大家好,你们可以叫我凌,是个16岁的网络安全学习者。
这篇我们依旧来讲汇编,这篇是连接底层汇编与高级语言的重要桥梁,读完以后你编写的汇编程序将更加实用、可读性也更高。
那废话不多说,我们直接开始吧!
GDB 的其他实用功能
在上篇中,我们已经掌握了 GDB 的基本操作:设置断点、单步执行、查看寄存器和内存。本篇将进一步学习几个更强大的命令,帮助你分析更复杂的程序(比如含有函数调用的程序)。
回顾基础命令
|---------------------|----------|
| 命令 | 作用 |
| break(b) | 设置断点 |
| run(r) | 运行程序 |
| stepi(si) | 单步执行一条指令 |
| info registers(i r) | 查看寄存器 |
| x | 查看内存 |
| quit(q) | 退出 |
新命令一览
|-------------|-------|------------------------|
| 命令 | 简写 | 作用 |
| watch | wa | 监视某个内存地址,当它的值发生变化时自动暂停 |
| backtrace | bt | 查看当前函数调用栈(谁调用了谁) |
| frame | f | 切换到指定的栈帧,查看该函数的局部变量 |
| disassemble | disas | 反汇编指定函数或地址范围 |
| continue | c | 继续执行程序,直到下一个断点或程序结束 |
这些命令在调试包含多个函数、循环或复杂逻辑的程序时非常有用。
示例:使用 watch 监视变量变化
假设我们有个程序 counter.asm,它在循环中递增一个内存变量:
注意:不需要理解代码!本节主要演示 GDB 的 watch、backtrace 等命令用法!
cpp
; counter.asm
section .data
count dq 0 ; 指令前可以有空格,但伪指令 section 要顶格
section .text
global _start ; 伪指令 global 也顶格
_start: ; 标签必须顶格
mov rcx, 5 ; 循环5次
loop: ; 标签顶格
inc qword [count] ; 增加 count 的值
dec rcx
jnz loop
mov rax, 60
mov rdi, [count] ; 退出码为 count 的值(应该是5)
