千行代码, 一步步搭出一个现代 LLM 推理引擎, 掌握大模型推理的每一项关键技术。
本篇你将学到
- 为什么 prefill 与 decode 要分两条路径? --- 不是工程拆分, 是模型本身两种用法的必然
- 为什么 prefill 只取
logits[-1]? --- 因果 attention: 前面位置的"下一个 token"都是已知 prompt - 为什么 decode 是循环 + 拼回去重跑? --- 自回归依赖前一步, 无 cache 时新 token 的 K/V 必须经完整 forward 才能得到
- 每步重算到底浪费了什么? --- 前缀 K/V 的重复计算, 累计 O(N²); 把 K/V 存下来就是下一篇的 KV cache
1. 接上篇: 第 3 篇末尾留下的 4 个问题
第 3 篇第 8 章用 ~15 行代码跑通了"问 Qwen3 你是谁": tokenize → prefill → decode 循环 → detokenize。流程跑通了, 但代码里有 4 个容易产生疑惑的地方。
python
# ① prefill: 一次性, 整段 input_ids 跑一次 forward
with torch.no_grad():
logits = model(input_ids, cos[:len(input_ids)], sin[:len(input_ids)])
next_id = logits[-1].argmax().item() # ② 为什么只取 [-1]?
output_ids = [next_id]
# ③ decode: 循环 + 拼回去 + 整段重跑
for step in range(MAX_NEW_TOKENS - 1):
if next_id == eos: break
input_ids = torch.cat([input_ids, torch.tensor([next_id], device=device)])
with torch.no_grad():
logits = model(input_ids, cos[:len(input_ids)], sin[:len(input_ids)]) # ④ 重算的代价?
next_id = logits[-1].argmax().item()
