目录
[Bean 生命周期](#Bean 生命周期)
[第二步:生成 BeanDefinition](#第二步:生成 BeanDefinition)
[第五步:Aware 回调](#第五步:Aware 回调)
[Spring 为什么能解决循环依赖?](#Spring 为什么能解决循环依赖?)
[Spring 为什么能解决?](#Spring 为什么能解决?)
[Spring AOP 底层原理](#Spring AOP 底层原理)
[@Transactional 为什么会失效?](#@Transactional 为什么会失效?)
[第三种情况抛 checked exception](#第三种情况抛 checked exception)
[@Autowired 底层原理](#@Autowired 底层原理)
[IOC 容器底层原理](#IOC 容器底层原理)
[什么是 IOC?](#什么是 IOC?)
[IOC 容器到底是什么?](#IOC 容器到底是什么?)
[Spring 启动流程](#Spring 启动流程)
[SpringBoot 启动流程](#SpringBoot 启动流程)
[第一步:创建 SpringApplication](#第一步:创建 SpringApplication)
[第三步:创建 IOC 容器](#第三步:创建 IOC 容器)
[第四步:扫描 Bean](#第四步:扫描 Bean)
[第五步:实例化 Bean](#第五步:实例化 Bean)
[第七步:Bean 初始化](#第七步:Bean 初始化)
[第九步:放入 IOC 容器](#第九步:放入 IOC 容器)
[第十步:启动 Tomcat](#第十步:启动 Tomcat)
[第十一步:接收 HTTP 请求](#第十一步:接收 HTTP 请求)
[DispatcherServlet 是什么](#DispatcherServlet 是什么)
[SpringMVC 请求完整流程](#SpringMVC 请求完整流程)
[第二步:Tomcat 接收请求](#第二步:Tomcat 接收请求)
[第三步:进入 DispatcherServlet](#第三步:进入 DispatcherServlet)
[第四步:HandlerMapping 找 Controller](#第四步:HandlerMapping 找 Controller)
[第五步:HandlerAdapter 执行方法](#第五步:HandlerAdapter 执行方法)
[第七步:调用 Controller 方法](#第七步:调用 Controller 方法)
[@RequestMapping 为什么会生效](#@RequestMapping 为什么会生效)
[SpringMVC 拦截器原理](#SpringMVC 拦截器原理)
[SpringBoot 自动装配原理](#SpringBoot 自动装配原理)
[spring,springboot,spring mvc ,spring cloud](#spring,springboot,spring mvc ,spring cloud)
[为什么需要 RPC/OpenFeign?](#为什么需要 RPC/OpenFeign?)
[Nacos 有哪些功能?Nacos 服务注册/发现是怎么实现的?](#Nacos 有哪些功能?Nacos 服务注册/发现是怎么实现的?)
[Nacos 有哪些功能?](#Nacos 有哪些功能?)
[Nacos 服务注册与发现原理](#Nacos 服务注册与发现原理)
[CAP 理论](#CAP 理论)
Bean 生命周期
1. Spring Bean 生命周期是什么?
2. Bean 是什么时候实例化的?
3. BeanPostProcessor 是什么?
4. 初始化方法有哪些?
