注:本文为 "Xilinx FFT" 相关合辑。
略作重排,未整理去重。
图片清晰度受引文原图所限。
如有内容异常,请看原文。
Xilinx FFT IP 核配置说明及使用方法
白码王子小张 2025-10-16 15:44:14
快速傅里叶变换(Fast Fourier Transform,FFT)为离散傅里叶变换(Discrete Fourier Transform,DFT)的高效实现算法,可完成有限长度离散时域信号至频域信号的映射运算,例如音频采样序列的域变换:时域表征信号幅值随时间的变化规律,频域表征信号对应的各频率正弦分量组成关系。离散傅里叶变换是时域与频域转换分析的通用数学工具,广泛应用于各类数字信号处理工程场景。
一、FFT IP 核配置界面参数说明
1. Configuration
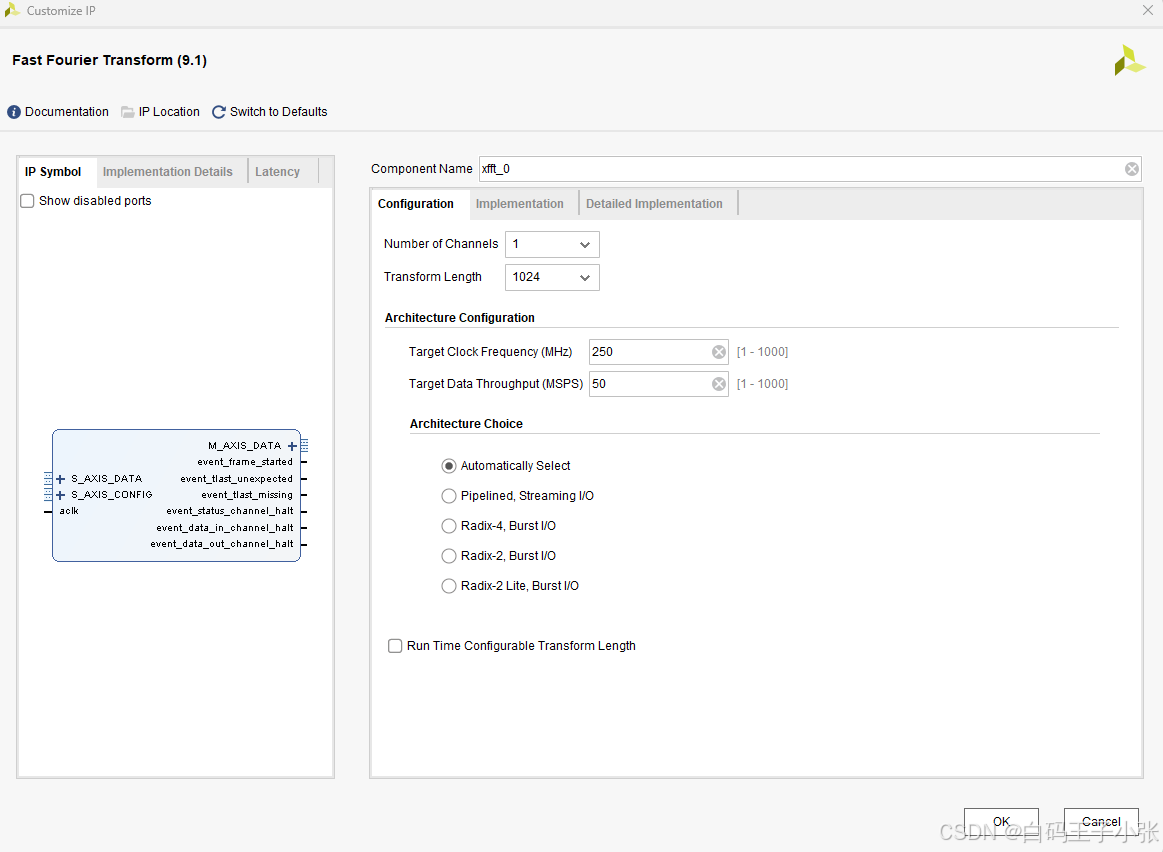
-
Number of Channels :配置参与 FFT 运算的数据通路数量,可选取值范围为 1 ∼ 12 1 \sim 12 1∼12。该参数适配三类 Burst I/O 架构的多通路工作模式;多通路配置下各数据通路共用控制逻辑,可缩减硬件资源占用,但扇出布线约束会降低器件可达到的最高工作时钟。若选用浮点数据格式(伪浮点、原生浮点),通道数量固定配置为 1 1 1。
-
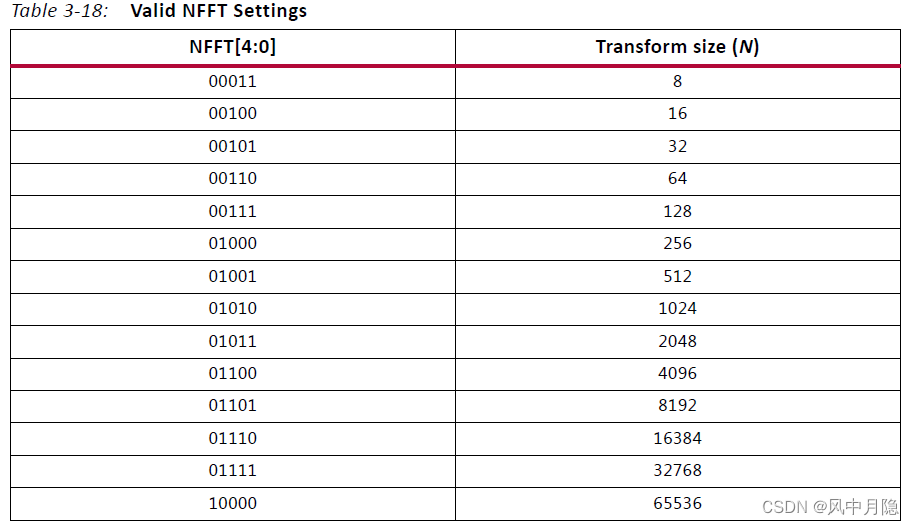
Transform Length :设定单次 FFT 运算的数据点数,可选数值为区间 8 , 65536 8,65536 8,65536 内全部 2 2 2 的整数次幂。
-
Architecture Configuration
-
Target Clock Frequency(MHz):IP 核额定工作时钟参数。
-
Target Data Throughput(MSPS):系统目标采样速率参数。
上述两项参数仅在 Architecture Choice 勾选 Automatically Select 时生效,用于 IP 核自动匹配硬件架构与运算时延,IP 核实际运行指标不强制匹配填写的时钟频率与吞吐速率。
-
-
Architecture Choice(FFT 运算架构选型)
FFT IP 核提供五类硬件架构,各类架构在硬件资源开销与单帧变换耗时上存在差异化表现,下述架构的单帧变换耗时沿行文顺序逐步增加:
- Automatically Select:自动配置模式,IP 核最终固化为 Pipelined Streaming I/O 架构。
- Pipelined Streaming I/O:支持变换点数范围 8 ∼ 65536 8 \sim 65536 8∼65536,具备连续数据流处理能力,兼容原生浮点数据格式。
- Radix-4 Burst I/O:支持变换点数范围 64 ∼ 65536 64 \sim 65536 64∼65536,采用迭代式数据读写与运算逻辑;硬件资源占用低于流水线架构,单帧变换耗时更长。
- Radix-2 Burst I/O:支持变换点数范围 8 ∼ 65536 8 \sim 65536 8∼65536,迭代运算逻辑与 Radix-4 Burst I/O 保持一致,蝶形运算单元规模更小;资源占用少于 Radix-4 Burst I/O,单帧变换耗时进一步增加。
- Radix-2 Lite Burst I/O:支持变换点数范围 8 ∼ 65536 8 \sim 65536 8∼65536,基于 Radix-2 架构采用时分复用方式复用运算内核实现蝶形运算,硬件资源占用最低,对应单帧变换耗时为五类架构最大值。
- Run Time Configurable Transform Length :使能选项后,可在 IP 核上电运行阶段动态修改 Transform Length 参数;取消勾选可缩减综合逻辑资源,提升器件可实现的最大时钟频率。配置原生浮点格式或定点格式
SSR> 1 >1 >1 时,该配置项锁定为不可选状态。
2. Implementation

-
Data Format :输入、输出采样数据格式配置项,可选定点格式或 32 32 32 位单精度浮点格式;多通道工作模式下浮点格式禁用。
-
Scaling Options
- Scaled:分级缩放截位模式,用户自定义分段缩放系数,控制 FFT 各级蝶形运算后的数据位宽截取规则。
- Unscaled:无缩放模式,运算全程不执行数据截位。
- Block Floating-Point:块浮点模式,由 IP 核自动计算各级缩放系数以充分利用数据动态范围,缩放系数以块指数字段对外输出。
-
Rounding Modes:蝶形运算输出低位比特的取舍规则配置,包含两种处理方案:
- Truncated:直接截断低位比特。
- Convergent Rounding:收敛舍入(无偏舍入),小数部分数值恰好等于 0.5 0.5 0.5 时,奇数原数向上取整、偶数原数向下取整;该方式可抑制截断操作引入的直流偏移量,但会增加 Slice 资源占用与运算链路延迟。
-
Precision Options
-
Input Data Width:输入采样数据位宽。
-
Phase Factor Width:旋转因子存储位宽。
定点格式下输入数据位宽、旋转因子位宽可独立配置在 8 ∼ 34 8 \sim 34 8∼34 bit;浮点格式输入数据位宽固定为 32 32 32 bit,旋转因子可选 24 24 24 bit、 25 25 25 bit;原生浮点格式旋转因子固定为 32 32 32 bit;定点格式
SSR> 1 >1 >1 时旋转因子固定为 19 19 19 bit,变换点数小于 65536 65536 65536 时输入位宽范围 8 ∼ 18 8 \sim 18 8∼18 bit,变换点数等于 65536 65536 65536 时输入位宽范围 8 ∼ 16 8 \sim 16 8∼16 bit。
-
-
Control Signals
-
Clock Enable (
aclken):高电平有效时钟使能控制信号。 -
Synchronous Clear (
aresetn):低电平有效异步复位控制信号。两项控制信号同时启用时,异步复位信号优先级高于时钟使能信号;取消对应信号勾选可节约逻辑资源,优化系统最高时钟指标。
-
-
Output Ordering Options
-
Output Ordering
-
Bit/Digit Reversed Order
逆序输出;基于 Radix‑2 的三类架构(Pipelined Streaming I/O、Radix‑2 Burst I/O、Radix‑2 Lite Burst I/O)生成位逆序数据,Radix‑4 Burst I/O 架构生成数字逆序数据。
-
Natural Order
自然顺序输出;Pipelined Streaming I/O 架构选用该模式将扩充片上存储资源开销,各类 Burst I/O 架构选用该模式将新增数据重排序卸载周期,拉长整体变换耗时。
-
Cyclic Prefix Insertion
循环前缀插入功能,仅自然顺序输出模式下可配置;除原生浮点
SSR流水线架构外,其余架构均支持该配置,多用于 OFDM 无线通信链路;原生浮点SSR、定点 S S R > 1 \boldsymbol{SSR>1} SSR>1 的流水线流式架构固定为自然序输出,无法启用循环前缀插入。
-
-
Optional Output Fields
XK_INDEX:数据输出通路可选附加字段。OVFLO:数据输出通路、状态输出通路可选附加字段。- 配置原生浮点格式或定点格式
SSR> 1 >1 >1 时,XK_INDEX、OVFLO两个字段全部禁用。
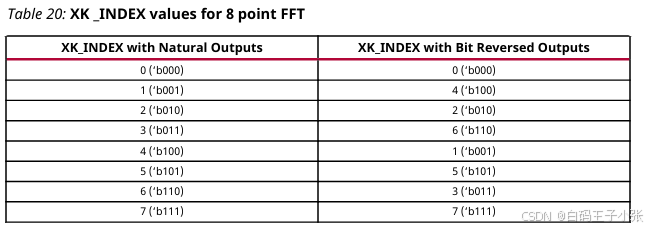
XK_INDEX字段用于标记当前输出XK_RE/XK_IM对应的采样序号;自然序输出时字段取值自 0 0 0 连续递增至 N − 1 N-1 N−1( N N N 为配置变换点数);逆序输出时取值区间不变,但序号排布遵循位/数字逆序规则。以 8 8 8 点 FFT 运算为例,
XK_INDEX映射规则参考下表:启用循环前缀插入时,IP 核优先输出循环前缀数据,
XK_INDEX由 N − N- N−CP_LEN起始计数至 N − 1 N-1 N−1;循环前缀数据输出完毕或CP_LEN= 0 =0 =0 时,序号重新由 0 0 0 计数至 N − 1 N-1 N−1;该功能仅适配自然顺序输出。
- Throttle Schemes
基于硬件资源与数据时序约束选择工作模式:
- Non Real Time:非实时模式,无严苛的数据收发时序约束,综合后硬件规模偏大、最高工作时钟偏低。
- Real Time:实时模式,硬件实现结构精简、可运行更高时钟,但上下游数据收发必须匹配 IP 核吞吐时序。
3. Detailed Implementation
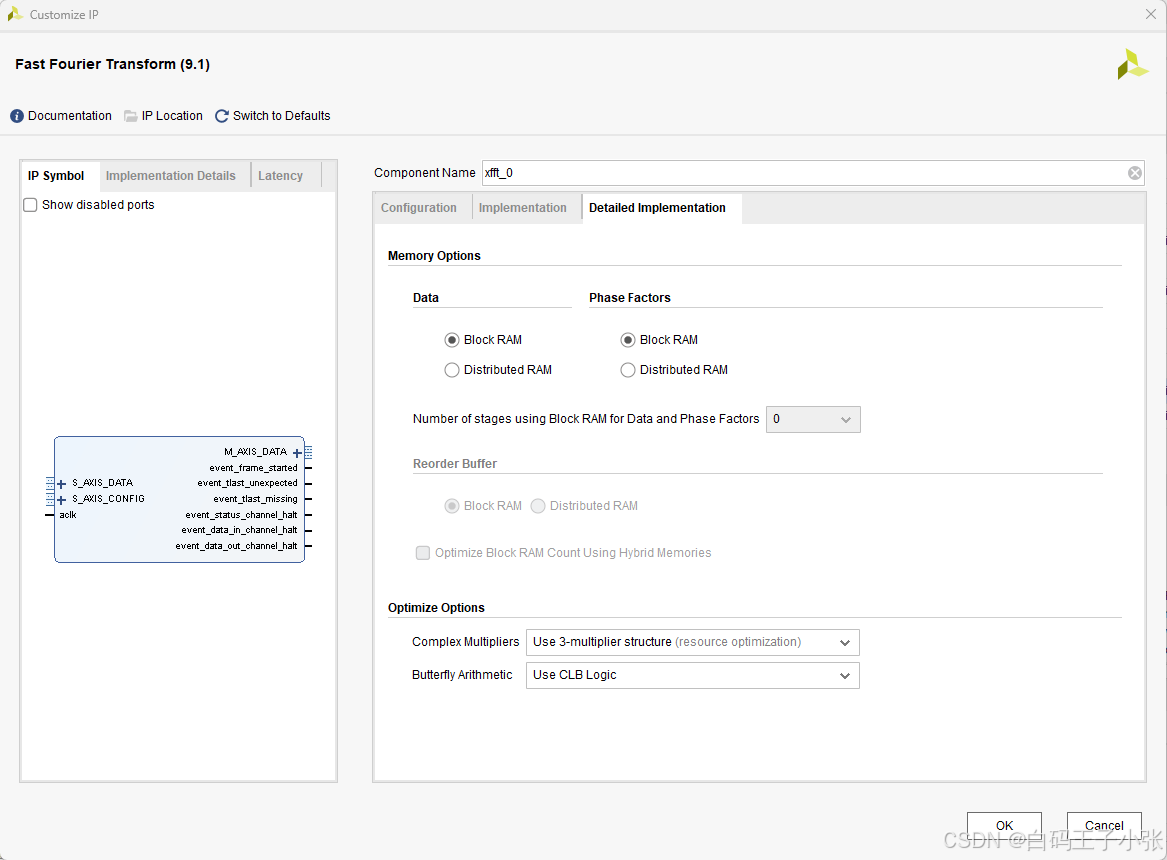
- Memory Options
- Data And Phase Factors (Burst I/O architectures):Burst I/O 架构的数据、旋转因子存储介质可选块 RAM 或分布式 RAM;变换点数 ≤ 1024 \le 1024 ≤1024 时,全部存储资源均可选用分布式 RAM。
- Data And Phase Factors (Pipelined Streaming I/O):流水线流式架构各级流水线可混合采用块 RAM、分布式 RAM 存储数据与旋转因子,流水线层级越靠后,所需存储容量逐步减小;用户可自定义前若干级流水线使用块 RAM,剩余层级自动选用分布式 RAM,Vivado 默认配置完成两类存储的折中选型。自然序输出所需重排序缓存可自由选择 RAM 类型,点数 ≤ 1024 \le 1024 ≤1024 时缓存可全部采用分布式 RAM;流水线架构选用块浮点格式时,需配置双份缓存分别存储自然序、逆序输出数据,变换点数 < 2048 <2048 <2048 时重排序缓存仍可选用分布式 RAM。
- Optimize Options
- Complex Multipliers:复数乘法器硬件实现方案:
- Use CLB logic:全部复数乘法单元依托 Slice 逻辑搭建,适配低性能指标、器件 DSP 资源稀缺的应用场景。
- Use 3-multiplier structure (resource optimization):采用三乘五加减复数运算架构,乘法运算由 DSP 单元实现;该方案降低 DSP 用量,占用额外 Slice 资源,依托 DSP 内置预加单元可削减附加逻辑开销。
- Use 4-multiplier structure (performance optimization):采用四乘两加减复数运算架构,全部运算在 DSP 单元内部完成;以消耗更多 DSP 硬件资源换取最优时序性能;原生浮点、定点
SSR> 1 >1 >1 配置强制选用该架构。
- Butterfly Arithmetic:蝶形运算单元硬件实现方案:
- Use CLB logic:全链路蝶形运算依托 Slice 逻辑实现。
- Use XtremeDSP Slices:强制所有蝶形运算在 DSP 内置加减单元中实现;原生浮点、定点
SSR> 1 >1 >1 配置默认启用本项。
- Complex Multipliers:复数乘法器硬件实现方案:
二、IP 核接口信号说明
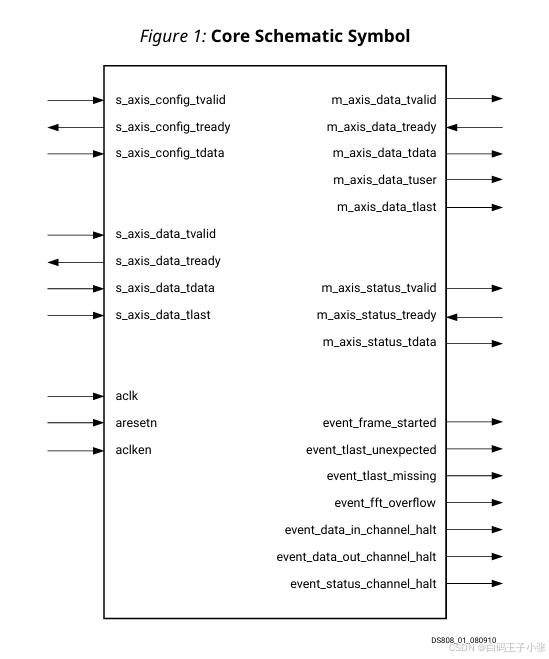
1. 时钟/复位接口
aclk:全局同步工作时钟。aresetn:低电平有效异步复位信号,配置可选,优先级高于aclken;有效脉冲宽度不小于 2 2 2 个时钟周期。aclken:高电平有效时钟使能信号,配置可选。
2. 数据配置接口
(1)接口信号定义
s_axis_config_tvalid:配置输入数据有效标志。s_axis_config_tready:IP 配置通道就绪握手标志,高电平代表可接收配置指令。s_axis_config_tdata:配置参数输入总线。
配置通道遵循 AXI4-Stream 规范,配置字段在 s_axis_config_tdata 内的排布规则参考下表:
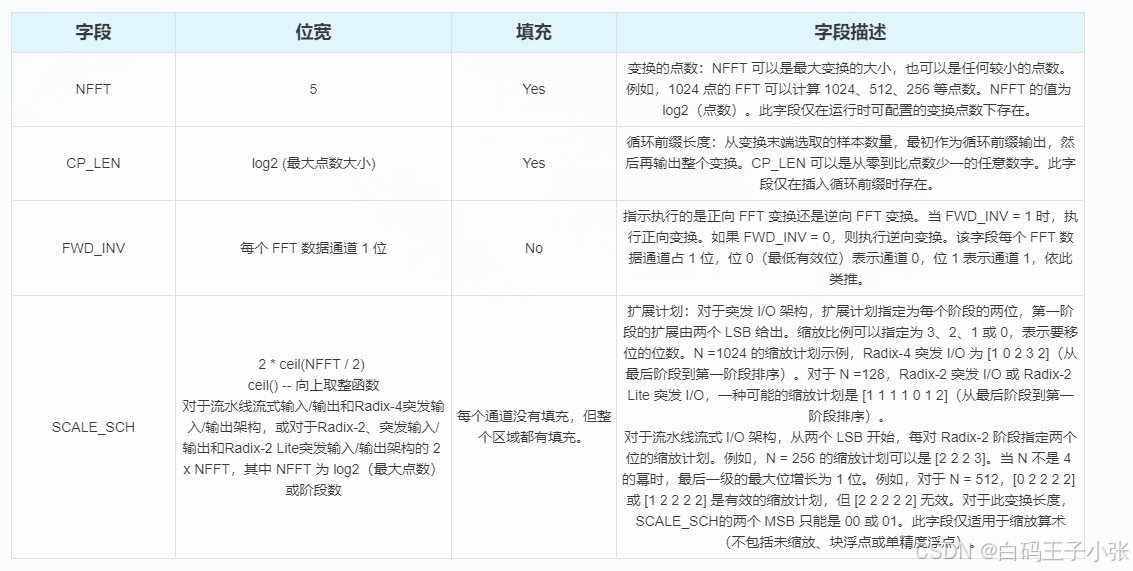
字段由最低有效位向高位依次排布:
- (可选)
NFFT字段 + 填充位 - (可选)
CP_LEN字段 + 填充位 FWD_INV正逆变换控制位- (可选)
SCALE_SCH分级缩放配置字段
虚线标注字段为可选配置项;s_axis_config_tdata 位宽可大于全部配置字段总位宽,冗余比特在综合阶段自动优化移除。
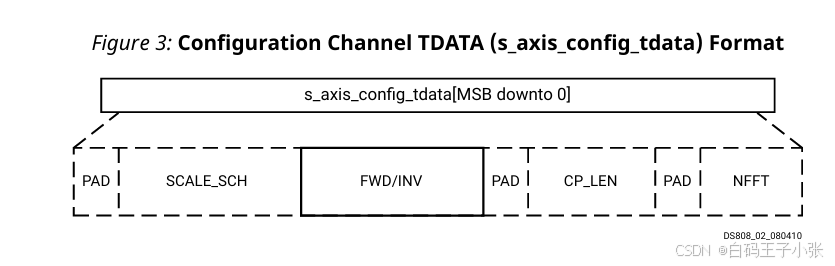
(2)配置实例
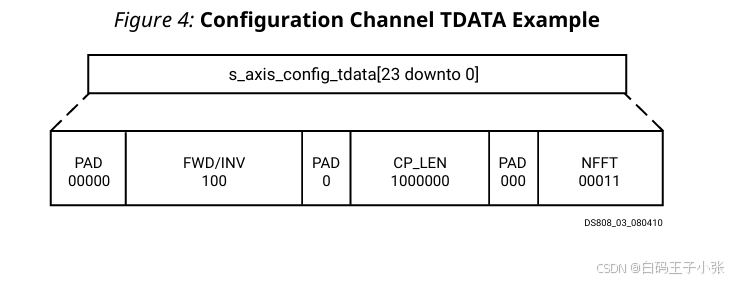
IP 最大支持 128 128 128 点变换、三路数据通道,启用循环前缀配置;需求参数:单帧执行 8 8 8 点 FFT,通道 0 0 0、通道 1 1 1 配置逆变换,通道 2 2 2 配置正变换,循环前缀长度 CP_LEN = 4 =4 =4。各字段赋值参考下表:
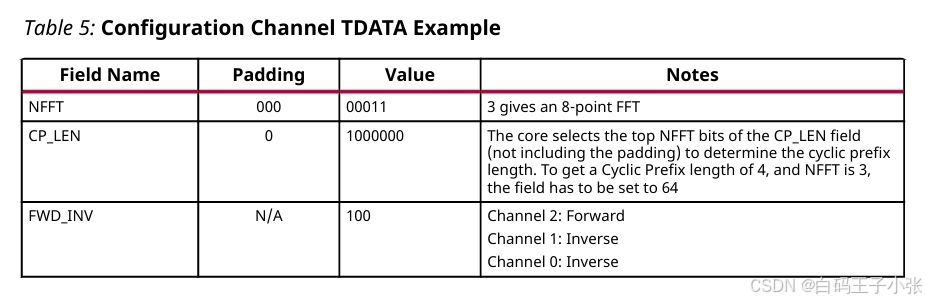
原始配置字段总位宽为 19 19 19 bit,AXI 总线要求字节对齐,补充 5 5 5 bit 填充位后 s_axis_config_tdata 总线位宽扩充至 24 24 24 bit。
3. 数据输入接口
(1)接口信号定义
s_axis_data_tvalid:输入采样数据有效标志。s_axis_data_tready:IP 数据输入通道就绪握手标志。s_axis_data_tdata:复数采样输入总线。s_axis_data_tlast:帧结束标记,由上游主控在单帧最后一个采样周期拉高;该信号用于生成event_tlast_unexpected、event_tlast_missing异常事件,不参与 FFT 运算逻辑。
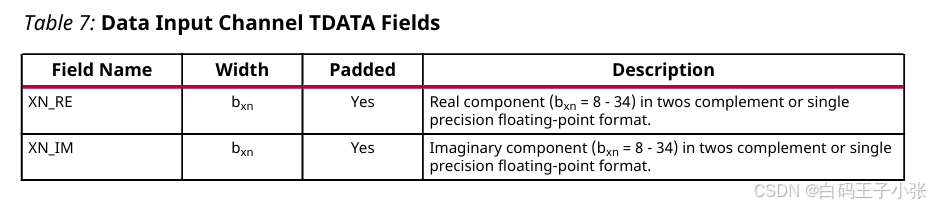
XN_RE:采样实部,位宽取值区间 8 ∼ 34 8 \sim 34 8∼34 bit,编码格式为二进制补码或单精度浮点,字段支持高位填充。XN_IM:采样虚部,位宽取值区间 8 ∼ 34 8 \sim 34 8∼34 bit,编码格式为二进制补码或单精度浮点,字段支持高位填充。
字段拼接后若总位宽无法被 8 8 8 整除,补充高位填充比特至字节边界;填充比特电平可固定,恒定电平输入可减少后端布线资源。多通道配置下,实虚部字段按通道序号循环排布。
SSR(Super Sample Rate,超采样率):单时钟周期传输多组采样数据;原生浮点格式SSR可选 2 , 4 , 8 , 16 , 32 , 64 2,4,8,16,32,64 2,4,8,16,32,64;定点格式SSR可选 1 , 2 , 4 1,2,4 1,2,4;伪浮点格式SSR固定为 1 1 1。
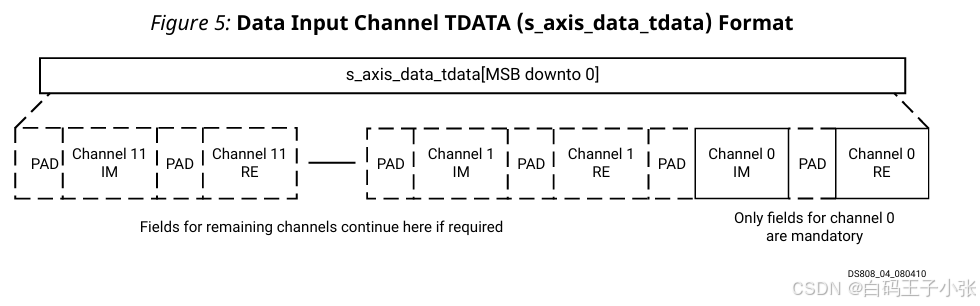
(2)多通道、 S S R = 1 \mathbf{SSR=1} SSR=1 数据排布规则
s_axis_data_tdata 由最低有效位向高位依次排布:
- 通道 0 0 0:
XN_RE+ 填充位 - 通道 0 0 0:
XN_IM+ 填充位 - (可选)通道 1 1 1:
XN_RE+ 填充位 - (可选)通道 1 1 1:
XN_IM+ 填充位 - 后续通道依次顺延排布至通道 11 11 11
虚线字段为可选配置项。
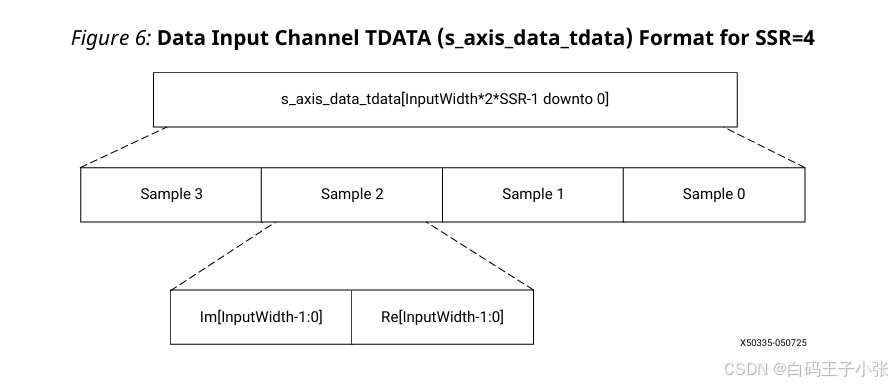
(3)单通道、 S S R > 1 \mathbf{SSR>1} SSR>1 数据排布规则
s_axis_data_tdata 由最低有效位向高位依次排布:
- 采样 0 0 0:
XN0_RE - 采样 0 0 0:
XN0_IM - 采样 1 1 1:
XN1_RE - 采样 1 1 1:
XN1_IM - (可选)采样 2 2 2:
XN2_RE - (可选)采样 2 2 2:
XN2_IM - 后续采样依次顺延排布
(4)输入数据排布实例
IP 配置两路输入通道,单通道实/虚部位宽 12 12 12 bit;
通道 0 0 0:Re = 0010 1101 1001 =0010\ 1101\ 1001 =0010 1101 1001,IM = 0011 1110 0110 =0011\ 1110\ 0110 =0011 1110 0110
通道 1 1 1:Re = 0111 0000 0000 =0111\ 0000\ 0000 =0111 0000 0000,IM = 0000 0000 0000 =0000\ 0000\ 0000 =0000 0000 0000
字段拼接参数参考下表:

