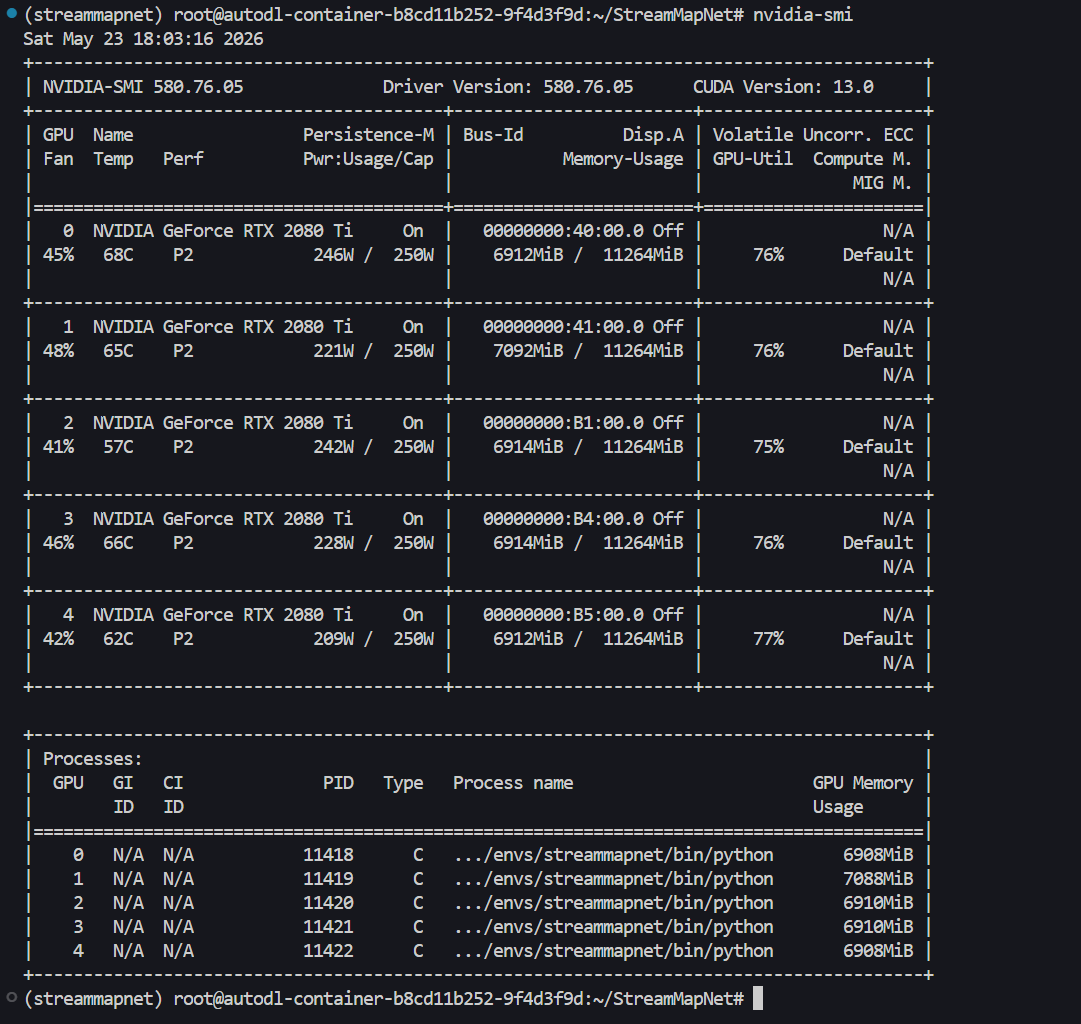
其中下载的是mini数据集,注意分割命令为
bash
#准备数据代码
python tools/data_converter/nuscenes_converter.py \
> --data-root ./datasets/nuScenes \
> --version v1.0-mini \
> --newsplit
# 训练代码
bash tools/dist_train.sh plugin/configs/nusc_newsplit_480_60x30_24e.py 5
# 评估代码
bash tools/dist_train.sh plugin/configs/nusc_newsplit_480_60x30_24e.py 5数据集下载命令
bash
wget https://d36yt3mvayqw5m.cloudfront.net/public/v1.0/v1.0-mini.tgz
wget https://d36yt3mvayqw5m.cloudfront.net/public/v1.0/nuScenes-map-expansion-v1.3.zip
mkdir -p datasets
mkdir -p datasets/nuscenes
tar -xzf v1.0-mini.tgz -C datasets/nuscenes
unzip nuScenes-map-expansion-v1.3.zip -d datasets
mv data/expansion data/nuscenes/maps
mv data/prediction data/nuscenes/maps
mv data/basemap data/nuscenes/maps
bash
pip uninstall timm -y
pip install timm==0.6.13
pip install av2==0.2.1
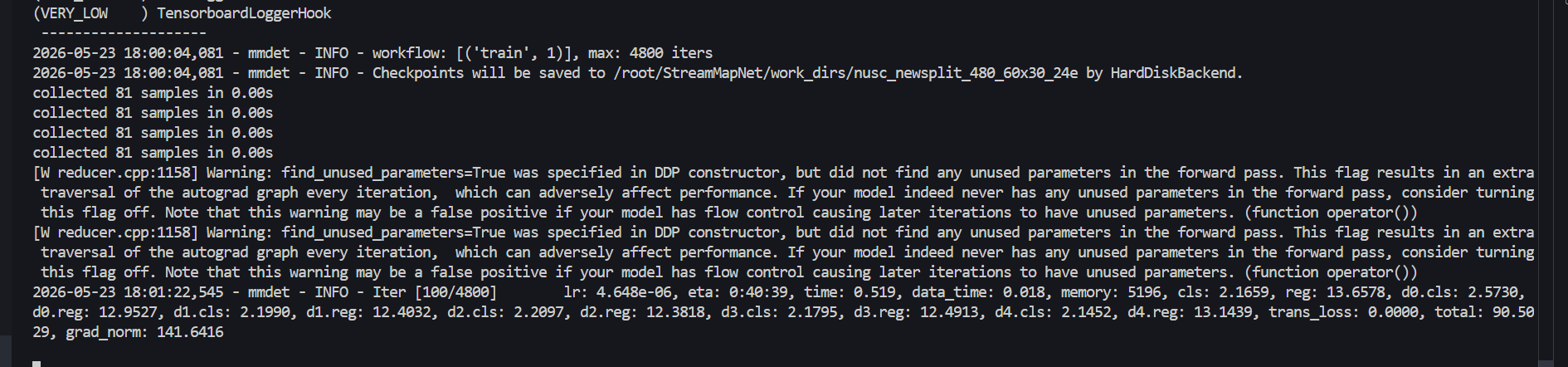
pip install yapf==0.32.0训练截图
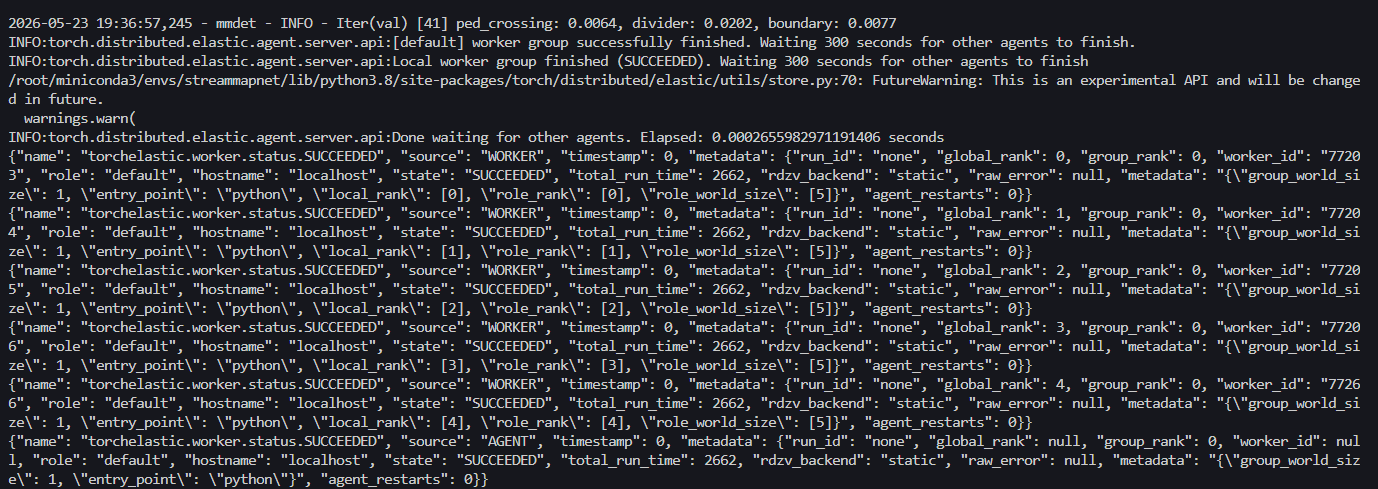
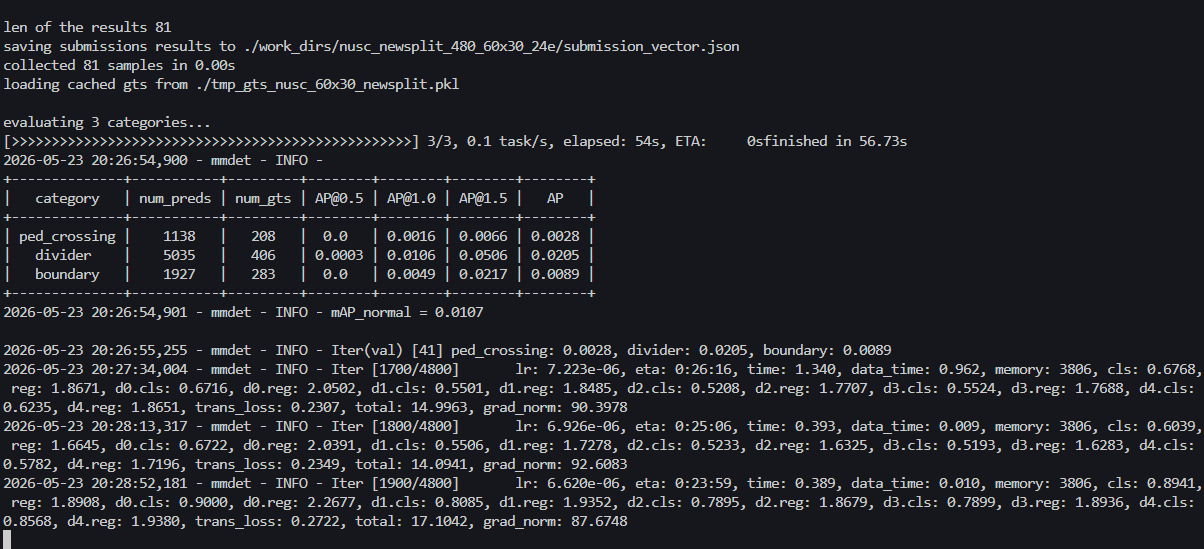
测试截图
修改配置文件,适配GPU数量
重点修改内容为
python
num_gpus = 5
batch_size = 1
num_iters_per_epoch = 150
num_epochs = 24
python
_base_ = [
'./_base_/default_runtime.py'
]
# model type
type = 'Mapper'
plugin = True
# plugin code dir
plugin_dir = 'plugin/'
# img configs
img_norm_cfg = dict(
mean=[103.530, 116.280, 123.675], std=[1.0, 1.0, 1.0], to_rgb=False)
img_h = 480
img_w = 800
img_size = (img_h, img_w)
num_gpus = 5
batch_size = 1
num_iters_per_epoch = 200
num_epochs = 24
num_epochs_single_frame = num_epochs // 6
total_iters = num_epochs * num_iters_per_epoch
num_queries = 100
# category configs
cat2id = {
'ped_crossing': 0,
'divider': 1,
'boundary': 2,
}
num_class = max(list(cat2id.values())) + 1
# bev configs
roi_size = (60, 30) # bev range, 60m in x-axis, 30m in y-axis
bev_h = 50
bev_w = 100
pc_range = [-roi_size[0]/2, -roi_size[1]/2, -3, roi_size[0]/2, roi_size[1]/2, 5]