output_ids.append(next_id)四个问号:
- ① prefill 写一次, decode 写一个循环 --- 为什么不是统一一种? 为什么要分两条路径?
- ②
logits[-1].argmax()--- logits 形状是[L, V], 前面 L-1 行是什么? 为什么扔掉? - ③
input_ids = torch.cat(...)之后又把整段重新 forward 了一次 --- 为什么不能只 forward 那 1 个新 token? - ④ 每一步都重 forward 整段 --- 这能跑, 但代价是什么? 长 prompt 长生成时会怎样?
2. 总览
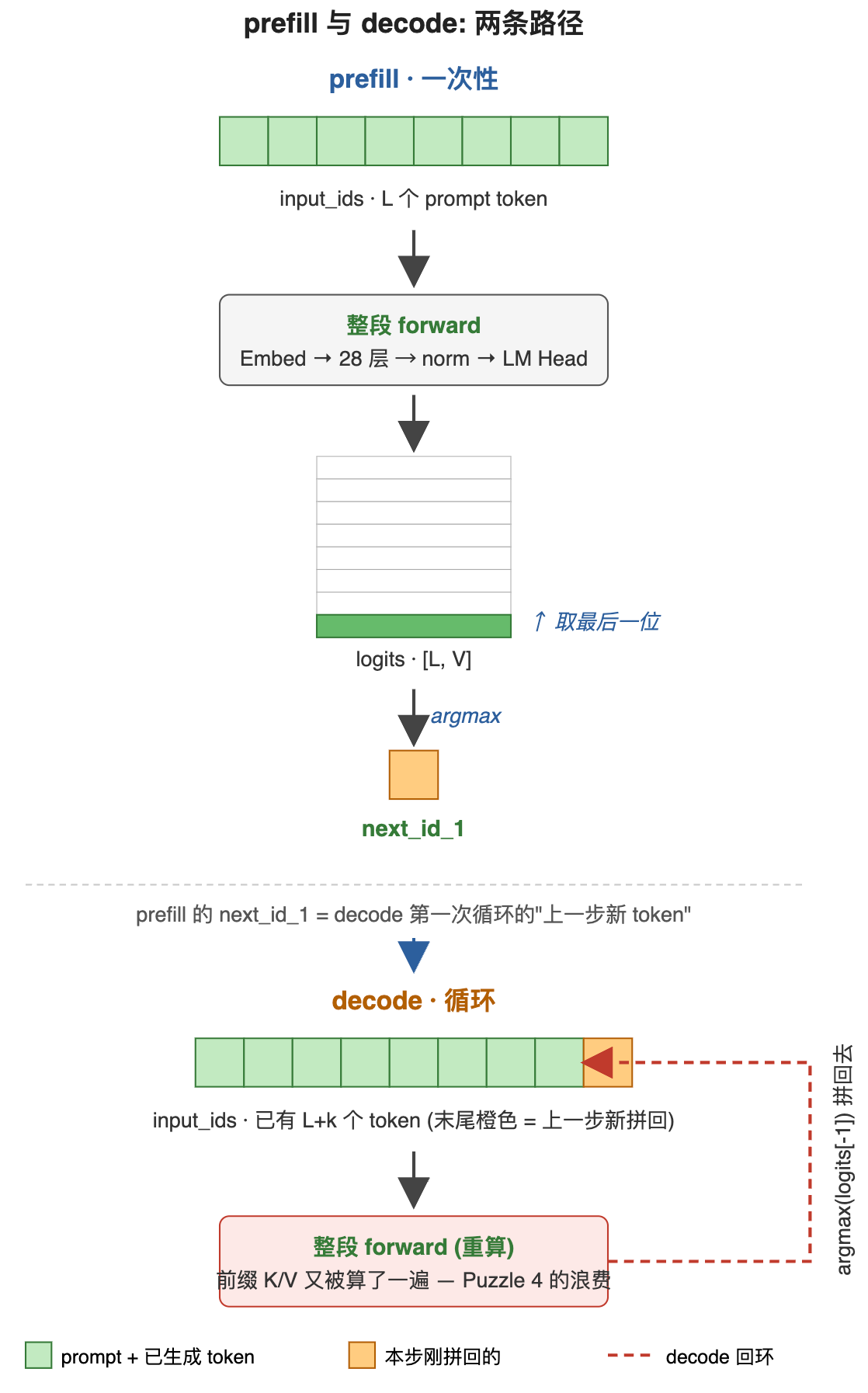
两条路径共用同一个 forward (Embed → 28 层 decoder → final norm → LM Head), 区别只在输入怎么准备 和输出怎么取:
| Puzzle | 触发问题 | 答案要点 |
|---|---|---|
| 1 | 为什么 prefill 与 decode 要分两条路径? | 自回归生成的本质 --- 一次性吞 prompt 算第一个 next_id, 之后每一步都依赖前一步输出, 模型本身就是两种用法 |
| 2 | 为什么 prefill 只取 logits[-1]? |
因果 attention 让每一位 logitsi 都是 P(next | tokens0...i); pos 0...L-2 的"下一个 token"已是已知 prompt, 只有 pos L-1 的"下一个"还没生成 |
| 3 | 为什么 decode 是循环 + 拼回去重跑? | 自回归 P(x_t | x_<t) 必须先有 x_<t; 无 cache 时新 token 的 K/V 是 forward 的中间产物, 不重跑拿不到 |
| 4 | 每步重算浪费了什么? | 前缀 token 的 K/V 在每步都被重算; 累计 forward 经过 token 数 ≈ NL + N²/2 = O(N²); 把 K/V 存下来就是 KV cache, 把它降到 O(N) |
3. 为什么 prefill 与 decode 要分两条路径?