全部字段拼接后总线位宽为 64 64 64 bit。

4. 数据输出接口
(1)接口信号定义
m_axis_data_tvalid:IP 输出数据有效标志。m_axis_data_tready:下游从设备就绪握手标志,仅非实时模式硬件引脚存在。m_axis_data_tdata:FFT 运算结果实虚部输出总线。m_axis_data_tuser:附加状态信息总线,承载XK_INDEX、OVFLO、BLK_EXP字段。m_axis_data_tlast:帧结束标记,IP 在单帧最后一个采样周期自动拉高。
m_axis_data_tdata 传输 FFT 变换结果,m_axis_data_tuser 同步输出逐采样状态参数,数据与状态同步传输保证时序对齐;单采样绑定状态包含三类参数:XK_INDEX、分通道块指数 BLK_EXP、分通道溢出标志 OVFLO。
m_axis_data_tdata 字段组成参考下表:
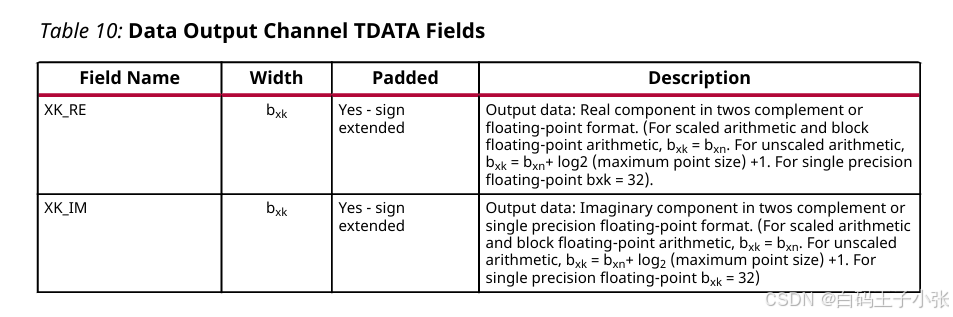
XK_RE:输出实部,缩放/块浮点模式下bxk= = =bxn;无缩放模式下bxk= = =bxn× log 2 N m a x + 1 \times \log_2N_\mathrm{max}+1 ×log2Nmax+1;单精度浮点格式固定 32 32 32 bit,字段支持符号扩展填充。XK_IM:输出虚部,位宽规则与XK_RE保持一致,字段支持符号扩展填充。
字段拼接位宽非 8 8 8 的整数倍时,高位符号扩展至字节边界;多通道配置下字段按通道序号循环排布。
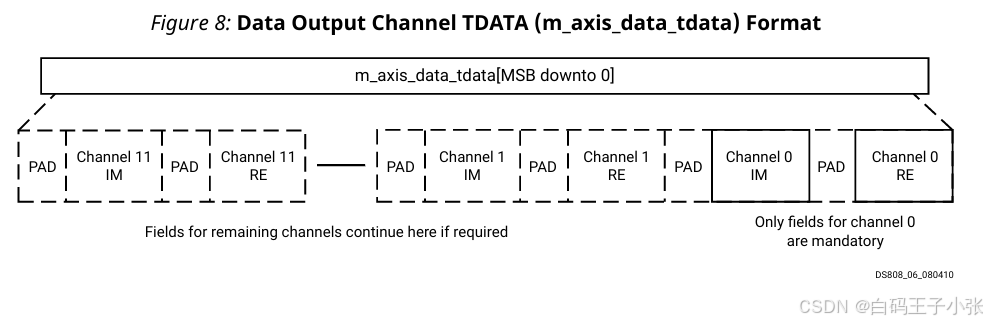
(2)多通道、 S S R = 1 \mathbf{SSR=1} SSR=1 输出排布规则
m_axis_data_tdata 由最低有效位向高位排布:
- 通道 0 0 0:
XK_RE+ 填充位 - 通道 0 0 0:
XK_IM+ 填充位 - (可选)后续通道实虚部字段依次顺延至通道 11 11 11
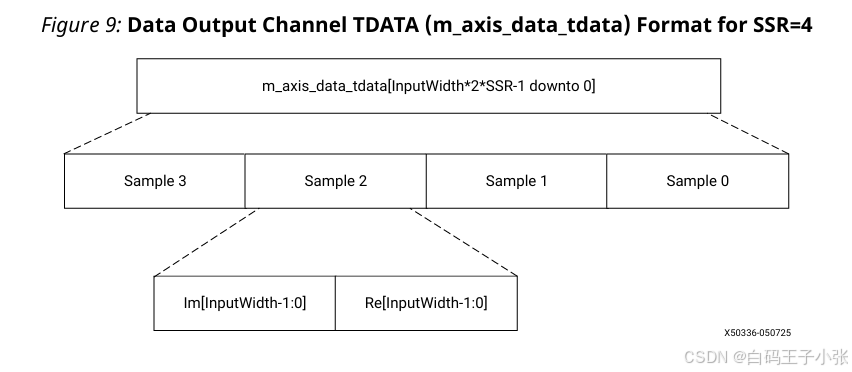
(3)单通道、 S S R > 1 \mathbf{SSR>1} SSR>1 输出排布规则
m_axis_data_tdata 由最低有效位向高位排布:
- 采样 0 0 0:
XK0_RE、XK0_IM - 采样 1 1 1:
XK1_RE、XK1_IM - (可选)后续采样字段依次顺延排布
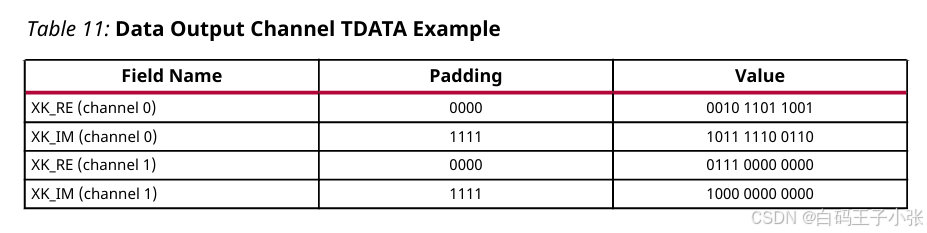
(4)输出数据排布实例
IP 配置两路输出通道,单通道实/虚部位宽 12 12 12 bit;
通道 0 0 0:Re = 0010 1101 1001 =0010\ 1101\ 1001 =0010 1101 1001,IM = 1011 1110 0110 =1011\ 1110\ 0110 =1011 1110 0110
通道 1 1 1:Re = 0111 0000 0000 =0111\ 0000\ 0000 =0111 0000 0000,IM = 1000 0000 0000 =1000\ 0000\ 0000 =1000 0000 0000
字段参数与总线拼接参考附图:

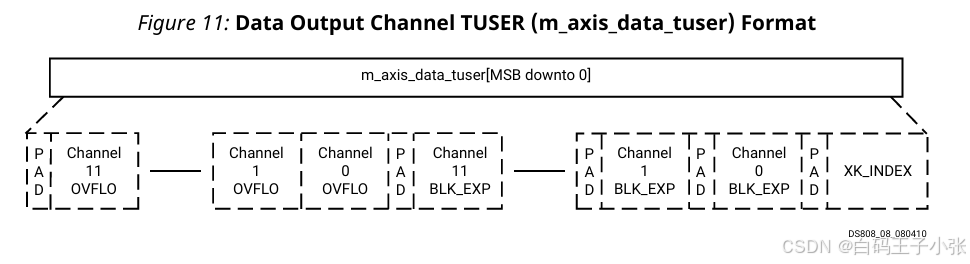
(5)TUSER 字段定义与排布
m_axis_data_tuser 字段组成参考下表:
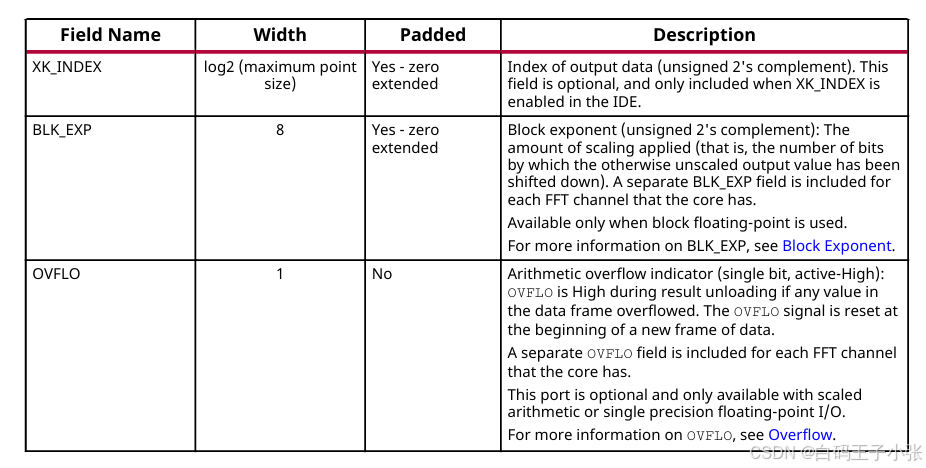
XK_INDEX:采样序号,无符号编码,可选字段,高位补零填充。BLK_EXP:单通道块指数,无符号编码,仅块浮点模式启用,高位补零填充,各通道独立字段。OVFLO:单比特溢出标志,高电平有效;单帧任意采样溢出则本帧标志置高,新帧启动自动复位;缩放、浮点格式可选,无填充位,各通道独立字段。
字段总位宽非 8 8 8 整数倍时补充零填充至字节边界;m_axis_data_tuser 由最低有效位向高位排布顺序:
- (可选)
XK_INDEX+ 填充位 - (可选)各通道
BLK_EXP+ 填充位(通道升序) - (可选)各通道
OVFLO(通道升序) - 补充填充位实现字节对齐(仅存在
OVFLO字段时)
同一 IP 配置无法同时启用 BLK_EXP、OVFLO 两个字段;全部字段取消勾选时 m_axis_data_tuser 引脚自动移除。
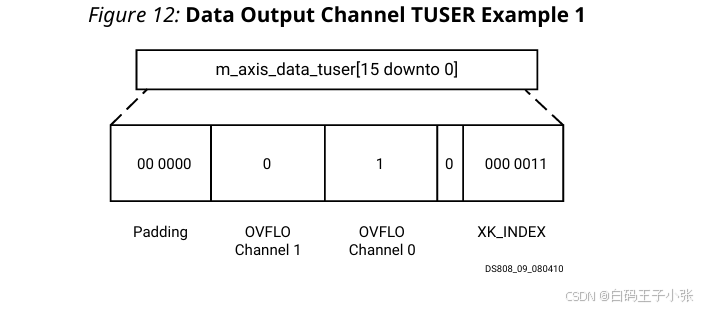
实例 1
双路通道、 128 128 128 点变换,启用 XK_INDEX 与 OVFLO;XK_INDEX 位宽 7 7 7 bit,通道 0 0 0 第 3 3 3 号采样溢出、通道 1 1 1 无溢出。字段赋值参考下表:

原始字段总位宽 10 10 10 bit,补充 6 6 6 bit 填充位后总线位宽 16 16 16 bit。
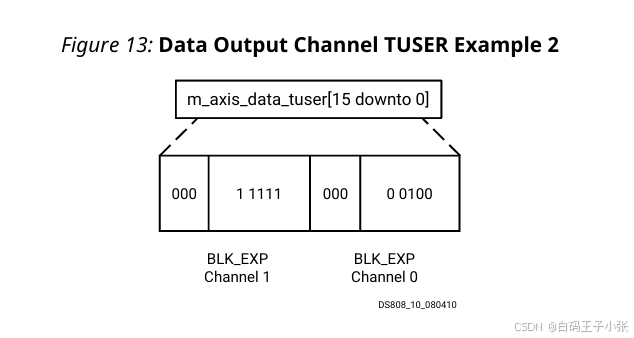
实例 2
双路通道,启用 BLK_EXP、禁用 XK_INDEX;通道 0 0 0 块指数 4 4 4、通道 1 1 1 块指数 31 31 31。字段拼接后总线位宽 16 16 16 bit,无需额外填充。

