一、前言
在图像检测、文本分类、异常识别、AI 风控等二分类任务中,TP、FP、FN、TN 是评估模型好坏最基础、最核心的四个指标。看懂这四个值,就能算出准确率、精确率、召回率、F1 分数,快速判断模型漏检、误判问题。
二、基础定义(二分类判定规则)
设定两类:
- 正样本 P:目标物体、异常、合格、阳性
- 负样本 N:背景、正常、不合格、阴性
模型只有两种预测结果:预测为正、预测为负,两两组合得到四种结果:
| 符号 | 全称 | 中文名称 | 实际情况 | 模型预测 | 通俗理解 |
|---|---|---|---|---|---|
| TP | True Positive | 真正例 | 正样本 | 预测正 | 猜对目标 |
| FP | False Positive | 假正例 | 负样本 | 预测正 | 误判认错 |
| FN | False Negative | 假负例 | 正样本 | 预测负 | 漏检漏掉 |
| TN | True Negative | 真负例 | 负样本 | 预测负 | 猜对背景 |
预测正(P) 预测负(N)
实际正(P) TP✅ FN❌
实际负(N) FP❌ TN✅
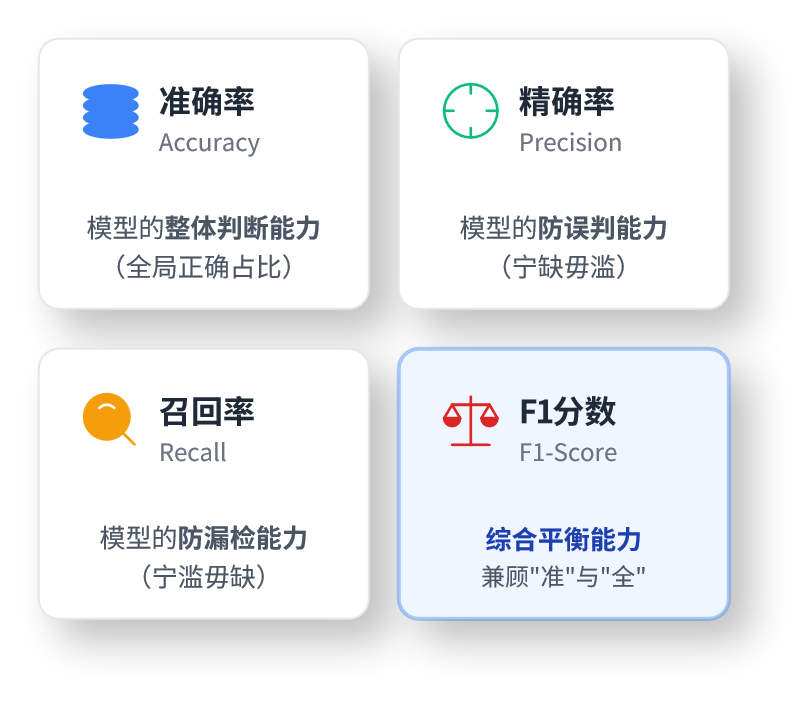
三、四大核心评估指标计算公式
总样本数:\(Total = TP+FP+FN+TN\)
-
准确率 Accuracy整体判断正确的比例\(Accuracy=\frac{TP+TN}{TP+FP+FN+TN}\)
-
精确率 Precision 模型判定为正样本里,真正正确的比例,防误判\(Precision=\frac{TP}{TP+FP}\)
-
召回率 Recall 所有真实正样本中,被成功检出的比例,防漏检\(Recall=\frac{TP}{TP+FN}\)
-
F1-Score精确率和召回率调和平均,综合衡量模型整体性能\(F1=\frac{2\times Precision\times Recall}{Precision+Recall}\)

四、F1-Score
F1分数:精确率与召回率的调和
当我们需要一个综合指标来平衡精确率和召回率时,F1分数就派上用场了。它综合反映了模型的稳健性。
定义:精确率和召回率的调和平均数,更强调二者的均衡性。

特点:取值范围 0,1,越接近1越好。它对P/R中的较低值非常敏感,仅当两者都较高时,F1分数才会高。适合样本不均衡或需兼顾质量与数量的场景。