注:本文为 "Xilinx Vivado 复数乘法" 相关合辑。
图片清晰度受引文原图所限。
略作重排,未整理去重。
如有内容异常,请看原文。
Vivado 中复数乘法器的 IP 核调用及其仿真的详细介绍
饭真好吃 2022-02-09 19:57:08
复数乘法器 IP 核的选型入口参考下图:

IP 核输入、输出端口参数配置界面参考下图:

在 Multiplier Construction 配置项勾选 Use LUTs 时,器件采用三乘法运算架构;对比四乘法运算架构,该架构可缩减逻辑资源占用,配套代价为额外配置查找表资源。
输出数据实部与虚部存在位间隔的成因参考下述图示(配套 AXI4-Stream 协议 TDATA 字段结构说明):

完成参数配置后,点击 Generate 执行 IP 核工程生成操作:

于 IP Sources 目录调取 IP 核 Verilog 实例化模板,作为顶层工程调用参考:

通过 Add Sources 完成顶层设计文件添加:

1. 顶层功能模块源码
verilog
/*
模块功能:调用 Vivado 内置 Math Functions 分组复数乘法 IP 核,完成双复数定点乘法运算
输入参数:实部、虚部位宽均为 16 bit,输入数据采用补码格式以支持负数运算
输出参数:实部、虚部位宽均为 33 bit,用于规避定点乘法运算溢出
*/
module top(
input clk,
input [15:0] re_a,im_a,re_b,im_b, // 两路复数输入,re 标识实部,im 标识虚部
output [32:0] re_result,im_result
);
wire [79:0] result; // 80 bit 输出总线,位段[39:34]、[79:75] 为预留无效位
// 从拼接输出总线拆分运算结果的实部、虚部
assign im_result = result[72:40];
assign re_result = result[32:0];
// 复数乘法 IP 核实例化
cmpy complex_multiplier1(
.aclk(clk),
.s_axis_a_tvalid(1'b1),
.s_axis_a_tdata({im_a,re_a}), // 单路 AXI 数据总线拼接:{虚部,实部},总位宽 32 bit
.s_axis_b_tvalid(1'b1),
.s_axis_b_tdata({im_b,re_b}),
.m_axis_dout_tvalid(),
.m_axis_dout_tdata(result)
);
endmodule2. 仿真激励(Testbench)源码
verilog
`timescale 1ns / 1ps
module testbench();
reg [15:0] re_a,im_a,re_b,im_b;
reg clk;
wire [32:0] re_result, im_result;
initial begin
re_a = 16'b0000_0000_0000_0001;
im_a = 16'b0000_0000_0000_0001;
re_b = 16'b0000_0000_0000_0001;
im_b = 16'b1111_1111_1111_1110; // 负数采用二进制补码赋值
clk = 0;
end
top u1(.clk(clk),.re_a(re_a),.im_a(im_a),.re_b(re_b),.im_b(im_b),.re_result(re_result),.im_result(im_result));
always begin
#10 clk = ~clk; // 时钟翻转周期:10 ns
end
endmoduleVivado 集成在线语法检测功能,编译阶段自动标注代码错误位置;源码添加完成后,在仿真菜单栏启动 Behavioral Simulation。

运算示例: ( 1 + 1 j ) × ( 1 − 2 j ) = 3 − j \left(1+1j\right)\times\left(1-2j\right)=3-j (1+1j)×(1−2j)=3−j,对应仿真波形参考下图:

参考文献
1 Xilinx 官方手册:复数乘法 IP 核技术文档 https://www.xilinx.com/content/dam/xilinx/support/documentation/ip_documentation/cmpy/v6_0/pg104-cmpy.pdf
Vivado 中复数乘法器 IP 核使用小结
子不语 zZ 2022-09-01 16:04:42
本文梳理 Vivado 环境下复数乘法 IP 核全流程使用步骤,涵盖 IP 实例添加、参数配置、工程调用与仿真校验环节;通过自定义 IP 命名与输入位宽参数,完成定点复数乘法运算并通过仿真核验运算结果。
1 IP 工程添加
打开目标工程,启动 IP Catalog,在分类目录依次选择 Math Functions → Multipliers → Complex Multiplier,完成复数乘法器 IP 选型。
2 IP 参数定制配置
双击已添加 IP 条目进入参数配置界面:

常规配置项包含 IP 实例名、输入数据位宽;本案例将 IP 命名为 mult,两路乘数输入位宽统一配置为 12 bit 12\ \text{bit} 12 bit。
打开 Implementation Details 页面查看总线位段分配规则:

- 输入单路 32 bit 32\ \text{bit} 32 bit 总线: 11 : 0 \left11:0\\right 11:0 映射实部数据, 27 : 16 \left27:16\\right 27:16 映射虚部数据;
- 输出单路 64 bit 64\ \text{bit} 64 bit 总线: 24 : 0 \left24:0\\right 24:0 映射实部运算结果, 56 : 32 \left56:32\\right 56:32 映射虚部运算结果。
打开 IP 配套.v文件,提取模块端口声明作为实例化参考:
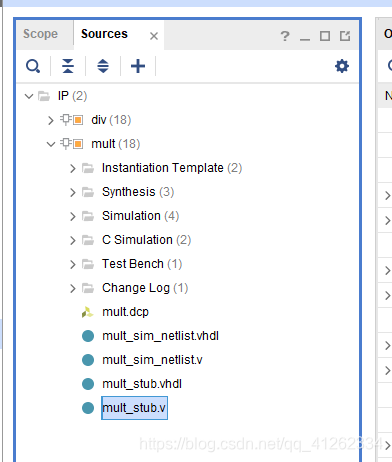
verilog
(* x_core_info = "cmpy_v6_0_15,Vivado 2018.2" *)
module mult(aclk, s_axis_a_tvalid, s_axis_a_tdata,
s_axis_b_tvalid, s_axis_b_tdata, m_axis_dout_tvalid, m_axis_dout_tdata)
/* synthesis syn_black_box black_box_pad_pin="aclk,s_axis_a_tvalid,s_axis_a_tdata[31:0],s_axis_b_tvalid,s_axis_b_tdata[31:0],m_axis_dout_tvalid,m_axis_dout_tdata[63:0]" */;
input aclk;
input s_axis_a_tvalid;
input [31:0]s_axis_a_tdata;
input s_axis_b_tvalid;
input [31:0]s_axis_b_tdata;
output m_axis_dout_tvalid;
output [63:0]m_axis_dout_tdata;
endmodule输入数据位宽为 32 bit 32\ \text{bit} 32 bit、输出数据位宽为 64 bit 64\ \text{bit} 64 bit;设计阶段需将复数实部、虚部按既定位段格式拼接至 32 bit 32\ \text{bit} 32 bit 寄存器,空余比特位填充逻辑 0 后送入 IP 输入端口。
3 模块调用与仿真验证
3.1 IP 实例化代码
verilog
mult mult_r(
.aclk (clk),
.s_axis_a_tvalid (r_valid_r),
.s_axis_a_tdata (r_data),
.s_axis_b_tvalid (c_valid_r),
.s_axis_b_tdata (c_data),
.m_axis_dout_tvalid (weight_valid_1),
.m_axis_dout_tdata (out_data_1)
);3.2 仿真激励片段
verilog
initial begin
valid_1 <= 1'b1;
r_re <= 12'b000000000001;
r_im <= 12'b000000000110;
valid_2 <= 1'b1;
c_re <= 12'b000000000010;
c_im <= 12'b000000000010;
end
// 实部、虚部数据总线位宽拼接
r_data[11:0] <= r_data_re_r;
r_data[15:12] <= 4'b0000;
r_data[27:16] <= r_data_im_r;
r_data[31:28] <= 4'b0000;
c_data[11:0] <= c_data_re_r;
c_data[15:12] <= 4'b0000;
c_data[27:16] <= c_data_im_r;
c_data[31:28] <= 4'b0000;Vivado 仿真波形:

配套 Matlab 数值校验结果:
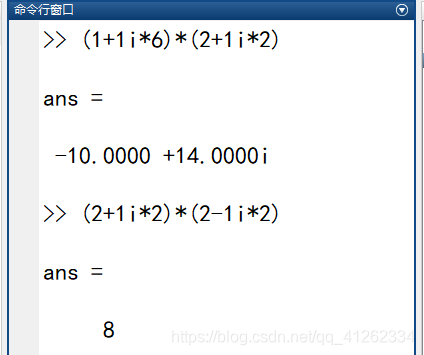
两组复数乘法运算结果与理论计算数值保持一致。
Xilinx Vivado 复数乘法器 Complex Multiplier IP 核调用及其仿真
jjzw1990 2022-10-11 23:26:21
本文围绕 Complex Multiplier IP 核定点输出截位规则展开说明;官方手册 PG104 针对输出截位的描述较为简略,下文结合多组仿真案例,分类阐述不同配置条件下的数据截位处理逻辑。
一、仿真测试代码
verilog
/*-------------------------------------------------------------------------------------------------------------------
Author: Zheng Wei
Date: 2022-10-10
Version: 1.0
Description: It is a tb_cmpy testbench file.
