elasticsearch-dsl-py 在 GitHub 上拿到了 3.8K Star。
Elastic 官方开源了这个库,目的是让 Python 开发者用更舒服的方式写 Elasticsearch 查询。
1、解决了什么问题
写过 Elasticsearch 查询的人都清楚:把查询写成 JSON 字典,嵌套一深就容易写错层级。加一个 filter 要在多层括号里找位置,聚合查询写完后自己都看不懂。
这个库把 JSON 查询包成 Python 对象,用方法链构造查询。
2、代码对比一下
官方 README 拿两种写法做了对比。
原生写法:
python
response = client.search(
index="my-index",
body={
"query": {
"bool": {
"must": [{"match": {"title": "python"}}],
"must_not": [{"match": {"description": "beta"}}],
"filter": [{"term": {"category": "search"}}]
}
},
"aggs" : {
"per_tag": {
"terms": {"field": "tags"},
"aggs": {
"max_lines": {"max": {"field": "lines"}}
}
}
}
}
)换成 DSL 之后:
python
s = Search(using=client, index="my-index") \
.filter("term", category="search") \
.query("match", title="python") \
.exclude("match", description="beta")
s.aggs.bucket('per_tag', 'terms', field='tags') \
.metric('max_lines', 'max', field='lines')
response = s.execute()库自动处理了 bool 查询组合、filter 和 query 的上下文区分。返回结果直接用属性访问,不用从字典里逐层提取。
3、模型映射
这个库提供了 Document 类,可以用 Python 对象操作 ES 文档:
python
class Article(Document):
title = Text(analyzer='snowball', fields={'raw': Keyword()})
tags = Keyword()
published_from = Date()
lines = Integer()
class Index:
name = 'blog'
article = Article(meta={'id': 42}, title='Hello world!')
article.save()字段类型、索引配置、自定义方法都写在类里,比手写 mapping JSON 直观得多。框架还提供了数据校验、save 生命周期钩子等功能。
4、重要变化
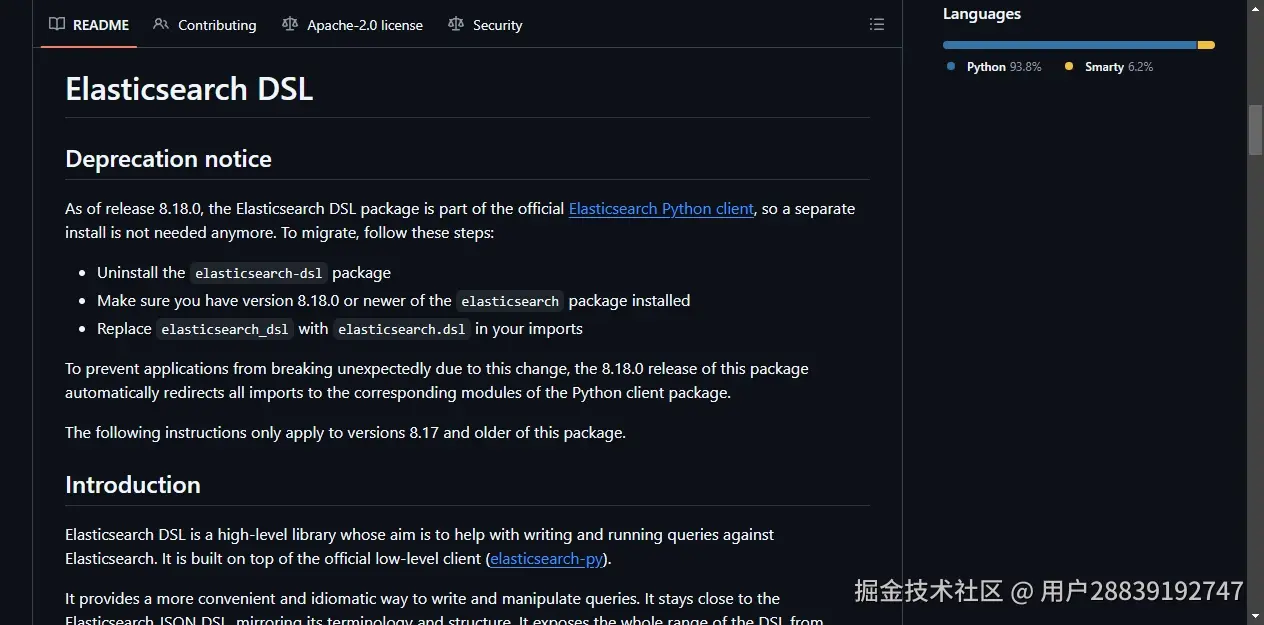
8.18.0 版本之后,这个库被合并到了官方的 elasticsearch-py 客户端。不再需要单独安装 elasticsearch-dsl,只需把 elasticsearch_dsl 改成 elasticsearch.dsl 即可。
新项目可直接用 elasticsearch-py 8.18.0+,老项目也可以逐步迁移。8.18.0 版本会自动把旧 import 重定向到新位置,不会突然报错。