📌 Data Agent技术干货 · 共四个部分
本文为系列上篇,涵盖阶段一:语义层接入探索 与阶段二:从查数到决策。下篇将介绍阶段三(本体语义层)与阶段四(团队技术进展)。
(后台私信,可以获取完整报告!)
在大语言模型(LLM)与生成式 AI 爆发的今天,企业对于"通过自然语言交互获取数据与支撑决策"的需求愈发迫切。然而,在实际落地中,直接让 LLM 面对杂乱无章的物理表生成 SQL(即 NL2SQL)往往会面临**"同问不同答"、业务定义无知、逻辑幻觉、权限安全难控以及结果不可解释**等一系列核心矛盾。
本文系统性地梳理了我们团队在 Data Agent 领域的实化探索与演进历程。我们将这一演进归纳为三个关键阶段:从最初引入指标语义层,打造 NL→MQL→SQL 链路,实现确定性熵减(阶段一);到基于开源 OpenClaw 框架注入阶梯式 Skill 体系,让 Agent 真正进入"查数、归因、异常检测及 What-if 预测"的业务决策深水区(阶段二);再到构建高维的本体化语义层------为 Agent 提供一套机器可读、可治理、可复用的"世界模型"(阶段三)。
通过这三个阶段的渐进式演进与落地,我们提炼出了企业级 Data Agent 的终局乘法公式。希望这些来自一线的工程实践与思考,能为正在探索数据智能基建、推动企业数字化转型的同行们提供有价值的参考与启发。
阶段一:语义层接入探索
1、现阶段的矛盾
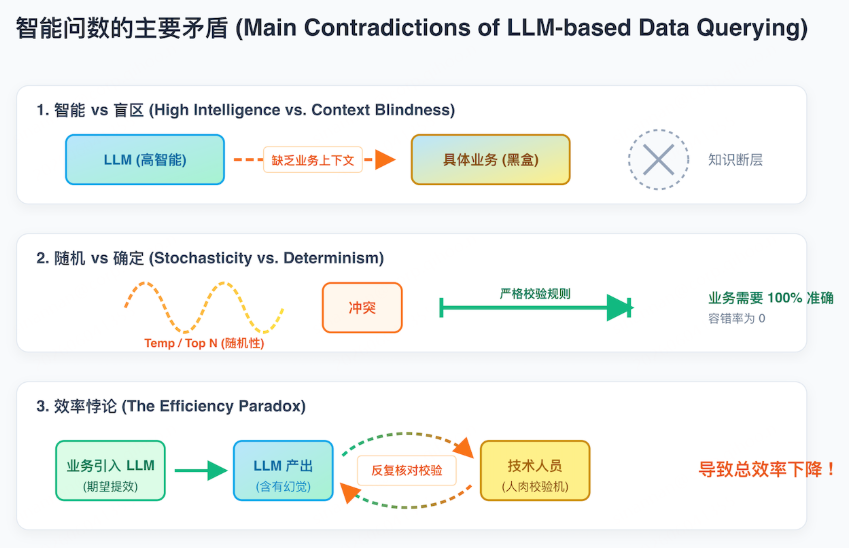
在业务使用智能问数的过程中,不同业务人员可能会提出相同的问题,例如:"这个月华北区域的销售额是多少?" 但往往出现的情况是:不同人、不同时间去问同一个问题,大模型返回的结果却不一致。于是业务同学经常会去找 IT 部门确认:大模型给到的数据到底准不准、为什么会不一样。
为什么会出现这种矛盾?我把它归纳为三类核心冲突。
第一类冲突:大家以为大模型很"聪明",但它对业务定义往往"无知"。
比如"销售额"到底怎么定义?退货/退款是否要扣除?赠品、小样算不算?零售电商场景下,优惠券、消费券的抵扣算不算销售额?这些问题本质上是业务口径问题,但大模型并不知道企业内部的统一口径。
第二类冲突:业务需要确定性,但大模型的生成具有随机性。
业务在做经营分析时要的是"确定的数字",不希望今天问一个答案、明天问另一个答案。但大模型本质上是概率模型,生成过程天然带有随机性,这会导致同问不同答。