5. IP 状态接口
(1)接口信号定义
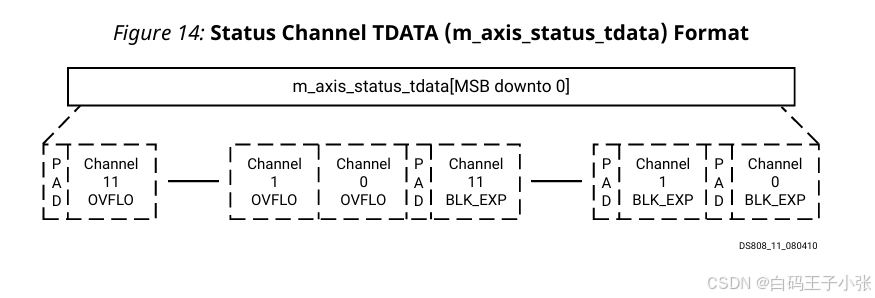
m_axis_status_tvalid:帧状态数据有效标志。m_axis_status_tready:下游状态接收就绪标志,仅非实时模式硬件引脚存在。m_axis_status_tdata:整帧状态输出总线,承载分通道BLK_EXP或OVFLO。
状态通道输出整帧全局参数:分通道块指数、分通道溢出标志;BLK_EXP 在帧起始周期输出,OVFLO 在帧结束周期输出;IP 无法同时配置两类状态字段。
m_axis_status_tdata 字段组成参考下表:
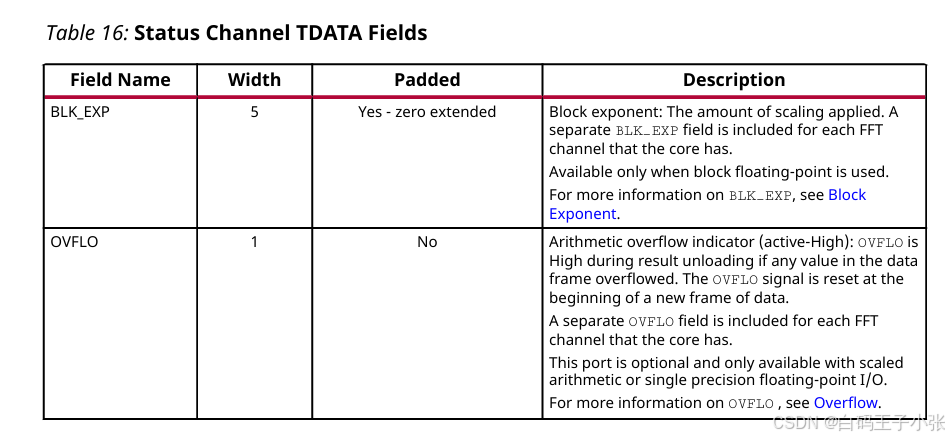
BLK_EXP:单通道块指数,块浮点模式启用,各通道独立字段。OVFLO:单比特帧溢出标志,高电平有效,新帧复位;缩放、浮点格式可选,各通道独立字段。
字段总位宽非 8 8 8 整数倍时补充零填充至字节边界;m_axis_status_tdata 由最低有效位向高位排布顺序:
- (可选)各通道
BLK_EXP+ 填充位(通道升序) - (可选)各通道
OVFLO(通道升序) - 补充填充位实现字节对齐(仅存在
OVFLO字段时)
全字段禁用时,整组状态接口引脚自动移除。
(2)状态输出实例 1
四路通道配置,启用 OVFLO;单帧通道 2 2 2、通道 3 3 3 发生数据溢出。字段原始位宽 4 4 4 bit,补充 4 4 4 bit 填充位后总线位宽 8 8 8 bit。


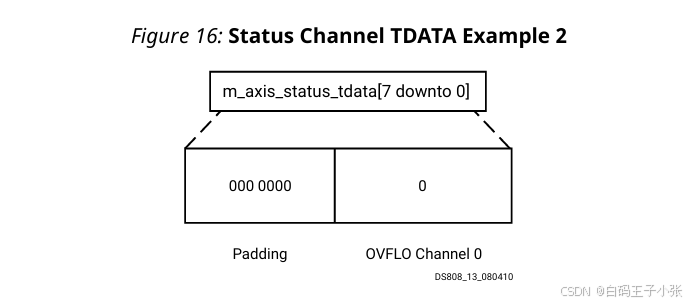
(3)状态输出实例 2
单路通道配置,启用 OVFLO;当前帧不包含溢出。字段原始位宽 1 1 1 bit,补充 7 7 7 bit 填充位后总线位宽 8 8 8 bit。

6. IP 事件接口
event_frame_started:IP 启动新一帧数据运算时拉高。event_tlast_unexpected:s_axis_data_tlast提前置高,当前采样非帧末尾采样时拉高,标记帧结束信号误触发。event_tlast_missing:单帧末尾采样抵达但s_axis_data_tlast保持低电平,拉高标记帧结束信号缺失。event_fft_overflow:运算过程出现数值溢出时拉高。event_data_in_channel_halt:IP 输入通道请求数据但上游无有效输入时拉高。event_data_out_channel_halt:IP 输出有效数据但下游未就绪,仅非实时模式有效。event_status_channel_halt:IP 输出状态数据但下游未就绪,仅非实时模式有效。
三、AXI 接口时序
FFT IP 核基于 AXI4-Stream 协议实现数据流收发。
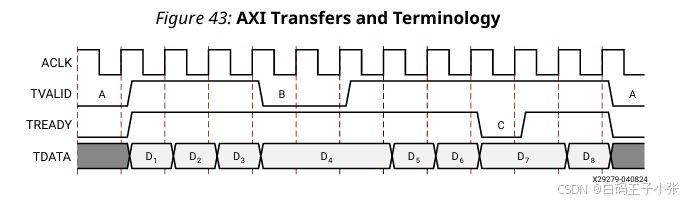
上游主控拉高 TVALID 后,数据总线电平保持稳定,直至从设备拉高 TREADY 完成握手。
非实时模式时序规则
上游主控在 s_axis_data_tready = 1 =1 =1 时发送采样数据,数据存入 IP 内部缓存等待运算;s_axis_data_tready = 0 =0 =0 时上游主控进入等待状态,暂停数据发送。附图为 8 8 8 点 FFT 数据载入时序,上游驱动 TVALID、IP 驱动 TREADY,收发双方均可插入等待周期。
IP 作为输出侧主控,m_axis_data_tvalid = 1 =1 =1 代表有效数据输出;下游从设备通过 m_axis_data_tready 控制接收时序,m_axis_data_tready = 0 =0 =0 时 IP 暂停输出,附图同步展示无循环前缀 8 8 8 点 FFT 数据卸载时序。
实时模式时序规则
启用实时模式后硬件接口发生三处变更:
- 移除
m_axis_data_tready引脚 - 移除
m_axis_status_tready引脚 - 帧载入启动后,
s_axis_data_tvalid电平不再参与握手判定
下游接收端必须在每个有效时钟周期完成数据锁存,接收不及时将造成数据丢失。
1. 无循环前缀 Pipelined Streaming I/O 架构
流水线架构支持帧载入与帧输出流水线重叠;上一帧末尾采样传输完毕后,上游可立即发送下一帧首采样,IP 同步开启新帧载入。
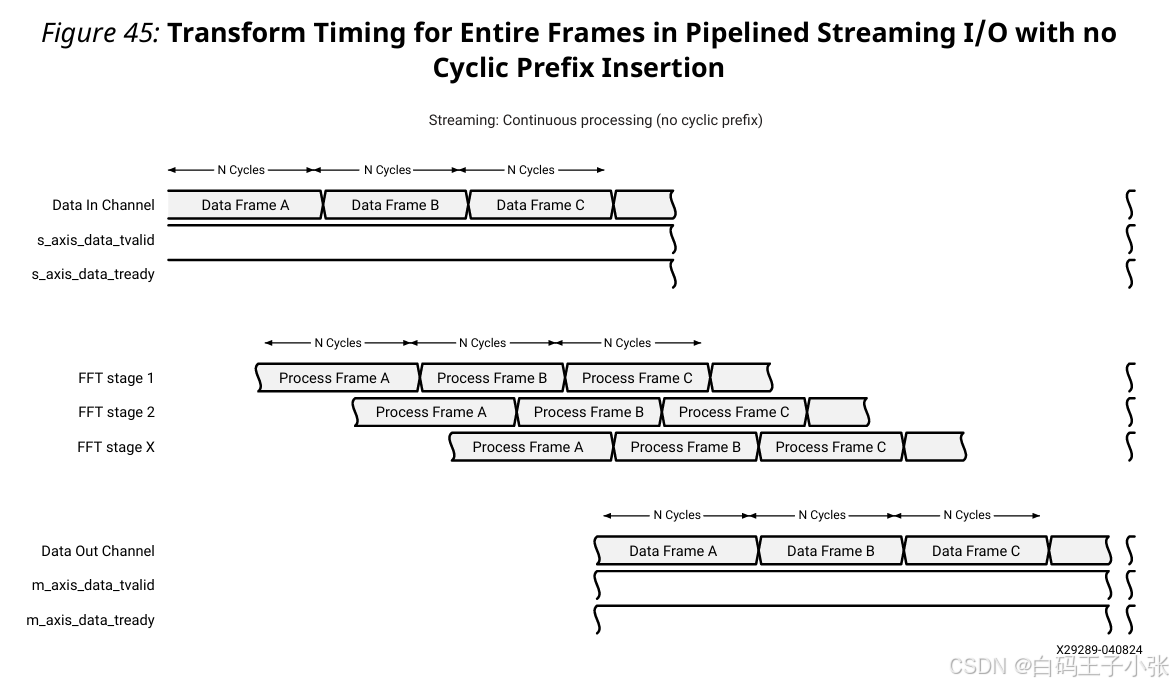
单帧载入至对应结果输出存在固定链路延迟,延迟数值由 IP 配置参数决定;延迟周期结束后各帧结果连续串行输出。
2. 启用循环前缀 Pipelined Streaming I/O 架构
插入循环前缀后输出总采样数量多于输入采样,帧与帧之间必须预留 CP_LEN 个时钟间隔用于前缀数据卸载;间隔阶段 s_axis_data_tready 拉低,阻塞上游输入。
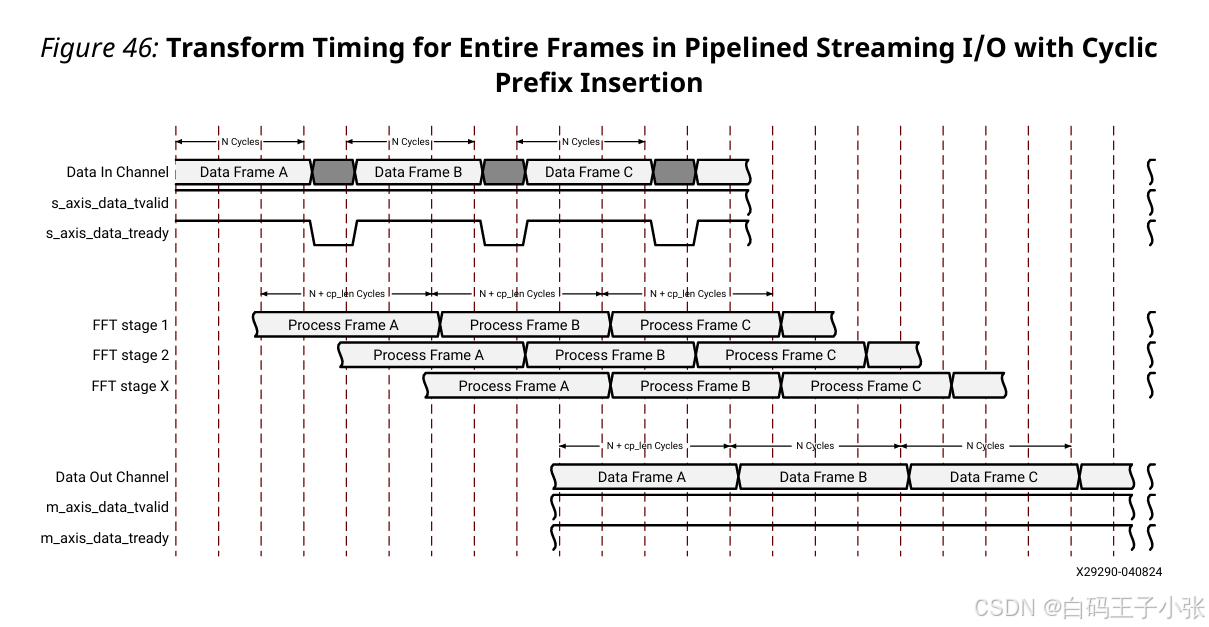
3. Burst I/O 架构
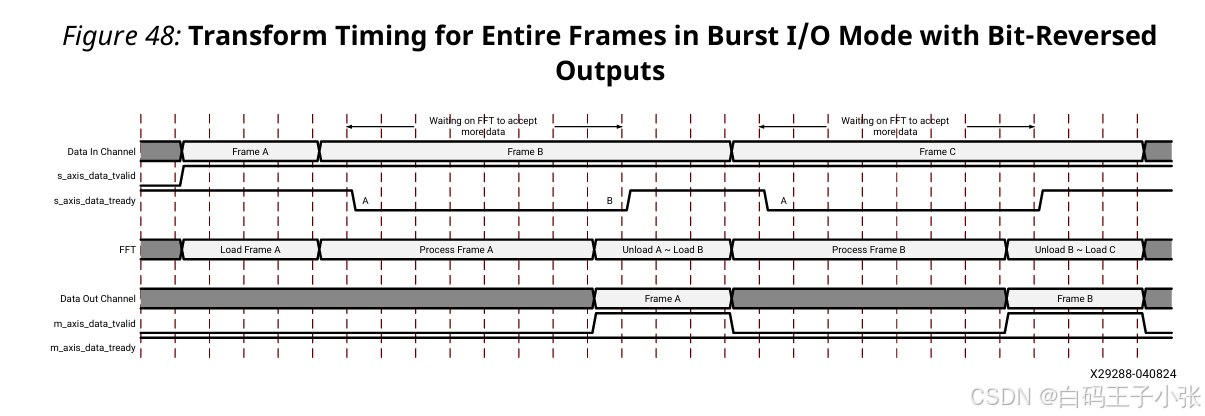
各类突发架构不支持帧运算与帧载入并行,整帧运算、数据输出全部完成后,IP 方可接收下一帧输入数据。
(1)自然顺序输出时序
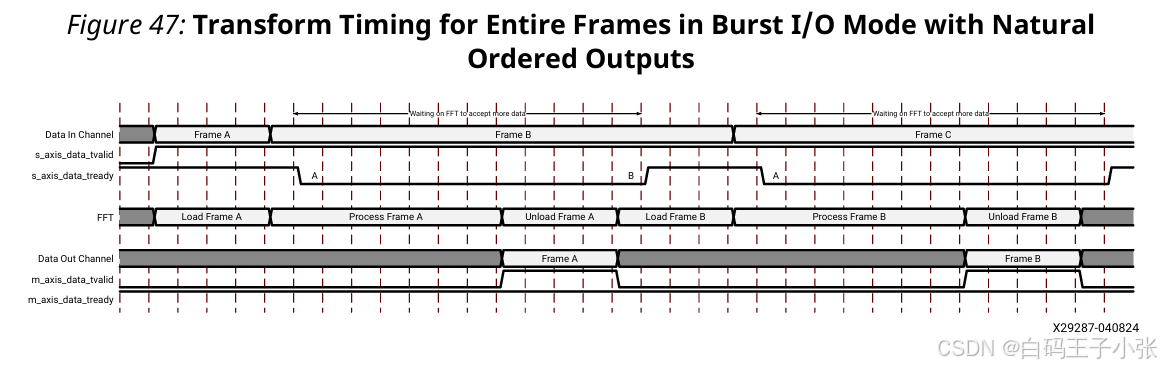
(2)位反转顺序输出时序
Xilinx FPGA FFT 应用笔记
yijingjing17 2015-08-31 18:26:22
初稿 2012 年
本文阐述基于 Xilinx Spartan 6 系列 FPGA 实现快速傅里叶变换(FFT)的信号处理工程流程,内容覆盖放大板标定流程、FPGA 硬件任务划分、离散傅里叶变换(DFT)原理推导、FFT 算法原理、Xilinx FFT IP 核参数配置与实例调试;依托实测案例完成 IP 核配置、数据收发解析,并对比 MATLAB 仿真数据,梳理影响输出幅值的各类影响因子。
系统运行环境
- 目标芯片:
Xilinx Spartan 6 - 开发软件:
ISE 12.2 - FFT IP 核版本:
7.1 - 工程目标:完成待测程控放大板全参数标定
一、放大板标定流程说明
待测放大板集成 3 级程控放大链路、4 路可选高频滤波电路、1 路 50 Hz 工频滤波电路,器件适用低频信号处理,额定通频带区间: 0 ∼ 20 k H z 0 \sim 20\ \mathrm{kHz} 0∼20 kHz。
标定参考原理图:
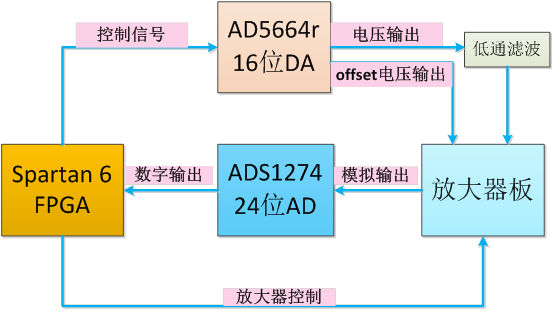
标定划分为偏置校准、直流标定、交流标定三个分项,分项操作规范如下:
1.1 偏置(offset)校准
将放大板输入端接地,配置放大器增益系数为 1000 1000 1000;采集 AD 输出电平,若输出偏离 0 V 0\ \mathrm{V} 0 V,表征放大器存在固有直流偏置;通过调整 DA 的 offset 输出电平,实现输入零电位条件下放大板输出归零。
1.2 直流参数标定
由 DA 输出固定直流电位,逐级配置放大器增益系数,比对放大板实际输出电压与理论计算值,完成放大链路直流响应特性校验。
实例:输入电平 0.1 m V 0.1\ \mathrm{mV} 0.1 mV、增益设置 1000 1000 1000,理论输出为 0.1 V 0.1\ \mathrm{V} 0.1 V,校验实测输出偏差。
1.3 交流参数标定
交流标定用于测定放大器件幅频特性与相频特性,工程实现逻辑:FPGA 驱动 DA 生成标准正弦激励信号,经放大板链路后由 AD 采集输出波形;对采集时域序列执行 FFT 运算,解析输出信号幅值、相位、频率参数,对比激励源原始参数,完成交流响应校验。
批量测试实例:
① 激励: f = 1 H z f=1\ \mathrm{Hz} f=1 Hz、 A = 10 m V A=10\ \mathrm{mV} A=10 mV、 φ = 0 ∘ \varphi=0^\circ φ=0∘ 正弦波,采集输出 A 、 φ 、 f A、\varphi、f A、φ、f;
② 激励: f = 2 H z f=2\ \mathrm{Hz} f=2 Hz、 A = 10 m V A=10\ \mathrm{mV} A=10 mV、 φ = 0 ∘ \varphi=0^\circ φ=0∘ 正弦波,采集输出 A 、 φ 、 f A、\varphi、f A、φ、f;
......
⑩ 激励: f = 2000 H z f=2000\ \mathrm{Hz} f=2000 Hz、 A = 10 m V A=10\ \mathrm{mV} A=10 mV、 φ = 0 ∘ \varphi=0^\circ φ=0∘ 正弦波,采集输出 A 、 φ 、 f A、\varphi、f A、φ、f。
该标定方案等效便携式频谱分析仪工作逻辑,依托频谱曲线判定放大链路是否出现频点偏移、幅值衰减。
二、FPGA 硬件功能划分
FPGA 在标定系统中承担五项硬件控制任务:
- 通用
IO端口逻辑控制,完成程控放大器档位配置; - 驱动模数转换芯片
ADS1274,实现模拟信号采集; - 驱动数模转换芯片
AD5664R,生成可编程激励波形; - 片内集成直接数字频率合成器(
DDS),输出频率、相位可编程正弦激励; - 对
AD采集的离散时域序列完成 FFT 频域变换运算。
三、傅里叶变换与 DFT 三角分解
3.1 傅里叶变换基础理论
傅里叶变换由法国数学家 Jean Baptiste Joseph Fourier(1768--1830)提出,1807 年于法国科学院发表热传导相关论文,论文提出核心结论:任意连续周期信号均可由若干组不同参数的正弦基函数加权叠加构成。
从信号表征维度区分,信号存在时域、频域两类描述形式:时域波形表征瞬时幅值随时间的变化规律,频域谱线表征各频率分量的权重占比,两类描述具备严格数学对偶关系。
一段音频信号的时域波形示例:
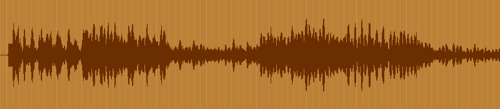
巴赫乐谱(频域特征描述):

