包一层启动器
要把这个思路落地,关键不是直接改 Codex 本身,而是在 Codex CLI 外面包一层启动器。
原因很简单:如果用户每次都直接执行 codex,启动前后没有地方插入自己的逻辑。我们无法在启动前判断基座是否过期,也无法自动决定应该生成基座、复用基座,还是从某个指定基座 fork。
所以需要一个自己的入口,负责在调用 Codex 之前先做一层调度。
在我的本地实现里,这个入口叫 cx。它不是新的 Agent,也不是 Codex 的替代品,只是 Codex CLI 外面的一层启动器:
用户输入 cx
│
▼
cx 启动器:检查基座 registry、必要时刷新、解析别名
│
▼
基于基座会话,派生新的工作会话,以免污染基座
│
▼
进入真正的 Codex 任务会话使用案例
下面举个具体的个人使用的例子。我的 harness 工程首轮对话会加载许多记忆、技能等,每次 codex 耗时约 30s,使用该方案就可以跳过这部分,从而直接聚焦于具体问题。
默认情况下,直接执行 cx,会从 memory 记忆基座派生新会话:
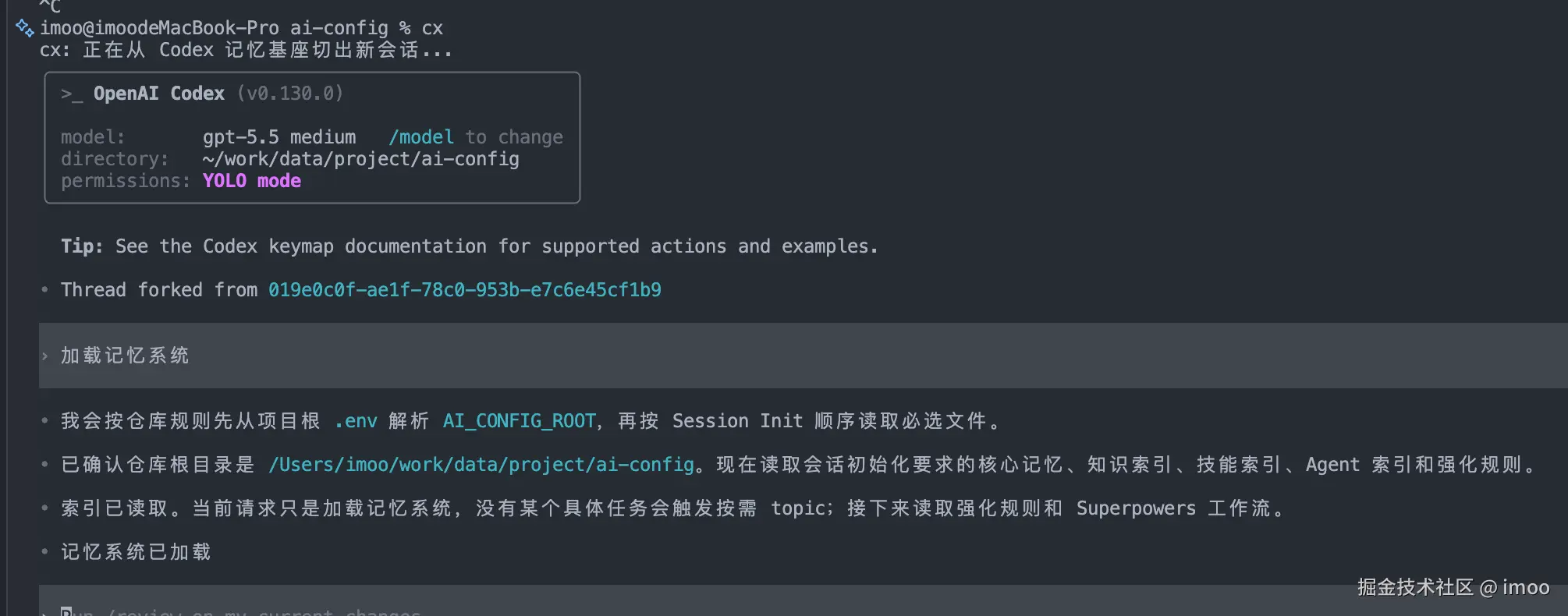
如果记忆相关的文件更新的情况下,则会通过文件哈希校验自动更新基座:
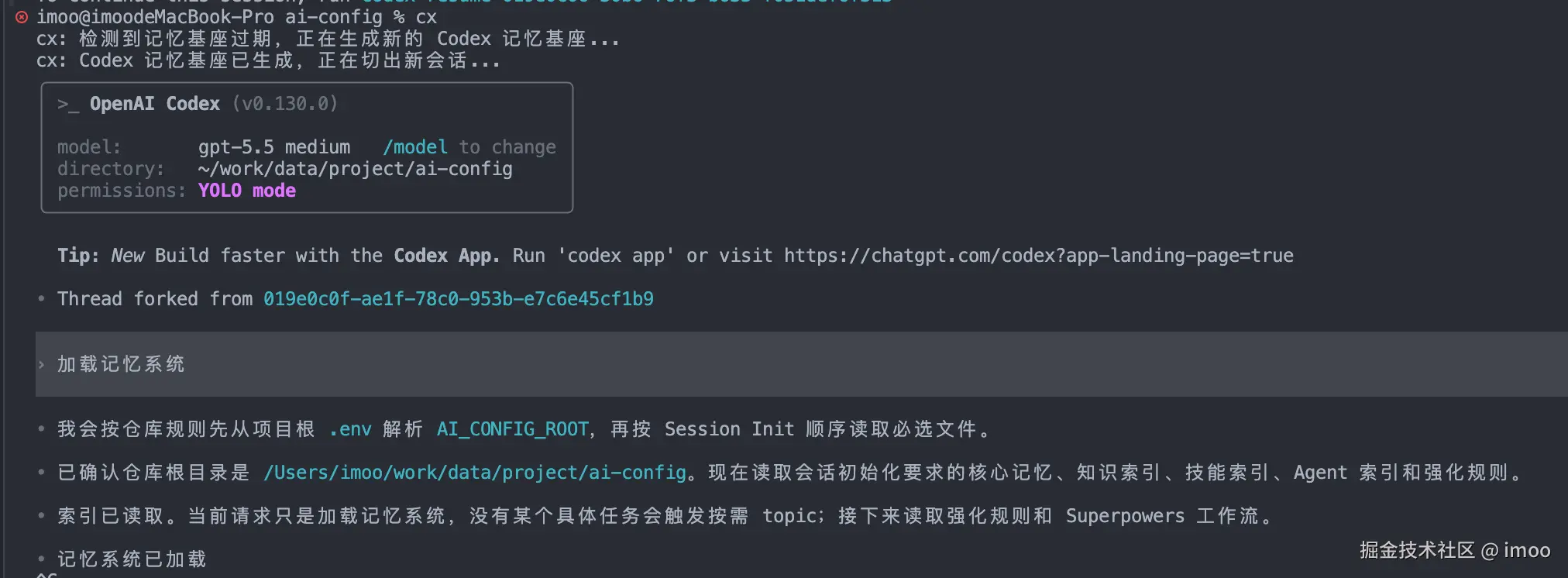
除此之外,我还添加了一套基座的管理命令,主要用于管理各个开发项目的上下文基座。
csharp
cx -add <session-id> <别名> # 把某个已有 Codex 会话登记为基座
cx -list # 查看当前登记的基座
cx -load <别名|session-id> # 从指定基座 fork 新会话
cx -remove <别名> # 删除手动登记的基座默认基座:memory
当前实现里,memory 是默认基座。用户不指定 -load 时,都会走它。
memory 基座是托管基座:
- 没有本机状态时,首次执行
cx会自动生成。 - 关键初始化资产变化时,会自动刷新。
- 它不能通过
-remove memory删除,避免默认启动链路被误删。
机器 B 第一次使用时不需要从机器 A 复制 state。只要 repo 里的基座定义还在,执行 cx 时就会在机器 B 上重新生成自己的 memory 基座。
手动基座:通过别名管理
除了默认 memory,还可以把某次已有 Codex 对话登记成一个手动基座。
这类基座适合临时复用某个已经加载过上下文的会话,比如某个项目、某类排查现场或某次专项分析。
不过它和 memory 不一样:手动基座记录的是本机 Codex session id,本质上是本机状态,换机器后不能自动恢复。
