想象你是一家电商公司的数据分析师。每天有大量数据进入数据库:用户订单、商品库存、用户行为日志等。如果数据有问题(比如订单金额是负数、用户邮箱格式错误、同一订单号出现两次),你的分析结果就是错的,业务决策也会出错。
概念和理论
数据质量管理就是一套方法和工具,用来:
- 定义规则:比如"邮箱必须符合格式"、"订单金额必须大于0"
- 自动检查:用程序定期扫描数据,找出不符合规则的记录
- 记录结果:保存每次检查的结果,方便追溯和汇报
OpenMetadata
OpenMetadata(OM) 是一个数据目录平台。可以把它理解为一个"数据库的数据库",它记录所有数据库的元信息:
- 有多少个数据库?叫什么名字?
- 每个库里有哪些表?每个表有哪些列?
- 表之间的血缘关系是什么?(比如表A的数据来自表B)
- 谁在用这些数据?多久没更新了?
还会保存数据质量检查的结果,这正是我们集成 Great Expectations 的原因。
对比 Hive Metastore
那么OpenMetadata 能替代 Hive Metastore 吗?不能直接替代,但可以同步。
Hive Metastore 不只是"存元数据",它是 Hadoop 生态的基础设施 ,Hive/Spark/Trino 通过 Thrift RPC 调用 Metastore,这是硬编码的协议。
Hive Metastore 职责
存储表定义
列名/类型/分区
存储数据位置
HDFS/S3 路径
存储序列化格式
ORC/Parquet
提供 Thrift RPC
供引擎调用
Hive
Spark
Trino
OpenMetadata 则是用来"看"数据的。正确的架构是两者并存,例如下图
元数据层
计算层
数据层
Thrift RPC
Thrift RPC
Thrift RPC
同步
SQL 查询
搜索/血缘
HDFS/S3
Hive
Spark
Trino
Hive Metastore
Thrift 接口
OpenMetadata
REST API
BI 工具
数据治理
如何将mestore同步到openmetadata?
yaml
# 摄取配置:hive-metastore-ingestion.yaml
source:
type: Hive
serviceName: hive-metastore-prod
serviceConnection:
config:
type: Hive
hostPort: hive-metastore:9083 # Thrift 端口
metastoreConnection: thrift://hive-metastore:9083
sink:
type: metadata-rest
config: {}
workflowConfig:
openMetadataServerConfig:
hostPort: http://localhost:8585/api运行同步指令
bash
metadata ingest -c hive-metastore-ingestion.yaml同步后OM 中会有:
- 所有数据库和表
- 表的分区信息
- 列的类型定义
- 数据位置(HDFS/S3 路径)
Great Expectations
Great Expectations(GX) 是一个 Python 数据质量检查框架。"Expectation"的意思是"期望"------你告诉它"我期望邮箱列不为空",它就会检查数据是否满足这个期望。
- 读取数据,检查每一行的 email 列,统计有多少行是空的
- 返回结果:通过/失败,失败的数量,失败的比例
python
suite.add_expectation(
gx.expectations.ExpectColumnValuesToNotBeNull(column="email")
)为什么要使用 GX?
- 不用写 SQL,用简单的 Python API 定义规则
- 自动生成检查报告
- 有 300+ 种内置期望规则
- 与 OpenMetadata 无缝集成
GX和OpenMetadata集成的具体流程
- 在 GX 里写好规则(比如"邮箱不能为空")
- GX 检查 PostgreSQL 中的数据
- GX 把检查结果推送到 OM
- 打开 OM 的网页,看到仪表盘上有红色/绿色的测试结果
下图说明了本文涉及到的所有组件关系
第三步:展示结果
第二步:检查数据质量
第一步:存储数据
读取数据
发送检查结果
存储
搜索
查看
PostgreSQL
存业务数据
端口 5433
Great Expectations
Python 脚本
OpenMetadata Server
端口 8585
MySQL
存元数据
端口 3307
OpenSearch
搜索引擎
端口 9202
网页界面
OpenMetadata需要 MySQL 和 OpenSearch
- MySQL,把"有哪些数据库"、"每个表的列信息"存在 MySQL 里。
- OpenSearch,当在 OM 网页里搜索"用户表"时,是 OpenSearch 在帮忙快速查找。
因此,OM Server 启动前,MySQL 必须已经准备好,数据库迁移必须在 Server 启动前完成(迁移就是创建 OM 需要的表结构)。此外,GX 检查前,OM 必须知道有这张表(否则 GX 的结果无处存放)
数据库迁移
例如以下场景:开发了一个应用,第一版只需要一张 users 表。第二版加了 orders 表。第三版改了 users 表的结构,加了一个 phone 列。怎么让数据库从第一版升级到第三版?手动执行 SQL 脚本?那如果生产环境已经是第二版了呢?
