银行业务
1104工程
一句话定义 :1104工程是原银监会(现国家金融监督管理总局)建立的银行业非现场监管报表体系 ,因为制度编号是"银监发〔2006〕1104号",所以叫1104工程。
一、为什么叫1104?(记住这个就够了)
文件编号 :银监发〔2006〕1104号
时间 :2006年启动
全称:银行业金融机构非现场监管报表体系
💡 巧记:11月4日发布?不对,就是文件编号,像你项目里的"合同编号"一样理解就行。
二、1104工程是做什么的?(核心目的)
| 维度 | 说明 |
|---|---|
| 谁报 | 银行、信托、财务公司等所有银行业金融机构 |
| 报给谁 | 监管机构(原银监会 → 金融监管总局) |
| 报什么 | 资产负债表、不良贷款、资本充足率、流动性等监管指标 |
| 怎么报 | 通过监管报送系统,按月/按季/按年定期上报 |
| 为什么要报 | 让监管"不出门便知银行事",提前发现风险 |
一句话:1104 = 银行定期向监管交"体检报告"的制度
三、1104报表长什么样?(举个例子)
| 报表编号 | 报表名称 | 报送频率 | 用途 |
|---|---|---|---|
| G01 | 资产负债项目统计表 | 月报 | 看银行资产规模、存款贷款情况 |
| G11 | 资产质量五级分类情况表 | 季报 | 看不良贷款有多少 |
| G12 | 贷款质量迁徙情况表 | 季报 | 看正常贷款变成不良的"迁徙"情况 |
| G02 | 衍生产品交易业务情况表 | 季报 | 看衍生品风险敞口 |
你项目里的征信数据、贷款明细、资产统计,很多就是1104报表的数据来源。
四、1104与你的项目有什么关系?
把概念和实际工作联系起来
| 你的项目模块 | 对应的1104监管点 |
|---|---|
| 贷前授信:存款、理财、资产统计 | G01资产负债统计 |
| 贷后预警:逾期贷款、不良 | G11五级分类、G12迁徙率 |
| 征信数据:客户征信报告 | 监管要求的信用风险监控 |
| 贷款流向模型:资金流向监控 | 监管要求防范资金违规流入房市/股市 |
示例 :
"数仓加工出来的贷款明细、逾期统计、资产质量分类,最终就是往1104报表里填报的。比如G11的五级分类表,就需要从贷后预警模型中取不良贷款余额。"
五、口述(1分钟版)
"1104工程是2006年原银监会建立的银行业非现场监管报表体系。简单说就是银行要定期向监管报送各种经营和风险指标,比如资产规模、不良贷款率、资本充足率这些。
这个制度的核心目的是让监管能随时掌握银行的经营状况和风险水平,不用非得去现场检查。
信贷风控数仓,加工出来的贷款明细、逾期统计、资产质量这些数据,本身就是1104报表的数据来源。比如不良贷款的监控,最后就是汇总到监管要求的G11报表里。"
六、和"监管报送"的区别(防止混淆)
| 概念 | 说明 |
|---|---|
| 1104工程 | 原银监会的非现场监管报表体系(关注经营风险、资产质量) |
| EAST系统 | 原银监会的现场检查分析系统(关注明细数据、交易流水) |
| 大集中 | 原人民银行的金融统计大集中系统(关注宏观统计数据) |
💡 记忆技巧:
1104 = 银行自己报汇总指标(体检查病)
EAST = 监管直接查明细流水(翻账本)
大集中 = 央行收宏观数据(看大数)
七、关键词
text
# 项目描述关键词
1104报送、非现场监管、G01/G11/G12报表、五级分类、不良贷款率
资本充足率、流动性覆盖率、监管指标口径、EAST、监管数据治理一句话总结(记住这个就够了)
1104工程 = 银行定期向监管报"体检数据"的制度,你数仓算出来的贷款、逾期、资产数据,最后就是往这里面填的。
EAST系统
一句话定义 :EAST是原银监会(现金融监管总局)建设的现场检查分析系统,全称"Examination and Analysis System Technology",让监管能直接查银行的明细流水数据。
一、EAST vs 1104 - 核心区别(必考)
| 对比维度 | 1104工程 | EAST系统 |
|---|---|---|
| 数据粒度 | 汇总指标(报表) | 明细流水(每笔交易) |
| 报送频率 | 按月/按季/按年 | 按固定周期(通常季度) |
| 数据量 | 几十到几百条 | 几亿到几十亿条 |
| 用途 | 日常监控、趋势分析 | 专项检查、问题发现 |
| 典型问题 | 不良率多少? | 谁转了多少钱给谁? |
| 记忆口诀 | "看总结" | "翻账本" |
💡 一句话讲透:
1104 = 银行自己报的体检报告(血压120,正常)
EAST = 监管直接看原始病历和化验单(自己算,不信任你报的)
