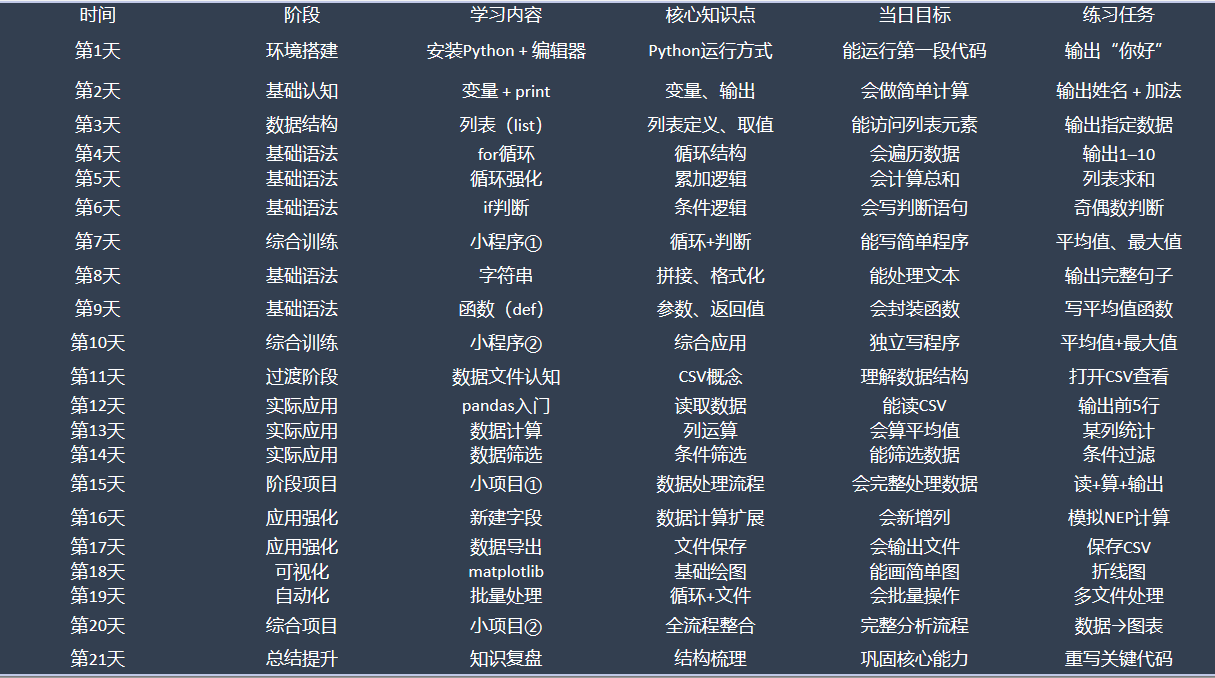
阶段:综合训练
学习内容:数据重复值处理
核心知识点:查找与删除重复行
当日目标:清洗行重复的数据
练习任务:去重并保存
1. 什么是数据去重?
(1)核心思想:现实中由于系统错误或人工重复录入,表格里经常会出现一模一样的"倒霉行"。数据去重就是把这些完全重复的行找出来,只留下一行,剩下的全部删掉。
(2)电脑做法:pandas 会自动比对每一行,发现内容完全一致时,默认保留第一次出现的行,后面出现的直接"抹除"。
2. 今日原材料准备(修改 data.csv)
为了测试去重功能,请用记事本打开 data.csv,故意制造两行完全相同的数据(比如让 alice 出现两次),修改为以下内容:
name,score
alice,100
ben,98
keely,87
delio,99
alice,1003. 核心去重指令
-
df.duplicated():检查哪些行是重复的(返回是/否)。 -
df.drop_duplicates():直接删掉重复的行,只留下一行。
4. 完整代码
Python
import pandas as pd
# 1. 读取含有重复值的数据
df = pd.read_csv('data.csv')
print("--- 1. 原始包含重复项的数据 ---")
print(df)
# 2. 检查重复行(额外查看,True 代表这一行是重复的)
print("\n--- 2. 检查哪些行重复了 ---")
print(df.duplicated())
# 3. 执行去重
# drop_duplicates() 会自动删掉后面重复的 alice
df_unique = df.drop_duplicates()
print("\n--- 4. 去重后的干净数据 ---")
print(df_unique)
# 4. 保存去重后的数据
df_unique.to_csv('unique_data.csv', index=False)
print("\n--- 去重数据已保存至 unique_data.csv ---")