数据库迁移就是一套自动化的数据库版本管理机制。每个版本对应一个迁移脚本,系统会记录当前是哪个版本,然后自动执行未运行的脚本。
版本 迁移脚本内容
----------- ---------------------------
V001 CREATE TABLE users (...)
V002 CREATE TABLE orders (...)
V003 ALTER TABLE users ADD phone VARCHAR(20)在 OM 启动过程中可能会出现如下错误,这说明数据库里缺少某些表。必须先运行迁移,才能启动服务。
ERROR: There are pending migrations to be run on the database.OM 官方提供了一个
openmetadata/db:1.12.0镜像,但这个镜像有个问题:它里面已经创建了一些表(Flowable 工作流引擎的ACT_*表)。当运行迁移时,迁移脚本会尝试创建这些表,发现表已存在就报错:
Table 'ACT_GE_PROPERTY' already exists我们不用官方 db 镜像,改用标准空的 MySQL 镜像(如
mysql:8.2),让迁移脚本从头创建所有表。
OpenMetadata 的数据模型层级
OM 用"层级"来组织数据的元信息。就像文件夹结构一样。OM 的层级是:
DatabaseService(数据库服务)
└── Database(数据库)
└── DatabaseSchema(模式)
└── Table(表)
└── Column(列)为什么要有这么多层级?
- DatabaseService:可能有好几个数据库(PostgreSQL、MySQL、Oracle),每个都是一个 Service
- Database:一个 PostgreSQL 里可以有好几个库(testdb、production、analytics)
- Schema:PostgreSQL 的概念,类似文件夹,把表分组(public 是默认 schema)
- Table:就是具体的表
- Column:表的列
每一层都有名字,组合起来就是 FQN,唯一标识一个实体,表的 FQN = test-postgres.testdb.public.users= 服务名.库名.schema名.表名
GX 推送检查结果到 OM 时,必须告诉 OM "这是哪张表的检查结果"。用的就是 FQN。
Great Expectations 核心概念
数据
Checkpoint
执行 Expectations
生成结果
Action: 推送到 OM
Expectation
就是一条数据质量规则。例如:
- ExpectColumnValuesToNotBeNull:列数据不能为空
- ExpectColumnValuesToBeUnique:列数据不可重复
- ExpectColumnValuesToMatchRegex:列数据符合正则格式
ExpectationSuite是一组期望的集合。比如针对 users 表,我们有 3 个期望:
python
suite = ExpectationSuite(name="users_suite")
suite.add_expectation(ExpectationValuesToNotBeNull(column="email"))
suite.add_expectation(ExpectColumnValuesToBeUnique(column="id"))
suite.add_expectation(ExpectColumnValuesToMatchRegex(column="email", regex=".*@.*"))Checkpoint
执行检查的入口。它的作用是:
- 连接数据库,读取数据
- 运行期望套件里的所有期望
- 把结果交给 Action 处理
Action
检查完成后的后续操作。常用的 Action:
ExpectationStore: 把结果保存到本地文件OpenMetadataValidationAction1xx: 把结果推送到 OpenMetadata
GX 的工作流程用代码理解如下
python
# 第一步:准备数据(告诉 GX 数据在哪里)
data_source = context.data_sources.add_postgres(name="my_db", connection_string="...")
