目录
-
- 一、项目概述
- 二、数据库设计(PlantUML)
-
-
- [模块一:用户体系(2 张表)](#模块一:用户体系(2 张表))
- [模块二:小说内容(3 张表)](#模块二:小说内容(3 张表))
- [模块三:用户交互(4 张表)](#模块三:用户交互(4 张表))
- [模块四:创作系统(2 张表)](#模块四:创作系统(2 张表))
- [模块五:系统运营(4 张表)](#模块五:系统运营(4 张表))
- 核心外键关系速查
-
- 三、核心功能实现
-
- [3.1 用户认证(注册 / 登录 / JWT 鉴权)](#3.1 用户认证(注册 / 登录 / JWT 鉴权))
- [3.2 小说浏览与分类展示](#3.2 小说浏览与分类展示)
- [3.3 小说搜索](#3.3 小说搜索)
- [3.4 阅读器与阅读进度追踪](#3.4 阅读器与阅读进度追踪)
- [3.5 作者申请与审批](#3.5 作者申请与审批)
- [3.6 草稿创作与发布](#3.6 草稿创作与发布)
- [3.7 AI 自动审核系统](#3.7 AI 自动审核系统)
- [3.8 AI 写作助手](#3.8 AI 写作助手)
- [3.9 TXT 文件上传与章节解析](#3.9 TXT 文件上传与章节解析)
- [3.10 前端 SPA 页面切换](#3.10 前端 SPA 页面切换)
- 四、功能架构总览
- 五、总结与未来展望
-
- 未来可用哪些技术完善
-
- [1. 前端工程化](#1. 前端工程化)
- [2. 后端架构升级](#2. 后端架构升级)
- [3. 搜索和推荐能力](#3. 搜索和推荐能力)
- [4. AI 能力深化](#4. AI 能力深化)
- [5. 运维与部署](#5. 运维与部署)
- 优化优先级建议
这是一个基于 FastAPI + MySQL + 纯前端的网络小说阅读与创作平台,集成 AI 写作助手与自动审核系统。
一、项目概述
通阅小说是一个功能完整的网络小说平台,支持读者阅读 和作者创作两条核心业务线。项目采用前后端分离架构,后端提供 RESTful API,前端通过 Axios 调用接口完成交互。
技术栈:
| 层级 | 技术 | 作用 |
|---|---|---|
| 后端框架 | Python FastAPI | 异步 API 框架 |
| 数据库 | MySQL 8.0 + SQLAlchemy (async) | 数据持久化 |
| 认证 | JWT + bcrypt | 用户登录鉴权 |
| 前端 | HTML + CSS + JavaScript + Axios | 页面展示与交互 |
| AI 能力 | Dify(聊天 API + 工作流 API) | 写作助手 + 自动审核 |
| 文件存储 | 本地文件系统 | 封面、头像、TXT 上传 |
二、数据库设计(PlantUML)
以下是核心数据表的关系图。
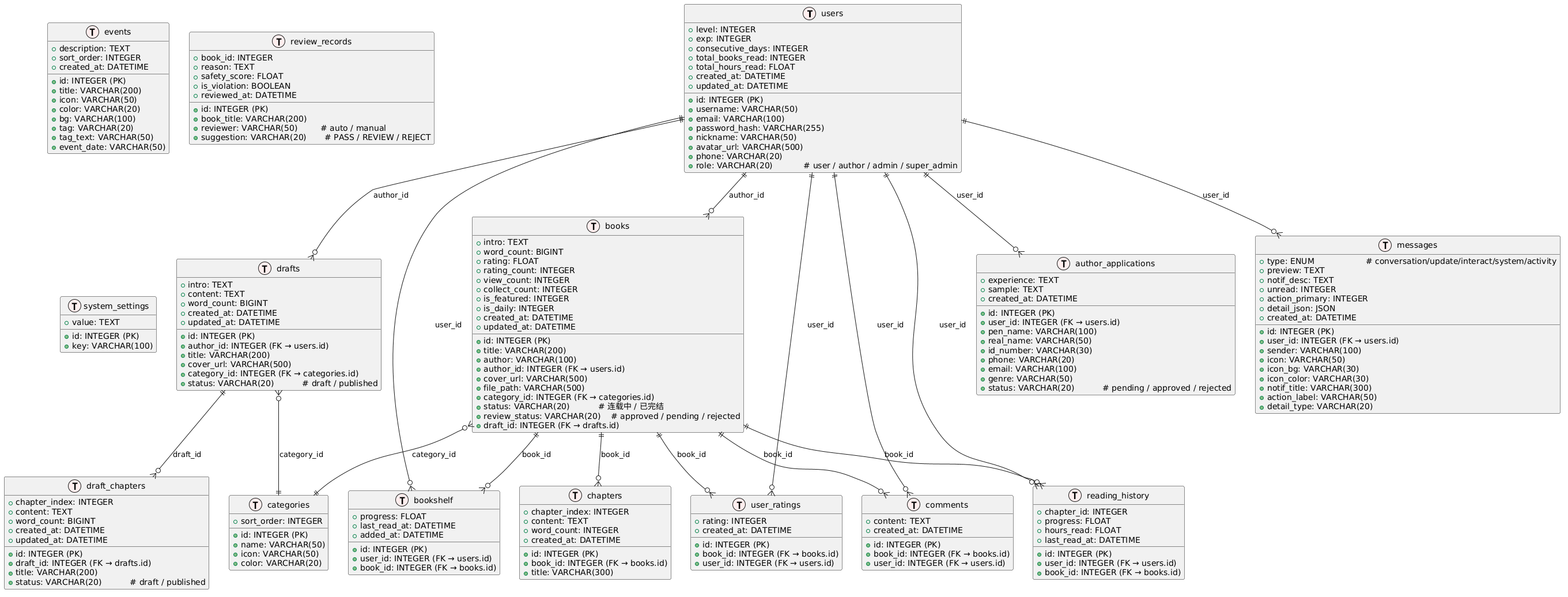
模块一:用户体系(2 张表)
users(用户表) author_applications(作者申请表)
┌──────────────────────┐ ┌──────────────────────────┐
│ id (PK) │──┐ │ id (PK) │
│ username │ │ │ user_id (FK) │──→ users.id
│ email │ └──────│ pen_name │
│ password_hash │ │ real_name / id_number │
│ role │ │ genre / experience │
│ nickname / avatar_url │ │ sample(试读样本) │
│ level / exp │ │ status(pending/approved/rejected)
│ created_at / updated_at│ │ created_at │
└──────────────────────┘ └──────────────────────────┘关系说明:
users.role有四个级别:user→author→admin→super_admin,控制不同权限author_applications.user_id→users.id,一个用户只能有一条被批准的申请- 审批通过时,后端同时更新
author_applications.status = approved和users.role = author
模块二:小说内容(3 张表)
books(书籍表) chapters(章节表)
┌────────────────────────┐ ┌──────────────────────────┐
│ id (PK) │──┐ │ id (PK) │
│ title / author / intro │ │ │ book_id (FK) │──→ books.id
│ author_id (FK) │──┘ │ title / content │
│ category_id (FK) │──┐ │ chapter_index(排序用) │
│ status(连载中/已完结) │ │ │ word_count │
