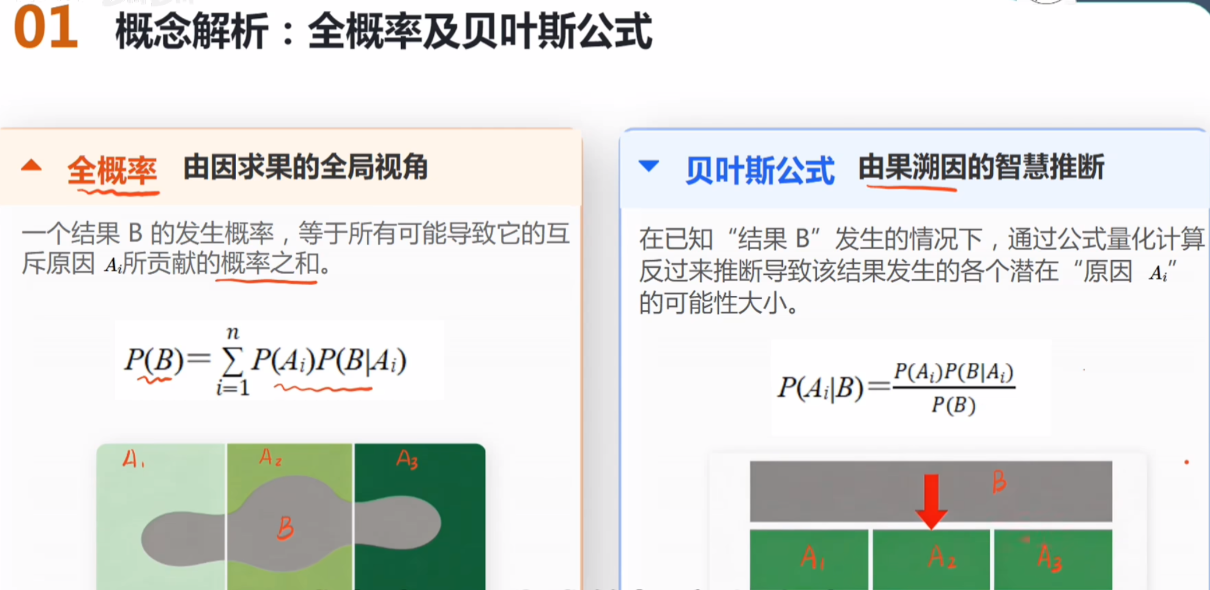
贝叶斯的理解
贝叶斯公式,就是把专门用来"根据新证据更新旧概率"的实用工具。
根据新情况,推翻或修正老看法
应用举例:
EG1
🧐 场景:你早上出门前纠结要不要带伞
旧概率(先验概率):
你早上起床拉开窗帘前,心里对"今天会不会下雨"有一个初始判断。比如你看了一下日历,现在是旱季,根据老经验,你觉得今天下雨的概率只有 20%。这就是你的"旧概率"。
新证据(似然度):
紧接着,你拉开窗帘,突然发现外面乌云密布,甚至开始刮大风了。这个"乌云密布"就是突然出现的"新证据"。
更新后的概率(后验概率):
在看到乌云的这一刻,你心里对"今天下雨"的判断绝对不会停留在 20% 了。你会立刻想:"天都黑成这样了,下雨的概率肯定飙升到了 80% 甚至更高!"
💡 这个过程,就是"用新证据更新旧概率"!
旧概率:没看窗外前,下雨概率 20%。
新证据:看到了乌云。
更新后的概率:结合乌云这个证据,下雨概率修正为 80%。
贝叶斯公式其实就是把咱们脑子里这个"看脸色行事"的直觉过程,用严谨的数学公式表达了出来:
P(下雨∣乌云)=P(乌云∣下雨)×P(下雨)/P(乌云)
P(下雨) 就是你脑子里的"旧概率"(20%)。
P(乌云|下雨) 是这个新证据的靠谱程度(如果真下雨,有多大概率会乌云密布?)。
P(下雨|乌云) 就是你看到乌云后,算出来的"更新后的概率"。
EG2抖音、快手、B站等平台的推荐算法,底层逻辑也是贝叶斯思维。
旧概率:系统一开始根据你的年龄、性别等基础画像,猜测你可能喜欢"美妆"或"游戏"(先验概率)。
新证据:你刷视频时,在一个健身视频上停留了5秒,并且点了个赞。
更新概率:系统立刻捕捉到这个新证据,迅速调高"健身/运动"类内容的推荐权重,降低其他内容的权重。你每一次的点击、停留、划走,都是在给系统提供新证据,让它不断更新对你喜好的判断,最终给你推送的全是你爱看的内容。
贝叶斯公式的"三步走"思维
先有个老看法(先验概率):在没看到新线索前,你凭经验或常识对一件事的初始判断。再看个新证据(新线索):突然出现了一个新的客观事实。修正出最终看法(后验概率):结合这个新证据,把你原来的老看法进行调整,得出一个更接近真相的新结论。
场景举例(阳性测试),更加明理
🏥场景设定:体检阳性,真的得病了吗?