data_asset = data_source.add_table_asset(name="my_table", table_name="users")
batch_definition = data_asset.add_batch_definition_whole_table("full_table")
# 第二步:准备规则(告诉 GX 检查什么)
suite = context.suites.add(ExpectationSuite(name="my_suite"))
suite.add_expectation(ExpectColumnValuesToNotBeNull(column="email"))
# 第三步:绑定数据和规则
validation = context.validation_definitions.add(
ValidationDefinition(name="my_validation", data=batch_definition, suite=suite)
)
# 第四步:执行检查
checkpoint = context.checkpoints.add(
Checkpoint(name="my_checkpoint", validation_definitions=[validation], actions=[...])
)
result = checkpoint.run()多数据源与血缘关系
前面的例子只有一个 PostgreSQL。但现实中,数据往往分散在多个系统,不同数据源需要不同的处理方式:
| 数据源类型 | 处理工具 | 原因 |
|---|---|---|
| 关系数据库(MySQL/PG/Oracle) | DataX | 结构化数据,直接同步 |
| 对象存储(S3/MinIO 文件) | Spark | 需要解析文件格式、处理非结构化数据 |
| 消息队列(Kafka) | Flink | 实时流处理,低延迟 |
| 复杂转换逻辑 | Spark/dbt | SQL 处理不了的场景 |
注意:S3 文件需要经过 Spark 解析才能入库。S3 中存放的是原始文件(CSV、JSON、Parquet),不能直接变成数仓表,必须通过 Spark 读取、解析格式、清洗后再写入。
数据仓库层
调度层(指挥官)
ETL 工具层(真正干活的)
数据源层
调度触发
调度触发
调度触发
结构化同步
结构化同步
写入
文件解析
写入
实时流
写入
MySQL
业务库
PostgreSQL
分析库
S3/MinIO
文件
Kafka
消息队列
DataX
数据同步
Spark
批处理
Flink
实时流
Airflow
调度编排
数据仓库
ClickHouse
Airflow编排任务
Airflow 不做数据抽取,它只负责调度。核心工作是:
- 定时触发任务(每天凌晨 2 点运行)
- 调用真正的 ETL 工具(DataX、Spark、Flink 等)
- 监控任务状态(成功/失败/重试)
- 发送告警(任务失败时通知)
一个典型的 Airflow DAG 示例如下
python
from airflow import DAG
from airflow.operators.bash import BashOperator
from airflow.providers.apache.spark.operators.spark_submit import SparkSubmitOperator
with DAG("daily_etl") as dag:
# 任务1:调用 DataX 同步 MySQL 数据
sync_mysql = BashOperator(
task_id="sync_mysql_to_clickhouse",
bash_command="python /opt/datax/bin/datax.py /jobs/mysql_to_ch.json"
)
# 任务2:调用 Spark 做数据清洗
process_data = SparkSubmitOperator(
task_id="spark_clean",
application="/jobs/clean_data.py"
)
# 任务3:运行质量检查
quality_check = BashOperator(
task_id="quality_check",
bash_command="cd /app && uv run python run_checkpoint.py"
)
# 任务顺序
sync_mysql >> process_data >> quality_check解决了任务的编排,对于复杂的数据流管道,下面的问题是:
- 数据从 A 流到 B,质量检查应该在哪做?
- A 的数据有问题,会影响到 B 吗?
- 多个数据源,检查规则怎么统一管理?