第三类冲突:企业想提升效率,但业务在结果校验又消耗了更多时间。
企业引入大模型的初衷,是提升分析与决策效率,实现"数据民主化"。虽然自然语言交互降低了使用门槛,业务人员不需要理解底层表结构,但当数据结果不稳定时,后续会花大量时间与 IT 来回沟通、对数、验算。这样一来,效率反而被抵消。
2、引入语义层概念
基于这些问题,目前业内通用做法:要解决智能问数的核心症结,打通公司内部的数据治理平台,必须以"指标语义层"作为智能问数的基础。
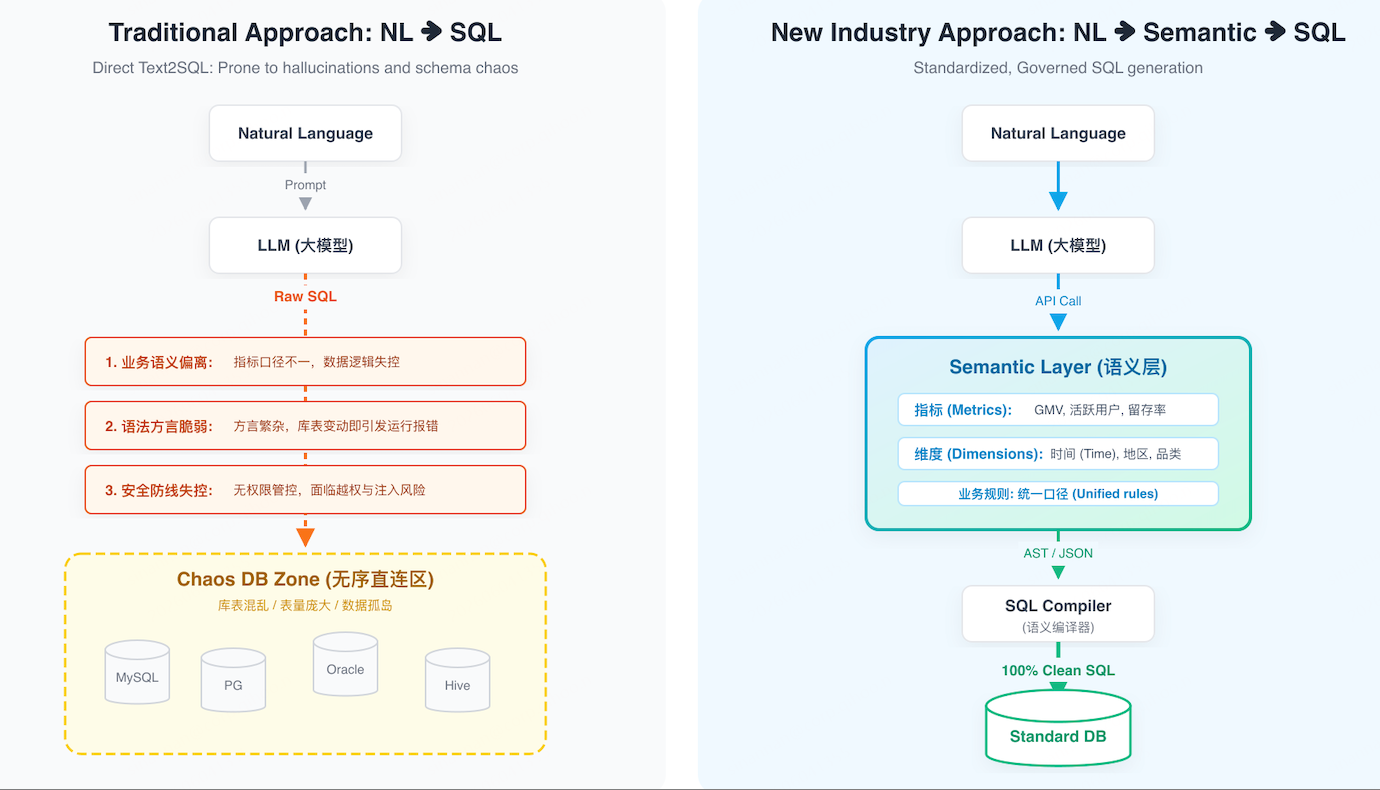
因此,结合"指标语义层"的灵活定义:让大模型先理解指标与维度,再在指标层面生成查询(而不是直接拼表写 SQL),既保证语义一致性与 SQL 准确性,又能让指标和维度像"搭积木"一样灵活拼装,同时保持查询性能与权限管控,实现准确、快速、安全、灵活的智能数据分析。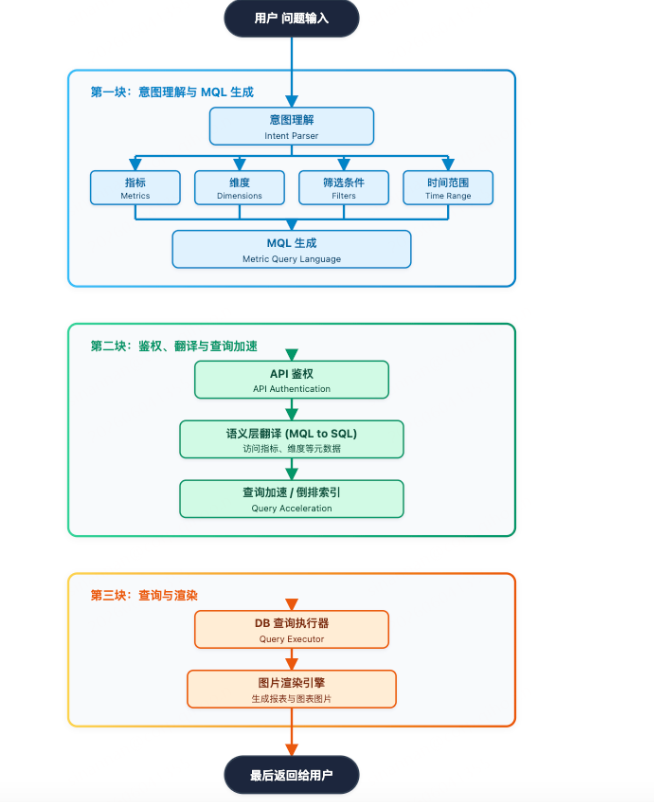
从整体架构上,我们把查询链路分成两块:大模型负责与用户交互、理解意图、解释数据结果;指标语义查询引擎负责稳定、准确、安全地做数据查询与加速。
具体流程是:用户提出问题后,大模型结合用户意图与已沉淀的指标语义知识,识别出用户想查的指标、维度与筛选条件;随后基于 MQL(指标查询语法)生成查询请求,并发送给指标语义查询引擎。引擎在执行前会做权限校验(例如用户是否有查看"华南区"数据的权限);校验通过后,将 MQL 转换为 SQL 并执行查询。由于 SQL 生成由工程化的查询引擎完成,只要 MQL 正确,SQL 就能稳定正确,不会"胡写"。查询引擎还会对复杂关联与计算做加速处理,最终把结果返回给大模型,由大模型进行数据解读并以图表等形式呈现给用户。
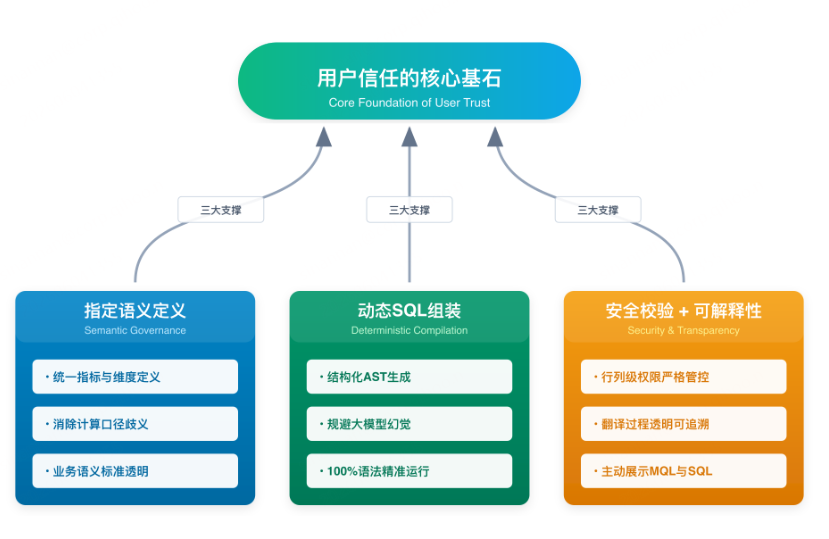
在上述的流程中,聪明的各位会发现想要实现在"百分之百准确"的背后,有一个技术"铁三角":
1)指标的逻辑化定义能力------通过语义层提前定义好指标口径与计算逻辑,确保业务含义确定。
2)SQL 的动态拼装能力------将大模型解析出的"指标/维度/条件/时间"等要素,与 SQL 片段建立工程化映射关系,通过规则与模板动态生成 SQL,并做必要优化(如:我们Archer DB全文索引语法支持等)。
