一、TiDB 分片存储架构:Region、Raft 与 RocksDB 底层机制
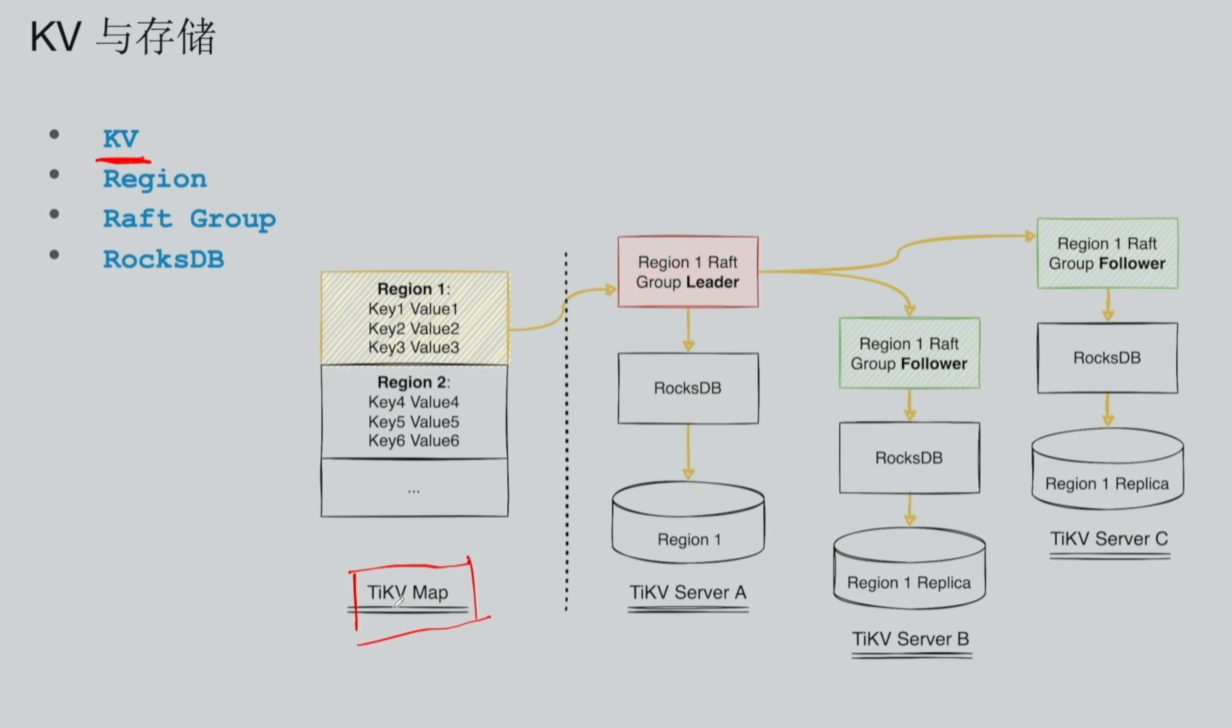
TiKV 作为 TiDB 的分布式存储核心,最小数据存储单元为单行 KV(Key-Value),集群内所有数据记录均以 KV 形式持久化存储。海量的 KV 数据在逻辑上会形成一张有序大 Map,所有 KV 严格按照 Key 字典字节序排序,为范围查询、有序扫描提供基础支撑。
TiDB 依靠 Raft 共识协议 保障分布式数据一致性,默认采用三副本存储。在数据分片与副本复制的设计中,存在两个极端不合理的粒度方案:
-
若以全集群超大有序 Map 作为 Raft 共识单元:数据体量过于庞大,副本同步、故障迁移、集群扩容等运维操作完全无法落地,实用性为零;
-
若以单条 KV 作为 Raft 最小复制单元:海量单行数据独立复制,会造成网络开销、元数据开销爆炸式增长,数据库性能严重劣化。
为平衡数据一致性、读写性能与运维效率,TiDB 引入了 Region 核心概念。Region 是 TiDB 统一的数据分片单元 与Raft 副本最小复制单元,系统默认单个 Region 容量为 96MB,是 TiDB 分布式存储的基础"细胞单元"。
(一)KV、Region、Raft Group、TiKV Server 对应关系
-
Region 与 KV:单个 Region 内部聚合大量有序 KV 数据,通过 Key 区间切分实现数据表分片,是物理数据的最小拆分单位;
-
Region 与 Raft Group:一个 Region 唯一绑定一个独立的 Raft Group,所有副本复制、数据一致性协商、故障自愈均以 Region 为单位进行;
-
Raft Group 与 TiKV 节点:一个 Raft Group 由多台 TiKV Server 节点组成,默认三副本架构。集群会自动将 Region 的三个副本打散部署在不同 TiKV 节点上,组内自动选举一个 Leader 主节点负责所有读写请求,其余节点为 Follower 从副本节点。所有写入操作经 Leader 同步至所有 Follower,完成三副本持久化落地。