-------------------------------------------------------------------------------------------------------------------*/
`timescale 1ns / 1ps
module tb_cmpy;
reg i_sys_clk ;
reg i_sys_rst ;
reg din_ena ;
reg [9:0] din_re0 ;
reg [9:0] din_im0 ;
reg [9:0] din_re1 ;
reg [9:0] din_im1 ;
// 时钟生成,周期 10 ns,对应时钟频率 100 MHz
parameter period = 10;
initial begin
i_sys_clk = 1'b0;
forever #(period/2) i_sys_clk = ~i_sys_clk;
end
task task_sysinit; begin end endtask
task task_reset;
begin
i_sys_rst = 1'b1;
repeat(2) @(negedge i_sys_clk);
i_sys_rst = 1'b0;
end
endtask
initial begin
task_sysinit;
task_reset ;
repeat(10) @(posedge i_sys_clk);
// 定点格式:1 bit 符号位+1 bit 整数位+8 bit 小数位
// 测试用例 1: x0 = 0.5 + j, x1 = 1 - 0.5j,运算结果 x0*x1 = 1 + 0.75j
din_ena = 1;
din_re0 = 10'b00_1000_0000;
din_im0 = 10'b01_0000_0000;
din_re1 = 10'b01_0000_0000;
din_im1 = 10'b11_1000_0000;
@(posedge i_sys_clk);
din_ena = 0;
repeat(20) @(posedge i_sys_clk);
// 测试用例 2: x0 = 0.5 - j, x1 = 1 - 0.75j,运算结果 x0*x1 = -0.25 - 1.375j
din_ena = 1;
din_re0 = 10'b00_1000_0000;
din_im0 = 10'b11_0000_0000;
din_re1 = 10'b01_0000_0000;
din_im1 = 10'b11_0100_0000;
@(posedge i_sys_clk);
din_ena = 0;
repeat(500) @(posedge i_sys_clk);
$stop;
end
// 方案 1:IP 输出配置 25 bit,无硬件自动截位
wire fft1_ena ;
wire signed [31:0] fft1_real ;
wire signed [31:0] fft1_imag ;
wire signed [11:0] fft1_re_dout;
wire signed [11:0] fft1_im_dout;
cmpy_1 u1_cmpy(
.aclk (i_sys_clk ),
.s_axis_a_tvalid (din_ena ),
.s_axis_a_tdata ({4'd0,{2{din_im0[9]}},din_im0,4'd0,{2{din_re0[9]}},din_re0}),
.s_axis_b_tvalid ( 1'b1 ),
.s_axis_b_tdata ({4'd0,{2{din_im1[9]}},din_im1,4'd0,{2{din_re1[9]}},din_re1}),
.m_axis_dout_tvalid (fft1_ena ),
.m_axis_dout_tdata ({fft1_imag,fft1_real} )
);
assign fft1_re_dout = fft1_real[8+:12];
assign fft1_im_dout = fft1_imag[8+:12];
// 方案 2:IP 输出配置 20 bit,硬件自动截去低位 5 bit
wire fft2_ena ;
wire signed [23:0] fft2_real ;
wire signed [23:0] fft2_imag ;
wire signed [11:0] fft2_re_dout;
wire signed [11:0] fft2_im_dout;
cmpy_0 u2_cmpy(
.aclk (i_sys_clk ),
.s_axis_a_tvalid (din_ena ),
.s_axis_a_tdata ({4'd0,{2{din_im0[9]}},din_im0,4'd0,{2{din_re0[9]}},din_re0}),
.s_axis_b_tvalid ( 1'b1 ),
.s_axis_b_tdata ({4'd0,{2{din_im1[9]}},din_im1,4'd0,{2{din_re1[9]}},din_re1}),
.m_axis_dout_tvalid (fft2_ena ),
.m_axis_dout_tdata ({fft2_imag,fft2_real} )
);
assign fft2_re_dout = fft2_real[3+:12];
assign fft2_im_dout = fft2_imag[3+:12];
// 方案 3:输入数据低位补 0 拓展位宽,IP 输出配置 20 bit
wire fft3_ena ;
wire signed [23:0] fft3_real ;
wire signed [23:0] fft3_imag ;
wire signed [11:0] fft3_re_dout;
wire signed [11:0] fft3_im_dout;
cmpy_0 u3_cmpy(
.aclk (i_sys_clk ),
.s_axis_a_tvalid (din_ena ),
.s_axis_a_tdata ({4'd0,din_im0,2'd0,4'd0,din_re0,2'd0}),
.s_axis_b_tvalid ( 1'b1 ),
.s_axis_b_tdata ({4'd0,din_im1,2'd0,4'd0,din_re1,2'd0}),
.m_axis_dout_tvalid (fft3_ena ),
