当大模型的胃口越来越大,"喂数据"这件事,比训练模型本身还难。MaxFrame 用一行 Python 代码,让图片、音频、视频这些"难啃的骨头",从此分布式起飞。
你是否被这些场景困扰过?
🎬 "老板让我从 OSS 上几千万张图里挑出 1080P 以上的素材,单机脚本跑了两天还没扫完......"
🎙️ "几十万段会议录音要转成文字做摘要,调外部 API 一条条转,预算和时间都顶不住。"
🖼️ "AI 训练同事天天来催数据:'帮我把图缩到 224×224、RGBA 转 RGB、再过一遍质量筛选',每次都要写一堆胶水代码。"
🛠️ "为了处理多模态数据,我们搭了一套图像服务集群、一套语音转写集群、还要再写一套调度------运维同学已经在崩溃边缘了。"
如果这些场景让你"血压拉满",MaxFrame 多模态数据处理算子模块就是为你准备的最佳解决方案。
一句话解释:它是什么?
MaxFrame 多模态算子模块 是分布式 AI 计算引擎 MaxFrame 内置的一套声明式多模态数据处理能力。
简单来说:你只需要写几行 Python 代码,就能在分布式集群上对海量图片、音频做下载、解码、属性提取、缩放裁剪、语音转录、VAD 检测------全部一气呵成。
✅ 不用搭服务集群:所有算子在 MaxFrame DPE 引擎上自动并行
✅ 不用学新 API:链式调用、声明式语法,简单易用
✅ 不用拆链路:多模态数据处理和 AI 大模型推理(AI Function)天然打通
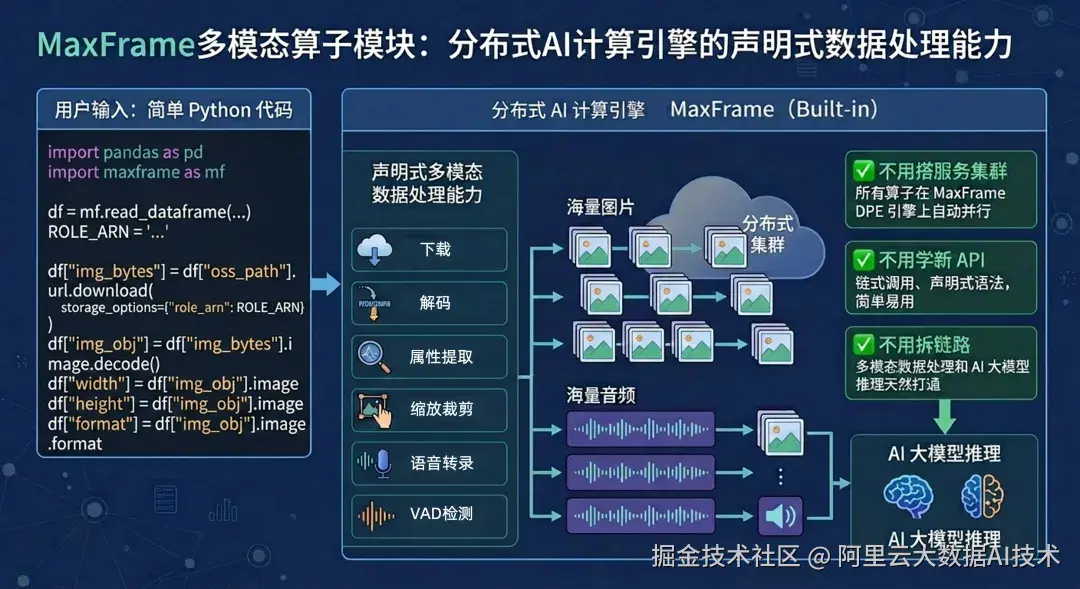
它能做什么?
