TensorFlow×AutoFuse实现算子自动融合,提升推荐模型48%的性能!
背景介绍
在电商行业中,推荐模型可以将合适的商品在合适的时间推送给最可能对其感兴趣的人群,从而大幅提升用户体验和平台转化率。某电商平台便使用了多个基于TensorFlow框架的传统推荐模型,这些模型存在大量的Add、ReLU、LayerNorm等轻量级算子,执行频繁,不仅调度开销高,还会频繁搬运算子的输入输出,极大降低了模型的执行效率。
采用融合算子的方式可以有效优化以上瓶颈,将这些小算子融合成一个大算子,既减少了调度次数从而降低调度开销,同时可以在新的融合算子中合理复用内存,内存搬运的耗时也会大幅降低。然而传统手工开发融合算子的方式费时费力,高昂的开发和维护成本阻塞了优化的进行。为此CANN提供了支持TensorFlow框架的AutoFuse组件,通过自动融合技术使算子融合实现了从"手工作坊"到"自动化现代工厂"的转变,降低算子融合的成本,并在多个推荐模型获得了20-48%的性能提升。
AutoFuse介绍
AutoFuse 是图编译层级的自动优化技术。它解决了开发者手动编写融合算子门槛高、工作量大的痛点。通过编译器自动识别并合并计算图中的多个子节点,从而提升模型在NPU上的执行效率。它的核心思路是将多个高频、轻量算子自动融合成一个大算子,从而减少算子调度和内存搬运开销,提高算子性能。
AutoFuse包括以下关键特性:
-
自动融合范围识别:智能分析计算图,确定可融合算子集合。
-
自动生成融合Kernel:前端分析图结构,后端生成高效 Kernel 和算子二进制文件。
-
Auto Tiling优化:根据硬件特性自动优化融合算子的数据切分方式,提高融合算子执行性能。

TensorFlow×AutoFuse技术路线解析
AutoFuse 面向 TensorFlow 框架的适配路线可分为三个阶段:
-
TensorFlow 模型解析与转换
通过 GE Parser 解析 TensorFlow 原始模型,将其转换为 Ascend IR 图,作为 AutoFuse 后续处理的统一图输入。
-
算子融合范围识别
基于 Ascend IR 图,依次经过符号化、Lowering 和融合策略求解三个阶段,识别可融合的算子组合,并将融合后的计算逻辑表示为 AscGraph。
-
融合算子代码生成
以 AscGraph 为输入,经过 Schedule、Codegen 和 Auto Tiling 等后端模块处理,自动生成面向昇腾 NPU 的高性能 Ascend C 融合算子代码。
算子融合范围识别
符号化
在模型编译和算子优化过程中,算子的 shape 信息是非常关键的前置输入。对于静态 shape 图,各个算子的输入输出 shape 通常可以在编译期直接推导出来;但在动态 shape 图中,未知维度往往只用 -1 表示。
仅用 -1 表达动态维度存在明显局限。虽然动态维度的具体取值在编译期不可知,但通过算子的 shape 推导,仍然可以获得不同算子、不同维度之间的关系,例如相等关系、广播关系、拼接后的维度表达,以及 Reduce 后的维度变化。如果这些关系仍然只用 -1 表示,后续的融合判断、循环轴合并、Tiling 策略生成和内存优化都会缺少足够精确的 shape 语义。
因此,AutoFuse 会在进入 Lowering 和融合策略处理之前,先对动态 shape 进行符号化。符号化会将输入 shape 中的动态维度转换为符号表达,例如:
javascript
[3, -1] -> [3, s0]
[-1, 5] -> [s1, 5]
[-1, -1] -> [s2, s3] 完成符号化后,符号会沿着计算图继续传播。比如 Concat 的两个输入 shape 分别为 s0, s1 和 s0, s2,当拼接轴为 1 时,输出 shape 就可以表达为 s0, s1 + s2。相比简单的 -1, -1,这种符号表达保留了更多维度关系信息,为后续优化提供了更精确的shape信息。
Lowering