.m_axis_dout_tdata ({fft3_imag,fft3_real} )
);
assign fft3_re_dout = fft3_real[7+:12];
assign fft3_im_dout = fft3_imag[7+:12];
endmodule二、IP 核参数配置说明
-
cmpy_1:输入位宽 12 bit 12\ \text{bit} 12 bit,输出位宽选用默认 25 bit 25\ \text{bit} 25 bit; -
cmpy_0:输入位宽 12 bit 12\ \text{bit} 12 bit,输出位宽手动配置为 20 bit 20\ \text{bit} 20 bit;
三、定点截位规则解析
3.1 输出位宽 25 bit(无硬件截位)
输入原始数据 10 bit 10\ \text{bit} 10 bit,小数域占用 8 bit 8\ \text{bit} 8 bit,等效数据左移 8 8 8;两路数据相乘后整体左移 16 16 16;若结果保留 8 8 8 位小数,需要对运算结果右移 8 8 8,对应截取代码:
verilog
assign fft1_re_dout = fft1_real[8+:12];3.2 输出位宽 20 bit(硬件预截 5 bit)
IP 输出由 25 bit 25\ \text{bit} 25 bit 缩减至 20 bit 20\ \text{bit} 20 bit,硬件自动舍弃低位 5 5 5;原需求右移 8 8 8,扣除硬件预截位数后,代码仅需右移 8 − 5 = 3 8-5=3 8−5=3:
verilog
assign fft2_re_dout = fft2_real[3+:12];3.3 输入末端补零拓展位宽场景
输入 10 bit 10\ \text{bit} 10 bit 数据低位补 2 2 2 个逻辑 0 拓展至 12 bit 12\ \text{bit} 12 bit,等效原始数据额外左移 2 2 2;相乘后整体左移 8 + 8 + 2 + 2 = 20 8+8+2+2=20 8+8+2+2=20;保留 8 8 8 位小数需要右移 12 12 12,扣除硬件预截 5 5 5,最终右移 7 7 7:
verilog
assign fft3_re_dout = fft3_real[7+:12];数据位宽拓展分为两类实现方案:符号位复制填充、低位补 0 填充。
四、仿真结果
Modelsim 仿真波形:
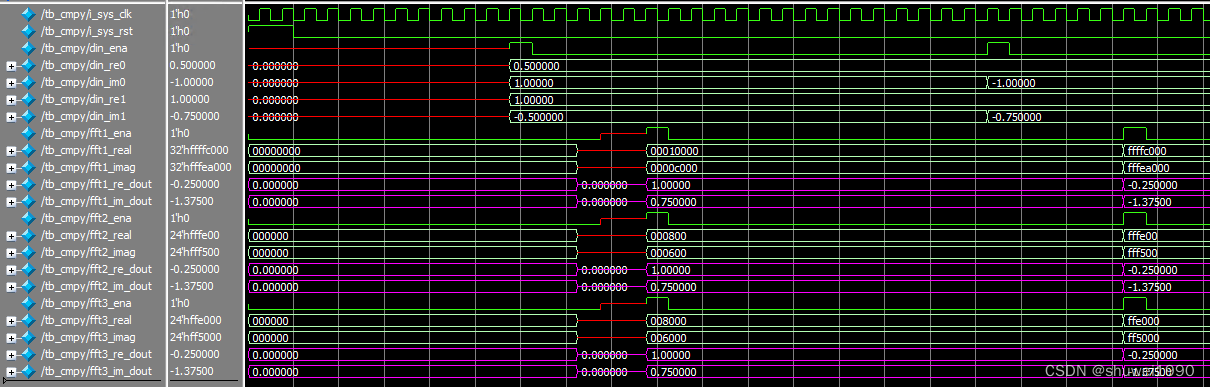
三组配置下的截位输出与理论数值匹配。
Vivado IP 核之定点复数乘法器 Complex Multiplier 使用说明
FPGA 与信号处理 2025-03-13 16:54:53 发布
前言
在数字信号处理、通信系统及嵌入式系统中,复数运算为基础运算单元。Vivado 设计套件集成 Xilinx 官方 IP 核,其中定点复数乘法器(Complex Multiplier,CMPY) 为复数运算的标准化硬件实现单元。本文阐述 Vivado 定点复数乘法器 IP 核的配置流程、参数定义与工程实现方法,通过 Verilog 仿真代码完成 IP 核功能验证。
一、Complex Multiplier IP 核配置流程
1.1 Input and Implementation 界面配置
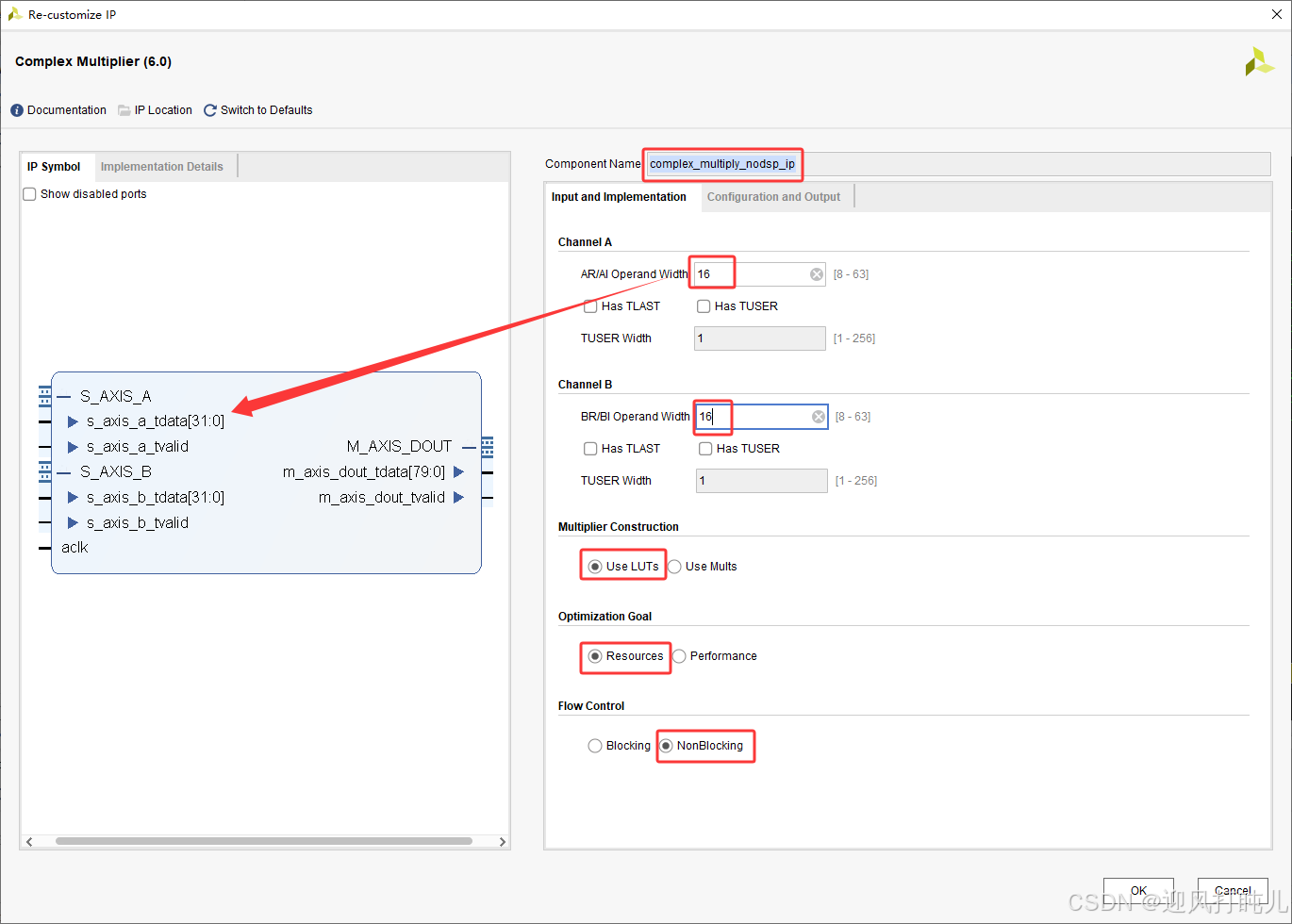
配置参数如下:
- 输入变量 A 实部、虚部位宽均配置为 16 bit;
- 输入变量 B 实部、虚部位宽均配置为 16 bit;
- 输入总线
s_axis_a_tdata位宽为 32 bit ,高 16 bit 映射虚部数据,低 16 bit 映射实部数据; - 资源架构选择:
Use LUTs仅占用可编程逻辑资源,Use Mults占用 DSP 硬件资源; - 工作模式:支持资源优化与性能优化配置,性能模式可提升 IP 核工作时钟频率;
- 流控制机制遵循 AXI4-Stream 协议,默认采用非阻塞模式,两路输入数据同步有效时输出运算结果。
1.2 Configuration and Output 界面配置
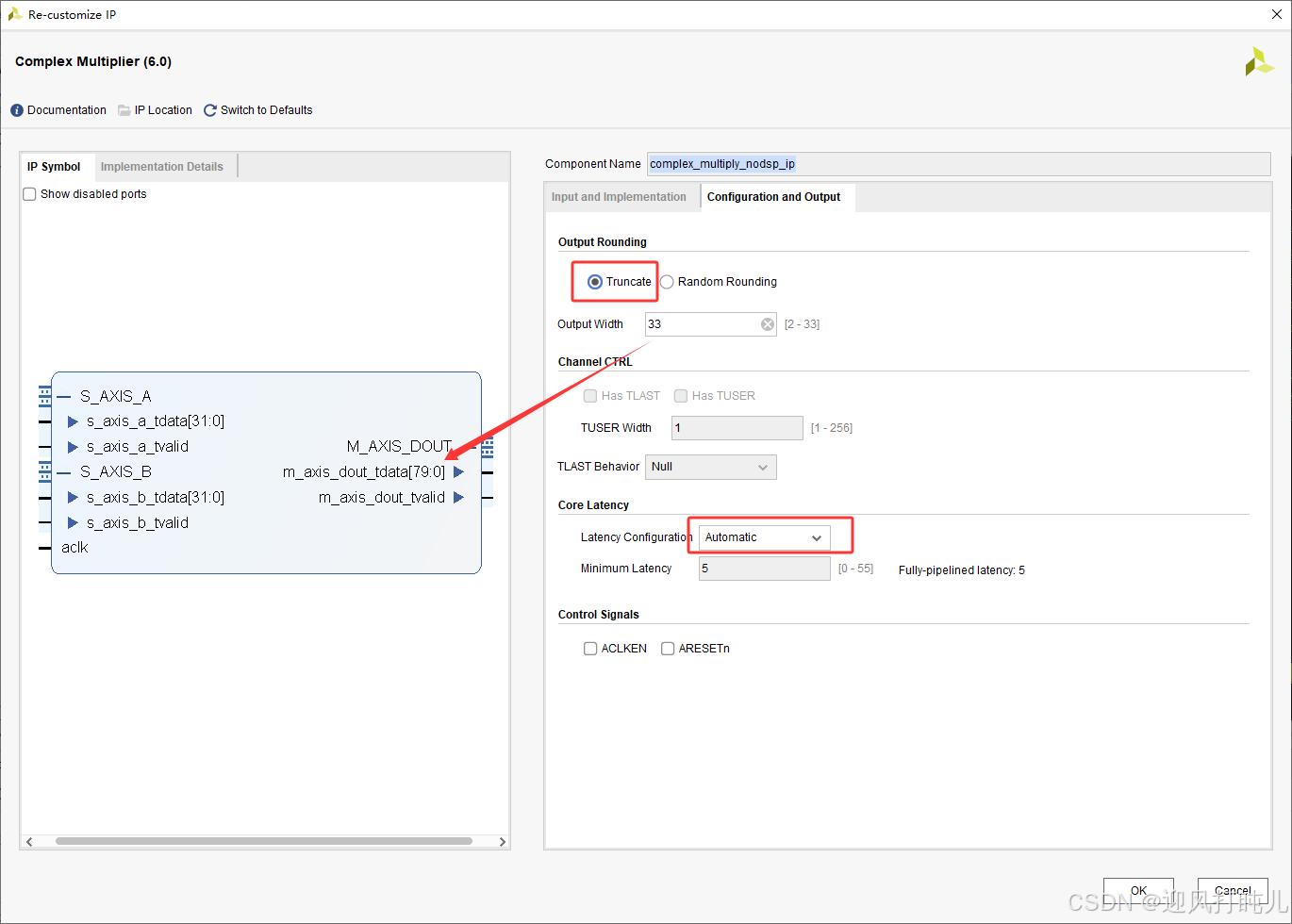
配置参数如下:
- 数据量化模式:截断模式,不新增外部控制端口;
- 输出有效位宽:实部、虚部均为 33 bit;
- 输出物理位宽:80 bit,满足 AXI4 协议字节对齐要求;
- 输出总线排布:高 40 bit 映射虚部,低 40 bit 映射实部;40 bit 位段内低 33 bit 为有效运算数据;
- 资源占用:本配置下消耗 LUT 1001 个,FF 974 个。
二、仿真验证工程实现
构建仿真模块 tb_complex_multiply_nodsp_ip,完成 IP 核功能仿真验证。
verilog
`timescale 1ns / 1ps
module tb_complex_multiply_nodsp_ip();
reg clk = 1'b1;
reg din_valid = 1'b0;
reg [15:0] real_a = 16'd0;
reg [15:0] imag_a = 16'd0;
reg [15:0] real_b = 16'd0;
reg [15:0] imag_b = 16'd0;
wire dout_valid;
wire [79:0] m_axis_dout_tdata;
wire [32:0] dout_real;
wire [32:0] dout_imag;
// 有效数据位段提取
assign dout_imag = m_axis_dout_tdata[72:40];
assign dout_real = m_axis_dout_tdata[32:0];
// 时钟生成模块
initial begin
forever #1 clk = ~clk;
end
// 测试激励生成
initial begin
#4 din_valid <= 1'b1; real_a = 16'd1; imag_a = 16'd2; real_b = 16'hFFFF; imag_b = 16'hFFFE;
#2 din_valid <= 1'b1; real_a = 16'd1; imag_a = 16'd2; real_b = 16'h3FFF; imag_b = 16'hC001;