3)结果可解释、可校验------传统 SQL 业务看不懂,即使展示 SQL 也难判断对不对。因此系统需要把查询过程"业务化透明":让业务看到本次查询用的指标、维度、筛选条件、时间范围,并可查看指标口径与计算逻辑,从而判断结果是否符合预期;必要时也支持交互式调整。降低业务与数仓人员的沟通成本,增加用户信任。
同时,底层还有两项基础保障:数据安全(权限)与查询实效(性能)。
可解释性主要就是将转化流程尽可能用最通俗的形式展示出来,打消用户疑虑,增加结果可信度。如下: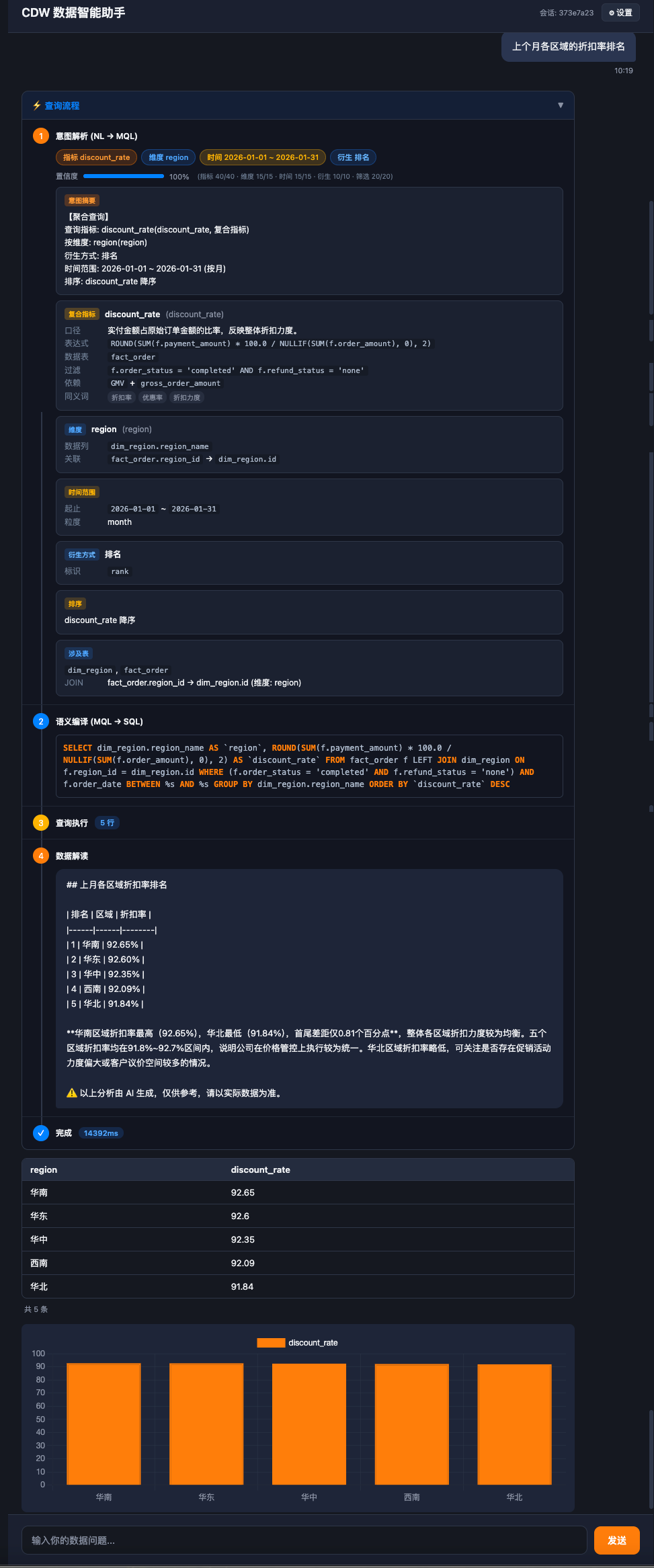
3、技术方案简介
数仓设计的data agent架构设计是:NL → 关键词提取 → ES/向量化检索 → LLM生成MQL → 规则后处理 → 校验 → 编译SQL → 执行 → 解释。多层防护(规则+LLM+验证+回环)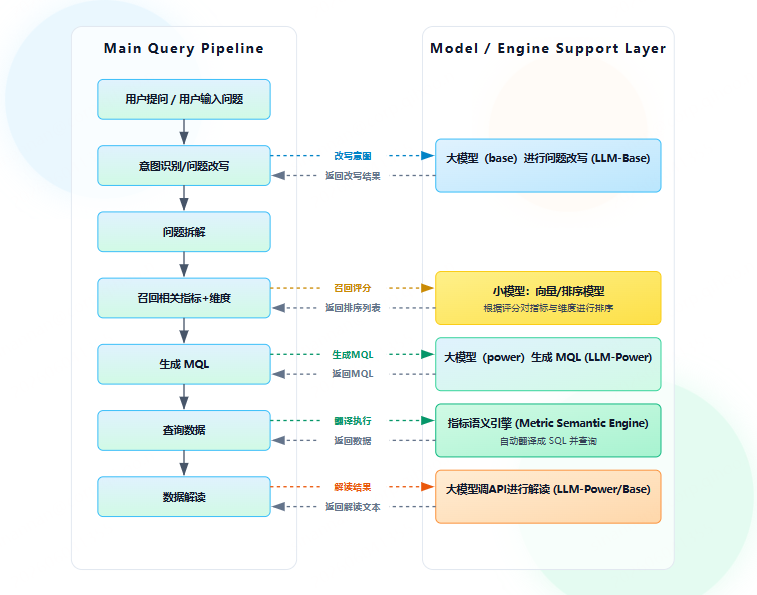
为此,我们需要在数仓智能问数中引入了 ReAct 机制(思考-行动-观察循环)。大模型会结合短期记忆(上下文、上一轮查询结果等)与长期记忆(指标语义知识库、预置业务知识与分析思路等),规划下一步行动;并调用工具完成任务,例如:查询指标/维度的元数据信息、做数据解读、发起指标查询并获得结果。每轮工具返回结果后,大模型再进行观察与新一轮思考,直到能完整回答用户的复杂问题为止。这样能把复杂问题拆解成多个原子查询,稳定输出关键结果;同时工具体系可扩展,后续缺什么能力就往工具库里补即可。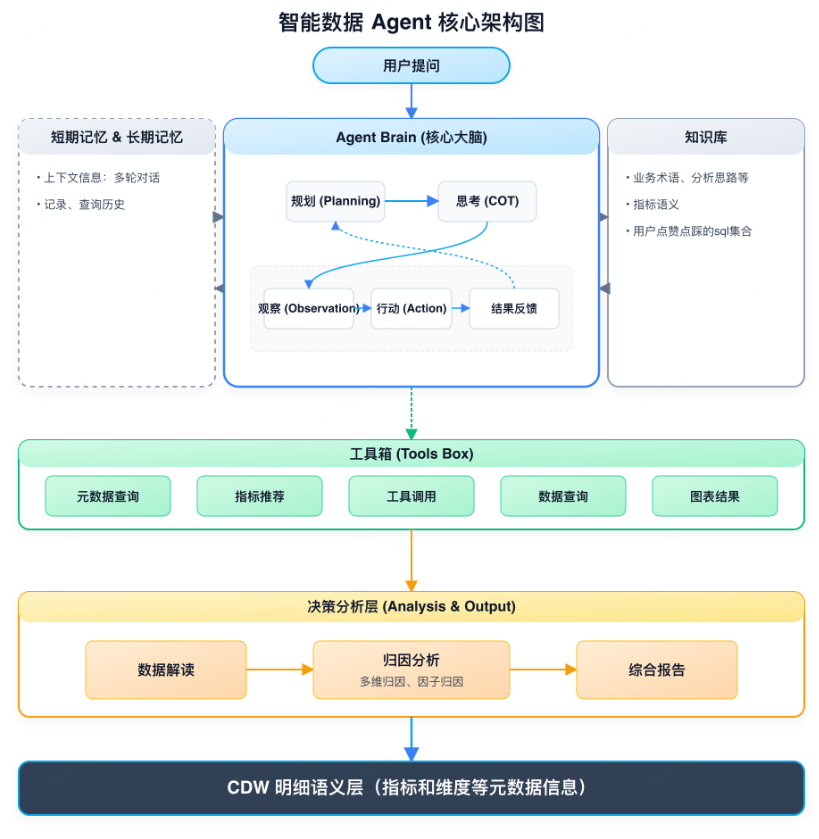
同时呢指标语义层的构建也要很重要,不过这是确定性的因素,用户只需要把奇麟湖数仓 DWD 层的数据接入指标语义层,并定义一些简单的基础指标、维度、衍生方式。数据侧就准备好了。
这里的基础指标通常是原子化的核心业务指标,比如销售额、收入,或通过少量字段做简单加减乘除得到的指标(如毛利额、利润率等)。定义好后,上层在智能问数时就可以把"指标 + 维度 + 日期 + 计算方式"像搭积木一样组合起来,形成非常灵活的查询;占比、排名等更复杂的计算也可以即时生成。
举个例子:指标语义层只定义了"销售额",并为它定义了相关维度(渠道、品牌等)。那么在问数时,用户可以围绕时间序列提问(最近 30 天每天、过去一年每个月、同比/环比增长率与增长值等),也可以问最大/最小/平均值等统计口径,或限定某渠道/某品牌进行查询,并灵活做占比、排名等分析。
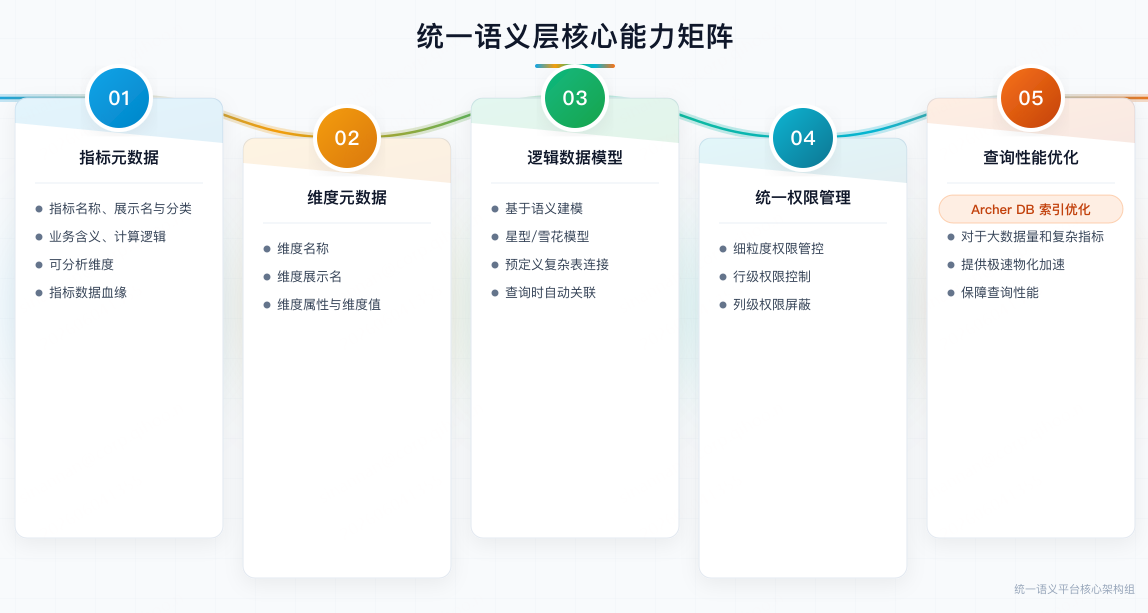
指标语义层主要包含五类核心能力:
