Normal Forms for Grammars
Normal Forms for Grammars
文法的范式(Normal Forms)
It is usually easier to work with a context-free language when the grammar is in a normal form.
当一个上下文无关文法被化为某种范式时,处理该语言通常更容易。
A grammar is in normal form if its production rules follow a special restricted structure.
若文法的产生式满足某种受限结构,就称该文法处于范式。
Chomsky Normal Form (CNF): productions have form A → BC or A → a.
乔姆斯基层范式(CNF):产生式形如 A → BC 或 A → a。
Greibach Normal Form (GNF): productions have form A → aα, where α ∈ V*.
Greibach 范式(GNF):产生式形如 A → aα,其中 α ∈ V*。
If ε is in the language, allow S → ε, and require S not to appear on the right-hand side of any rule.
若语言包含 ε,可允许 S → ε,并要求 S 不出现在任何规则右侧。

Eliminating ε-productions (Motivation)
Eliminating ε-productions
消除 ε-产生式
We often want intermediate strings in derivations not to be much longer than the final derived string.
我们通常希望推导过程中的中间串不要明显长于最终串。
But ε-productions A → ε can make long intermediate strings shrink suddenly.
但 ε-产生式 A → ε 会让很长的中间串突然缩短。
So a natural question is: can we rewrite the grammar without ε-productions?
因此自然问题是:能否改写文法,使其不含 ε-产生式?
分析(在讲什么):
这页给动机:ε-规则会让推导长度"虚高",不利于复杂度分析与规范化处理,所以要系统消除。
Eliminating ε-production (Problem Statement)
Eliminating ε-production --- The Problem
消除 ε-产生式------问题定义
Given grammar G, construct an equivalent grammar G′ such that L(G)=L(G′).
给定文法 G,构造等价文法 G′,使 L(G)=L(G′)。
Require G′ to have no rules of form A → ε, except possibly S → ε.
要求 G′ 不含 A → ε 形式规则(可能保留 S → ε 例外)。
Also require S not to appear on the right-hand side of any production.
同时要求开始符号 S 不出现在任何产生式右侧。
Reason: if S appears on RHS and S → ε exists, long intermediate strings can still collapse undesirably.
原因:若 S 出现在右侧且有 S → ε,仍可能出现中间串过长再塌缩的问题。
Nullable Variables
Nullable Variables
可空变量(Nullable Variables)
Definition: variable A is nullable if A ⇒* ε.
定义:若 A ⇒* ε,则称变量 A 是可空的。
从文法的非终结符 A 出发,经过零步或多步推导,可以得到空串 ε。
满足这个条件的变量 A 就叫做可空的(nullable)------"可空"= 能一路展开成什么都没有。
⇒¹(或一步):用一条产生式走一步。
⇒ⁿ:走 n 步。
⇒*:走 0 步、1 步、2 步......任意有限步 都可以。
How to detect nullables:
如何判断可空变量:
If A → ε is a production, then A is nullable.
若 A → ε 是规则,则 A 可空。
If A → B₁B₂...Bₖ and every Bᵢ is nullable, then A is nullable.
若 A → B₁B₂...Bₖ 且每个 Bᵢ 都可空,则 A 可空。
Use a fixed-point procedure: keep propagating nullable labels until no new variable becomes nullable.
采用不动点算法:反复传播"可空"标记,直到集合不再变化。
消 ε 的核心预处理步骤就是先找全体 nullable。这个集合直接决定后面"哪些符号可删、可替换成 ε"。
Using nullable variables --- Initial ideas
使用可空变量------初步思路
For each variable A in G, create corresponding A in G′ so that A derives exactly the same non-empty strings.
对 G 中每个变量 A,在 G′ 中保留对应 A,使其推导能力与原来一致(但关注非空串)。
If a rule is B → CAD and A is nullable, add alternatives that either keep or drop nullable A.
若有规则 B → CAD 且 A 可空,就加入"保留 A"与"删除 A"的候选规则。
Example alternatives include B → CAD and B → CD.
例如可同时保留 B → CAD 与新增 B → CD。
这页讲"组合展开"思想:nullable 变量在右侧出现时,可选"在派生里消失"或"保留",所以要把这些选择显式写成新规则。