二、EAST的核心特点
1️⃣ 明细级数据
不是汇总数,是每笔交易、每个账户、每张借据的原始记录
text
1104报表:不良贷款余额 = 1000万
EAST明细:一笔一笔贷款明细,监管自己判断哪些属于不良2️⃣ 标准化数据格式
监管统一规定了数据字典,银行必须按标准格式报送
| 数据域 | 示例表 |
|---|---|
| 客户信息 | 个人客户表、企业客户表 |
| 账户信息 | 存款账户表、贷款账户表 |
| 交易流水 | 交易流水表、信贷分户账 |
| 财务信息 | 科目明细表、总账凭证 |
3️⃣ 用于现场检查
监管去银行检查前,先把EAST数据导入自己的系统,提前分析问题线索,到了现场直接查
三、EAST能查出什么?(实际案例)
| 违规类型 | EAST怎么发现 | 你项目里对应的东西 |
|---|---|---|
| 以贷转存 | 贷款发放后 → 同一客户账户变成定期存款 | 你的贷款流向模型 |
| 流入房市/股市 | 贷款资金 → 转账给房地产/证券账户 | 你的公检法/监控账户匹配 |
| 以贷养贷 | 放款 → 转给小贷公司 → 还款日前转回 | 你的还款资金来源监控 |
| 关联交易 | 银行员工账户 → 贷款客户账户转账 | 交易对手分析 |
| 虚假贷款 | 借据无对应合同、抵押物重复抵押 | 合同关联校验 |
亮点 :"我们做的贷款流向模型,本质上就是类似EAST的检查逻辑------通过交易流水关联,发现资金是否违规流入禁入领域。"
四、EAST与数仓的关系
把EAST和工作联系起来
text
监管要求 ←→ EAST报送 ←→ 数仓加工 ←→ 业务系统
你的数仓位置:
业务系统 → ODS → DWD → DWS → ADS → EAST报送接口
↑
你加工的表可能直接映射到EAST示例 :
"数仓加工出来的交易流水表、贷款合同明细、客户账户关系表,很多就是直接对应EAST报送口径的。比如贷款账户流水表,字段命名和数据类型都要按照EAST的规范来,确保监管能直接取数。监管要查资金流向,用我们的明细表跑一遍就行了。"
五、口述(1分钟版)
"EAST是原银监会建立的现场检查分析系统,全称是Examination and Analysis System Technology。和1104不同,1104是银行自己报汇总指标,而EAST是报送明细流水数据------每笔交易、每个账户、每张借据。
监管拿到EAST数据后,会导入自己的分析系统,提前跑出问题线索。比如查以贷养贷:先筛选放款记录,再关联交易流水,看钱有没有转给小贷公司,然后还款日前又从小贷公司转回来。
做信贷数仓时,像贷款流向模型、还款资金来源监控这些,本质上就是EAST的检查逻辑。我们也会确保表结构和字段规范对齐EAST标准,方便后续监管报送。"
六、对比速记表(1104 + EAST + 大集中)
| 维度 | 1104工程 | EAST系统 | 大集中(央行) |
|---|---|---|---|
| 监管机构 | 金融监管总局(原银监会) | 金融监管总局 | 中国人民银行 |
| 数据粒度 | 汇总报表 | 明细流水 | 汇总+部分明细 |
| 关注点 | 银行经营风险 | 业务合规、违规线索 | 宏观金融统计 |
| 报送内容 | 不良率、资本充足率 | 每笔贷款、每笔交易 | 信贷增量、社融数据 |
| 记忆口诀 | 体检报告 | 原始账本 | 国民经济账本 |
七、关键词
text
EAST报送、现场检查、明细数据、交易流水关联、资金流向监控
以贷养贷识别、EAST数据字典、监管口径对齐、数据标准化一句话总结
1104是银行自己报"我有没有病",EAST是监管直接查"你到底有没有病"------翻你的原始账本,一笔一笔看。
EAST系统
一句话定位 :EAST开发不是"写SQL跑数"那么简单,而是一套受监管约束的、版本严控的、必须通过多轮测试的规范化流程。
一、EAST开发全流程(6步法)
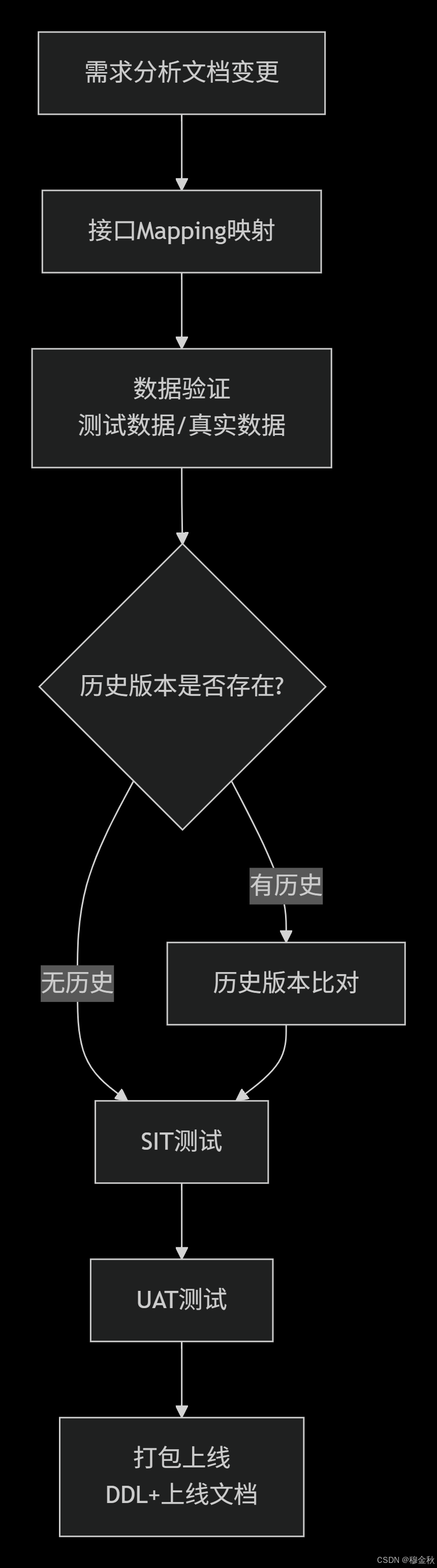
二、每一步详解
第1步:需求分析文档 → 接口Mapping
| 动作 | 说明 | 输出物 |
|---|---|---|
| 需求来源 | 监管发文(如EAST 4.0升级到5.0)、行内自查整改 | 监管需求文档 |
| 变更分析 | 新增什么表?删了什么字段?枚举值变了没? | 变更清单 |
| Mapping映射 | 监管字段 → 行内表字段 → 加工逻辑 | 接口Mapping文档 |
Mapping示例:
text
监管字段:贷款借据号(LoanContractNo) 行内来源:个人借据明细表.借据号 加工逻辑:直接映射 备注:长度20位,左补0
