1. 指针与数据的"暧昧"关系(基础篇)
-
涵盖内容:
-
字符指针 :
char p = "hello"vschar arr[] = "hello"的本质区别(常量区 vs 栈区)。 -
指针数组 :
int *arr[5]------ 存放指针的数组。 -
数组指针 :
int (*p)[5]------ 指向数组的指针。
-
-
攻克目标:
-
彻底分清"指针数组"和"数组指针"的写法和含义。
-
理解字符串常量在内存中的位置。
-
汇编映射点: mov 指令取地址的区别(取栈地址 lea vs 取常量区地址 mov)。
-
1.1 字符指针
反汇编映射:
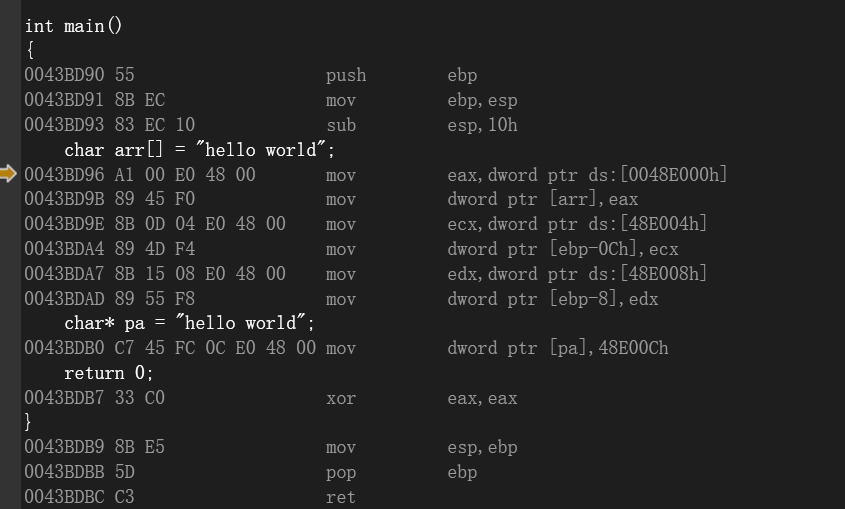
-
编译器优化(反汇编特征)
-
现象: 没有看到
rep movs或loop循环复制。 -
本质: 对于短字符串,编译器会将其拆解为多个
DWORD(4字节),使用MOV指令直接"暴力填充"到栈中。 -
实战意义: 在逆向
Shellcode或还原算法时,看到连续的MOV [EBP-XX], Imm32,要立刻反应过来这是在初始化字符串或数组。
-
-
字符数组 vs 字符指针(内存本质)
-
字符数组 (char arr\[\]):
-
动作: 搬运工。把常量区的数据,完整拷贝一份到栈(Stack)上。
-
关键点: 栈上的数据是可读可写的。你可以修改
arr[0] = 'A',程序正常运行。 -
汇编特征:
mov reg, [地址]->mov [栈], reg(先读内容,再写内容)。
-
-
字符指针 (
char *p):-
动作: 遥控器。只在栈上保存一个 4 字节的地址编号,直接指向常量区。
-
关键点: 常量区通常是只读的(Read-Only)。如果你尝试
*p = 'A',程序会直接崩溃 (Access Violation)。 -
汇编特征:
mov [栈], 立即数地址(直接写地址编号)。
-
-
1.2 指针数组
反汇编映射:
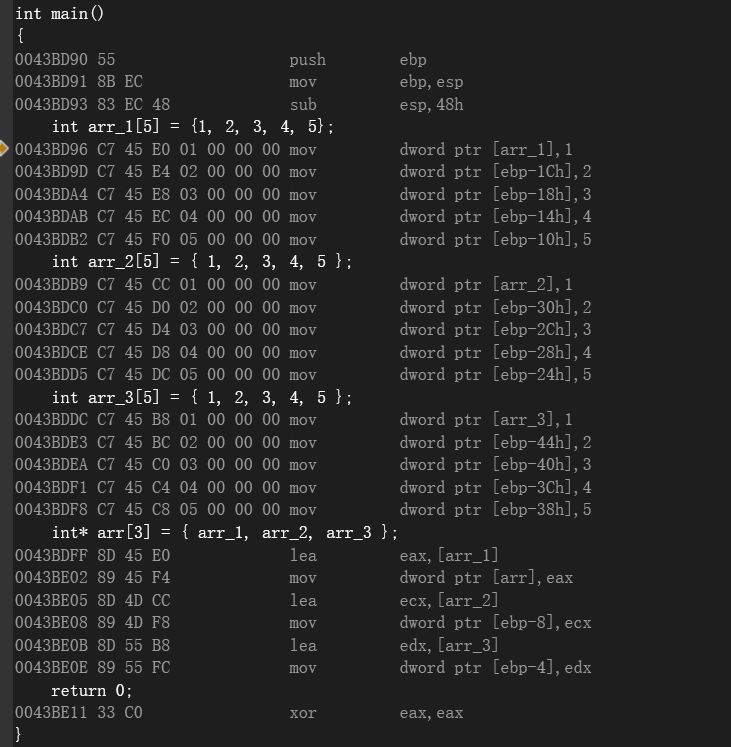
- 从这里我们可以看到指针数组的元素是每个数组首元素的地址,也就是说是把首元素地址当作数据存储到指针数组中。
那么问题来了,在汇编角度中,我们该如何进行取出数组中每个数据(首元素地址 )里面的值(例如:arr_1里面的某个元素)呢?