Eliminating ε-productions: Algorithm
The Algorithm
算法
Create G′ with the same variables as G, plus a new start symbol S′.
构造 G′:变量与 G 基本相同,但新增开始符号 S′。
For each rule A → X₁X₂...Xₖ in G, generate rules A → α₁α₂...αₖ.
对 G 中每条 A → X₁X₂...Xₖ,生成 A → α₁α₂...αₖ 的候选规则。
If Xᵢ is non-nullable (or terminal), then αᵢ = Xᵢ.
若 Xᵢ 不可空(或为终结符),则 αᵢ = Xᵢ。
If Xᵢ is nullable, αᵢ can be Xᵢ or ε.
若 Xᵢ 可空,则 αᵢ 可取 Xᵢ 或 ε。
Keep only candidates where not all αᵢ are ε.
保留时要求不能所有 αᵢ 都是 ε(避免无意义全空右侧)。
Add S′ → S, and if S is nullable in G, also add S′ → ε.
加入 S′ → S;若 S 在 G 中可空,再加入 S′ → ε。
这是可直接写代码/手算的标准算法页。核心是"枚举 nullable 位点的保留/删除组合",再用新开始符号处理 ε 的保留边界情况。

Eliminating ε-productions: Example
Eliminating ε-productions --- An Example
消除 ε-产生式------例子
Given grammar:
给定文法:
S → AB
A → AaA | ε
B → BbB | ε
First compute nullables (here A and B are nullable, and therefore S is nullable via S→AB).
先求可空变量(此处 A、B 可空,且由 S→AB 可知 S 也可空)。
Then generate equivalent non-ε productions by keeping/dropping nullable symbols in each rule.
然后在每条规则中对可空符号做"保留/删除"组合,生成等价的非 ε 规则。
Finally handle start symbol using S′ → S (and S′ → ε if needed).
最后用 S′ → S(必要时加 S′ → ε)处理开始符号。
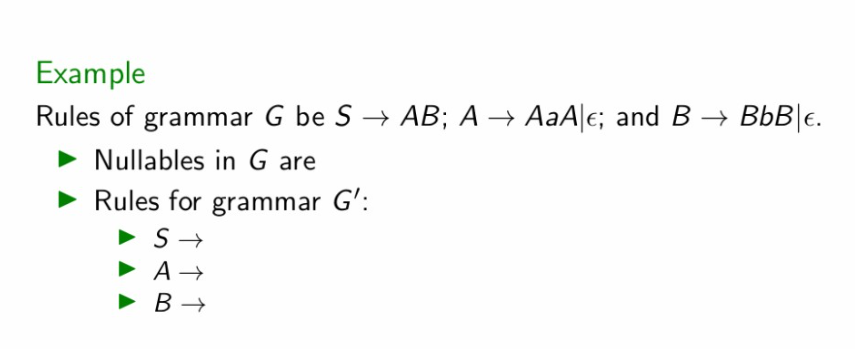
Eliminating Unit Productions
Eliminating Unit Productions
消除单元产生式(Unit Productions)
A unit production has form A → B where B is a non-terminal.
单元产生式指 A → B,其中 B 是非终结符。
A → a is not a unit production.
A → a 不是单元产生式。
Long chains of unit productions can add many derivation steps without real progress.
单元链会增加很多推导步数,却几乎不产生终结符进展。
Goal: given G, produce equivalent G′ with no rules of form A → B (B ∈ V′).
目标:给定 G,构造等价 G′,使其不再含 A → B(B ∈ V′)类型规则。
这页把"第二类冗余规则"拿出来处理。去 unit 和去 ε 一样,都是为让文法更规范、推导更高效。
Role of Unit Productions
Role of Unit Productions
单元产生式的作用
Unit productions can be useful in grammar design, e.g., S′ → S introduced during ε-elimination.
单元产生式在文法设计中有实际用途,比如去 ε 时引入的 S′ → S。
They also appear in layered unambiguous expression grammars (e.g., E→T, T→F, F→I/N).
它们也常出现在分层表达式文法中(如 E→T, T→F, F→I/N)。
Even so, they can be eliminated safely while preserving language equivalence.
即便如此,仍可在保持语言等价的前提下安全消除它们。

