1. Vibe Coding 与 Spec Coding 是什么?
- Vibe Coding:无前置规范,靠口语化 prompt 即时让 AI 生成代码、边做边改的快速试错式 AI 编程。
- Spec Coding:先产出结构化规格文档,再交由 AI 落地的规范驱动开发。
| 维度 | Vibe Coding | Spec Coding |
|---|---|---|
| 方式 | 即兴 prompt,逐条迭代 | 先写完整规范,再按任务实现 |
| 适用 | 原型、探索、一次性脚本 | 生产功能、团队协作、可维护模块 |
| 代码质量 | 快但易脆弱 | 结构化、可测、可审计 |
| 可复用性 | 一次性对话 | 规范可跨迭代复用 |
| 文档 | 常滞后或缺失 | 规范即文档,随 Git 演进 |
| 团队协作 | 依赖个人 prompt 技巧 | 共享规范与规则,统一标准 |
对大多数项目而言,AI 编辑器与 IDE 插件本身就能修改代码、完成相对完整的功能,但两种方式的差异非常显著。
1.1 两种 AI 编程方式对比
1.1.1 Vibe Coding
由于缺乏整体项目上下文,提出需求时往往必须手动指定代码块,才能让 AI 更精准地识别上下文、保证需求落地。这要求开发者对项目有相当细致的把控,时间与效率成本随之放大,Token 消耗也会成倍增加。
优点:
- 适合小功能迭代、测试 Demo 的快速落地
缺点:
- 缺少约束,需手动把控架构,或经多轮对话详细描述架构,否则容易跑偏
- 深度依赖模型能力;复杂功能受上下文长度限制,最终交付可能无法落地(AI 声称代码已完成、Token 已消耗,但代码报错、功能未做完)
1.1.2 Spec Coding
以文档形式记录每次变更的需求,让 AI 无需通读代码即可快速理解整体上下文。向 AI 提问的方式从过程导向 转变为结果导向:过程导向需要理解 AI 的代码逻辑、手动指定每个部分;结果导向则用自然语言描述规范,过程中少介入具体代码。
能走通这一步,是因为 AI 在修改代码时以文档驱动开发------每次变更都以文档形式沉淀,便于 AI 快速理解项目整体上下文,以及自然语言与代码之间的映射关系。
优点:
- 有明确的需求、接口、边界与异常规范约束 AI,不易逻辑跑偏、漏场景
- 规范可复用、可审计,便于团队协作与长期维护
缺点:
- 每次做功能前,需与 AI 反复对话,把需求点描述清楚

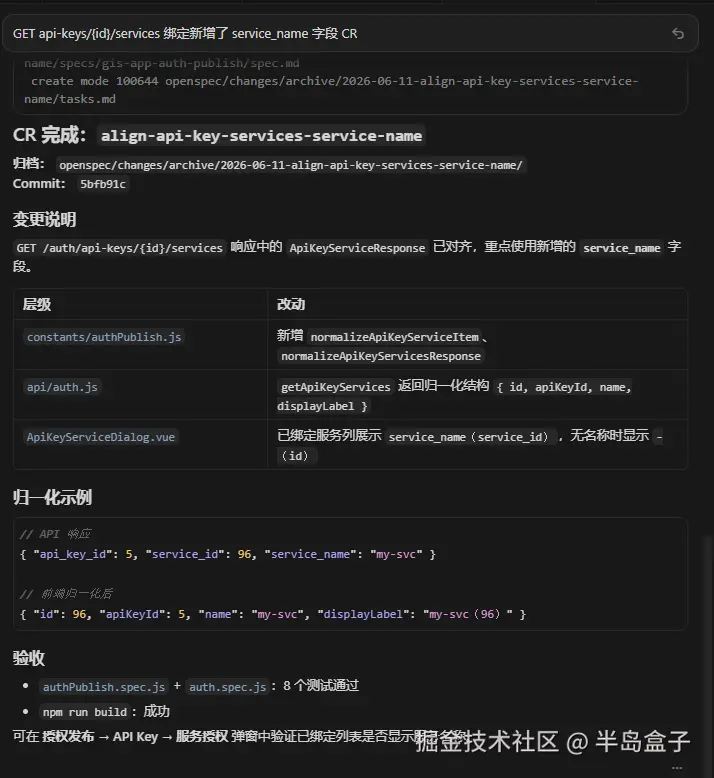
2. Spec Coding 的自动化执行工作流 CR
Spec Coding 的实现方式很多:各类库、插件,乃至 IDE 自带的 Plan 模式,单独拎出来都是一套完整的 Spec Coding。为什么不直接用其中一种?首先,虽然同属 Spec Coding 规范,但各库的实现与用法差异很大------做同一功能,时间成本可能是 8 小时与 10 分钟的区别。其次,单一库对软件开发各环节的覆盖强度并不一致。因此我组合了三套库/技能体系,针对每次修改的每个阶段分别把控,并用 Rule 建立自动化执行工作流,简化大批量命令,提升效率。
引入的三套「库/技能体系」分工明确,分别覆盖软件交付链的不同阶段:
确保 AI 的每次执行结果都可靠、可验收。
┌─────────────┐ ┌──────────────┐ ┌─────────────────┐
│ OpenSpec │ │ Superpowers │ │ agent-skills │