是什么 : prefill 一次性把 L 个 prompt token 全部送进 forward, 出来 [L, V] 的 logits, 取最后一位 argmax 得到第一个 next_id; decode 是单步循环, 每一步把上一步生成的 next_id 拼到 input_ids 末尾, 整段再 forward 一次, 取最后一位 argmax 得到下一个 next_id, 直到 EOS 或步数上限。
打个比方: 像阅读理解考试。prefill 是"通读全文"环节, 一次性把题面 (prompt) 全看一遍, 头脑里形成了对前 L 个 token 的全部理解, 顺势答出第一题 (第一个 next_id); decode 是"一问一答接龙"环节, 老师每接收一个新答案, 都要把"全文 + 已答的部分" 重新过一遍, 才能给出下一答。
为什么需要 : 因果语言模型本质是个条件概率分解 --- 生成长度 T 的句子, 概率被分解成 P(x_1, ..., x_T) = P(x_1) · P(x_2|x_1) · ... · P(x_T|x_<T)。生成第一个 next_id 时, 条件是整段 prompt (L 个已知 token); 生成第 k 个 next_id 时, 条件是 prompt 加前 k-1 个已生成 token。输入长度在变, 但模型架构是定长 forward --- 输入多长就 forward 多长。第一步 (prefill) 一次性吞 L 个, 之后每步 (decode) 输入长度 +1, 自然就是两种形态。
解决了什么问题: 让生成长度可任意, 又不需要专门的"序列生成模型" --- Transformer 训练时只学了"给定一段, 预测下一个", 推理时用 prefill 完成"给定 prompt 预测第一个", 用 decode 循环完成"给定 prompt+已生成预测下一个"; 两者共用同一组权重, 没有任何架构差异。
怎么解决: 工程上的体现就是本篇第 1 章代码的两段:
- prefill:
model(input_ids, ...)调用一次, 拿到 next_id_1 - decode:
for循环里反复model(input_ids_new, ...), 每次 input_ids 长度 +1
4. 为什么 prefill 只取 logits[-1]?