示例 :
"需求来了之后,第一步是改Mapping。监管说字段A要改成B,我们就要在Mapping文档里标清楚:新字段从哪张表取、怎么加工、数据类型是什么。这个Mapping是后面开发测试的唯一依据。"
第2步:数据验证(测试数据/真实数据)
| 数据来源 | 适用场景 | 优缺点 |
|---|---|---|
| 测试数据 | 开发阶段、无真实数据 | 可控、安全,但可能覆盖不全 |
| 真实数据(脱敏) | 验证业务逻辑、发现边界问题 | 真实有效,但需脱敏审批 |
执行动作:
-
按照Mapping写SQL,跑出结果
-
检查:空值率、异常值、枚举值是否合法
-
主键是否唯一、金额精度是否丢失
示例 :
*"Mapping改完后,会先用一个月的数据跑一下,看看结果对不对。比如新加了'客户类型'字段,要确认枚举值只有0/1/2,没有空值或者'其他'这种脏数据。"*
第3步:历史版本比对(关键步骤)
只有历史已有这个接口/字段时才需要做
| 比对维度 | 比对内容 | 差异怎么办 |
|---|---|---|
| 数据量 | 本期记录数 vs 上期 | 波动超过阈值要分析 |
| 字段值 | 同一客户同一时点的字段值 | 确认是业务变更还是BUG |
| 汇总口径 | 总分、各维度汇总 | 确认口径调整是否合理 |
比对SQL示例:
sql
-- 上期结果 vs 本期结果,看同一主键的值是否变化
SELECT
COALESCE(a.借据号, b.借据号) AS 借据号,
a.五级分类 AS 上期分类,
b.五级分类 AS 本期分类
FROM 上期结果表 a
FULL OUTER JOIN 本期结果表 b ON a.借据号 = b.借据号
WHERE a.五级分类 != b.五级分类
OR (a.五级分类 IS NULL AND b.五级分类 IS NOT NULL)
OR (a.五级分类 IS NOT NULL AND b.五级分类 IS NULL);示例 :
"如果这个字段历史上就存在,比如EAST4.0就有,5.0还在,那就必须做版本比对。会拿上个月跑的结果和这个月跑的结果对比,看同一个借据号的五级分类变了没有。如果大量变动,要确认是业务原因还是程序BUG。"
第4步:SIT测试(系统集成测试)
目标:验证系统内部各模块之间能否正常协作
| 测试内容 | 具体验证点 |
|---|---|
| 数据流向 | ODS → DWD → DWS → ADS → EAST接口,每一层数据量是否一致 |
| 依赖关系 | 上游表没跑完,下游是否等待/报错 |
| 性能 | 跑批时间是否在窗口内(如天亮前跑完) |
| 异常处理 | 某张源表为空时,程序是否优雅降级 |
输出物:SIT测试报告(含缺陷清单)
示例 :
"SIT是系统集成测试,主要验证整个数据加工链路能不能跑通。比如改了贷款流向模型的逻辑,要确认依赖的交易流水表、合同表都能正常关联,跑批时间从2小时变成3小时也没超窗口。"
第5步:UAT测试(用户验收测试)
目标:业务方/监管报送团队确认结果符合预期
| 测试角色 | 关注点 | 典型问题 |
|---|---|---|
| 监管报送团队 | 是否符合报送口径 | "这个不良的认定标准不对" |
| 业务方(风控/信管) | 数据是否合理 | "为什么XX分行的不良突然翻倍?" |
| 数据治理团队 | 数据质量是否达标 | "这个字段空值率超过5%了" |
UAT典型流程:
-
开发提供结果表 + 数据质量报告
-
业务方抽数验证
-
业务方签字确认 → 才能上线
示例 :
"UAT是业务方说了算。把跑出来的结果给监管报送的老师看,他们抽几条数据确认口径对了,签字确认,才能往下走。之前遇到过字段口径理解不一致,UAT阶段返工了一周,所以现在我会提前拉上业务对齐。"
第6步:打包上线
上线不是"把代码扔上去" ,而是需要准备完整的上线物料
| 上线物料 | 内容 | 格式示例 |
|---|---|---|
| DDL脚本 | 建表语句、加字段、改字段类型 | ALTER TABLE ADD COLUMN |
| ETL代码包 | SQL脚本、Shell脚本、配置文件 | .sql / .sh / .conf |
| 上线文档 | 变更内容、影响范围、回滚方案 | Word/Confluence |
| 数据初始化脚本 | 历史数据回刷(如需) | INSERT OVERWRITE |
| 版本标记 | Git Tag、版本号、上线时间 | v2.1.0_20250331 |
上线文档必备内容:
text
1. 变更概述:改了哪个接口/哪个字段
2. 影响范围:下游哪些报表/系统依赖
3. 上线步骤:先停调度?先加字段?后部署代码?