不同 Region 对应的 Raft Group 相互独立,Leader 节点、副本节点随机打散部署,实现集群负载均衡。
核心结论:Region 是 TiDB 数据分片与 Raft 复制的核心载体,依托 Raft Group 跨机器多副本机制,实现分布式数据的高可用与强一致性。
(二)RocksDB 在 TiKV 中的核心角色
RocksDB 是 Facebook 开源的单机高性能持久化 KV 存储引擎,由 Google LevelDB 分支迭代优化而来,具备高性能、高可靠、适配海量数据落地的特性。
在 TiDB 分层架构中,TiKV 仅作为分布式调度与计算外壳,不具备本地持久化能力,RocksDB 是 TiKV 唯一的底层磁盘存储底座。完整读写链路为:TiKV 接收上层 Region 读写请求 → 交由 RocksDB 处理 → 最终将所有 KV 数据持久化到物理磁盘。
二、TiDB MVCC 多版本机制:实现原理、核心作用与 GC 回收实战
(一)MVCC 底层更新实现原理
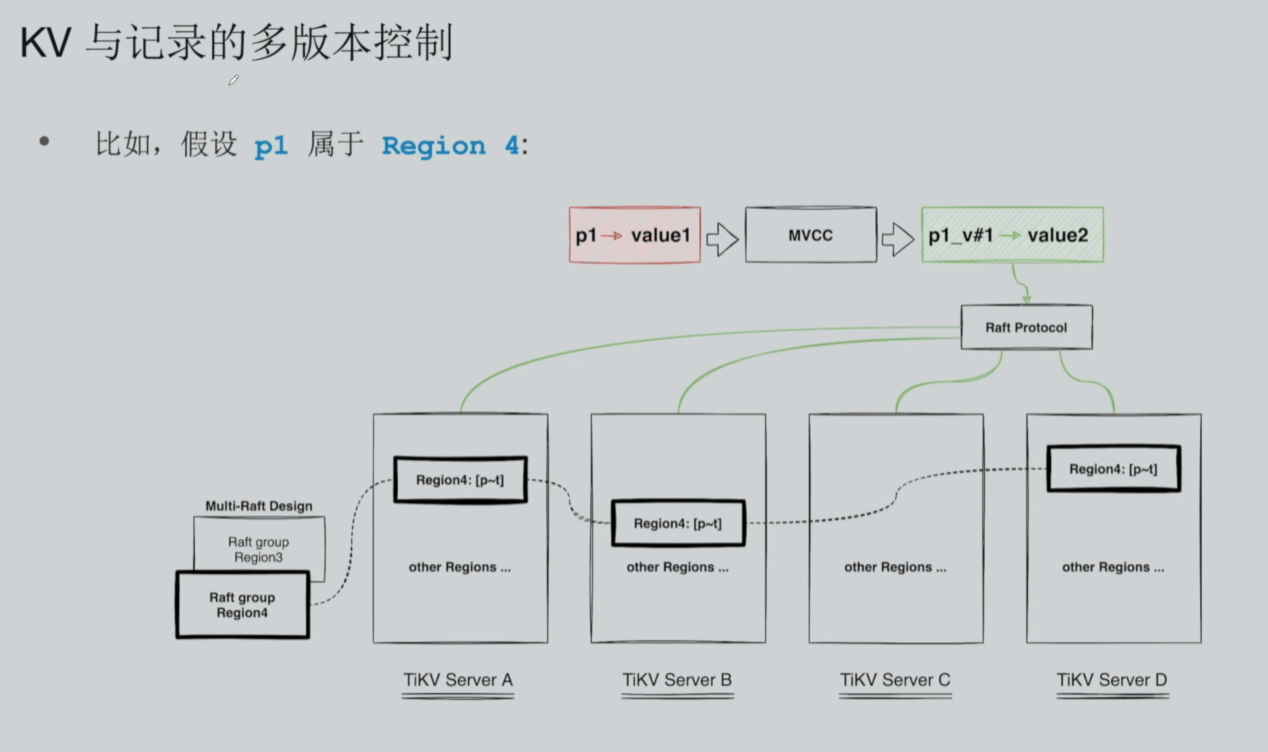
以数据变更场景举例:原始数据 Key=P1,Value=1,业务需求为update P1 set value=2。 普通单机 KV 采用原地覆盖逻辑,直接执行 put (P1,2),旧值 1 直接丢失,无历史版本;TiKV MVCC 采用追加新版本、绝不覆盖原数据的设计思路:原 KV P1=1 完整保留不改动,从 PD 申请全局 TSO 时间戳作为版本号,生成新 Key:P1_TS,执行新增 put (P1_TS,2)。简言之,Update 本质是新增一条带版本的 KV,新旧版本物理共存。
- TSO 版本号说明 PD 提供 TSO 全局单调递增时间戳,兼顾时序 + 全局唯一序号,是 TiDB 全集群统一版本来源;事务开启、数据写入前申请 TS,保证分布式环境版本有序无冲突。
- Key 前缀设计 键格式为:原 Key + 下划线 + TS。示例:旧键 P1、新版键 P1_xxxx (TS),同主键所有历史版本在 RocksDB 有序排列、物理相邻,按前缀扫描即可获取全版本,优化范围查询、快照扫描性能。