5. Bean 销毁阶段有哪些?
1. Spring Bean 生命周期是什么?
Bean 生命周期,就是一个对象从"被 Spring 发现"到"被销毁"的完整过程
你自己 new 一个对象时:
java
UserService userService = new UserService();生命周期很简单:
java
new 出来
↓
你自己用
↓
等待 GC但 Spring 不一样。Spring 是容器,它要帮你管理对象,所以流程更复杂
第一步:扫描类
Spring 启动时,会扫描你的包。
比如:
@SpringBootApplication默认会扫描启动类所在包及其子包。
它看到:
@Service
public class UserService {}就知道:
这个类需要交给 Spring 管理。
第二步:生成 BeanDefinition
Spring 不会马上只记一个 Class,它会把这个 Bean 的"配置信息"封装成 BeanDefinition。
你可以把 BeanDefinition 理解成:
Bean 的说明书
里面会记录:
class 是什么
beanName 是什么
是否单例
是否懒加载
依赖哪些属性
初始化方法是什么
销毁方法是什么比如:
beanName = userService
beanClass = UserService.class
scope = singleton
lazy = false第三步:实例化
实例化就是创建对象。
类似:
UserService userService = new UserService();此时对象只是被 new 出来了,但里面的依赖还没有注入。
也就是说:
private OrderService orderService;这个时候可能还是 null
第四步:属性注入
Spring 看到:
@Autowired
private OrderService orderService;它会从容器里找 OrderService,然后通过反射塞进去。
类似:
userService.orderService = orderServiceBean;第五步:Aware 回调
如果 Bean 实现了一些 Aware 接口,Spring 会把容器相关的信息告诉它。
比如:
@Component
public class UserService implements ApplicationContextAware {
private ApplicationContext applicationContext;
@Override
public void setApplicationContext(ApplicationContext applicationContext) {
this.applicationContext = applicationContext;
}
}这表示:
这个 Bean 想知道自己所在的 Spring 容器是谁。
Spring 就会把 ApplicationContext 传给它。
第六步:初始化前置处理
这里会执行 BeanPostProcessor 的前置方法。
你可以理解成:
Spring 给所有 Bean 初始化前提供了一个统一拦截点。
比如某些框架可以在这里检查注解、补充属性。
例如:你有个 Bean:
@Service
public class UserService {
@PostConstruct
public void init() {
System.out.println("UserService init");
}
}再写一个:
java
@Component
public class MyBeanPostProcessor implements BeanPostProcessor {
@Override
public Object postProcessBeforeInitialization(Object bean, String beanName) {
System.out.println("初始化前:" + beanName);
return bean;
}
}启动时:
初始化前:userService
UserService init说明:
Spring 在执行 init 前调用了你的 Processor。
第七步:初始化方法
这一步执行你自己定义的初始化逻辑。
比如:
@PostConstruct
public void init() {
System.out.println("初始化连接");
}此时依赖已经注入完成,所以你可以安全使用其他 Bean。
第八步:初始化后置处理
这里会执行 BeanPostProcessor 的后置方法。
java
@Component
public class MyProcessor implements BeanPostProcessor {
@Override
public Object postProcessBeforeInitialization(
Object bean,
String beanName
) {
System.out.println("前置处理:" + beanName);
return bean;
}
@Override
public Object postProcessAfterInitialization(
Object bean,
String beanName
) {
System.out.println("后置处理:" + beanName);
return bean;
}
}第九步:放入容器使用
最后 Spring 把处理好的对象放进单例池。
以后你注入:
@Autowired
private UserService userService;拿到的就是这个 Spring 管理好的 Bean。
第十步:销毁
容器关闭时,Spring 会调用销毁方法。
比如:
@PreDestroy
public void destroy() {
System.out.println("关闭资源");
}Spring 为什么能解决循环依赖?
什么是循环依赖
例如:
@Service
public class AService {
@Autowired
private BService bService;
}
@Service
public class BService {
@Autowired
private AService aService;
}关系:
A 依赖 B
B 又依赖 ASpring 为什么能解决?
Spring 允许"提前暴露半成品对象"。
什么叫"半成品对象"?
例如:
AService a = new AService();此时:
对象已经 new 出来了但:
属性还没注入
初始化还没完成
AOP 还没做Spring 会:
1. 先实例化 A
AService a = new AService();2. 不等它完全初始化
先:"提前暴露"出去
3. 然后 A 注入 B
4. 创建 B 时
虽然 A 还没初始化完成,但Spring 已经提前暴露了 A,所以B可以拿到A
5. B 创建完成
然后完成A注入B
但为什么构造器循环依赖不行?
因为根本没有"半成品 A"
核心原理:三级缓存
一级缓存
singletonObjects这是完整 Bean 池。
二级缓存
earlySingletonObjects放提前暴露的半成品 Bean
也就是:
已经实例化
但没初始化完成三级缓存
放的不是 Bean,而是ObjectFactory。
为什么需要三级缓存?