Eliminating Unit Productions: Basic Idea
Basic Idea
基本思路
Replace unit productions by look-ahead shortcuts to the eventual non-unit productions they can reach.
把单元产生式替换为"前看直达"规则,直接到达最终可到达的非单元产生式。
Example chain: E → T → F → I → a|b|Ia|Ib, so add direct rules E → a|b|Ia|Ib.
示例链:E → T → F → I → a|b|Ia|Ib,因此可添加直达规则 E → a|b|Ia|Ib。
However, unit-production cycles (e.g., A→B, B→C, C→A) break naive look-ahead and may cause infinite loops.
但若存在 unit 环(如 A→B, B→C, C→A),朴素前看会陷入无限循环。

Eliminating Unit Productions: Algorithm
The Algorithm
算法
Step 1: Compute unit pairs ⟨A,B⟩ such that A ⇒*_u B using only unit productions.
步骤 1:计算 unit pair ⟨A,B⟩,满足 A 仅通过 unit 规则可推出 B(A ⇒*_u B)。
A practical method is graph reachability: nodes are variables, edges are unit productions.
实用做法是图可达:点为变量,边为 unit 规则。
Step 2: For each unit pair ⟨A,B⟩, add to A all non-unit productions of B.
步骤 2:对每个 unit pair ⟨A,B⟩,把 B 的所有非 unit 规则复制给 A。
Step 3: Remove all unit productions.
步骤 3:删除所有 unit 规则。
Resulting grammar G′ satisfies L(G′)=L(G).
所得文法 G′ 满足 L(G′)=L(G)。
分析(在讲什么):
这是去 unit 的标准闭包算法,考试高频:
1)先求 unit 可达闭包;
2)再拷贝非 unit 规则;
3)最后删除 unit 边。
本质是"把沿 unit 链才能拿到的实质规则提前展开"。

Eliminating Unit Productions: Algorithm (Recap)
The Algorithm (recap)
算法(回顾)
Compute all unit pairs ⟨A,B⟩ using unit-only reachability, copy B's non-unit rules to A, then delete all unit rules.
先计算所有 unit pair ⟨A,B⟩(仅 unit 规则可达),再把 B 的非 unit 规则拷贝给 A,最后删除全部 unit 规则。
The resulting grammar G′ remains language-equivalent: L(G′)=L(G).
得到的文法 G′ 与原文法语言等价:L(G′)=L(G)。
Correctness Proof: L(G′) ⊆ L(G)
Correctness Proof --- L(G′) ⊆ L(G)
正确性证明------L(G′) ⊆ L(G)
For every rule A → w in G′, there is a derivation in G from A to w via zero or more unit steps followed by one non-unit step.
对 G′ 中每条 A → w,都可在 G 中通过"若干 unit 步 + 一次非 unit 步"从 A 推导到 w。
So every derivation in G′ can be simulated in G, implying L(G′) ⊆ L(G).
因此 G′ 的每个推导都可被 G 模拟,从而得到 L(G′) ⊆ L(G)。
Correctness Proof: L(G) ⊆ L(G′)
Correctness Proof --- L(G) ⊆ L(G′)
正确性证明------L(G) ⊆ L(G′)
Take any w ∈ L(G) and consider a leftmost derivation in G.
任取 w ∈ L(G),考虑其在 G 中的最左推导。
Group derivation into big-steps: zero or more unit steps on the leftmost variable, then one non-unit step.
把推导分成"宏步":对最左变量先做若干 unit 步,再做一次非 unit 步。
Each such big-step is a single rule in G′, so the whole derivation is reproducible in G′.
每个宏步在 G′ 中都对应一条规则,因此整条推导可在 G′ 中复现。
Hence L(G) ⊆ L(G′).
故 L(G) ⊆ L(G′)。