│ review_status(审核状态) │ │ │ created_at │
│ word_count / rating │ │ └──────────────────────────┘
│ view_count / collect │ │
│ is_featured / is_daily │ │ categories(分类表)
│ draft_id (FK) │ │ ┌──────────────────────────┐
│ created_at / updated_at│ │ │ id (PK) │
└────────────────────────┘ │ │ name(玄幻/仙侠/都市...) │
│ │ icon / color / sort_order│
└─────│ category_id (FK) │
└──────────────────────────┘关系说明:
books.author_id→users.id:一本书只有一个作者,一个作者可以写多本书books.category_id→categories.id:一本书属于一个分类chapters.book_id→books.id:一章属于一本书,CASCADE 删除(书删了所有章节自动删)chapter_index决定章节顺序,不是依赖 idreview_status控制作品可见性:只有approved的书才会出现在读者端is_featured和is_daily用于首页推荐位控制
模块三:用户交互(4 张表)
bookshelf(书架) reading_history(阅读历史)
┌──────────────────┐ ┌──────────────────────────┐
│ id (PK) │ │ id (PK) │
│ user_id (FK) │──→ users│ user_id (FK) │──→ users.id
│ book_id (FK) │──→ books│ book_id (FK) │──→ books.id
│ progress(阅读进度)│ │ chapter_id(当前章节) │
│ last_read_at │ │ progress / hours_read │
│ added_at │ │ last_read_at │
└──────────────────┘ └──────────────────────────┘
comments(评论) user_ratings(评分)
┌──────────────────┐ ┌──────────────────────────┐
│ id (PK) │ │ id (PK) │
│ book_id (FK) │──→ books│ book_id (FK) │──→ books.id
│ user_id (FK) │──→ users│ user_id (FK) │──→ users.id
│ content(TEXT) │ │ rating(1-5 分) │
│ created_at │ │ created_at │
└──────────────────┘ │ UNIQUE(book_id, user_id) │
└──────────────────────────┘关系说明:
- 这四张表都通过外键关联到
users和books,构成用户和书籍之间的多对多关系 user_ratings有联合唯一约束(book_id, user_id),确保一人一评bookshelf和reading_history的区别:书架是"收藏列表",阅读历史是"阅读轨迹"books.collect_count和books.rating是反范式设计的冗余字段,避免每次 COUNT 查询
模块四:创作系统(2 张表)
drafts(草稿) draft_chapters(草稿章节)
┌──────────────────────┐ ┌──────────────────────────┐
│ id (PK) │──┐ │ id (PK) │
│ author_id (FK) │──┘ │ draft_id (FK) │──→ drafts.id
│ title / intro │ │ title │
│ cover_url │ │ chapter_index │
│ category_id (FK) │ │ content(TEXT) │
│ status(draft/published)│ │ word_count │
│ word_count │ │ status(draft/published) │
│ created_at/updated_at│ │ created_at / updated_at │
└──────────────────────┘ └──────────────────────────┘关系说明:
- 草稿表和正式表结构镜像------
drafts≈books,draft_chapters≈chapters - 作者发布作品时,后端将草稿数据复制到正式表,而不是移动(保留草稿副本)
- 发布后
books.draft_id指向草稿,便于追溯 - 作者在草稿阶段可自由增删改章节,不影响正式内容
模块五:系统运营(4 张表)
messages(消息通知) events(活动管理)
┌──────────────────────┐ ┌──────────────────────────┐