syscall编译运行后退出码为 5。现在我们用 watch 监视 count 的变化。
操作步骤
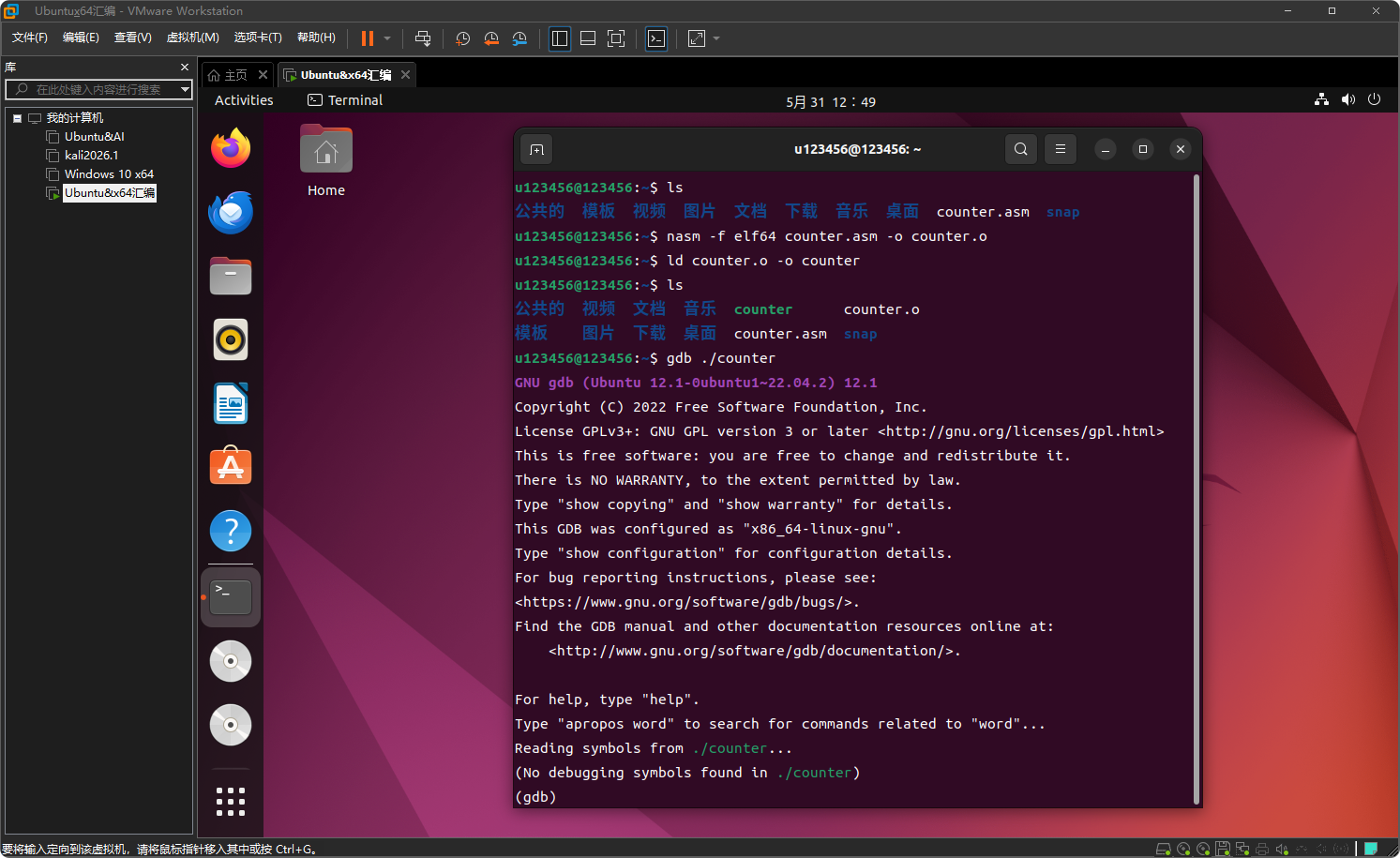
编译并启动 GDB
nasm -f elf64 counter.asm -o counter.o
ld counter.o -o counter
gdb ./counter
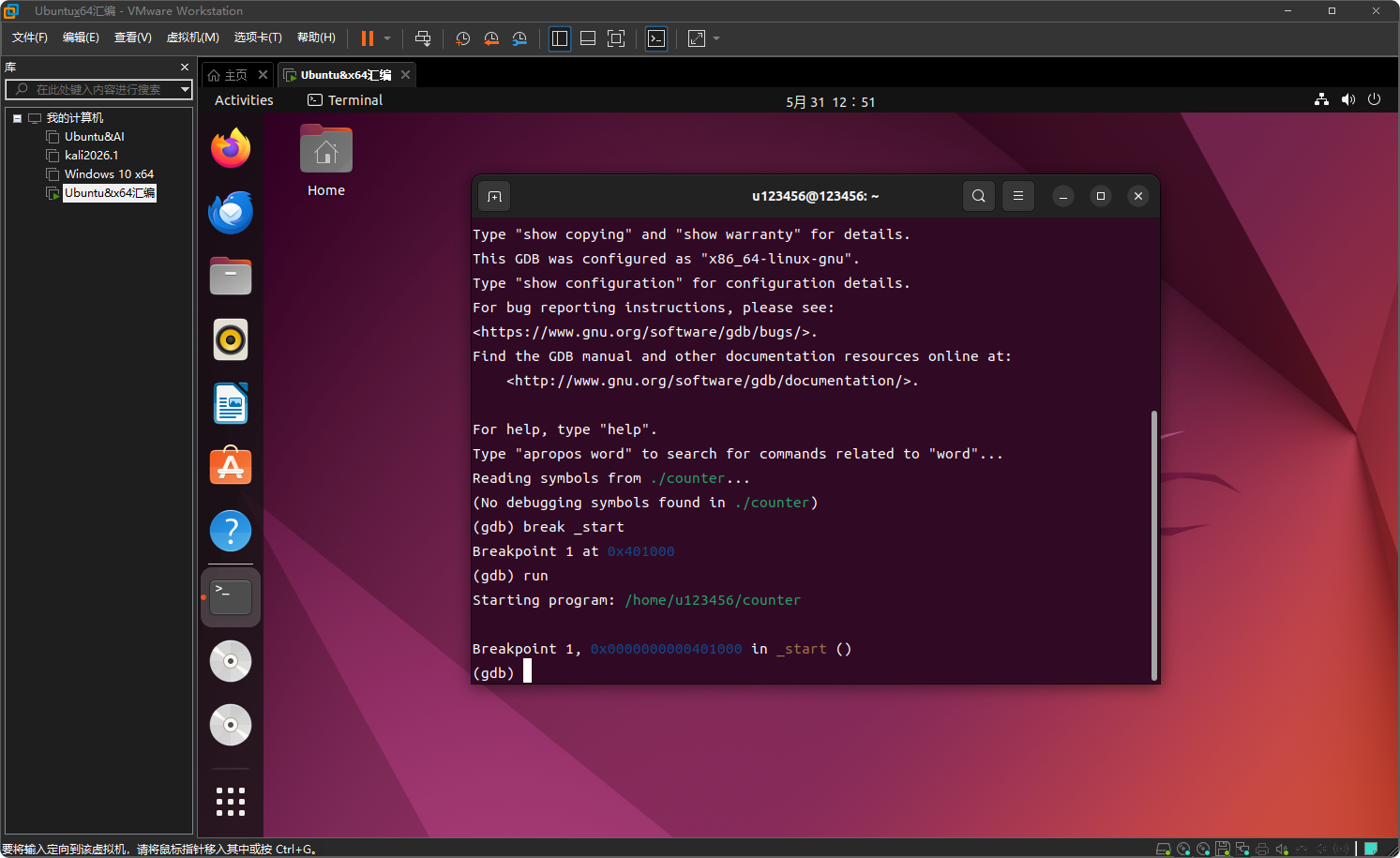
在 _start 设置断点并运行
break _start
run
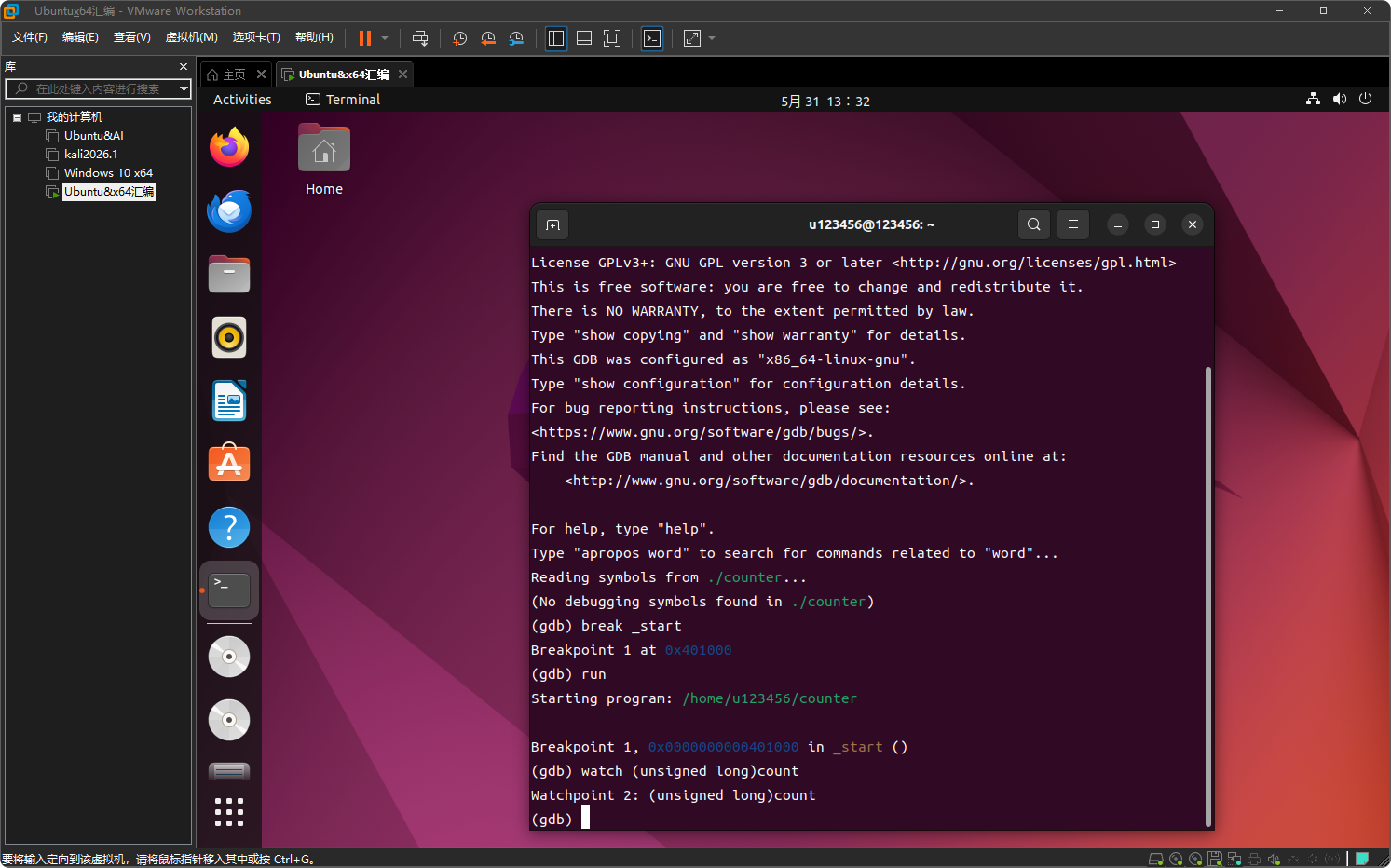
在 _start 处设置监视点
watch (unsigned long)count #强制类型转换
GDB 会提示 Watchpoint 2: (unsigned long)count。
GDB 设置监视对象的数据类型解决方法
观察上面命令,发现有个 "(unsigned long)" 这个东西,那它有什么用呢?我们现在先来聊聊
首先如果直接输入 "watch count" 会出现以下错误:
'count' has unknown type; cast it to its declared type
这是因为GDB 需要知道监视对象的数据类型(占几个字节)。汇编语言中定义的标号(如 count)只是个地址没有类型信息,所以GDB无法判断要监视多少个字节。
以下为针对该问题的解决方法
方案一:强制类型转换(推荐)
根据变量定义时的大小,在 watch 命令中加上类型转换:
watch (unsigned long)count ; 对应 dq(8字节)
watch (unsigned int)counter ; 对应 dd(4字节)
watch (unsigned short)flag ; 对应 dw(2字节)
watch (unsigned char)byte ; 对应 db(1字节)
注意:语法为 watch (类型)变量名,不需要加 &。
方案二:使用地址加长度(不依赖类型)
先用 info address count 获取地址,然后监视从该地址开始的 N 个字节:
info address count ; 假设输出地址 0x402000
watch *(unsigned long *)0x402000
或者更简洁地直接使用 &count:
watch *(unsigned long *)&count