因为AOP/日志这种后置处理,会产生代理对象
B中注入的A就不是最终的A了
Spring 不直接提前暴露 Bean。
而是提前暴露"生成 Bean 的工厂"。
java
ObjectFactory factory = () -> getEarlyBeanReference(bean);这样:如果后面需要 AOP,可以提前生成代理对象。
注意:
java
ObjectFactory factory = () -> getEarlyBeanReference(bean);可能会提取创建代理对象,所以我们存入二级缓存的就是最终的A/代理
总结一下
Spring 解决循环依赖时,会先实例化 A 对象,但此时 A 还只是半成品,属性注入、初始化、AOP 都还没完成。Spring 会先把一个能够返回 A 的 ObjectFactory 提前放入三级缓存
singletonFactories中。随后 A 在属性注入阶段依赖 B,于是开始创建 B。创建 B 时又发现依赖 A,这时候 Spring 不会重新创建 A,而是从三级缓存中拿到对应的 ObjectFactory,通过它获取提前暴露的 A 对象或者 A 的代理对象,然后将这个提前暴露的对象放入二级缓存earlySingletonObjects,同时删除三级缓存中的工厂。这样 B 就能成功注入 A,从而打破循环依赖。之后 B 完成初始化,再回过头继续完成 A 的属性注入、初始化和 AOP 代理,最后 A 和 B 都会进入一级缓存singletonObjects,成为真正完整可用的 Bean。
Spring AOP 底层原理
AOP 本质是什么?
动态代理
原本:
OrderServiceSpring给你生成:
OrderServiceProxy面试回答:
AOP是什么?
"AOP 可以理解为 Spring 提供的一种动态增强机制,它的核心目标是在不修改业务代码的情况下,给方法统一添加公共逻辑,比如事务、日志、权限校验、监控、缓存等。
AOP的底层原理是什么
"AOP 的底层核心其实就是动态代理。
Spring 在 Bean 生命周期的后置处理阶段,会通过 BeanPostProcessor 判断当前 Bean 是否需要增强,比如有没有 @Transactional、切面类等。
如果发现需要增强,Spring 就不会直接返回原始 Bean,而是会基于动态代理生成一个代理对象,最后放入 Spring 容器。
后续业务调用的其实是代理对象,而不是原对象。
Spring AOP 主要有两种代理方式:
- JDK 动态代理
如果 Bean 实现了接口,Spring 会基于java.lang.reflect.Proxy生成接口代理对象。 - CGLIB 动态代理
如果 Bean 没有实现接口,Spring 会使用 CGLIB 生成当前类的子类,通过重写方法实现增强。
而真正调用目标方法时,本质还是通过反射完成的。
比如 JDK 动态代理底层会进入:
InvocationHandler.invoke()然后通过:
method.invoke(target,args)反射调用目标方法。
java
业务代码调用方法
↓
实际调用的是代理对象的方法
↓
代理对象拦截请求
↓
进入 InvocationHandler.invoke()
↓
执行前置增强,比如开启事务/打印日志
↓
通过 method.invoke(target, args) 调用原始目标对象方法
↓
执行后置增强,比如提交事务/统计耗时
↓
如果异常,执行异常增强,比如回滚事务
↓
返回结果@Transactional 为什么会失效?
第一种情况:本质上还是AOP方面的问题
1.内部调用
java
@Service
public class OrderService {
public void test() {
createOrder();
}
@Transactional
public void createOrder() {
}
}本质上是调用内部的方法,没有走代理对象,所以就不会实现日志功能了,日志失效
2.方法不是public
默认情况下,spring只会代理public方法
第二种情况是异常被吃掉
java
@Transactional
public void test(){
try{
int i = 1/0;
}catch(Exception e){
}
}Spring 事务默认遇到异常才回滚
第三种情况抛 checked exception
默认Spring只回滚 RuntimeException
Spring事务底层原理
"Spring 事务底层本质上是:
AOP + 动态代理 + ThreadLocal + 数据库事务。
Spring 在 Bean 初始化后,会为带有 @Transactional 的 Bean 生成代理对象。
业务调用方法时,实际上先进入代理对象。
代理对象会:
- 开启事务
- 获取数据库连接
- 把连接绑定到 ThreadLocal
- 执行业务方法
- 成功则 commit
- 异常则 rollback
所以 Spring 事务本质上是通过 AOP 在方法前后织入事务逻辑实现的。"
Spring 并没有发明事务。Spring 做的是:自动帮你管理事务。
你原来得这样写:
Connection conn = dataSource.getConnection();
try {
conn.setAutoCommit(false);
// 执行业务
conn.commit();
} catch (Exception e){
conn.rollback();
}ThreadLocal保证是用的同一个数据库链接
注解是什么,有什么用,底层原理是什么
什么是注解
本质上:注解就是"给程序打标签"。
注解本身没有能力,注解本质只是元数据
类似:
给类、方法、字段附加说明信息为什么加注解就能生效?