│ id (PK) │ │ id (PK) │
│ user_id (FK) │ │ title / description │
│ sender / type │ │ icon / color / bg │
│ preview / notif_title │ │ tag(ongoing/ended) │
│ notif_desc / unread │ │ event_date / sort_order │
│ created_at │ │ created_at │
└──────────────────────┘ └──────────────────────────┘
review_records(审核记录) system_settings(系统设置)
┌──────────────────────┐ ┌──────────────────────────┐
│ id (PK) │ │ id (PK) │
│ book_id │ │ key(唯一键) │
│ book_title │ │ value(TEXT 存储值) │
│ reviewer(auto/manual)│ │ │
│ suggestion(PASS/REVIEW/REJECT)│ │
│ reason / safety_score│ │ 键值对结构,如: │
│ is_violation │ │ auto_review → true/false │
│ reviewed_at │ │ site_name → 通阅小说 │
└──────────────────────┘ └──────────────────────────┘关系说明:
messages.user_id→users.id:通知定向推送给用户review_records不设外键(因为审核时要记录已删除的书籍信息),book_id是普通索引system_settings使用键值对设计,灵活存储配置项,不需要改表结构就能加新配置
核心外键关系速查
| 外键 | 源表 | 目标表 | 级联策略 | 含义 |
|---|---|---|---|---|
author_id |
books | users | SET NULL | 作者被删,书籍保留但 author_id 置空 |
book_id |
chapters | books | CASCADE | 书被删,所有章节自动删除 |
book_id |
comments | books | CASCADE | 书被删,所有评论自动删除 |
book_id |
bookshelf | books | CASCADE | 书被删,书架项自动删除 |
user_id |
bookshelf | users | CASCADE | 用户注销,书架项自动删除 |
draft_id |
draft_chapters | drafts | CASCADE | 草稿删,草稿章节自动删 |
category_id |
books | categories | SET NULL | 分类删,书籍的 category_id 置空 |
所有外键中,CASCADE 用于"附属数据"(章节、评论),SET NULL 用于"可选关联"(作者、分类)。
三、核心功能实现
3.1 用户认证(注册 / 登录 / JWT 鉴权)
功能描述: 用户注册时校验用户名合法性、邮箱格式、密码强度,密码加密后存库。登录时验证密码,发放 JWT Token。前端将 Token 存入 sessionStorage,后续请求通过 Axios 拦截器自动携带。
核心实现: 密码使用 hash_password 和 verify_password 处理,JWT 用 python-jose 库生成和解析。
python
# app/utils/security.py
from passlib.context import CryptContext
from jose import jwt
from datetime import datetime, timedelta
pwd_context = CryptContext(schemes=["bcrypt"], deprecated="auto")
def hash_password(password: str) -> str:
return pwd_context.hash(password)
def verify_password(plain: str, hashed: str) -> bool:
return pwd_context.verify(plain, hashed)
def create_access_token(data: dict) -> str:
to_encode = data.copy()
expire = datetime.utcnow() + timedelta(days=7)
to_encode.update({"exp": expire})
return jwt.encode(to_encode, SECRET_KEY, algorithm=ALGORITHM)登录接口(后端):
python
# app/routers/auth.py
@router.post("/login")
