PDF 的设计目标是"所见即所得"的文档交换,而非数据结构化,这给表格提取带来了结构性障碍:
- PDF 缺乏表格语义模型:表格在 PDF 中仅表现为线条与字符的集合,不存在行/列/单元格的抽象定义
- 复杂表格结构构成典型挑战:合并单元格、旋转文字、跨页断表、无边框表格------以上每一种场景均会导致多数工具输出结果严重降质
- 扫描件与文本型 PDF 本质差异:前者依赖 OCR 引擎将图像转为文字,后者可直接解析字符编码层,二者对工具能力的要求截然不同
本文对市面上主流的商用 SDK/API、开源工具及免费在线工具进行 PDF 表格提取横向实测,基于统一测试样本输出可量化的对比结论。
测试 PDF 说明
测试文件:扫描型 PDF(《SEO 的艺术第三版》英文版第 114 页)
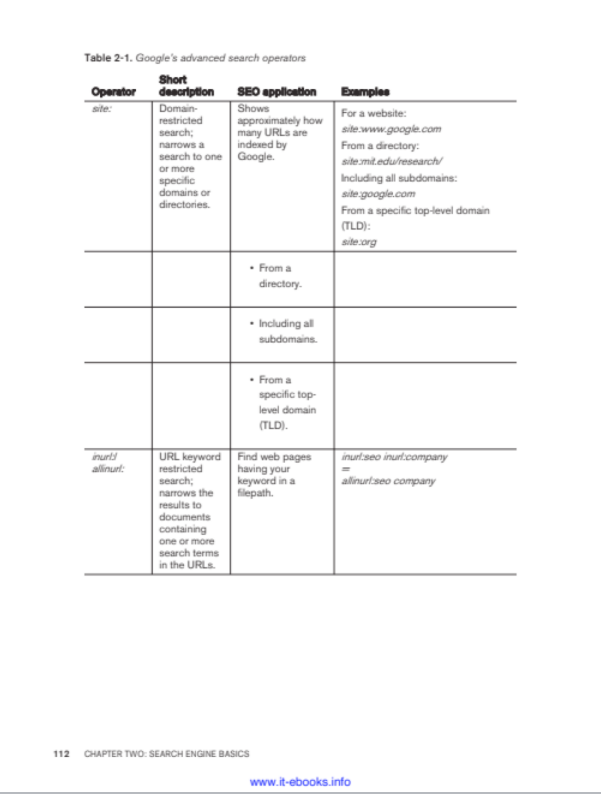
| 属性 | 值 |
|---|---|
| 类型 | 扫描件(纯图像,无文字层) |
| 页面尺寸 | 504 x 661.5 pt |
| 内嵌图像 | 1008 x 1323 px, RGB, 8bit |
| 字符/线条/矩形 | 0 / 0 / 0 |
| 实际内容 | 1 个 4 列多行表格 |
该样本属于高难度测试场景:扫描型 PDF 无文字层、半边框表格结构、包含分层表头,要求工具兼具 OCR 识别与表格结构还原能力,多数纯解析型 Python 库无法直接处理。
在线 PDF 表格提取工具
快速选择指南
| 使用场景 | 推荐工具 | 备选 | 选型理由 |
|---|---|---|---|
| 日常简单表格转 Excel | SmallPDF | iLovePDF | 操作路径最短,上传即得结果 |
| 隐私敏感文档处理 | PDF24 | --- | 完全免费,隐私保护机制完善 |
| 开发者 API 集成 | ComPDF 等 | PDFTables | 提供 REST API 可编程调用 |
| 复杂表格(合并单元格/分层表头) | 推荐 ComPDF 等商业 SDK | --- | 在线工具在复杂表格场景下普遍表现不佳,建议选用具备结构化还原能力的专业 SDK |
1. ExtractTable
| 项目 | 内容 |
|---|---|
| 地址 | extracttable.com |
| 类型 | 云端 API + 网页 Demo |
| 扫描件支持 | 支持 OCR |