因为框架会读取这些标签。
例如 Spring会:
扫描类
↓
读取注解
↓
根据注解执行逻辑例如:
if(method.isAnnotationPresent(
Transactional.class
)){
// 做事务增强
}注解有什么用?
核心:用声明方式代替配置
以前:
XML:
<bean id="userService"/>现在:
@Service
public class UserService {}注解底层原理是什么?
注解本质:Java 类的元数据
编译后会保存到 class 文件
例如:
@Service
public class UserService{}编译后:class 文件里面会额外保存:
@Service这个信息
那运行时怎么拿到?
依靠反射
例如:
Class<?> clazz = UserService.class;
boolean exists =
clazz.isAnnotationPresent(Service.class);或者:
Service service =
clazz.getAnnotation(Service.class);这里:
JVM 会读取 class 文件中的注解元数据
然后生成Annotation对象
真正流程:
注解写到代码
↓
编译进class文件
↓
运行时反射读取
↓
框架解析注解
↓
执行逻辑为什么有些注解运行时读不到?
@Retention
java
@Retention(RetentionPolicy.RUNTIME)它决定:
注解保留到什么时候
SOURCE
只存在源码
CLASS
存在 class 文件,运行时拿不到
RUNTIME(最重要)
运行时还能通过反射读取
@Autowired 底层原理
Spring在 Bean 创建过程中:
java
发现 @Autowired
↓
去 IOC 容器找 Bean
↓
通过反射赋值所以:
@Autowired 本质:Spring 自动完成:
field.set(bean, dependency)运行时强行给对象字段塞值
IOC 容器底层原理
面试回答:
IOC 容器本质上是 Spring 用来管理 Bean 的一个大型对象工厂。
Spring 启动时会扫描 Bean,生成 BeanDefinition,然后把 Bean 创建并保存到 IOC 容器中。
IOC 容器内部本质上可以理解为:
Map<String,Object>key 是 beanName,value 是 Bean对象
什么是 IOC?
Inversion Of Control 即控制反转
本质:对象创建权交给 Spring
IOC 容器到底是什么?
本质就是 Bean 管理中心
Spring 启动流程
Spring 启动流程本质上就是:
Spring 创建 IOC 容器并初始化所有 Bean 的过程
SpringBoot 启动流程
自动装配 + 内嵌TomcatSpringBoot 启动入口
@SpringBootApplication
public class Application {
public static void main(String[] args) {
SpringApplication.run(
Application.class,
args
);
}
}真正启动:
SpringApplication.run()启动流程
第一步:创建 SpringApplication
- 保存主启动类(后续需要扫码包)
2.推断应用类型(判断是web项目还是普通java程序)
java
DispatcherServlet
Tomcat
WebFlux**3.**推断 ApplicationContext 类型(不同项目Spring 容器不同)
4.加载启动监听器(监听 Spring 生命周期)
第二步:读取配置环境
java
application.yml
application.properties
环境变量第三步:创建 IOC 容器
本质就是ApplicationContext
第四步:扫描 Bean
扫描:
@Component
@Service
@Repository
@Controller第五步:实例化 Bean
第六步:依赖注入
第七步:Bean 初始化
第八步:AOP/事务代理
第九步:放入 IOC 容器
第十步:启动 Tomcat
SpringBoot会:自动创建内嵌Tomcat
第十一步:接收 HTTP 请求
DispatcherServlet 是什么
本质上是:SpringMVC 的请求总调度中心
所有 HTTP 请求都会先进入DispatcherServlet
然后,它再负责**找哪个 Controller,****找哪个方法,****参数怎么传,**返回值怎么处理,最终响应浏览器
没有 SpringMVC 之前
原生 Servlet:
@WebServlet("/user")
public class UserServlet extends HttpServlet {
}如果有100个接口,那你就得有100个servlet
而且:
- URL匹配自己写
- 参数解析自己写
- JSON转换自己写
- 异常处理自己写
SpringMVC 怎么解决?