4. 验证方案:跑哪条SQL确认上线成功
5. 回滚方案:出问题怎么回到上一版本
6. 联系人:开发、业务、运维示例 :
"上线前会准备完整的物料包:DDL脚本、代码、上线文档。文档里重点写回滚方案------万一上线出问题,怎么快速切回老版本。EAST报送是有监管deadline的,不能因为我们的问题耽误报送。"
三、口述(2分钟版)
"EAST开发有一套标准流程,我把它总结成6步:
第一步:需求来了先改Mapping文档。监管发文说要加字段或者改口径,我要把这个变更映射到行内具体的数据表字段和加工逻辑。
第二步:用测试数据或者真实数据跑一下,验证逻辑对不对,检查空值、异常值。
第三步:如果这个字段历史就有,要做版本比对。拿上期的结果和这期的对比,看差异是不是合理的。如果没有历史,就直接进SIT。
第四步:SIT测试,验证整个加工链路跑得通,性能不超时。
第五步:UAT测试,业务方确认结果符合预期,签字后才能上线。
第六步 :打包上线。要准备DDL脚本、代码包、上线文档,尤其是回滚方案*必须写清楚,因为EAST报送有监管时间要求,不能出问题卡住。*
整个流程下来,每个环节都有文档产出,监管检查的时候是要看这些痕迹的。"
四、追问
Q1:SIT和UAT有什么区别?
| 维度 | SIT | UAT |
|---|---|---|
| 谁测 | 开发/测试工程师 | 业务方/监管报送团队 |
| 测什么 | 技术链路通不通 | 业务口径对不对 |
| 发现问题类型 | 空指针、性能慢、数据丢了 | 口径不对、枚举值错了 |
| 通过标准 | 技术指标达标 | 业务方签字确认 |
Q2:版本比对发现差异怎么办?
"先分类:如果是业务原因(比如贷款真的逾期了),那正常;如果是代码逻辑变了导致的,要确认是有意修改还是BUG;如果是数据源问题(上游少传了文件),要协调上游修复。差异超过阈值(比如不良率从1%突然变5%)要拉业务一起分析。"
Q3:上线失败怎么回滚?
"我们保留上一版本的代码和调度配置。回滚步骤写在上线文档里:第一步停调度,第二步还原代码版本,第三步重启调度,第四步验证。整个回滚要求在30分钟内完成。"
五、流程总结速记表
| 步骤 | 名称 | 核心产出 | 一句话记忆 |
|---|---|---|---|
| 1 | 需求→Mapping | Mapping文档 | 监管说改啥,我对到表 |
| 2 | 数据验证 | 验证结果 | 跑个数看看对不对 |
| 3 | 版本比对 | 差异报告 | 和上次比,变了没 |
| 4 | SIT测试 | SIT报告 | 技术链路通不通 |
| 5 | UAT测试 | UAT签字 | 业务说行不行 |
| 6 | 打包上线 | DDL+上线文档 | 物料齐了,可回滚 |
六、关键词
text
EAST开发流程、接口Mapping、版本比对、SIT测试、UAT测试
上线文档、回滚方案、DDL脚本、监管报送口径、数据验证EAST V5跑批全流程
一句话定位 :EAST跑批不是"跑完SQL就完事了",而是一条完整的生产流水线:调度→跑批→补录→校验→卸数→报送,每一步都有监管要求。
一、EAST V5跑批六步法(全景图)
💡 核心理解 :这是一个闭环------补录和校验不通过都会回到跑批,直到数据合格才能卸数报送。
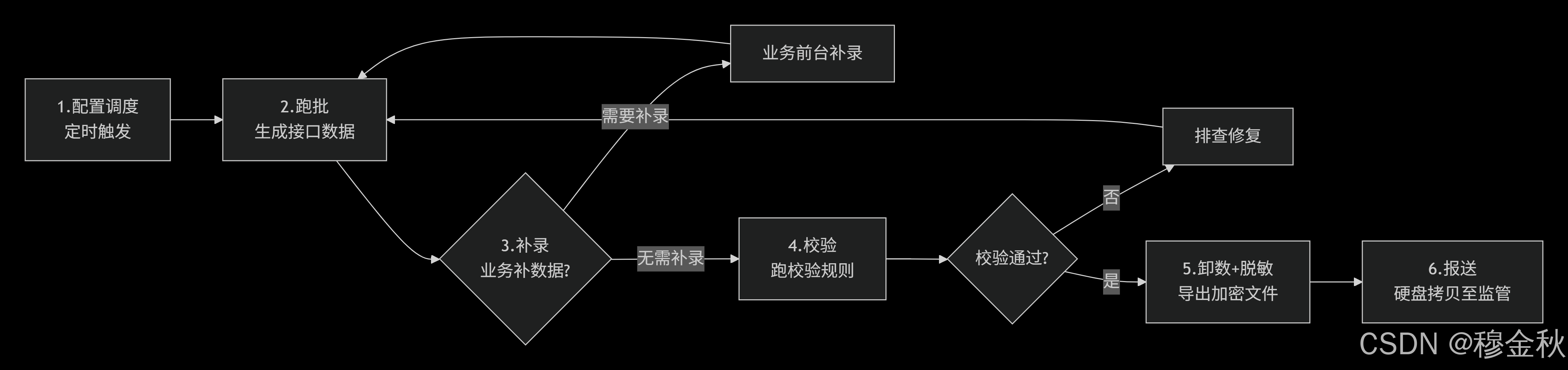
二、每一步详解
第1步:配置调度
| 维度 | 说明 |
|---|---|
| 调度工具 | Control-M、Airflow、Dataphin、自家调度平台 |
| 调度频率 | 月报(次月第X个工作日)、季报、半年报 |
| 调度对象 | 每个报送接口对应一个作业(Job) ,如:EAST_G01_贷款明细 |
| 依赖关系 | 上游数仓跑完 → EAST作业才能跑 |
| 时间窗口 | 必须在监管截止时间前完成(如次月10日24:00前) |
示例 :
"调度是第一步。我们会用调度工具把每个报送接口配成一个作业,设置好依赖和触发时间。比如上游DWS层跑完后才触发EAST跑批,确保数据是最新的。调度频率根据监管要求来,大部分是月报,次月5号凌晨自动跑。"
第2步:跑批(生成接口数据)
| 动作 | 说明 |
|---|---|
| 执行内容 | 运行ETL脚本,从数仓加工出EAST接口表 |
| 输入 | DWD/DWS层数据 + Mapping逻辑 |
| 输出 | EAST接口表(如:EAST_LN_LOAN_DETAIL) |
| 跑批模式 | 全量跑(每月重跑所有历史)或增量跑(只跑本月新增) |
示例 :
"跑批就是执行我们开发好的SQL,从数仓里把数据加工出来,写入EAST接口表。比如贷款明细接口,跑完后这张表里就是本月要报送给监管的所有贷款记录。"