多数据源检查方案
业界最佳实践是在数据生命周期的不同阶段设置检查点:
消费检查
传输检查
源头检查
MySQL 入库前检查
API 数据校验
ETL 行数对比
源 vs 目标
数据完整性校验
数据仓库表检查
报表指标监控
源头检查,不让脏数据进入系统,在应用层做校验,数据写入数据库前拦截:
python
# 在应用写入数据库前检查
def create_user(name, email):
if not email or "@" not in email:
raise ValueError("邮箱格式错误")
db.insert("users", {"name": name, "email": email})传输检查,确保数据完整传输
python
# 方式一:SQL 聚合对比(最轻量)
def check_data_integrity(source_conn, target_conn, table_name):
with source_conn.cursor() as src, target_conn.cursor() as tgt:
src.execute(f"SELECT COUNT(*) FROM {table_name}")
tgt.execute(f"SELECT COUNT(*) FROM {table_name}")
if src.fetchone()[0] != tgt.fetchone()[0]:
return {"passed": False, "error": "行数不一致"}
# 关键指标对比
src.execute(f"SELECT SUM(amount) FROM {table_name}")
tgt.execute(f"SELECT SUM(amount) FROM {table_name}")
if src.fetchone() != tgt.fetchone():
return {"passed": False, "error": "汇总值不一致"}
return {"passed": True}
# 方式二:DataDiff 工具(逐行差异检查)
from datadiff import diff_tables
diff = diff_tables(source_url, target_url, table_name="orders", key_columns=["id"])消费检查,确保分析用正确数据。使用 GX + OM 定期检查数据仓库中的表。
py
suite = ExpectationSuite(name="users_suite")
suite.add_expectation(ExpectationValuesToNotBeNull(column="email"))与 Airflow 集成实现完整 ETL和质量检查流程示例如下,实现质量检查的分层职责
源头检查 GX
通过
不通过
通过
不通过
MySQL 源表
检查通过?
数据同步
阻断 + 告警
传输检查
SQL 聚合对比
ClickHouse 目标表
告警 + 人工介入
消费检查
定期 GX + OM
示例代码
python
from airflow import DAG
from airflow.operators.python import PythonOperator
from airflow.operators.bash import BashOperator
def run_checkpoint(source, table):
"""运行 GX 检查并推送到 OM"""
import great_expectations as gx
# ... checkpoint 代码 ...
def check_row_count():
"""传输检查:对比源和目标的行数"""
source_count = mysql.query("SELECT COUNT(*) FROM orders")
target_count = clickhouse.query("SELECT COUNT(*) FROM orders")
if source_count != target_count:
raise Exception(f"行数不一致: {source_count} vs {target_count}")
with DAG("daily_etl", schedule_interval="@daily") as dag:
# 1. 源头检查(GX)
source_check = PythonOperator(
task_id="source_quality_check",
python_callable=run_checkpoint,
op_kwargs={"source": "mysql_prod", "table": "orders"}
)
# 2. 数据同步
sync_data = BashOperator(
task_id="sync_orders",
bash_command="python /opt/datax/bin/datax.py /jobs/orders.json"
)
# 3. 传输检查(SQL 聚合,不用 GX)
transfer_check = PythonOperator(
task_id="transfer_check",
python_callable=check_row_count
)
# 4. 消费检查(GX + OM)
sink_check = PythonOperator(
task_id="sink_quality_check",
python_callable=run_checkpoint,
op_kwargs={"source": "clickhouse_dwh", "table": "orders"}
)
# 任务顺序:源头检查 → 同步 → 传输检查 → 消费检查
source_check >> sync_data >> transfer_check >> sink_check数据血缘与质量追溯
血缘就是记录数据"从哪来、到哪去"的关系:
订单表(MySQL) ──ETL──→ 订单宽表(数仓) ──SQL──→ 销售报表
│ │ │
└── 数据有问题 ────────┴── 会传播到 ────────┘如果"订单表"的 amount 列有负数,这个问题会传播到所有下游:
- 订单宽表的
total_amount会出错 - 销售报表的"总销售额"会偏低
OM 中的血缘
INSERT INTO
CREATE VIEW
质量检查失败
影响分析
影响分析
users
MySQL
user_stats
PostgreSQL
daily_report
ClickHouse
告警
当 users 表质量检查失败时,OM 会提示:"下游影响:user_stats、daily_report 可能受影响"。