其中 unsigned long 表示 8 字节,若变量大小为其他值,则换成对应类型。
常见错误
**错误写法:**watch *8*&count
**原因:**GDB 不支持 *N* 这种语法,会报 Argument to arithmetic operation not a number or boolean。
**正确写法:**watch *(unsigned long *)&count
继续执行程序
continue
程序会运行,并在 count 的值第一次被修改时停下,显示修改前的值和修改后的值。
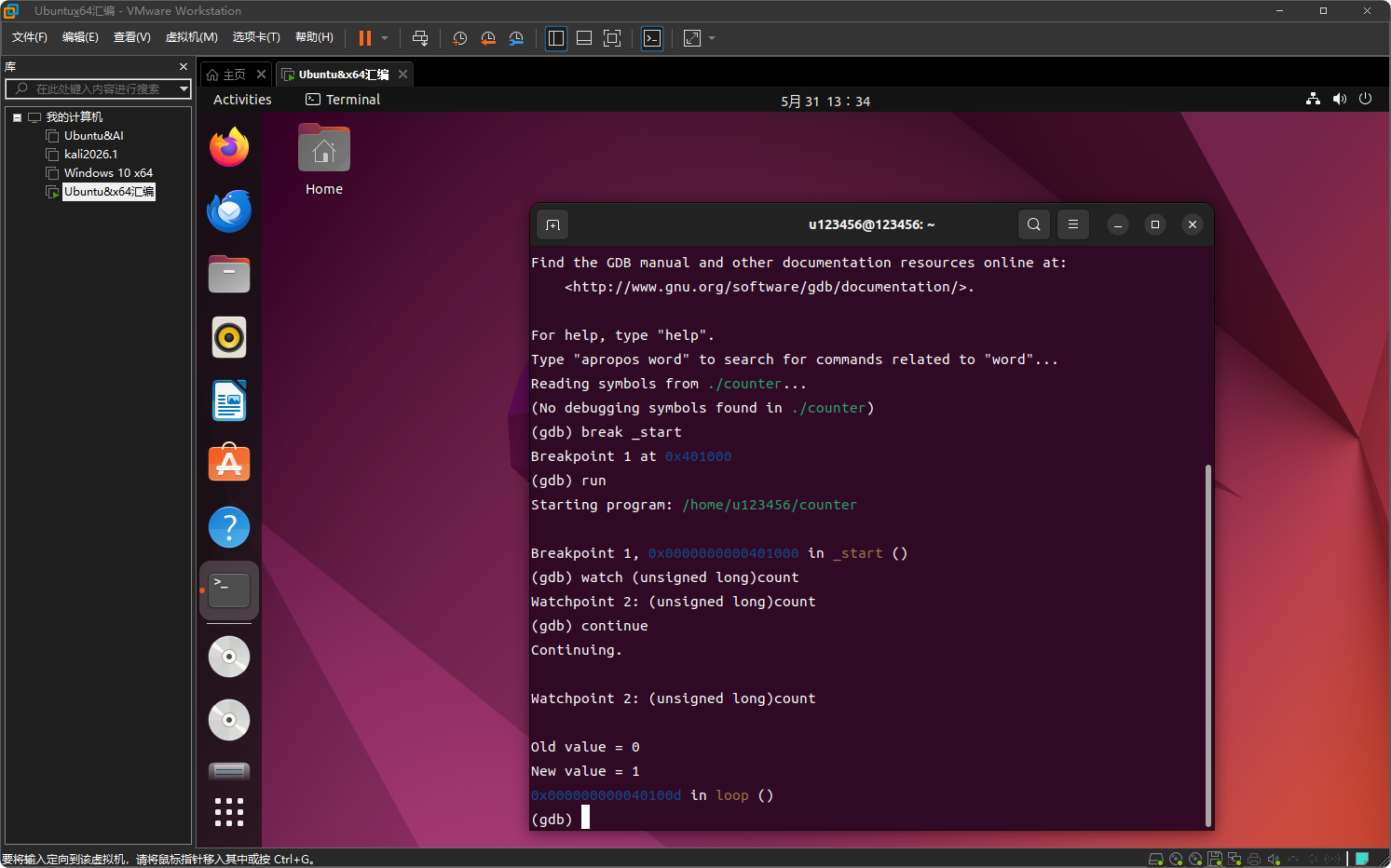
- 重复执行 continue,每次 inc 指令执行后都会触发断点,可以观察 count 的递增过程。
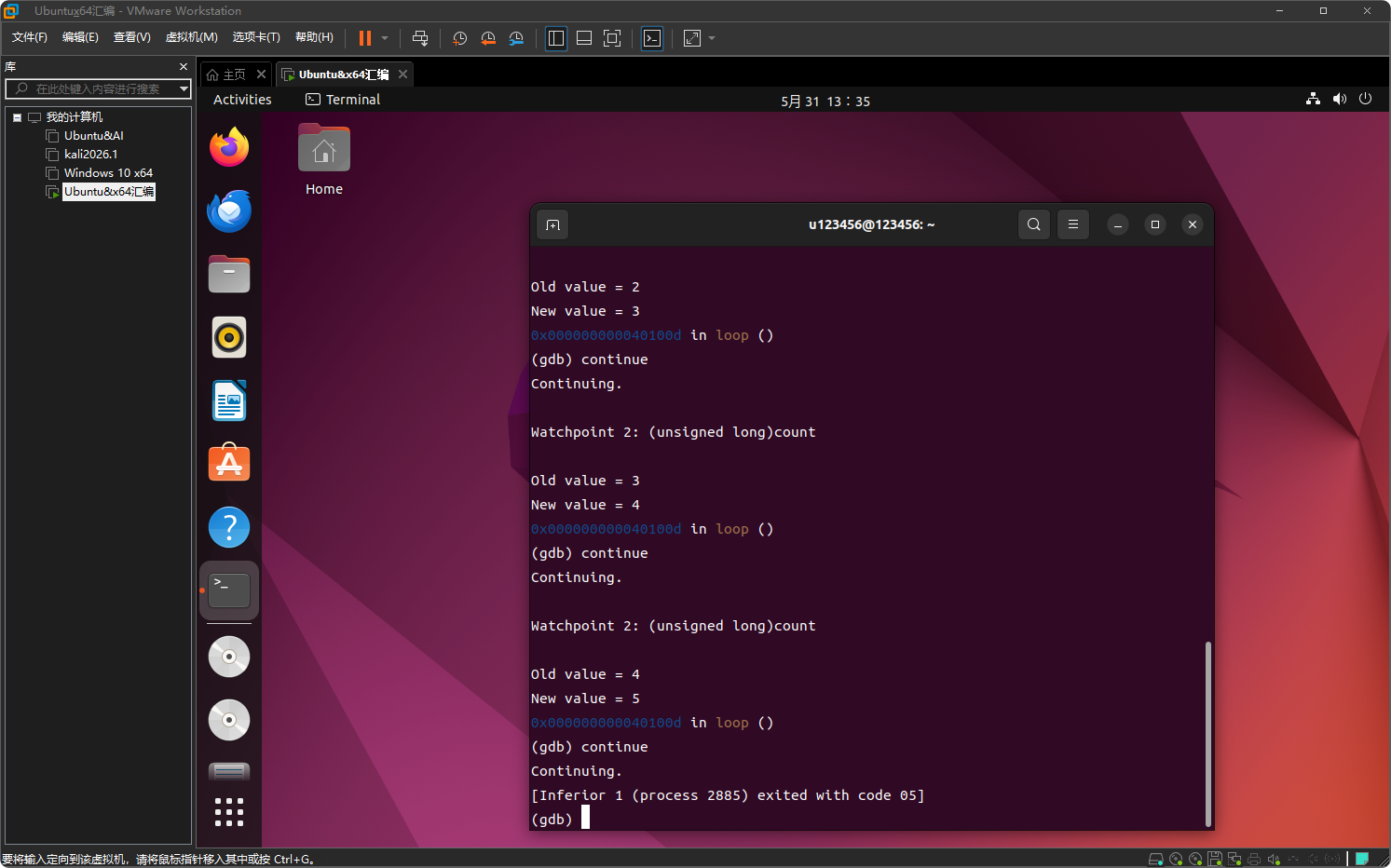
程序退出,可以用 info breakpoints 查看监视点状态
当然,简写为 "i b" 也可以
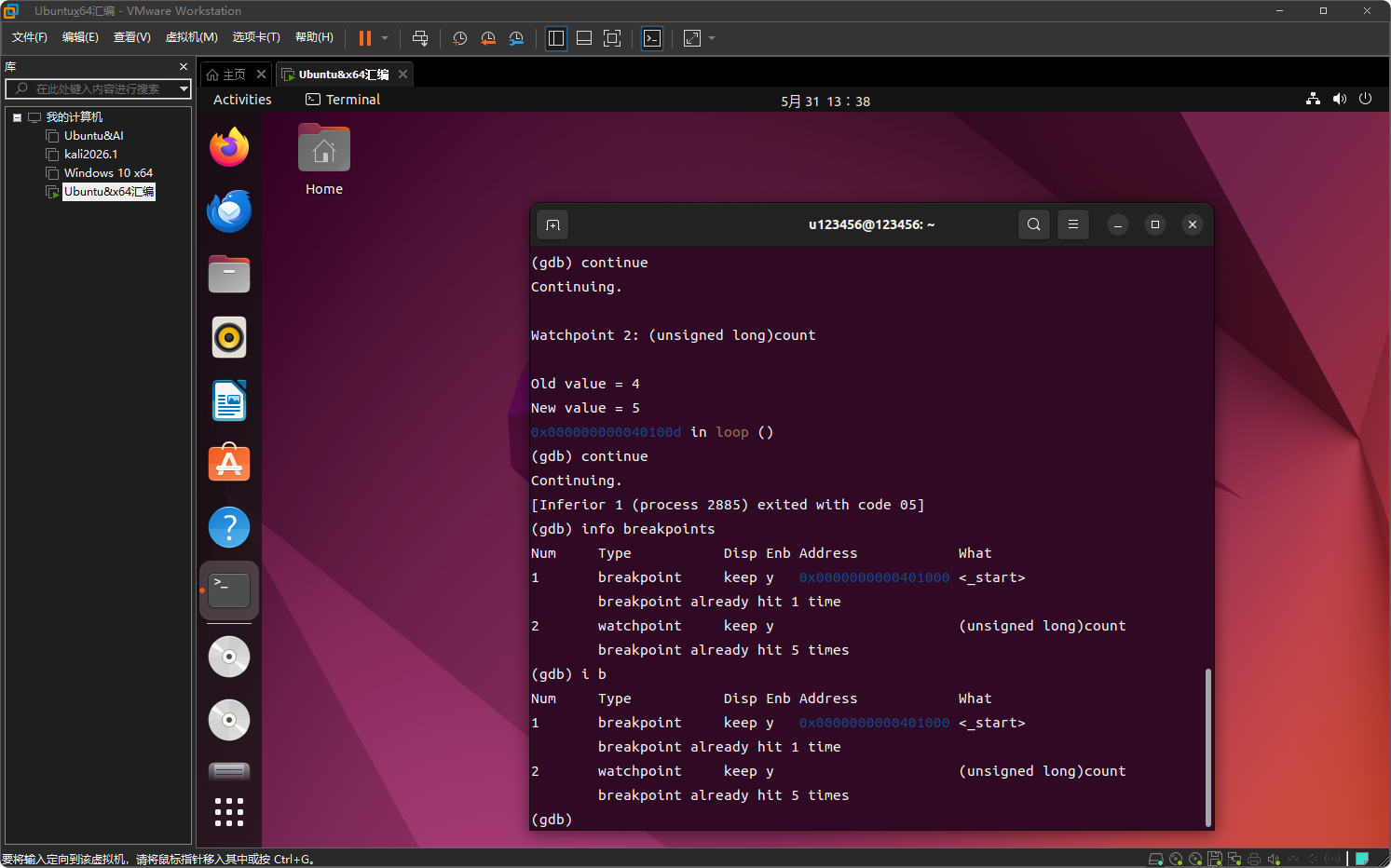
注意:watch 需要硬件支持,但大多数现代 CPU 都支持。如果提示无法设置,可以改用 rwatch(读监视)或 awatch(读写监视),但通常 watch 就够了。
示例:使用 backtrace 查看函数调用栈
依旧不要理解代码的意思!这只是在讲 backtrace 的使用教学!堆栈内容我将会在下篇以纯理论无代码的方式讲解!到时候再回头看也不迟!盲目理解硬啃只会打磨掉学习的兴趣!
为了更好地展示 backtrace,我们需要一个包含函数调用的程序。下面是个简单的汇编程序 caller.asm,它定义一个函数 add_two,然后在 _start 中调用它:
cpp
; caller.asm
section .text
global _start
_start:
mov rdi, 5
call add_two ; 调用函数,参数在 rdi
mov rdi, rax ; 返回值作为退出码
mov rax, 60
syscall
add_two:
push rbp
mov rbp, rsp
add rdi, 2
mov rax, rdi
pop rbp
ret以下为CPP/Python的类比
cpp
#include <cstdlib>
int add_two(int x) {