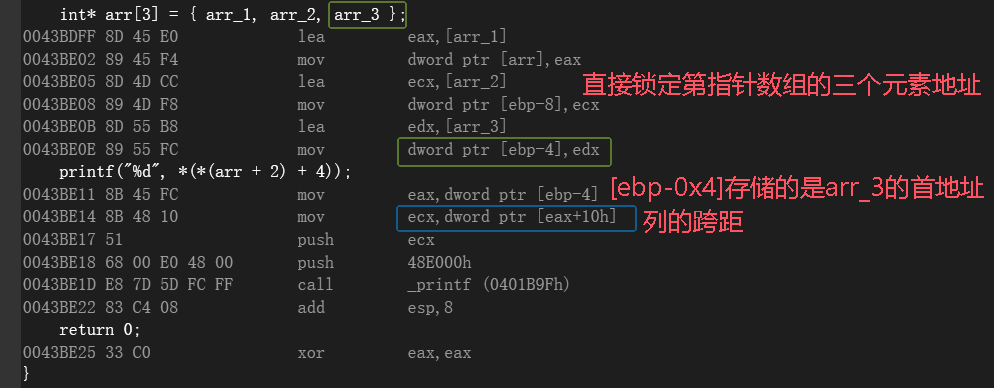
-
分析复盘:
-
第一层:提取"钥匙" (Base Address)
-
分析: 从
[ebp - 0x4]取出 arr_3 数组的首元素地址 汇编指令:mov eax, dword ptr [ebp-4] -
本质: arr 是一个指针数组,它在栈上存的不是数字,而是地址(即 arr_1, arr_2, arr_3 的首地址)。
-
动作:
[ebp-4]是数组 arr 的第 3 个元素(arr2)。 -
结果: 寄存器 EAX 现在拿着一把"钥匙",这把钥匙通向 arr_3 的老家。
-
-
第二层:拿着钥匙找"宝藏" (Value Access)
-
分析: 首元素地址 + 0x10 -> 偏移16个字节,找到 arr_34 的地址。然后取值。
-
汇编指令:
mov ecx, dword ptr [eax+10h] -
动作:CPU 以 EAX (arr_3 的基址) 为起点,向后跳 0x10 个字节,把在那里的数据读出来。
-
-
核心特征总结:如何在逆向中一眼识别"指针数组"?
- 指针数组 (int *arr3) 的汇编签名是: "两次 MOV,一次计算"
-
c
mov reg1, [栈地址A] ; 1. 先读出一个地址 (读到了 arr_3 的基址)
mov reg2, [reg1 + 偏移] ; 2. 再去读那个地址里的内容 (读到了 arr_3[4] 的值)1.3 数组指针
C语言视角:
c
int main()
{
int arr[10] = { 0 };
// 实验组 A:打印地址
printf("%p\n", arr);
printf("%p\n", &arr);
// 实验组 B:加法运算(核心!)