1)指标元数据------包含指标名称、展示名、业务含义(口径)、计算逻辑、可分析维度、关联关系等。
2)维度元数据------包含维度名称、展示名、维度值等。例如"北京地区",其实是"城市"维度下的一个维度值"北京"。
3)逻辑数据模型------解决跨表查询问题:业务不关心底层来自哪张表,但系统需要提前定义清楚表与表的关联关系(包括一对一、一对多、多次关联、拉链表等复杂场景),从而支持自动 Join 与 SQL 翻译。
4)权限控制------保证数据安全:行级权限(哪些用户可以看到哪些数据范围);列级权限(哪些用户可以查询哪些维度/字段)。
5)查询性能保障------Mql 转化规则要基于查询引擎特性适配,目前引擎测试的优化基本不需要,但是需要切换不同的引擎准备和单引擎内部的语法,比如我们Archer DB 带索引和不带索引的情况。
4、查询模版内置
用户的使用场景我们参考业内敏捷BI平台可以归类出以下8点: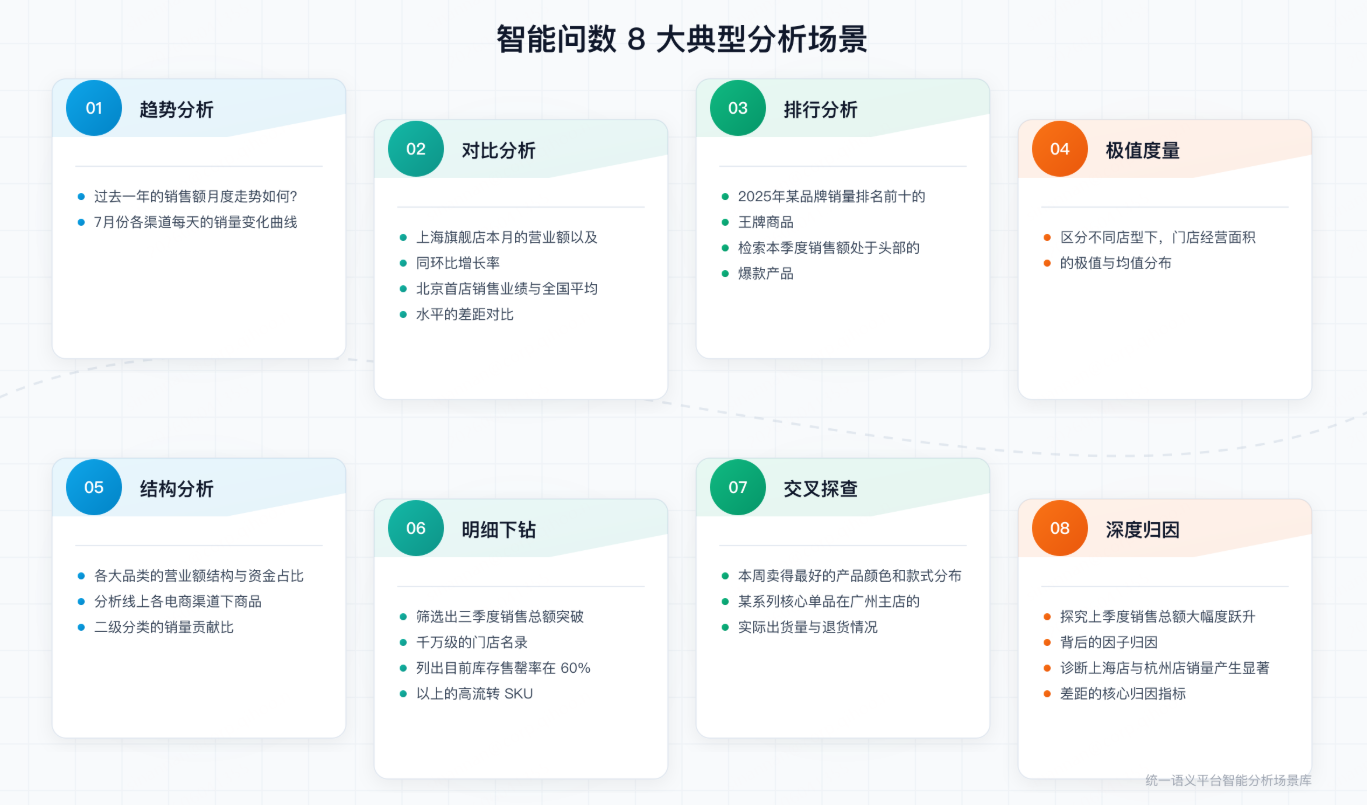
接下来我们用一些案例说明动态生成的能力。我们把智能问数问题抽象为 8 类常见场景:1)问趋势(例如近几个月销售趋势);2)做对比(门店 vs 全国平均、同比/环比);3)看排名(某年销量 Top 商品/品牌);4)看分组/分类(按门店类型、区域划分);5)看构成/分布(不同品类占比、结构变化);6)查明细(穿透到订单/小票/商品);7)探索式分析(不断调整维度和筛选条件);8)做归因(解释增长/下滑原因)。
阶段二:从查数到决策
Data Agent + Skill 如何让 AI Agent进入业务深水区
1、实验背景
在当前的企业级 AI 落地实践中,绝大多数 Agent 依然搁浅在低复杂度的"业务浅水区":撰写日常邮件、日报、或是自动填报简单表单。这些任务有一个共同的底层特征------它们完全绕开了企业最核心的资产:数据分析与决策流。
我们基于开源 Agent 运行时 OpenClaw,接入麒麟云数据仓库(CDW)语义层开展了迭代实验。我们通过为 Agent 注入阶梯式的 Skill(业务自己的技能包),成功实现了从"初级问数"到"主动诊断",再到"决策闭环"的惊艳跨越。
2、让 Agent 学会查数和归因
metric-query:问数的 Skill------把自然语言翻译成语义层的指标查询 API 请求。流程是:

关键设计:它不是凭记忆猜指标名。每次查询前都先去语义层搜索,确认指标和维度确实存在。这就是为什么它不会"幻觉"出一个不存在的指标。支持的查询能力覆盖:基础查询、同环比(年/季/月/周/日)、占比、排名、维度筛选、结果筛选、临时指标定义、时间限定、多层聚合。
metric-attribution:归因的 Skill ------一个诊断流程的编排器。当你问"为什么跌了",它按照五步诊断逻辑走:
每一步都会调用 metric-query 的查询能力取数据,然后在本地做归因计算。为什么要拆成两个 Skill?日常 80% 的场景是"查个数",metric-query 轻量、快速、一问一答。只有需要深挖原因的时候,才触发 metric-attribution 的完整诊断流程。简单问题不走复杂流程,复杂问题有专门的方法论。
3、时序基线诊断、What-if 预测与分析闭环
六个 Skill 形成三层结构: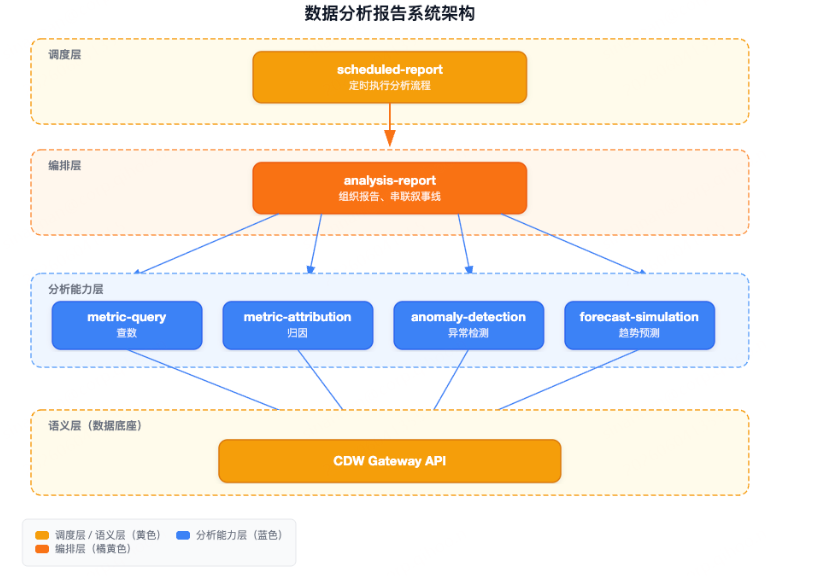
为了验证Skill 矩阵的协同效应,我们模拟了一次真实的电商商家资金链健康度诊断:
Round 1:全局异常扫描
用户输入:"帮我体检一下当前的资金水位,是否有异常?"Agent 行为:调用 anomaly-detection,自动提取"可用资金余额"、"待结算货款"和"资金周转天数"近 30 天的数据。诊断结论:全局指标在 3σ 范围内,资金周转天数维持在 12 天左右(健康区间),系统未触发全局告警。
Round 2:趋势外推
用户输入:"按照当前的消耗速度(日常运营+投流),未来 30 天资金走势如何?"Agent 行为:调度 forecast-simulation,基于日均资金消耗率外推。预测结论:未来 30 天可用资金将平稳下降至 150 万元。
Round 3:压力测试(What-if 仿真)
用户输入:"如果下个月我们启动年中大促,备货和投流支出预期暴涨 30%,资金链撑得住吗?"Agent 行为:在 forecast-simulation 中注入促销支出系数。仿真结论:若维持当前回款节奏,30 天后资金结余 95 万元,处于安全线以上;若平台回款延迟 3 天,现有资金仅能支撑 36 天,大促第 30 天结束时可用资金将降至 8.4 万元的极度濒危水位(面临断链违约风险)。Agent 主动提示:必须在大促前 15 天追加供应链金融授信或申请平台极速回款服务。
Round 4:高维下钻------戳破"全局均值"的幻觉