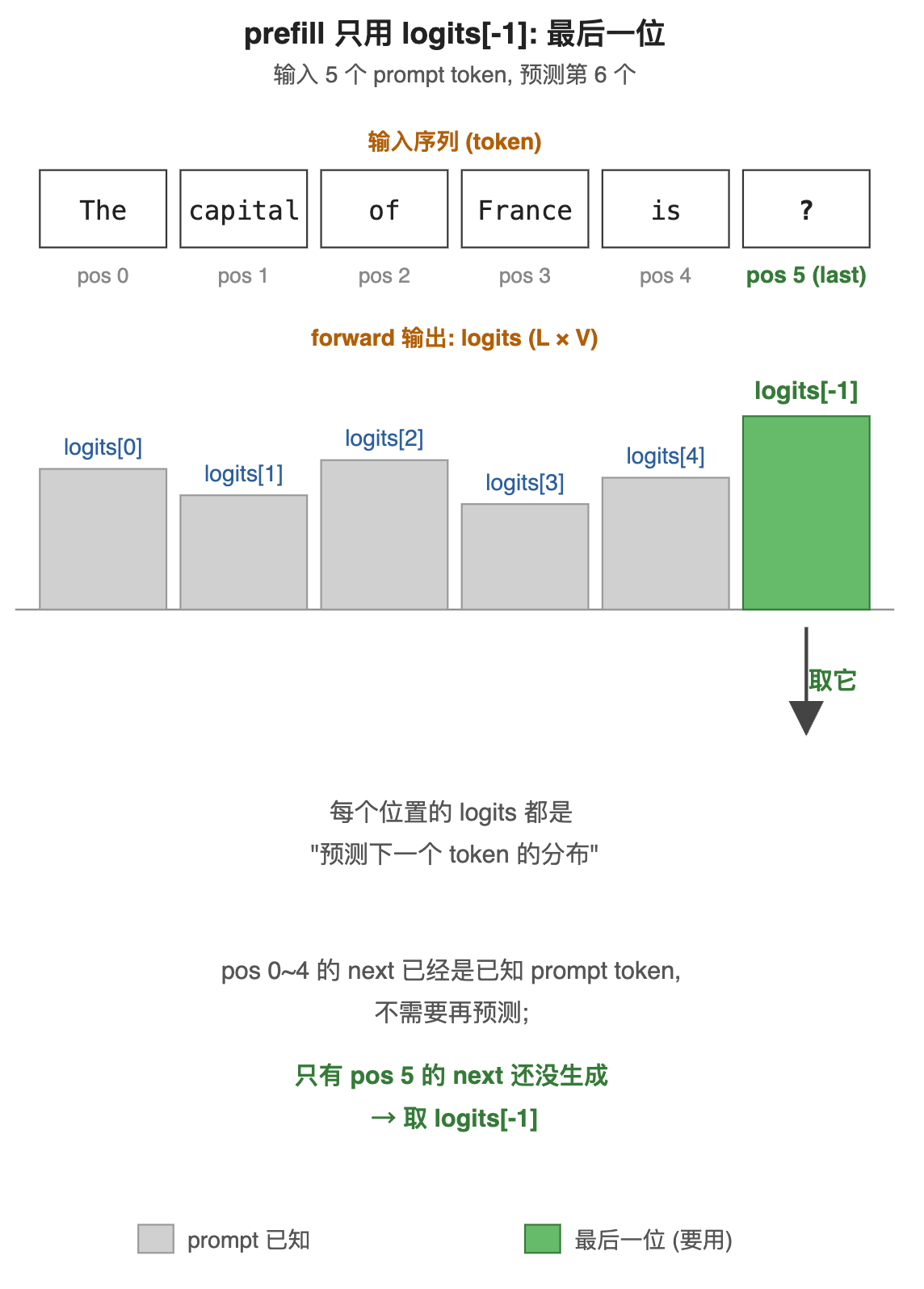
是什么 : prefill 的输出 logits 形状是 [L, V], 不是 [V] 一个向量。代码里只用 logits[-1], 前面 logits[0]..logits[L-2] 都被扔掉。
打个比方: 像期末考试 28 道题, 前 27 道是平时已经做过的练习题 (答案早就知道), 卷子发下来你只需要看第 28 道。前 27 道的答题位也写上去, 但老师只看最后一道。
为什么需要 : 关键在因果 attention (第 3 篇第 4.6 章 SDPA + 因果 mask 已讲)。因果 mask 让位置 i 的 attention 只能看到 ≤ i 的位置 --- 所以 logits[i] 实际是 P(next_token | tokens[0..i]), 即"看完前 i+1 个 token 后, 下一个 token 的分布"。这是模型训练时的目标函数: 给定 token0...i, 预测 tokeni+1。
解决了什么问题: 训练时所有位置一起算, 损失是 L-1 个位置的交叉熵之和 (位置 i 的目标是真实的 tokeni+1); 推理 prefill 时也是所有位置一起算 (因为因果 mask 已经隔离开了), 一次 forward 同时拿到了 L 个位置各自的"下一个 token 分布" --- 看似浪费, 实际是矩阵乘的副产品 --- 主要开销是矩阵乘本身, 多算几个位置的输出几乎不增加成本。
怎么解决 : 推理时 logits[0]..logits[L-2] 的"下一个 token"分别对应 input_ids[1]..input_ids[L-1] (已知 prompt 的后 L-1 位), 我们不需要再让模型"预测"已知答案。只有 logits[L-1] 的"下一个 token"还没被知道 , 这就是 prompt 之后要生成的第一个 token。所以取 logits[-1].argmax()。
在第 8 章会用代码验证: 跑一次 prefill, 把
logits[0..L-2].argmax()与input_ids[1..L-1]错位对比, 多数会重合 (说明前 L-1 位的 logits 确实在预测已知 prompt 的下一个 token)。
5. 为什么 decode 是循环 + 拼回去重跑?
