---
tags:
- translation
- hy-mt
- quant
- 1.25bit
- sherry
- gguf
language:
- multilingual
base_model:
- AngelSlim/Hy-MT1.5-1.8B-1.25bit
---
<p align="center">
<picture>
<source media="(prefers-color-scheme: dark)" srcset="https://github.com/Tencent/AngelSlim/blob/main/docs/source/assets/logos/angelslim_logo_light.png?raw=true">
<img alt="AngelSlim" src="https://github.com/Tencent/AngelSlim/blob/main/docs/source/assets/logos/angelslim_logo.png?raw=true" width=55%>
</picture>
</p>
<h3 align="center">
Dedicated to building a more intuitive, comprehensive, and efficient LLMs compression toolkit.
</h3>
<p align="center">
📱 <a href="https://huggingface.co/AngelSlim/Hy-MT1.5-1.8B-2bit-GGUF/resolve/main/Hy-MT-demo.apk?download=true">Android Demo</a> |
📣 <a href="https://huggingface.co/AngelSlim/Hy-MT1.5-1.8B-1.25bit">Weights</a> |
✒️ <a href="https://arxiv.org/abs/2601.07892">Sherry Paper (ACL 2026)</a> |
📖 <a href="https://angelslim.readthedocs.io/">Documentation</a> |
🤗 <a href="https://huggingface.co/AngelSlim">AngelSlim</a> |
💬 <a href="https://github.com/Tencent/AngelSlim/blob/main/docs/source/assets/angel_slim_wechat.png?raw=true">WeChat</a>
<br>
</p>
<p align="center">
<img src="https://github.com/Tencent/AngelSlim/blob/main/docs/source/assets/HYMT1.5/model_scores.png?raw=true" alt="model_scores" width="80%">
<br>
<em>Hy-MT1.5-1.8B translation quality scores. Source: <a href="https://arxiv.org/abs/2512.24092">HY-MT1.5 Technical Report</a></em>
</p>
## 📣 Latest News
- [26/05/08] **We have released STQ1_0 kernel for 1.25-bit model** and given a PR to llama.cpp [PR #22836](https://github.com/ggml-org/llama.cpp/pull/22836) ! If you have any questions or suggestions for STQ_0, welcome to comment under the PR !🔥🔥🔥
- [26/04/29] We have released **Hy-MT1.5-1.8B-2bit (574MB)** and **Hy-MT1.5-1.8B-1.25bit (440MB)**, on-device translation models supporting 33 languages, with both weights and GGUF formats available. We also have made an [Android Demo](https://huggingface.co/AngelSlim/Hy-MT1.5-1.8B-2bit-GGUF/resolve/main/Hy-MT-demo.apk?download=true) for you to try out. We invite you to give it a spin! 🔥🔥🔥
- [26/02/09] We have released HY-1.8B-2Bit, 2-bit on-device large language model.
- [26/01/13] We have released v0.3. We support the training and deployment of Eagle3 for all-scale LLMs/VLMs/Audio models. And we released **Sherry**, the hardware-efficient 1.25-bit quantization algorithm [[Paper]](https://arxiv.org/abs/2601.07892) | [[Code]](https://github.com/Tencent/AngelSlim/tree/sherry/Sherry)
For more detailed information, please refer to [[AngelSlim]](https://github.com/Tencent/AngelSlim) and [[HY-MT]](https://github.com/Tencent-Hunyuan/HY-MT)
## 🌟 Hy-MT1.5-1.8B-1.25bit-GGUF Key Features
- **World-Class Translation Quality** Hy-MT1.5-1.8B-1.25bit is built upon the Hy-MT1.5-1.8B foundation model, a specialized translation model developed by Tencent Hunyuan Team through a holistic multi-stage training pipeline integrating MT-oriented pre-training, supervised fine-tuning, on-policy distillation, and reinforcement learning. The base model natively supports **33 languages**, **5 dialects/minority languages**, and **1,056 translation directions**. With only 1.8B parameters, it comprehensively outperforms much larger open-source models (e.g., Tower-Plus-72B, Qwen3-32B) and mainstream commercial translation APIs (e.g., Microsoft Translator, Doubao Translator). For full details, please refer to the [HY-MT1.5-1.8B](https://huggingface.co/tencent/HY-MT1.5-1.8B) and [HY-MT1.5 Technical Report](https://arxiv.org/abs/2512.24092).
- **Sherry: Extreme 1.25-bit Quantization** This model employs [**Sherry**](https://arxiv.org/abs/2601.07892) (accepted at **ACL 2026**), a hardware-efficient ternary quantization framework. Sherry introduces a **3:4 fine-grained sparsity** strategy: for every 4 model weights, the 3 most important are stored in 1-bit ({-1, +1}), while the remaining 1 is zeroed out. This packs 4 weights into just 5 bits, achieving an effective **1.25-bit** width with power-of-two alignment, compressing the original 3.3GB FP16 model to just **440MB**, with minimal accuracy loss.