依据信号时域连续性、周期性特征,傅里叶变换划分为四类标准形式。

四类信号对应变换域图谱:
四类信号对应变换域图谱:
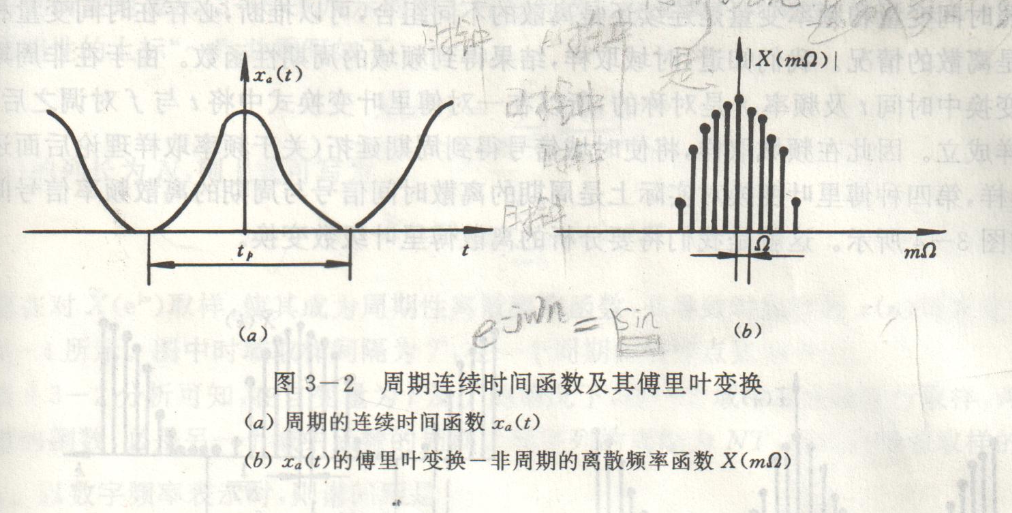
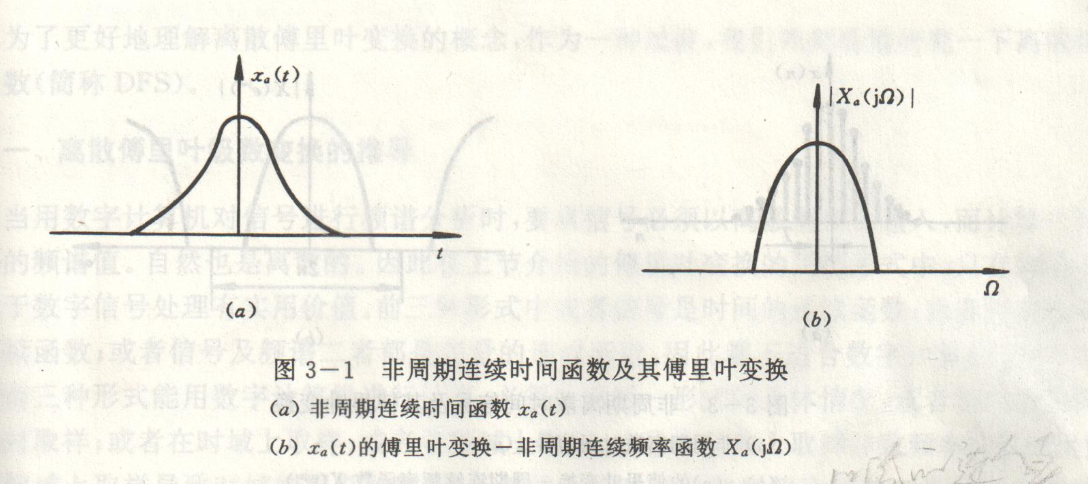
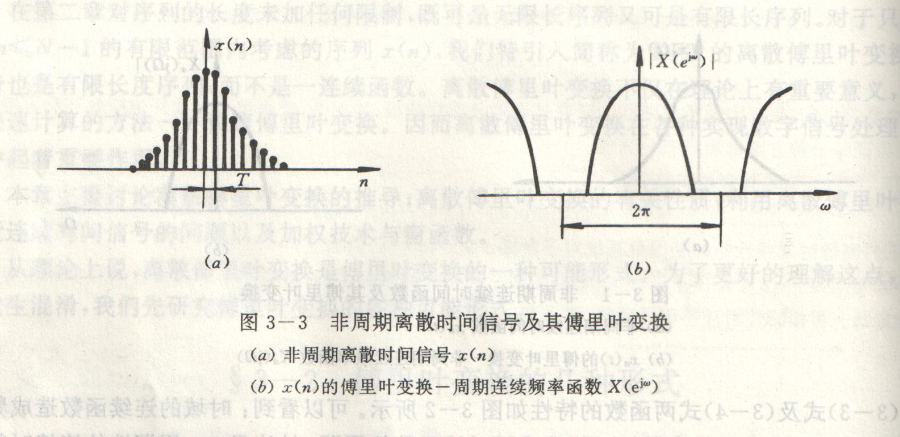
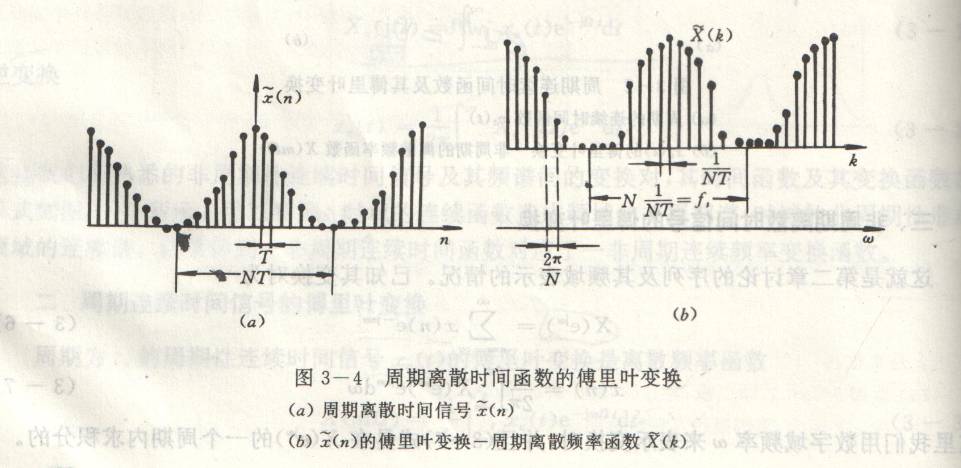
资料出处:王世一《数字信号处理》
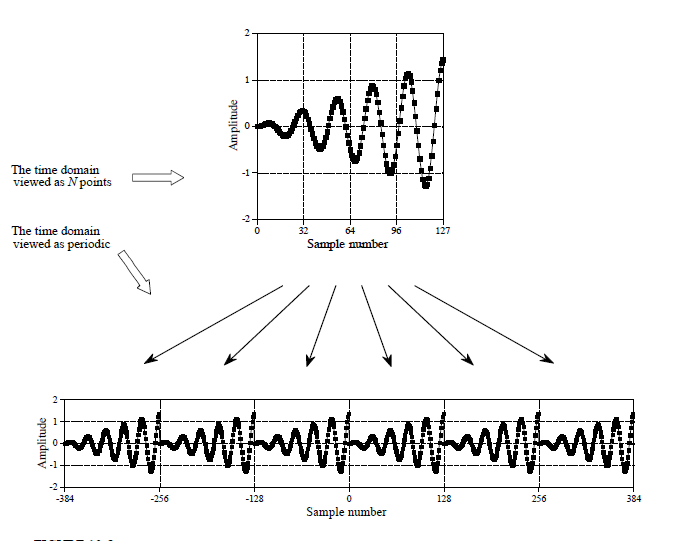
数字信号处理仅可处理离散序列,四类变换中仅离散周期序列适配离散傅里叶变换;工程实测信号多为有限长非周期离散序列,处理方案:对有限长序列周期延拓,构造虚拟周期序列后开展 DFT 运算。
周期延拓原理示意图:
3.2 DFT 公式物理释义与实序列 IDFT 三角分解
3.2.1 DFS/IDFT 三角分解数学表达式
离散傅里叶级数(DFS)三角展开为实值有限长离散序列的逆离散傅里叶变换(IDFT)三角分解式 ,依托实序列频谱共轭对称特性 X N − k = X k ‾ XN-k=\overline{Xk} XN−k=Xk,频域求和区间压缩至 k ∈ 0 , N / 2 k\in0,N/2 k∈0,N/2:
x i = ∑ k = 0 N / 2 R e { X ‾ k } cos ( 2 π k i N ) + ∑ k = 0 N / 2 I m { X ‾ k } sin ( 2 π k i N ) x\lefti\\right = \sum_{k=0}^{N/2} \mathrm{Re}\big\{\overline{X}k\big\}\cos\left(\frac{2\pi k i}{N}\right)+ \sum_{k=0}^{N/2} \mathrm{Im}\big\{\overline{X}k\big\}\sin\left(\frac{2\pi k i}{N}\right) xi=k=0∑N/2Re{Xk}cos(N2πki)+k=0∑N/2Im{Xk}sin(N2πki)
DFT 由连续周期信号傅里叶变换经时域抽样推导得到,上式由标准完整 IDFT 原式化简而来。
标准 IDFT 完整原式:
x i = 1 N ∑ k = 0 N − 1 X k e j 2 π k i N xi=\frac1N\sum_{k=0}^{N-1}Xk\mathrm{e}^{\mathrm{j}\frac{2\pi k i}{N}} xi=N1k=0∑N−1XkejN2πki
化简依据:欧拉公式 e j θ = cos θ + j sin θ \mathrm{e}^{\mathrm{j}\theta}=\cos\theta+\mathrm{j}\sin\theta ejθ=cosθ+jsinθ、实序列频谱共轭对称关系 X N − k = X k ‾ XN-k=\overline{Xk} XN−k=Xk。
3.2.2 公式参数定义
- x i xi xi:待变换离散时域序列,时域下标 i ∈ { 0 , 1 , ... , N − 1 } i \in \{0,1,\dots,N-1\} i∈{0,1,...,N−1};
- R e ⋅ \mathrm{Re}\\cdot Re⋅:复数取实部运算,原始频域下标 k ∈ { 0 , 1 , ... , N − 1 } k \in \{0,1,\dots,N-1\} k∈{0,1,...,N−1};
- cos ( ⋅ ) \cos(\cdot) cos(⋅):余弦基函数,与正弦基 sin ( ⋅ ) \sin(\cdot) sin(⋅) 共同构成离散正交分解基底。
3.2.3 DFT 物理含义与变换数学特性
由连续周期信号叠加定理推广至离散域:任意离散周期信号均可由若干组离散正弦基函数加权叠加构成。
傅里叶变换数学特性:
- 变换具备可逆性,有限能量时域/空域信号存在唯一频域映射,变换过程无信号信息损耗;
- 两信号时域内积等价于对应频域内积,可依托相关运算判定目标频率分量存在性;
- 时域收敛序列对应频域同步收敛。
信号相关运算示例:将待测序列与标准单频正弦序列逐点相乘后累加,累加均值表征两组信号相关度。
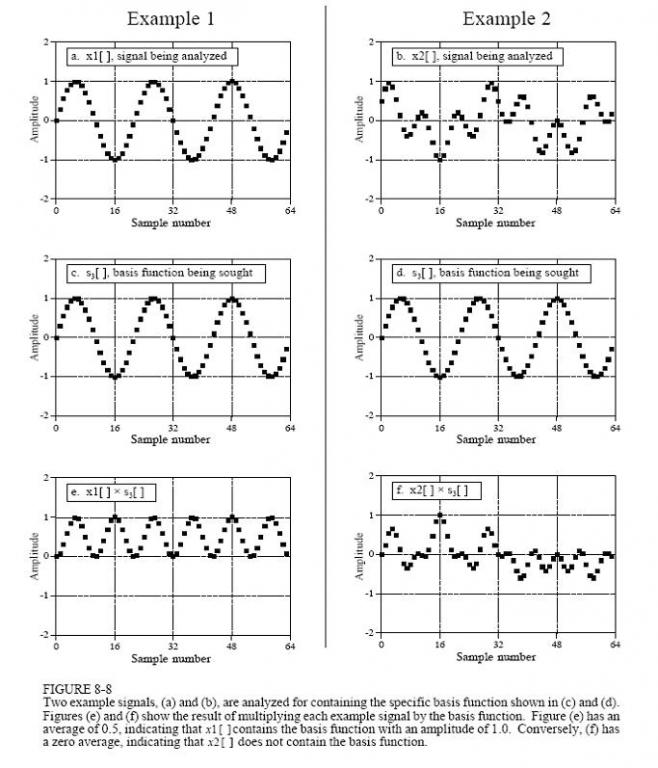
采样-FFT 幅值换算规则
设采样频率 F s F_\mathrm{s} Fs、单帧采样点数 N N N,FFT 输出为 N N N 点复数序列,频点计算公式:
F n = ( n − 1 ) ⋅ F s N F_n = \frac{(n-1)\cdot F_\mathrm{s}}{N} Fn=N(n−1)⋅Fs
频率分辨率: Δ F = F s N \Delta F = \dfrac{F_\mathrm{s}}{N} ΔF=NFs,分辨率与单帧采样时长互为倒数。
设频点 n n n 对应复数 Z n = a + j b Z_n = a+\mathrm{j}b Zn=a+jb,模值 A n = a 2 + b 2 A_n=\sqrt{a^2+b^2} An=a2+b2 、相位 φ n = a t a n 2 ( b , a ) \varphi_n=\mathrm{atan2}(b,a) φn=atan2(b,a):
- 直流分量( n = 1 n=1 n=1):原始直流幅值 A D C = A 1 N A_\mathrm{DC}= \dfrac{A_1}{N} ADC=NA1;
- 交流分量( 2 ≤ n ≤ N / 2 2\le n\le N/2 2≤n≤N/2):原始正弦幅值 A = 2 ⋅ A n N A = \dfrac{2\cdot A_n}{N} A=N2⋅An。
仿真算例:
原始信号 S ( t ) = 2 + 3 cos ( 2 π ⋅ 50 t − π 6 ) + 1.5 cos ( 2 π ⋅ 75 t + π 2 ) S(t)=2+3\cos\left(2\pi\cdot50t-\dfrac{\pi}{6}\right)+1.5\cos\left(2\pi\cdot75t+\dfrac{\pi}{2}\right) S(t)=2+3cos(2π⋅50t−6π)+1.5cos(2π⋅75t+2π), F s = 256 H z F_\mathrm{s}=256\ \mathrm{Hz} Fs=256 Hz、 N = 256 N=256 N=256;
频点 1 对应 0 H z 0\ \mathrm{Hz} 0 Hz、频点 51 对应 50 H z 50\ \mathrm{Hz} 50 Hz、频点 76 对应 75 H z 75\ \mathrm{Hz} 75 Hz。
FFT 幅值频谱:
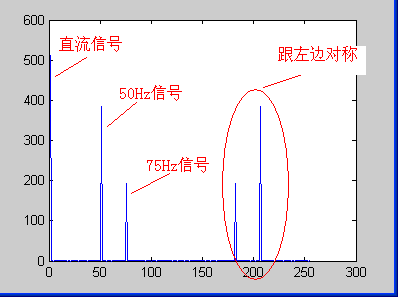
关键频点复数输出:
- 1 号频点: 512 + 0 j 512+0\mathrm{j} 512+0j, A D C = 512 / 256 = 2 A_\mathrm{DC}=512/256=2 ADC=512/256=2;
- 51 号频点: 332.55 − 192 j 332.55-192\mathrm{j} 332.55−192j, A n = 384 A_n=384 An=384, A = 2 × 384 / 256 = 3 A=2\times384/256=3 A=2×384/256=3;
- 76 号频点: 3.4315 × 10 − 12 + 192 j 3.4315\times10^{-12}+192\mathrm{j} 3.4315×10−12+192j, A n = 192 A_n=192 An=192, A = 2 × 192 / 256 = 1.5 A=2\times192/256=1.5 A=2×192/256=1.5。
DFT 物理含义:以 0 H z 、 1 H z ... F s / 2 H z 0\ \mathrm{Hz}、1\ \mathrm{Hz}\dots F_\mathrm{s}/2\ \mathrm{Hz} 0 Hz、1 Hz...Fs/2 Hz 为基准频率,用各组标准正弦基与输入序列做内积运算,内积数值表征对应频率分量在原始信号中的权重。
3.3 FFT 与 DFT 算法对比
FFT 依托 DFT 旋转因子 W N W_N WN 的周期性、对称性优化运算流程,为 DFT 的快速实现方案,未变更傅里叶变换理论体系。
N N N 点直接 DFT 运算复杂度 O ( N 2 ) \mathcal O(N^2) O(N2);基 2 时分 FFT 不断对半拆分运算序列,总运算复杂度降至 O ( N log 2 N ) \mathcal O(N\log_2 N) O(Nlog2N)。
例: N = 1024 N=1024 N=1024,直接 DFT 运算量级 1024 2 = 1048576 1024^2=1048576 10242=1048576;FFT 运算量级 1024 × log 2 1024 = 10240 1024\times \log_21024=10240 1024×log21024=10240,运算开销大幅缩减。
四、Xilinx FFT IP 核工程仿真
4.1 IP 核基础参数
运行环境同前文:Xilinx Spartan 6、ISE 12.2、FFT IP V7.1。
Xilinx FFT IP 支持 FFT/IFFT 复数、实数序列变换,提供三类硬件架构:
- 流水线 Streaming I/O:连续流式数据处理,输入、运算、输出三阶段并行;
- 基 4 Burst I/O:分载入-运算-导出三阶段,逻辑资源占用偏低、单帧转换耗时更长;
- 基 2 Burst I/O:全架构资源占用最低,工作时序与基 4 突发架构一致。
本文选用流水线 Streaming I/O架构做连续数据流测试,架构由多级基 2 蝶形运算单元串联构成,各级配置独立缓存。
4.2 IP 核端口定义
| 端口名 | 端口属性 | 功能说明 |
|---|---|---|
XN_RE/XN_IM |
输入 | 变换序列实部、虚部,二进制补码格式输入,位宽用户自定义 |
START |
输入 | 帧启动信号,高电平有效;单脉冲触发一帧 FFT,持续高电平实现连续帧运算 |
UNLOAD |
输入 | 突发架构专用结果导出触发,流水线架构端口悬空 |
NFFT |
输入 | 可动态配置变换点数配置端,仅动态配置模式启用 |
NFFT_WE |
输入 | NFFT端口写使能 |
FWD_INV |
输入 | 运算模式选择: 1 = F F T 1=\mathrm{FFT} 1=FFT, 0 = I F F T 0=\mathrm{IFFT} 0=IFFT,支持逐帧动态切换 |
FWD_INV_WE |
输入 | FWD_INV端口写使能 |
SCALE_SCH |
输入 | 分级移位压缩配置字,仅定点压缩架构生效,位宽 2 ⋅ ⌈ l o g 2 ( N ) / 2 ⌉ 2\cdot\lceil \mathrm{log}_2(N)/2\rceil 2⋅⌈log2(N)/2⌉(流水线) |
SCALE_SCH_WE |
输入 | SCALE_SCH配置字写使能 |
SCLR |
输入 | 可选异步清零 |
Reset |
输入 | 全局复位,高电平复位运算链路,片内帧缓存数据保留 |
CE |
输入 | 可选时钟使能 |
CLK |
输入 | 全局系统时钟 |
XK_RE/XK_IM |
输出 | 频域结果实部、虚部,补码输出;压缩有效时输出位宽=输入位宽,否则输出位宽=输入位宽 + l o g 2 N + 1 +\mathrm{log}_2N+1 +log2N+1 |
XN_INDEX |
输出 | 输入数据下标,位宽 l o g 2 N \mathrm{log}_2N log2N |
XK_INDEX |
输出 | 输出频点下标,位宽 l o g 2 N \mathrm{log}_2N log2N |
RFD |
输出 | 输入就绪标志,高电平时允许写入输入数据 |
BUSY |
输出 | 运算忙标志,FFT 运算周期持续高电平 |
DV |
输出 | 输出数据有效标志,高电平代表XK_RE/XK_IM输出有效 |
EDONE |
输出 | 完成预标志,DONE前一个时钟周期拉高 |
DONE |
输出 | 单帧运算完成标志,仅保持单个时钟周期高电平 |
BLK_EXP |
输出 | 块浮点架构专用块指数输出,流水线定点模式端口无效 |
OVFLO |
输出 | 溢出标志,单帧运算出现数据溢出时拉高,帧起始自动复位 |
工程实操优化:START端口固定接高电平,首帧加载作为初始化,自第二帧起进入正式运算,规避启动时序约束。
4.3 IP 核三种数据精度架构
- 全精度无压缩 :运算全程保留有效整数位,小数直接截断/舍入,输出位宽=输入位宽 + l o g 2 N + 1 +\mathrm{log}_2N+1 +log2N+1,资源开销最大;
- 块浮点型 :整帧共用同一压缩移位量,压缩值由
BLK_EXP对外输出,仅溢出预警触发移位; - 定点用户自定义压缩 :由
SCALE_SCH逐阶配置移位量,单阶移位可选 0 / 1 / 2 / 3 0/1/2/3 0/1/2/3(对应右移 0 / 1 / 2 / 3 b i t 0/1/2/3\ \mathrm{bit} 0/1/2/3 bit),可均衡资源占用与动态范围,为本设计选用架构。
定点压缩配置经验(防溢出)
- 基 4 突发 N = 1024 N=1024 N=1024: S C A L E _ S C H = 10 10 10 10 11 \mathtt{SCALE\_SCH=10\\ 10\\ 10\\ 10\\ 11} SCALE_SCH=10 10 10 10 11
- 基 2 突发 N = 1024 N=1024 N=1024: S C A L E _ S C H = 01 01 ⋯ 01 10 \mathtt{SCALE\_SCH=01\\ 01\\cdots01\\ 10} SCALE_SCH=01 01⋯01 10
- 流水线 N = 512 N=512 N=512: S C A L E _ S C H = 01 10 10 10 11 \mathtt{SCALE\_SCH=01\\ 10\\ 10\\ 10\\ 11} SCALE_SCH=01 10 10 10 11
- 流水线 N = 1024 N=1024 N=1024: S C A L E _ S C H = 10 10 10 10 11 \mathtt{SCALE\_SCH=10\\ 10\\ 10\\ 10\\ 11} SCALE_SCH=10 10 10 10 11
4.4 前期调试问题汇总
- 编码规范:
two's complement为二进制补码,非"2 的补码"; - 实数转复数输入:
AD实测数据接入XN_RE,XN_IM固定置 0 0 0; - 溢出调试:预留
OVFLO引脚观测电平,迭代修正SCALE_SCH配置字; - 输入时序:仅
RFD=1时,XN_RE/XN_IM写入生效。
4.5 仿真 1:N=16 点方波 FFT
IP 核配置参数
- 变换长度: T r a n s f o r m l e n g t h = 16 \mathrm{Transform\ length}=16 Transform length=16
- 架构:R-2 Burst IO
- 输入位宽: d a t a w i d t h = 16 \mathrm{datawidth}=16 datawidth=16,旋转因子位宽 P h a s e f a c t o r = 16 \mathrm{Phase\ factor}=16 Phase factor=16
- 运算模式:定点缩放 scaled、收敛舍入 convergent rounding
- 输出序:naturalorder,无循环前缀
- 存储:Block RAM
- 复数乘法器:3 multiplier structure
- 蝶形运算资源:CLB logic
Verilog 仿真源码
verilog
`timescale 1ns / 1ps
////////////////////////////////////////////////////////////////////////////////
//Company:
//Engineer:calm_yi
//Create Date: 09:47:47 04/24/2012
//Design Name: fft
//Module Name: C:/Users/PC/Desktop/FFT/fft/fftt.v
//Project Name: fft
//Target Device:
//Tool versions:
//Description:
//Verilog Test Fixture created by ISE for module: fft
//Dependencies:
//Revision:
//Revision 0.01 - File Created
//Additional Comments:
////////////////////////////////////////////////////////////////////////////////
module fftt;
// Inputs
reg start;
reg fwd_inv;
reg clk;
reg scale_sch_we;
reg fwd_inv_we;
reg [7:0] scale_sch;
wire rfd;
wire [3:0] xn_index;
reg [15:0] xn_re;
reg [15:0] xn_im;
// Outputs
wire done;
wire busy;
wire edone;
wire ovflo;
wire dv;
wire [3:0] xk_index;
wire [15:0] xk_im;
wire [15:0] xk_re;
// Instantiate the Unit Under Test (UUT)
fft uut (
.rfd(rfd),
.start(start),
.fwd_inv(fwd_inv),
.dv(dv),
.done(done),
.clk(clk),
.busy(busy),
.scale_sch_we(scale_sch_we),
.fwd_inv_we(fwd_inv_we),
.edone(edone),
.ovflo(ovflo),
.xn_re(xn_re),
.xk_im(xk_im),
.xn_index(xn_index),
.scale_sch(scale_sch),
.xk_re(xk_re),
.xn_im(xn_im),
.xk_index(xk_index)
);
initial begin
// Initialize Inputs
start = 1;
fwd_inv = 1;
clk = 0;
scale_sch_we =1;
scale_sch = 8'b01010101;
fwd_inv_we = 1;
xn_re = 0;
xn_im = 0;
#100;
end
always begin
#10 clk<= 1;
#10 clk<= 0;
end
reg[3:0]num;
always@(posedge clk)
begin
if(rfd)
begin
num<= num + 1'b1;
case(num)
4'd0: xn_re<= 10000;
4'd1:xn_re<= 10000;
4'd2:xn_re<= 10000;
4'd3:xn_re<= 10000;
4'd4:xn_re<= 10000;
4'd5:xn_re<= 10000;
4'd6:xn_re<= 10000;
4'd7:xn_re<= 10000;
4'd8:xn_re<= 0;
4'd9:xn_re<= 0;
4'd10:xn_re<= 0;
4'd11:xn_re<= 0;
4'd12:xn_re<= 0;
4'd13:xn_re<= 0;
4'd14:xn_re<= 0;
4'd15: xn_re<=10000;
default: ;
endcase
end
end
endmodule输入序列
XN_RE: 10000 , 10000 , 10000 , 10000 , 10000 , 10000 , 10000 , 10000 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 10000 10000,10000,10000,10000,10000,10000,10000,10000,0,0,0,0,0,0,0,10000 10000,10000,10000,10000,10000,10000,10000,10000,0,0,0,0,0,0,0,10000XN_IM:全 0 0 0,等效占空比 50 % 50\% 50%、幅值 10000 10000 10000 的方波。
输入时序波形:
FPGA 输出数据(DV=1有效)
| Num | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Re | 5000 | 625 | 0 | 625 | 0 | 625 | 0 | 625 | 0 | 625 | 0 | 625 | 0 | 625 | 0 | 625 |
| Im | 0 | -3142 | 0 | -936 | 0 | -418 | 0 | -124 | 0 | 124 | 0 | 418 | 0 | 936 | 0 | 3142 |
MATLAB 同参数仿真结果:
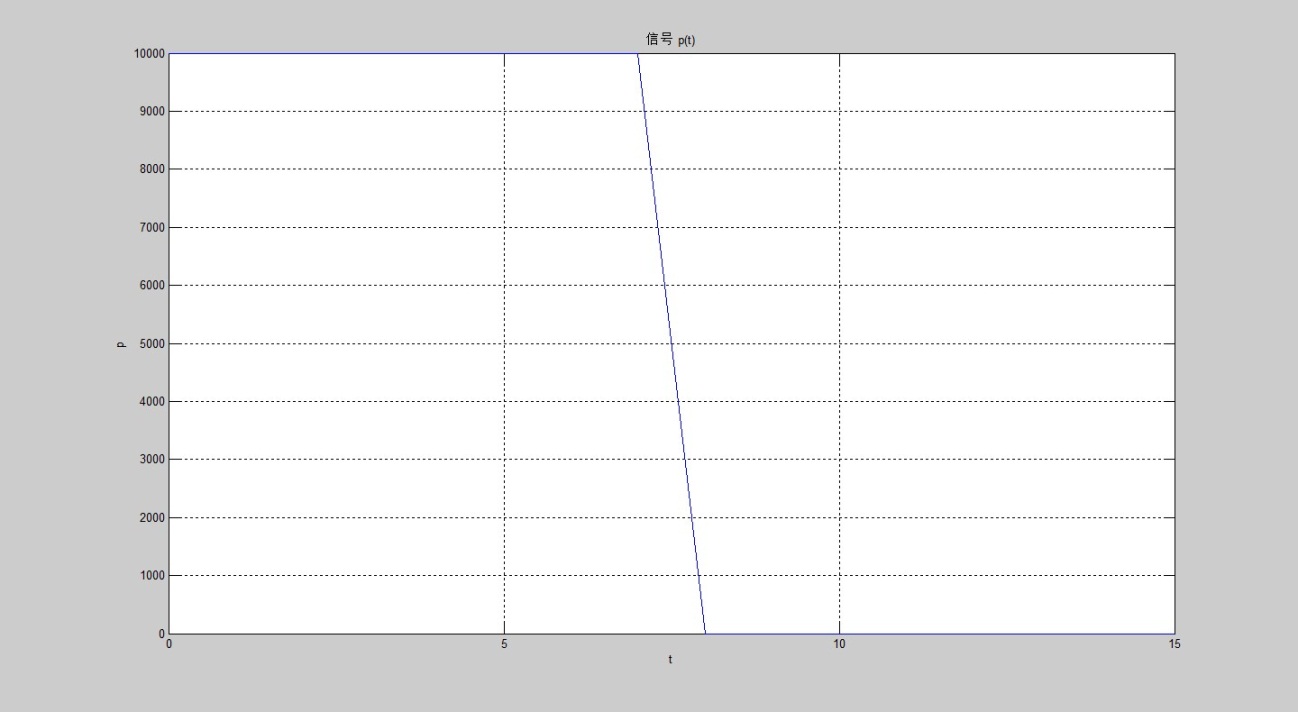
结果特征:MATLAB 输出幅值为 FPGA 定点结果的 2 2 2 倍,直流分量数值比例匹配,幅值系数差异待后续溯源。
4.6 仿真 2: N = 64 N=64 N=64 多频混合信号
- 配置: S C A L E _ S C H = 12 ′ b 000000010101 \mathtt{SCALE\SCH=12'b000000010101} SCALE_SCH=12′b000000010101; F s = 64 H z F\mathrm{s}=64\ \mathrm{Hz} Fs=64 Hz,采样时长 1 s 1\ \mathrm{s} 1 s;输入信号含 5 H z 、 18 H z 、 22 H z 5\ \mathrm{Hz}、18\ \mathrm{Hz}、22\ \mathrm{Hz} 5 Hz、18 Hz、22 Hz 频率分量。
原始输入波形:
采样细节:

初始配置输出频谱:
频点匹配结论: 5 H z 、 18 H z 、 22 H z 5\ \mathrm{Hz}、18\ \mathrm{Hz}、22\ \mathrm{Hz} 5 Hz、18 Hz、22 Hz 对应频点出现峰值,频率分量匹配,但幅值偏离理论值,偏差由缩放配置参数导致。
修正配置: S C A L E _ S C H = 12 ′ b 010101010101 \mathtt{SCALE\_SCH=12'b010101010101} SCALE_SCH=12′b010101010101,修正后频谱:
MATLAB 对标频谱:
后续工作:定量建立SCALE_SCH移位配置与输出幅值的映射关系,完善定点缩放系数整定规范。
Vivado Xilinx FFT IP 核 v9.0 使用详解(附仿真实例)
傅外叶 2021-01-16 00:34:16
一、傅里叶变换与 FFT
时域信号经 FFT 运算可完成时域至频域的映射变换,针对时域难以解析的信号,可在频域完成参数处理与特征提取。本节定义两项基础设计参数:采样频率、FFT 变换采样点数。
- 依据奈奎斯特采样定理,采样频率取值需大于被测信号最高频率的 2 2 2 倍;
- FFT 采样点数表征频域维度下的离散采样总量。
设采样频率为 F s F_\mathrm{s} Fs,FFT 采样点数为 N N N,频域分辨率满足关系式:
Δ f = F s N \Delta f = \frac{F_\mathrm{s}}{N} Δf=NFs
N N N 数值增大时频域分辨率提升, N N N 数值减小则频域分辨率下降。
二、Xilinx FFT v9.0 IP 核参数说明
1. 输入与输出端口定义

端口排布遵循左入右出规则,关键端口定义如下:
S_AXIS_DATA:时域数据输入端口,待变换序列经由该端口送入 IP 核;S_AXIS_CONFIG:配置参数输入端口,端口内数据包含变换方向(FFT/IFFT)、缩放系数、变换点数等配置信息;M_AXIS_DATA:频域变换结果输出端口。
端口完整电气与时序规范参照器件手册 pg109。
2. Vivado 环境下 IP 核可视化配置
实验所用 Vivado 软件版本:2018.04
在 IP 库检索并选中 FFT IP 核,双击唤起配置弹窗:
Implementation 配置分页:
第三项配置分页:

全部配置项设定完毕后,切换至左侧 implementation detail 分页查看端口位宽定义:
S_AXIS_DATA_TDATA:总线位宽 32 b i t 32\ \mathrm{bit} 32 bit,数据域划分与标注存在文档歧义,手册标注低 16 b i t 16\ \mathrm{bit} 16 bit 为实部、高 16 b i t 16\ \mathrm{bit} 16 bit 为虚部;工程实测为高 16 b i t 16\ \mathrm{bit} 16 bit 承载实部、低 16 b i t 16\ \mathrm{bit} 16 bit 承载虚部。S_AXIS_CONFIG_TDATA:最低有效位(bit0)控制变换模式, bit0 = 1 \text{bit0}=1 bit0=1 执行 FFT 运算, bit0 = 0 \text{bit0}=0 bit0=0 执行 IFFT 运算;配置总线位宽扩展至 8 b i t 8\ \mathrm{bit} 8 bit,剩余高位统一补零。M_AXIS_DATA_TDATA:输出总线位宽 48 b i t 48\ \mathrm{bit} 48 bit,低 24 b i t 24\ \mathrm{bit} 24 bit 存储变换结果实部,高 24 b i t 24\ \mathrm{bit} 24 bit 存储变换结果虚部。
3. 软件仿真流程
完成 IP 核配置后编写 TestBench 仿真文件,采用 MATLAB 生成时域采样序列。待测连续信号表达式:
F ( t ) = 200 + 100 cos ( 2 π ⋅ 10 ⋅ t ) + 100 cos ( 2 π ⋅ 30 ⋅ t ) F(t)=200+100\cos\left(2\pi\cdot10\cdot t\right)+100\cos\left(2\pi\cdot30\cdot t\right) F(t)=200+100cos(2π⋅10⋅t)+100cos(2π⋅30⋅t)
设定采样参数:采样频率 F s = 100 H z F_\mathrm{s}=100\ \mathrm{Hz} Fs=100 Hz,FFT 变换点数 N = 128 N=128 N=128;采样数据量化为 16 16 16 位二进制格式,导出至文本文件。
MATLAB 数据源生成代码
matlab
clear;
Fs = 100;
N = 128;
n = 1:N;
t = n/Fs;
f1 = 10;
f2 = 30;
s1 = cos(2*pi*f1*t);
s2 = cos(2*pi*f2*t);
signalN = 2 + s1 + s2;
data_before_fft = 100 * signalN;
fp = fopen('D:\Zynq_Core\data_before_fft.txt','w');
for i = 1:N
if(data_before_fft(i)>=0)
temp = dec2bin(data_before_fft(i),16);
else
temp = dec2bin(data_before_fft(i)+2^16+1,16);
end
for j = 1:16
fprintf(fp,'%s',temp(j));
end
fprintf(fp,'\r\n');
end
fclose(fp);
y = fft(data_before_fft,N);
y = abs(y);
f = n*Fs/N;
plot(f,y);代码运行后在指定路径生成采样数据文本:

IP 输入位宽配置为 16 b i t 16\ \mathrm{bit} 16 bit,采样序列总长度为 N = 128 N=128 N=128。
在 Vivado 工程内新增仿真文件:
Verilog TestBench 仿真代码
verilog
`timescale 1ns / 1ps
module FFT_test2();
reg clk;
reg rst_n;
reg signed [15:0] Time_data_I[127:0];
reg data_finish_flag;
wire fft_s_config_tready;
reg signed [31:0] fft_s_data_tdata;
reg fft_s_data_tvalid;
wire fft_s_data_tready;
reg fft_s_data_tlast;
wire signed [47:0] fft_m_data_tdata;
wire signed [7:0] fft_m_data_tuser;
wire fft_m_data_tvalid;
reg fft_m_data_tready;
wire fft_m_data_tlast;
wire fft_event_frame_started;
wire fft_event_tlast_unexpected;
wire fft_event_tlast_missing;
wire fft_event_status_channel_halt;
wire fft_event_data_in_channel_halt;
wire fft_event_data_out_channel_halt;
reg [7:0] count;
reg signed [23:0] fft_i_out;
reg signed [23:0] fft_q_out;
reg signed [47:0] fft_abs;
initial begin
clk = 1'b1;
rst_n = 1'b0;
fft_m_data_tready = 1'b1;
$readmemb("D:/Zynq_Core/data_before_fft.txt",Time_data_I);
end
always #5 clk = ~clk;
always @ (posedge clk or negedge rst_n) begin
if(!rst_n) begin
fft_s_data_tvalid <= 1'b0;
fft_s_data_tdata <= 32'd0;
fft_s_data_tlast <= 1'b0;
data_finish_flag <= 1'b0;
count <= 8'd0;
rst_n = 1'b1;
end
else if (fft_s_data_tready) begin
if(count == 8'd127) begin
fft_s_data_tvalid <= 1'b1;
fft_s_data_tlast <= 1'b1;
fft_s_data_tdata <= {Time_data_I[count],16'd0};
count <= 8'd0;
data_finish_flag <= 1'b1;
end
else begin
fft_s_data_tvalid <= 1'b1;
fft_s_data_tlast <= 1'b0;
fft_s_data_tdata <= {Time_data_I[count],16'd0};
count <= count + 1'b1;
end
end
else begin
fft_s_data_tvalid <= 1'b0;
fft_s_data_tlast <= 1'b0;
fft_s_data_tdata <= fft_s_data_tdata;
end
end
always @ (posedge clk) begin
if(fft_m_data_tvalid) begin
fft_i_out <= fft_m_data_tdata[23:0];
fft_q_out <= fft_m_data_tdata[47:24];
end
end
always @ (posedge clk) begin
fft_abs <= $signed(fft_i_out)* $signed(fft_i_out)+ $signed(fft_q_out)* $signed(fft_q_out);
end
xfft_0 u_fft(
.aclk(clk),
.aresetn(rst_n),
.s_axis_config_tdata(8'd1),
.s_axis_config_tvalid(1'b1),
.s_axis_config_tready(fft_s_config_tready),
.s_axis_data_tdata(fft_s_data_tdata),
.s_axis_data_tvalid(fft_s_data_tvalid),
.s_axis_data_tready(fft_s_data_tready),
.s_axis_data_tlast(fft_s_data_tlast),
.m_axis_data_tdata(fft_m_data_tdata),
.m_axis_data_tuser(fft_m_data_tuser),
.m_axis_data_tvalid(fft_m_data_tvalid),
.m_axis_data_tready(fft_m_data_tready),
.m_axis_data_tlast(fft_m_data_tlast),
.event_frame_started(fft_event_frame_started),
.event_tlast_unexpected(fft_event_tlast_unexpected),
.event_tlast_missing(fft_event_tlast_missing),
.event_status_channel_halt(fft_event_status_channel_halt),
.event_data_in_channel_halt(fft_event_data_in_channel_halt),
.event_data_out_channel_halt(fft_event_data_out_channel_halt)
);
endmodule仿真配置为固定正向 FFT 模式,s_axis_config_tdata 常量赋值 1。
数据读取函数区分:$readmemb() 读取二进制文本,$readmemh() 读取十六进制文本,二者不可混用。
4. 仿真结果分析
仿真时序波形:
数据传输逻辑:
- 判定
fft_s_data_tready电平状态,高电平代表 IP 核处于数据接收就绪状态;该信号有效后拉高fft_s_data_tvalid,启动数据写入流程,同步开启计数器count。 fft_s_data_tvalid有效周期内,读取外部文本存储的采样数据,低位16 bit补零后组装为32 bit总线数据送入fft_s_data_tdata。count计数值到达127(末位采样点),拉高fft_s_data_tlast,表征单帧时域数据输入完毕。
单帧数据写入完成后,fft_s_data_tready 电平拉低,IP 核进入运算阻塞状态,暂停新数据写入:
经过固定运算延时后,fft_m_data_tvalid 置高,fft_m_data_tdata 输出 128 点频域变换结果;fft_i_out、fft_q_out 分别锁存输出实部与虚部。IP 输出数据同 MATLAB 浮点运算结果比对,实部吻合度较高,虚部存在小幅数值偏差。
频点换算公式:
f i d x = i d x ⋅ F s N f_\mathrm{idx}=\frac{\mathrm{idx}\cdot F_\mathrm{s}}{N} fidx=Nidx⋅Fs
仿真波形在索引 0、14、34 位置出现幅值峰值,对应频点 0 Hz、10 Hz、30 Hz,与原始信号频率分量一一匹配,IP 运算结果有效。
全帧频域数据输出结束时 fft_m_data_tlast 拉高,经过短时空闲周期后 fft_s_data_tready 恢复高电平,IP 核可接收下一帧时域数据。
2021/03/23 补充更新
工程运行出现全不定态(XXXX)的诱因:MATLAB 生成文件路径与 TestBench 内 $readmemb 文件路径不一致,仿真无法读取有效采样数据,修改路径参数即可完成数据载入。
基于 Vivado 实现 FFT/IFFT 级联变换
可乐乐 yy 2021-11-23 17:19:53
前言
依托 Vivado 2018.3 \boldsymbol{2018.3} 2018.3 完成 DDS、FFT、IFFT 三类 IP 核级联设计,DDS 生成正交时域序列送入 FFT 模块,FFT 输出频域数据接入 IFFT 模块完成逆变换复原原始时域波形。系统架构框图如下:

一、工程搭建流程
1. 新建工程
打开 Vivado 软件主界面:
选择 Open\ Project\rightarrow Next:

填写工程名称与本地存储路径,点击 Next:

器件选型:xc7z020-1clg400c,本设计仅做功能仿真,无硬件上板调试:

参数汇总页点击 Finish 完成工程创建:

工程主界面:
2. DDS IP 配置(生成 10 M H z 10\ \mathrm{MHz} 10 MHz 正弦序列)
打开 IP Catalog,检索关键词 dds 并双击进入配置页面:
逐项配置参数:



参数确认后点击 OK。
3. FFT IP 配置
检索 FFT,路径:Digital Signal Processing→Transforms→FFTs→Fast Fourier Transform,双击打开配置界面:

配置参数:

配置完成后点击 OK。
二、Verilog 源码编写
1. 顶层设计文件 fft.v
新增设计源码:Add Sources→Add or create design sources→Create File,文件名 fft。