Eliminating Useless Symbols (Motivation)
Eliminating Useless Symbols
消除无用符号
We prefer compact grammars with as few variables as possible.
我们希望文法尽量紧凑,变量尽量少。
A grammar may contain useless variables that never participate in any valid derivation of terminal strings.
文法可能包含无用变量,它们不会出现在任何有效终结符推导中。
We can identify and remove them, though other redundancies may still remain.
这些变量可以被识别并移除,但文法中可能仍有其他冗余。
Useless Symbols: Definition
Useless Symbols --- Definition
无用符号------定义
A symbol X ∈ V ∪ Σ is useless if there is no derivation S ⇒* αXβ ⇒* w with w ∈ Σ*.
若不存在推导 S ⇒* αXβ ⇒* w(w ∈ Σ*),则符号 X ∈ V ∪ Σ 是无用的。
Removing useless symbols (and associated rules) does not change the generated language.
删除无用符号(及相关规则)不会改变文法生成语言。

Revisiting Useless Symbols
Revisiting Useless Symbols
再看无用符号
X is useless iff either it is not reachable from S, or it cannot contribute to terminal-string generation in context.
X 无用当且仅当:要么它从 S 不可达;要么它无法在上下文中导出终结符串。
Type 1: not reachable.
类型 1:不可达(not reachable)。
Type 2a: not generating (X ⇒* w for no w ∈ Σ*).
类型 2a:不生成(不存在 X ⇒* w,w ∈ Σ*)。
Type 2b: appears only in sentential forms that contain other non-generating symbols.
类型 2b:只出现在含有其他不生成符号的句型环境中。
分析(在讲什么):
这页把 useless 拆成可操作子类。实做算法时会先处理 generating,再处理 reachable,正是对应这些类型。