# vectorize params
coords_dim = 2
sample_dist = -1
sample_num = -1
simplify = True
# meta info for submission pkl
meta = dict(
use_lidar=False,
use_camera=True,
use_radar=False,
use_map=False,
use_external=False,
output_format='vector')
# model configs
bev_embed_dims = 256
embed_dims = 512
num_feat_levels = 3
norm_cfg = dict(type='BN2d')
num_class = max(list(cat2id.values()))+1
num_points = 20
permute = True
model = dict(
type='StreamMapNet',
roi_size=roi_size,
bev_h=bev_h,
bev_w=bev_w,
backbone_cfg=dict(
type='BEVFormerBackbone',
roi_size=roi_size,
bev_h=bev_h,
bev_w=bev_w,
use_grid_mask=True,
img_backbone=dict(
type='ResNet',
with_cp=False,
# pretrained='./resnet50_checkpoint.pth',
pretrained='open-mmlab://detectron2/resnet50_caffe',
depth=50,
num_stages=4,
out_indices=(1, 2, 3),
frozen_stages=-1,
norm_cfg=norm_cfg,
norm_eval=True,
style='caffe',
dcn=dict(type='DCNv2', deform_groups=1, fallback_on_stride=False),
stage_with_dcn=(False, False, True, True)),
img_neck=dict(
type='FPN',
in_channels=[512, 1024, 2048],
out_channels=bev_embed_dims,
start_level=0,
add_extra_convs=True,
num_outs=num_feat_levels,
norm_cfg=norm_cfg,
relu_before_extra_convs=True),
transformer=dict(
type='PerceptionTransformer',
embed_dims=bev_embed_dims,
encoder=dict(
type='BEVFormerEncoder',
num_layers=1,
pc_range=pc_range,
num_points_in_pillar=4,
return_intermediate=False,
transformerlayers=dict(
type='BEVFormerLayer',
attn_cfgs=[
dict(
type='TemporalSelfAttention',
embed_dims=bev_embed_dims,
num_levels=1),
dict(
type='SpatialCrossAttention',
deformable_attention=dict(
type='MSDeformableAttention3D',
embed_dims=bev_embed_dims,
num_points=8,
num_levels=num_feat_levels),
embed_dims=bev_embed_dims,
)
],
feedforward_channels=bev_embed_dims*2,
ffn_dropout=0.1,
operation_order=('self_attn', 'norm', 'cross_attn', 'norm',