Lowering 模块包含 图 Lowering 和 算子 Lowering 两个层级。其中,Graph Lowering 是整体驱动流程,会按照图拓扑顺序遍历算子;在遍历到每个算子时,调用对应的算子 Lowering 实现,将该算子的计算语义转换为 Loop IR 表达。
Loop IR 描述的是算子在循环层面的计算逻辑,例如输入如何加载、Broadcast 关系如何映射、每个输出元素如何计算、结果如何写回。图 Lowering 会基于这些 Loop IR 表达继续判断前后算子是否可以在同一段计算逻辑中内联融合,并在满足约束条件时,将可融合片段组织成一张张AscGraph。
Lowering 阶段主要支持以下三类融合结构:
-
Pointwise + Pointwise
逐元素算子之间的连续计算,例如 Add、Mul、Sub、Abs、Sigmoid 等。
典型形式:
javascriptAdd -> Mul -> Abs -
Pointwise + View
View 类算子通常不引入新的数学计算,主要改变数据访问或索引映射关系,例如 Broadcast。
典型形式:
c++Broadcast -> Add Add -> Broadcast -> Mul -
Pointwise + Reduction
先进行逐元素计算,再接 ReduceSum、ReduceMax 等规约类算子。
典型形式:
javascriptAdd -> Abs -> ReduceSum
当遇到不支持算子 Lowering、shape 符号推导不足、Loop/Load 规模超过阈值、控制依赖或 dtype 约束不满足等情况时,图 Lowering 会终止当前融合链路,将已经积累的计算表达固化为 AscGraph,并由后续模块继续处理。
融合策略
Lowering 阶段会生成初始的 AscBackend 和 AscGraph,融合策略阶段则在这些融合节点基础上继续做二次融合,判断已有融合节点之间是否还能进一步合并。
融合判断主要包括两类条件:
-
CanFuse 通用条件
CanFuse 负责从图结构和资源影响角度判断节点对是否具备融合价值,主要包括:
- 垂直融合:两个节点之间存在直接或间接的输入输出关系,一个节点的输出会被另一个节点消费。融合后可以减少中间结果写回和再次读取。
- 水平融合:两个节点之间没有直接输入输出关系,但它们读取同一个上游节点的输出。融合后可以复用同一份输入数据,减少重复搬运。
- 成环检测:融合不能破坏原图依赖关系,融合后不能形成环。
- 融合规模限制:融合后的节点规模不能超过后端可处理的阈值。
- 内存峰值评估:融合后不能明显增加中间 Tensor 生命周期,避免导致内存峰值上升。
-
Backend 后端条件
Backend 负责判断融合结构是否能被 AutoFuse 后端实现,主要包括:
- 两个 AscGraph 的 Loop 轴是否可以映射。
- 是否满足 Schedule 的 group merge 规则,能够生成合法的 TilingCase。
然后融合策略阶段会经过以下流程实现算子的二次融合:
- 获取当前图中可能融合的节点对。
- 根据融合收益计算优先级,主要考虑节省的内存大小和节点拓扑距离。
- 按优先级对候选节点对排序。
- 依次调用 CanFuse 和 Backend 判断融合是否成立。
- 对通过判断的节点对执行融合,并进行多轮迭代。
最终和Lowering阶段一样,二次融合后的每个融合算子都对应一张新的AscGraph。
融合算子代码生成
融合算子代码生成阶段以 AscGraph 作为输入。经过算子融合范围识别阶段的处理,输出了每个融合算子的AscGraph,这些AscGraph依次完成 Schedule 、Auto Tiling 和 Codegen 三个阶段处理,生成可在昇腾NPU上执行的融合算子Ascend C 实现代码。
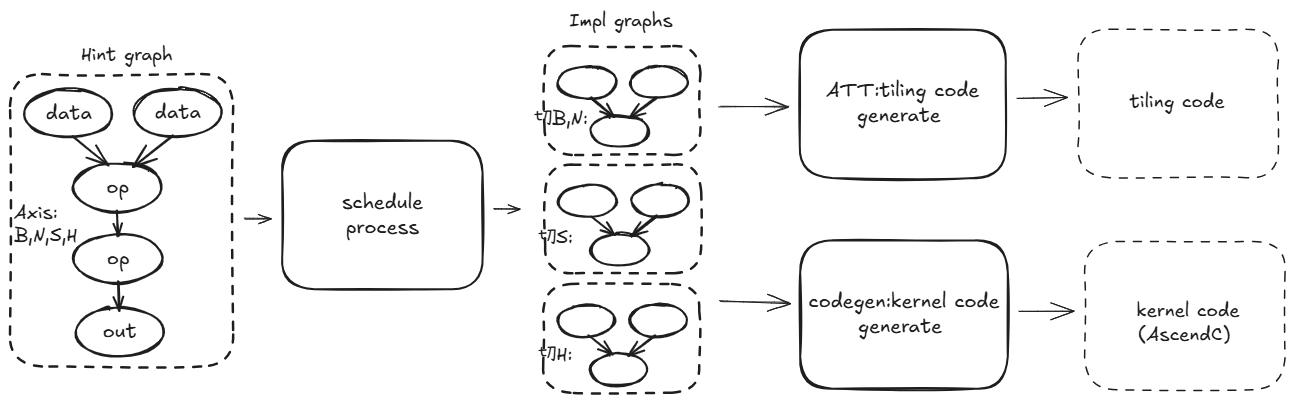
-
Schedule:对输入的AscGraph进行重排和优化,并生成多个候选优化图供后续挑选.