- 新数据落盘全链路 新增 KV 归属固定 Region,一个 Region 对应一套独立 Raft Group(默认 3 副本);Leader 节点先写入本地 RocksDB,通过 Raft 同步数据至另外两个 Follower 副本;三副本全部持久化磁盘,旧值、新值永久保存在集群。
(二)MVCC 四大核心作用
- 一致性快照读(支撑 RR/RC 隔离级别):事务启动时绑定快照 TS,读取只选用版本 TS ≤ 快照 TS 的数据,屏蔽后续新写入数据,构建某一刻数据快照。
- 读写无阻塞,提升并发性能:读访问旧版本、写追加新版本,读写互不阻塞,规避传统行锁带来的读写互等阻塞。
- 事务快速回滚:事务失败仅废弃本次新增版本,原有历史数据完好,无需反向回退修改旧数据。
- 历史数据闪回 Flashback Table:依靠留存的多版本,指定历史时间戳即可查询过往数据,用于误删误改的数据恢复。
(三)实战案例:长报表查询 + 并发更新
- 会话 A(报表):10:00 启动大范围 Scan 查询,扫描海量数据,耗时 10min 至 10:10 结束,10 点时 110 行数据:Key=110,V1;
- 会话 B(更新):10:05 执行 update,110 行由 V1 修改为 V2;MVCC 生成新 KV:110_TS (10:05)=V2,旧数据 110=V1 保留。
落地效果
- 快照保证报表数据一致:A 的快照 TS=10:00,10:10 读取 110 行时,10:05 的 V2 版本 TS 大于快照时间,直接过滤,读取旧值 V1;整张报表全部是 10:00 同一时间点的数据,数据口径统一。
- 读写并行不阻塞:无 MVCC 时 A 持有读锁,B 的 update 必须等待 10 分钟查询结束;启用 MVCC 后,A 读旧数据、B 追加新数据,10:05 可立刻完成更新,并发能力大幅提升。
(四)过期版本 GC 回收机制