return x + 2;
}
int main() {
int result = add_two(5); // 调用函数,参数 5,返回值存到 result
exit(result); // 退出码为 result(7)
}
python
import sys
def add_two(x):
return x + 2
def main():
result = add_two(5)
sys.exit(result) # 退出码为 result
if __name__ == "__main__":
main()编译并启动 GDB:
nasm -f elf64 caller.asm -o caller.o
ld caller.o -o caller
gdb ./caller
操作步骤
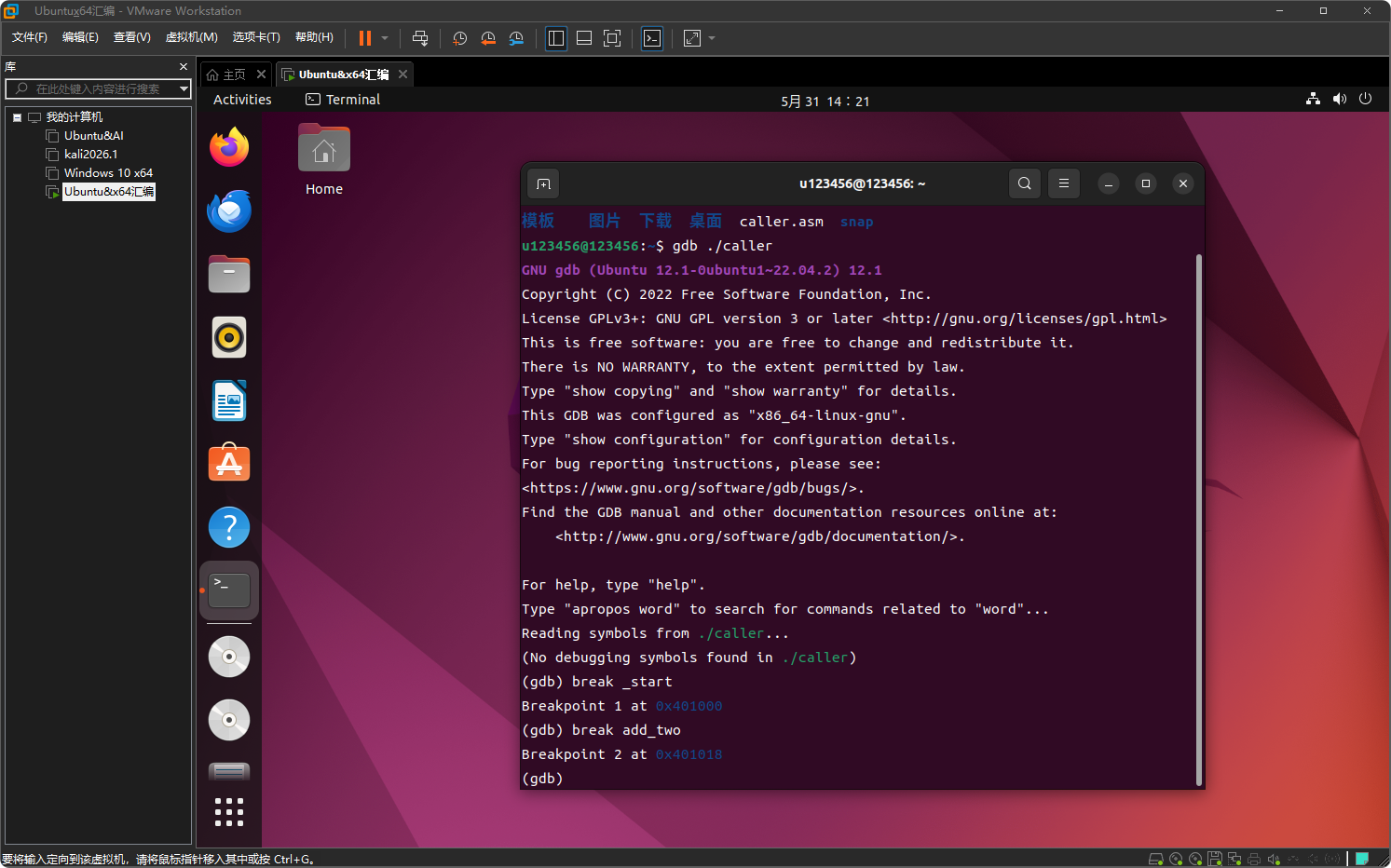
在 _start 和 add_two 分别设置断点
break _start
break add_two
运行程序
run
程序停在 _start。
查看当前调用栈
backtrace
输出类似于:
#0 0x0000000000401000 in _start ()
当前程序刚刚启动停在 _start 入口,还没有执行 call add_two,所以调用栈里只有 _start 自己。
继续执行到 add_two 断点
continue
程序停在 add_two 的第一条指令。
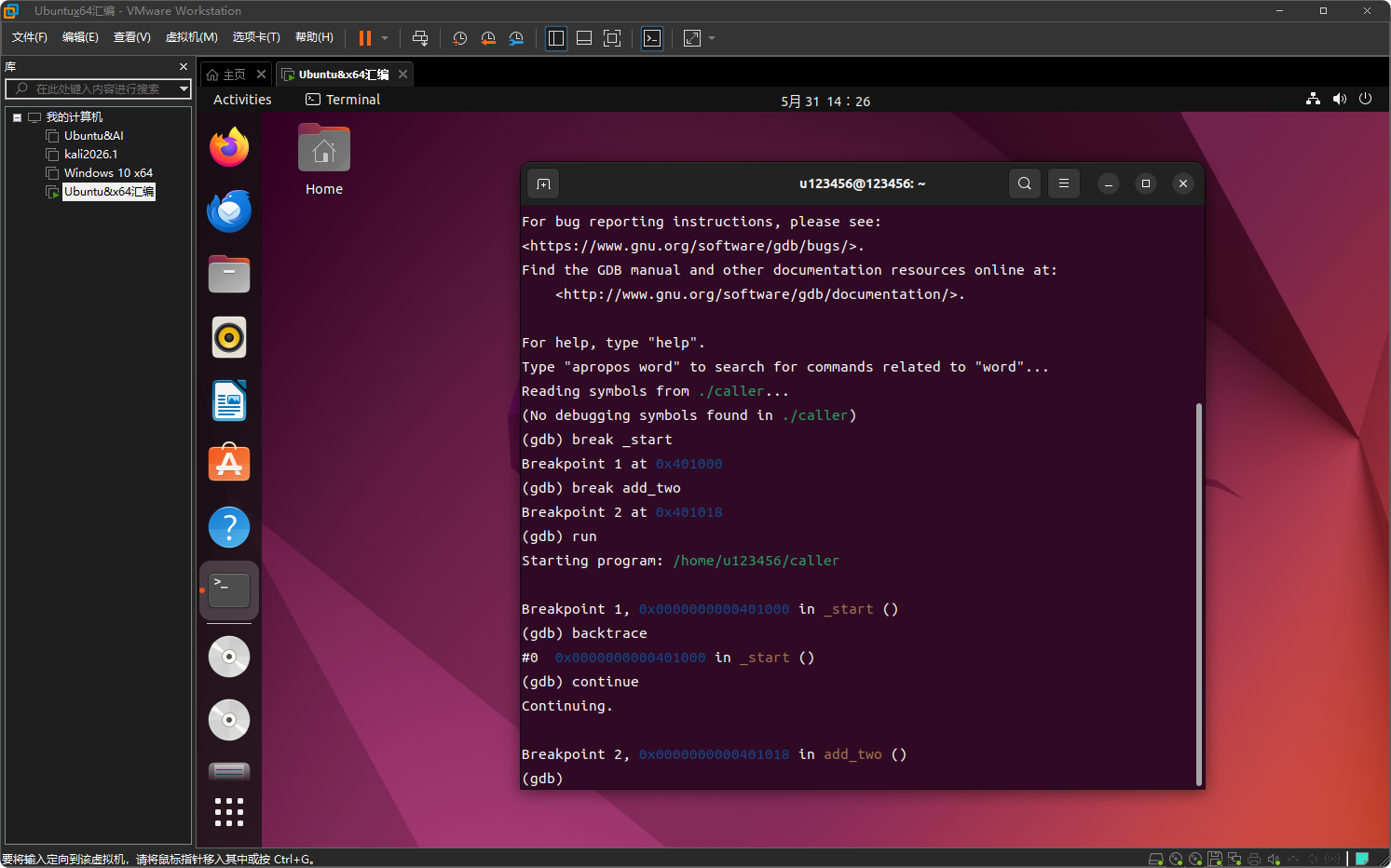
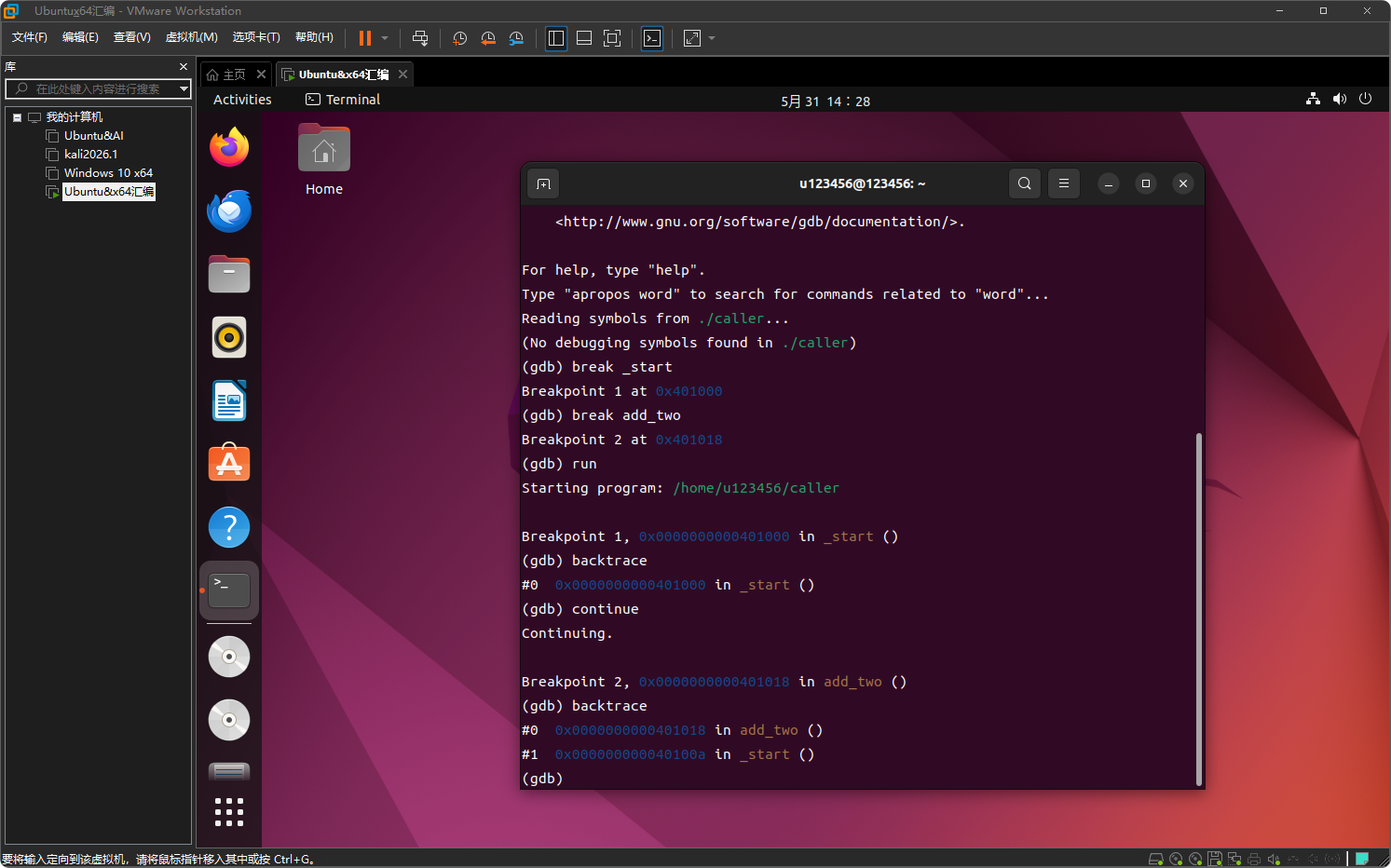
再次查看调用栈
backtrace
现在输出:
#0 0x0000000000401018 in add_two ()
#1 0x000000000040100a in _start ()
这表示backtrace 显示当前正在执行 add_two 函数,它是由 _start 函数调用的。
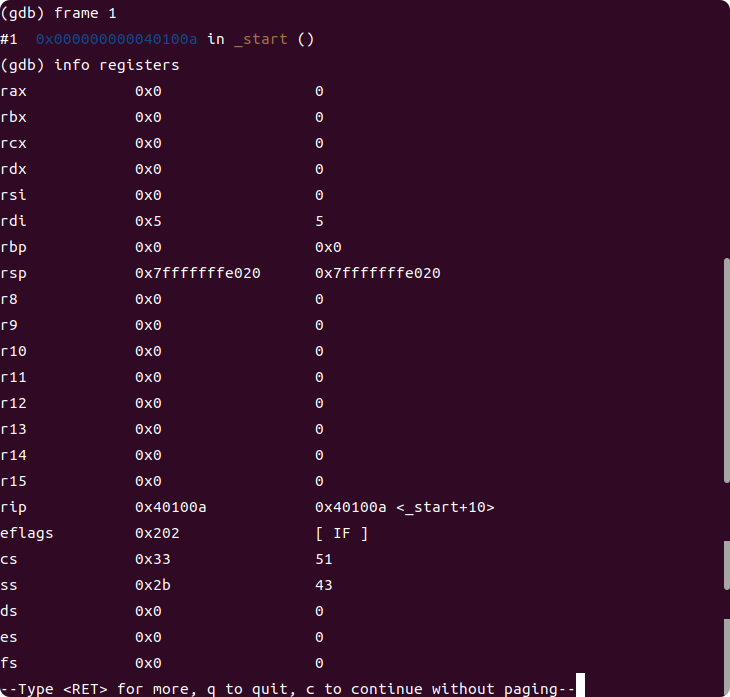
使用 frame 1 切换到 _start 的栈帧,查看当时的寄存器
frame 1
info registers
可以看到调用前的 rdi 值等。
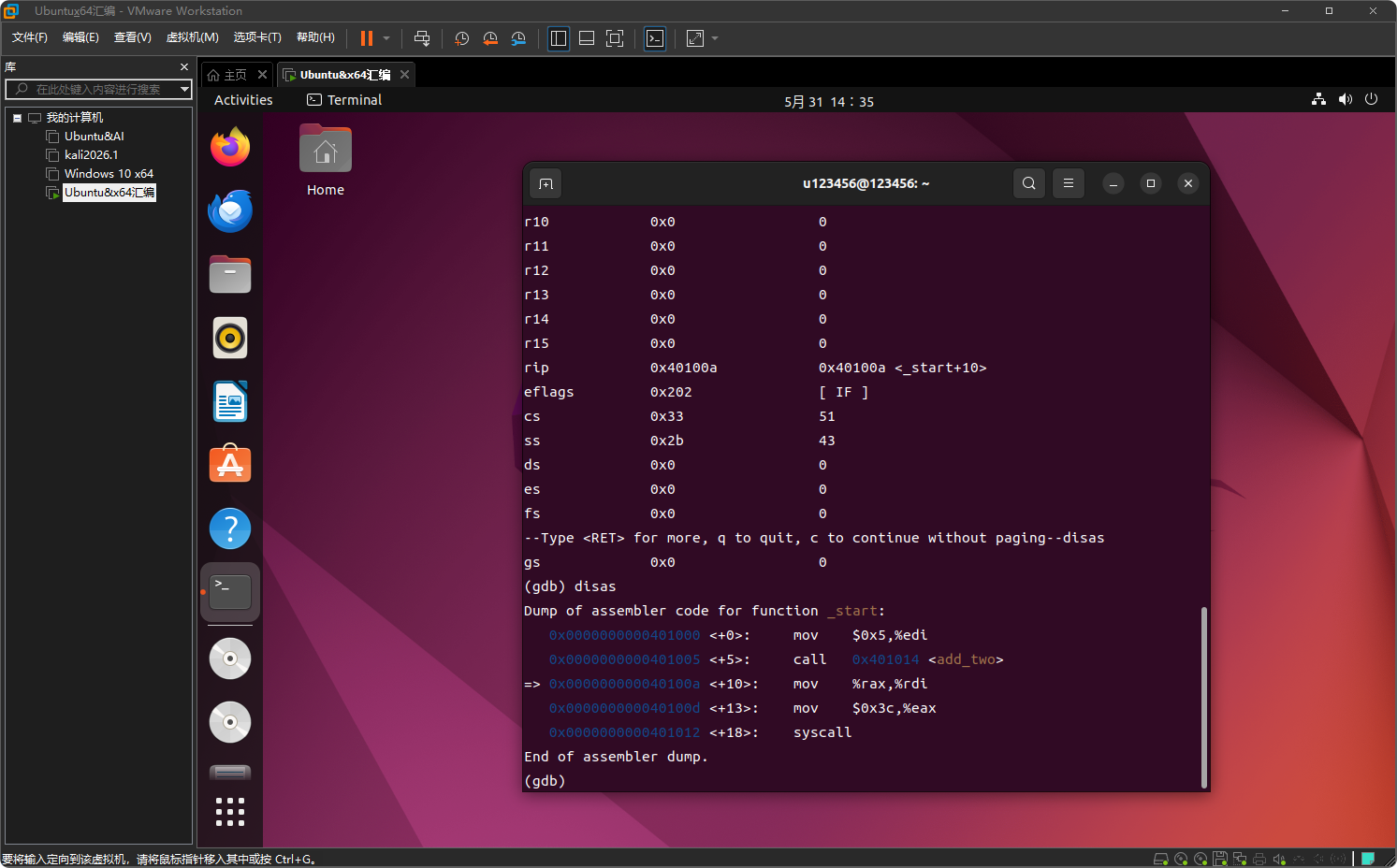
使用 disas 反汇编当前函数
disas