'ffn', 'norm')
)
),
),
positional_encoding=dict(
type='LearnedPositionalEncoding',
num_feats=bev_embed_dims//2,
row_num_embed=bev_h,
col_num_embed=bev_w,
),
),
head_cfg=dict(
type='MapDetectorHead',
num_queries=num_queries,
embed_dims=embed_dims,
num_classes=num_class,
in_channels=embed_dims//2,
num_points=num_points,
roi_size=roi_size,
coord_dim=2,
different_heads=False,
predict_refine=False,
sync_cls_avg_factor=True,
streaming_cfg=dict(
streaming=True,
batch_size=batch_size,
topk=int(num_queries*(1/3)),
trans_loss_weight=0.1,
),
transformer=dict(
type='MapTransformer',
num_feature_levels=1,
num_points=num_points,
coord_dim=2,
encoder=dict(
type='PlaceHolderEncoder',
embed_dims=embed_dims,
),
decoder=dict(
type='MapTransformerDecoder_new',
num_layers=6,
prop_add_stage=1,
return_intermediate=True,
transformerlayers=dict(
type='MapTransformerLayer',
attn_cfgs=[
dict(
type='MultiheadAttention',
embed_dims=embed_dims,
num_heads=8,
attn_drop=0.1,
proj_drop=0.1,
),
dict(
type='CustomMSDeformableAttention',
embed_dims=embed_dims,
num_heads=8,
num_levels=1,
num_points=num_points,
dropout=0.1,
),
],
ffn_cfgs=dict(
type='FFN',
embed_dims=embed_dims,
feedforward_channels=embed_dims*2,
num_fcs=2,
ffn_drop=0.1,
act_cfg=dict(type='ReLU', inplace=True),
),
feedforward_channels=embed_dims*2,
ffn_dropout=0.1,
# operation_order=('norm', 'self_attn', 'norm', 'cross_attn',
# 'norm', 'ffn',)
operation_order=('self_attn', 'norm', 'cross_attn', 'norm',
'ffn', 'norm')
)
)
),
loss_cls=dict(
type='FocalLoss',
use_sigmoid=True,
gamma=2.0,
alpha=0.25,
loss_weight=5.0
),
loss_reg=dict(
type='LinesL1Loss',
loss_weight=50.0,
beta=0.01,
),
assigner=dict(
type='HungarianLinesAssigner',
cost=dict(
type='MapQueriesCost',
cls_cost=dict(type='FocalLossCost', weight=5.0),
reg_cost=dict(type='LinesL1Cost', weight=50.0, beta=0.01, permute=permute),