1. 图像处理:解码、属性、缩放、裁剪、格式转换全都有
| 能力 | 算子示例 | 典型用途 |
|---|---|---|
| 🔓 解码 | image.decode() |
训练样本预处理 |
| 📐 属性 | image.width / height / size / format / mode |
数据清洗、规格筛选 |
| 🔧 变换 | image.resize() / crop() / convert() |
训练样本预处理 |
数据清洗这件原本"又脏又累"的活,现在变成几行声明式代码。
2. 音频处理:从文件到文本,一站式打通
| 能力 | 算子示例 | 典型用途 |
|---|---|---|
| 🔓 解码 | audio.decode() |
字节流 → 音频对象 |
| 📊 属性 | audio.duration / sample_rate / channels / format |
元数据归集 |
| 🌐 语种检测 | audio.detect_language() |
多语种数据分流 |
| 📝 语音转录 | audio.transcribe(language="zh") |
录音转文本、字幕生成 |
| 🎯 VAD 检测 | audio.vad_detect() |
静音切除、有效片段提取 |
"音频 → 文本 → 大模型摘要" 这条原本要穿越三个产品的链路,在 MaxFrame 里就是几行代码的事。
实战演示:三个真实场景
场景一:千万级图片数据集"质量筛选"
帮我从 OSS 里挑出宽 1000-5000、高2000-6000 的高清图,写到结果表里
plaintext
from maxframe import dataframe as md
df = md.read_odps_table("image_src_table")
# 下载 → 解码 → 属性提取(链式调用)
df["img_bytes"] = df["oss_path"].url.download(
storage_options={"role_arn": ROLE_ARN}
)
df["img_obj"] = df["img_bytes"].image.decode()
df["width"] = df["img_obj"].image.width
df["height"] = df["img_obj"].image.height
df["format"] = df["img_obj"].image.format
# 按规格过滤
df_ok = df[
df["width"].between(1000, 5000) &
df["height"].between(2000, 6000)
]
df_ok[["id", "oss_path", "width", "height", "format"]] \
.to_odps_table("image_sink_table", overwrite=True).execute()🚀 单机几天的扫描任务,在 MaxFrame 上分钟级搞定,全程零运维。
场景二:为 AI 训练准备"标准入参图"
"把图统一缩到 224×224,色彩模式归一化为 RGB"
plaintext
df["img_bytes"] = df["oss_path"].url.download(storage_options={"role_arn": ROLE_ARN})
df["img_obj"] = df["img_bytes"].image.decode()
df["img_resized"] = df["img_obj"].image.resize((224, 224)) # 训练标准尺寸
df["img_cropped"] = df["img_obj"].image.crop((100, 100, 500, 500)) # 局部裁剪
df["img_rgb"] = df["img_obj"].image.convert("RGB") # 色彩模式归一化💡 声明式描述目标,分布式执行细节交给引擎。
场景三:批量音频转录 + 语种识别
"把这一批客服录音转成中文文本,再做一次有效语音片段检测"
plaintext
df = md.read_odps_table("audio_src_table")
df["audio_bytes"] = df["audio_path"].url.download(storage_options={"role_arn": ROLE_ARN})
df["audio_obj"] = df["audio_bytes"].audio.decode()
df["duration"] = df["audio_obj"].audio.duration