printf("%p\n", arr + 1);
printf("%p\n", &arr + 1);
return 0;
}反汇编视角:
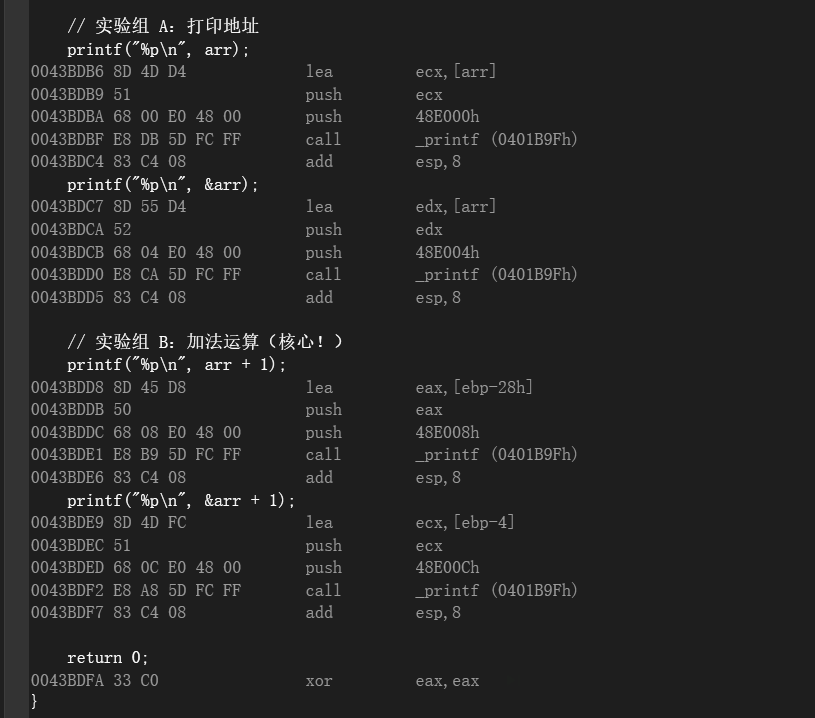
-
我们可以看到编译器其实还是做了轻微优化,并没有告诉我们
[ebp - 0x28]以及[ebp - 0x4]是什么,但是根据我们上下文分析可以推断, -
[ebp - 0x28]->arr + 1;[ebp - 0x4]->&arr + 1; -
arr+1是跨了一个字节距离,&arr + 1是跨了一个数组大小的距离。
战术总结:
-
汇编里的"类型"就是"步长":
-
当 CPU 看到
int *,它眼里的步长是 4。 -
当 CPU 看到
int (*)[10],它眼里的步长是40 (0x28)。 -