第3步:补录(关键差异化步骤)
为什么需要补录? 有些数据在数仓里没有,或者不完整,需要业务人员在前台系统手动补。
| 补录场景 | 举例 | 谁操作 |
|---|---|---|
| 历史原因 | 老系统迁移前的数据缺失 | 业务人员 |
| 业务原因 | 线下台账未录入系统 | 客户经理 |
| 流程原因 | 贷款已批但系统还没走完流程 | 信审人员 |
| 监管要求 | 监管要求填数仓没有的新字段 | 业务人员 |
补录流程:
text
跑批完成 → 发现数据缺失 → 业务在前台补录 → 重新跑批(覆盖)示例 :
"补录是EAST报送里很常见的一步。比如监管要填'贷款实际用途',但这个字段数仓里没有,就需要业务人员在前台系统手动补。补完之后我们重新跑对应的接口,用补录的数据覆盖原来的结果。这也是为什么调度要设计成可重跑的。"
第4步:校验(质量门禁)
核心理解:跑批出来的数据,不仅要"有数据",还要"符合规则"。
| 校验类型 | 校验内容 | 示例 |
|---|---|---|
| 完整性校验 | 必填字段不能为空 | 借据号 IS NOT NULL |
| 规范性校验 | 格式、长度、枚举值 | 五级分类 IN ('正常','关注','次级','可疑','损失') |
| 逻辑性校验 | 表内/表间勾稽关系 | 放款金额 = 分期还款总额 |
| 一致性校验 | 与1104等其他系统对账 | EAST不良余额 ≈ 1104不良余额 |
| 波动性校验 | 较上月变化不超过阈值 | 不良率变化 < 20% |
校验结果处理:
示例 :
"校验是质量门禁。跑完批后,我们会跑一套校验SQL,比如检查必填字段有没有空值、枚举值是不是合法、不良余额和1104对不对劲。校验不通过就报错,我们排查修复后重新跑批,直到全部通过才能往下走。"
第5步:卸数 + 脱敏
| 步骤 | 动作 | 说明 |
|---|---|---|
| 卸数 | 从数据库导出数据 | 导出为监管要求的格式(TXT、CSV、XML) |
| 脱敏 | 敏感信息处理 | 客户姓名、身份证、手机号等按要求脱敏 |
| 加密 | 文件加密 | 使用监管指定的加密算法(如SM4) |
| 文件命名 | 按规范命名 | 机构代码_报表期_接口代码_版本号.dat |
脱敏规则示例:
| 字段 | 原始值 | 脱敏后 |
|---|---|---|
| 客户姓名 | 张三 | 张* |
| 身份证号 | 11010119900307663X | 110101********63X |
| 手机号 | 13812345678 | 138****5678 |
示例 :
"卸数就是把数据库里的接口表导出成监管要求的文件格式。导出前要做脱敏,比如姓名只留姓、身份证脱中间几位。导出后用监管指定的算法加密,文件名也要按规范命名,方便监管那边解析。"
第6步:报送(物理拷贝至监管)
关键理解 :EAST数据量大(几十GB到TB级),网上传太慢,所以采用物理介质报送。
| 动作 | 说明 |
|---|---|
| 介质 | 加密硬盘(U盘/移动硬盘)、光盘 |
| 拷贝 | 将加密后的文件拷贝到介质 |
| 送达 | 专人送至金融监管总局或当地监管局 |
| 签收 | 监管接收后签收确认 |
| 留存 | 银行保留一份副本,备查 |
报送方式对比:
| 方式 | 适用场景 | 优缺点 |
|---|---|---|
| 硬盘拷贝 | 数据量大(TB级) | 安全、可靠,但物理送达慢 |
| 专线传输 | 数据量中等 | 快,但需要专线建设 |
| 监管平台上传 | 数据量小 | 便捷,但大文件易超时 |
示例 :
"最后一步是报送。因为EAST数据量很大,我们用的是加密硬盘,把卸数出来的文件拷进去,专人送到金融监管总局。监管签收后,这个月的报送才算完成。整个过程从调度到报送,我们一般要在监管截止时间前3天完成,留出缓冲期。"
三、口述(2分钟版)
"EAST V5的跑批流程,我把它总结成6步:
第一步配置调度:用调度工具把每个报送接口配成作业,设置好触发时间和依赖。
第二步跑批:执行ETL,从数仓加工出EAST接口表。
第三步补录:如果数仓里缺数据,业务人员在前台补录后,我们重新跑批覆盖。
第四步校验:跑完整性、规范性、逻辑性等校验规则,全部通过才能往下走。
第五步卸数和脱敏:导出文件,对客户姓名、身份证这些敏感字段做脱敏,再用指定算法加密。
第六步报送:把加密文件拷到硬盘,专人送到监管局。
整个流程是闭环的------补录或校验不通过都要回到跑批重跑,直到数据合格。我们一般会提前3天完成,留出缓冲时间应对突发问题。"
四、追问
Q1:补录和重新跑批,怎么保证数据不重复/不丢?