async def login(req: LoginRequest, db: AsyncSession = Depends(get_db)):
result = await db.execute(
select(User).where((User.username == req.username) | (User.email == req.username))
)
user = result.scalars().first()
if not user or not verify_password(req.password, user.password_hash):
raise HTTPException(status_code=401, detail="用户名或密码错误")
token = create_access_token({"user_id": user.id, "username": user.username})
return TokenResponse(token=token, user={...})前端 Axios 拦截器(自动携带 Token):
javascript
// forward/js/api.js
const api = axios.create({
baseURL: 'http://127.0.0.1:8000/api',
timeout: 10000,
headers: { 'Content-Type': 'application/json' }
});
api.interceptors.request.use(config => {
const token = sessionStorage.getItem('token');
if (token) {
config.headers.Authorization = 'Bearer ' + token;
}
return config;
});涉及到 users 表------注册时 INSERT,登录时 SELECT,密码以 bcrypt 哈希形式存储,不存明文。
3.2 小说浏览与分类展示
功能描述: 首页展示推荐作品和每日精选,支持按分类筛选、按热度/评分/时间排序。
核心实现: 后端根据查询参数动态构建 SQL 查询,返回书籍列表。前端渲染卡片式展示。
python
# app/routers/books.py
@router.get("/books")
async def get_books(
featured: bool | None = None,
daily: bool | None = None,
sort: str = "hot",
limit: int = 10,
db: AsyncSession = Depends(get_db),
):
q = select(Book).where(Book.review_status == "approved")
if featured:
q = q.where(Book.is_featured == 1)
if daily:
q = q.where(Book.is_daily == 1)
if sort == "new":
q = q.order_by(Book.created_at.desc())
elif sort == "rating":
q = q.order_by(Book.rating.desc())
else:
q = q.order_by(Book.view_count.desc())
result = await db.execute(q.limit(limit))
return [BookOut.from_orm(b) for b in result.scalars().all()]涉及到 books 和 categories 表。category_id 作为外键关联分类名称。
3.3 小说搜索
功能描述: 按书名或作者名模糊搜索已审核通过的小说。
python
# app/routers/search.py
@router.get("/search")
async def search(q: str = Query(..., min_length=1), db: AsyncSession = Depends(get_db)):
keyword = f"%{q}%"
result = await db.execute(
select(Book)
.where(Book.review_status == "approved",
(Book.title.like(keyword)) | (Book.author.like(keyword)))
.limit(20)
)
return [{"id": b.id, "title": b.title, "author": b.author, ...} for b in result.scalars().all()]核心是 SQL 的 LIKE %keyword% 模糊匹配,在 books 表的 title 和 author 字段上做搜索。
3.4 阅读器与阅读进度追踪
功能描述: 点击书籍进入详情页,查看章节列表,点击章节进入阅读器。阅读时自动记录当前章节和进度。
python
# app/routers/user.py(阅读历史)
@router.post("/user/history")