前端控制器模式
java
所有请求
↓
先进入一个统一入口
↓
再统一调度统一入口就是:DispatcherServlet
真正请求流程
浏览器请求
↓
Tomcat接收
↓
DispatcherServlet
↓
Controller
↓
返回结果
↓
响应浏览器
它真正核心的方法:doDispatch()
doDispatch() 做了什么?
java
1. 找 Handler(Controller方法)
↓
2. 找 HandlerAdapter
↓
3. 参数绑定
↓
4. 执行 Controller
↓
5. 获取返回值
↓
6. JSON转换/视图解析
↓
7. 响应浏览器HandlerMapping
URL 找 ControllerHandlerAdapter
执行 Controller 方法HttpMessageConverter
JSON 转换ViewResolver
页面解析SpringMVC 请求完整流程
第一步:浏览器发送请求
GET /user/list第二步:Tomcat 接收请求
Tomcat本质是:Web服务器
它负责:
- 监听8080端口
- 建立Socket连接
- 解析HTTP协议
第三步:进入 DispatcherServlet
第四步:HandlerMapping 找 Controller
第五步:HandlerAdapter 执行方法
第六步:参数绑定
java
@PostMapping("/user")
public User add(
@RequestBody UserDTO dto,
Integer age
)第七步:调用 Controller 方法
第八步:处理返回值
情况1:
返回页面
return "login";进入:
ViewResolver
解析:
/templates/login.html情况2:
返回 JSON
@RestController
public User test(){}进入:
HttpMessageConverter
第九步:响应浏览器
@RequestMapping 为什么会生效
@RequestMapping 能生效:
本质上是:
SpringMVC 启动时扫描 Controller 上的 @RequestMapping 注解
然后建立:
URL -> Controller方法映射关系
请求来了之后:
DispatcherServlet 再根据 URL 找到对应方法执行。
参数绑定原理
Spring 根据请求内容,通过反射自动给 Controller 方法参数赋值
例如:
@GetMapping("/user")
public String test(
String name,
Integer age
){}用户请求:
/user?name=张三&age=18Spring:
会自动:
name -> "张三"
age -> 18SpringMVC 参数绑定发生在 HandlerAdapter 执行 Controller 方法之前。DispatcherServlet 找到目标方法后,会交给 HandlerAdapter 处理。HandlerAdapter 会遍历方法参数,然后使用不同的 HandlerMethodArgumentResolver 解析参数,比如 @RequestParam、@PathVariable、@RequestBody 都有对应的参数解析器。对于普通请求参数,Spring 会从 HttpServletRequest 中取值,再通过 WebDataBinder 和类型转换器把字符串转换成目标 Java 类型,最后通过反射调用 Controller 方法。
SpringMVC 拦截器原理
"SpringMVC 拦截器本质上是 SpringMVC 提供的一种请求统一扩展机制,主要用于在 Controller 执行前后插入公共逻辑,比如登录校验、JWT 鉴权、TraceId、日志打印、权限控制等
SpringMVC 拦截器本质:
DispatcherServlet 在执行 Controller 前后提供的统一扩展机制
底层核心接口是HandlerInterceptor,主要有三个方法:
preHandle()
postHandle()
afterCompletion()底层原理是 DispatcherServlet 在执行 Controller 前,会先执行拦截器链。如果某个 preHandle 返回 false,请求会被直接拦截,不再继续执行 Controller。
另外拦截器和 Filter 的区别是:
- Filter 属于 Servlet 规范,更底层
- Interceptor 属于 SpringMVC,可以拿到 Controller 方法信息,更适合做业务层拦截
java
HTTP请求
↓
Tomcat
↓
Filter
↓
DispatcherServlet
↓
Interceptor
↓
Controller
↓
AOP
↓
Service
↓
DAO"Filter、Interceptor、AOP 本质上都是一种扩展或拦截机制,但它们工作的层级不同。
Filter 属于 Servlet 规范,工作在 Tomcat 和 DispatcherServlet 之间,适合做请求过滤。
Interceptor 属于 SpringMVC,工作在 DispatcherServlet 内部,可以拿到 Controller 方法信息,适合做登录校验、JWT、TraceId、权限控制等。
AOP 属于 Spring Bean 方法层,本质是动态代理,适合做事务、日志、方法增强等。
真正执行顺序一般是:
请求先经过 Filter,再进入 DispatcherServlet,然后执行 Interceptor,最后 Controller 调用 Service 时进入 AOP
SpringBoot 自动装配原理
SpringBoot 自动装配本质就是:
SpringBoot 启动时自动帮你创建并注册大量 Bean
你只引入依赖:
spring-boot-starter-web结果自动:
Tomcat
DispatcherServlet
Jackson
SpringMVC
JSON转换器
自动装配真正入口
java
@SpringBootApplication@SpringBootApplication 本质是什么?