"补录接口的设计是覆盖写 ,不是追加。重新跑批时,会用最新的补录数据全量覆盖之前跑的结果。接口表的主键设计要能唯一标识一条记录,这样覆盖是安全的。"
Q2:校验不通过最常见的原因是什么?
"最常见的是枚举值不合法 。比如监管规定'五级分类'只能填那5种,但源数据里可能有'正常类'(多个类字)或者空值。其次是必填字段为空,比如借据号丢了。这些我们会在DWD层做数据质量监控,尽量在上游解决。"
Q3:卸数文件监管不通过怎么办?
"监管那边也会做校验,如果文件格式不对或者数据有问题,会打回来。我们会根据反馈的问题修复,重新跑批、重新卸数、重新报送。所以留出缓冲期很重要,要有返工的时间。"
Q4:有没有遇到过补录来不及的情况?
"有的。比如业务人员月底才发现缺了1000条数据,补录要一周。我们的预案是:先报已有数据,下一期再补。但要跟监管提前沟通,说明情况,不能擅自不报。"
五、流程总结速记表
| 步骤 | 名称 | 核心动作 | 常见问题 | 一句话记忆 |
|---|---|---|---|---|
| 1 | 配置调度 | 设定时、配依赖 | 依赖漏配、时间设错 | 定时开跑 |
| 2 | 跑批 | 执行ETL生成接口表 | SQL报错、数据倾斜 | 算出数据 |
| 3 | 补录 | 业务补数 → 重跑 | 补录不及时、补错 | 缺啥补啥 |
| 4 | 校验 | 跑规则、检查质量 | 枚举值错、勾稽不对 | 质量把关 |
| 5 | 卸数+脱敏 | 导出、脱敏、加密 | 脱敏漏了、加密不对 | 打包加密 |
| 6 | 报送 | 硬盘拷贝、专人送达 | 硬盘损坏、送达超时 | 物理送达 |
六、EAST时间轴示例(月报)
text
时间线(假设监管要求:次月10日前报送)
次月1日 00:00 ─┬→ 上游数仓跑完上月数据
次月2日 00:00 ─┼→ EAST调度触发,开始跑批
次月2日 06:00 ─┼→ 跑批完成
次月2日-3日 ─┼→ 补录窗口(业务补数据)
次月3日 ─┼→ 重新跑批(含补录数据)
次月4日 ─┼→ 校验 + 修复 + 重跑(循环)
次月6日 ─┼→ 卸数 + 脱敏 + 加密
次月7日 ─┼→ 硬盘拷贝,专人送达
次月8日 ─┴→ 监管签收 ✅(提前2天完成)七、关键词
text
EAST V5、调度配置、跑批、补录机制、校验规则、脱敏加密
卸数报送、物理介质报送、监管报送窗口、数据质量门禁大集中系统
一句话定义 :大集中是中国人民银行建立的金融统计大集中系统,全称"金融统计大集中系统",用于收集银行业的宏观统计数据,是央行制定货币政策的核心数据支撑。
一、为什么叫"大集中"?
| 维度 | 说明 |
|---|---|
| "大" | 覆盖所有银行业金融机构(银行、农信社、财务公司等) |
| "集中" | 全国数据统一上报到人民银行总行,集中管理 |
| 对比 | 以前是各分行报给总行再汇总,现在是直接集中报送 |
💡 一句话 :大集中 = 所有银行把统计数据直接报给央行总行,央行一张表看全国。
二、大集中 vs 1104 vs EAST - 三合一对比
| 对比维度 | 大集中 | 1104工程 | EAST系统 |
|---|---|---|---|
| 监管机构 | 人民银行 | 金融监管总局 | 金融监管总局 |
| 数据粒度 | 汇总指标 + 部分明细 | 汇总报表 | 明细流水 |
| 核心用途 | 货币政策制定 | 银行风险监控 | 现场检查、违规查处 |
| 报送频率 | 月报、季报、年报 | 月报、季报、年报 | 季报(部分月报) |
| 数据量级 | 中等(MB-GB) | 小(KB-MB) | 大(GB-TB) |
| 典型问题 | 全国贷款增量多少? | 工行不良率多少? | 谁的钱转给了谁? |
| 记忆口诀 | "看大盘" | "看体检" | "翻账本" |
💡 一句话区分:
大集中:央行问"全国经济怎么样?" → 宏观
1104:监管问"银行有没有风险?" → 中观
EAST:监管问"这笔违规怎么查?" → 微观
三、大集中的核心内容
1️⃣ 核心报表
| 报表类型 | 示例内容 | 用途 |
|---|---|---|
| 存贷款统计 | 本外币存款余额、贷款余额 | 看信贷规模 |
| 分行业贷款 | 房地产贷款、制造业贷款、普惠金融贷款 | 看资金流向 |
| 分地区统计 | 各省/市存款贷款分布 | 看区域经济 |
| 利率统计 | 贷款加权平均利率 | 看货币政策传导 |
2️⃣ 核心指标
text
M0(流通中现金)
M1(狭义货币 = M0 + 企业活期存款)
M2(广义货币 = M1 + 准货币)
社会融资规模(社融)
人民币贷款增量
存款准备金率示例 :"央行每个月发布的金融统计数据,比如M2增速、人民币贷款增量,源头就是大集中系统。"
3️⃣ 与项目的关系
| 数仓模块 | 对应大集中统计 |
|---|---|
| 存款账户汇总 | 存款余额统计 |
| 贷款合同明细 | 贷款增量、分行业贷款 |
| 客户信息表 | 分地区、分企业类型统计 |
| 利率字段 | 贷款利率统计 |
示例 :
"大集中需要分行业的贷款统计,我们数仓里贷款合同表有'贷款投向行业'字段,按这个字段GROUP BY汇总,就能出分行业贷款表。我们也会确保这个字段的枚举值对齐央行的行业分类标准。"
四、大集中的报送流程(简化版)
与EAST的区别 :大集中一般用监管平台上传 (网络),EAST大文件用硬盘拷贝。
五、口述(1分30秒版)
"大集中是人民银行建立的金融统计大集中系统,所有银行业金融机构把统计数据直接报给央行总行。
它和1104、EAST的区别在于:1104看银行风险,EAST查违规明细,而大集中是看宏观经济的,为央行制定货币政策服务。比如每个月发布的M2增速、人民币贷款增量,源头就是大集中。
我们数仓会按央行的统计口径加工数据,比如分行业的贷款余额、分地区的存款分布,这些最终会汇总到大集中的报表里。报送频率一般是月报,通过央行的报送平台上传统计文件。
简单说:大集中回答的是'全国经济怎么样',1104回答的是'银行有没有病',EAST回答的是'谁干了违规的事'。"
六、追问
Q1:大集中和1104会不会数据重复?