df["sample_rate"] = df["audio_obj"].audio.sample_rate
df["text"] = df["audio_bytes"].audio.transcribe(language="zh") # 转录
df["vad_result"] = df["audio_bytes"].audio.vad_detect() # 有效片段检测🎙️ 告别"调外部 API + 自写并发 + 写库"的胶水代码,一段流水线一气呵成。
为什么选择 MaxFrame 多模态算子?
你可能会问:这些处理我自建服务,自己写代码也能做,为什么要用 MaxFrame?
| 传统做法的痛点 | MaxFrame 的解法 |
|---|---|
| ❌ 自建图像/语音处理服务集群 | ✅ 多模态算子内置,零集群运维 |
| ❌ 多模态处理与大模型推理割裂 | ✅ 与 AI Function 天然打通,一套代码端到端 |
| ❌ 学习曲线陡峭,要懂各类不同引擎 | ✅ 类 Pandas 风格,懂 Python 就会用 |
| ❌ 并行度、分片要手动调 | ✅ 引擎自动分片调度,按需扩缩 |
| ❌ 算力买少了卡死,买多了浪费 | ✅ 背靠 MaxCompute 弹性 CU 资源池,提供十万核级算力,按需调度、按量收费 |
💪 十万核级弹性算力,海量多模态数据"敞开跑"
MaxFrame 多模态算子背后,是 MaxCompute 提供的十万核级弹性 CU 计算资源池:
🔋 弹性扩缩:作业高峰自动拉起算力,闲时自动释放,无需提前规划集群规模
💰 按量计费:用多少 CU 付多少钱,告别"买多了浪费、买少了卡顿"的两难
🚀 海量并发:千万级图片、百万级音频可同时分发到大规模 Worker 并行处理
🛡️ 稳定可靠:依托 MaxCompute 多年大规模生产实践,作业稳定性和资源 SLA 有保障
-
这意味着:当你需要处理 1 亿张图片或 100 万段音频时,不用再纠结"要不要再申请 500 台机器"------MaxFrame 直接调度 MaxCompute 的弹性算力池,几分钟内拉起规模化算力跑完。
-
MaxFrame 多模态算子模块不是"在 DataFrame 上加几个图像函数"那么简单------它是把"多模态数据处理 + 分布式调度 + 弹性算力 + AI 推理"四件事,重新封装成了一行声明式代码。
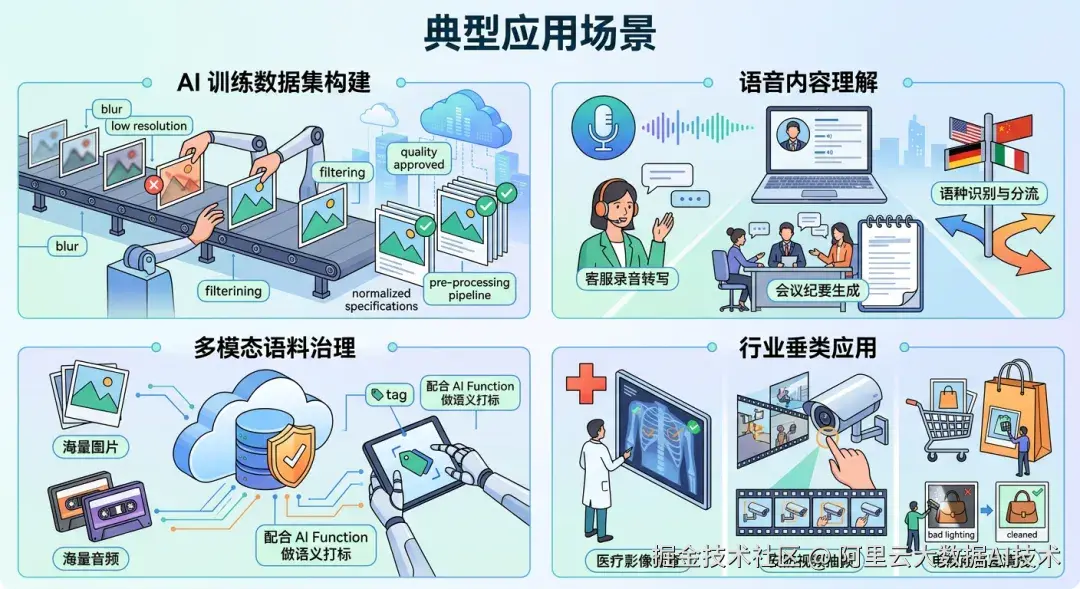
典型应用场景
🖼️ AI 训练数据集构建:图像质量过滤、样本规格归一化、训练前预处理流水线
🎙️ 语音内容理解:客服录音转写、会议纪要生成、语种识别与分流
🎬 多模态语料治理:海量图片/音频元数据归集,配合 AI Function 做语义打标
🏥 行业垂类应用:医疗影像筛查、安防视频抽帧、电商商品图清洗
📺 即将到来:视频算子,敬请期待
图像与音频之后,下一个"硬骨头"是视频。
我们正在打磨 MaxFrame 视频算子模块,目标是把视频这类体量更大、结构更复杂的多模态数据,也纳入同一套声明式 DataFrame 体验:
🎞️ 视频解码与抽帧:一行代码完成关键帧 / 等间隔帧抽取,输出可直接喂给图像算子与大模型
📐 视频属性提取:时长、帧率、分辨率、编码格式等元数据批量归集,海量视频数据"一眼看清"
✂️ 视频片段切分:按时长、镜头切换、VAD 等策略切片,支撑训练样本构建与内容理解
🔗 与图像/音频/AI Function 打通:视频 → 帧 → 标签/Embedding/摘要,端到端一条流水线
🚀 一句话剧透 :未来你只需要一句 df["video"].video.extract_frames(...),就能把千万级视频"打散成可训练的素材"。
敬请关注 MaxFrame 后续版本发布,第一时间体验视频算子能力。
写在最后
多模态数据时代,数据准备的成本,常常远高于模型训练本身。
MaxFrame 多模态算子模块的目标只有一个:让"准备数据"这件事,重新变得简单。
无论你是:
🧪 算法工程师:想把更多时间花在模型迭代,而不是写数据胶水
🛠️ 数据工程师:想用一套 Python 代码搞定结构化 + 多模态处理
🚀 业务同学:想快速验证一个多模态 AI 想法,不想自建集群
MaxFrame 多模态算子模块都能让你从"先搭一个月平台",变成"今天就能跑出第一批结果"。
现在就升级到最新版 MaxFrame,把那行 df["bytes"].image.decode() 跑起来吧 👇
相关链接:
-
MaxFrame 多模态算子模块介绍:help.aliyun.com/zh/maxcompu...
-
MaxFrame 官方文档介绍:maxframe.readthedocs.io/en/latest/