核心洞察:全局均值是数据分析中最致命的"致幻剂"。平均资金周转 12 天看似健康,但当 Agent 引入"资金占用渠道"维度进行矩阵分解后,真相大白:
|--------|-------------|---------|---------------------------------------------|
| 资金占用渠道 | 核心指标 (周转天数) | 风险判定 | 运营优化建议 |
| 平台待结算 | 45 天 | 🔴 重度积压 | 建议立即开通极速回款特权,或通过保理业务提前变现,释放现金流。 |
| 广告投放账户 | 8 天 | 🟡 逼近红线 | 适当放缓投流消耗节奏(建议核减 20% 低效渠道),优化 ROI,避免资金被无效占用。 |
| 供应链应付 | 15 天 | 🟢 极度健康 | 维持现状,合理利用账期杠杆。 |
| 日常运营开支 | 3 天 | 🟢 高速周转 | 保持监控,确保底仓资金安全。 |
此时,Agent 的表达完成了质变:它不再只是冰冷地报数,而是指明了风险发生的精确位置(平台待结算账期过长)并给出了业务建议(极速回款/保理/核减低效投流)。
Round 5 & 6:一键生成报告与定时任务录制
Agent 调度 analysis-report,将上述多维矩阵、What-if 仿真曲线及优化建议组装成精美的 HTML 资金健康周报,并通过 scheduled-report 自动生成了 0 10 * * 1(每周一上午 10:00)自动重跑该诊断流的任务。
4、融入行业知识图谱的控制决策闭环
前面讲到Agent 给出的建议是"电商积压,建议大促清仓"。但对于一个一线的运营经理而言,这依然不够具体。清哪些品牌?哪些 SKU?春季款和夏季款的生命周期一样吗?折扣应该怎么给?断货的爆款应该补多少件?各渠道分配优先级是什么?从"发现风险"到"生成可执行的策略指令",中间隔着一整层行业领域知识(Domain Knowledge)与业务规则约束。
如果说分析 Skill 是给企业做体检的"诊断报告",那么 inventory-strategy 就是主治医生开具的"精准处方"。它在底层无缝复用了之前的基础 Skill,但在其上封装了三层极为严苛的业务决策引擎。
决策流实战:从 1200 万待回笼资金中激活现金流
用户输入:"全盘扫描资金链,生成本周的现金流激活方案。"Agent 行为:触发 cashflow-strategy,自动调度 metric-query 提取所有渠道的回款率、资金占用比、应收账款周转天数(DSO)及待结算余额。