如何在 OM 中建立血缘?通常OM 可以自动解析血缘(例如 dbt 管理 SQL 转换,)
sql
-- models/user_stats.sql
SELECT
u.id,
u.name,
COUNT(o.id) as order_count
FROM {{ ref('users') }} u -- dbt 知道依赖 users
LEFT JOIN {{ ref('orders') }} o ON u.id = o.user_id
GROUP BY u.id, u.nameOM 摄取 dbt 的 manifest.json 后自动建立血缘:users → user_stats,orders → user_stats。
在集成Airflow场景中,OM 还可以解析 Airflow DAG 中的 SQL,自动推断血缘。
环境搭建
OpenSearch 需要设置内核参数设置
bash
echo "vm.max_map_count=262144" | sudo tee -a /etc/sysctl.conf
sudo sysctl -pOpenSearch 内部使用一种叫"mmapfs"的文件系统来存储索引数据。
vm.max_map_count控制进程可以创建的内存映射区域数量。默认值(通常是 65530)太小,OpenSearch 启动时会报错:
max virtual memory areas vm.max_map_count [65530] is too low
Docker Compose 配置
创建一个配置文件来管理所有 OM 组件:
yaml
services:
# OM 的数据库
mysql:
image: mysql:8.2
container_name: om-mysql
restart: unless-stopped
environment:
MYSQL_ROOT_PASSWORD: password
MYSQL_USER: openmetadata_user
MYSQL_PASSWORD: openmetadata_password
MYSQL_DATABASE: openmetadata_db
ports:
- "3307:3306"
volumes:
- om-db-data:/var/lib/mysql
healthcheck:
test: ["CMD", "mysqladmin", "ping", "-h", "localhost"]
interval: 10s
timeout: 5s
retries: 10
networks:
- om-net
# OM 的搜索引擎
opensearch:
image: opensearchproject/opensearch:2.19.1
container_name: om-opensearch
restart: unless-stopped
environment:
- discovery.type=single-node
- DISABLE_SECURITY_PLUGIN=true
- "OPENSEARCH_JAVA_OPTS=-Xms512m -Xmx512m"
- cluster.name=open-metadata
ports:
- "9202:9200"
volumes:
- om-es-data:/usr/share/opensearch/data
healthcheck:
test: ["CMD-SHELL", "curl -s http://localhost:9200/_cluster/health | grep -q '\"status\":\"green\\|yellow\"'"]
interval: 10s
timeout: 5s
retries: 10
networks:
- om-net
# OM 服务器
server:
image: docker.getcollate.io/openmetadata/server:1.12.0
container_name: om-server
restart: unless-stopped
depends_on:
mysql:
condition: service_healthy
opensearch:
condition: service_healthy
environment:
- DB_HOST=mysql
- DB_PORT=3306
- DB_USER=openmetadata_user
- DB_USER_PASSWORD=openmetadata_password
- OM_DATABASE=openmetadata_db
- SEARCH_TYPE=opensearch
- ELASTICSEARCH_HOST=opensearch
- ELASTICSEARCH_PORT=9200
- ELASTICSEARCH_SCHEME=http
- AUTHENTICATION_PROVIDER=basic
- OM_HEAP_SIZE=1G
ports:
- "8585:8585"
healthcheck:
test: ["CMD-SHELL", "curl -s http://localhost:8585/api/v1/system/version"]
interval: 30s
timeout: 10s
retries: 15
start_period: 180s
networks:
- om-net
# 测试用的 PostgreSQL
test-postgres:
image: postgres:15
container_name: test-postgres
restart: unless-stopped
environment:
POSTGRES_PASSWORD: postgres
POSTGRES_DB: testdb
ports:
- "5433:5432"
networks:
- om-net
networks:
om-net:
driver: bridge
volumes:
om-db-data:
om-es-data:一键启动所有服务
bash
docker-compose -f docker-compose.om.yml up -d首次启动时执行openmetadata的迁移命令
bash
# 运行迁移(首次必须)
docker run --rm \
--network om-net \
-e DB_HOST=mysql \
-e DB_PORT=3306 \
-e DB_USER=openmetadata_user \
-e DB_USER_PASSWORD=openmetadata_password \
-e OM_DATABASE=openmetadata_db \
-e SEARCH_TYPE=opensearch \
-e ELASTICSEARCH_HOST=opensearch \
