llama.cpp进行模型格式转换和量化
- [1. 什么是llama.cpp](#1. 什么是llama.cpp)
- [2. 核心底层:GGML + GGUF](#2. 核心底层:GGML + GGUF)
- [3. 拉取项目](#3. 拉取项目)
- [4. 安装依赖](#4. 安装依赖)
- [5. 编译](#5. 编译)
- [6. 转换模型](#6. 转换模型)
- [7. 量化](#7. 量化)
本文介绍如何使用llama将safetensor格式的模型装成gguf,并对转换后的模型进行量化。
1. 什么是llama.cpp
llama.cpp 是由开发者 Georgi Gerganov 开源、基于纯 C/C++ 实现的轻量化大语言模型本地推理引擎,MIT 开源协议免费商用,最初为在普通消费硬件运行 Meta LLaMA 模型而生,现已成为本地 / 边缘跑量化大模型的工业事实标准。
核心目标:零 Python 依赖、极致轻量化、全硬件兼容、低内存量化推理,让 7B/13B/34B/70B 大模型在普通 CPU、轻薄本、树莓派、手机、无独显电脑流畅运行。
2. 核心底层:GGML + GGUF
- GGML(底层张量库)
llama.cpp 内置自研 C 张量计算库 GGML,是高性能的根源:
无第三方数学库依赖,手写硬件原生算子;
深度优化 CPU 指令集:x86 AVX2/AVX512/AMX、ARM NEON;
延迟计算图、算子融合、栈内存分配、mmap 文件内存映射,减少内存开销;
统一硬件抽象层,插拔式后端(CPU/CUDA/Metal/Vulkan/ROCm),支持 CPU+GPU 混合推理。 - GGUF(标准模型格式,替代旧 GGML)
GGUF = GGML Universal Format,当前唯一推荐模型格式,本地量化模型通用标准(Hugging Face、Ollama、LM Studio、KoboldCpp 全部支持):
单文件打包一切:权重、分词器、模型架构、上下文长度、Prompt 模板、量化参数全部存在一个 .gguf 文件,无需额外配置;
原生支持内存映射 mmap:模型文件不完整载入内存,低配设备(4GB/8GB 内存)也能加载超大模型;
完整向后兼容,支持 FP16、FP32、各类 2~8bit 量化权重;
结构化元数据,自动识别 LLaMA3、Qwen、Mistral、Gemma、Yi、Mamba 等几乎所有主流开源模型架构。
3. 拉取项目
bash
git clone https://github.com/ggerganov/llama.cpp.git
# 假设根目录是/home/wengad
cd llama.cpp4. 安装依赖
bash
pip install -r requirements.txt5. 编译
bash
make
#或者 cmake -B build && cmake --build build --config Release
cmake -B build && cmake --build build --config Release6. 转换模型
bash
cd /home/wengad/llama.cpp
python convert-hf-to-gguf.py \
/mnt/f/vproject/Moment/models/qwen3_5-4b \
--outfile /mnt/f/vproject/Moment/models/qwen3_5-4b-f16.gguf \