所谓的 "数组指针" ,在汇编层面不过是一次更大跨度的内存偏移计算而已。
1.4 遍历数组指针和指针数组的区别
指针数组遍历核心片段:
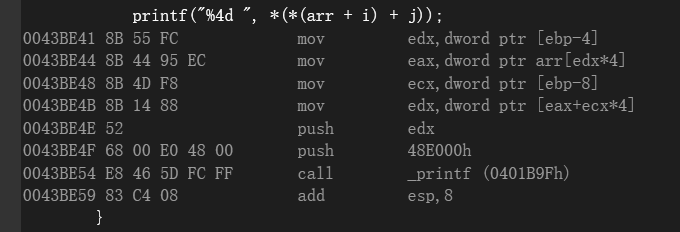
总结:先提取数组首元素地址,然后在进行数组内的偏移拿到值。
数组指针遍历核心片段:
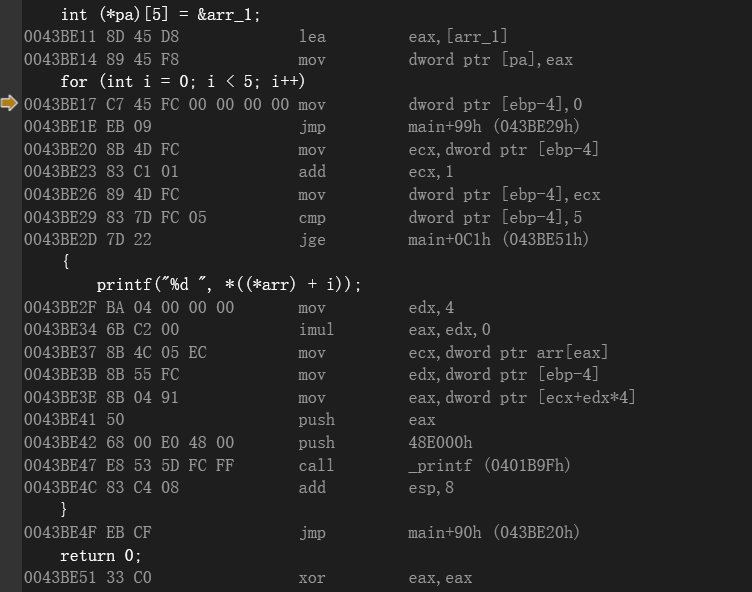
总结:以数组首元素为基准,在此基础上进行偏移。
2. 调用函数指针与调用函数区别
C语言:
c
void test()
{
printf("hello world\n");
}
int main()
{
test();
void(*pa)() = &test;
pa();
return 0;
}反汇编:
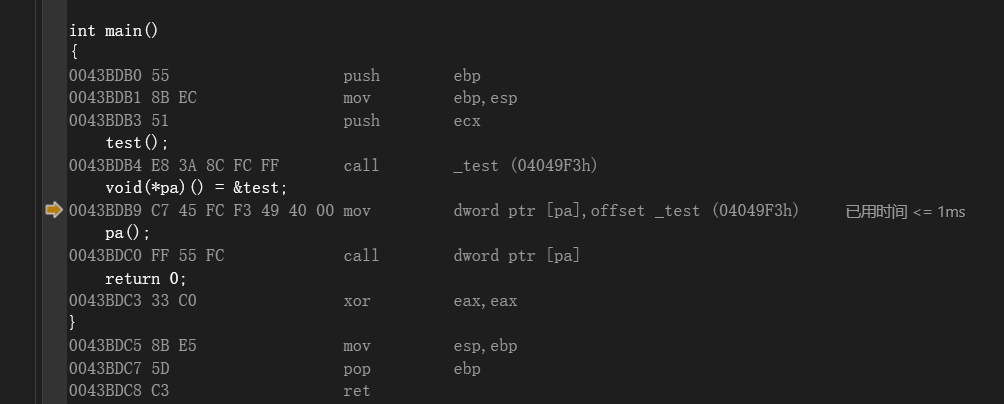
-
调用函数: 直接call立即数
-
调用函数指针: 将pa存储的值(函数地址)放入寄存器,call 寄存器
-
因为立即数是死的,也就代表着调用的是死地址,这种直接的风格也是代表着调用的函数是确定性的;但是函数指针则不确定,我们要知道,指针严格意义上来讲是变量,变量存储什么函数地址是不确定的,所以我们把变量放入寄存器再去call符合间接调用。
2.1 遍历函数指针数组与分析反汇编特征
C语言:
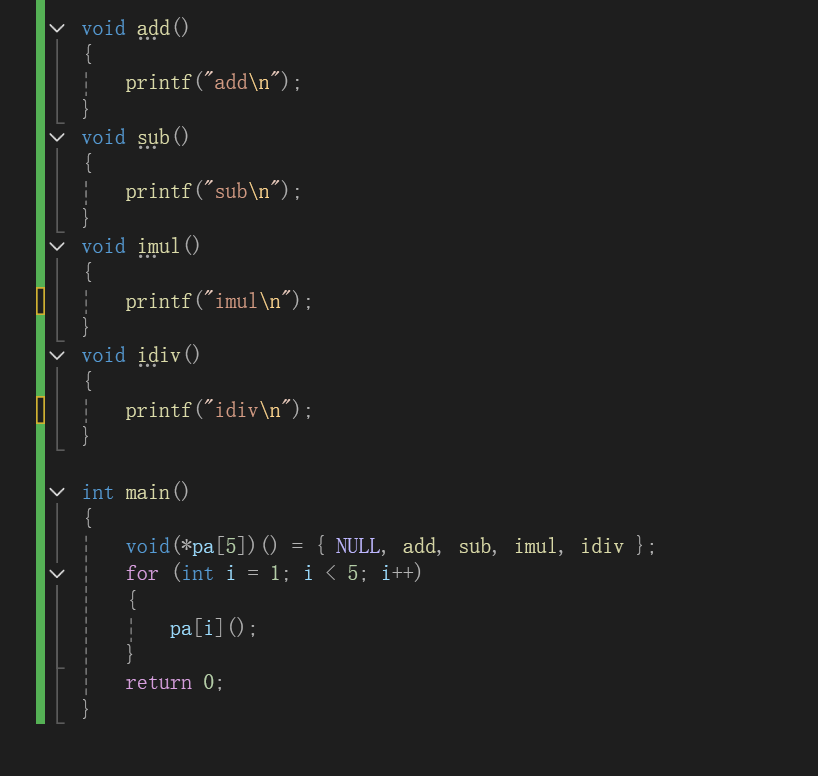
反汇编:
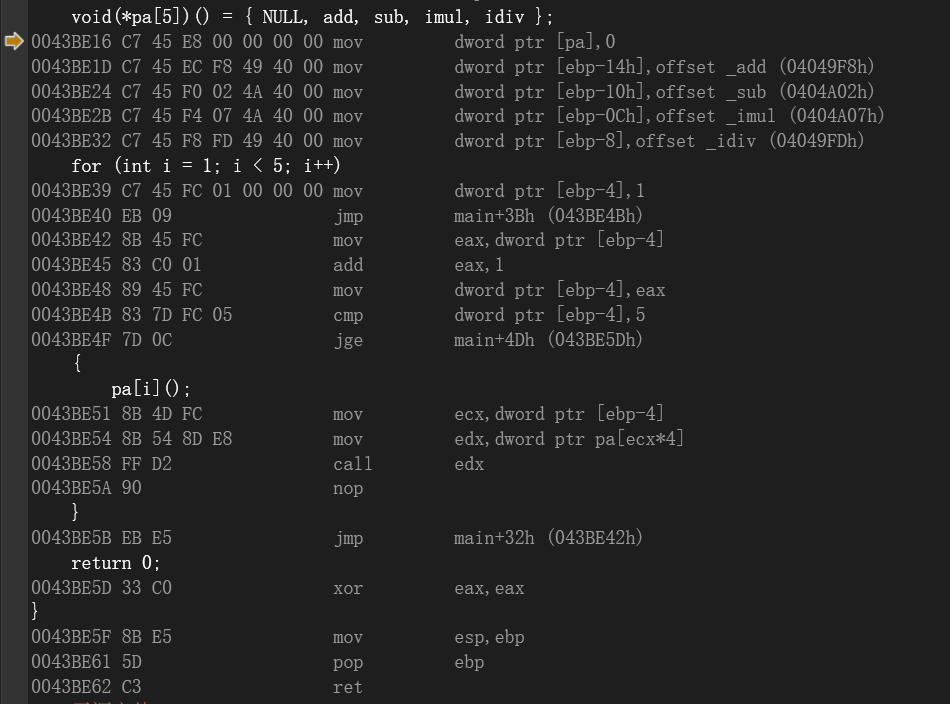
-
核心复盘:遍历函数指针数组 (The Essence of Function Pointer Arrays)