-e ELASTICSEARCH_PORT=9200 \
-e ELASTICSEARCH_SCHEME=http \
-e AUTHENTICATION_PROVIDER=basic \
docker.getcollate.io/openmetadata/server:1.12.0 \
./bootstrap/openmetadata-ops.sh migrate迁移脚本会打印很多日志,关键是看有没有报错:
SERVER_CHANGE_LOG table doesn't exist yet, will run all migrations [MigrationWorkFlow] Migration Run started for Version: 0.0.0 [MigrationWorkFlow] Migration Run finished for Version: 0.0.0 ... [MigrationWorkFlow] Migration Run finished for Version: 1.12.0 Successfully completed如果看到
Table 'ACT_GE_PROPERTY' already exists,说明用了错误的 MySQL 镜像。检查docker images确认使用的是mysql:8.2。
创建测试数据
bash
# 进入 PostgreSQL 容器
docker exec -it test-postgres psql -U postgres -d testdb
# 创建表
CREATE TABLE users (
id SERIAL PRIMARY KEY,
name VARCHAR(100),
email VARCHAR(100),
created_at TIMESTAMP DEFAULT NOW()
);
# 插入数据
INSERT INTO users (name, email) VALUES
('Alice', 'alice@example.com'),
('Bob', 'bob@example.com'),
('Charlie', 'charlie@example.com'),
('Diana', 'diana@example.com'),
('Eve', 'eve@example.com'),
('Frank', 'frank@example.com'),
('Grace', 'grace@example.com');安装python依赖
bash
uv init
uv add great_expectations psycopg2-binary
uv add "openmetadata-ingestion[great-expectations-1xx]"连接 OpenMetadata
OM 使用 JWT 令牌认证。需要先登录获取令牌:
bash
echo -n "admin" | base64 # 输出:YWRtaW4=
curl -X POST http://localhost:8585/api/v1/users/login \
-H "Content-Type: application/json" \
-d '{"email": "admin@open-metadata.org", "password": "YWRtaW4="}' \
| jq -r '.accessToken'创建配置文件
yaml
# 文件:om_config/config.yml(注意是 .yml 不是 .yaml)
hostPort: http://localhost:8585/api
authProvider: basic
apiVersion: v1
securityConfig:
jwtToken: "<刚才获取的令牌>"文件名必须是
config.yml(不是config.yaml)。如果文件名错了,GX 运行时会打印警告:
WARNING - Template file at config.yml not found
securityConfig只接受jwtToken字段。如果你写username和password,会触发 Pydantic 校验错误:
ValidationError: Extra inputs are not permitted
注册表元数据
这是最关键的一步,很多人在这里踩坑。
GX 推送结果到 OM 时,会:
- 用 FQN 查找 OM 中的表
- 如果找到,把测试结果挂在这张表下面
- 如果找不到,静默跳过(不报错,但也没有结果)
所以必须先在 OM 里创建实体
python
import requests
BASE = "http://localhost:8585/api/v1"
resp = requests.post(
f"{BASE}/users/login",
json={"email": "admin@open-metadata.org", "password": "YWRtaW4="}
)
headers = {"Authorization": f"Bearer {resp.json()['accessToken']}"}
# 1. 创建数据库服务
print("创建 DatabaseService...")
resp = requests.post(
f"{BASE}/services/databaseServices",
headers=headers,
json={
"name": "test-postgres",
"serviceType": "Postgres",
"connection": {
"config": {
"type": "Postgres",
"hostPort": "test-postgres:5432",
"database": "testdb"
}
}
}
)
# 2. 创建数据库
print("创建 Database...")
resp = requests.post(
f"{BASE}/databases",
headers=headers,
json={"name": "testdb", "service": "test-postgres"}
)
print(f" 状态: {resp.status_code}")
# 3. 创建 Schema
print("创建 Schema...")
resp = requests.post(
f"{BASE}/databaseSchemas",
headers=headers,
json={"name": "public", "database": "test-postgres.testdb"}
)
print(f" 状态: {resp.status_code}")
# 4. 创建表(注意 VARCHAR 要指定长度)
print("创建 Table...")