| 定价 | 信用点制,50 credits/$3 起 |
网页 Demo 仅限图片(JPG/PNG),付费版支持 PDF,输出格式为 CSV/Excel。
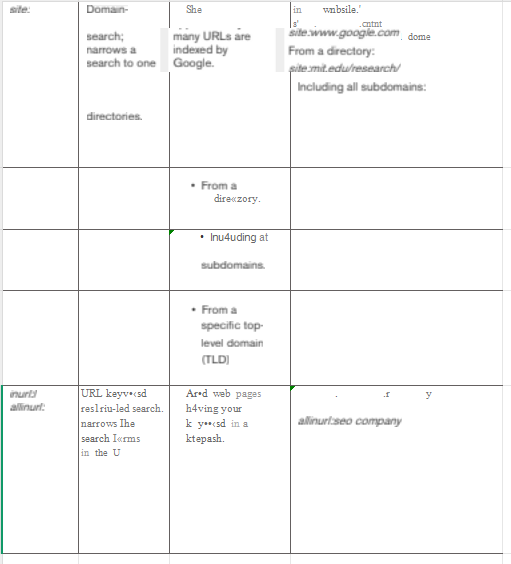
实测结果 :因 Demo 仅支持图片输入且每日限 2 次,未能完成扫描件 PDF 完整测试流程。测试改用图片输入------普通连续文本还原基本可用,但 = 符号被误识别为 ---,粗体样式、单元格尺寸、无序列表等格式化信息全部丢失。
据 Mark Kramer 评测,ExtractTable 存在合并单元格内容错位、遗漏数据等问题。
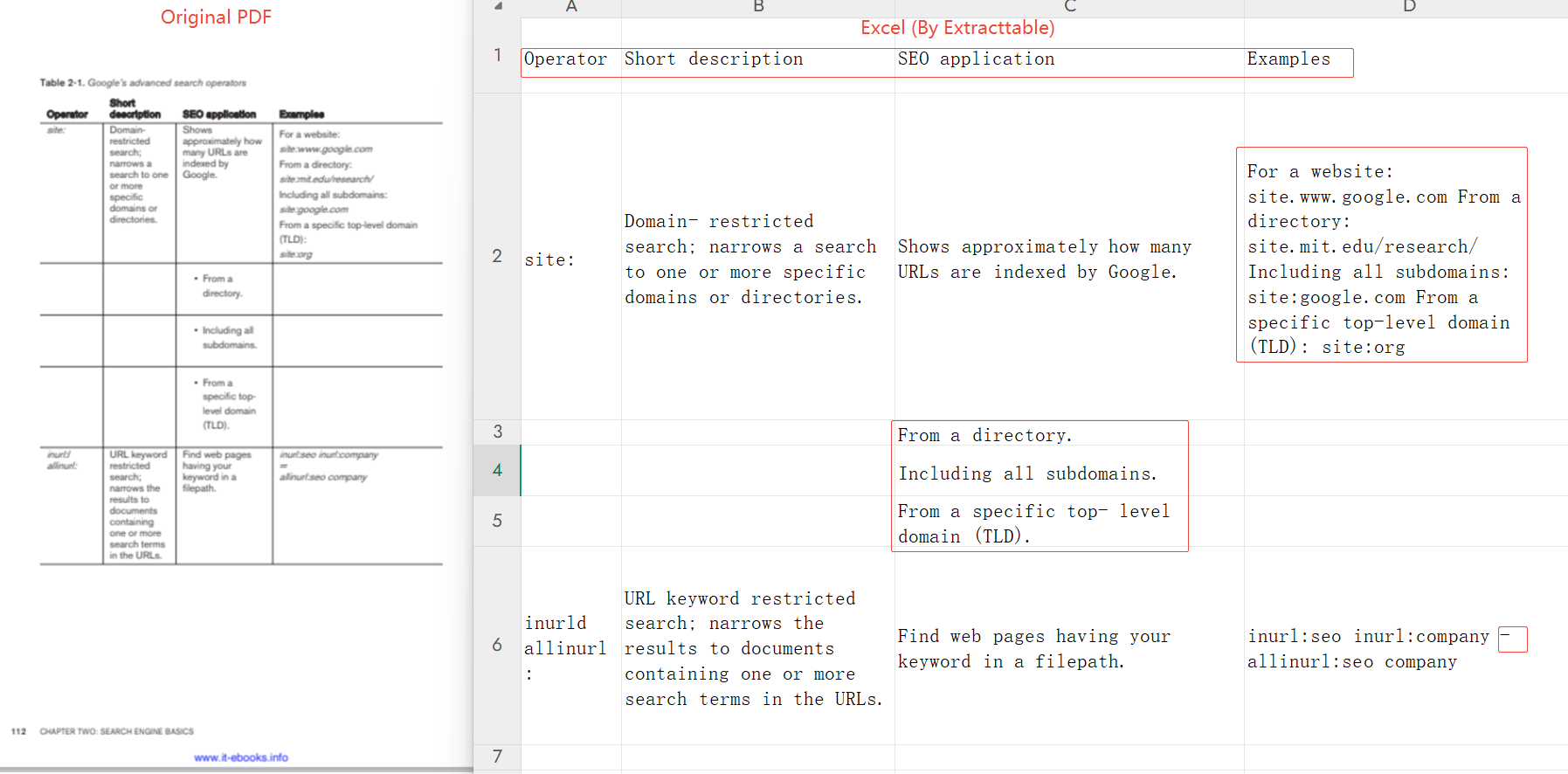
2. SmallPDF
| 项目 | 内容 |
|---|---|
| 地址 | smallpdf.com |
| 类型 | 在线网页工具 |
| 扫描件支持 | 支持 OCR(Pro 版,免费试用 7 天) |
| 免费限制 | 每日 2 次免费,Pro $12/月 |
提供 PDF 转 Excel 功能,操作便捷。但面对合并单元格、旋转文字等复杂结构时,识别能力有限。
实测结果:在同类型在线工具中表现良好,表格结构、合并单元格、竖向文本、上下角标等元素均实现有效识别。
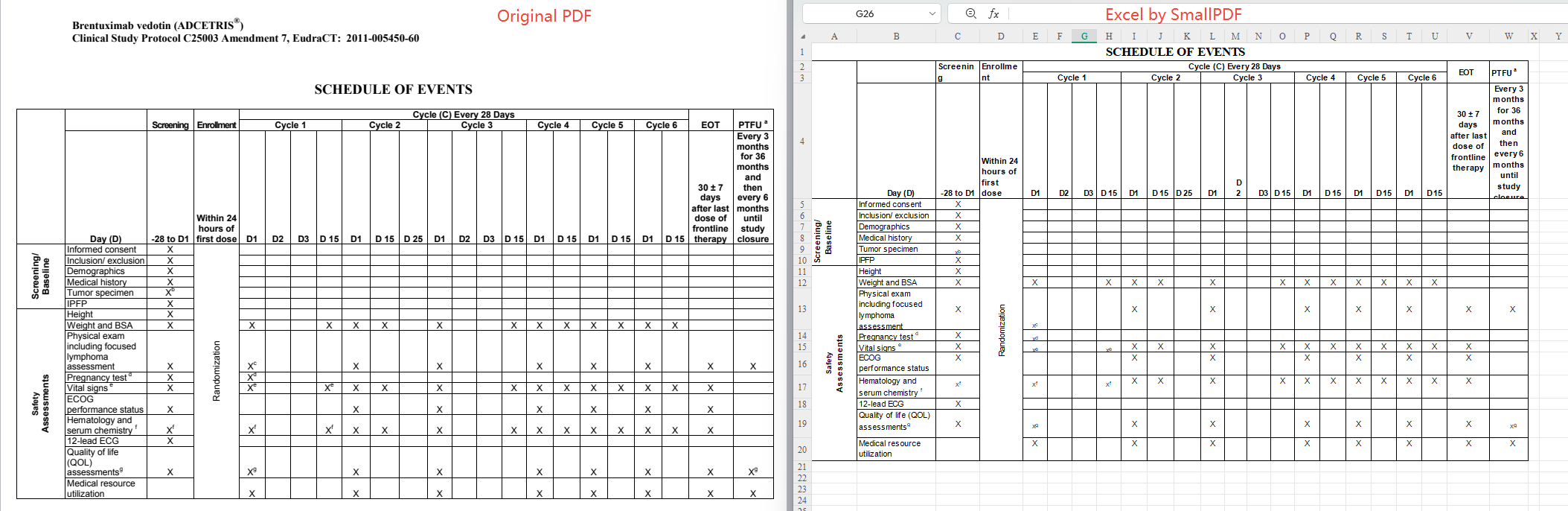
3. iLovePDF
| 项目 | 内容 |
|---|---|
| 地址 | ilovepdf.com |
| 类型 | 在线网页工具 |
| 扫描件支持 | 支持 OCR(付费版) |
| 免费限制 | 每小时 2 次,Pro $6/月 |
提供 PDF 转 Excel、PDF 转 Word 等多格式转换功能。免费版不含 OCR 能力。
实测结果:OCR 识别精度不足,部分文字区域成功转换,但仍有大量内容以原始图片切片形式嵌入表格,未完成真正结构化。
4. PDF24 Tools
| 项目 | 内容 |
|---|---|
| 地址 | tools.pdf24.org |
| 类型 | 在线 + 桌面客户端 |
| 扫描件支持 | 有限 |
| 定价 | 完全免费 |
德国开发的免费 PDF 工具集,提供 PDF 转 Excel 功能,无文件大小限制,隐私保护机制完善。但对复杂表格结构支持有限。
实测结果:扫描件未经 OCR 处理,直接以图片形式嵌入 Excel 输出;表格结构识别失败,存在文本丢失与单元格合并逻辑错误。