参考 IP 生成的 .veo 例化模板编写顶层代码:
verilog
`timescale 1ns / 1ps
module fft(
input aclk,
input aresetn,
output [7:0] fft_real,
output [7:0] fft_imag,
output [7:0] ifft_real,
output [7:0] ifft_imag
);
wire [15:0] dds_m_data_tdata;
wire fft_s_data_tready;
wire dds_m_data_tvalid;
wire dds_m_data_tlast;
dds_compiler_0 dds_MHz (
.aclk(aclk),
.aresetn(aresetn),
.m_axis_data_tdata(dds_m_data_tdata),
.m_axis_data_tready(fft_s_data_tready),
.m_axis_data_tvalid(dds_m_data_tvalid)
);
wire [7:0] fft_s_config_tdata;
wire fft_s_config_tready;
wire fft_s_config_tvalid;
wire [7:0] fft_m_status_tdata;
wire fft_m_status_tready;
wire fft_m_status_tvalid;
wire [15:0] fft_m_data_tdata;
wire fft_m_data_tlast;
wire ifft_s_data_tready;
wire [23:0] fft_m_data_tuser;
wire fft_m_data_tvalid;
wire fft_event_frame_started;
wire fft_event_tlast_unexpected;
wire fft_event_tlast_missing;
wire fft_event_status_channel_halt;
wire fft_event_data_in_channel_halt;
wire fft_event_data_out_channel_halt;
wire [11:0] xk_index;
assign xk_index = fft_m_data_tuser[11:0];
assign fft_s_config_tdata = 8'd1;
assign fft_s_config_tvalid = 1'd1;
xfft_0 usr_fft(
.aclk(aclk),
.aresetn(aresetn),
.s_axis_data_tdata(dds_m_data_tdata),
.s_axis_data_tlast(dds_m_data_tlast),
.s_axis_data_tready(fft_s_data_tready),
.s_axis_data_tvalid(dds_m_data_tvalid),
.s_axis_config_tdata(fft_s_config_tdata),
.s_axis_config_tready(fft_s_config_tready),
.s_axis_config_tvalid(fft_s_config_tvalid),
.m_axis_status_tdata(fft_m_status_tdata),
.m_axis_status_tready(fft_m_status_tready),
.m_axis_status_tvalid(fft_m_status_tvalid),
.m_axis_data_tdata(fft_m_data_tdata),
.m_axis_data_tlast(fft_m_data_tlast),
.m_axis_data_tready(ifft_s_data_tready),
.m_axis_data_tuser(fft_m_data_tuser),
.m_axis_data_tvalid(fft_m_data_tvalid),
.event_frame_started(fft_event_frame_started),
.event_tlast_unexpected(fft_event_tlast_unexpected),
.event_tlast_missing(fft_event_tlast_missing),
.event_status_channel_halt(fft_event_status_channel_halt),
.event_data_in_channel_halt(fft_event_data_in_channel_halt),
.event_data_out_channel_halt(fft_event_data_out_channel_halt)
);
wire [7:0] ifft_s_config_tdata;
wire ifft_s_config_tready;
wire ifft_s_config_tvalid;
wire [7:0] ifft_m_status_tdata;
wire ifft_m_status_tready;
wire ifft_m_status_tvalid;
wire [15:0] ifft_m_data_tdata;
wire ifft_m_data_tlast;
wire ifft_m_data_tready;
wire [23:0] ifft_m_data_tuser;
wire ifft_m_data_tvalid;
wire ifft_event_frame_started;
wire ifft_event_tlast_unexpected;
wire ifft_event_tlast_missing;
wire ifft_event_status_channel_halt;
wire ifft_event_data_in_channel_halt;
wire ifft_event_data_out_channel_halt;
wire [11:0] ixk_index;
assign ixk_index = ifft_m_data_tuser[11:0];
assign ifft_s_config_tdata = 8'd0;
assign ifft_s_config_tvalid = 1'd1;
assign ifft_m_data_tready = 1'd1;
xfft_0 usr_ifft(
.aclk(aclk),
.aresetn(aresetn),
.s_axis_data_tdata(fft_m_data_tdata),
.s_axis_data_tlast(fft_m_data_tlast),
.s_axis_data_tready(ifft_s_data_tready),
.s_axis_data_tvalid(fft_m_data_tvalid),
.s_axis_config_tdata(ifft_s_config_tdata),
.s_axis_config_tready(ifft_s_config_tready),
.s_axis_config_tvalid(ifft_s_config_tvalid),
.m_axis_status_tdata(ifft_m_status_tdata),
.m_axis_status_tready(ifft_m_status_tready),
.m_axis_status_tvalid(ifft_m_status_tvalid),
.m_axis_data_tdata(ifft_m_data_tdata),
.m_axis_data_tlast(ifft_m_data_tlast),
.m_axis_data_tready(ifft_m_data_tready),
.m_axis_data_tuser(ifft_m_data_tuser),
.m_axis_data_tvalid(ifft_m_data_tvalid),
.event_frame_started(ifft_event_frame_started),
.event_tlast_unexpected(ifft_event_tlast_unexpected),
.event_tlast_missing(ifft_event_tlast_missing),
.event_status_channel_halt(ifft_event_status_channel_halt),
.event_data_in_channel_halt(ifft_event_data_in_channel_halt),
.event_data_out_channel_halt(ifft_event_data_out_channel_halt)
);
assign fft_real = fft_m_data_tdata[7:0];
assign fft_imag = fft_m_data_tdata[15:8];
assign ifft_real = ifft_m_data_tdata[7:0];
assign ifft_imag = ifft_m_data_tdata[15:8];
endmodule2. 仿真文件 fft_tb.v
新增仿真源文件:Add\ or\ create\ simulation\ sources

verilog
`timescale 1ns / 1ps
module fft_tb;
reg aclk,aresetn;
wire [7:0] fft_real,fft_imag;
wire [7:0] ifft_real,ifft_imag;
fft fft_test(
.aclk(aclk),
.aresetn(aresetn),
.fft_real(fft_real),
.fft_imag(fft_imag),
.ifft_real(ifft_real),
.ifft_imag(ifft_imag)
);
initial begin
aclk = 0;
aresetn = 0;
#30 aresetn = 1;
end
always #5 aclk=~aclk;
endmodule三、仿真运行与结果解析
1. 仿真参数配置
在仿真设置页修改仿真时长:SIMULATION→Simulation Settings
仿真总时长设定为 300 μ s 300\ \mu\mathrm{s} 300 μs:
启动行为级仿真:Run Simulation→Run Behavioral Simulation

2. 波形显示配置
展开例化模块 fft_test,将内部信号添加至波形窗口:
对 dds_m_data_tdata、fft_m_data_tdata、ifft_m_data_tdata 配置波形属性:
Waveform Style→Analog(模拟波形)Radix→Signed decimal(有符号十进制)

3. 结果分析
系统时钟周期 10 n s 10\ \mathrm{ns} 10 ns,采样频率 F s = 100 M H z F_\mathrm{s}=100\ \mathrm{MHz} Fs=100 MHz,DDS 输出正弦波周期 100 n s 100\ \mathrm{ns} 100 ns,对应频率 10 M H z 10\ \mathrm{MHz} 10 MHz;复位信号保持至少两个时钟周期低电平。
FFT 频域峰值对应索引为 409 409 409,FFT 变换点数 N = 4096 N=4096 N=4096,频点计算公式:
f = i d x ⋅ F s N = 409 × 100 × 10 6 4096 ≈ 9.985 × 10 6 H z ≈ 10 M H z f=\frac{\mathrm{idx}\cdot F_\mathrm{s}}{N}=\frac{409\times100\times10^6}{4096}\approx9.985\times10^6\ \mathrm{Hz}\approx10\ \mathrm{MHz} f=Nidx⋅Fs=4096409×100×106≈9.985×106 Hz≈10 MHz

IFFT 输出波形周期 100 n s 100\ \mathrm{ns} 100 ns,复原原始 10 M H z 10\ \mathrm{MHz} 10 MHz 正弦信号,级联链路变换有效。
一文快速掌握 Vivado 的 FFT IP
FPGA 入门到精通 2025-02-24 20:20:44
FFT 全称快速傅里叶变换,实现时域至频域的快速映射,相较标准 DFT 具备更低运算复杂度,广泛应用于无线通信、音频处理、图像信号处理领域。全定制 Verilog 蝶形运算开发周期长、参数适配灵活性受限,工程设计优先选用 Xilinx 原厂 FFT IP,下文梳理配置参数与接口规范。
一、VIVADO FFT IP 核基础介绍
Vivado 内置 FFT IP 可配置正向 FFT 与反向 IFFT,支持多架构与数值格式,适配实时数据流处理系统。
1. 功能与特性
- 变换模式:软件动态切换 FFT / IFFT;
- 变换点数:基 2 2 2 结构点数满足 N = 2 k N=2^k N=2k,数值区间 8 ≤ N ≤ 65536 8\le N \le 65536 8≤N≤65536,支持混合基架构;
- 数值格式:定点格式资源开销低;块浮点格式动态调整小数位,兼顾运算精度与硬件资源;
- 硬件架构
- Pipelined Streaming I/O:流水线流式架构,数据吞吐速率高,适配连续数据流;
- Radix-4 Burst I/O:基 4 4 4 突发架构,单帧运算效率高,运算延时提升;
- Radix-2 Burst I/O:基 2 2 2 突发架构,硬件资源占用量更低;
- 运行参数:支持运行时动态修改变换长度、运算方向;内置多级缩放配置,抑制定点运算数据溢出。
2. 关键配置参数
- 变换长度 N N N:单帧 FFT/IFFT 采样总量;
- 输入输出位宽:定点数据量化位数;
- 旋转因子位宽:决定蝶形运算系数精度,常规与输入位宽保持一致;
- 时钟与吞吐:依托架构选型优化工作频率与数据吞吐指标;
- 存储资源:中间缓存选用 Block RAM 或分布式 RAM。
3. 接口定义