步骤一:全盘扫描与渠道定位------Agent 发现待回笼资金总额 1,256 万元,整体回款率仅 32%,资金占用比高达 1.8(严重偏离 0.6 的健康安全线)。其中,"B2B大客户分销"单渠道占用了全盘 65% 的资金(816.4 万元)。
步骤二:四象限投影与风控二次修正------Agent 将核心渠道投影至专家模型。值得注意的是,在计算"B2B大客户分销"时,虽然其账面毛利和单客产值指标表现优异,但由于 DSO(应收账款周转天数)已超过 120 天(严重逾期),风控引擎自动将其从"优质大客区"强行拉回"🔴 坏账预警/紧急催收区"。这种基于时效特征的动态纠偏,避免了死套利润公式带来的现金流断裂风险。
步骤三:交互式决策暂停点(Human-in-the-Loop)------设计原则:对于高资金风险的策略输出,Agent 必须设计主动确认机制,防止未经审查的指令直接流入下游通道。Agent 输出:"B2B分销渠道存在严重资金占用,坏账风险极高。我已定位到核心逾期客户,是否允许我继续拆解并生成具体的折让催收方案及停发货管控单?"用户输入:"允许,请输出具体数据。"
步骤四:输出结构化行动方案------在获得授权后,Agent 输出了极其精准的行动清单:
|---------|--------|---------|-------|-------|-----------------|---------|--------|
| 涉及客户/平台 | 业务属性 | 待结余额 | 资金占用比 | 逾期天数 | 推荐策略 | 优先级 | 预期回笼 |
| 华南大代理 | Q1 备货款 | 456 万元 | 36.3% | 122 天 | 折让 3% 极速回款/保理贴现 | P0 (极高) | 442 万元 |
| 某直播平台 | 坑位费及货款 | 285 万元 | 22.7% | 45 天 | 申请平台极速回款特权 | P0 (极高) | 285 万元 |
| 某零售小B | 日常补货 | 75.4 万元 | 6.0% | 12 天 | 正常账期(维持合作) | P3 (观望) | - |
同时,针对现金流枯竭风险明显的"直营电商渠道"(日常高频运转,但被大客拖累导致无钱投流),Agent 直接基于资金缺口算出了精准的融资指令:"直营电商渠道需紧急申请供应链金融授信 500 万元,优先投放至本月高ROI投流计划"。这套行动方案不再是虚无飘渺的分析,而是可以直接作为决策依据、甚至直接转化为催收函、保理申请单与风控拦截规则的结构化指令集。