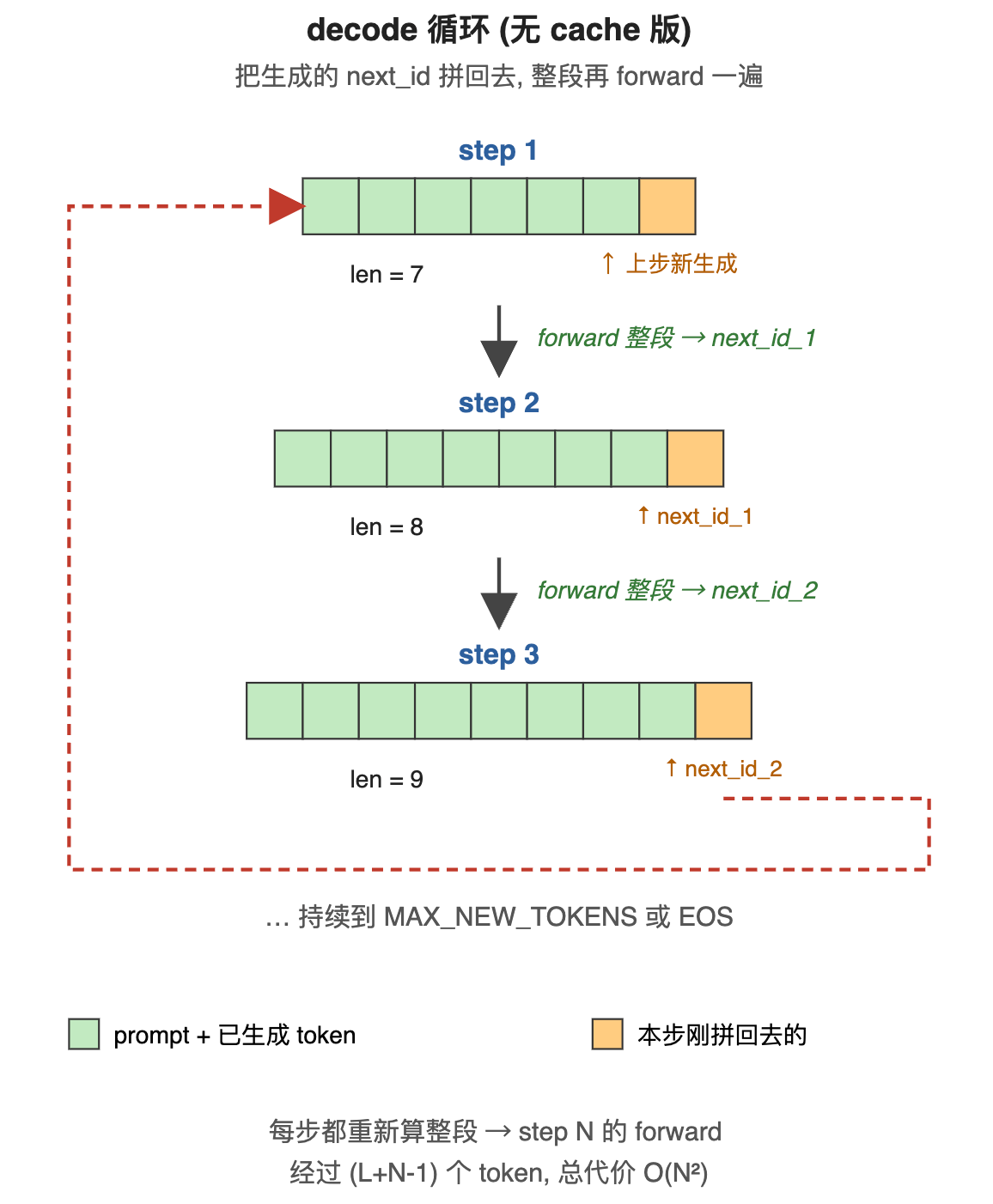
是什么 : decode 阶段每生成一个 next_id, 都要执行三步: ① input_ids = torch.cat([input_ids, [next_id]]); ② logits = model(input_ids, ...) (整段重 forward); ③ next_id = logits[-1].argmax()。直到 EOS 或步数上限。
打个比方: 像写一个字默读整篇。每写完一个字, 把"原题面 + 已经写好的字"从头默读一遍, 才知道下一个字写什么。
为什么需要 : 生成 next_id_{k+1} 需要 attention 看到 input_ids0...L+k-1 的全部 K/V --- 但在无 cache 版里, K/V 是 forward 内部的中间产物, forward 结束后就被丢弃了, 下一步要用必须重新算。新拼进来的 next_id 是新位置 (pos = L+k), 它的 K/V 需要走一次完整的 Embed → 28 层 attention 才能拿到; 顺便, 前面 L+k-1 位的 K/V 也被一起重算了一遍。
怎么解决 : 把"已生成的"重新当成"prompt 的一部分", 拼到 input_ids 末尾, 整段重跑。每一步生成一个新 token, input_ids 长度 +1, 直到模型自己生成 EOS (<|im_end|>) 或达到 MAX_NEW_TOKENS 上限。
6. 每步重算到底浪费了什么? → KV cache
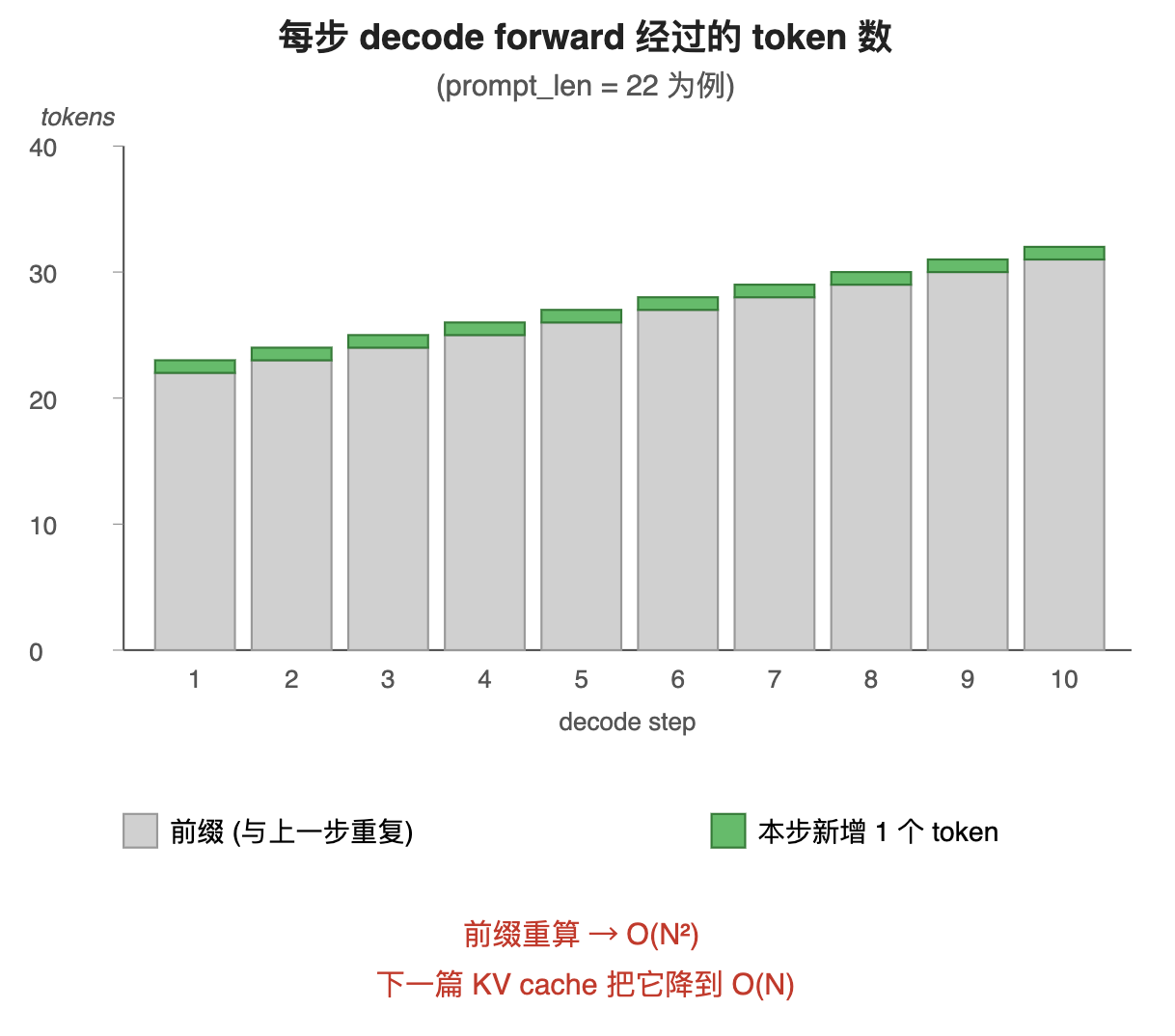