│ 定「做什么」 │ ──► │ 管「怎么做」 │ ──► │ 管「够不够好」 │
│ 需求与变更 │ │ 实现方法论 │ │ 评审与安全门禁 │
└─────────────┘ └──────────────┘ └─────────────────┘2.1 OpenSpec、Superpowers、agent-skills
以下分别介绍各库/插件的定位与职责。
2.1.1 OpenSpec --- 需求与变更的「单一事实来源」
是什么 :基于 spec-driven schema 的变更管理工具链,产物落在 openspec/ 目录。
| 产物 | 作用 |
|---|---|
proposal.md |
Why / What / Impact / 非目标 |
design.md |
技术方案与权衡 |
specs/**/spec.md |
可验收的需求与场景(WHEN / THEN / AND) |
tasks.md |
可勾选、可逐条执行的实现清单 |
archive/ |
完成后合并入主规范,形成项目长期记忆 |
为什么要用:
- 把口头需求变成可验收契约 --- 场景化 spec 比「帮我做个弹窗」可测、可回归
- 控制范围 ---
非目标明确排除项,防止 Vibe 对话中的 scope creep - 变更可追溯 --- 每个 feature/fix 有独立 change 目录,归档后进入
openspec/specs/ - 驱动 Agent 节奏 ---
tasks.md强制「一次一条」,避免批量裸写
2.1.2 Superpowers --- 实现过程的「工程纪律」
是什么 :一组 Cursor Agent Skills(如 using-superpowers、test-driven-development、executing-plans、verification-before-completion),约束写代码的方式,而非替代写代码。
易误解点:Superpowers ≠ 只跑测试。它是「用技能系统来写代码、改行为」。
| 技能 | 阶段 | 职责 |
|---|---|---|
using-superpowers |
每条 task 开始前 | 选择合适方法论(TDD、分步计划等) |
test-driven-development |
写代码过程 | 行为变更先测后写或同步补测 |
executing-plans / subagent-driven-development |
写代码过程 | 按 tasks 分步实现,不跳步 |
verification-before-completion |
全部做完之后 | 有命令输出才能说完成 |
为什么要用:
- 证据先于断言 --- 禁止「应该能跑」;必须
npm run build/npm run test有 exit 0 - 降低 Agent 随机性 --- 同一类任务走同一 skill,输出更稳定
- 实现与规范解耦 --- OpenSpec 不管「先写测试还是先写组件」;Superpowers 管
- 可组合的战术 --- 小改走 TDD,大改走
executing-plans,不必每次 reinvent
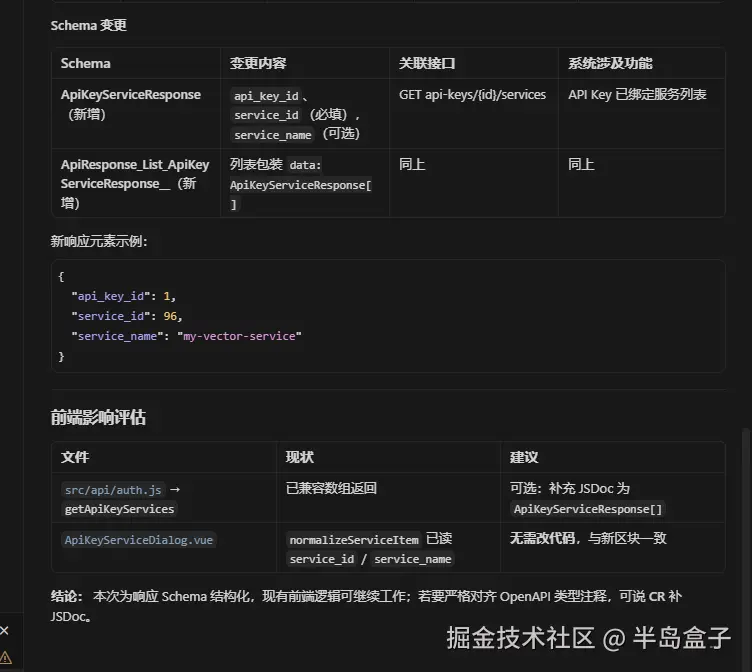
2.1.3 agent-skills --- 合并前的「质量与安全门禁」
是什么 :项目内 .agents/skills/ 下的评审类技能,代表第三方视角对已完成 diff 的审查。
| 技能 | 何时 | 关注点 |
|---|---|---|