5、终局公式:Data Agent 深水区的四个因子
基于实验的成功落地,我们提炼出了企业级 Data Agent 进入深水区并产生真实商业价值的终局乘法公式:

这是一个乘法模型。任何一个因子的缺失或羸弱,都会导致整体业务效果呈指数级塌缩。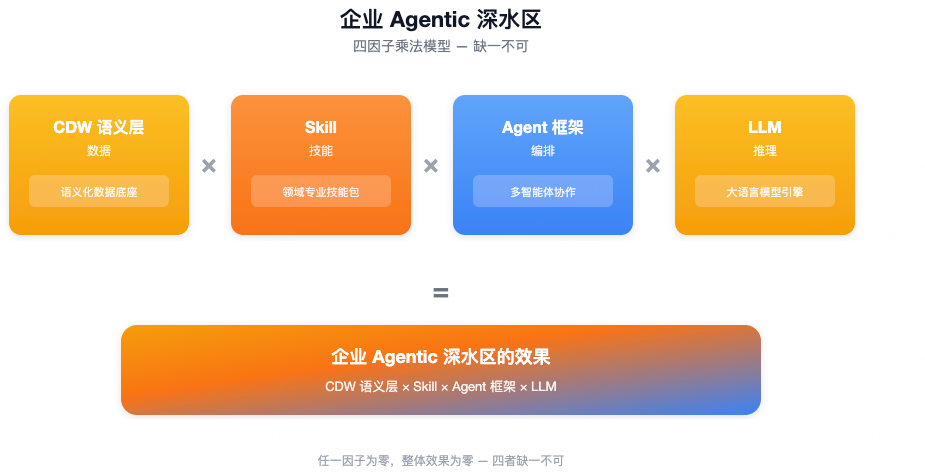
在过去,人们寄希望于 LLM 直接去理解杂乱无章的物理表结构,这被证明是一条死胡同。语义层不是 AI 的替代品,而是 AI 的前置依赖。
确定性熵减
同一自然语言问题,在语义层的约束下,无论问多少次,其执行的指标路径和输出口径永远保持绝对一致。
上下文解耦
Agent 交互时,无需向 LLM 的上下文窗口中塞入庞大的数据表 Schema 和复杂的 Join 逻辑。Agent 只需要说"我需要坪效",CDW Gateway 即可在底层透明地完成指标的高效计算。
架构屏障
当底层的物理数据表结构发生迁移(如分库分表、字段重命名)时,只需在语义层进行一次映射调整,所有上层的 Agent 和 Skill 依然完全可用,实现了极佳的软件工程解耦。
大语言模型拥有通识能力,但缺乏特定行业的"临床经验"。Skill 体系的本质,是将行业专家的分析方法论与决策树,编写为 Agent 能够理解并调度的结构化模块(以 .md 提示词元数据或 Python 脚本为载体)。一个企业的竞争壁垒,不再仅仅是拥有的数据量,而是其沉淀并软件化的 Skill 数量与深度。这些 Skill 将专家的脑力资产转化为企业组织可以无限复制、高频执行的数字化劳动力。
6、结语:迈向 Agentic Strategy 的全面自动化
Claude Code 源码揭示了一个冷酷现实:它超半数的工程量都在对上下文进行"高压脱水"------工具按需冷启动、历史对话极限压缩,大体积结果落盘仅传递文件指针。
**把 Agent 的平庸归咎于"模型不够聪明",是一种极其舒适的思维逃避。**事实上,运行时的上下文裁剪与 Skill 编排,才是真正的胜负手。
技术弹道很清晰:基座模型在野蛮迭代,框架也在迅速同质化。当这两者退化为行业常量,真正的战局将彻底收敛在**"语义层"与"Skill 体系"的深度**上。数据分析的终点从来不是制作一份"自我感动的精美报告",而是发起一次"精准见血的业务刺刀行动"。
📌 技术干货 · 下篇将介绍阶段三(本体语义层)与阶段四(团队技术进展),敬请期待!