#2 din_valid <= 1'b0; real_a = 16'd0; imag_a = 16'd0; real_b = 16'd0; imag_b = 16'd0;
#20 $finish;
end
// IP 核实例化
complex_multiply_nodsp_ip u_complex_multiply_nodsp_ip (
.aclk(clk),
.s_axis_a_tvalid(din_valid),
.s_axis_a_tdata({imag_a, real_a}),
.s_axis_b_tvalid(din_valid),
.s_axis_b_tdata({imag_b, real_b}),
.m_axis_dout_tvalid(dout_valid),
.m_axis_dout_tdata(m_axis_dout_tdata)
);
endmodule三、仿真结果与分析
仿真波形如下:
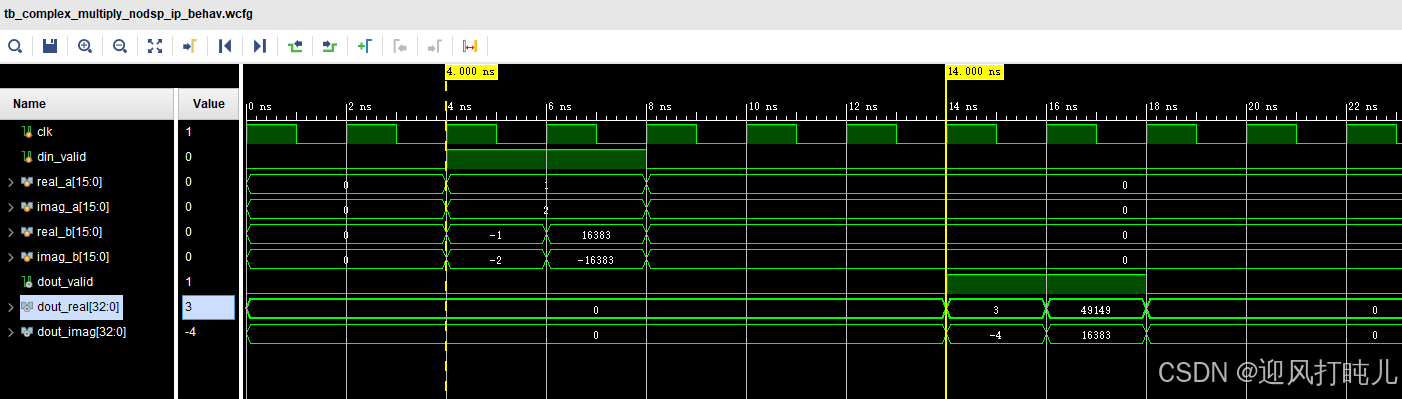

仿真结论:
- 运算输出相对输入存在 5 个时钟周期 的固定延迟;
- 运算结果与 MATLAB 理论计算值一致;
- 验证定点复数乘法器 IP 核功能正常。
总结
本文系统阐述 Xilinx Vivado 定点复数乘法器(Complex Multiplier)IP 核的全流程使用方法,包含参数配置、端口定义、数据位段排布规则及 Verilog 仿真实现。
通过仿真验证,该 IP 核可完成 16 bit 定点复数乘法运算,输出数据格式、延迟特性与理论指标匹配,可直接应用于数字信号处理与通信工程设计。
Vivado 带小数定点格式复数运算 CMPY IP 核应用
imspm 2023-10-10
一、应用背景
基于 Verilog 与 Vivado 平台实现 FFT 运算时,蝶形运算环节需要将运算中间数据与旋转因子 W N r W_N^r WNr 完成复数乘法;旋转因子取值包含小数,定点量化后需依托 Complex Multiplier(CMPY) IP 完成带小数位的复数乘算。工程实操中易出现定点小数点位错位问题,下文给出参数匹配与代码实现方案。
二、问题处理原则
定点小数运算错位的处理准则:输入、输出定点位宽与小数位配置必须一一匹配 。
三、顶层工程代码实现
verilog
`timescale 1ns / 1ns
module complex(
input [11:0] A_real,
input [11:0] A_imag,
input [11:0] B_real,
input [11:0] B_imag,
output reg [24:0] C_real,
output reg [24:0] C_imag
);
reg clk;
wire [63:0] out_data;
// 固定测试激励赋值
assign A_real = 12'b000000000000;
assign A_imag = 12'b001011001100;
assign B_real = 12'b000000000000;
assign B_imag = 12'b000010110101;
// 从AXI输出总线拆分实部、虚部有效结果
assign C_real = out_data[56:32];
assign C_imag = out_data[24:0];
// CMPY复数乘法IP实例化
cmpy_0 u_cmpy_0 (
.aclk(clk),
.s_axis_a_tvalid(1'b1),
.s_axis_a_tdata({4'd0,A_imag,4'd0,A_real}), // 32 bit总线:虚部在前、实部在后,两端补4 bit填充位
.s_axis_b_tvalid(1'b1),
.s_axis_b_tdata({4'd0,B_imag,4'd0,B_real}),
.m_axis_dout_tdata(out_data)
);
// 系统时钟生成,周期 10 ns
initial begin
clk = 1'b1;
end
always #5 clk = ~clk;
endmodule四、仿真结果
工程编译运行波形参考:
五、小结
带小数定点复数乘法的关键约束为输入量化位宽、IP配置小数位、结果截取位宽三者协同匹配;遵循位宽匹配规则可消除小数点位偏移,该配置方案适用于 FFT 旋转因子定点乘法场景。
基于 Verilog 与 Vivado 平台实现 FFT 运算时蝶形运算中的旋转因子 W N r W_N^r WNr
在基于 Verilog 与 Vivado 实现 FFT(快速傅里叶变换)时, W N r W_N^r WNr 为 FFT 蝶形运算的旋转因子(Twiddle Factor),属于复指数常数,对应单位圆上的复数,可对蝶形运算的中间数据执行相位旋转操作,是降低 DFT 运算复杂度的关键参数。
一、数学定义
旋转因子的标准数学表达式为:
W N r = e − j 2 π r N = cos ( 2 π r N ) − j sin ( 2 π r N ) W_N^r = e^{-j\frac{2\pi r}{N}} = \cos\left(\frac{2\pi r}{N}\right) - j\sin\left(\frac{2\pi r}{N}\right) WNr=e−jN2πr=cos(N2πr)−jsin(N2πr)
1.1 符号含义
- j j j :虚数单位,满足 j 2 = − 1 j^2 = -1 j2=−1,工程领域采用 j j j 以区分电学符号 i i i;
- N N N:FFT 变换点数,例如 8 点、16 点、1024 点 FFT;
- r r r :旋转因子索引,取值范围为 r = 0 , 1 , 2 , ... , N − 1 r = 0, 1, 2, \dots, N - 1 r=0,1,2,...,N−1;
- 数值特性:模长为 1 的复数,运算过程仅改变输入数据的相位,不改变幅度。
二、物理意义
- 单位复数 :模长 ∣ W N r ∣ = 1 |W_N^r| = 1 ∣WNr∣=1,与数据相乘仅执行相位旋转,不进行幅度缩放;
- 相位调整:对蝶形运算内的复数中间值执行相位旋转操作;
- 数学特性:旋转因子的周期性、对称性支撑 FFT 的分治运算结构。
三、数学性质
该类性质为 FPGA 硬件实现提供资源优化依据。
3.1 周期性
W N r + N = W N r W_N^{r + N} = W_N^r WNr+N=WNr