本质是3个直接的组合
核心注解@EnableAutoConfiguration
EnableAutoConfiguration 干了什么?
开启自动装配
它怎么知道该装配什么?
真正核心:
SPI + 自动配置类
SpringBoot启动时会:
去 classpath 找配置文件
以前是:
META-INF/spring.factoriesSpringBoot3变成:
META-INF/spring/org.springframework.boot.autoconfigure.AutoConfiguration.imports里面写着:
xxxAutoConfiguration例如:
DispatcherServletAutoConfiguration
JacksonAutoConfiguration
DataSourceAutoConfiguration这些 AutoConfiguration 是什么?
本质就是配置类。
例如:
@Configuration
public class JacksonAutoConfiguration {
}里面会:
@Bean
public ObjectMapper objectMapper(){
}于是Spring自动注册 Bean
真正自动装配流程
java
SpringBoot启动
↓
@EnableAutoConfiguration
↓
读取 AutoConfiguration.imports
↓
找到大量 AutoConfiguration
↓
加载配置类
↓
@Bean 注册 Bean
↓
放入 IOC 容器为什么引 starter 就生效?
例如引入依赖:
spring-boot-starter-web里面依赖:
-
spring-webmvc
-
tomcat
-
jackson
于是SpringBoot发现classpath存在:
-
DispatcherServlet
-
Tomcat
-
ObjectMapper
于是对应AutoConfiguration生效
总结面试话语
"SpringBoot 自动装配本质上是 SpringBoot 在启动时自动帮我们向 IOC 容器注册 Bean。
核心入口是:
@EnableAutoConfiguration启动时,SpringBoot 会通过 AutoConfigurationImportSelector 读取自动配置类名单。
SpringBoot2 以前主要读取:
META-INF/spring.factoriesSpringBoot3 之后主要读取:
META-INF/spring/org.springframework.boot.autoconfigure.AutoConfiguration.imports这个文件里其实提前写好了大量自动配置类,比如:
WebMvcAutoConfiguration
JacksonAutoConfiguration
DataSourceAutoConfiguration
RedisAutoConfiguration这些自动配置类本质上都是:
@Configuration配置类,里面会通过:
@Bean向 IOC 容器注册 Bean。
但是 SpringBoot 并不会让所有自动配置类全部生效,而是会结合:
@ConditionalOnClass
@ConditionalOnMissingBean等条件注解做条件装配。
比如:
@ConditionalOnClass(DispatcherServlet.class)意思是:
只有 classpath 中存在 DispatcherServlet 时,当前 MVC 自动配置类才会生效。
我们只需要引入:
spring-boot-starter-webclasspath 中出现对应jar包中的class
流程总览
java
引入 starter
↓
classpath 中出现对应类
↓
SpringBoot 读取自动配置类名单
↓
尝试加载 AutoConfiguration
↓
Conditional 条件判断
↓
条件成立
↓
@Bean 注册 Bean
↓
放入 IOC 容器spring-boot-starter-web 本质上不是直接往 classpath 写内容,而是通过 Maven 引入 spring-webmvc、tomcat、jackson 等 jar 包。
这些 jar 中的 class 会进入 JVM 的 classpath。
SpringBoot 启动时会通过 @ConditionalOnClass 判断 classpath 中是否存在 DispatcherServlet、Tomcat、ObjectMapper 等类。
如果存在,就让对应的 AutoConfiguration 生效,然后通过 @Bean 自动向 IOC 容器注册相关 Bean。
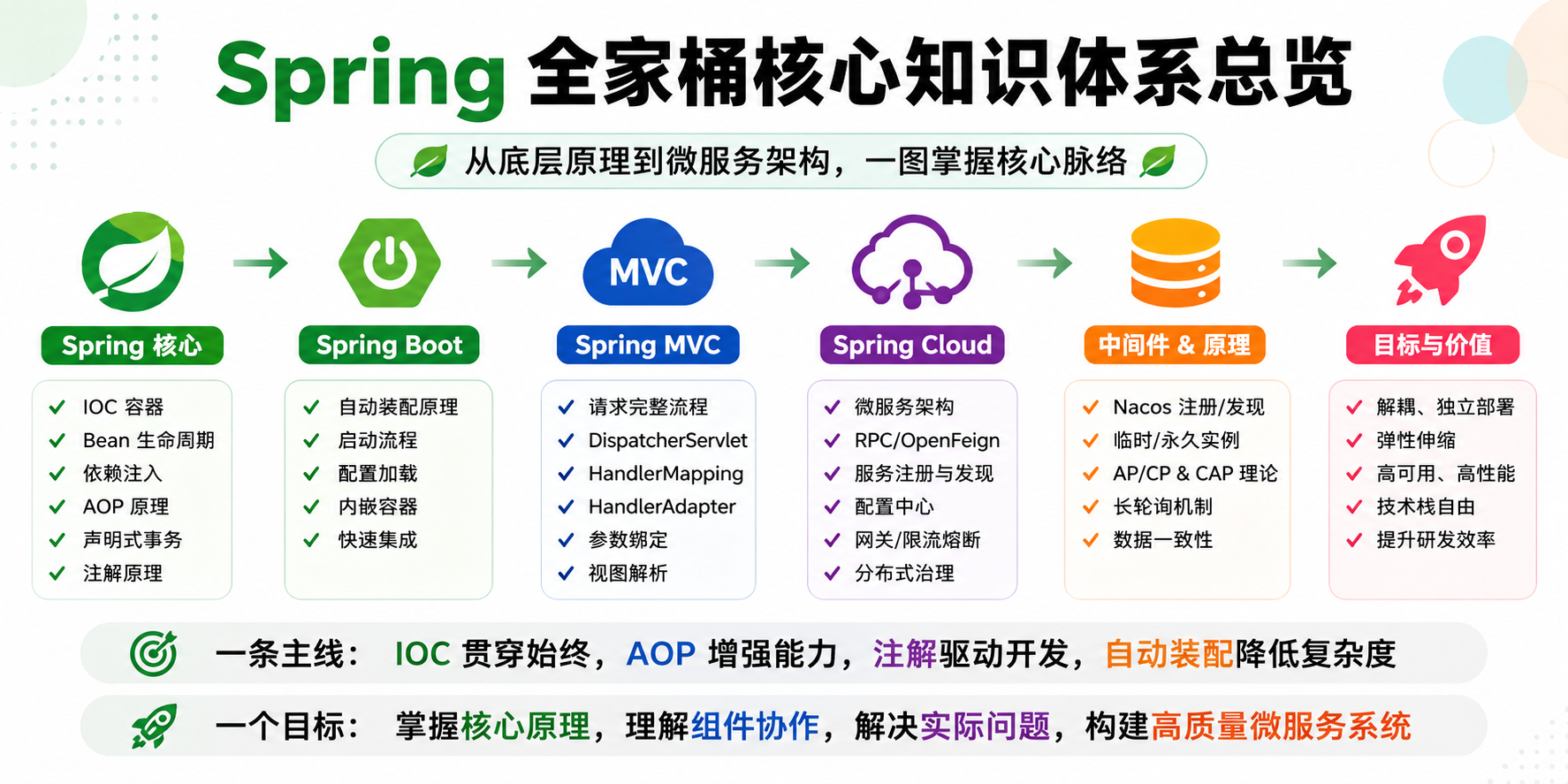
spring,springboot,spring mvc ,spring cloud
"Spring 是 Java 企业开发的基础框架,核心是 IOC 和 AOP,主要负责 Bean 管理、依赖注入、事务、AOP 等能力。
SpringMVC 是 Spring 的 Web 模块,负责处理 HTTP 请求,核心包括 DispatcherServlet、HandlerMapping、参数绑定、JSON 转换等。
SpringBoot 是 Spring 的快速开发框架,核心是自动装配,通过 starter 和 AutoConfiguration 帮助开发者快速完成 Spring 应用搭建,减少 XML 和复杂配置。
SpringCloud 则是在 SpringBoot 基础上的微服务解决方案,提供注册中心、配置中心、网关、服务调用、限流熔断等分布式能力。
所以它们之间其实是层层递进关系:
Spring 提供基础能力,SpringMVC 提供 Web 能力,SpringBoot 提供自动化配置,而 SpringCloud 负责微服务治理。"
为什么需要微服务?单体架构有什么问题?