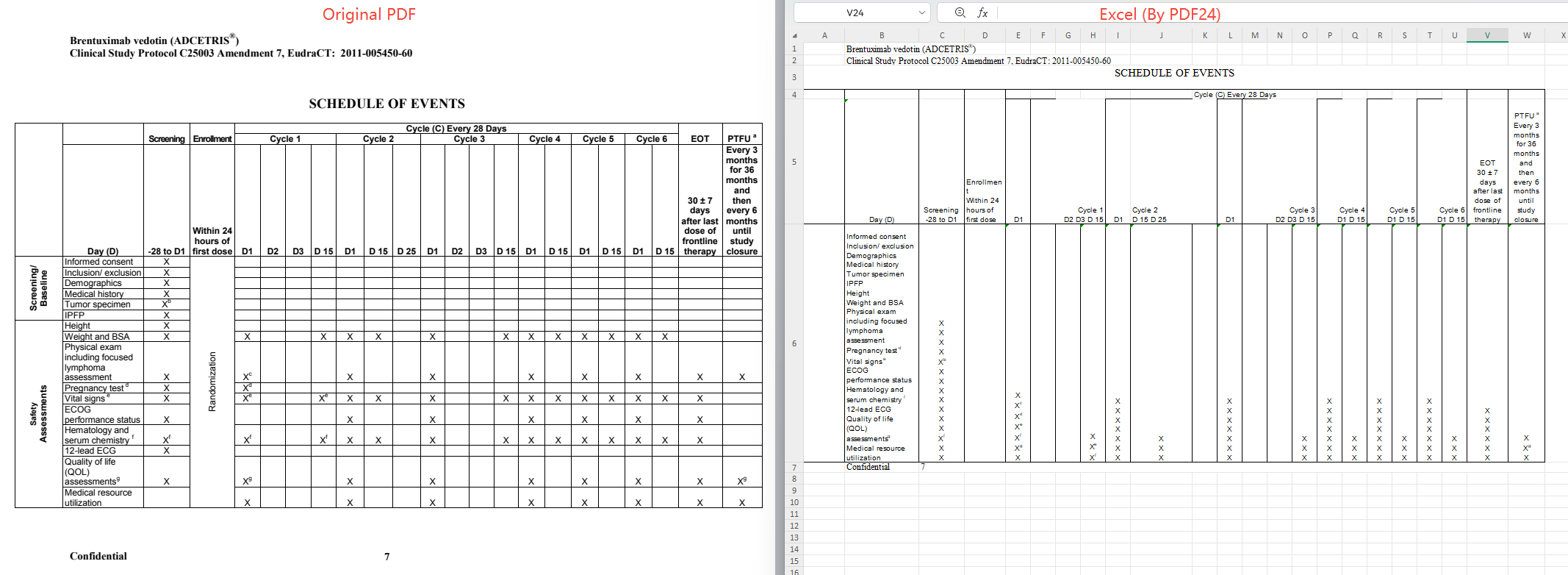
5. PDFTables.com(在线版)
| 项目 | 内容 |
|---|---|
| 地址 | pdftables.com |
| 类型 | 在线网页 + API |
| 扫描件支持 | 不支持 OCR |
| 定价 | 信用点制,$50/1000 页起 |
支持在线拖拽上传转换。标准有线表格场景下转换质量良好,但不支持扫描件,且无免费试用机制。
PDF 表格提取商业工具实测
快速选择指南
| 使用场景 | 首选工具 | 选型理由 |
|---|---|---|
| 复杂合并单元格/分层表头/保留样式 | ComPDF | 本测试唯一在分层表头、合并单元格及样式保留三项均通过验证的商业 SDK |
| 云原生/高吞吐/AWS 生态 | AWS Textract | 与 AWS 深度集成,按量付费,适合弹性吞吐场景 |
| 跨平台 SDK 集成(Web/移动端) | ComPDF | 原生跨平台 SDK,适合嵌入场景 |
| 桌面端单次使用 | Adobe Acrobat | 覆盖面最广的 PDF 桌面工具 |
| 企业级全栈文档处理 | ComPDF | 全平台 SDK,企业级私有化部署 |
1. ComPDF(推荐)
| 项目 | 内容 |
|---|---|
| 产品 | ComPDF SDK / API |
| 提供 SDK 语言 | Python, Java, Go, iOS, Android, C# |
| 定价 | 联系销售 |
核心能力 (来源:ComPDF 官网)
ComPDF 是目前少数同时覆盖以下三项能力的商业表格提取 SDK:
| 能力维度 | 支持情况 |
|---|---|
| 表格类型覆盖 | 有线表格、不规则边框表格、无边框表格 |
| 复杂合并单元格 | 跨行/跨列合并单元格结构化还原 |
| 内容保留 | 单元格内文字与图片同时提取 |
| 样式保留 | 字体/字号/颜色/粗斜体完整还原 |
第三方评测背景 :Mark Kramer 在 MITRE 主持的横向评测中测试了 12 款主流工具,结论如下(来源:Medium):
"Among all the commercial solutions, ComPDF was the only tool to correctly capture the hierarchical column headers."