是什么 : 无 cache 版 decode 每一步都从头跑整段 forward, 前面已经算过的 K/V 在下一步又被原模原样重新算了一遍。把 L 个 prompt token + 生成 N 步, 累计 forward 经过的 token 数是 L + (L+1) + (L+2) + ... + (L+N-1) ≈ NL + N²/2, 渐进 O(N²)。
打个比方: 像每写一个字都把前面整段重抄一遍 --- 写第 1 个字抄 0 字, 写第 2 个字抄 1 字, ..., 写第 1000 个字要抄 999 字; 看似每步只多 1 个字, 累加起来抄写量是新写量的几百倍。
为什么需要 : K/V 是位置相关的量 (q_proj/k_proj/v_proj 输出再过 RoPE 后), 但对同一个 token 而言, K 和 V 一旦算出来就不变了 --- 前面位置的 K/V 在下一步本可以直接复用, 现在却被重算。Q 是新位置的 query, 当前步独有, 不算浪费; 浪费的纯粹是前缀位置的 K/V 重复计算。
解决了什么问题: 揭示朴素 decode 在长生成下的性能瓶颈。L=23 + 30 步只多几倍开销, 但 L=1000 + 1000 步就接近 100 万 token 的累计 forward 量, 远超 prompt 本身的 1000 token, 在生产环境完全不可接受。
怎么解决 : 给每一层加一块 K/V 缓冲: prefill 阶段整段写入 (L 个位置的 K/V 一次写满), decode 阶段每步只算新增 1 个 token 的 K/V 并 append 到缓冲尾部, 前缀位置直接读缓存。把每步 forward 经过的 token 数从 L+k 降到 1, 累计代价从 O(N²) 降到 O(N)。