<p align="center">
<img src="https://github.com/Tencent/AngelSlim/blob/main/docs/source/assets/HYMT1.5/Sherry.png?raw=true" alt="Sherry" width="80%">
<br>
<em>Sherry fine-grained sparsity: for every 4 weights, the 3 most important are stored in 1-bit, and the remaining 1 is zeroed out.</em>
</p>
- **On-Device Deployment for the Most Phones** Paired with our custom **STQ kernel** designed specifically for mobile CPUs, the 1.25-bit model achieves perfect SIMD instruction set alignment. This means even ordinary phones with limited memory can run high-quality offline translation smoothly. No internet connection required, and your data never leaves the device.
## 📈 Translation Benchmarks
Performance comparison of different model sizes on the Flores-200 Chinese-Foreign mutual translation benchmark:
<p align="center">
<img src="https://github.com/Tencent/AngelSlim/blob/main/docs/source/assets/HYMT1.5/flores_model_size.png?raw=true" alt="flores_model_size" width="80%">
<br>
<em>Performance of different model sizes on the Flores-200 Chinese-Foreign mutual translation benchmark.</em>
</p>
## ⚡ Speed Demo
FP16 (8x speed) vs. 1.25-bit speed comparison.
<p align="center">
<img src="https://github.com/Tencent/AngelSlim/blob/main/docs/source/assets/HYMT1.5/fp16vs1.25bit.gif?raw=true" alt="fp16_vs_1.25bit" width="60%">
<br>
<em> Demo device: Snapdragon 888, 8GB RAM.</em>
</p>
## 📱 Demo
We provide a ready-to-use Android demo APK for offline translation. The app features a **background word extraction mode** that works across any app on your phone --- browse emails, webpages, or chat messages and get instant translations without switching apps. No network required, no data collection, one-time download for permanent use.
**Download Demo:**
https://huggingface.co/AngelSlim/Hy-MT1.5-1.8B-1.25bit-GGUF/resolve/main/Hy-MT-demo.apk
### Translation Demo
<p align="center">
<img src="https://github.com/Tencent/AngelSlim/blob/main/docs/source/assets/HYMT1.5/app_demo.gif?raw=true" alt="app_demo" width="40%">
<br>
<em>Demo device: Snapdragon 865, 8GB RAM.</em>
</p>
### Background Word Extraction Mode
<p align="center">
<img src="https://github.com/Tencent/AngelSlim/blob/main/docs/source/assets/HYMT1.5/demo2.gif?raw=true" alt="demo2" width="40%">
<br>
<em>Demo device: Snapdragon 7+ Gen 2, 16GB RAM.</em>
</p>
## 💻 Deployment
**❕❕ This gguf depends on our STQ kernel, which is released at [PR #22836](https://github.com/ggml-org/llama.cpp/pull/22836).**
### Clone llama.cpp
```bash
git clone https://github.com/ggml-org/llama.cpp.git
```
### Enter the llama.cpp folder
```bash
cd llama.cpp
```
### Fetch and check out the PR branch
```bash
git fetch origin pull/22836/head:pr-22836-stq_0
git checkout pr-22836-stq_0
```
### Build llama.cpp
```bash
cmake -B build
cmake --build build --config Release
```
### Download the GGUF model
```bash
pip install huggingface_hub
huggingface-cli download AngelSlim/Hy-MT1.5-1.8B-1.25bit-GGUF \
--local-dir model_zoo/Hy-MT1.5-1.8B-1.25bit-GGUF
```
### Run a completion example
The prompt format can be viewed at [HY-MT1.5-1.8B](https://huggingface.co/tencent/HY-MT1.5-1.8B)
```bash
./build/bin/llama-completion \
--model model_zoo/Hy-MT1.5-1.8B-1.25bit-GGUF/Hy-MT1.5-1.8B-1.25bit.gguf \
-p "Translate the following segment into Chinese, without additional explanation:Hello" \
--jinja \
-ngl 0 \
-n 64 -st
```
### Run the llama.cpp benchmark
```bash
./build/bin/llama-bench -m model_zoo/Hy-MT1.5-1.8B-1.25bit-GGUF/Hy-MT1.5-1.8B-1.25bit.gguf -ngl 0
```
## 📥 Download Links
- 1.25-bit model weights: https://huggingface.co/AngelSlim/Hy-MT1.5-1.8B-1.25bit
- 1.25-bit model GGUF: https://huggingface.co/AngelSlim/Hy-MT1.5-1.8B-1.25bit-GGUF
- 2-bit model weights: https://huggingface.co/AngelSlim/Hy-MT1.5-1.8B-2bit
- 2-bit model GGUF: https://huggingface.co/AngelSlim/Hy-MT1.5-1.8B-2bit-GGUF
- Demo APK: https://huggingface.co/AngelSlim/Hy-MT1.5-1.8B-1.25bit-GGUF/resolve/main/Hy-MT-demo.apk
## 📄 Technical Reports
- HY-MT1.5 Technical Report: https://arxiv.org/abs/2512.24092
- Sherry Paper (ACL 2026): https://arxiv.org/abs/2601.07892
- AngelSlim Technical Report: https://arxiv.org/abs/2602.21233
## 📝 License
The code for this project is open-sourced under the [License for AngelSlim](LICENSE).