本次实测各项表现:

| 评估项 | 实测结论 |
|---|---|
| 分层合并表头(列头) | 正确捕获,在本次所有商业工具中表现最优 |
| 行/列合并 | 跨行跨列合并逻辑完整还原 |
| 表格文字样式 | 字体、字号、粗斜体基本还原 |
| 表格边框 | 正确识别并还原边框位置与线型 |
| 行列尺寸 | 列宽、行高与实际 PDF 保持一致 |
| 已知局限 | 脚注归属、文字上标、旋转文字的识别仍存在改进空间 |
| SDK 覆盖 | 6 种语言(Python / Java / Go / iOS / Android / C#) |
2. AWS Textract
| 项目 | 内容 |
|---|---|
| 产品 | Amazon Textract API |
| 免费层 | 新用户每月 100 页(3 个月)定价页 |
| 定价 | $0.015/页(表格模式) |
import boto3
client = boto3.client('textract')
response = client.analyze_document(
Document={'S3Object': {'Bucket': 'my-bucket', 'Name': 'invoice.pdf'}},
FeatureTypes=['TABLES', 'FORMS']
)评估:
- 基础表格识别:文本型 PDF 有线表格表现良好,结构还原准确
- 扫描件 OCR:依托 AWS 底层 OCR 引擎,扫描件处理能力处于商业 API 第一梯队
- 合并单元格:支持有限,分层表头场景下输出结果与独立单元格存在偏差
- 生态集成:与 AWS 服务(S3/Lambda/SageMaker)原生打通,适合已有 AWS 基础设施的团队
3. Nanonets
| 项目 | 内容 |
|---|---|
| 产品 | Nanonets API |
| 定价 | $0.10-0.30/次 定价页 |
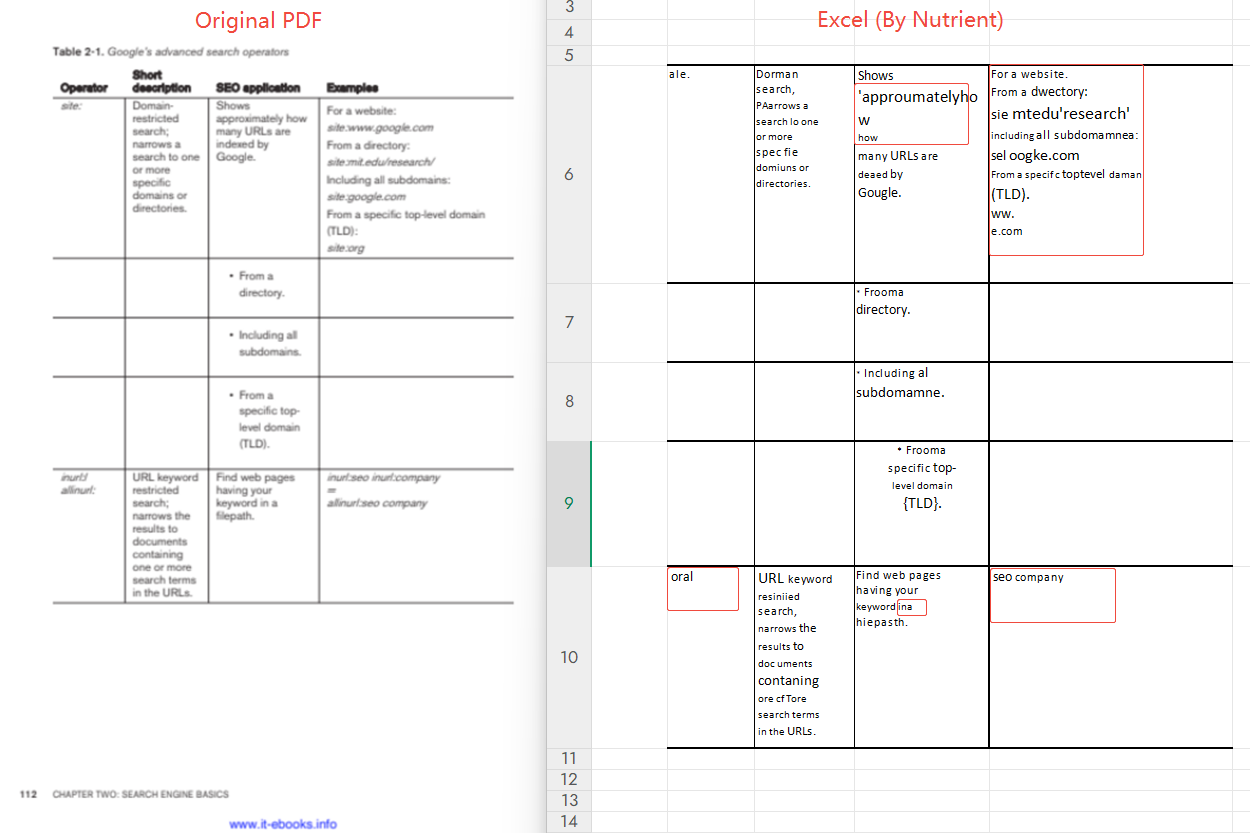
第三方评测参考 :Mark Kramer 评测显示其遗漏率低于 ExtractTable,但脚注内容输出为乱码,合并单元格无法正确表达层级关系。
本次实测:连续文本识别基本可用,基础文字样式(字体/字号)得到保留;文本颜色、表格边框线型等格式化信息未还原。

4. Nutrient(原 PSPDFKit)
| 项目 | 内容 |
|---|---|
| 产品 | Nutrient SDK / API |
| 官网 | nutrient.io |
| 定位 | 企业级 PDF SDK(跨平台) |
| 支持平台 | Web, iOS, Android, Windows, macOS |
| 定价 | 联系销售(企业级) |
Nutrient(前身 PSPDFKit)是知名的跨平台 PDF SDK 厂商,核心能力集中于 PDF 渲染、标注与编辑,表格提取以 API 模块形式提供。
产品定位:
- 跨平台原生 SDK,在 PDF 渲染与交互领域性能突出
- 表格提取并非其核心场景,需自行开发集成逻辑
- 适合已有 Nutrient 部署、需要补充表格能力的团队