-
Auto Tiling:结合输入shape和硬件约束从候选优化图中选择最合适的优化图,并计算出此种优化图下最佳的Tiling参数。
-
Codegen:对Schedule生成的多张候选图各生成一份可执行的硬件代码,并接收Auto Tiling计算的Tiling参数确认此次输入下应该选择的执行代码.
三个阶段的详细介绍可参考此前发布的文章:AutoFuse×TorchInductor实现算子自动融合,提升DeepSeekV3.1-Terminus性能17%!
TensorFlow + AutoFuse 使用示例
下面演示一个基于 TF 1.x 的简单使用示例。示例包含两个输入 input1 和 input2,计算逻辑为:
output = relu ( | input1 | + input2 )
在未使能 AutoFuse 前,该计算会拆分为 Abs、Add 和 Relu 三个独立算子执行。每个算子都需要分别完成输入搬运、计算和输出搬运,因此整体耗时近似于这三个阶段的和。使能 AutoFuse 后,Abs、Add 和 Relu 可以被自动合并为一个融合算子。融合后,中间结果不再需要反复写回和读取,例如 Abs 的输出搬运、Add 对 \|input1\| 的输入搬运、Add 的输出搬运以及 Relu 的输入搬运都可以被省去,从而减少访存开销并提升执行效率。
python
import tensorflow as tf
import numpy as np
## TF1.X environment
from npu_bridge.npu_init import *
if __name__ == '__main__':
input1 = tf.placeholder(tf.float32, shape=[128])
data1 = np.random.rand(128).astype(np.float32)
input2 = tf.placeholder(tf.float32, shape=[2560, 128])
data2 = np.random.rand(2560, 128).astype(np.float32)
## 构造模型结构
abs_0 = tf.abs(input1)
add_0 = tf.add(abs_0, input2)
output = tf.nn.relu(add_0)
sess_config = tf.ConfigProto(allow_soft_placement=True, log_device_placement=False)
custom_op = sess_config.graph_options.rewrite_options.custom_optimizers.add()
custom_op.name = "NpuOptimizer"
custom_op.parameter_map["use_off_line"].b = True
# 设置为推理模式
custom_op.parameter_map["graph_run_mode"].i = 0
feed_dict = {input1: data1, input2: data2}
step = 100
## 执行模型
with tf.compat.v1.Session(config=sess_config) as sess:
for _ in range(step):
sess.run(output, feed_dict=feed_dict) TensorFlow + AutoFuse 实际场景收益
| 模型 | 未使能AutoFuse | 使能AutoFuse | 性能提升比 |
|---|---|---|---|
| 秒杀推荐模型 | 1341us | 906us | 48.01% |
| 百亿补贴推荐模型 | 2256us | 1877us | 20.19% |
总结
TensorFlow 与 AutoFuse 的结合,大幅降低了基于 TensorFlow 的传统模型优化成本,并已在电商推荐等典型场景中得到充分验证。该适配路线对前端框架的依赖较低,更多依托统一的 Ascend IR 和 AutoFuse 后端能力完成融合优化,因此不仅为 AutoFuse 适配其他框架提供了可复用的参考样本,也降低了后续框架自身演进对 AutoFuse 能力迭代的影响。未来,AutoFuse 将持续优化融合性能,并进一步扩展对更多 AI 框架的支持。