会显示 add_two 的汇编代码,并用箭头 => 标出当前执行位置。
可以继续单步执行,观察栈的变化
函数序言和尾声
本节只讲栈的变化过程,不要求理解具体指令。堆栈的完整工作原理将在下章以纯理论方式讲解,届时再回头看本节的代码图示会非常清晰。
为什么需要函数序言和尾声
当程序调用一个函数时,CPU 需要做三件事:
记住应该回到哪里(返回地址)。
保护调用者的现场(比如调用者的栈基址 rbp)。
为新函数分配局部变量空间。
"序言"是函数开头的几行指令,负责完成第 2、3 项。
"尾声"是函数末尾的几行指令,负责释放局部变量空间并恢复调用者的现场。
示例函数(仅用于观察栈的变化)
cpp
my_func:
push rbp ; 序言开始
mov rbp, rsp
sub rsp, 32
; ... 函数体(什么都不做)
mov rsp, rbp ; 尾声开始
pop rbp
ret不需要逐条理解这些指令,只需知道它们对栈造成了什么样的改变。下面用图示描述整个过程。
栈的变化过程
假设在调用 my_func 之前,栈的状态如下:
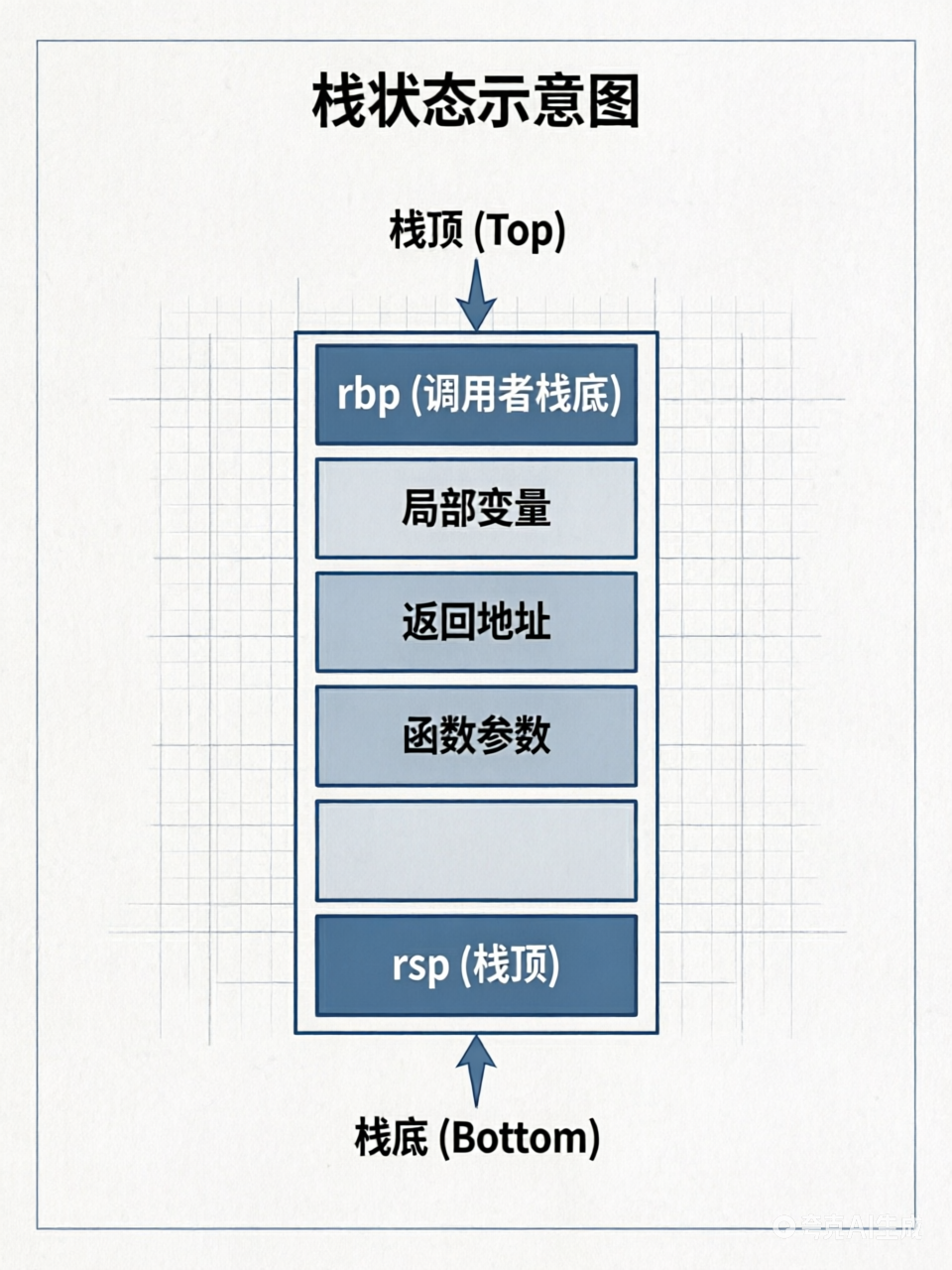
执行 call my_func
CPU 自动将返回地址压入栈中,rsp减小 8 字节。
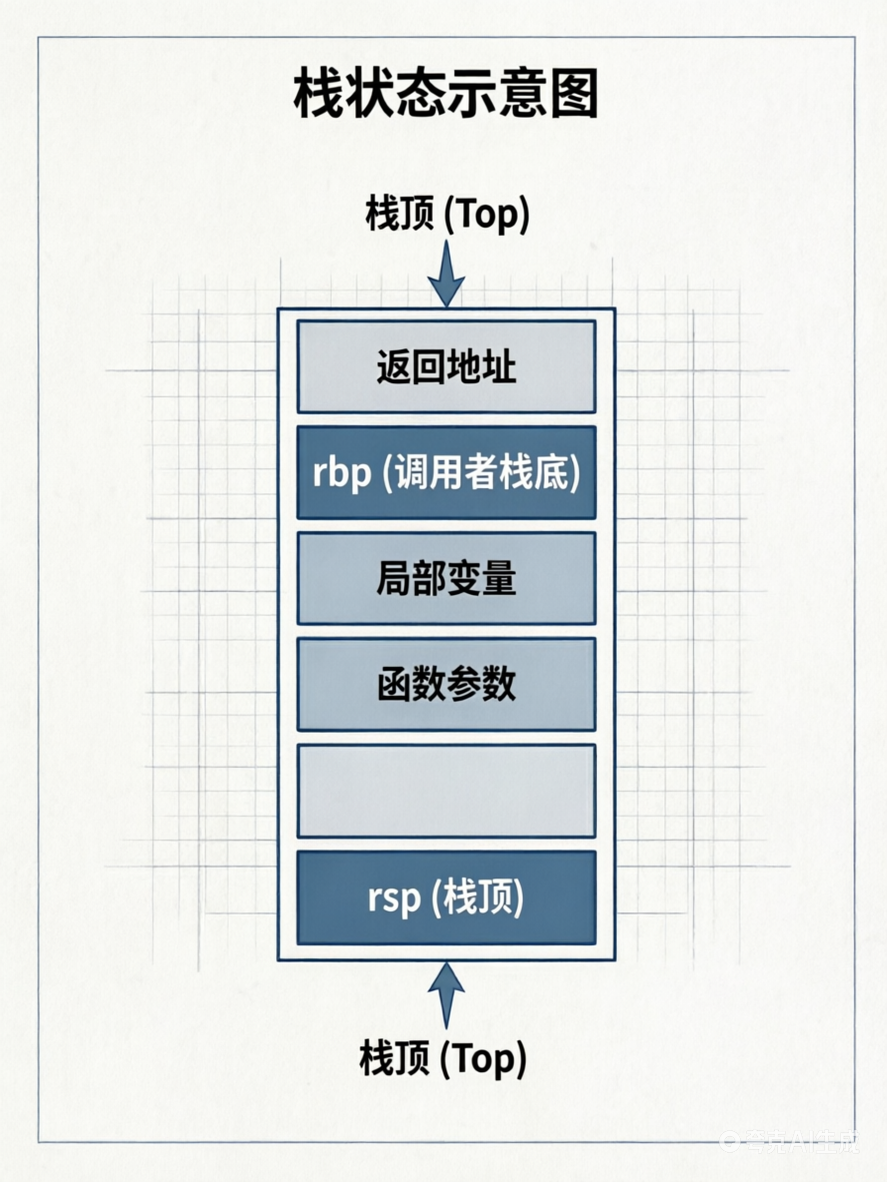
序言第一步:push rbp
将调用者的 rbp 值压栈,rsp 再次减小 8 字节。
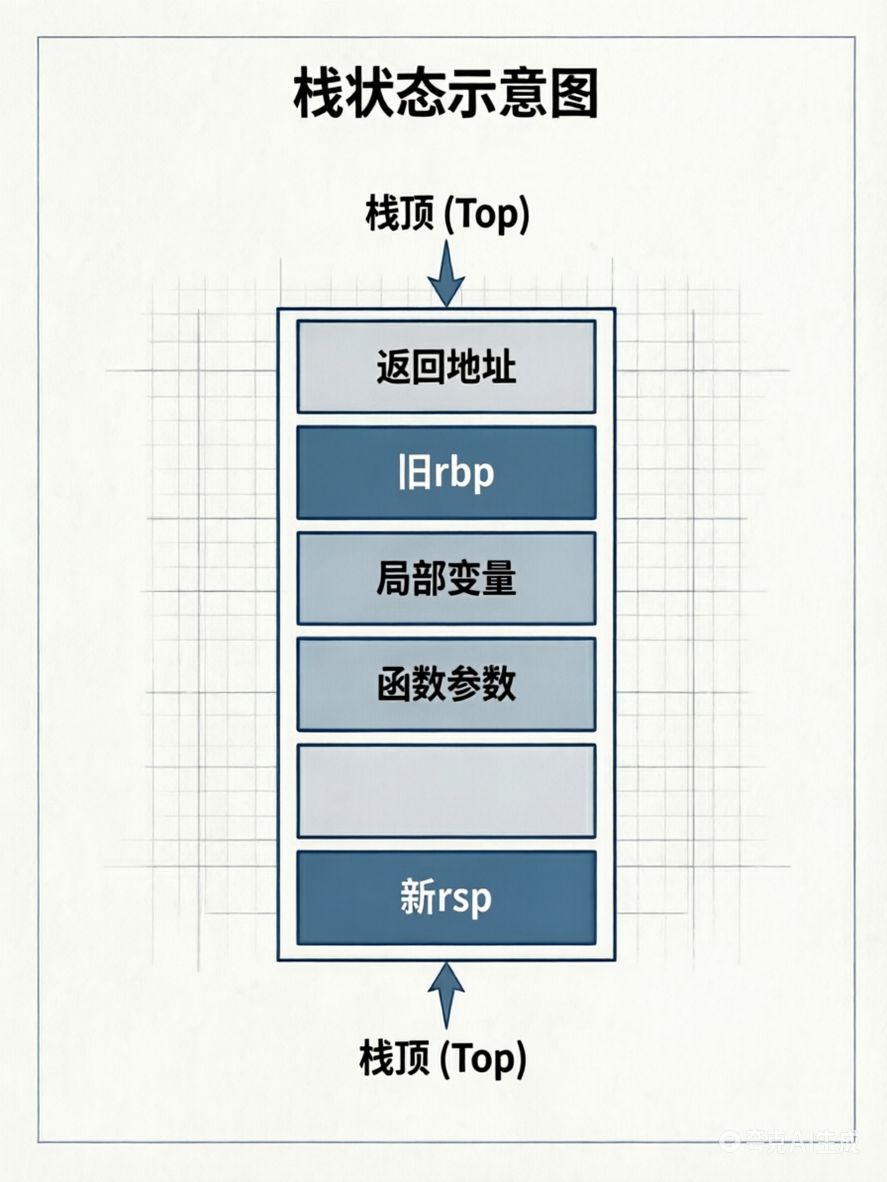
序言第二步:mov rbp, rsp
将 rbp 指向当前栈顶(即旧 rbp 保存的位置)。从此 rbp 成为当前函数的栈帧基址。
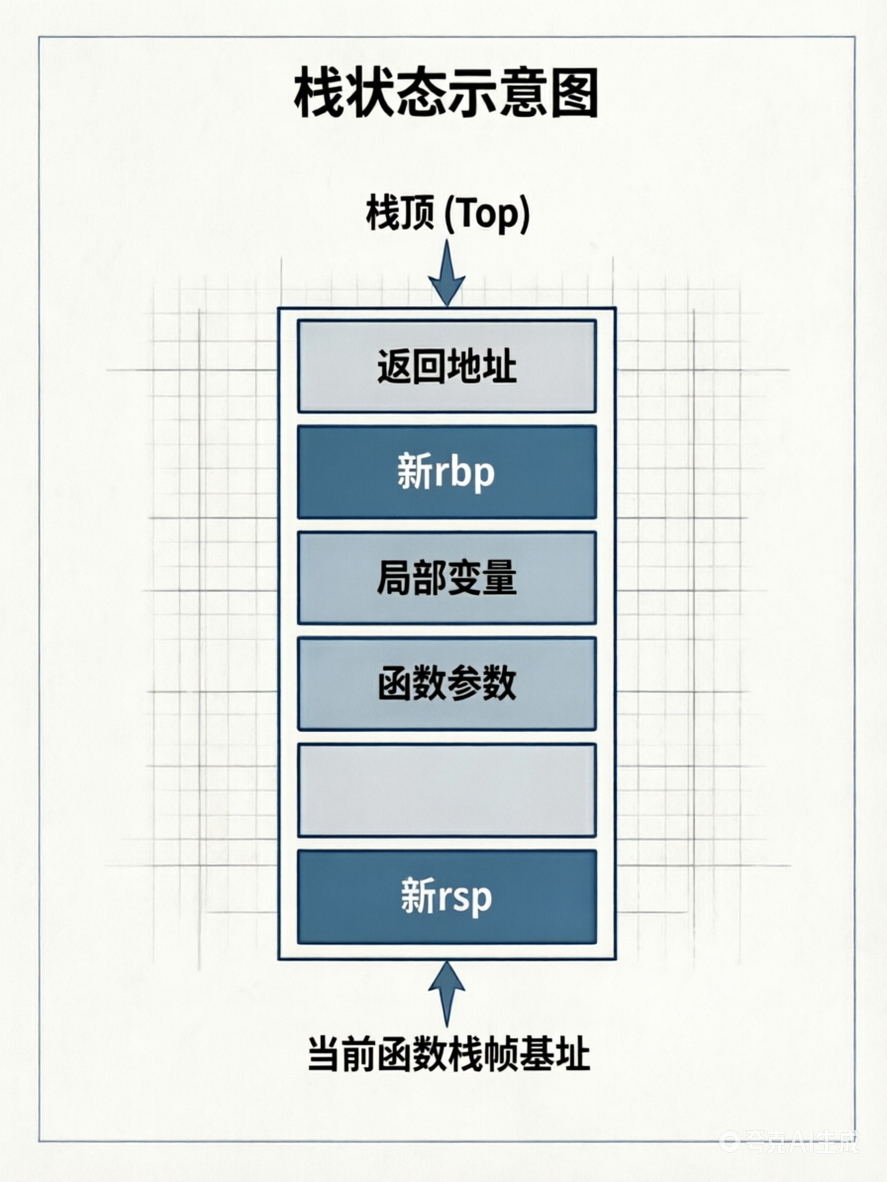
序言第三步:sub rsp, 32
将 rsp 向下移动 32 字节,为局部变量留出空间。此时 rbp-8、rbp-16 等可访问局部变量。
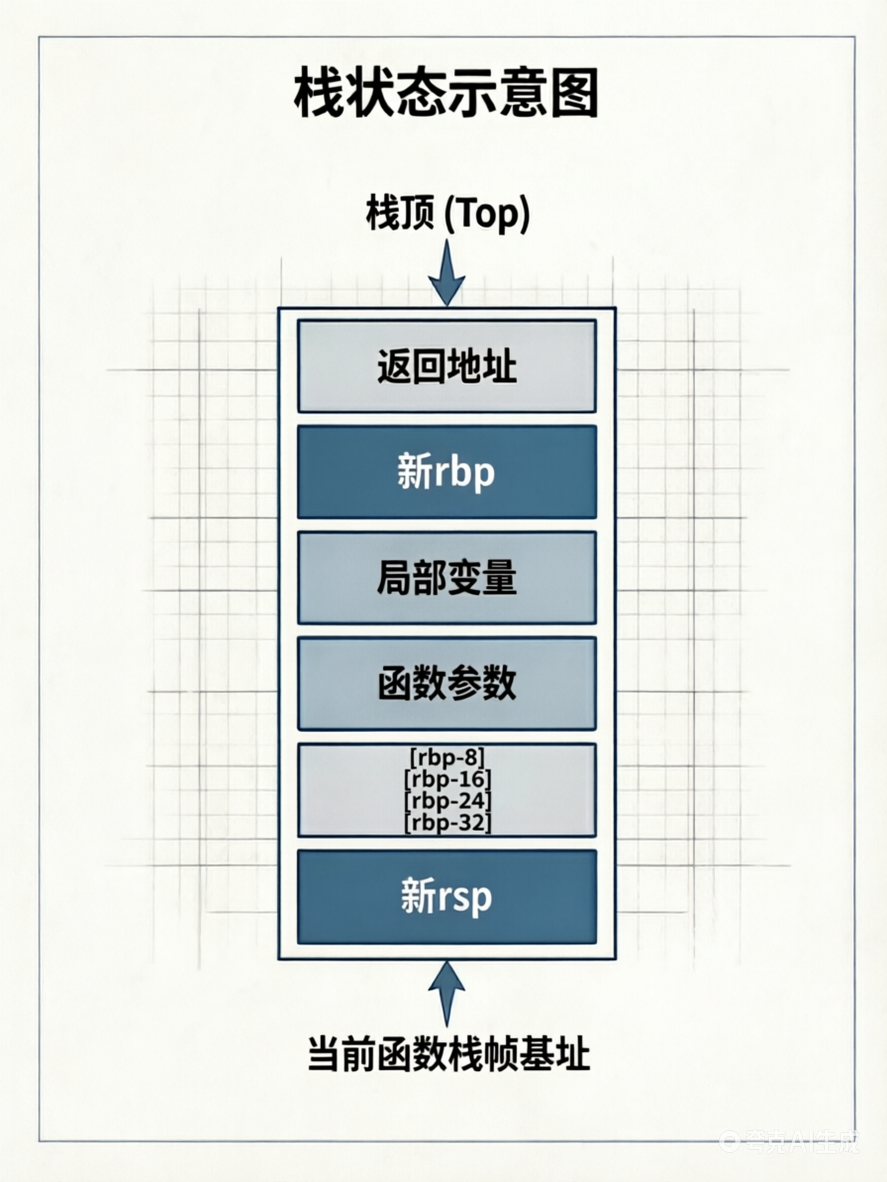
函数体(本例为空)
栈状态保持不变。
尾声第一步:mov rsp, rbp
将 rsp 重新指向 rbp 的位置(即局部变量空间被释放)。
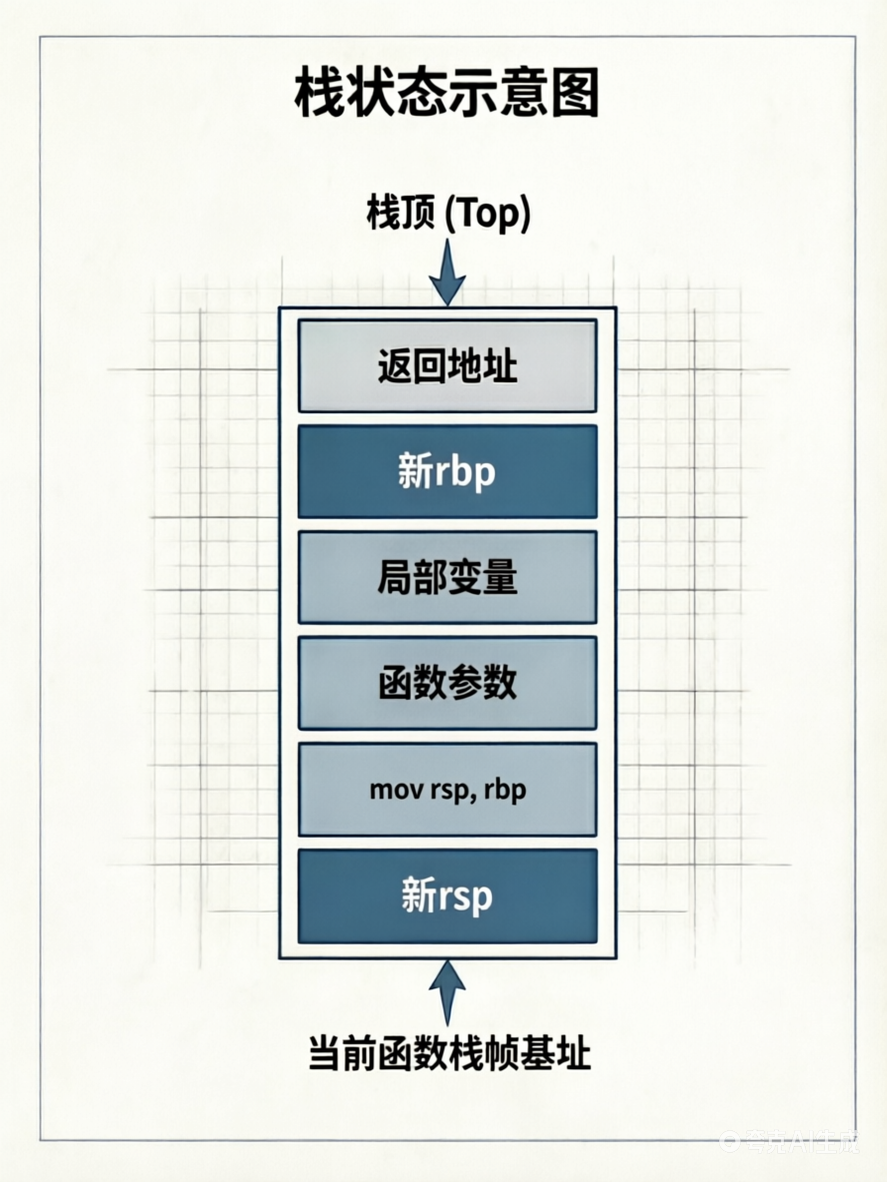
尾声第二步:pop rbp
从栈顶弹出之前保存的调用者 rbp 值,恢复到 rbp 寄存器,同时 rsp 增加 8 字节。