旋转因子序列以 N N N 为周期重复。
3.2 对称性
W N r + N / 2 = − W N r W_N^{r + N/2} = -W_N^r WNr+N/2=−WNr
序列存在对称关系,可减少存储量。
3.3 可约性
W m N m r = W N r W_{mN}^{mr} = W_N^r WmNmr=WNr
不同点数的 FFT 可复用旋转因子数值。
四、蝶形运算中的作用
FFT 基础运算单元为蝶形运算单元,2 点蝶形运算公式为:
{ X 0 = A + B ⋅ W N r X 1 = A − B ⋅ W N r \begin{cases} X_0 = A + B \cdot W_N^r \\ X_1 = A - B \cdot W_N^r \end{cases} {X0=A+B⋅WNrX1=A−B⋅WNr
4.1 功能描述
- 复数乘法 :蝶形运算需执行 B × W N r B \times W_N^r B×WNr 运算,即输入复数与旋转因子相乘;
- 数据映射:通过旋转因子完成时域数据到频域的分治运算;
- 硬件实现方式 : W N r W_N^r WNr 为固定常数,FPGA 实现时需预先计算并存储于 ROM 中。
五、示例:8 点 FFT( N = 8 N = 8 N=8)旋转因子
8 点 FFT 旋转因子计算式为:
W 8 r = cos ( 2 π r 8 ) − j sin ( 2 π r 8 ) W_8^r = \cos\left(\frac{2\pi r}{8}\right) - j\sin\left(\frac{2\pi r}{8}\right) W8r=cos(82πr)−jsin(82πr)
| r r r | W 8 r W_8^r W8r 复数形式 | 数值近似 |
|---|---|---|
| 0 | 1 − j ⋅ 0 1 - j \cdot 0 1−j⋅0 | ( 1 , 0 ) (1, 0) (1,0) |
| 1 | 2 2 − j 2 2 \dfrac{\sqrt{2}}{2} - j\dfrac{\sqrt{2}}{2} 22 −j22 | ( 0.7071 , − 0.7071 ) (0.7071, -0.7071) (0.7071,−0.7071) |
| 2 | 0 − j ⋅ 1 0 - j \cdot 1 0−j⋅1 | ( 0 , − 1 ) (0, -1) (0,−1) |
| 3 | − 2 2 − j 2 2 -\dfrac{\sqrt{2}}{2} - j\dfrac{\sqrt{2}}{2} −22 −j22 | ( − 0.7071 , − 0.7071 ) (-0.7071, -0.7071) (−0.7071,−0.7071) |
FPGA 实现采用定点数存储上述数值,例如 16 bit、32 bit 量化格式,不使用浮点数。
六、Vivado 平台中旋转因子的使用方法
6.1 旋转因子预处理与量化
- FPGA 不支持浮点运算,需将 W N r W_N^r WNr 的实部、虚部分别进行定点量化;
- 确定位宽,例如 16 bit 有符号数,1 bit 符号位、15 bit 小数位;
- 生成量化后的系数文件,格式为 .coe 或 .mif。
6.2 基于 Vivado IP 核生成旋转因子 ROM
- 打开 Vivado 工程,展开 IP Catalog ,搜索 Block Memory Generator;
- 配置 IP 类型为 Single Port ROM,设置深度与 FFT 旋转因子数量匹配;
- 加载已生成的旋转因子系数文件,完成 IP 例化;
- 综合实现后,IP 核自动映射为 FPGA 片内存储资源。
6.3 Verilog 代码调用流程
- 例化 ROM IP 核,输入地址信号对应旋转因子索引 r r r;
- 蝶形运算模块读取 ROM 输出的旋转因子实部、虚部;
- 执行复数乘法运算,运算公式为:
( a + j b ) ( c + j d ) = ( a c − b d ) + j ( a d + b c ) (a + jb)(c + jd) = (ac - bd) + j(ad + bc) (a+jb)(c+jd)=(ac−bd)+j(ad+bc)
- 将乘法结果送入蝶形运算的加法、减法单元,完成单级蝶形运算。
6.4 资源优化方案
- 依托旋转因子对称性,仅存储 N / 2 N/2 N/2 个系数,降低存储资源占用;
- 多级 FFT 运算可复用同一套旋转因子 ROM,减少硬件开销。
七、总结
- W N r W_N^r WNr 为 FFT 旋转因子,数学表达式为 W N r = cos ( 2 π r / N ) − j sin ( 2 π r / N ) W_N^r = \cos(2\pi r / N) - j\sin(2\pi r / N) WNr=cos(2πr/N)−jsin(2πr/N);
- 该参数模长为 1,与数据相乘仅执行相位旋转操作;
- FPGA 实现流程为定点量化、存储至 ROM、蝶形运算时调用并执行复数乘法;
- Vivado 可通过 Block Memory Generator IP 核实现旋转因子的存储与调用。
Xilinx Complex Multiplier(PG104)
以下是根据 EETOP 论坛讨论帖 及官方 PG104 文档整理。
一、IP 接口形态
1.1 AXI4-Stream 接口
Vivado 2016 及更新版本的 Complex Multiplier IP 仅提供 AXI4-Stream(AXIS)接口,无传统并行 Native 端口选项。输入输出统一为:
- 输入 A 通道:
s_axis_a - 输入 B 通道:
s_axis_b - 输出通道:
m_axis_dout
1.2 TDATA 数据拼接规则
关键易错点:TDATA 中数据采用高位虚部、低位实部的排布方式。
对于输入通道 A,TDATA 拼接规则为:
s_axis_a_tdata = {虚部 AI, 实部 AR}即:
- 高位段为虚部(Imaginary)
- 低位段为实部(Real)
示例:若实部和虚部各为 16 bit,则 32 bit TDATA 的位域分配为:
| 位域 | 内容 |
|---|---|
tdata[31:16] |
虚部 A I A_I AI |
tdata[15:0] |
实部 A R A_R AR |
注意:实部占用 TDATA 最低有效位,虚部从下一字节边界开始排布,空余 bit 由符号位自动填充,IP 硬件忽略空闲位。