这就是 KV cache , 也是下一篇 《5 Naive KV Cache》 的主题:
- 每根柱的绿色顶端永远只有 1 个 token --- 本步真正"新增"的工作量
- 灰色下段是上一步已经算过的前缀, 这一步又被重新走了一遍 attention + MLP --- 这部分将被 KV cache 消除
7. 小结 + 下一篇预告
回答上文的 4 个问题:
- prefill 与 decode 分两条路径: 自回归概率分解的必然 --- 第一次给整段 prompt 算第一个 next_id, 之后每步依赖前一步输出, 输入长度在变, 模型 forward 是定长, 自然就两种形态
- prefill 只取
logits[-1]: 因果 attention 让每位 logits 都是"下一个 token 的分布"; 前 L-1 位预测的是已知 prompt, 只有最后一位的"下一个"还没生成 - decode 循环 + 拼回重跑: 无 cache 时新 token 的 K/V 必须经一次完整 forward 才能拿到; 拼回 input_ids 整段重跑是工程上最简实现
- 重算的代价 O(N²): 前缀位置的 K/V 每步都被重算; 把 K/V 存下来就把代价从 O(N²) 降到 O(N)
下一篇 《5 Naive KV Cache》 给每一层加一块连续的 K/V 缓冲: prefill 时整段写入, decode 时只算新增 1 个 token, 直接解决重复计算的问题。