code-review-and-quality |
diff 较大或改 3+ 文件 | 正确性、可读性、架构、性能五轴评审 |
security-and-hardening |
auth/API/权限相关 | 注入、鉴权、敏感数据 |
为什么要用:
- 实现者 ≠ 评审者 --- Superpowers 写代码的人容易确认偏误;独立 review 轴补盲
- 合并标准一致 --- 五轴 checklist 比「感觉 OK」可执行
- 安全变更不侥幸 --- 敏感面强制走 hardening,不依赖对话里的口头提醒
2.1.4 三者对比一览
| 对比项 | 普通 Vibe Coding | OpenSpec | Superpowers | agent-skills |
|---|---|---|---|---|
| 核心问题 | 快 | 做什么、做到哪了 | 怎么写、怎么验 | 够不够格上线 |
| 产出形态 | 聊天 + 代码 | Markdown 规范与 tasks | 遵循 skill 的代码与测试 | Review 结论 |
| 触发方式 | 随时 | propose / apply / archive | 写代码与验收时自动遵循 | 大 diff / 敏感变更 |
| 失败模式 | 幻觉、漂移、难维护 | 只写 proposal 不实现 | 跳过验证就说完成 | 无人 review 就 merge |
| 知识沉淀 | 弱 | 强(archive → specs) | 中(流程可复用) | 中(门禁可复用) |
结论 :规范化编程不是否定 Vibe 的灵活,而是把探索 和交付分层------小修小补可用默认模式保留 Vibe 速度;正式功能/修复走完整流水线,换取可维护性与可验收性。
2.2 CR 工作流是什么(不是 Code Review 聊天)
当用户说 CR 、按 CR 、CR 工作流 等触发词时,进入的是完整交付流水线,自动串联上述三套库/技能体系。
结构
| 层次 | 框架 | 一句话 |
|---|---|---|
| 需求层 | OpenSpec | 写清楚做什么、不做什么,拆成可勾选 tasks |
| 实现层 | Superpowers | 按 skill 写代码,用命令输出证明能跑 |
| 质量层 | agent-skills | 独立评审与安全门禁,防止自嗨式合并 |
| 编排层 | Cursor CR.mdc |
用户说 CR → 自动串联上述三层 + 归档 + commit |
普通 Vibe Coding 追求速度 ;规范化编程在 Cursor 里通过 CR 事件流 追求速度 + 可验收 + 可沉淀。二者并存:日常小改用默认模式保留手感,正式交付用 CR 把「氛围」关进 spec 和门禁里,让下一次对话仍然站在同一套事实之上。
公式:
ini
CR = OpenSpec(定做什么)
→ Superpowers(管怎么做)
→ agent-skills(管够不够好)
→ 验收通过 → OpenSpec 归档 + git commit流程:
sql
用户明确说 CR
│
▼
openspec propose(若无 change)→ tasks.md
│
▼
for each task in tasks.md:
│ using-superpowers 选 skill
│ Superpowers 执行(TDD / 分步实现)
│ [x] 勾选
▼
verification-before-completion
│ build + mock/web + E2E/浏览器
▼