输出通道 m_axis_dout_tdata 的排布规则与输入完全一致:高位虚部、低位实部。
1.3 常规控制信号
| 信号名 | 说明 |
|---|---|
aclk |
时钟 |
aresetn |
低电平有效同步复位 |
tvalid |
数据有效握手信号 |
tready |
从机就绪信号 |
在固定数据流场景中,通常将 tvalid 置为 1'b1 以实现连续输入。
二、输出舍入模式(Output Rounding)
当输出位宽小于全精度自然位宽时,IP 提供两种舍入/截断选项。
2.1 Truncate(截断)
原理:乘法全精度结果位宽大于配置输出位宽时,直接舍弃低位 bit,不进位。硬件逻辑最简单,不新增控制端口。
误差特性:
截断的量化误差概率密度函数(PDF)为:
p ( e ) = { 1 Δ , − Δ < e < 0 0 , otherwise p(e) = \begin{cases} \dfrac{1}{\Delta}, & -\Delta < e < 0 \\ 0, & \text{otherwise} \end{cases} p(e)=⎩ ⎨ ⎧Δ1,0,−Δ<e<0otherwise
误差的均值与方差:
m e = ∫ − Δ 0 e p ( e ) d e = − Δ 2 m_e = \int_{-\Delta}^{0} e \, p(e) \, de = -\frac{\Delta}{2} me=∫−Δ0ep(e)de=−2Δ
σ e 2 = ∫ − Δ 0 e 2 p ( e ) d e = Δ 2 3 \sigma_e^2 = \int_{-\Delta}^{0} e^2 \, p(e) \, de = \frac{\Delta^2}{3} σe2=∫−Δ0e2p(e)de=3Δ2
截断引入约 − Δ / 2 -\Delta/2 −Δ/2 的固定直流负偏置(系统误差)。在级联滤波器或 FFT 等大量级联运算场景中,误差会累积放大。
端口变化 :选中 Truncate 后,不生成 s_axis_ctrl 控制通道,例化代码无需对接 ctrl 端口。
2.2 Random Rounding(随机舍入)
2.2.1 精度优势
常规静态四舍五入(0.5 进位)仍存在微弱统计偏置。随机舍入通过随机 bit 动态选择舍 0 或进 1,使统计平均量化误差趋于 0(无直流偏置),适用于雷达、通信、FFT 等高信噪比 DSP 场景。PG104 文档推荐在高精度需求场景下选用此模式。
舍入的量化误差概率密度函数(PDF)为:
p ( e ) = { 1 Δ , − Δ 2 < e < Δ 2 0 , otherwise p(e) = \begin{cases} \dfrac{1}{\Delta}, & -\dfrac{\Delta}{2} < e < \dfrac{\Delta}{2} \\ 0, & \text{otherwise} \end{cases} p(e)=⎩ ⎨ ⎧Δ1,0,−2Δ<e<2Δotherwise
误差的均值与方差:
m e = ∫ − Δ / 2 Δ / 2 e p ( e ) d e = 0 m_e = \int_{-\Delta/2}^{\Delta/2} e \, p(e) \, de = 0 me=∫−Δ/2Δ/2ep(e)de=0
σ e 2 = ∫ − Δ / 2 Δ / 2 e 2 p ( e ) d e = Δ 2 12 \sigma_e^2 = \int_{-\Delta/2}^{\Delta/2} e^2 \, p(e) \, de = \frac{\Delta^2}{12} σe2=∫−Δ/2Δ/2e2p(e)de=12Δ2
2.2.2 s_axis_ctrl_tdata[7:0] 作用
端口触发条件:仅选择 Random Rounding 时才生成 CTRL AXIS 通道,Truncate 模式下无此端口。
tdata 的有效位定义:
s_axis_ctrl_tdata[0](ROUND_CY):舍入进位控制位s_axis_ctrl_tdata[7:1]:无效,可任意填 0
ROUND_CY 取值含义:
tdata[0] |
舍入行为 |
|---|---|
| 0 | 向负无穷截断(round-down) |
| 1 | 向上进位舍入 |
随机舍入的实现方式:每一拍输入 1 bit 随机电平到 tdata[0],使 0/1 概率各为 50%,从而实现无偏置舍入。
2.2.3 CTRL 端口赋值方案
| 方案 | s_axis_ctrl_tdata 赋值 |
适用场景 |
|---|---|---|
| 简易静态 | 固定 8'h00(bit0 恒为 0) |
非极致精度需求、快速调试,近似普通向下舍入 |
| 标准随机 | bit0 接入分频时钟或伪随机码(LFSR),高低电平交替随机 |
正式产品、需要零偏置高精度运算 |
补充 :
s_axis_ctrl_tvalid通常接1'b1,保证每一拍乘法都获取到舍入控制位。
PG104 文档推荐的随机源包括:
- 时钟二分频触发器(50% 占空比)
- 与运算结果分数部分不相关的任意随机信号
- 复数乘法器输入操作数之一的最低有效位(LSB)
三、输出位宽配置
3.1 全精度自然位宽
复数乘法的全精度自然输出位宽为:
W out,natural = W A + W B + 1 W_{\text{out,natural}} = W_A + W_B + 1 Wout,natural=WA+WB+1
其中 W A W_A WA 和 W B W_B WB 分别为操作数 A 和 B 的位宽(实部/虚部各为 W A W_A WA bit 和 W B W_B WB bit)。
当输出位宽等于自然位宽时,无任何舍入/截断选项,IP 保留全部运算 bit,无精度丢失。
3.2 自定义缩窄输出位宽
当输出位宽小于自然位宽时,启用 Truncate 或 Random Rounding。位宽减少 N N N 位即舍弃 N N N 个最低有效位。
注意:设置输出位宽过小时,会出现输出整体等比例缩小的现象。调试时应优先增大输出位宽复测结果。
四、IP 硬件实现选型(Multiplier Construction)
4.1 乘法器结构
| 选项 | 说明 | 资源占用 | 时钟频率 |
|---|---|---|---|
| Use Mults(默认) | 调用 FPGA 内部 DSP48E 资源做乘法 | DSP Slice 少 | 高 |