async def save_history(data: ..., user: User = Depends(get_current_user), db: AsyncSession = Depends(get_db)):
record = ReadingHistory(
user_id=user.id,
book_id=data.book_id,
chapter_id=data.chapter_id,
progress=data.progress,
hours_read=data.hours_read,
)
db.add(record)
await db.commit()书架管理:
python
@router.post("/user/bookshelf")
async def add_to_bookshelf(data: ..., user: User = Depends(get_current_user), db: AsyncSession = Depends(get_db)):
item = Bookshelf(user_id=user.id, book_id=data.book_id)
db.add(item)
await db.commit()
# 同时增加 books 表的 collect_count
book = await db.get(Book, data.book_id)
book.collect_count = (book.collect_count or 0) + 1
await db.commit()涉及到 reading_history、bookshelf、comments、user_ratings 四张表,均通过外键关联到 users 和 books。user_ratings 设置了联合唯一约束 (book_id, user_id),确保一个用户对一本书只能评一次分。
3.5 作者申请与审批
功能描述: 普通用户提交作者申请,填写笔名、真实姓名、试读样本等。管理员审核通过后,用户的角色从 user 升级为 author。
提交申请:
python
# app/routers/author.py
@router.post("/author/apply")
async def submit_application(req: ..., user: User = Depends(get_current_user), db: AsyncSession = Depends(get_db)):
app = AuthorApplication(
user_id=user.id,
pen_name=req.pen_name,
real_name=req.real_name,
sample=req.sample,
genre=req.genre,
)
db.add(app)
await db.commit()
return {"message": "申请已提交"}管理员审批(核心代码):
python
@router.post("/admin/applications/{app_id}/approve")
async def approve_application(app_id: int, admin: User = Depends(require_admin), db: AsyncSession = Depends(get_db)):
app = await db.get(AuthorApplication, app_id)
app.status = "approved"
# 关键:同时更新用户角色
user = await db.get(User, app.user_id)
user.role = "author"
await db.commit()
return {"message": "已批准"}涉及到 author_applications 和 users 两张表。审批的本质是事务性地更新两条记录------application 的状态和 user 的角色。
3.6 草稿创作与发布
功能描述: 作者在创作中心创建草稿作品,分章节写作,支持新增、编辑、删除、排序章节。完成后提交审核发布。
草稿数据结构: 作品发布前,数据存在 drafts 和 draft_chapters 两张表,结构与 books + chapters 一致但相互独立。
前端新建章节:
javascript
// forward/js/api.js
function apiAuthorAddWorkChapter(bookId, title) {
return api.post(`/author/works/${bookId}/chapters`, { title });
}
function apiAuthorUpdateWorkChapter(bookId, chapterId, data) {
return api.put(`/author/works/${bookId}/chapters/${chapterId}`, data);
}发布流程(后端核心逻辑):
python
@router.post("/author/publish-draft")
async def publish_draft(draft_id: int, user: User = Depends(...), db: AsyncSession = Depends(get_db)):