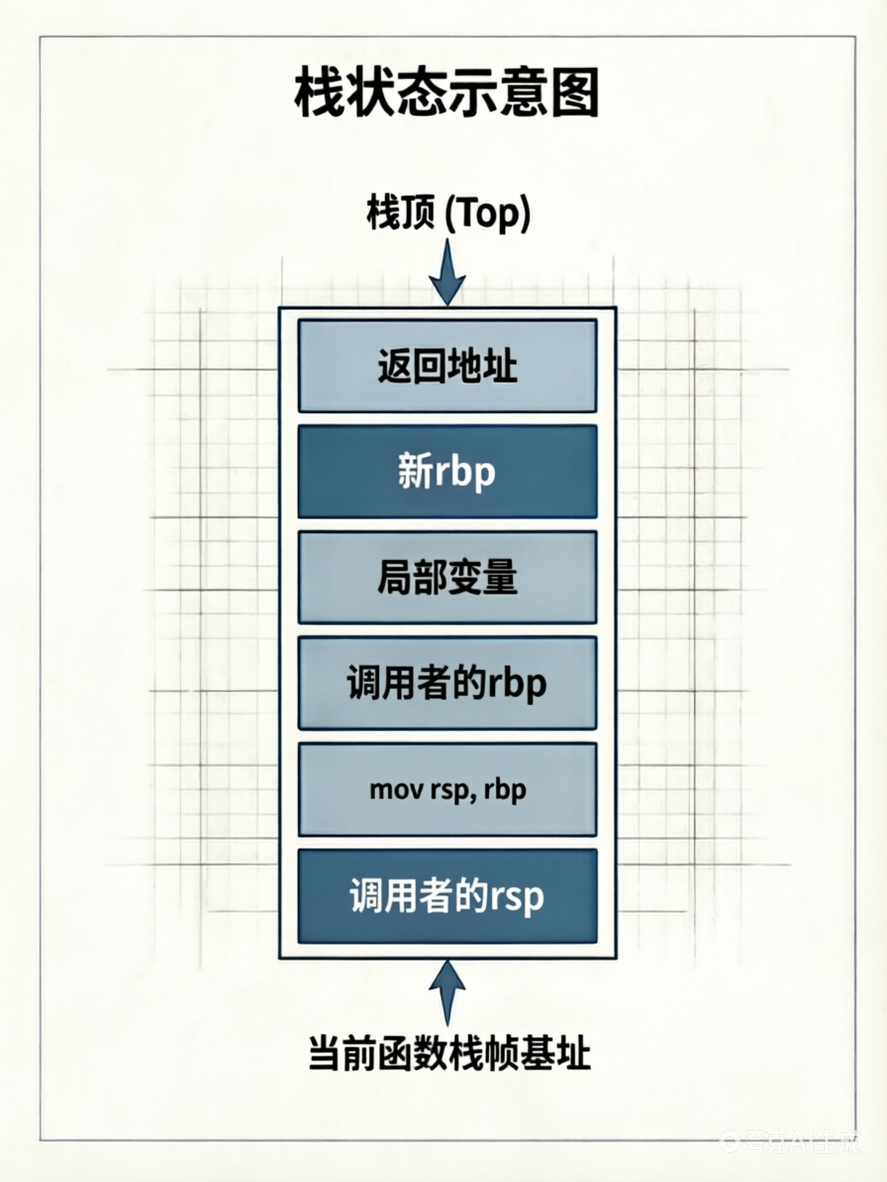
尾声第三步:ret
从栈顶弹出返回地址,跳转回调用函数,rsp 增加 8 字节,栈完全恢复调用前的状态。
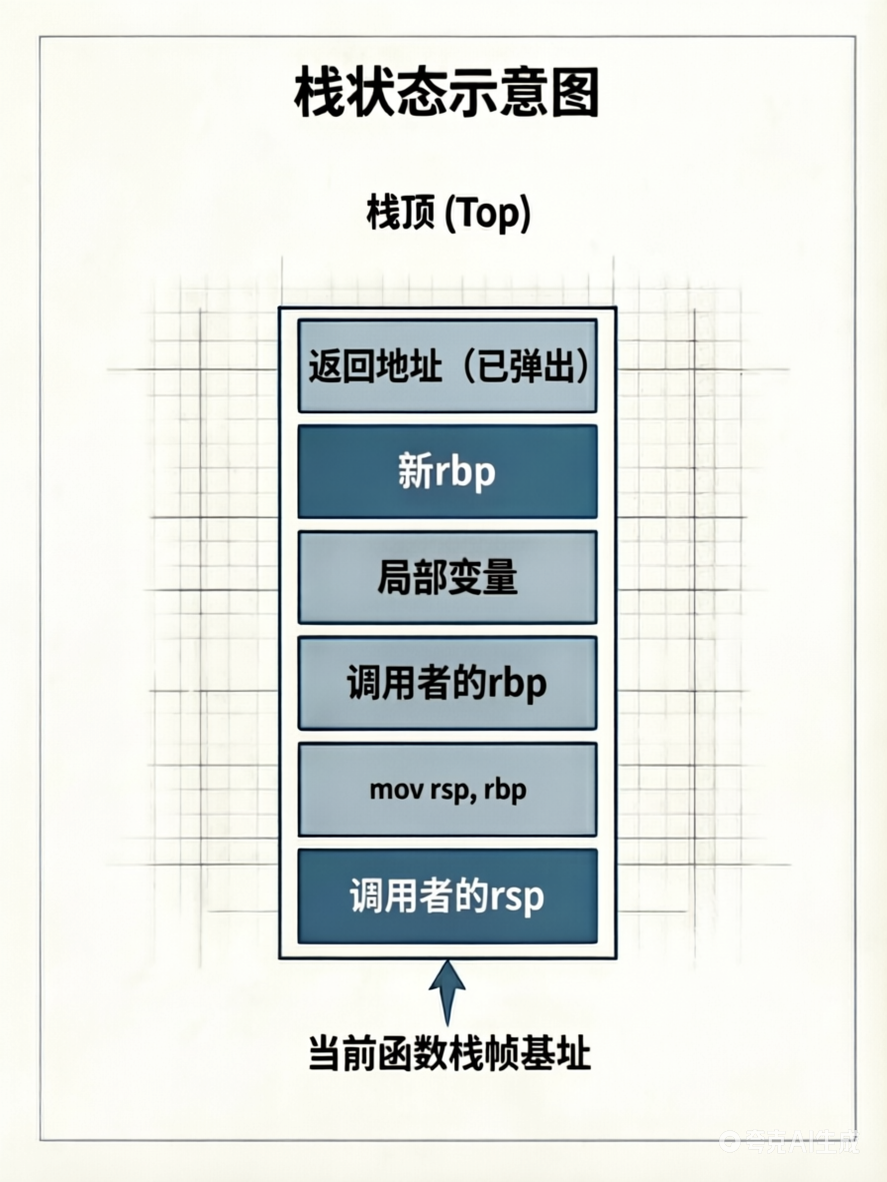
核心概念总结
|--------------|--------------------------------------------------------|
| 概念 | 作用 |
| 返回地址 | 由 call 自动压栈,ret 自动弹栈,保证函数能回到正确位置。 |
| 保存 rbp | 在序言中压栈保存调用者的栈基址,在尾声中恢复。 |
| 新的 rbp | 指向当前栈帧的固定位置,便于通过 rbp-偏移 访问局部变量,通过 rbp+偏移 访问参数。 |
| sub rsp, N | 分配 N 字节的局部变量空间。 |
| mov rsp, rbp | 撤销局部变量空间,相当于 add rsp, N |
大端与小端(字节序)
本节解释多字节数据在内存中的存放顺序,不涉及汇编指令,只讲概念和查看方法。
什么是字节序
当数据超过 1 个字节时(例如 2 字节、4 字节、8 字节的整数),需要决定哪个字节存放在低地址,哪个字节存放在高地址。这种顺序称为字节序(Endianness)。
- 大端(Big-Endian):高位字节存放在低地址,低位字节存放在高地址。
类比:书写数字从左到右,高位在左(如 0x1234,12 在高位,存在低地址)。
- 小端(Little-Endian):低位字节存放在低地址,高位字节存放在高地址。
类比:从右向左写数字,低位在前。
x86 / x64 架构使用小端序,网络协议通常使用大端序(也叫网络字节序)。
对比示例
以 32 位整数 0x12345678 为例,它在内存中的存放情况(假设起始地址 0x1000):

-
大端:高位 0x12 放低地址,符合人类阅读习惯。
-
小端:低位 0x78 放低地址,方便 CPU 进行类型转换和算术运算。
生活类比
-
大端:写十进制数 1234,从左到右是千位、百位、十位、个位,高位(千位)写在最左边(低地址位置)。
-
小端:把数字倒着写,个位在前,千位在后。如同某些语言中读时间"分:秒:时"(低位优先)。
为什么小端在 x86 上流行
-