历史版本不会永久占用磁盘:TiDB 后台 GC 线程,根据 GC 生存时间(默认 10min,运维可改),清理无任何活跃事务依赖的过期 KV,自动释放磁盘;GC 参数调优属于 DBA 运维内容。
一句话总结 MVCC:更新只追加不覆盖,查询按快照时间读取历史版本;实现快照一致性、读写无锁并发、历史数据闪回,过期版本由 GC 异步回收。
三、TiDB 分布式 SQL 原理:协处理器下推与 Raft 多副本容灾机制
(一)TiDB 分布式 SQL 整体架构
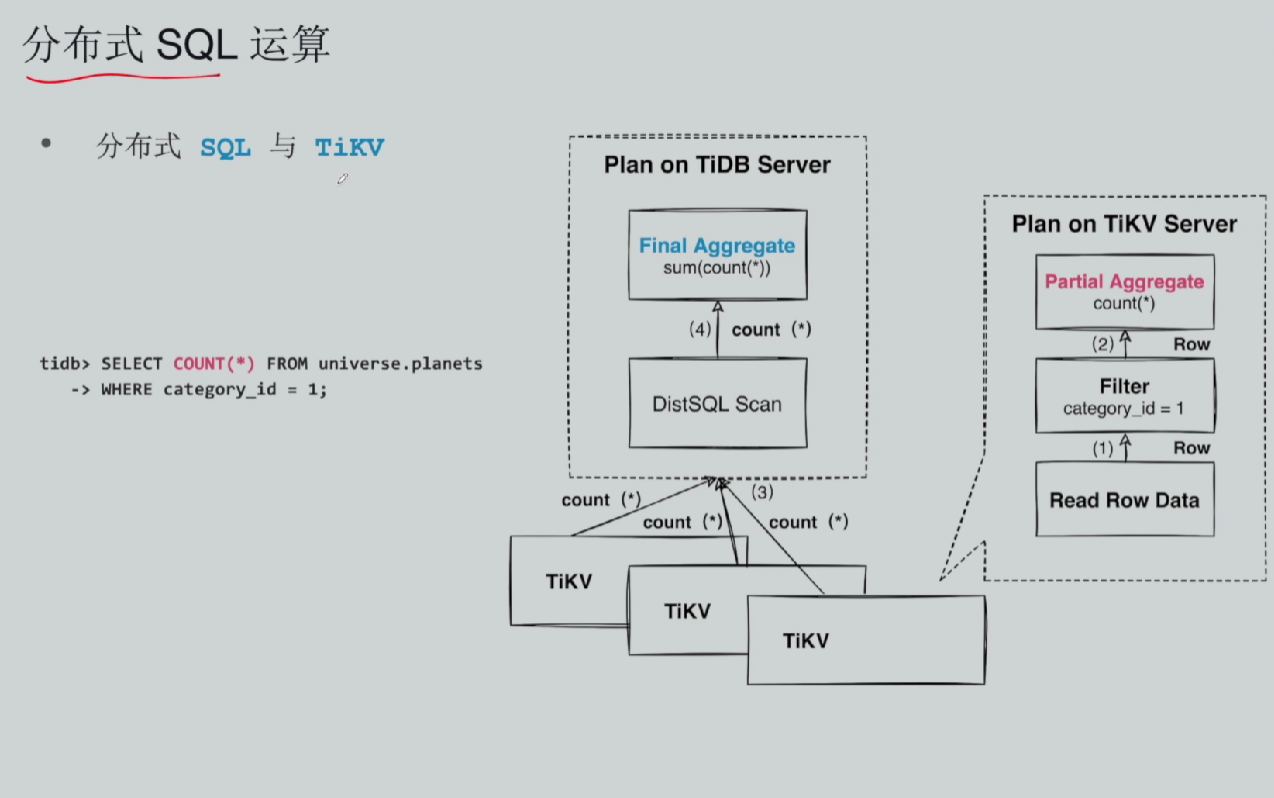
客户端会话连接 TiDB Server(无状态 SQL 计算节点),TiDB 后端对接多台 TiKV Server(分布式存储节点)。一张表的数据按 Key 区间拆分成大量 Region,Region 打散分布在不同 TiKV 实例;一条 SQL 需要跨多个 Region 取数时,TiDB 下发计算任务到多台 TiKV 并行运算,这种 SQL 拆分为多子任务、多存储节点并行执行的模式,就是分布式 SQL。
业务示例 SQL:(统计行星分类 = 1 的数据总行数)
sql
SELECT COUNT(*) FROM universe.planets WHERE category = 1;- 下推计算(Coprocessor 协处理器):TiDB 解析 SQL、查询 PD 获取数据对应的所有 Region 位置,把过滤 category=1+ 局部 count 任务下发到各个 Region 对应的 Leader TiKV 节点;
- TiKV 本地分片计算:多台 TiKV 分别扫描自身管辖数据,在节点内部过滤、统计本地符合条件行数(分片统计值);
- TiDB 汇总结果:各 TiKV 把分片统计结果回传给前端 TiDB Server,TiDB 做最终 sum 汇总,输出全局总计数;本案例 3 个 TiKV 并行运算,并行度 DOP=3。
(二)EXPLAIN ANALYZE 执行计划解读
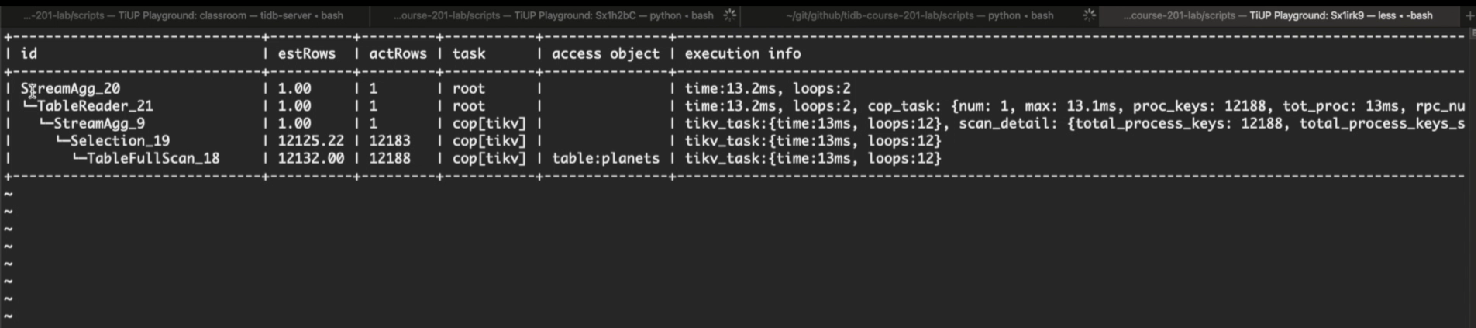