实测结果:文本内容识别准确率不足,出现位置偏移、间距失真、部分文字缺失等问题;表头与正文的层级关系未能正确还原。
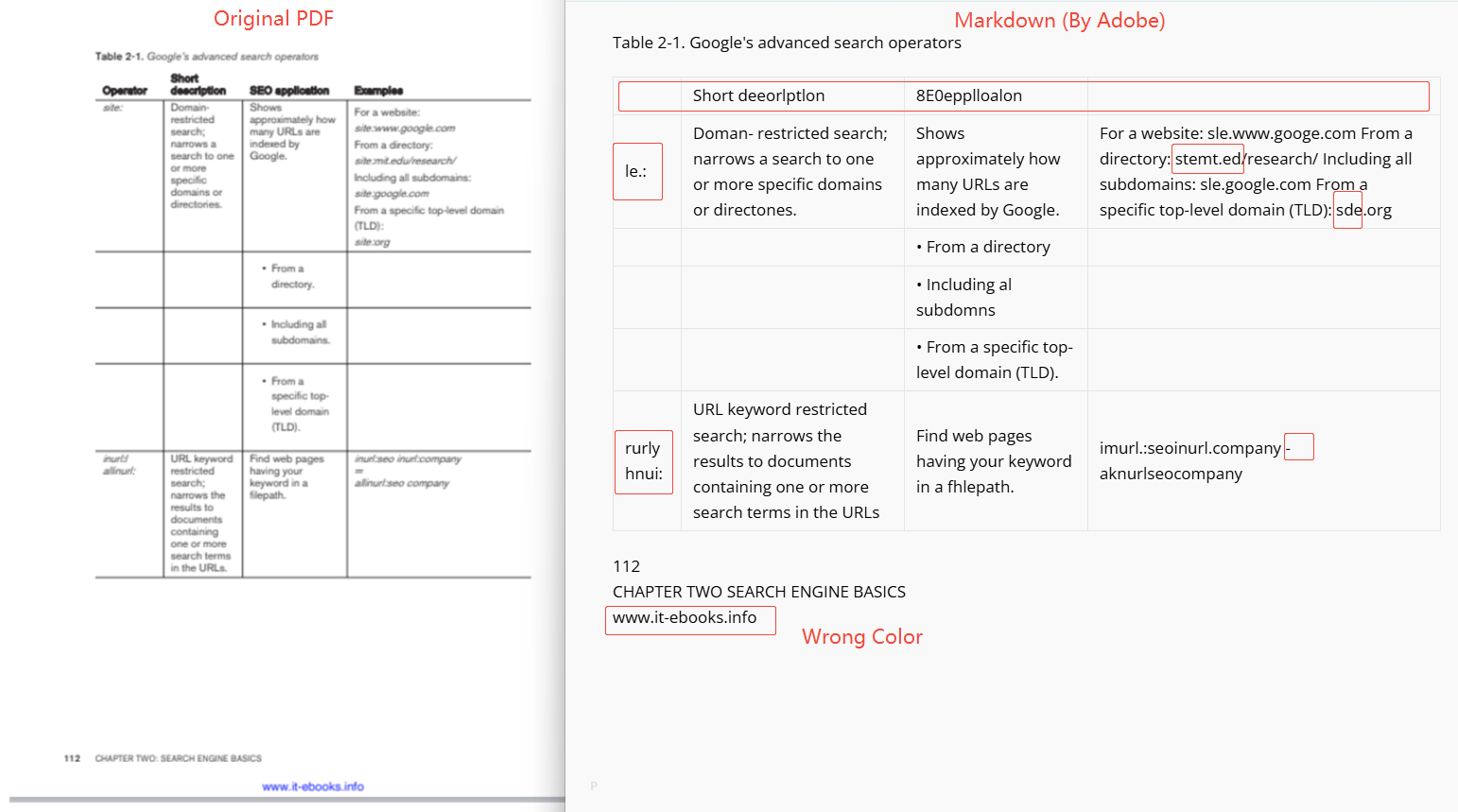
5. Adobe Acrobat
| 项目 | 内容 |
|---|---|
| 产品 | Adobe Acrobat Pro DC |
| 定价 | 订阅制 ~$19.99/月 |
| 扫描件支持 | 内置 OCR(Pro 版) |
| 适用场景 | 桌面端单次、小规模处理 |
产品特点:
- 优势:操作门槛低,无需编程;Pro 版内置 OCR,扫描件可直接导出
- 局限:缺乏批量自动化接口;合并单元格场景下输出质量不稳
实测结果:表格整体结构得到还原,但存在文本丢失、个别字符识别错误等现象;表格边框线型与单元格样式未能保留。
6. iText(iText 8 Core / iText 7 Community)
| 项目 | 内容 |
|---|---|
| 产品 | iText 8 Core / iText 7 Community |
| 官网 | itextpdf.com |
| 协议 | AGPL(免费开源)/ 商业许可证 |
| 支持平台 | Java, .NET(C#) |
| 定价 | AGPL 免费 / 商业版联系销售 |
iText 是最老牌的 PDF 处理库之一(始于 1998 年)。iText 本身不提供专门的表格提取 API ------需要用 LocationTextExtractionStrategy 自行解析文字位置来推断表格结构。
本次实测三份 PDF:
| 测试文件 | 类型 | 提取结果 | 表格结构还原 |
|---|---|---|---|
| SEO 书籍第 114 页 | 扫描件 | 0 字符 | --- |
| Transcript (1).pdf | 文本型成绩单 | 2218+866 字符 | 连续文本流 |
| Prot_000 8.pdf | 文本型临床方案表 | 1062 字符 | 连续文本流 |
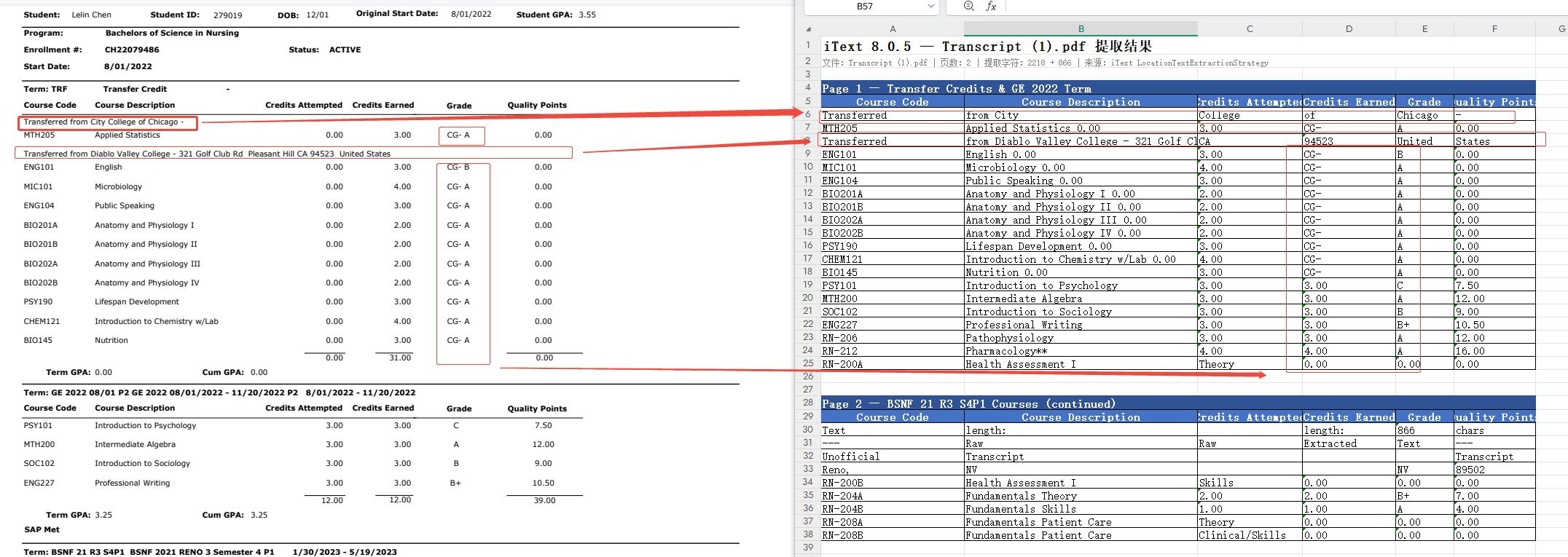
可用情况总结:
| 场景 | 结果 |
|---|---|
| 文本型 PDF 文字提取 | 4/5------文字层提取能力成熟 |
| 表格自动识别 | 需自行开发(基于坐标推断) |
| 扫描件 OCR | 无内置 OCR |
| PDF 创建/编辑 | 5/5------行业标杆 |
核心结论:iText 在 PDF 底层操作领域能力成熟,但并非开箱即用的表格提取工具。文字内容提取(累计 4,146 字符)完整可靠,但表格结构(列对齐、合并单元格、旋转文字)全部丢失。如需直接获取结构化表格输出,建议选用 ComPDF(商业场景)、Camelot 或 Docling(开源场景)等专注于表格还原的专业工具。
开源 PDF 表格提取工具实测
快速选择指南
| 使用场景 | 推荐工具 | 选型理由 |
|---|---|---|
| 扫描件/图像 PDF 表格提取 | Docling | 实测 9.39s 完成扫描件表格提取,支持 AI 管道集成 |