AXI4-Stream 接口定义
IP 采用 AXI4-Stream 标准总线,接口划分如下:
- 全局控制
aclk:全局同步时钟;aclken:可选时钟使能引脚;aresetn:低电平同步复位,有效电平需维持不少于两个时钟周期;
- 配置总线
S_AXIS_CONFIGs_axis_config_tdata:配置数据, b i t 0 = 1 \mathrm{bit0}=1 bit0=1 执行 FFT, b i t 0 = 0 \mathrm{bit0}=0 bit0=0 执行 IFFT;s_axis_config_tvalid:配置数据有效标志,工程常设为逻辑 1 1 1;s_axis_config_tready:IP 配置接收就绪标志;
- 输入数据总线
S_AXIS_DATAs_axis_data_tdata:时域复数据, 31 : 16 31:16 31:16 虚部、 15 : 0 15:0 15:0 实部;s_axis_data_tvalid:输入数据有效;s_axis_data_tready:IP 时域数据接收就绪;s_axis_data_tlast:单帧时域数据结束标志;
- 输出数据总线
M_AXIS_DATAm_axis_data_tdata:频域复数据, 47 : 24 47:24 47:24 虚部、 23 : 0 23:0 23:0 实部;m_axis_data_tvalid:输出频域数据有效;m_axis_data_tuser:频点索引 i d x \mathrm{idx} idx,对应频率 f = i d x ⋅ F s N \displaystyle f=\frac{\mathrm{idx}\cdot F_\mathrm{s}}{N} f=Nidx⋅Fs;m_axis_data_tready:下游模块数据接收就绪。
二、IP 可视化配置步骤
1. 打开配置入口
新建工程后打开 I P C a t a l o g \boldsymbol{IP\ Catalog} IP Catalog,检索 F F T \boldsymbol{FFT} FFT 并双击启动配置:
2. Configuration 配置页
左侧分页:IP 引脚示意图、资源占用(Implementation Details)、运算延时(Latency);右侧三项配置标签:Configuration、Implementation、Detailed Implementation。
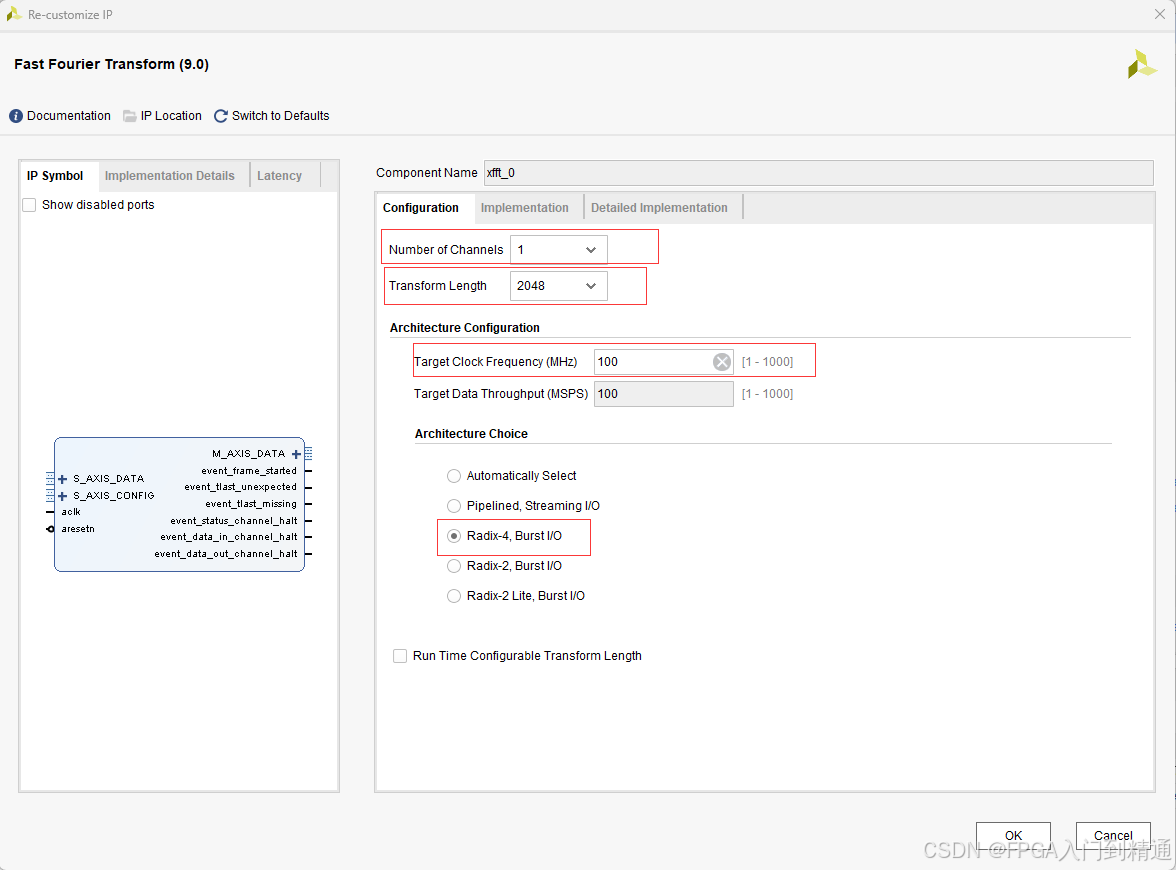
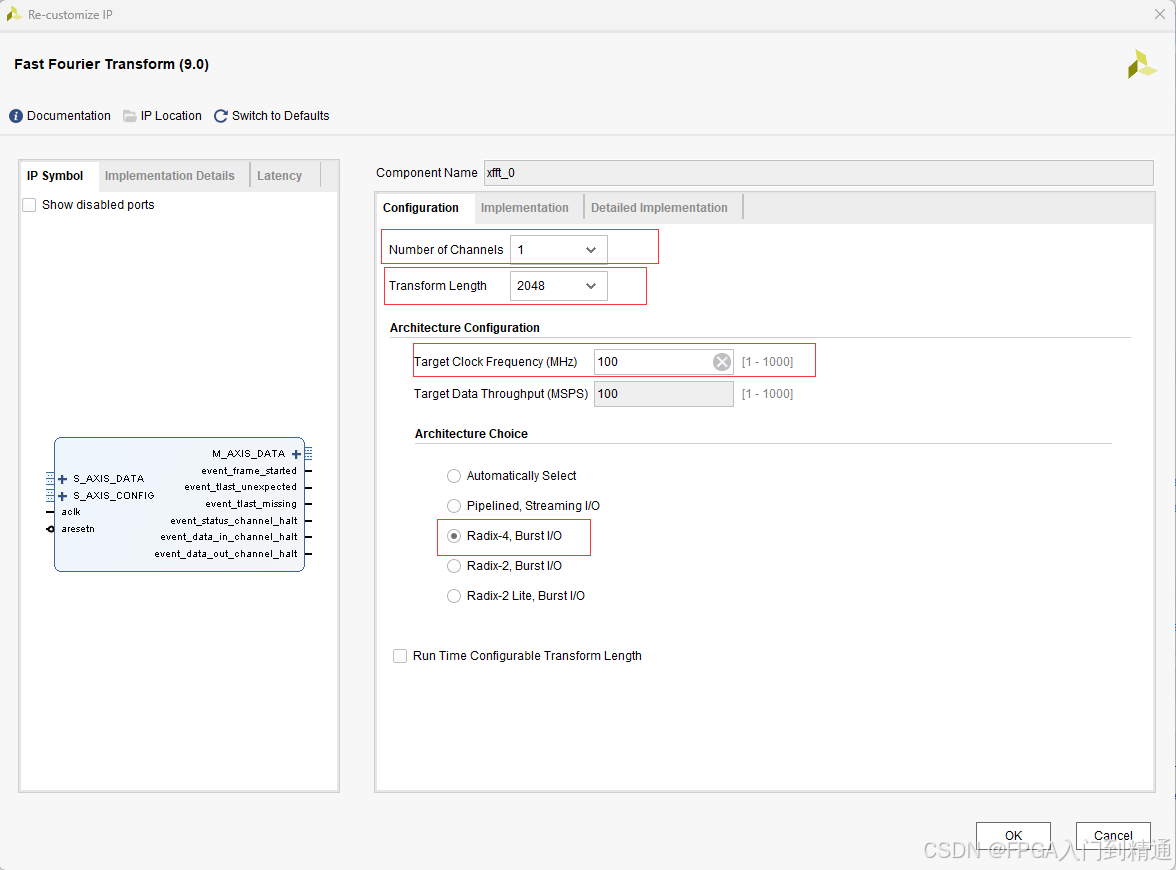
- Number of Channels:通道数量,单通道设计取值 1 1 1;
- Transform Length:固定变换点数设为 1024 1024 1024,取消运行时可变长度选项;
- Target Clock Frequency:目标时钟 250 M H z 250\ \mathrm{MHz} 250 MHz;
- Target Data Throughput:目标吞吐参数 50 50 50;
- Architecture Choice:架构选型 R a d i x − 2 , B u r s t I / O \boldsymbol{Radix-2,\ Burst\ I/O} Radix−2, Burst I/O。
3. Implementation 配置页
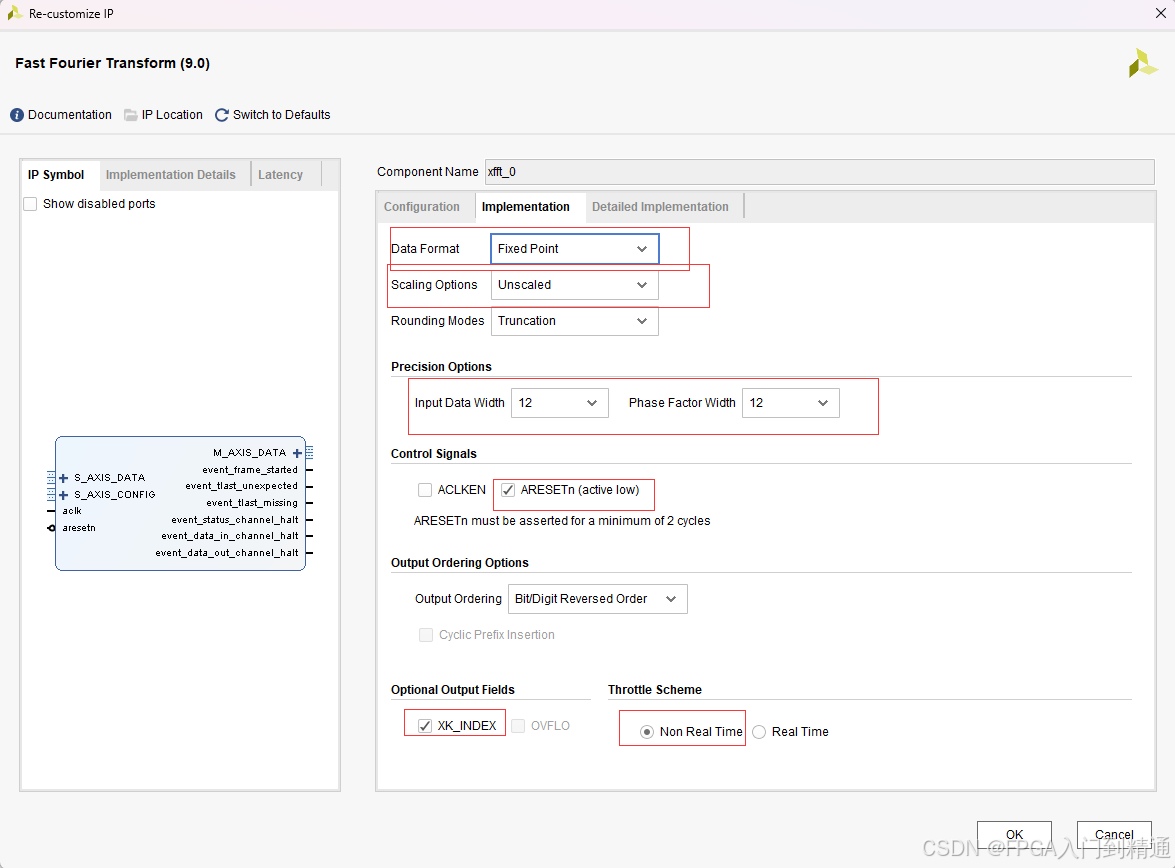
IP 参数配置项
- Data Format:Fixed Point(定点格式);
- Scaling Options
Scaled:分级缩放,抑制定点溢出;Unscaled:无缩放,输出位宽显著增大;Block Floating-Point:块浮点,输入输出位宽统一;
- Rounding Modes :
Truncated直接截断 /Convergent rounding收敛舍入; - Precision Options :输入位宽、旋转因子位宽独立配置( 8 ∼ 34 b i t 8\sim34\ \mathrm{bit} 8∼34 bit);
- Control Signals :勾选
aresetn同步复位引脚; - Output Ordering :
Natural Order(自然序)/Bit Reversed Order(位逆序); - Optional Output Fields :开启
XK_INDEX索引输出、OVFLO溢出标志; - Throttle Schemes :
Real Time/Not Real Time工作模式。
4. Detailed Implementation 配置页
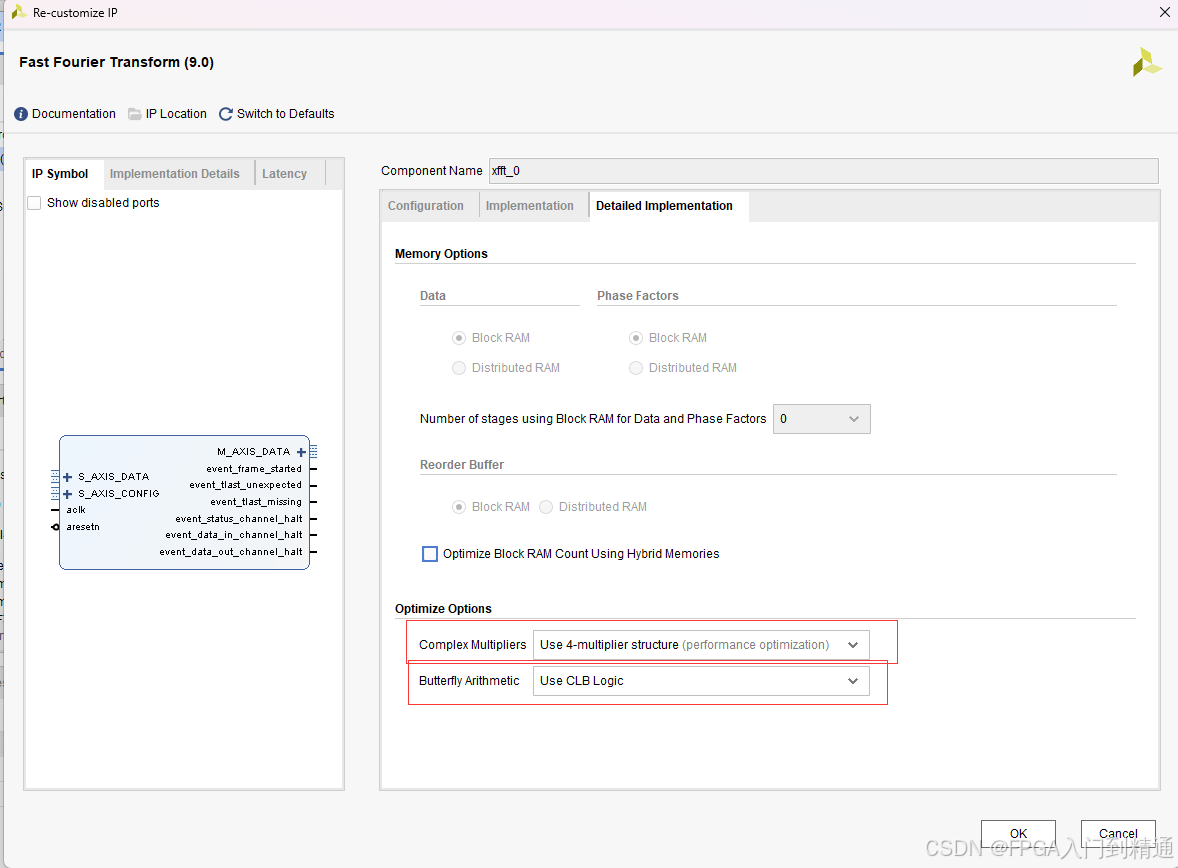
- Memory Options:缓存资源指定 Block RAM / Distributed RAM;
- Complex Multipliers
- Use CLB logic:组合逻辑实现复数乘法,节省 DSP;
- 3-multiplier:资源优化型复数乘法架构;
- 4-multiplier:性能优化型复数乘法架构;
- Butterfly Arithmetic:蝶形运算选用 CLB 逻辑或 XtremeDSP Slice。
5. 资源与延时查看
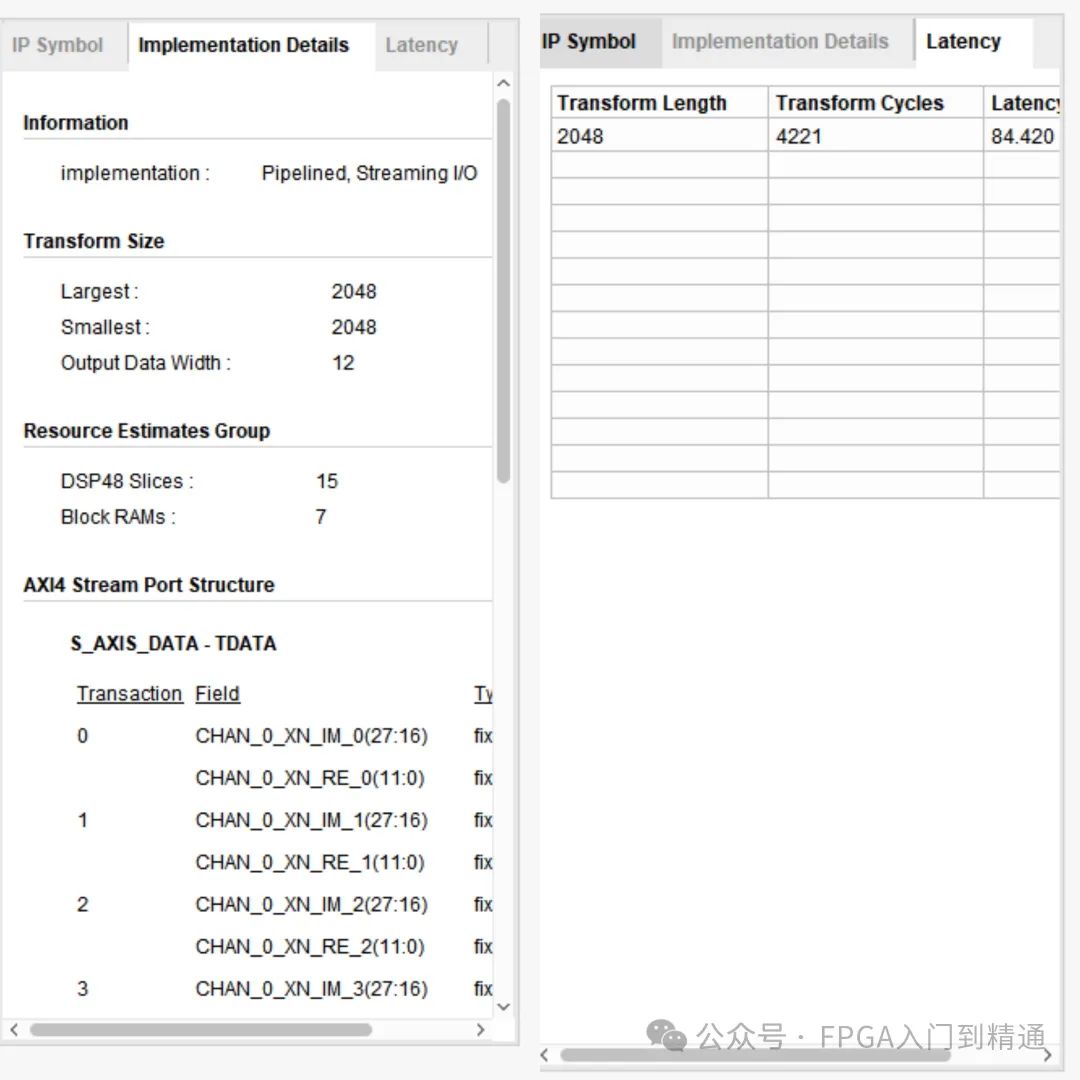
左侧 Implementation Details 实时展示 DSP、BRAM、FF 等资源消耗与流水线总延时。
三、IP 模块例化与仿真测试
1. IP 例化模板
verilog
xfft_0 your_instance_name (
.aclk(aclk),
.aresetn(aresetn),
.s_axis_config_tdata(s_axis_config_tdata),
.s_axis_config_tvalid(s_axis_config_tvalid),
.s_axis_config_tready(s_axis_config_tready),
.s_axis_data_tdata(s_axis_data_tdata),
.s_axis_data_tvalid(s_axis_data_tvalid),
.s_axis_data_tready(s_axis_data_tready),
.s_axis_data_tlast(s_axis_data_tlast),
.m_axis_data_tdata(m_axis_data_tdata),
.m_axis_data_tuser(m_axis_data_tuser),
.m_axis_data_tvalid(m_axis_data_tvalid),
.m_axis_data_tready(m_axis_data_tready),
.m_axis_data_tlast(m_axis_data_tlast),
.event_frame_started(event_frame_started),
.event_tlast_unexpected(event_tlast_unexpected),
.event_tlast_missing(event_tlast_missing),
.event_status_channel_halt(event_status_channel_halt),
.event_data_in_channel_halt(event_data_in_channel_halt),
.event_data_out_channel_halt(event_data_out_channel_halt)
);2. 频谱仿真结果
-
2 M H z 2\ \mathrm{MHz} 2 MHz 单频信号频谱
-
20 M H z 20\ \mathrm{MHz} 20 MHz 单频信号频谱
高频分量对应的频谱峰值在波形中心位置。
基于 Xilinx FPGA 的 FFT IP 使用例程说明文档(可动态配置 FFT 点数,可计算信号频率与幅度)
2024-05-23 17:03
1 概述
本文用于阐述 Xilinx 官方 FFT IP 配套工程示例的功能参数与使用方法,为工程使用者提供标准化的上机调试流程。
参考文档:《PG109》
2 IP examples 功能
本工程示例由风中月隐编制,面向 Xilinx FFT IP 完成功能封装,并依托仿真环境完成下述项目验证:
- 支持运行阶段动态配置 FFT 变换点数;
- 依托频谱数据完成输入正弦信号的频率求解;
- 基于频谱序列完成 FFT 输出幅度峰值提取运算;
- 对比 I/Q 数据输入次序变化对 FFT 输出频谱序列带来的影响;
- 实测动态修改 FFT 变换点数时 IP 内部参数的约束边界;
- 验证数据流连续输入模式下 IP 的数据吞吐适配能力;
- 完成全部 FFT 输出频点对应物理频率的逐点换算;
- 推导 FFT IP 输出幅值与分贝(dB)参数的换算表达式。
例程运行硬件环境配置:
- 仿真器件型号:XC7Z030-ffg676-2;
- 软件开发环境:Vivado 2018.2。
3 IP 使用例程
3.1 IP 设置
3.2 fft_demo 端口
3.3 例程框图
上图为系统整体硬件架构框图,各功能子模块与端口信号定义如下:
- DDS IP 用于生成余弦、正弦正交波形,等效模拟外部 ADC 采集得到的 I/Q 正交采样数据;
- Tlast_cfg 模块依据当前配置的 FFT 采样点数生成
tlast帧同步信号,实现时序与 FFT IP 输入接口规范匹配; - FFT IP 实现离散傅里叶变换运算,实部、虚部分别对应正交输入与正交输出通道;
- 后端数据处理模块运算规则:
a) DOUT = DOUT_RE 2 + DOUT_IM 2 \text{DOUT} = \text{DOUT\_RE}^2 + \text{DOUT\_IM}^2 DOUT=DOUT_RE2+DOUT_IM2
b) DOUT_MAX \text{DOUT\_MAX} DOUT_MAX 为 DOUT \text{DOUT} DOUT 序列的最大值,表征原始输入信号幅值;
c) DOUT_FRE \text{DOUT\_FRE} DOUT_FRE 为最大值对应频点的物理频率,表征原始输入信号频率。
3.4 仿真结果
全部仿真工况的激励信号统一由 DDS 生成 1 MHz 单频信号,各组测试结果分项记录如下:
-
分段间歇输入
din数据流工况a) 配置参数 fft_transform_length = 1024 \text{fft\_transform\_length} = 1024 fft_transform_length=1024;
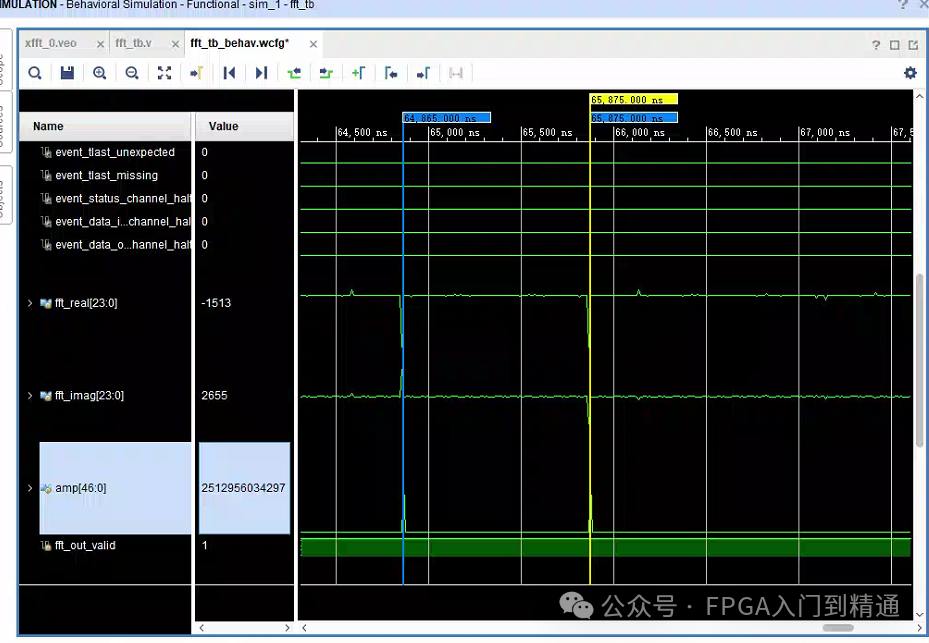
b) FFT_OUT \text{FFT\_OUT} FFT_OUT 序列存在单点极值
035b7xxx, fft_out_max \text{fft\_out\_max} fft_out_max 寄存数值与该极值保持一致;c) 极值对应频点计算数值为 976560 Hz 976560\ \text{Hz} 976560 Hz, fft_out_fre \text{fft\_out\_fre} fft_out_fre 输出结果与计算值一致。
-
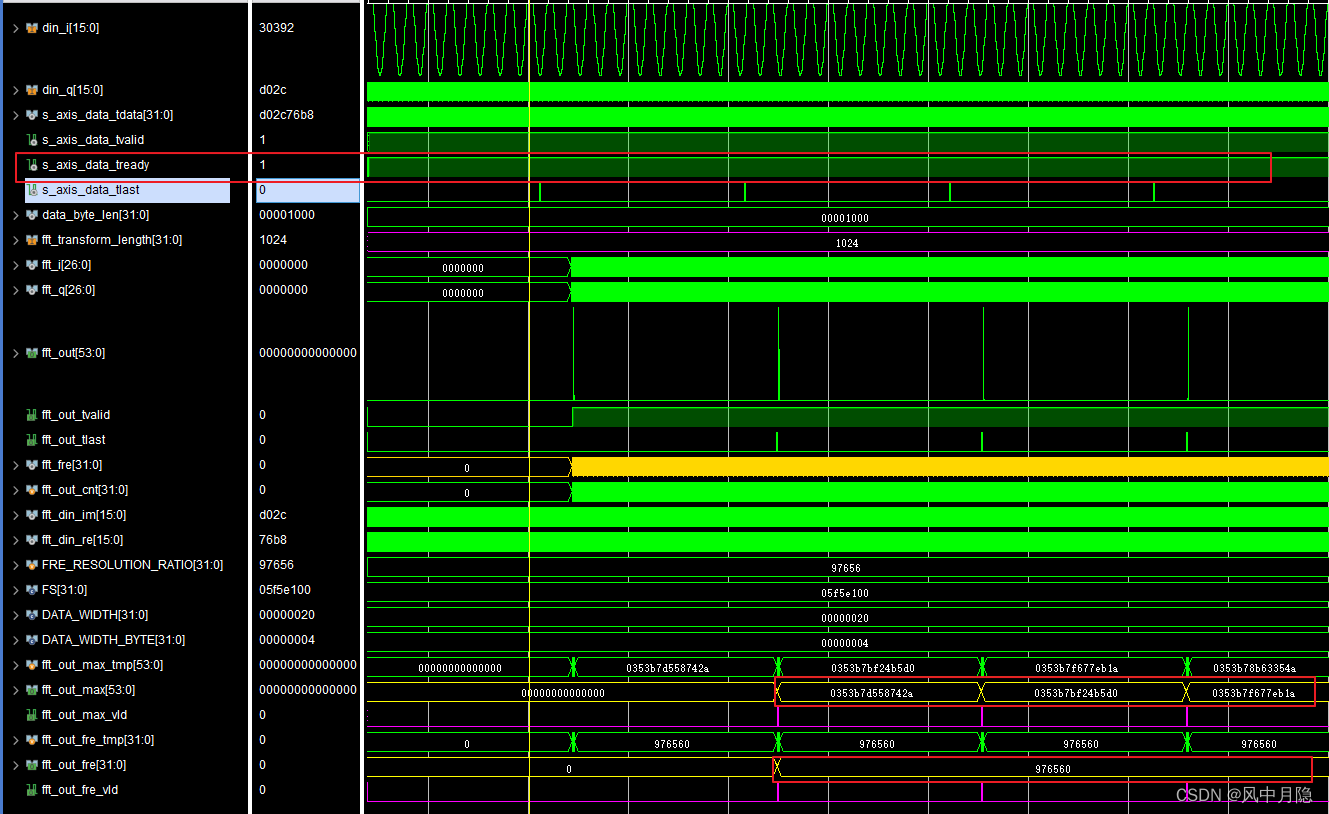
连续不间断输入
din数据流工况a) FFT IP 从机就绪信号 s_axis_data_tready \text{s\_axis\_data\_tready} s_axis_data_tready 持续置高电平;
b) 配置参数 fft_transform_length = 1024 \text{fft\_transform\_length} = 1024 fft_transform_length=1024;
c) FFT_OUT \text{FFT\_OUT} FFT_OUT 极值为
035b7xxx, fft_out_max \text{fft\_out\_max} fft_out_max 寄存高位数值恒定,低位尾数据随流水时序产生小幅浮动;d) 极值对应频点计算数值为 976560 Hz 976560\ \text{Hz} 976560 Hz, fft_out_fre \text{fft\_out\_fre} fft_out_fre 输出结果与计算值一致。
-
I/Q 输入通道与 RE/IM 端口互换工况
a) 配置参数 fft_transform_length = 1024 \text{fft\_transform\_length} = 1024 fft_transform_length=1024;
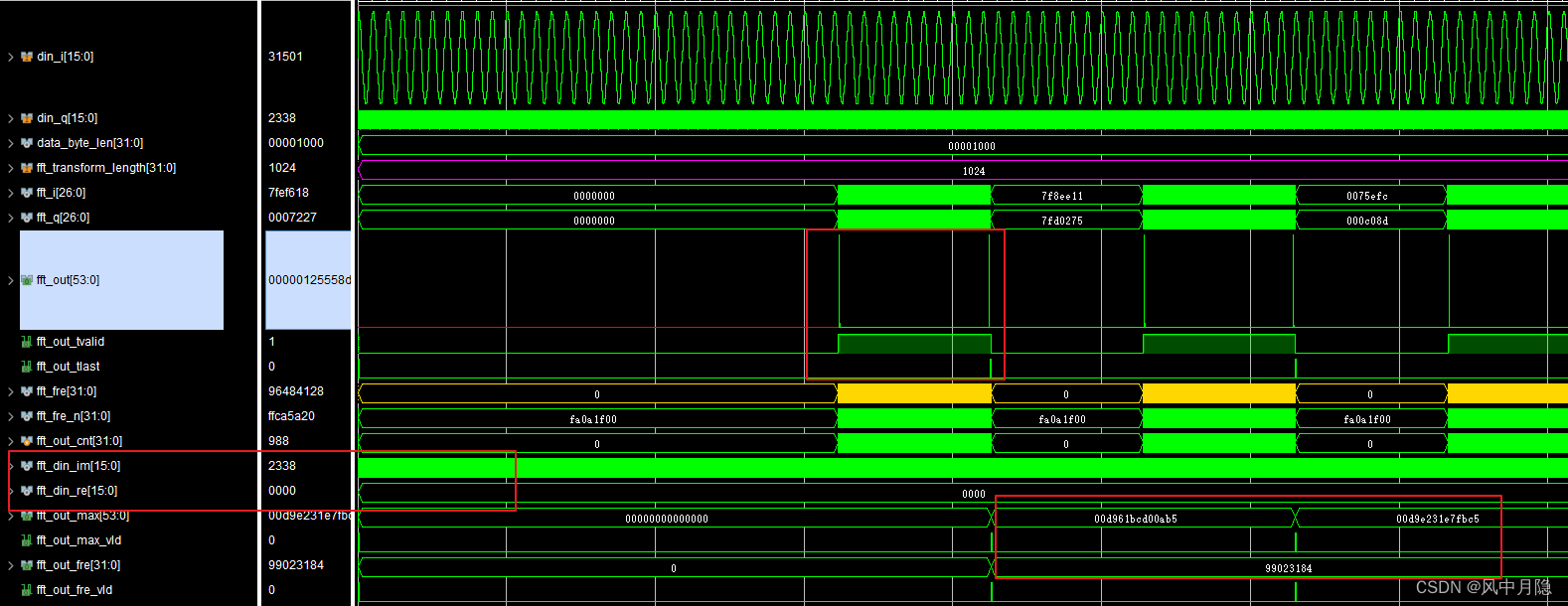
b) FFT_OUT \text{FFT\_OUT} FFT_OUT 极值
035b7xxx, fft_out_max \text{fft\_out\_max} fft_out_max 高位幅值不发生改变;c) 原正频率计算值为 99023184 Hz 99023184\ \text{Hz} 99023184 Hz,共轭负频率 fft_fre_n = − 976816 Hz \text{fft\_fre\_n} = -976816\ \text{Hz} fft_fre_n=−976816 Hz。
-
实部通道 RE \text{RE} RE 接入有效信号、虚部通道 IM = 0 \text{IM}=0 IM=0 工况
a) 配置参数 fft_transform_length = 1024 \text{fft\_transform\_length} = 1024 fft_transform_length=1024;
b) FFT_OUT \text{FFT\_OUT} FFT_OUT 频谱出现两处峰值,峰值位置以 F S / 2 F_S/2 FS/2 中点呈轴对称分布;
c) 序列最大值出现在采样频率后半频段。
-
实部通道 RE = 0 \text{RE}=0 RE=0、虚部通道 IM \text{IM} IM 接入有效信号工况
a) 配置参数 fft_transform_length = 1024 \text{fft\_transform\_length} = 1024 fft_transform_length=1024;
b) FFT_OUT \text{FFT\_OUT} FFT_OUT 频谱出现两处峰值,峰值位置以 F S / 2 F_S/2 FS/2 中点呈轴对称分布;
c) 序列最大值出现在采样频率后半频段。
-
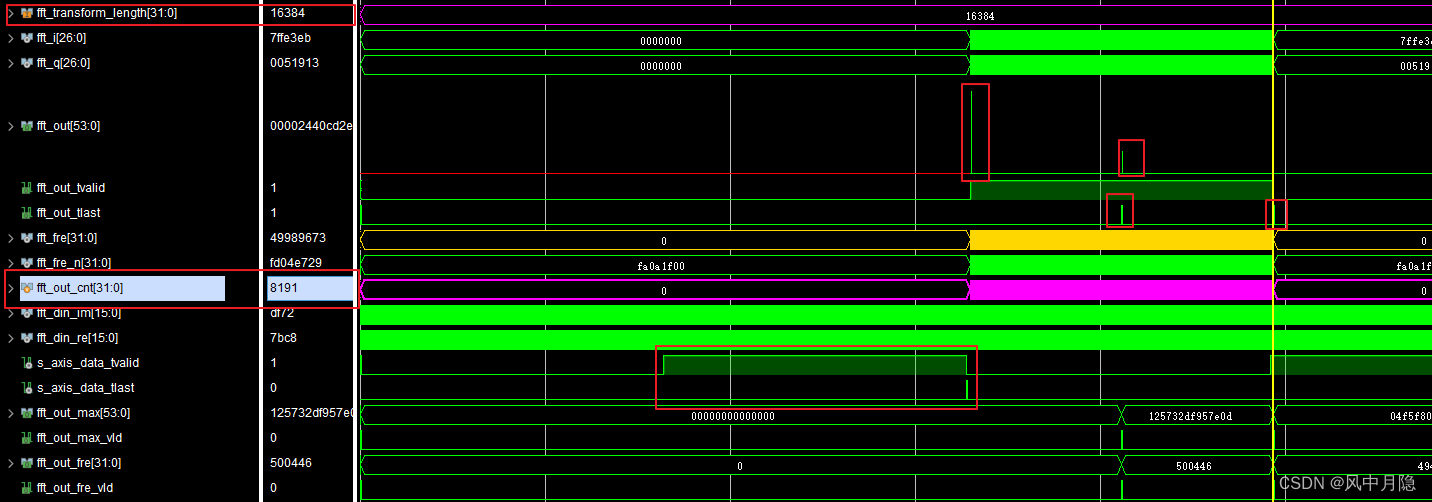
运行配置点数超出 IP 预设上限工况: fft_transform_length = 16384 \text{fft\_transform\_length}=16384 fft_transform_length=16384,IP 界面最大配置点数为 8192 8192 8192
a) 单次输入数据总量为 16384 16384 16384 点,运行配置点数参数写入数值为 16384 16384 16384;
b) FFT IP 自动拆分数据,分两次按单组 8192 8192 8192 点完成变换输出,对应 fft_fre_tlast \text{fft\_fre\_tlast} fft_fre_tlast 信号两次拉高;
c) FFT_OUT \text{FFT\_OUT} FFT_OUT 单峰值落在采样频率前半频段,首轮 8192 8192 8192 点运算输出幅值高于次轮输出幅值;
d) 峰值位置对应的频点换算结果出现偏差。
3.5 仿真验证得出的结论
- FFT IP 支持流水线不间断运算,仅需在每组变换数据末端通过 tlast \text{tlast} tlast 标识帧边界即可实现连续数据流收发;
- 正交 I/Q 采样数据输入时,I 与 Q 信号需要和 RE、IM 端口一一对应,端口错位将造成输出频点沿 F S / 2 F_S/2 FS/2 对称翻转;
- 单路实信号输入场景下,数据接入 RE 端口或 IM 端口均可完成频谱运算,峰值位置与幅值参数无明显差异;
- FFT 运行点数支持在线改写,但配置数值不得超过 IP 可视化界面预设的最大变换点数;超限配置时,IP 以预设最大值为单位对输入数据做分组运算,频点与幅值换算结果存在误差。
4 注意事项