执行EXPLAIN ANALYZE SELECT COUNT(*) FROM universe.planets WHERE category = 1;查看真实执行树: 执行计划是树形结构:下层在 TiKV 执行、上层 Root 聚合在 TiDB 执行;cop=Coprocessor(协处理器),过滤、局部计数逻辑下推至 TiKV 执行。
计划优劣判定:大量数据过滤、扫描、初步统计在 TiKV 完成,仅少量聚合结果回传给 TiDB,减少网络传输、减轻 SQL 节点压力,是优质的分布式执行计划;细节优化、执行计划深度分析在调优专项课程,开发只需掌握分层执行思想。
(三)Raft 多副本高可用:单机 TiKV 宕机业务无感知
1. 副本容错规则(默认 3 副本 Raft Group)
Raft 三副本:最多允许宕机 1 个节点,剩余 2 节点满足过半投票,Raft 集群正常工作、读写不受影响;若配置 5 副本:最多容忍宕机 2 个节点。
2. 关停单台 TiKV 的业务表现
读写业务完全无感知: TiKV 是带状态存储节点,但受 Raft 协议多副本保护;某一台 TiKV 下线后,对应 Region 自动在剩余副本中重新选举新 Leader,数据完整无损。
TiDB 与 TiKV 宕机差异:TiDB Server 是无状态,客户端直连的 TiDB 宕机,应用仅需自动重连其他存活 TiDB 节点即可恢复;TiKV 是有状态存储,依托 Raft 自动故障转移,上层业务不用修改任何代码、无需手动处理故障容灾,数据库底层屏蔽存储故障细节。
集群风险提示:3 副本集群连续宕机≥2 台,不满足 Raft 过半法定人数,对应 Region 不可读写,业务阻塞。
(四)本章节核心知识点总结
- 分布式 SQL 本质:TiDB 做 SQL 解析 + 结果汇总,过滤 / 聚合等计算下推 TiKV 并行执行;
- Cop 协处理器:TiKV 承担数据层计算,减少数据回传,是分布式 SQL 高性能关键;
- Raft 多副本容错:N 副本集群,最大可宕机数量 = floor ((副本数 - 1)/2);3 副本容 1 坏,5 副本容 2 坏;
- 故障隔离:TiDB 无状态、TiKV 靠 Raft 自愈,底层故障对上层业务透明。