单体架构
mall-system
├── user
├── order
├── product
├── pay
最终打包:
一个 jar部署:
一个服务- 开发简单
- 部署简单
- 调试简单
- 不需要网络通信
问题:
- 项目越来越臃肿
- 模块耦合严重
- 无法按模块独立扩容
- 一个模块崩,可能拖垮整个系统
- 技术栈无法独立升级
什么是微服务?
按业务拆分服务。
例如:
-
用户服务
-
订单服务
-
商品服务
-
支付服务
每个都是:
-
独立工程
-
独立部署
-
独立数据库
-
独立扩容
真正变化是什么?
以前:
userService.getUser()现在变成:
网络调用。
例如:
http://user-service/user/1或者RPC。
为什么需要 RPC/OpenFeign?
"单体架构里,服务之间是在同一个 JVM 内,调用本质是:
userService.getUser()属于本地方法调用,不需要网络通信。
但微服务拆分后,比如:
order-service
user-service
pay-service已经是不同进程、不同机器,甚至不同服务器。
这时候订单服务想调用用户服务,就不能再直接:
userService.getUser()因为已经没有这个本地对象了。
所以必须通过网络通信,比如 HTTP、TCP。
但如果开发者每次都自己写:
HttpClient
RestTemplate
OkHttp会非常麻烦。
于是 RPC 出现了。
RPC 的核心目标,就是:
像调用本地方法一样调用远程服务OpenFeign 本质上就是 SpringCloud 提供的 RPC 调用组件。
它底层其实还是 HTTP 请求,但通过动态代理,把远程调用封装成了接口方法调用。
例如:
@FeignClient("user-service")
public interface UserFeignClient {
@GetMapping("/user/{id}")
User getUser(@PathVariable Long id);
}业务里直接:
userFeignClient.getUser(1);看起来像本地方法调用。
但底层实际上会:
动态代理
↓
拼接URL
↓
发送HTTP请求
↓
JSON序列化/反序列化
↓
返回结果所以 OpenFeign 本质上是通过动态代理,把 HTTP 远程调用伪装成了本地方法调用。"
Nacos 有哪些功能?Nacos 服务注册/发现是怎么实现的?
Nacos 有哪些功能?
核心主要有两个功能:
1.服务注册与发现
微服务启动后会把自己的 IP、端口、服务名注册到 Nacos,消费者通过服务名从 Nacos 获取实例列表,实现动态服务发现。
2.配置中心
Nacos 可以统一管理微服务配置,比如数据库、Redis、MQ 配置等,支持配置动态刷新,避免频繁修改本地 yml 和重启服务。
除此之外,Nacos 还提供心跳检测 、健康检查、命名空间等能力。"
Nacos 服务注册与发现原理
"Nacos 服务注册与发现本质上是维护了一份:
服务名 -> 实例地址列表的映射关系。
服务启动时,会通过 SpringCloud Alibaba 自动装配触发注册逻辑,向 Nacos 服务端发送注册请求,内容包括服务名、IP、端口、权重等信息。
Nacos 服务端收到后,会把这些实例信息保存起来。
服务注册成功后,还会通过心跳机制定时向 Nacos 发送健康状态,默认 5 秒一次。如果长时间没有心跳,Nacos 会认为实例下线并剔除。
消费者调用服务时,比如 OpenFeign,会先根据服务名去 Nacos 拉取实例列表,然后通过 LoadBalancer 选择一个实例,最后发起 HTTP 请求
所以 Nacos 本质上是通过服务注册、服务发现和心跳机制,实现微服务环境下的动态服务治理。"
临时实例和永久实例
什么是实例?
例如:
user-service
↓
10.0.0.1:8080这个:
10.0.0.1:8080就叫一个服务实例
什么是临时实例?
默认Nacos注册的都是临时实例
特点:
需要心跳
心跳断开自动删除
例如服务每 5 秒告诉 Nacos:
我还活着如果长时间没跳:Nacos直接:删除实例。
永久实例是什么?
永久实例:不依赖心跳。
即使:服务挂了。
Nacos也不会自动删除。
需要:人工下线。
为什么需要永久实例?
适合:
- 数据库
- Redis
- MQ
这些不希望自动剔除
AP/CP
CAP 理论
- C:一致性
- A:可用性
- P:分区容错。
为什么 P 必须选?
因为分布式一定可能网络分区
AP 是什么?
优先可用性:数据短时间不一致,也先返回结果。
CP 是什么?
优先一致性
Nacos 配置中心是 CP,Nacos 服务注册,发现默认 AP