resp = requests.post(
f"{BASE}/tables",
headers=headers,
json={
"name": "users",
"databaseSchema": "test-postgres.testdb.public",
"columns": [
{"name": "id", "dataType": "INT"},
{"name": "name", "dataType": "VARCHAR", "dataLength": 100},
{"name": "email", "dataType": "VARCHAR", "dataLength": 100},
{"name": "created_at", "dataType": "TIMESTAMP"}
]
}
)
print(f" 状态: {resp.status_code}")运行:
bash
uv add requests
uv run python register_table.py创建表时如果看到这个错误:
json{"code":400,"message":"For column data types char, varchar, binary, varbinary dataLength must not be null"}说明 VARCHAR 列没有指定长度。OM 要求所有变长类型必须提供
dataLength:
json{"name": "email", "dataType": "VARCHAR", "dataLength": 100}
验证查询表是否存在
bash
curl -s "http://localhost:8585/api/v1/tables/name/test-postgres.testdb.public.users" \
-H "Authorization: Bearer $TOKEN" | jq '.name'编写数据质量检查脚本
python
# 文件:run_checkpoint.py
import os
os.environ['GX_ANALYTICS_ENABLED'] = 'False'
os.environ['GE_ANALYTICS_ENABLED'] = 'False'
import great_expectations as gx
from metadata.great_expectations.action1xx import OpenMetadataValidationAction1xx
# 1. 创建上下文(GX 的入口)
context = gx.get_context()
# 2. 连接数据库
data_source = context.data_sources.add_postgres(
name="test_datasource",
connection_string="postgresql+psycopg2://postgres:postgres@test-postgres:5432/testdb"
)
# 3. 指定要检查的表
data_asset = data_source.add_table_asset(
name="users_table",
table_name="users",
schema_name="public"
)
batch_definition = data_asset.add_batch_definition_whole_table("users_batch")
# 4. 定义期望规则
suite = context.suites.add(
gx.core.expectation_suite.ExpectationSuite(name="users_suite")
)
# 规则1:邮箱不能为空
suite.add_expectation(