| Use LUTs | 仅用逻辑 LUT 搭建乘法 | Slice 资源大量占用 | 低 |
4.2 优化目标(Optimization Goal)
- Performance:优先实现高频工作,始终使用 4 实数乘法结构
- Resources:优先节省 DSP 资源,在 3 乘法结构资源更优时使用 3 乘法结构,否则使用 4 乘法结构
4.3 三乘法与四乘法方案
- 三实数乘法方案:利用 DSP Slice 的前置加法器,节省通用 fabric 资源,但使用更多 Slice 资源(LUT/FF),最高时钟频率低于四乘法方案
- 四实数乘法方案:最大化利用 DSP Slice 资源,时钟频率性能更高,在许多情况下可达到器件 DSP Slice 的最高时钟频率
- LUT 方案:仅使用 LUT 实现,Slice 资源消耗显著,最高时钟频率低,功耗高于 DSP Slice 实现,适用于 DSP Slice 资源受限或时钟频率要求较低的场景
注意:选择 LUT 实现时,三乘法配置被强制使用。
五、常见问题与解决方案
5.1 Truncate 仿真结果与手动计算不符、整体偏小
原因:输出位宽设置过小 + 直接截断丢失低位。
解决:
- 增大 Output Width 至全精度位宽
- 或改用 Random Rounding 消除偏置
5.2 Random Rounding 新增 s_axis_ctrl 端口,接线不明确
临时调试 :s_axis_ctrl_tdata = 8'd0,tvalid = 1'b1
量产方案 :LFSR 生成随机 bit 接入 tdata[0]
5.3 实虚部数据算反
原因 :{实部, 虚部} 错误拼接,IP 规定必须为 {虚部, 实部}。
修正 :tdata = {I, R}
六、Verilog 例化模板
6.1 Truncate 模式
verilog
complex_mult MULT_TRUNC (
.aclk (clk),
.aresetn (rst_n),
.s_axis_a_tvalid (dataa_valid),
.s_axis_a_tdata ({dataa_i, dataa_r}), // {虚部, 实部}
.s_axis_b_tvalid (datab_valid),
.s_axis_b_tdata ({datab_i, datab_r}), // {虚部, 实部}
.m_axis_dout_tvalid (data_out_valid),
.m_axis_dout_tdata ({data_out_i, data_out_r}) // {虚部, 实部}
);6.2 Random Rounding 模式(含 CTRL 通道)
verilog
complex_mult MULT_RND (
.aclk (clk),
.aresetn (rst_n),
.s_axis_a_tvalid (dataa_valid),
.s_axis_a_tdata ({dataa_i, dataa_r}),
.s_axis_b_tvalid (datab_valid),
.s_axis_b_tdata ({datab_i, datab_r}),
.s_axis_ctrl_tvalid (1'b1),
.s_axis_ctrl_tdata ({7'b0, rounding_cy}), // bit[0] = 随机舍入控制
.m_axis_dout_tvalid (data_out_valid),
.m_axis_dout_tdata ({data_out_i, data_out_r})
);说明 :
rounding_cy建议接入 50% 占空比的随机信号源(如 LFSR 最低位或时钟二分频输出)。
七、参考文档
- PG104 :LogiCORE IP Complex Multiplier v6.0 Product Guide (2013-12-18)
- 舍入模式、CTRL 端口规范、位宽规则的原始定义来源
- 随机舍入随机源推荐:时钟二分频生成 0/1 交替电平
Xilinx 复数乘法 IP 文后讨论
一、流水线延迟与吞吐量
1.1 延迟来源
Xilinx 复数乘法 IP(Complex Multiplier LogiCORE,文档编号 PG104)内部采用流水线(Pipeline)架构 ,将完整运算拆分为多个时钟周期分步执行。根据官方文档,延迟(Latency)为可配置参数:
- Automatic 模式:IP 自动设置为全流水线架构,以获得最大性能
- Manual 模式:用户可手动指定最小延迟值;若设定值小于全流水线所需延迟,性能下降;若大于全流水线延迟,IP 使用 SRL 延迟输出
在论坛讨论中提到的"延迟 3 拍"(第 1 拍输入 → 第 4 拍输出),对应特定配置下的全流水线延迟。具体延迟拍数取决于:
- 输入位宽
- 实现方案(3 乘法器 / 4 乘法器)
- 资源选择(DSP Slice / LUT)
- 是否启用舍入
1.2 流水线特性
流水线架构保证数据流连续不间断:
| 时钟周期 | 输入数据 | 输出数据 |
|---|---|---|
| 1 | 数据 D 1 D_1 D1 | --- |
| 2 | 数据 D 2 D_2 D2 | --- |
| 3 | 数据 D 3 D_3 D3 | --- |
| 4 | 数据 D 4 D_4 D4 | D 1 D_1 D1 结果 |
| 5 | 数据 D 5 D_5 D5 | D 2 D_2 D2 结果 |
| 6 | 数据 D 6 D_6 D6 | D 3 D_3 D3 结果 |
吞吐量恒为 1 数据/时钟周期,延迟为固定值,与输入数据速率无关。
1.3 工程注意事项
- 仿真时必须等待足够延迟周期才能获取正确结果
- 若使用 Blocking 流控模式,延迟不固定,仅可指定最小延迟值
- 3 乘法器方案通常延迟较长,但节省 DSP 资源;4 乘法器方案延迟较短,时钟频率更高
二、输入数据格式
2.1 有符号数要求
复数乘法 IP 强制使用有符号数(Signed),原因如下:
- 复数乘法运算中 j × j = − 1 j \times j = -1 j×j=−1,结果包含负数
- 只有有符号数(二进制补码表示)才能正确表示负数
- IP 硬件逻辑强制采用有符号运算,无法配置为无符号模式
官方文档明确指出:"Within each channel, operands and the results are represented in signed two's complement format."