draft = await db.get(Draft, draft_id)
draft.status = "published"
# 创建正式书籍记录
book = Book(
title=draft.title, intro=draft.intro, author_id=user.id,
category_id=draft.category_id, draft_id=draft.id,
review_status="pending", # 待审核
)
db.add(book)
await db.flush()
# 复制草稿章节到正式章节表
chapters = await db.execute(select(DraftChapter).where(...).order_by(DraftChapter.chapter_index))
for dc in chapters.scalars().all():
db.add(Chapter(book_id=book.id, title=dc.title,
chapter_index=dc.chapter_index, content=dc.content))
await db.commit()发布后,books.review_status 设为 pending,触发下一节的自动审核流程。
3.7 AI 自动审核系统
功能描述: 后台定时任务每 30 秒扫描待审核作品,调用 Dify 工作流 API 进行内容安全检测,根据结果自动更新审核状态并通知作者。
核心代码(后台定时任务):
python
# app/services/auto_review.py
async def _review_single_book(db, book: Book):
# 1. 取前 5000 字
chapters = await db.execute(select(Chapter).where(Chapter.book_id == book.id).order_by(Chapter.chapter_index))
content = "\n".join(ch.content for ch in chapters.scalars().all() if ch.content)[:5000]
# 2. 调用 Dify 工作流
async with httpx.AsyncClient() as client:
resp = await client.post(
f"{DIFY_API_URL}/workflows/run",
json={
"inputs": {"book_title": book.title, "book_genre": genre, "book_content": content},
"response_mode": "blocking",
"user": "auto-review-system",
},
headers={"Authorization": f"Bearer {DIFY_REVIEW_API_KEY}"},
)
outputs = resp.json()["data"]["outputs"]
# 3. 根据结果更新状态
if outputs.get("suggestion") == "PASS":
book.review_status = "approved"
elif outputs.get("suggestion") == "REJECT":
book.review_status = "rejected"
if book.draft_id:
draft = await db.get(Draft, book.draft_id)
draft.status = "draft"
# 4. 记录审核结果 + 发送通知
db.add(ReviewRecord(book_id=book.id, suggestion=suggestion, ...))
db.add(Message(user_id=book.author_id, ...))
python
# app/main.py ------ 启动时创建后台任务
@app.on_event("startup")
async def startup():
from app.services.auto_review import auto_review_loop
asyncio.create_task(auto_review_loop())涉及 books、review_records、messages、system_settings 四张表。system_settings 用键值对存储"是否开启自动审核"的开关,审核任务每次循环都会检查。
3.8 AI 写作助手
功能描述: 作者在写作页面打开 AI 助手对话框,发送消息给 Dify 聊天 API,AI 实时回复创作建议。
python
# app/routers/assistant.py ------ 纯代理转发
@router.post("/assistant/chat")
async def assistant_chat(body: dict):
async with httpx.AsyncClient(timeout=httpx.Timeout(120.0)) as client:
try:
resp = await client.post(
f"{DIFY_API_URL}/chat-messages",
json=body,
headers={"Authorization": f"Bearer {DIFY_API_KEY}"},
)
return resp.json()
except httpx.ConnectError:
raise HTTPException(status_code=503, detail="Dify 服务不可用")这个功能技术上极轻量------后端只是一个代理层,不涉及数据库,不存储对话记录,只负责转发请求和响应。好处是前端不需要直接暴露 API 密钥。
3.9 TXT 文件上传与章节解析
功能描述: 管理员上传 TXT 小说文件,后端自动识别编码,按章节标题正则拆分,批量入库。
python
# app/utils/chapter_parser.py
def parse_chapters_from_txt(file_path: str) -> list[dict]:
# 1. 自动检测编码(utf-8 / gbk / gb2312 / gb18030)
for enc in ["utf-8", "gbk", "gb2312", "gb18030"]:
try:
with open(file_path, "r", encoding=enc) as f:
f.read(500)
encoding = enc
break
except (UnicodeDecodeError, UnicodeError):
continue
with open(file_path, "r", encoding=encoding) as f:
full_text = f.read()
# 2. 多模式正则匹配章节标题
# 模式1:"第X章" 或 "第X卷" 或 "第X集"
# 模式2:"第X章 标题"(行内任意位置)
# 模式3:遇到无法识别时,按连续空行分割
matches = _find_chapter_matches(full_text)
if len(matches) < 2:
return _fallback_split(full_text)
chapters = []
for i, match in enumerate(matches):
title = match.group(0).strip()
start = match.end()
end = matches[i + 1].start() if i + 1 < len(matches) else len(full_text)
content = full_text[start:end].strip()
if len(content) >= 50:
chapters.append({"title": title, "content": content, "chapter_index": len(chapters)})
return chapters这个解析器的核心挑战是不同 TXT 文件的章节格式不统一。项目用了多模式正则匹配 + 降级策略来兼容:
| 模式 | 正则 | 示例匹配 |
|---|---|---|
| 标准章节 | 第[一二三四五六七八九十百千\d]+[卷章集節] |
"第一章 觉醒" |
| 斗罗大陆风格 | 第X集 卷名 (N) 标题 |
"第一集 斗罗世界 (1) 觉醒" |
| 降级策略 | 按 \n{4,}(连续4个换行) 分割 |
无章节标题的纯文本 |
3.10 前端 SPA 页面切换
功能描述: 项目没有使用 Vue / React 等框架,而是通过 JavaScript 操作 DOM 实现单页应用效果------点击导航栏时切换显示不同的视图区域,不刷新页面。
javascript
// forward/js/index.js(核心视图切换)
function switchView(viewFn) {
// 隐藏所有视图
document.querySelectorAll('.view-section').forEach(el => el.style.display = 'none');
document.querySelectorAll('.view-section-creator').forEach(el => el.style.display = 'none');
// 显示目标视图
viewFn();
}
// 导航点击绑定
document.querySelectorAll('.nav-menu a').forEach(link => {
link.addEventListener('click', (e) => {
e.preventDefault();
const view = link.dataset.view;
// 根据 data-view 属性切换到对应的视图函数
switchView(viewMap[view]);
});
});所有 API 请求通过 api.js 中的 Axios 实例统一管理,每个功能模块(登录、书籍、评论、作者等)在单独的 JS 文件中定义对应的 API 函数,保持代码结构清晰。
四、功能架构总览
┌─────────────────────────────────────────────────────┐
