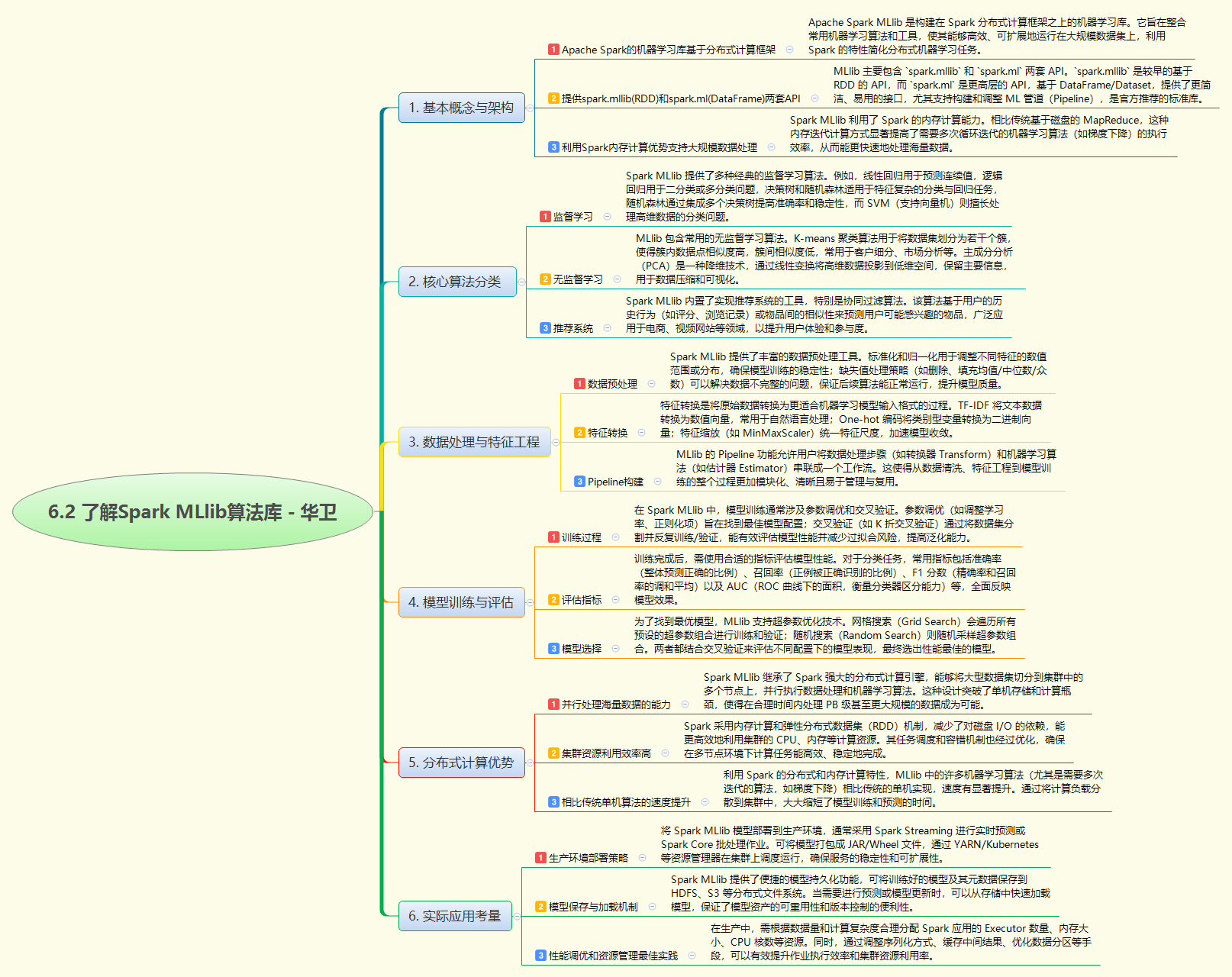
Apache Spark MLlib 是构建于 Spark 分布式计算框架之上的机器学习库,旨在高效处理大规模数据。它提供基于 RDD 的 spark.mllib 和基于 DataFrame 更易用的 spark.ml 两套 API。核心算法涵盖监督学习(如线性回归、逻辑回归、决策树、SVM)、无监督学习(如 K-means、PCA)及推荐系统(协同过滤)。它具备强大的数据预处理、特征转换和 Pipeline 构建能力,支持模型训练、评估(准确率、召回率、AUC 等指标)及超参数优化(网格搜索、随机搜索)。利用 Spark 内存计算和分布式特性,MLlib 相比传统方法在处理海量数据时速度更快、资源利用率更高,且提供了生产环境部署、模型持久化及性能调优的最佳实践。