| 标准有线文本型 PDF 表格 | Camelot | lattice 模式配置简单,数行代码完成提取 |
| 复杂表格(合并单元格/旋转文字) | pdfplumber + 自定义 | 需精细调参与自定义后处理逻辑 |
| Java 生态/已有 Java 项目 | tabula-py / iText | 天然适配 Java 技术栈 |
| 完整文档理解(AI 管道) | Docling | 原生集成 LangChain/LlamaIndex |
| 预算为零 | 任一开源工具均可 | 全部采用 MIT 协议,无授权费用 |
1. Docling(IBM)
| 项目 | 内容 |
|---|---|
| 版本 | v2.99.0(2026 年 6 月 8 日)GitHub |
| 协议 | MIT |
| GitHub Stars | 61,200+------增长最快的 PDF 开源项目 |
| 依赖 | Python 3.10+,首次需下载模型(约 2-5GB) |
核心特性 (来源:GitHub README + 技术报告)
- 多种格式支持(PDF/DOCX/PPTX/XLSX/HTML/图片/音频/邮件等)
- 内置 TableFormer(声称 93.6% 准确率 vs Tabula 67.9%、Camelot 73.0%)
- 内置 OCR(通过 RapidOCR 支持扫描件)
- 集成 LangChain / LlamaIndex / Crew AI / Haystack
实测结果(2026 年 6 月)
环境:通过 HF_ENDPOINT=https://hf-mirror.com 成功下载模型
- 转换时间:9.39s
- Markdown 长度:2573 字符
- Heron layout 模型:加载成功(770/770 weights)
- OCR 引擎:RapidOCR
- 表格检测:成功

结论:
- 表格结构识别:4 列多行表格结构完整保留,行列对应关系正确
- 扫描件处理能力:成功从纯图像 PDF 提取结构化表格,验证了 AI 模型在扫描件上的可行性
- OCR 英文准确率偏低:因内置 RapidOCR 主要针对中文字符优化,英文识别出现偏差(如 "Google" 误识为 "Googfe"),是当前版本的主要瓶颈
改进方向:搭配英文专用 OCR 引擎(如 Tesseract 英文模型)可显著提升扫描件英文表格的识别准确率。
2. pdfplumber
| 项目 | 内容 |
|---|---|
| 版本 | v0.11.9(2026 年 1 月)PyPI |
| 协议 | MIT,基于 pdfminer.six |
| 定位 | 精确到每个字符的底层 PDF 解析引擎 |
实测结果(2026 年 6 月):
Chars: 0, Lines: 0, Rects: 0, Tables: 0扫描件无法处理------0 字符、0 线条、0 表格。符合官方说明:"Works best on machine-generated, rather than scanned, PDFs"。
文本型PDF测试(本次新增):
Transcript (1).pdf(学生成绩单,2页) Chars: 2905 | Tables: 0 | Time: 0.13s