"会有重叠但不完全相同。比如不良贷款余额,1104要报,大集中也要报。但两个系统的统计口径可能不一样:1104按监管五级分类,大集中可能按逾期天数。我们数仓会维护两套口径,分别加工。"
Q2:大集中的校验规则有哪些?
*"主要是逻辑校验。比如:全国贷款增量 = 各省贷款增量之和;各项存款 + 各项贷款不能超过总资产。还有波动校验:如果某分行贷款环比增长超过50%,会触发预警。"*
Q3:大集中和EAST哪个更急?
*"都急,但大集中对时效性要求更高。因为央行每月中旬要发布金融统计数据,所以大集中的报送截止时间通常在次月5-7号,比EAST早。我们调度设计时会把大集中排在最前面。"*
七、大集中 + 1104 + EAST 速记表
| 维度 | 大集中 | 1104 | EAST |
|---|---|---|---|
| 谁管的 | 人民银行 | 金融监管总局 | 金融监管总局 |
| 看什么 | 宏观经济 | 银行风险 | 违规细节 |
| 数据粒度 | 汇总+部分明细 | 汇总报表 | 明细流水 |
| 典型输出 | M2、社融、贷款增量 | 不良率、资本充足率 | 交易流水、资金链 |
| 报送方式 | 平台上传 | 平台上传 | 硬盘拷贝 |
| 截止时间 | 次月5-7号 | 次月10号 | 次月中下旬 |
| 一句话 | 国家经济体温计 | 银行体检报告 | 银行账本原件 |
八、关键词
text
大集中系统、人民银行、金融统计、M2、社融、存款贷款统计
分行业贷款、货币政策、统计口径对齐、监管报送、校验规则九、终极一句话总结
大集中看大盘(宏观),1104看银行(中观),EAST看细节(微观)。三个系统合起来,监管就能全方位掌握金融体系的健康状况。
大集中 vs 1104 vs EAST 三系统对比表
一句话总结:大集中看宏观(央行管经济),1104看中观(总局管银行风险),EAST看微观(总局查违规细节)。
一、核心对比总表
| 对比维度 | 大集中 | 1104工程 | EAST系统 |
|---|---|---|---|
| 监管机构 | 中国人民银行 | 金融监管总局(原银监会) | 金融监管总局(原银监会) |
| 系统全称 | 金融统计大集中系统 | 非现场监管报表体系 | 现场检查分析系统 |
| 启动时间 | 2000年代(早期统计)→ 2010年后大集中 | 2006年 | 2012年(EAST 1.0)→ 2024(EAST 5.0) |
| 法规依据 | 《金融统计管理规定》 | 银监发〔2006〕1104号 | 银监办发〔2012〕XX号 |
| 数据粒度 | 汇总指标 + 部分明细 | 汇总报表 | 明细流水 |
| 数据量级 | MB ~ GB | KB ~ MB | GB ~ TB |
| 报送频率 | 月报、季报、年报、旬报(部分) | 月报、季报、半年报、年报 | 季报为主,部分月报 |
| 报送方式 | 监管平台上传 | 监管平台上传 | 加密硬盘物理拷贝 |
| 截止时间 | 次月5-7号(最急) | 次月10-15号 | 次月中下旬 |
| 核心用途 | 货币政策制定、宏观分析 | 银行日常风险监控 | 现场检查、违规线索发现 |
| 关注问题 | M2多少?贷款增了多少? | 不良率多少?资本充足吗? | 谁违规放贷?谁以贷养贷? |
| 典型用户 | 央行统计司 | 总局/各地监管科室 | 总局/各地现场检查处 |
| 数据来源 | 银行资产负债、信贷台账 | 银行全量业务报表 | 银行核心交易系统 |
| 是否有明细 | 少量(按地区/行业/企业规模) | 无 | 全部明细 |
| 校验重点 | 逻辑勾稽、与历史可比 | 口径正确、波动合理 | 完整、规范、可追溯 |
| 记忆口诀 | 看大盘 | 看体检 | 翻账本 |
二、三个系统的定位关系图
┌─────────────────────────────────────────────────────────────┐
│ 中国金融监管体系 │
├─────────────────────────────────────────────────────────────┤
│ │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ 人民银行(货币政策) │ │
│ │ ↓ │ │
│ │ 大集中系统 │ │
│ │ "全国经济体温计" │ │
│ │ M2、社融、贷款增量、利率 │ │
│ └─────────────────────────────────────────────────────┘ │
│ │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ 金融监管总局(机构监管) │ │
│ │ ↓ │ │
│ │ ┌─────────────────┐ ┌─────────────────────┐ │ │
│ │ │ 1104工程 │ │ EAST系统 │ │ │
│ │ │ "银行体检报告" │ │ "银行账本原件" │ │ │
│ │ │ 不良率、资本率 │ │ 明细流水、资金链 │ │ │