2.2 补码输入
负数输入必须采用**二进制补码(Two's Complement)**格式:
- 正数:原码表示
- 负数:按位取反后加 1
- 例如:8 位有符号数中, − 3 -3 −3 表示为 11111101 2 11111101_2 111111012
三、顶层模块功能
顶层模块(Top-Level Module)的作用为:
- 封装调用 Xilinx 复数乘法器 IP 核
- 提供接口:时钟(ACLK)、复位(ARESETn)、数据输入(TDATA)、数据输出(TDATA)
- 完成功能 :输入两个复数 A = a r + j a i A = a_r + j a_i A=ar+jai 和 B = b r + j b i B = b_r + j b_i B=br+jbi,计算乘积 P = A × B = p r + j p i P = A \times B = p_r + j p_i P=A×B=pr+jpi
- 作为入口:工程中使用该模块作为复数乘法的调用接口
复数乘法运算公式:
4 乘法器直接实现:
p r = a r b r − a i b i p i = a r b i + a i b r p_r = a_r b_r - a_i b_i \\ p_i = a_r b_i + a_i b_r pr=arbr−aibipi=arbi+aibr
3 乘法器优化方案:
p r = a r ( b r + b i ) − ( a r + a i ) b i p i = a r ( b r + b i ) + ( a i − a r ) b r p_r = a_r (b_r + b_i) - (a_r + a_i) b_i \\ p_i = a_r (b_r + b_i) + (a_i - a_r) b_r pr=ar(br+bi)−(ar+ai)bipi=ar(br+bi)+(ai−ar)br
3 乘法器方案利用 DSP Slice 的预加器(Pre-Adder)节省一个乘法器,但增加预组合加法器并扩展乘法器位宽,通常延迟较长且时钟频率较低。
四、TDATA 保留位确定方法
4.1 快速查看法
在 Vivado 中:
- 双击打开复数乘法 IP
- 切换至 Implementation Details 标签页
- 直接查看 TDATA 位域定义及未使用位信息
4.2 标准文档法
查阅官方手册 PG104(Complex Multiplier LogiCORE IP Product Guide):
- 文档中明确规定 TDATA 的位域结构
- 包含 A、B 输入通道和 DOUT 输出通道的 TDATA 格式
- 未使用位由 IP 内部实现结构决定,非随意定义
TDATA 格式示例(多通道数据):
TDATA = {Imaginary_Part, Real_Part}数据按字节对齐,不额外增加逻辑资源。AXI4-Stream 接口支持多通道 TDATA 拆分,实部与虚部分别映射至 TDATA 的不同字段。
五、官方文档获取方法
- 打开 Vivado 设计套件
- 在 IP Catalog 中找到并双击复数乘法 IP
- 在 Customize IP 界面左上角点击 Documentation
- 直接下载对应版本的官方手册(PG104)
六、代码调试排查思路
无输出/无结果的常见原因及排查方向:
| 排查项 | 检查内容 |
|---|---|
| 延迟等待 | 是否等待足够时钟周期(取决于配置,通常 3~6 拍) |
| 实虚部顺序 | 输入数据实部与虚部是否写反 |
| 位宽匹配 | 输入/输出位宽是否与 IP 配置一致 |
| 握手信号 | AXI4-Stream 的 TVALID / TREADY 信号是否正常交互 |
| 时钟复位 | 时钟频率是否满足要求,复位信号 ARESETn 是否正确释放(需保持至少 2 个时钟周期) |
| 数据格式 | 是否采用有符号补码格式输入 |
| 舍入配置 | 若使用舍入模式,ROUND_CY 信号是否正确连接 |
七、IP 关键参数速查
| 参数 | 说明 |
|---|---|
| 输入位宽 | 8 bit ~ 63 bit(实部与虚部等宽) |
| 输出位宽 | 最高 127 bit |
| 延迟配置 | Automatic(全流水线)/ Manual(手动指定最小延迟) |
| 实现方式 | 3 乘法器方案 / 4 乘法器方案 |
| 资源选择 | DSP48 Slice / LUT |
| 舍入模式 | 截断(Truncation)/ 无偏舍入(Unbiased Rounding) |
| 接口协议 | AXI4-Stream |
| 数据格式 | 有符号二进制补码 |
| 控制信号 | ACLKEN(时钟使能)、ARESETn(低电平有效同步复位) |
八、舍入与量化
8.1 截断(Truncation)
直接舍弃低位,硬件实现零成本,但引入 − Δ / 2 -\Delta/2 −Δ/2 的均值误差和 Δ 2 / 12 \Delta^2/12 Δ2/12 的方差。
8.2 无偏舍入(Unbiased Rounding)
通过添加舍入常数并随机化阈值(使用 ROUND_CY 信号)消除 DC 偏置。理想舍入器均值为 0,方差为 Δ 2 / 12 \Delta^2/12 Δ2/12。
对于 DSP Slice 实现,舍入常数加法通常"免费"------利用 C 端口和进位输入即可实现。
流水线延迟
时钟周期 1、2、3 没有输出数据,是因为流水线(Pipeline)架构的固有延迟特性。
复数乘法 IP 内部将一次完整运算拆分为多个步骤,每个步骤占用一个时钟周期。以论坛讨论中提到的"延迟 3 拍"为例:
| 时钟周期 | 流水线第 1 级 | 流水线第 2 级 | 流水线第 3 级 | 输出 |
|---|---|---|---|---|
| 1 | D 1 D_1 D1 进入,执行步骤 A | --- | --- | 无 |
| 2 | D 2 D_2 D2 进入,执行步骤 A | D 1 D_1 D1 进入步骤 B | --- | 无 |
| 3 | D 3 D_3 D3 进入,执行步骤 A | D 2 D_2 D2 进入步骤 B | D 1 D_1 D1 进入步骤 C | 无 |
| 4 | D 4 D_4 D4 进入,执行步骤 A | D 3 D_3 D3 进入步骤 B | D 2 D_2 D2 进入步骤 C | D 1 D_1 D1 结果输出 |
- 周期 1 : D 1 D_1 D1 刚进入第 1 级,只完成了部分运算(如预加/预减),结果尚未产生
- 周期 2 : D 1 D_1 D1 进入第 2 级继续运算(如乘法),但仍未完成
- 周期 3 : D 1 D_1 D1 进入第 3 级进行最终运算(如后加/后减),结果刚产生但尚未到达输出端口
- 周期 4 : D 1 D_1 D1 的结果才从输出端口送出
延迟 ≠ 空闲
虽然前 3 个周期没有输出,但 IP 内部一直在满负荷工作:
- 周期 1:第 1 级在处理 D 1 D_1 D1
- 周期 2:第 1 级在处理 D 2 D_2 D2,第 2 级在处理 D 1 D_1 D1
- 周期 3:第 1 级在处理 D 3 D_3 D3,第 2 级在处理 D 2 D_2 D2,第 3 级在处理 D 1 D_1 D1
从周期 4 开始,每个周期都会输出一个结果 ( D 1 D_1 D1、 D 2 D_2 D2、 D 3 D_3 D3......),吞吐量恒为 1 数据/时钟周期。
reference
-
vivado 中复数乘法器的 ip 核调用及其仿真的详细介绍_vivado 复数乘法器 ip 核-CSDN 博客
https://blog.csdn.net/weixin_45159528/article/details/122797490
-
vivado 中复数乘法器 IP 核使用小结_vivado 复数绝对值-CSDN 博客
-
Xilinx Vivado 复数乘法器 Complex Multiplier IP 核调用及其仿真-CSDN 博客
-
Vivado IP 核之定点复数乘法器 Complex Multiplier 使用说明_complex multiplier ip核-CSDN博客
-
Vivado 中复数运算 ip 核的使用(带小数) - 超级产品经理
-
xilinx 复数乘法器的一个疑问。 - 数字 IC 设计讨论(IC 前端| FPGA|ASIC) - EETOP 创芯网论坛 (原名:电子顶级开发网) - 2017
-
Complex Multiplier