整数运算时,CPU 从最低字节开始处理,小端序可直接从低地址取最低位,提高效率。
-
类型强制转换(如将 int* 转为 char*)无需移动数据,直接取低地址就是低字节。
如何观察字节序
对于汇编程序中的变量 "value dd 0x12345678",在 GDB 中可以使用 "x/4xb &value" 查看内存,依次显示四个字节的十六进制值。若看到 "78 56 34 12" 则为小端序,"12 34 56 78" 为大端序。
不要求实际操作,只需知道 x64 环境是小端序即可。
使用 C 库函数 printf
为什么要用 printf
在前面我们使用 sys_write 输出字符串,但它不支持格式化(如输出整数 42 需要手动转换数字为字符串)。而 printf 可以轻松输出字符串、整数、浮点数等,极大方便调试和信息展示。
调用 printf 需要做什么
在汇编源文件中声明 extern printf。
按照 System V AMD64 调用约定传递参数:
rdi:格式字符串地址(如 "Hello, %d\n")。
rsi:第一个要输出的值(对应 %d)。
rdx:第二个值,依此类推(浮点数用 xmm0 等)。
确保栈指针 rsp 在 call 之前是 16 字节对齐(因为 printf 内部可能使用 SSE 指令,对齐要求更高)。
使用 gcc 链接(因为需要链接 C 库),不能直接用 ld。
示例:输出字符串和整数
cpp
; printf_demo.asm
extern printf ; 声明外部函数
section .data
fmt db "Hello, %s! The answer is %d", 10, 0
msg db "world", 0
answer dd 42
section .text
global main ; 使用 main 以便 gcc 处理初始化
main:
push rbp
mov rbp, rsp
; 调用 printf(fmt, msg, 42)
mov rdi, fmt ; 格式字符串
mov rsi, msg ; 第一个 %s
mov edx, [answer] ; 第二个 %d(使用 edx 传递)
call printf
; 恢复栈并返回
mov rsp, rbp
pop rbp
ret编译运行:
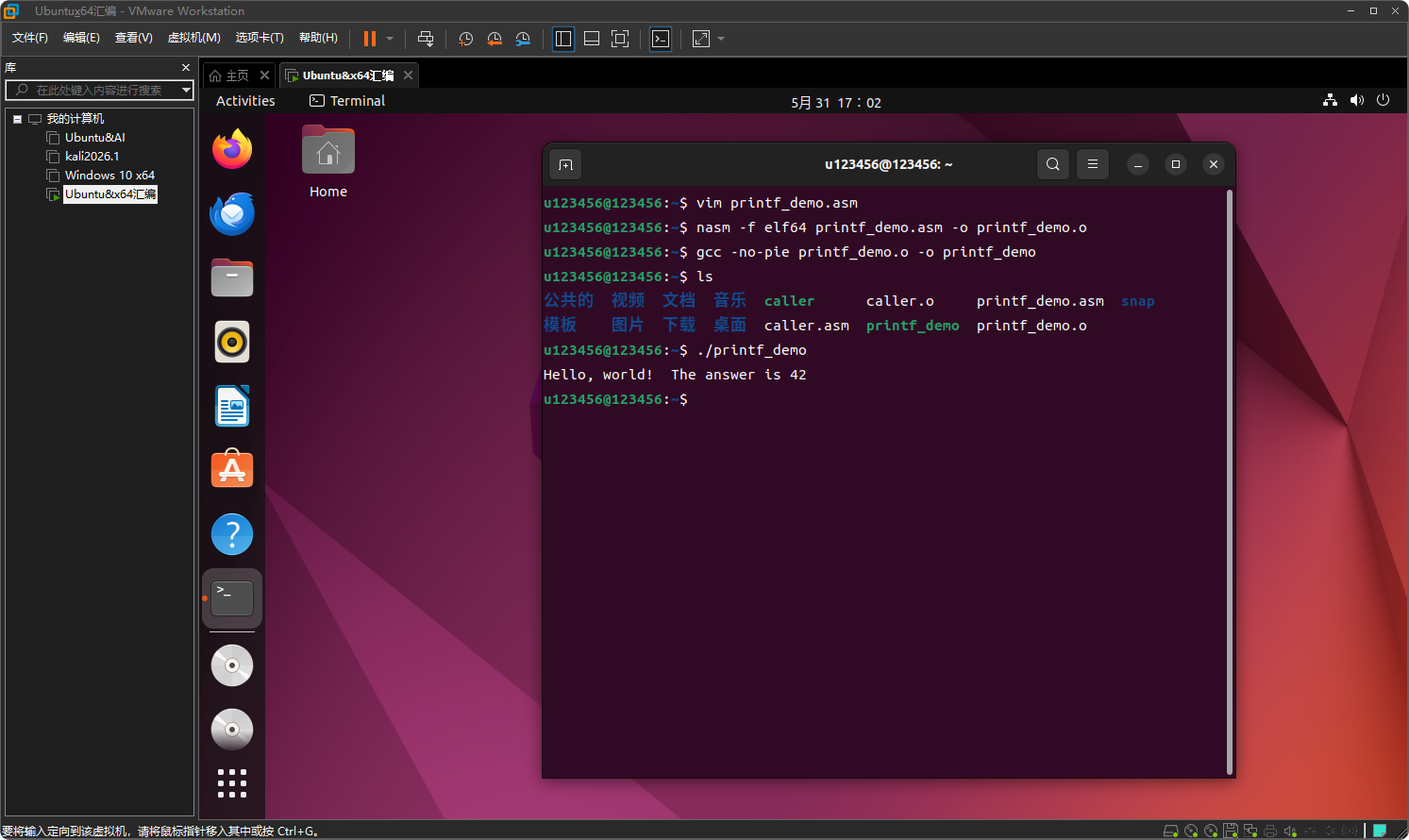
nasm -f elf64 printf_demo.asm -o printf_demo.o