agent-skills 质检
▼
openspec archive → git commit → 报告2.3 为什么要「这样结合」------分层职责与互补
(1)OpenSpec 在前:先对齐「做什么」,再动代码
- 问题:Vibe 对话里需求常在实现中途变形。
- 做法 :
proposal锁定 Why/What/非目标;spec用场景写验收标准;tasks拆成可勾选步骤。 - 结合点 :
openspec apply只驱动清单,Agent 不得跳过 tasks 直接裸写------把「计划」和「执行」绑在一起。
(2)Superpowers 在中:统一「怎么做」与「何时算做完」
- 问题:有 tasks 仍可能一次性改十个文件,或没跑测试就 claim 完成。
- 做法 :每条 task 前
using-superpowers;行为变更走 TDD;收尾verification-before-completion。 - 结合点 :OpenSpec 提供节奏 (一条 task),Superpowers 提供方法与证据(怎么写、怎么证)。
(3)agent-skills 在后:实现完成 ≠ 可以合并
- 问题:自写自审容易漏边界、漏安全、漏架构债。
- 做法 :阶段 3 硬性门禁------大 diff 走
code-review-and-quality;auth/API 走security-and-hardening。 - 结合点:Superpowers 保证「能跑」;agent-skills 保证「该跑」且「跑得够好」。
(4)OpenSpec 收尾:把一次交付沉淀为主规范
- 问题:CR 做完若只留 git commit,需求文档仍散落在 change 目录。
- 做法 :
openspec archive合并到openspec/specs/,change 移入archive/YYYY-MM-DD-<name>/。 - 结合点 :形成活文档 --- 下次 Vibe 对话或新 Agent 会话可直接读 spec,而不是重读半年前的 chat。
(5)Cursor Rules 作为编排层
CR.mdc(alwaysApply: true)的角色是编排器,不是第四套框架:
- 定义触发词(何时进入 CR vs 默认模式)
- 规定阶段顺序与禁止项(如:不能用 build alone 代替浏览器验收)
- 绑定项目命令(
npm run build/npm run test/ Playwright E2E) - 规定 OpenSpec 文档语言(简体中文)与归档后 git 行为
没有这层 rule,三套技能各自为战;有了它,用户一句「CR」就能启动可重复的端到端流水线。
2.4 总结
2.4.1 何时用哪种模式(决策建议)
| 场景 | 推荐模式 |
|---|---|
| 一行文案、注释、配置微调 | 默认模式(自然语言) |
| 新页面、跨模块功能、API 对齐 | CR |
| 修生产 bug、需回归证据 | CR |
| 仅同步后端 OpenAPI 文档 | CAPI (另一流水线,见 CAPI.mdc) |
| 探索想法、尚未定需求 | 默认模式 + 可选 openspec explore |
3. CAPI 工作流
前端有一个常见痛点:后端接口变更后,前端要先弄清文档改了什么,再改业务组件,有时组件甚至需要重写。我设计了一条 CAPI 同步流水线------拉取最新 API 文档,与项目已用接口对比,生成变更报告。基于报告可快速定位哪些接口发生了变化,再执行 CR 工作流完成变更落地。