│ │ └─────────────────┘ └─────────────────────┘ │ │
│ └─────────────────────────────────────────────────────┘ │
│ │
└─────────────────────────────────────────────────────────────┘三、数据粒度对比(举例说明)
| 场景 | 大集中 | 1104 | EAST |
|---|---|---|---|
| 不良贷款 | 全行业不良贷款总额 | 工行不良贷款余额 | 张三那笔10万元的借据,五级分类=次级 |
| 贷款流向 | 房地产贷款总额 | 房地产贷款占比 | 李四贷款发放后第3天 转给某某房产公司 |
| 客户信息 | 大型企业贷款户数/金额 | 前十大客户集中度 | 王**(脱敏后)身份证号、手机号、住址 |
| 存款 | 全国居民存款总额 | 工行个人存款余额 | 赵某账户每笔存取明细 |
| 利率 | 贷款加权平均利率 | 各期限贷款利率区间 | 某笔合同的实际执行利率、浮动方式 |
四、报送流程对比
| 步骤 | 大集中 | 1104 | EAST |
|---|---|---|---|
| 数据准备 | 数仓按统计口径加工 | 数仓按监管口径加工 | 数仓按明细标准加工 |
| 校验 | 逻辑校验 + 历史可比 | 五级校验 + 波动分析 | 完整性+规范性+勾稽+波动 |
| 补录 | 较少(统计字段较全) | 较少 | 经常需要(字段不全) |
| 报送方式 | 平台上传(网络) | 平台上传(网络) | 硬盘物理拷贝 |
| 接收方 | 央行统计司 | 总局/属地监管局 | 总局现场检查处 |
| 时效要求 | 最严(次月7号前) | 较严(次月10-15号) | 相对宽松(次月中下旬) |
五、三者关系速记卡
┌─────────────────────────────────────────────────────────┐
│ 一句话记三个 │
├─────────────────────────────────────────────────────────┤
│ │
│ 🏦 大集中:央行问 "全国经济怎么样?" │
│ → 回答:M2增长8%,贷款新增2万亿 │
│ │
│ 🏛️ 1104:监管问 "银行有没有风险?" │
│ → 回答:不良率1.5%,资本充足率12% │
│ │
│ 🔍 EAST:监管问 "这笔违规贷款怎么查出来的?" │
│ → 回答:查了交易流水,发现钱进了房地产公司 │
│ │
└─────────────────────────────────────────────────────────┘六、与项目的关联
| 数仓产出 | 大集中 | 1104 | EAST |
|---|---|---|---|
| 存款账户汇总表 | ✅ 存款余额统计 | ✅ G01资产负责表 | ❌ |
| 贷款合同明细表 | ✅ 分行业/地区贷款 | ✅ G11五级分类 | ✅ 贷款明细接口 |
| 交易流水表 | ❌ | ❌ | ✅ 交易流水接口 |
| 客户信息表 | ✅ 分企业规模 | ✅ 大额客户 | ✅ 客户信息接口 |
| 逾期统计表 | ❌ | ✅ G12迁徙率 | ✅ 逾期明细 |
| 利率表 | ✅ 利率统计 | ✅ G03利率表 | ❌ |
示例 :
"数仓会同时服务这三个系统:存款汇总表给大集中出M2和存款统计,贷款明细给1104出五级分类和不良率,交易流水和客户明细给EAST出资金流向监控。不同的系统,不同的加工口径,我们会在DWS层按主题分别建模。"
七、追问
Q:三个系统中,哪个对数据质量要求最高?
"EAST要求最高,因为它是明细数据,一笔错了会影响整个检查结果。而且EAST数据要留存多年,监管随时可能回溯查几年前的问题。大集中和1104是汇总数,有一定的容错空间,但勾稽关系必须平。"
Q:哪个系统最消耗计算资源?
"EAST,没有之一。一张交易流水表可能就是几十亿行,要在规定时间内加工完,对Hive/Spark性能要求很高。我们做过优化,把表按时间分区、用ORC列存储、做数据倾斜处理,才把跑批时间压进窗口。"
Q:如果三个系统的数据对不上,以哪个为准?
"分场景。如果是货币政策的宏观数据,以大集中 为准;如果是银行风险评级,以1104 为准;如果是现场检查发现问题,以EAST明细为准。理论上三个系统的底层数据源是一致的,口径不同会导致差异。我们会维护一份'差异说明书',解释哪些差异是合理的。"
八、关键词
text
# 大集中关键词
人民银行、金融统计、货币政策、M0/M1/M2、社会融资规模
存款贷款统计、分行业贷款、利率统计、宏观审慎
# 1104关键词
非现场监管、不良贷款、五级分类、资本充足率、流动性
G01/G11/G12、监管指标、风险监控、审慎监管
# EAST关键词
现场检查、交易流水、资金流向、明细数据、脱敏加密
以贷养贷、硬盘报送、数据字典、校验规则、EAST5.0九、终极总结(5秒记忆)
大集中 = 央行看大盘
1104 = 总局看体检
EAST = 总局翻账本
三个一起看 = 全方位监管