),
),
),
streaming_cfg=dict(
streaming_bev=True,
batch_size=batch_size,
fusion_cfg=dict(
type='ConvGRU',
out_channels=bev_embed_dims,
)
),
model_name='SingleStage'
)
# data processing pipelines
train_pipeline = [
dict(
type='VectorizeMap',
coords_dim=coords_dim,
roi_size=roi_size,
sample_num=num_points,
normalize=True,
permute=permute,
),
dict(type='LoadMultiViewImagesFromFiles', to_float32=True),
dict(type='PhotoMetricDistortionMultiViewImage'),
dict(type='ResizeMultiViewImages',
size=img_size, # H, W
change_intrinsics=True,
),
dict(type='Normalize3D', **img_norm_cfg),
dict(type='PadMultiViewImages', size_divisor=32),
dict(type='FormatBundleMap'),
dict(type='Collect3D', keys=['img', 'vectors'], meta_keys=(
'token', 'ego2img', 'sample_idx', 'ego2global_translation',
'ego2global_rotation', 'img_shape', 'scene_name'))
]
# data processing pipelines
test_pipeline = [
dict(type='LoadMultiViewImagesFromFiles', to_float32=True),
dict(type='ResizeMultiViewImages',
size=img_size, # H, W
change_intrinsics=True,
),
dict(type='Normalize3D', **img_norm_cfg),
dict(type='PadMultiViewImages', size_divisor=32),
dict(type='FormatBundleMap'),
dict(type='Collect3D', keys=['img'], meta_keys=(
'token', 'ego2img', 'sample_idx', 'ego2global_translation',
'ego2global_rotation', 'img_shape', 'scene_name'))
]
# configs for evaluation code
# DO NOT CHANGE
eval_config = dict(
type='NuscDataset',
data_root='./datasets/nuScenes',
ann_file='./datasets/nuScenes/nuscenes_map_infos_val_newsplit.pkl',
meta=meta,
roi_size=roi_size,
cat2id=cat2id,
pipeline=[
dict(
type='VectorizeMap',
coords_dim=coords_dim,
simplify=True,
normalize=False,
roi_size=roi_size
),
dict(type='FormatBundleMap'),
dict(type='Collect3D', keys=['vectors'], meta_keys=['token'])
],
interval=1,
)
# dataset configs
data = dict(
samples_per_gpu=batch_size,