--outtype f16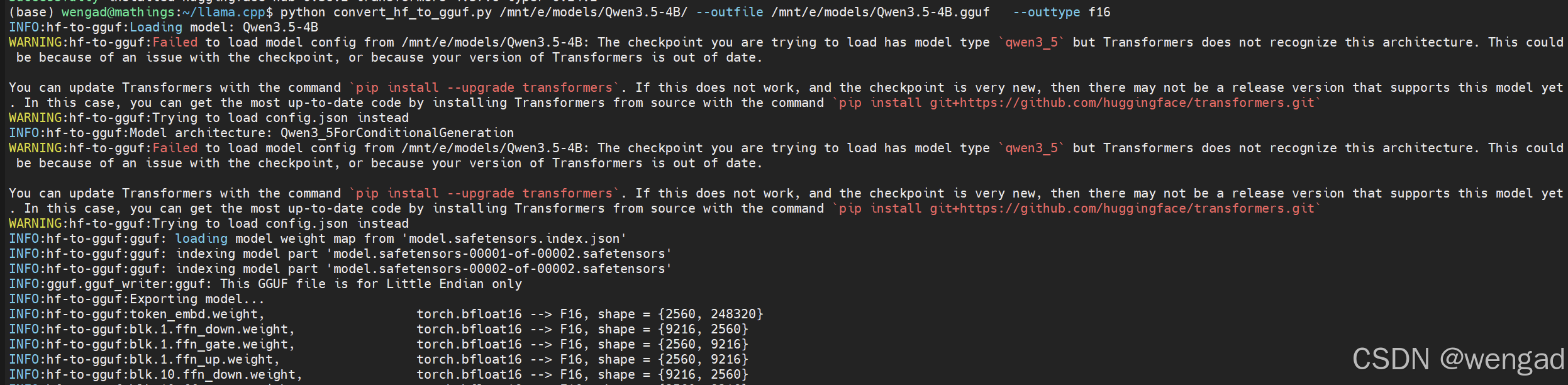
INFO:gguf.gguf_writer:Writing the following files:
INFO:gguf.gguf_writer:/mnt/e/models/Qwen3.5-4B.gguf: n_tensors = 441,
total_size = 8.7G Writing:
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████|
8.65G/8.65G 00:59\<00:00, 145Mbyte/s INFO:hf-to-gguf:Model successfully exported to /mnt/e/models/Qwen3.5-4B.gguf
7. 量化
bash
# 量化
./llama-quantize /mnt/e/models/Qwen3.5-4B.gguf /mnt/e/models/Qwen3.5-4B_q8_0.gguf q8_0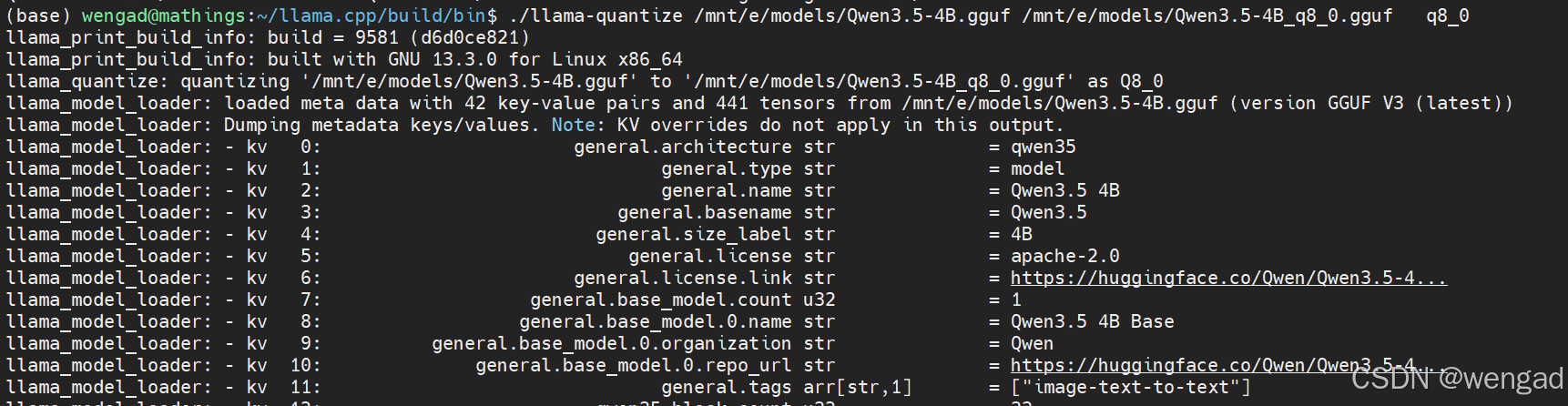
434/ 441 blk.32.ffn_down.weight - [ 9216, 2560,
1, 1], type = f16, converting to q8_0 ... size = 45.00 MiB
-> 23.91 MiB 435/ 441 blk.32.ffn_gate.weight - 2560, 9216, 1, 1, type = f16, converting to q8_0 ...
size = 45.00 MiB -> 23.91 MiB 436/ 441 blk.32.ffn_up.weight
2560, 9216, 1, 1\], type = f16, converting to q8_0 ... size = 45.00 MiB -\> 23.91 MiB \[ 437/ 441
blk.32.nextn.eh_proj.weight - 5120, 2560, 1, 1, type = f16, converting to q8_0 ... size = 25.00 MiB ->
13.28 MiB 438/ 441 blk.32.nextn.enorm.weight - 2560, 1, 1, 1, type = f32, size = 0.010 MiB 439/ 441
blk.32.nextn.hnorm.weight - 2560, 1, 1, 1, type = f32, size = 0.010 MiB 440/ 441
blk.32.nextn.shared_head_norm.weight - 2560, 1, 1, 1, type = f32, size = 0.010 MiB 441/ 441
blk.32.post_attention_norm.weight - 2560, 1, 1, 1, type = f32, size = 0.010 MiB llama_model_quantize_impl:
model size = 8253.72 MiB (16.00 BPW) llama_model_quantize_impl:
quant size = 4386.53 MiB (8.51 BPW)llama_quantize: quantize time = 68303.38 ms llama_quantize: total
time = 68303.38 ms