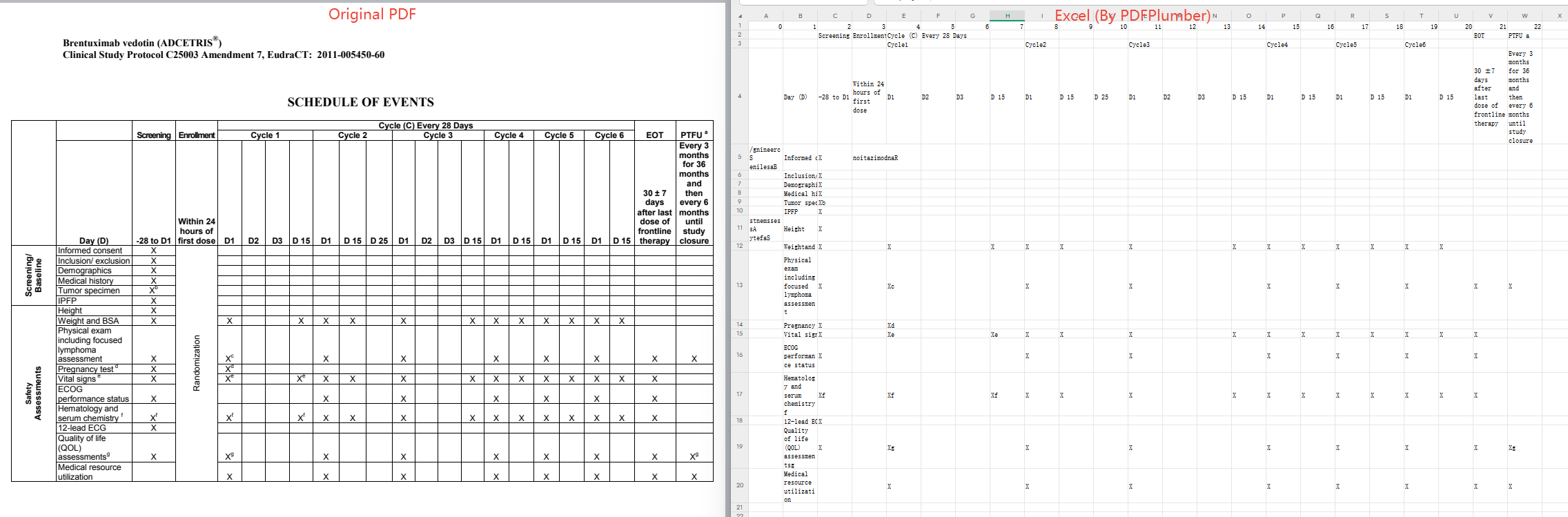
pdfplumber 成功提取了 2905 字符的文本内容,但未检测到任何表格(0 tables)。原因是 pdfplumber 的表格检测依赖图形线条(lines/rects),而该成绩单的表格是无线框的("ghost table"),仅靠文字对齐形成表格视觉,pdfplumber 无法自动识别。
Prot_000 8.pdf(临床试验方案表,1页) Chars: 1017 | Tables: 1 | Time: 1.19s
成功检测到 1 个表格(Schedule of Events),得益于该表格有完整的边框线条。但提取结果中合并单元格(如跨列的时间轴表头)信息丢失,旋转文字无法识别。
结论 :pdfplumber 在有线表格 上检测精准(契合Mark Kramer评测结论),但对无线框表格完全无效。作为底层库,需大量自定义代码才能处理复杂场景。
3. Camelot
| 项目 | 内容 |
|---|---|
| 版本 | v2.0.0(2026 年 6 月 4 日)PyPI |
| 协议 | MIT |
| 依赖 | Python 3.10+,ML 模式可选 PyTorch |
5 种解析器:lattice(有线)/ stream(无线)/ network(文本对齐)/ ml(Table Transformer)/ auto(自动)
实测结果:
- Lattice 模式:扫描件无法处理,解析器明确拒绝图像型页面输入
文本型PDF测试(本次新增):
Transcript (1).pdf(成绩单,无线框表格):
| 模式 | 结果 |
|---|---|
| lattice | ❌ 0 tables --- 无表格线条,无法识别 |
| stream | ✅ 1 table, 95.8% accuracy --- 0.07s,成功识别无线框表格 |
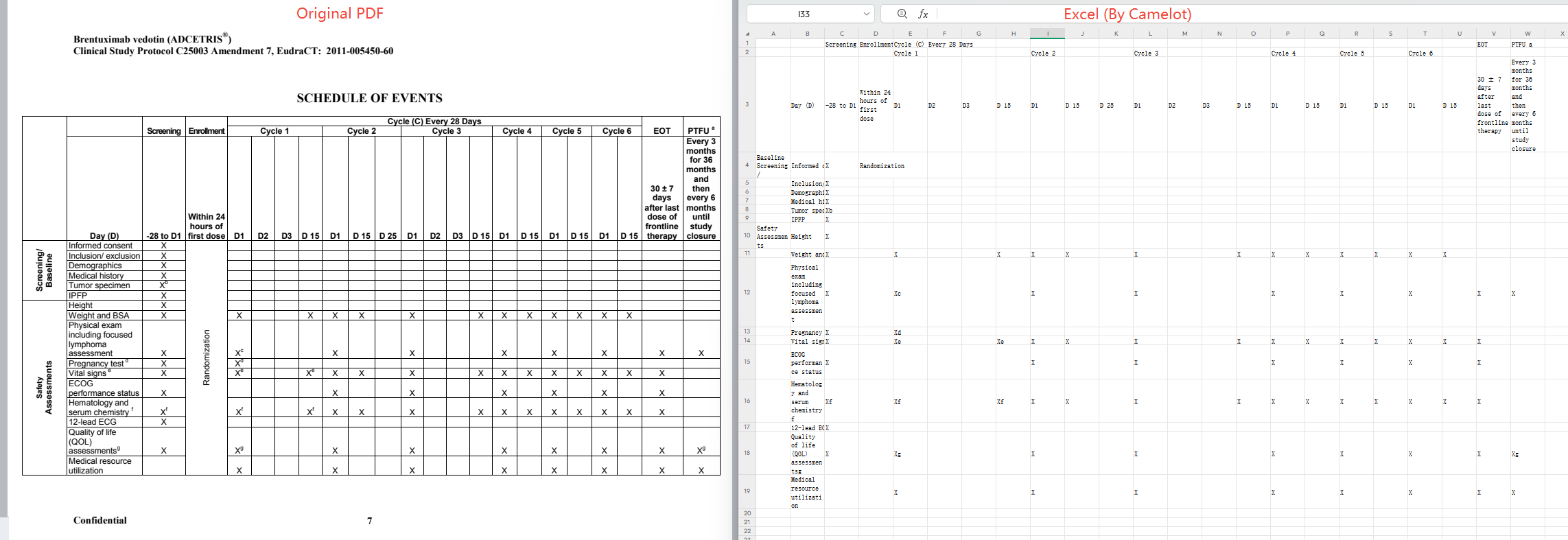
Prot_000 8.pdf(临床方案表,有线框表格):
| 模式 | 结果 |
|---|---|
| lattice | ✅ 1 table, 97.97% accuracy --- 0.36s,结构完整 |
| stream | ✅ 2 tables, 100% accuracy --- 0.08s,速度最快 |
结论: 提取后的Excel文件表格结构混乱,文本与单元格对应出现混乱。
4. tabula-py
| 项目 | 内容 |
|---|---|
| 版本 | v2.10.0(2024 年 10 月)PyPI |
| 协议 | MIT |
| 依赖 | Java 8+ + Python 3.9+ |
实测结果(Java 21 + tabula-py 2.10.0):
Tables found: 0扫描件无法处理。即使已安装 Java 运行时,tabula-py 也无法解析无文字层的图像型 PDF。Tabula 官方说明明确:"Tabula only works on text-based PDFs, not scanned documents."