│ 前端(静态 HTML/JS) │
│ index.html / login.html / reader.html / admin.html │
│ └── Axios 请求 → Bearer Token │
├─────────────────────────────────────────────────────┤
│ FastAPI 后端(15 个路由模块) │
│ │
│ 认证 书籍 章节 分类 搜索 评论 评分 │
│ 书架 历史 作者 草稿 消息 活动 管理 │
│ │
│ 写作助手(代理 Dify) 自动审核(后台定时任务) │
├─────────────────────────────────────────────────────┤
│ MySQL 数据库 │
│ 15 张表:users / books / chapters / categories │
│ bookshelf / reading_history / comments / ratings │
│ author_applications / drafts / draft_chapters │
│ messages / events / review_records / system_settings │
└─────────────────────────────────────────────────────┘五、总结与未来展望
通阅小说是一个完整度较高的全栈项目,核心设计思路可总结为三点:
-
数据库驱动业务:15 张表围绕"读者 - 书籍 - 作者"三条主线展开,外键关系清晰,CASCADE 级联确保数据一致性。
-
异步非阻塞 :后端全链路使用
async/await,数据库操作通过 SQLAlchemy 异步引擎执行,后台定时任务也以asyncio.create_task启动,不阻塞主线程。 -
AI 能力集成:通过 Dify 平台的 API 接口,以代理模式在项目中引入了 AI 写作助手和自动内容审核,不依赖额外的大模型部署成本。
未来可用哪些技术完善
当前项目已经实现了完整的功能闭环,但在工程化和性能层面仍有较大的提升空间。以下是从五个维度出发的优化思路:
1. 前端工程化
| 现状 | 可升级的方向 |
|---|---|
| 纯 HTML + JS 手写 SPA,页面切换手动控制 DOM 显隐 | 迁移到 Vue3 或 React,利用组件化和虚拟 DOM 提升开发效率和页面性能 |
| 代码散落在多个 JS 文件中,无模块化管理 | 引入 Vite 作为构建工具,使用 TypeScript 重写,实现类型安全和模块化 |
| 样式手写 CSS | 引入 Tailwind CSS 或 UnoCSS,统一设计规范,减少重复样式代码 |
| 无单元测试 | 引入 Vitest 做组件测试,保证迭代质量 |
2. 后端架构升级
| 现状 | 可升级的方向 |
|---|---|
| FastAPI 单进程运行 | 引入 Gunicorn + Uvicorn Worker 多进程部署,充分利用多核 CPU |
| 文件存储在本地磁盘 | 迁移到 阿里云 OSS / 腾讯云 COS 对象存储,封面和头像走 CDN 加速访问 |
| 同步的 MySQL 查询 | 引入 Redis 缓存,热门书籍详情和排行榜数据缓存到内存中,减少数据库压力 |
| 验证码用明文返回 | 升级为 图形验证码 或对接 滑动验证(极验等),防止脚本攻击 |
3. 搜索和推荐能力
| 现状 | 可升级的方向 |
|---|---|
搜索用 LIKE %keyword%,性能差 |
引入 Elasticsearch 实现全文搜索,支持分词、高亮、相关性排序 |
| 首页推荐靠手动标记 is_featured | 接入 推荐算法 (基于用户阅读历史和评分做协同过滤),或接入 DeepSeek 等模型做个性化推荐 |
4. AI 能力深化
| 现状 | 可升级的方向 |
|---|---|
| 写作助手只做会话式对话 | 增加 AI 续写段落 、自动生成章节大纲 、角色关系图生成 等定向功能 |
| 自动审核只检查前 5000 字 | 完整的章节逐章扫描,增加敏感图片检测(NSFW 识别) |
| 审核结果只有 PASS / REJECT | 增加 违规类型分类(色情、暴力、涉政等),细分违规等级 |
5. 运维与部署
| 现状 | 可升级的方向 |
|---|---|
| 本地手动启动 | 编写 Docker Compose 编排文件(MySQL + Redis + FastAPI + Nginx),一键部署 |
| 无持续集成 | 接入 GitHub Actions,push 后自动运行测试、构建镜像、部署到服务器 |
| 无日志监控 | 引入 Sentry 做错误监控,Prometheus + Grafana 做性能指标可视化 |
优化优先级建议
第一优先级(投入产出比最高):
Redis 缓存热门数据 → 减少数据库压力
Docker 部署 → 环境一致,方便迁移
第二优先级(核心体验提升):
Elasticsearch 全文搜索 → 搜索体验质的飞跃
Vue3 重构前端 → 开发效率和可维护性提升
第三优先级(锦上添花):
AI 深度集成 → 续写、大纲生成
推荐算法 → 个性化推荐
CI/CD → 自动化部署