假设有一种比较罕见的疾病(X病),现在医学界研发出了一种检测试剂。我们需要计算的是:如果你去体检,结果显示"阳性",你到底有多大几率是真的得了这种病?
首先,我们把题目中给出的已知条件(也就是贝叶斯公式需要的"原材料")列出来:
老看法(先验概率):这种病在人群中很罕见,发病率只有 1%。
新证据的可靠性(似然度):
如果你真的得了病,试剂有 99% 的概率能测出阳性(真阳性)。
如果你没得病(健康),试剂有 5% 的概率会误报为阳性(假阳性)。
🧮 贝叶斯公式"三步走"计算
我们的目标是算出:P(得病 | 阳性)。
第一步:先有个老看法(先验概率)
在没做体检前,随便拉一个人,他得病的概率就是人群发病率。
P(得病) = 1% = 0.01
那么,P(健康) = 1 - 1% = 0.99
第二步:再看新证据(计算分子)
我们要计算"一个人真的得病,并且被测出阳性"的概率。也就是公式的分子部分:P(阳性|得病) × P(得病)。
分子 = 99% × 1% = 0.99 × 0.01 = 0.0099
第三步:修正出最终看法(计算分母与结果)
分母 P(阳性) 代表所有能测出阳性的情况。这包含两种可能:
真的得病且测出阳性(真阳性):0.01 × 0.99 = 0.0099
没得病但被误测为阳性(假阳性):0.99 × 5% = 0.0495
所以,测出阳性的总概率(分母) = 0.0099 + 0.0495 = 0.0594
最后,代入公式相除:
P(得病 | 阳性) = 分子 ÷ 分母 = 0.0099 ÷ 0.0594 ≈ 0.1667
计算结果:约为 16.7%。
💡 为什么结果这么低?(大白话复盘)
算完你可能会大吃一惊:试剂准确率高达99%,为什么测出阳性后,真正得病的概率才16.7%?
我们可以假设一个10000人 的大社区来直观理解:
老看法:因为发病率是1%,所以这10000人里,真正得病的只有 100人,健康的有 9900人。
新证据:
那100个病人去体检,99%被查出,也就是 99人 显示阳性(真阳性)。
那9900个健康人去体检,有5%被误判,也就是 9900 × 5% = 495人 显示阳性(假阳性)。
最终看法:现在医院手里一共有 99 + 495 = 594份 阳性报告。如果你随便拿起其中一份,这份报告的主人真的是病人的概率是多少?
也就是:99(真病人) ÷ 594(所有阳性者) ≈ 16.7%。
结论:贝叶斯公式告诉我们,因为健康的人群基数太大了(9900人),哪怕只有5%的误判率,产生的"假阳性"人数(495人)也远远超过了真正的病人数(99人)。
上述场景数学化
我们把体检这件事拆成两个最基本的事件:
- 设事件 D 代表:真的得病 (Disease)
- 设事件 T 代表:检测出阳性 (Test Positive)
题目给出的已知条件(原材料)用事件表示就是:
- P(D) = 0.01 (得病的基础概率是 1%)
- 那么,P(非D) = 0.99 (没得病的概率就是 99%)
- P(T|D) = 0.99 (真的得病了,被测出阳性的概率是 99%)
- P(T|非D) = 0.05 (没得病,却被误测出阳性的概率是 5%)
我们的目标是求:P(D|T) (在检测出阳性的条件下,真的得病的概率)。

贝叶斯的分子与分母
贝叶斯公式的分子,算的就是 "新证据" 和 "原来的原因"同时发生的概率 ,在数学上叫做联合概率。
分母其实就是 "所有能导致这个结果(新证据)发生的情况的总和"。
结果表明新的概率,也叫后验概率,在掌握了最新线索后,这件事发生的真实可能性到底有多大。