- 工程调试阶段需要规范 I/Q 采样信号与 FFT 实部、虚部输入端口的映射关系;
- 输出频点数值依托采样频率 F S F_S FS 与变换点数 N N N 完成换算,采样频率变更时需同步修改源码内 F S F_S FS 定义参数;
- FFT 输出序列单频点物理频率推导公式:
a) 采样频段被 N N N 个频点均分,频点间隔(频率分辨率):
Δ f = F S N \Delta f = \frac{F_S}{N} Δf=NFS
b) 序号 number ∈ 0 , N − 1 \text{number}\in0,N-1 number∈0,N−1 对应物理频率:
f number = number ⋅ F S N f_{\text{number}} = \text{number}\cdot \frac{F_S}{N} fnumber=number⋅NFS - IP 配置页面的最大变换点数依照项目需求选定,不同点数配置方案对应的 FPGA 逻辑资源占用量存在显著差异;
- FFT 输出幅值向分贝单位转换:
Mag(dB) = 10 ⋅ log 10 ( DOUT ) = 20 ⋅ log 10 ( DOUT ) \begin{align} \text{Mag(dB)} &= 10\cdot \log_{10}\left(\text{DOUT}\right) \\ &= 20\cdot \log_{10}\left(\sqrt{\text{DOUT}}\right) \end{align} Mag(dB)=10⋅log10(DOUT)=20⋅log10(DOUT )
式中 DOUT = DOUT_RE 2 + DOUT_IM 2 \text{DOUT}=\text{DOUT\_RE}^2+\text{DOUT\_IM}^2 DOUT=DOUT_RE2+DOUT_IM2; - 若实现运算数值与 ADC 实际输入功率一一对应,需要在后端增加固定系数标定环节;
- IP 内部控制位 fwd_inv = 1 \text{fwd\_inv}=1 fwd_inv=1 配置为傅里叶正变换(FFT), fwd_inv = 0 \text{fwd\_inv}=0 fwd_inv=0 配置为傅里叶逆变换(IFFT);
- IP 参数 nfft \text{nfft} nfft 与实际变换点数存在固定映射关系,本款 IP 支持的最大变换点数为 65536 65536 65536。
5 例程位置
FFT 核:原理、应用、优化及发展趋势
一、基础定义
FFT 核(Fast Fourier Transform Kernel)是实现快速傅里叶变换运算的底层算法单元与硬件功能单元。在软件层面,其为封装蝶形运算逻辑的底层子程序;在 FPGA、ASIC 等硬件层面,其为构成完整 FFT IP 核的基础蝶形运算电路。快速傅里叶变换具备天然的并行运算属性,并行架构所产生的各类设计约束,均集中体现在 FFT 核的架构设计与硬件实现过程中,是数字电路并行设计的主要难点之一。
二、FFT 核数学构成与分类
2.1 蝶形运算的数学基础
快速傅里叶变换的核心运算依托蝶形运算(Butterfly Operation)实现。单组基 2 蝶形运算构成最简结构的 FFT 核,其运算关系式如下:
{ X m = A + W N k ⋅ B X n = A − W N k ⋅ B \begin{cases} X_m = A + W_N^k \cdot B \\ X_n = A - W_N^k \cdot B \end{cases} {Xm=A+WNk⋅BXn=A−WNk⋅B
式中, A A A、 B B B 为复数输入采样数据, W N k = e − j 2 π k N W_N^k = e^{-j\frac{2\pi k}{N}} WNk=e−jN2πk 为旋转因子(Twiddle Factor)。标准蝶形运算单元由复数乘法运算通路与复数加减运算通路共同组成。
2.2 按运算基数的分类
依据运算基数的差异,工程主流 FFT 核可分为三类:
- 基 2 FFT 核 :单次完成 2 点蝶形运算,控制逻辑架构简洁,硬件实现难度低,单次并行处理数据规模有限,适用于低速、低资源开销的信号处理场景。要求运算点数 N = 2 M N = 2^M N=2M( M M M 为正整数)。
- 基 4 FFT 核 :单次完成 4 点蝶形运算,整体复数乘法运算总量较基 2 降低约 25%,硬件数据吞吐效率更高,时序性能更优,广泛应用于高速实时信号处理硬件系统。要求运算点数 N = 4 M N = 4^M N=4M。
- 混合基 FFT 核 :包含基 2、基 4 及基 8 等复合基数架构,通过 Cooley-Tukey 算法或素因子算法(Prime Factor Algorithm, PFA)进行分解,适配非单一基整数次幂运算点数(如 N = 2 a ⋅ 4 b N = 2^a \cdot 4^b N=2a⋅4b),在定点 ASIC 芯片设计中应用较为广泛。
2.3 按抽取方式的分类
从算法结构角度,FFT 核还可按抽取方式分为:
- 按时域抽取(DIT, Decimation-In-Time):输入序列需经位反转(Bit-Reversal)重排,输出为自然顺序。适用于输入数据可预先缓存的场景。citeweb_search:1#4
- 按频域抽取(DIF, Decimation-In-Frequency):输入为自然顺序,输出需经位反转重排。适用于输出需连续读取与后续级联处理的场景。citeweb_search:1#3
- Stockham 自排序算法:各级输入输出均为自然顺序,无需位反转操作,对 SIMD 向量化和混合基融合更为友好,但需额外的存储空间用于数据重排。
三、软件架构下的 FFT 核实现形式
3.1 通用运算库
主流通用运算库均集成标准化软件 FFT 核。FFTW(Fastest Fourier Transform in the West)通过运行时代码生成与自适应规划(Planner)机制,针对目标 CPU 的缓存层次、SIMD 指令集(如 SSE/AVX/NEON)进行自动优化;NVIDIA CUFFT 针对 CUDA 架构中的 GPU 硬件调度机制提供专用 FFT 运算单元(cufftKernel),可实现大规模并行频域变换;ARM NEON 运算框架通过 SIMD 向量化并行处理,为嵌入式 ARM 处理器提供标准化底层算力支撑。
3.2 嵌入式轻量化实现
在嵌入式微控制器系统中,经过定点量化适配的蝶形运算子程序属于轻量化软件 FFT 核。典型实现采用 Q15 或 Q31 定点格式,通过预计算旋转因子查表、循环展开及块浮点(Block Floating Point)动态缩放机制,满足低端嵌入式设备的基础频域运算需求。
四、硬件架构下的 FFT 核分类与并行设计约束
4.1 硬件架构分类
基于硬件资源复用方式的不同,硬件 FFT 核可分为三类架构:
- 全并行 FFT 核 :完整布设 N N N 点 FFT 所需的全部蝶形运算单元,所有运算同步并行执行,数据处理时延极低、吞吐能力极强,但逻辑门与寄存器资源消耗随运算点数 N N N 呈 O ( N log N ) O(N \log N) O(NlogN) 增长,硬件资源开销极高,工程实践中极少采用完整全并行结构,通常仅在关键级采用局部并行。citeweb_search:1#0
- 流水线 FFT 核:将蝶形运算按时序层级拆分排布,数据逐级流转完成分时运算,有效降低硬件资源占用,整体时序稳定性较强。典型实现包括 Pipelined Streaming I/O 架构,适合连续数据流处理。设计需适配多级时序约束,配套跨时钟域信号处理电路。citeweb_search:1#6
- 折叠串行 FFT 核:依托单组或少量蝶形单元分时轮换完成全部运算流程,硬件资源占用规模最小,架构轻量化优势显著,但单位时序内数据处理量较低,整体吞吐性能受限。典型实现包括 Radix-2 Burst I/O 架构。
4.2 并行设计约束
FFT 核的硬件并行实现存在多项固有设计约束,是电路设计的主要难点:
- 旋转因子存储带宽约束:多路并行蝶形单元同步读取旋转因子时,片上 ROM、BRAM 存储结构需匹配多通道高带宽并行访问需求。通常采用多端口分区配置或双端口存储器阵列,将旋转因子按级数与蝶形组号分体存储。citeweb_search:1#0web_search:1#7
- 位反转地址生成约束:FFT 输入输出数据存在位反转固有排布特征(DIT 输入反序、DIF 输出反序),并行数据流需配套专用地址分配与硬件布线架构。工程实现中可通过二进制位倒置逻辑、格雷码计数器或专用位反转地址生成电路(Bit-Reversal Address Generator)替代通用寻址逻辑,精简数据重排时序。
- 时序同步与流水线对齐约束:多路复数并行运算通路需完成时序同步,实现流水线级数对齐与信号完整性优化。各级蝶形运算间需插入延时对齐模块(Delay Alignment Module),采用 FIFO 或移位寄存器链补偿路径差异导致的时序偏移,确保参与同一蝶形计算的两个输入数据严格同步到达。
五、硬件 FFT 核应用领域
硬件 FFT 核具备高速、实时、低时延的运算特性,是各类数字信号处理系统的基础单元,主要应用领域如下:
- 无线通信领域:广泛应用于 4G、5G 移动通信基带解调、OFDM 载波频谱解析、射频信道滤波等模块,完成时域信号到频域信号的高速转换,保障通信系统的实时解调与频谱调度能力。citeweb_search:4#1
- 雷达探测领域:应用于脉冲多普勒雷达回波频谱分析、目标距离与径向速度解算模块,实现雷达信号距离维、速度维的频域变换与参数提取,支撑雷达目标探测与跟踪功能。
- 声学与音频检测领域:部署于工业噪声监测、有源降噪(ANC)、声源定位等硬件设备,实现音频采样序列的实时频域分解,完成噪声滤波、信号特征提取等基础处理。
- 电力与计量仪器领域:作为电能质量分析仪、工频谐波检测设备的核心运算单元,对电网电压、电流瞬时采样数据进行频域分析,实现电网谐波、电压波动等参数的精准检测。
- 遥感与成像领域:集成于合成孔径雷达(SAR)成像、卫星遥感数据预处理硬件平台,通过高频次 FFT 运算完成图像频域滤波、数据压缩与成像变换,满足海量遥感数据的高速处理需求。
六、FFT 核性能优化方式
FFT 核的性能优化围绕运算时延、吞吐能力、资源占用、运行效率四项指标展开,可从算法、软件、硬件三个层级实现系统性优化:
6.1 算法层级优化
- 采用高基数蝶形运算架构:以基 4、基 8 架构替代传统基 2 架构,有效削减复数乘法运算总量(基 4 较基 2 减少约 25% 乘法量),降低整体运算复杂度。
- 旋转因子预计算与定点量化:将固定系数固化至片上存储(ROM/BRAM),消除运行过程中实时三角函数求解的冗余流程;采用 CORDIC 算法或查找表插值法在运行时动态生成高精度复数系数,同时支持可配置点数与缩放因子。
- 分段分块运算机制:拆分超大点数 FFT 运算任务,适配片上存储容量限制,减少外部存储器高频读写带来的性能损耗。
6.2 软件层级优化
- SIMD 向量化:充分调用处理器 SIMD、NEON、AVX 等单指令多数据流指令集,对蝶形运算逻辑进行向量化编译,提升单次指令的数据处理规模。实验表明,自动 SIMD 向量化可实现与手工优化代码相当的性能,使 FFTW 浮点性能翻倍。
- 缓存优化:优化程序循环排布结构,适配处理器高速缓存读写机制,降低缓存缺失(Cache Miss)引发的运算开销;采用循环分块(Loop Tiling)技术提升数据局部性。
- 定点运算替代:采用定点整型运算替代高精度浮点运算,在满足工程精度要求的前提下,缩短单周期运算时延。
6.3 硬件层级优化
- 流水线切割:对运算通路进行流水线切割,在乘法、加法单元之间插入时序寄存器,缩短硬件关键路径延时,提升系统最高工作时钟频率。
- 旋转因子存储多端口化:对旋转因子存储器件进行多端口分区配置,满足多路蝶形单元并行读取需求,破除存储带宽瓶颈。
- 混合架构设计:采用并行与折叠混合架构,根据业务需求平衡硬件资源消耗与数据吞吐性能。
- 专用位反转电路:集成专用位反转地址生成电路,替代通用寻址逻辑,精简数据重排时序,提升整体运算效率。
七、FFT 核行业发展趋势
随着高速数字信号处理、异构计算、低功耗物联网技术的迭代,FFT 核呈现出架构定制化、异构融合化、低功耗化、可配置化、轻量化的发展趋势,具体表现为以下五个方向:
- 行业架构定制化:传统通用型 FFT 核逐步向场景化定制演进,针对通信、雷达、电力测控等不同领域的带宽、点数、时延指标需求,完成硬件逻辑裁剪与架构优化,消除通用架构的资源冗余,提升场景适配性。
- 异构协同融合化:FFT 运算任务逐步实现 CPU、GPU、FPGA 多硬件异构协同调度。高速实时运算任务由硬件 FFT 核承载,超长序列、低实时性运算任务由软件 FFT 核分担,形成软硬件协同的分层算力架构。
- 低功耗设计常态化:面向便携探测设备、物联网终端、嵌入式低功耗场景,通过门控时钟(Clock Gating)、动态电压频率调节(DVFS)、运算单元分时休眠等硬件技术,持续降低 FFT 核的静态功耗与动态功耗,适配低功耗终端设备的应用需求。研究表明,门控时钟可节省 20%~60% 的动态功耗;DVFS 技术可根据操作模式节省 18%~43% 的功耗。
- 参数动态可配置化:固定点数 FFT 核逐步迭代为自适应可配置架构,支持 2 的整数次幂、混合基数等多规格运算点数动态切换,可适配多场景信号处理需求,减少硬件 IP 核的储备与开发成本。
- 轻量化近似计算普及化:在非高精度、宽动态的通用检测场景中,通过低位宽近似运算架构优化(如 16 bit 定点、块浮点),在满足工程精度阈值的基础上,进一步压缩硬件资源占用、降低运算时延,实现算力与成本的最优匹配。
八、概念区分
FFT IP 核 与 FFT 核为两个不同层次的概念:
- FFT IP 核:为集成完整控制逻辑、存储单元、运算通路、接口协议的标准化成品硬件模块,具备固定运算规格与完整功能,可直接嵌入 SoC 或 FPGA 设计中使用。
- FFT 核:为构成 FFT IP 核的最小基础蝶形运算单元,可通过级联、并联、时分复用的组合方式,搭建生成不同点数、不同性能规格的 FFT 运算模块,是 FFT 硬件系统的原子计算单元。
reference
- Xilinx FFT IP 核配置说明及使用方法 (超详细)_xilinx fft ip 核 说明文档-CSDN 博客
https://blog.csdn.net/weixin_45137708/article/details/153397978 - Xilinx FPGA FFT 应用笔记_xilinx 观察频谱的软件-CSDN 博客
https://blog.csdn.net/yijingjijng/article/details/48137897 - Vivado Xilinx FFT IP 核 v9.0 使用详解(附仿真实例)_vivado fft 仿真测试-CSDN 博客
https://blog.csdn.net/weixin_41594632/article/details/112689545 - 基于 vivado 实现 FFT/IFFT_fft vivado-CSDN 博客
https://blog.csdn.net/qq_45600102/article/details/121487844 - 一文快速掌握 Vivado 的 FFT IP_vivado fft ip 核-CSDN 博客
https://blog.csdn.net/mengzaishenqiu/article/details/145819176 -
基于 xilinx FPGA 的 FFT IP 使用例程说明文档(可动态配置 FFT 点数,可计算信号频率与幅度)
https://blog.mvui.cn/detail/46721.html - 如何配置并验证在 Vivado 使用各种测试信号的 FFT IP 核 - hczyydqq - 博客园
https://www.cnblogs.com/linkstu/p/19092018 - vivado FFT ip 核全解析 - 知乎
https://zhuanlan.zhihu.com/p/637653195 - Xilinx Vivado FFT IP 核使用介绍 - devindd - 博客园
https://www.cnblogs.com/devindd/articles/16793294.html - ......