gx.expectations.ExpectColumnValuesToNotBeNull(column="email")
)
# 规则2:ID 必须唯一
suite.add_expectation(
gx.expectations.ExpectColumnValuesToBeUnique(column="id")
)
# 规则3:邮箱格式必须正确
suite.add_expectation(
gx.expectations.ExpectColumnValuesToMatchRegex(
column="email",
regex=r"^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}$"
)
)
# 5. 绑定数据和规则
validation_definition = context.validation_definitions.add(
gx.core.validation_definition.ValidationDefinition(
name="users_validation",
data=batch_definition,
suite=suite
)
)
# 6. 配置推送到 OM 的 Action
actions = [
OpenMetadataValidationAction1xx(
database_service_name="test-postgres",
database_name="testdb",
schema_name="public",
table_name="users",
config_file_path="om_config/",
)
]
# 7. 创建检查点
checkpoint = context.checkpoints.add(
gx.checkpoint.checkpoint.Checkpoint(
name="users_checkpoint",
validation_definitions=[validation_definition],
actions=actions
)
)
# 8. 执行
result = checkpoint.run()
print(f"\n检查结果: {'通过' if result.success else '失败'}")
print(f"详细结果: {result}")运行
bash
uv run python run_checkpoint.py成功输出示例
Calculating Metrics: 100%|██████████| 24/24
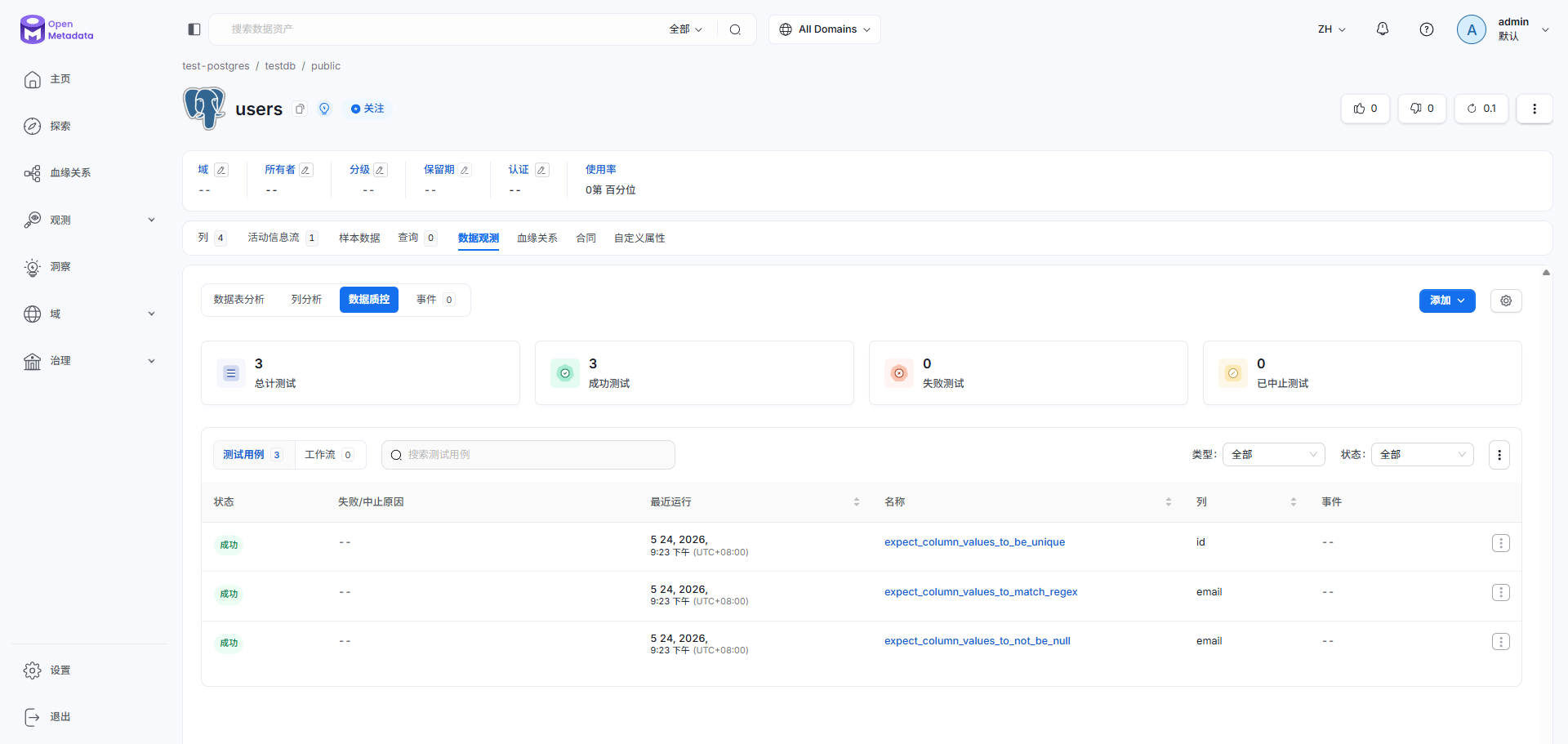
Checkpoint result: True验证结果
检查 OM 中的测试用例
bash
# 获取令牌
TOKEN=$(curl -s -X POST http://localhost:8585/api/v1/users/login \
-H "Content-Type: application/json" \
-d '{"email": "admin@open-metadata.org", "password": "YWRtaW4="}' \
| jq -r '.accessToken')
# 查看测试用例
curl -s "http://localhost:8585/api/v1/dataQuality/testCases?limit=10" \
-H "Authorization: Bearer $TOKEN" | jq '.data[].name'期望输出如下
"expect_column_values_to_not_be_null"
"expect_column_values_to_be_unique"
"expect_column_values_to_match_regex"打开 Web 界面访问数据质控页面