workers_per_gpu=4,
train=dict(
type='NuscDataset',
data_root='./datasets/nuScenes',
ann_file='./datasets/nuScenes/nuscenes_map_infos_train_newsplit.pkl',
meta=meta,
roi_size=roi_size,
cat2id=cat2id,
pipeline=train_pipeline,
seq_split_num=1,
),
val=dict(
type='NuscDataset',
data_root='./datasets/nuScenes',
ann_file='./datasets/nuScenes/nuscenes_map_infos_val_newsplit.pkl',
meta=meta,
roi_size=roi_size,
cat2id=cat2id,
pipeline=test_pipeline,
eval_config=eval_config,
test_mode=True,
seq_split_num=1,
),
test=dict(
type='NuscDataset',
data_root='./datasets/nuScenes',
ann_file='./datasets/nuScenes/nuscenes_map_infos_val_newsplit.pkl',
meta=meta,
roi_size=roi_size,
cat2id=cat2id,
pipeline=test_pipeline,
eval_config=eval_config,
test_mode=True,
seq_split_num=1,
),
shuffler_sampler=dict(
type='InfiniteGroupEachSampleInBatchSampler',
seq_split_num=1,
num_iters_to_seq=num_epochs_single_frame*num_iters_per_epoch,
random_drop=0.0
),
nonshuffler_sampler=dict(type='DistributedSampler')
)
# optimizer
optimizer = dict(
type='AdamW',
lr=1e-4,
paramwise_cfg=dict(
custom_keys={
'img_backbone': dict(lr_mult=0.1),
}),
weight_decay=1e-2)
optimizer_config = dict(grad_clip=dict(max_norm=35, norm_type=2))
# learning policy & schedule
lr_config = dict(
policy='CosineAnnealing',
warmup='linear',
warmup_iters=500,
warmup_ratio=1.0 / 3,
min_lr_ratio=3e-3)
evaluation = dict(interval=num_epochs_single_frame*num_iters_per_epoch)
find_unused_parameters = True #### when use checkpoint, find_unused_parameters must be False
checkpoint_config = dict(interval=num_epochs_single_frame*num_iters_per_epoch)
runner = dict(
type='IterBasedRunner', max_iters=num_epochs * num_iters_per_epoch)
log_config = dict(
interval=100,
hooks=[
dict(type='TextLoggerHook'),
dict(type='TensorboardLoggerHook')
])
SyncBN = True成功用5张2080显卡,python3.8,ubuntu20,04的环境对mini dataset进行训练