-
内存布局:连续的"跳板"
-
存储形态: 函数指针数组本质上是一个 "地址列表"。
-
物理特征: 所有函数的入口地址(如 add, sub)在内存中是 紧密排列、互不间隔 的。
-
数据宽度: 每个元素占用 4 字节(32位环境下),这决定了汇编运算的步长(Scale)。
-
-
寻址逻辑:查表法 (Look-up Table)
-
我们不是通过 if-else 去判断调用谁,而是通过 "计算" 来定位:
-
输入: 数组下标 i (索引)。
-
计算:
i * 4(偏移量)。 -
定位: 基址 + 偏移量 = 目标函数指针在栈上的存储位置。
-
动作: "下标背后的值,就是函数的地址。"
-
-
汇编三部曲 (The Assembly Trilogy)
-
在底层视角下,一次函数指针数组的调用 (pai) 永远分为这三步:
-
算 (Calculate): 利用 CPU 的 SIB 寻址 硬件能力,直接计算出内存地址。
- Raw Assembly: ebp - 基址偏移 + ecx \* 4
-
取 (Fetch): 从计算出的内存地址中,把目标函数的 入口地址 搬运到寄存器。
- Instruction: MOV EDX, 算出来的地址
-
跳 (Indirect Call): CPU 对寄存器内的地址发起"盲跳"。
- Instruction: CALL EDX (间接调用)
-
-
一句话总结:
- "函数指针数组,就是将'逻辑流'变成了'数据流'。我们通过计算偏移量(Stride),从连续的内存中抓取目标地址,实现精准的间接跳转。"
-
3. 模拟C语言以及正向汇编实现快速排序