## 🔗 Citation
```bibtex
@misc{huang2026sherry,
title={Sherry: Hardware-Efficient 1.25-Bit Ternary Quantization via Fine-grained Sparsification},
author={Hong Huang and Decheng Wu and Qiangqiang Hu and Guanghua Yu and Jinhai Yang and Jianchen Zhu and Xue Liu and Dapeng Wu},
year={2026},
eprint={2601.07892},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2601.07892},
}
@article{angelslim2026,
title={AngelSlim: A more accessible, comprehensive, and efficient toolkit for large model compression},
author={Hunyuan AI Infra Team},
journal={arXiv preprint arXiv:2602.21233},
year={2026}
}
@misc{zheng2025hymt,
title={HY-MT1.5 Technical Report},
author={Mao Zheng and Zheng Li and Tao Chen and Mingyang Song and Di Wang},
year={2025},
eprint={2512.24092},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2512.24092},
}
```
## 💬 Technical Discussion
* AngelSlim is continuously iterating and new features will be released soon. If you have any questions or suggestions, please open an issue on [GitHub Issues](https://github.com/Tencent/AngelSlim/issues) or join our [WeChat discussion group](https://github.com/Tencent/AngelSlim/blob/main/docs/source/assets/angel_slim_wechat.png?raw=true).Hy-MT1.5-1.8B-1.25bit-GGUF 混元翻译
支持手机
llama要用分支编译,才能加载模型推理
我编译的cpu的,推理速度跟电脑cpu,内存配置相关
可以本地离线用
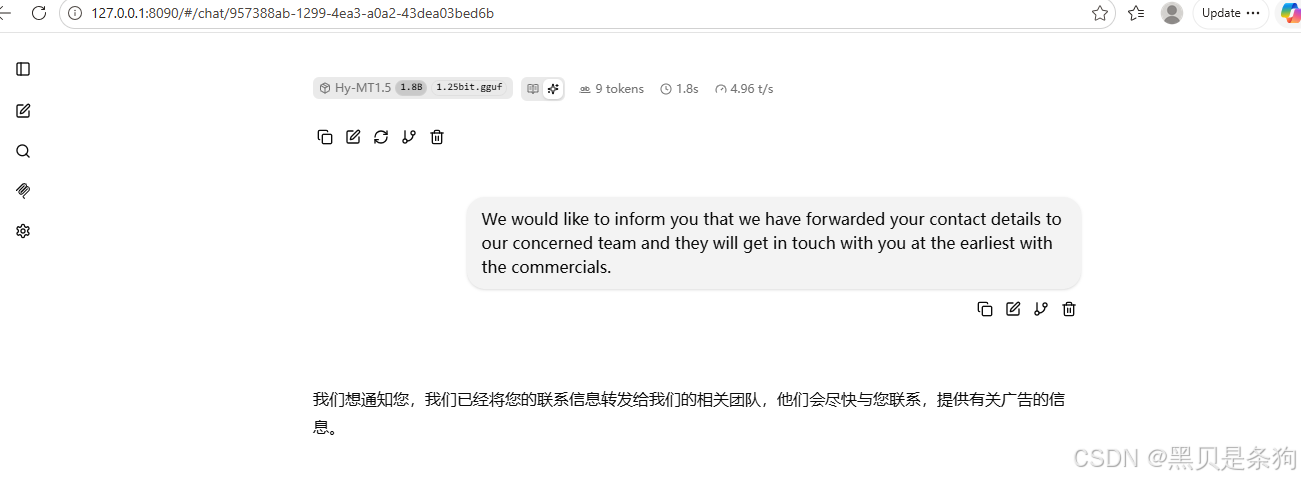
有这种需求的可以下载
运行程序后,打开llama网页即可
网盘地址:通过网盘分享的文件:混元翻译离线本地版.7z
链接: https://pan.baidu.com/s/15blt94PgbLjWQZWMoB9Qnw 提取码: hebe