Algorithm to Remove Useless Symbols
Algorithm to Remove Useless Symbols
去除无用符号算法
Step 1: remove all non-generating symbols.
步骤 1:先删掉所有不生成符号。
Step 2: in the resulting grammar, remove all unreachable symbols.
步骤 2:在新文法中,再删掉所有不可达符号。
This order removes both originally unreachable symbols and symbols that become unreachable after step 1.
这个顺序既能删原本不可达的,也能删第 1 步后新变不可达的符号。
分析(在讲什么):
顺序是关键:先 generating,后 reachable。反过来可能保留本应删除的噪声结构。属于 quiz 常考"为什么按这个顺序"。
Generating and Reachable Symbols
Generating and Reachable Symbols
可生成与可达符号
Generating:
可生成:
If A → x with x ∈ Σ*, then A is generating.
若 A → x 且 x ∈ Σ*,则 A 是可生成的。
If A → γ and all variables in γ are generating, then A is generating.
若 A → γ 且 γ 中所有变量可生成,则 A 也可生成。
Reachable:
可达:
S is reachable.
S 是可达的。
If A is reachable and A → αBβ, then B is reachable.
若 A 可达且有 A → αBβ,则 B 可达。
Both can be computed by fixed-point propagation.
两者都可用不动点传播算法计算。
The Three Simplifications Together
The Three Simplifications, Together
三种简化合并使用
For grammar G with non-empty language, we can build equivalent G′ with:
对语言非空的文法 G,可构造等价 G′,满足:
No ε-productions (except possibly S → ε), no unit productions, and no useless symbols.
无 ε-产生式(可能保留 S → ε)、无 unit 产生式、无无用符号。
S does not appear on the RHS of rules.
且 S 不出现在规则右侧。
Apply steps in this order:
按以下顺序执行:
-
eliminate ε-productions
1)去 ε-产生式
-
eliminate unit productions
2)去 unit 产生式
-
eliminate useless symbols
3)去无用符号
Different order may fail to satisfy all desired properties.
若顺序改变,可能无法同时满足全部目标性质。
Chomsky Normal Form (Refined Proposition)
Chomsky Normal Form
乔姆斯基层范式
For every non-empty CFL L, there exists grammar G with L(G)=L and each rule in one of forms:
对每个非空 CFL L,存在文法 G 使 L(G)=L,且每条规则属于以下形式:
A → a, or A → BC (B and C not start symbol), or S → ε (iff ε ∈ L).
A → a,或 A → BC(B、C 不是开始符号),或 S → ε(当且仅当 ε ∈ L)。
Furthermore, G has no useless symbols.
此外,G 不含无用符号。
Outline of Normalization to CNF
Outline of Normalization
归一化流程概览
Given G=(V,Σ,S,P), first obtain G′ by eliminating ε-productions, unit productions, and useless symbols.
给定 G=(V,Σ,S,P),先得到 G′:去 ε、去 unit、去 useless。
In G′, rules with RHS length 0 or 1 are already in valid CNF forms (with start/terminal constraints).
在 G′ 中,右侧长度为 0 或 1 的规则已满足 CNF 合法形式(含开始符号/终结符约束)。
Remaining long rules A → X₁X₂...Xₙ (n≥2) are transformed in two steps:
剩余长规则 A → X₁X₂...Xₙ(n≥2)再做两步变换:
-
make RHS contain only variables
1)右侧先全变量化
-
make RHS length exactly 2
2)右侧二元化(长度化为 2)
Make RHS Consist Only of Variables
Make the RHS consist only of variables
让右侧只包含变量
For rule A → X₁X₂...Xₙ where some Xᵢ are terminals, introduce new variables for terminals.
对规则 A → X₁X₂...Xₙ(若有终结符),给每个终结符引入新变量。
For each terminal a, add variable X_a and rule X_a → a.
对每个终结符 a,新建 X_a 并加入规则 X_a → a。
Then replace each terminal occurrence in long RHS by its variable proxy X_a.
再把长右侧中出现的终结符 a 全部替换为 X_a。
Make RHS Length 2
Make the RHS be of length 2
让右侧长度变为 2
After terminal replacement, remaining long rules look like A → B₁B₂...Bₙ with n > 2.
终结符替换后,剩余长规则形如 A → B₁B₂...Bₙ(n > 2)。
Introduce new helper variables to binarize:
引入新的辅助变量进行二元化:
A → B₁B_(2,n), B_(2,n) → B₂B_(3,n), ..., B_(n−1,n) → B_(n−1)Bₙ.
A → B₁B_(2,n), B_(2,n) → B₂B_(3,n), ..., B_(n−1,n) → B_(n−1)Bₙ。
Now every long rule is replaced by binary rules only.
这样每条长规则都被替换为纯二元规则。
CNF Conversion Example
An Example
一个例子
Convert grammar
把文法
S → aA | bB | b, A → Baa | ba, B → bAAb | ab
into Chomsky Normal Form by three stages:
转换为 CNF,分三步:
-
eliminate ε-productions, unit productions, useless symbols (already satisfied here)
1)先去 ε、去 unit、去 useless(此例已基本满足)
-
replace terminals in long RHS via X_a → a, X_b → b
2)对长右侧做终结符变量替换(如 X_a → a, X_b → b)
-
binarize long RHS using new variables (e.g., X_aa, X_AAb)
3)用新变量把长右侧二元化(如 X_aa、X_AAb)