3.1 模拟快排_C语言
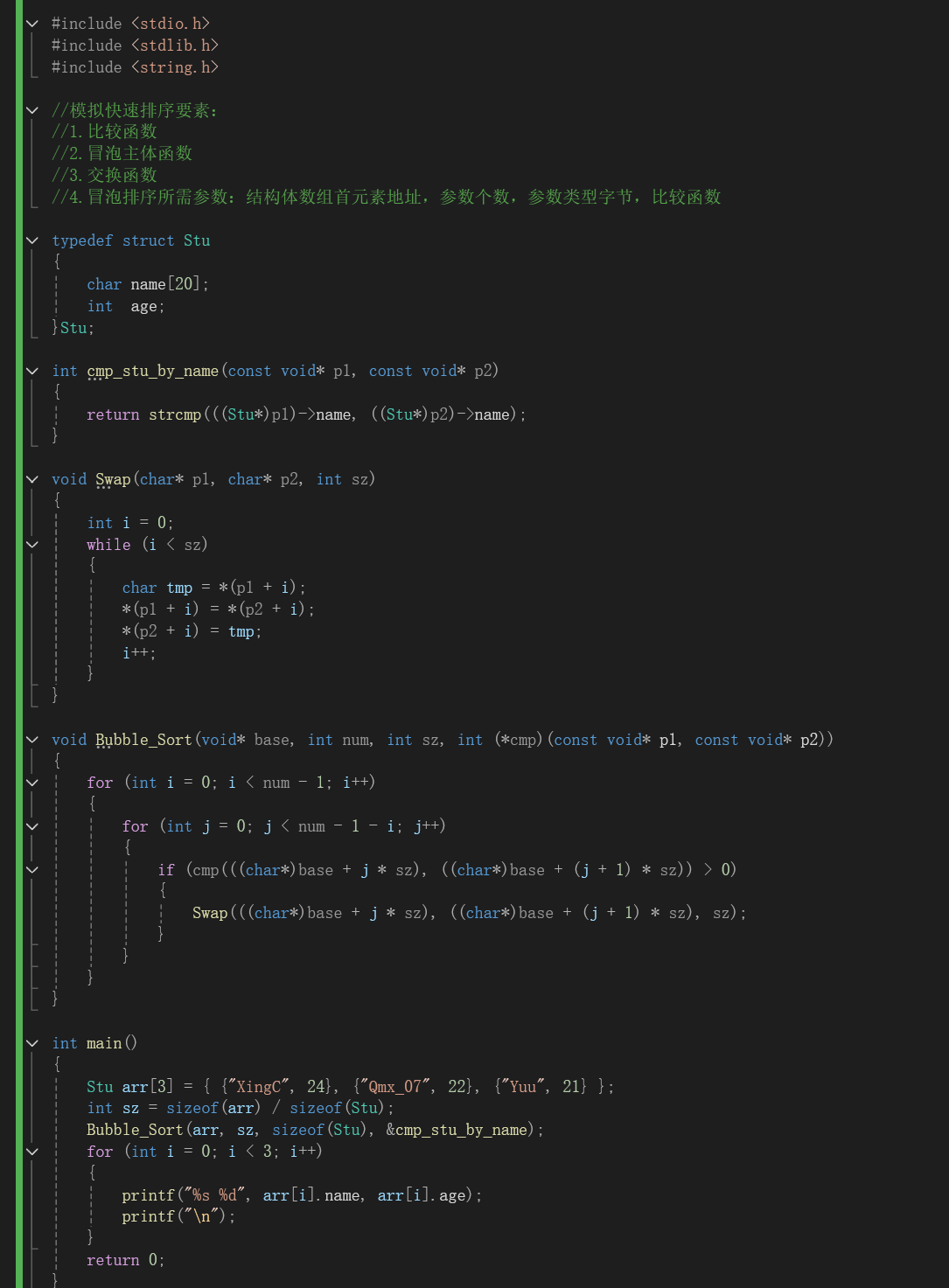
3.2 正向汇编_模拟快排
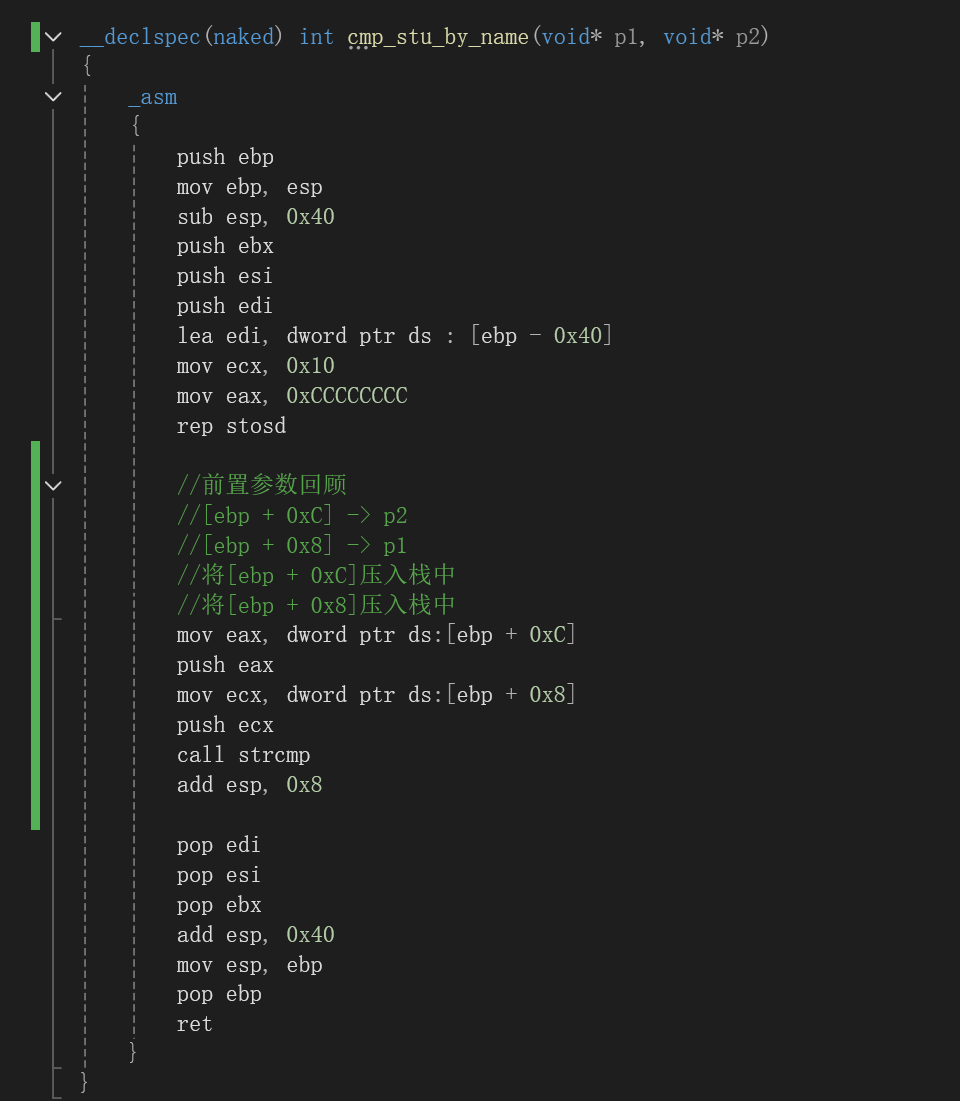
3.2.1 cmp_stu_by_name
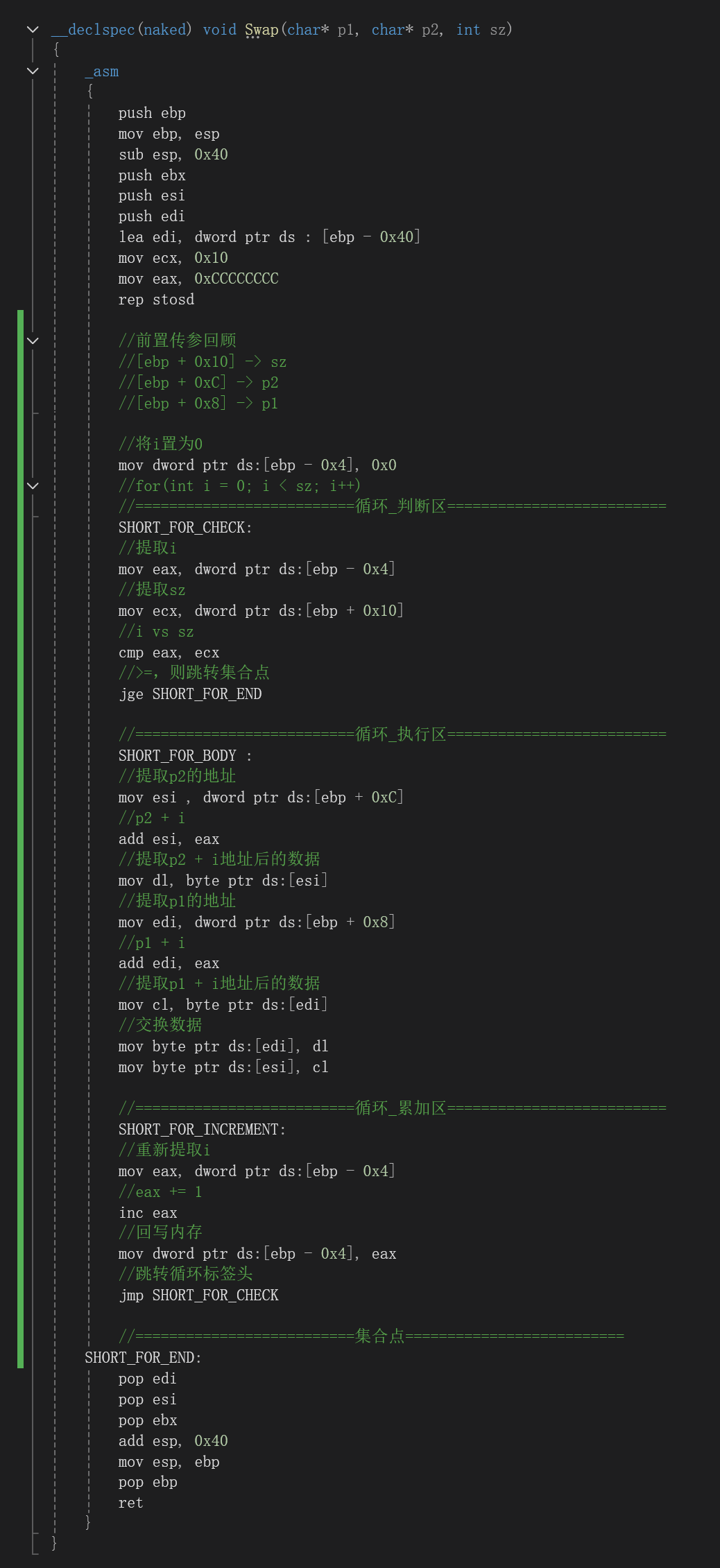
3.2.2 Swap
3.2.3 Bubble_Sort
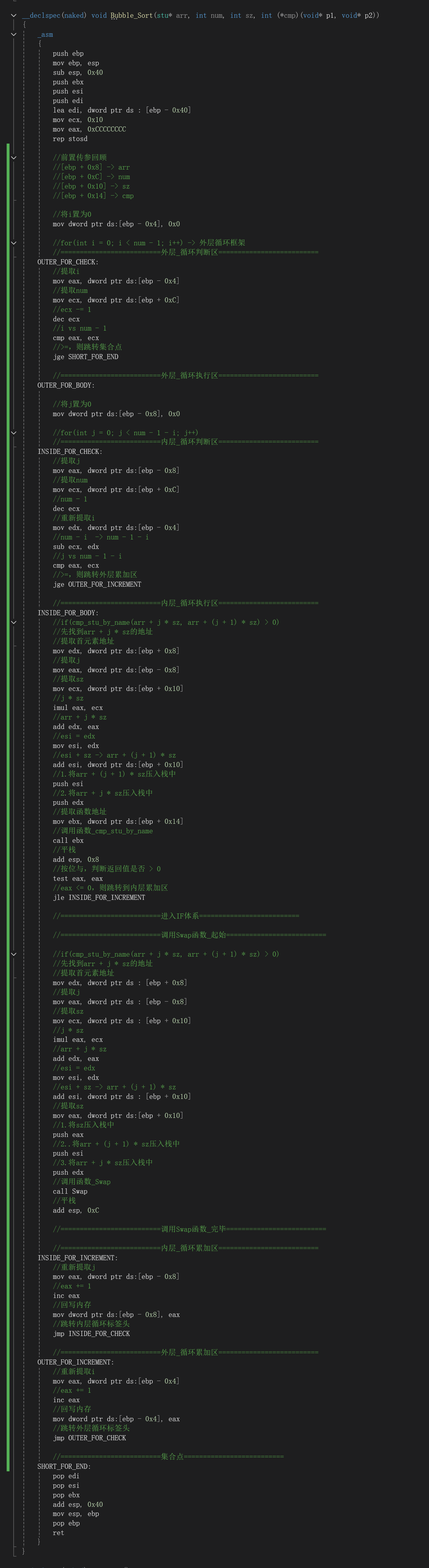
3.2.4 main
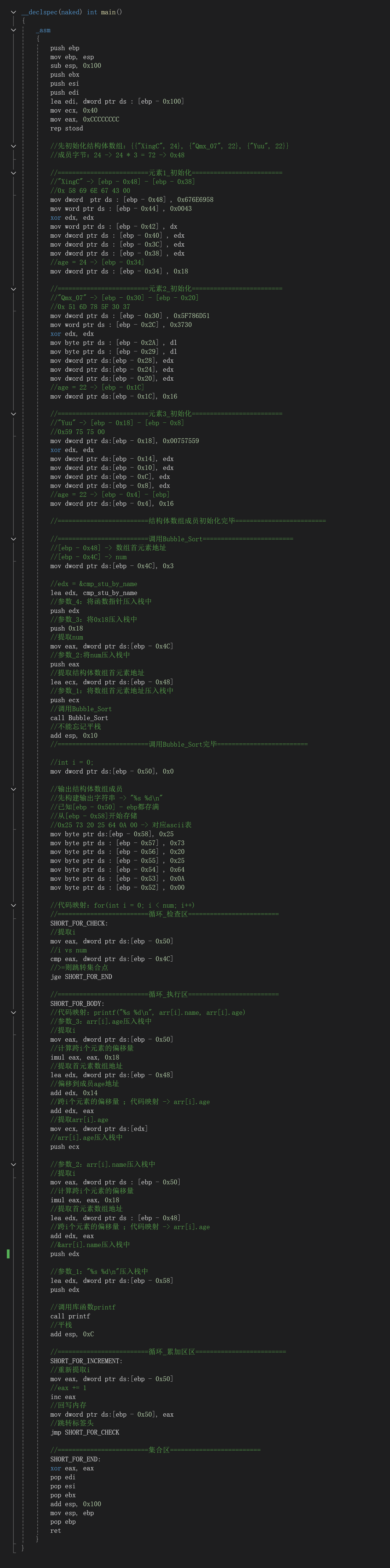
- 以上练习主要从汇编角度手写一个结构体排序算法,内心觉得只有把汇编当作母语般去学习,才能对汇编进行彻底祛魅。
本章完~