文本型PDF测试(本次新增):
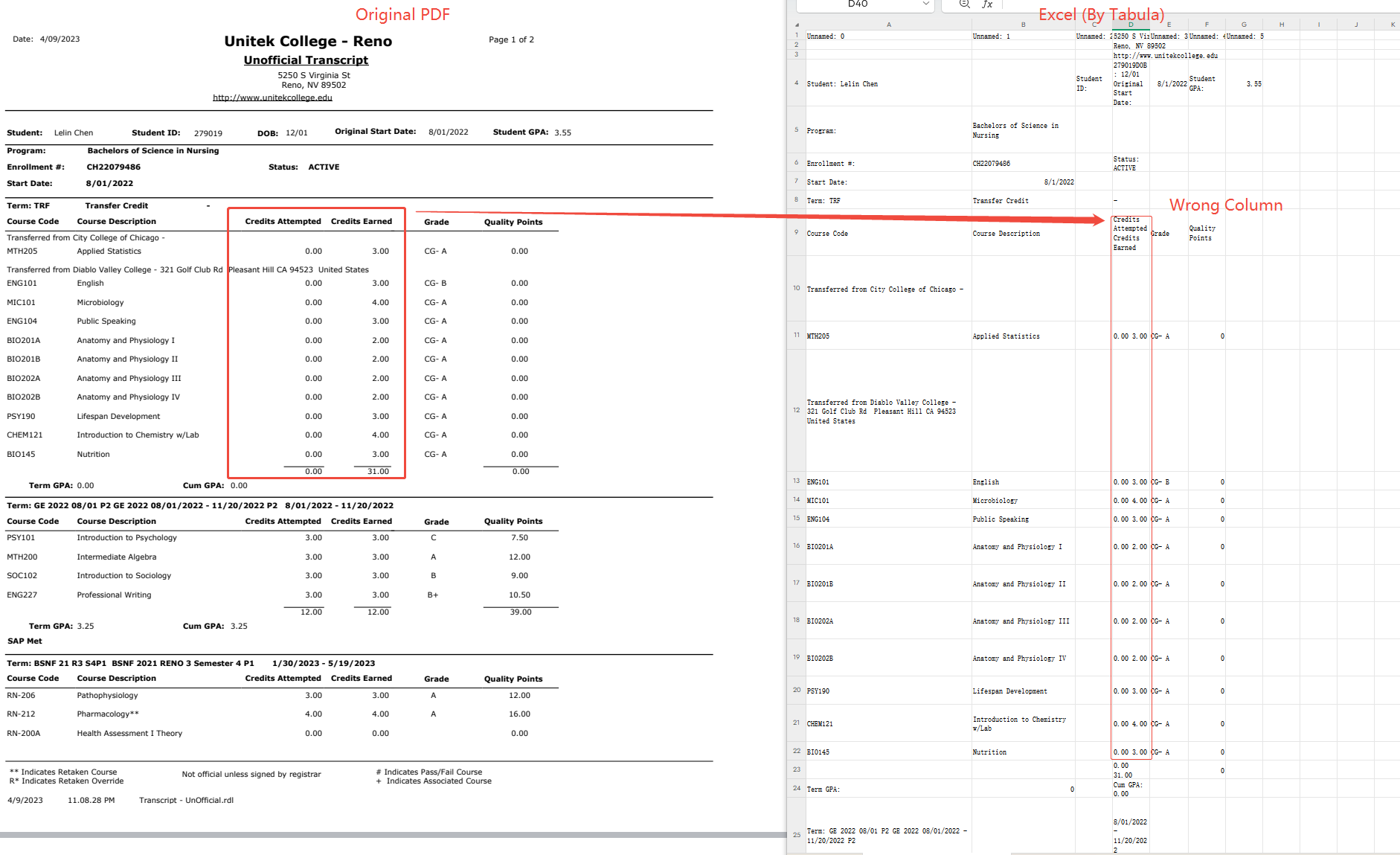
Transcript (1).pdf(学生成绩单,2页) Tables found: 2 | Time: 1.54s Table 1: 29 rows x 7 cols(转学分部分) Table 2: 8 rows x 7 cols(GE 2022学期部分)
tabula-py 成功将成绩单的两个学期课程表格分别识别为独立的 DataFrame,列结构完整(Course Code / Description / Credits / Grade / Quality Points)。29行转学分课程数据全部正确捕获。
Prot_000 8.pdf(临床试验方案表,1页) ERROR: 'utf-8' codec can't decode byte 0xa1
tabula-py 在处理该PDF时因编码问题抛出异常。该PDF包含特殊字符(如注册商标符号®、±等),tabula-py 的 Java 子进程输出解码失败。
小结:tabula-py 对标准表格(如成绩单)的文本识别基本正确,但是结构还原得有些混乱,文本与行列关系对应失败,表格边框等都没有正确识别。
结论
本文通过 三份不同难度等级的测试文件 (扫描件无文字层PDF / 文本型成绩单PDF / 文本型临床试验方案PDF),对 15 款工具 进行了横向实测,核心发现如下:
1. 扫描件仍是最大分水岭
- 15 款工具中,仅 Docling、ComPDF、AWS Textract、Nanonets、Nutrient、Adobe Acrobat 具备扫描件处理能力
- pdfplumber、Camelot(lattice)、tabula-py、iText 等纯解析型工具在扫描件上完全失效(0 字符/0 表格)
- OCR 能力的有无,是 PDF 表格提取工具的第一道分水岭
2. 文本型PDF的表格结构还原才是真正考验
- 即便是成功提取文字的文本型PDF,能 完整保留表格结构(行列对应/合并单元格/边框样式) 的工具屈指可数
- Docling 在文本型成绩单上产出 27 个 Markdown 表格(18,048 字符),在临床方案表上产出 21 个表格(12,922 字符),AI 驱动的版面分析能力显著领先其他开源工具
- Camelot 在有线表格场景下准确率最高(lattice 97.97%),在无线框表格上 stream 模式同样可用(95.8%),是纯解析工具中的最优选择
- tabula-py 对标准成绩单表格的列识别正确,但编码兼容性存在问题
- iText 文字提取完整(累计 4,146 字符),但表格结构完全丢失,仅输出连续文本流
3. 商业工具 vs 开源工具的差距在复杂表格场景下最大
- 在合并单元格/分层表头场景下,ComPDF 是唯一通过验证的商业 SDK
- 开源工具在简单有线表格上已够用,但在复杂表格场景下差距明显