所以可以把基座分成两类:
| 类型 | 生成方式 | 是否可跨机器自动恢复 | 适合场景 |
|---|---|---|---|
memory 默认基座 |
根据 repo 里的记忆和规则自动生成 | 可以重新生成 | 长期稳定初始化 |
| 手动基座 | cx -add <session-id> <别名> |
不可以,需要重新登记 | 临时项目现场、专项上下文 |
资产指纹:判断 memory 是否过期
对于默认 memory 基座,启动器会跟踪一组关键初始化资产。
ini
const KEY_FILES = [
"src/brain/claude.md",
"src/brain/knowledge/claude.md",
"src/config/skills/claude.md",
"src/config/agents/claude.md",
"src/brain/knowledge/reinforced-rules.md",
"src/brain/knowledge/workflow-superpowers.md",
];这些文件决定了 Agent 启动后要加载哪些记忆、遵守哪些规则、知道哪些 skills / agents。
启动器会对它们计算 hash,并合成一个整体指纹:
csharp
function computeFingerprint(root) {
const lines = KEY_FILES.map(file => {
const content = fs.readFileSync(path.join(root, file));
return sha256(content) + " " + file;
});
return sha256(lines.join("\n"));
}指纹没变,说明 memory 基座仍然可用。
指纹变了,说明记忆、规则或 skill 索引发生变化,需要重新生成 memory 基座。
哪些内容适合被基座化
适合进入基座的内容,通常满足三个条件:
- 稳定:变化频率低。
- 高频:多个任务都会用到。
- 必要:缺失后会明显影响执行质量。
常见基座类型:
| 类型 | 适合放入的内容 |
|---|---|
| 个人基座 | 长期记忆、协作偏好、输出风格、常用工作习惯 |
| 项目基座 | 项目背景、目录结构、技术栈、常用命令、开发约定 |
不适合进入基座的内容也要明确:
- 单次任务里的临时信息
- 尚未确认的推测
- 变化频繁的业务细节
- 只对当前会话有价值的过程记录
简单判断标准是:如果一段内容下次大概率还会用到,并且启动时就需要知道,它就有机会被基座化。