日常 Oracle 开发运维中,人员姓名、地址等字段时常碰到生僻汉字乱码、存储异常问题,比如䢺、䶮、㛃这类小众汉字入库变成问号 / 乱码字符。本文结合实操落地经验,分享生僻字存储改造方案,同时梳理字段从 VARCHAR2 改为 NVARCHAR2 后衍生的各类报错与修复办法。
一、生僻字乱码根源排查
1. 核查数据库字符集
ZHS16GBK 字符集无法覆盖全部国标生僻汉字,是乱码首要诱因,执行 SQL 查看库字符集:
sql
select userenv('language') from dual;查询结果若为SIMPLIFIED CHINESE_CHINA.ZHS16GBK,代表库字符集固定,无法整体变更,只能通过字段类型调整兼容生僻字。
2. 字段类型是关键:VARCHAR2 不支持生僻字
VARCHAR2 依托数据库 GBK 字符集存储,超出 GBK 编码范围的生僻字无法正常保存,想要兼容全量 Unicode 汉字,需要将字段VARCHAR2 改为 NVARCHAR2(N 类型基于 AL16UTF16 Unicode 编码)。
二、字段类型变更实操步骤
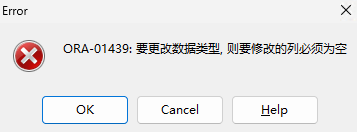
重要提醒:字段 VARCHAR2→NVARCHAR2不可逆 ,后续无法直接改回原类型,改回会触发 ORA-01439 报错(列非空不能修改字段类型),修改前必须全量备份表数据。
- 备份原表数据
sql
create table xm_xyxxb_bak as select * from xm_xyxxb;- 修改字段为 NVARCHAR2
sql
ALTER TABLE xm_xyxxb MODIFY (xm NVARCHAR2(200));- 反向修改报错说明
直接从 NVARCHAR2 改回 VARCHAR2 会抛出ORA-01439:要更改数据类型,则要修改的列必须为空,若无清空字段数据,无法回撤字段类型。
三、生僻字入库与显示验证
1. Unicode 辅助录入生僻字
生僻字可通过在线工具查询对应 Unicode 编码,辅助数据录入,参考转换站点:bejson 编码转换。
2. 测试生僻字更新查询
sql
-- 更新生僻字数据
UPDATE xm_xyxxb SET xm = '䢺 䶮 㛃' where fid = '821028414571024384';
-- 查询校验存储结果
select xm from xm_xyxxb where fid = '821028414571024384';执行后可正常查询出原生僻字,代表存储改造生效。
3. PL/SQL Developer 客户端生僻字显示异常处理
若数据库存储正常,但 PL/SQL 客户端展示乱码:
打开【工具】→【首选项】→【选项】,勾选unicode enable,重启客户端即可正常展示 Unicode 生僻字。
四、NVARCHAR2 改造后衍生问题 & 解决方案
字段改为 NVARCHAR2 后,会出现聚合函数失效、UNION 关联字符集不匹配两大高频故障,下文逐个解决。
问题 1:WM_CONCAT 聚合函数查询无数据
原因 :WM_CONCAT 原生适配 VARCHAR2,不兼容 NVARCHAR2 类型字段。
临时处理方案 :通过TO_CHAR()强制转换字段字符类型后聚合
sql
SELECT WM_CONCAT(TO_CHAR(name)) FROM TT;问题 2:UNION 关联报 ORA-12704 字符集不匹配
报错场景 :一张表字段为 NVARCHAR2,另一张为 VARCHAR2,使用 UNION 拼接查询触发ORA-12704:字符集不匹配。
sql
-- 错误SQL
select name from TT
union
select vname from tt;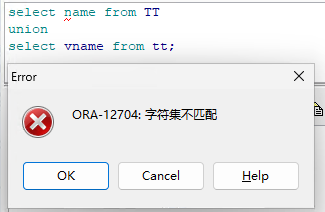
解决思路 :VARCHAR2 字段拼接N''隐式转为 NVARCHAR2,统一两边字符编码
sql
-- 修正SQL
select name from TT
union
select N''||vname from tt;五、总结
-
库字符集为 ZHS16GBK 时,生僻字存储最优方案:VARCHAR2→NVARCHAR2;
-
NVARCHAR2 修改不可逆,上线前务必备份全量数据表;
-
改造后重点排查 WM_CONCAT、UNION 多表拼接等 SQL,提前做类型转换适配;
-
PL/SQL 客户端开启 Unicode 配置,解决客户端可视化乱码问题。