gcc -no-pie printf_demo.o -o printf_demo
./printf_demo
输出:
Hello, world! The answer is 42
参数传递规则回顾(仅整数/指针)
|------|-----|----------------------|
| 参数顺序 | 寄存器 | 说明 |
| 第1个 | rdi | 格式字符串地址 |
| 第2个 | rsi | 对应 %d、%s 等的值 |
| 第3个 | rdx | |
| 第4个 | rcx | |
| 第5个 | r8 | |
| 第6个 | r9 | |
| 第7个 | 栈 | 从右向左压栈(与调用约定有关,暂不展开) |
浮点数参数使用 xmm0 -- xmm7 寄存器传递,后续章节会详细说明。
关于栈对齐的简单说明
在调用 printf 之前,要求 rsp 的值必须是16 的倍数。示例中,在 main 函数入口处 rsp 满足对齐条件(因为 main 被 C 启动代码调用时已经对齐)。如果在自己写的 _start 中直接调用 printf,则需要手动调整对齐(例如 push rbp 后再检查 rsp,或执行 sub rsp, 8 等)。本节暂时不深入,只需要知道这是必须的规则即可。
输出浮点数示例(简要)
cpp
section .data
fmtf db "pi = %f", 10, 0
pi dq 3.1415926535
section .text
extern printf
global main
main:
push rbp
mov rbp, rsp
mov rdi, fmtf
movsd xmm0, [pi] ; 将双精度浮点数放入 xmm0
call printf
mov rsp, rbp
pop rbp
ret编译链接同上,输出 pi = 3.141593。
常见问题
- 链接错误:undefined reference to printf
必须使用 gcc 链接,不能用 ld。且源文件中需要 extern printf。
- 输出乱码或段错误
可能是格式字符串与参数数量/类型不匹配,或者栈未对齐。
- 使用 _start 还是 main?
为了简化栈对齐和 C 库初始化,推荐使用 main 作为入口,由 gcc 自动处理。若坚持用 _start,则需手动调用 exit 而非 ret,并处理栈对齐。